Hive小文件处理
MR任务
mr任务参考链接
set hive.exec.reducers.max=3
set hive.exec.dynamic.partition.mode = true; --使用动态分区时,设置为ture。 set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式,默认值:strict,表示必须指定一个分区为静态分区;nonstrict模式表示允许所有的分区字段都可以使用动态分区。一般需要设置为nonstrict。 set hive.exec.max.dynamic.partitions.pernode =10; --在每个执行MR的节点上,最多可以创建多少个动态分区,默认值:100。 set hive.exec.max.dynamic.partitions =1000; --在所有执行MR的节点上,最多一共可以创建多少个动态分区,默认值:1000。 set hive.exec.max.created.files = 100000; --整个MR Job中最多可以创建多少个HDFS文件,默认值:100000。 set hive.error.on.empty.partition = false; --当有空分区产生时,是否抛出异常,默认值:false。 Hive文件产生大量小文件的原因: 一是文件本身的原因:小文件多,以及文件的大小; 二是使用动态分区,可能会导致产生大量分区,从而产生很多小文件,也会导致产生很多Mapper; 三是Reduce数量较多,Hive SQL输出文件的数量和Reduce的个数是一样的。 小文件带来的影响: 文件的数量和大小决定Mapper任务的数量,小文件越多,Mapper任务越多,每一个Mapper都会启动一个JVM来运行,所以这些任务的初始化和执行会花费大量的资源,严重影响性能。 在NameNode中每个文件大约占150字节,小文件多,会严重影响NameNode性能。 解决小文件问题: 如果动态分区数量不可预测,最好不用。如果用,最好使用distributed by分区字段,这样会对字段进行一个hash操作,把相同的分区给同一个Reduce处理; 减少Reduce数量; 进行以一些参数调整。
Hdfs文件数
指定目录下的文件夹,文件,容量大小
[root@mz-hadoop-01 ~]# hdfs dfs -count /user/hive/warehouse/paascloud_tcm.db/dwd/dwd_t_record_detailed568 7433 6065483664 /user/hive/warehouse/paascloud_tcm.db/dwd/dwd_t_record_detailed[root@mz-hadoop-01 ~]# hdfs dfs -count -h /user/hive/warehouse/paascloud_tcm.db/dwd/dwd_t_record_detailed568 7.3 K 5.6 G /user/hive/warehouse/paascloud_tcm.db/dwd/dwd_t_record_detailedHive文件数
SELECT tbl_id,SUM(PARAM_VALUE) AS file_cnts
FROM
(
SELECT * FROM PARTITIONS WHERE tbl_id='97387'
) aLEFT JOIN (SELECT * FROM partition_params WHERE PARAM_KEY='numFiles' ) b
ON a.part_id=b.part_idGROUP BY tbl_id
ORDER BY file_cnts DESC;TBL_ID file_cnts
------ -----------97387 2082
所有文件数
SELECT SUM(PARAM_VALUE) AS file_cnts
FROM
(
SELECT * FROM PARTITIONS
) aLEFT JOIN (SELECT * FROM partition_params WHERE PARAM_KEY='numFiles' ) b
ON a.part_id=b.part_idfile_cnts
-----------340323
表文件数topN
SELECT e.*,f.*
FROM
(SELECT c.*,d.db_id,d.tbl_name
FROM
(
SELECT tbl_id,SUM(PARAM_VALUE) AS file_cnts
FROM
(
SELECT * FROM PARTITIONS
) aLEFT JOIN (SELECT * FROM partition_params WHERE PARAM_KEY='numFiles' ) b
ON a.part_id=b.part_idGROUP BY tbl_id
ORDER BY file_cnts DESC
) cLEFT JOIN (SELECT * FROM tbls
) d
ON c.tbl_id=d.tbl_id) e LEFT JOIN
(SELECT db_id AS db_id2,`desc`,DB_LOCATION_URI,NAME as db_name,OWNER_NAME,OWNER_TYPE FROM dbs
)f ON e.db_id=f.DB_ID2
库文件数topN
select
db_id,db_name,DB_LOCATION_URI,sum(file_cnts) as file_cnts
from (SELECT e.*,f.*
FROM
(SELECT c.*,d.db_id,d.tbl_name
FROM
(
SELECT tbl_id,SUM(PARAM_VALUE) AS file_cnts
FROM
(
SELECT * FROM PARTITIONS
) aLEFT JOIN (SELECT * FROM partition_params WHERE PARAM_KEY='numFiles' ) b
ON a.part_id=b.part_idGROUP BY tbl_id
ORDER BY file_cnts DESC
) cLEFT JOIN (SELECT * FROM tbls
) d
ON c.tbl_id=d.tbl_id) e LEFT JOIN
(SELECT db_id AS db_id2,`desc`,DB_LOCATION_URI,NAME as db_name,OWNER_NAME,OWNER_TYPE FROM dbs
)f ON e.db_id=f.DB_ID2)g group by db_id,db_name,DB_LOCATION_URI order by file_cnts desc小文件压缩任务
package com.mingzhi.common.universalimport com.mingzhi.common.interf.{IDate, MySaveMode}
import com.mingzhi.common.utils.{HiveUtil, SinkUtil, SparkUtils, TableUtils}
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel/*** 处理只有一个分区dt的表*/
object table_compress_process {private var hive_dbs: String = "paascloud"private var hive_tables: String = "dwd_order_info_abi"private var dt: String = "2023-06-30"private var dt1: String = "2023-06-30"def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val builder = SparkUtils.getBuilderif (System.getProperties.getProperty("os.name").contains("Windows")) {builder.master("local[*]")} else {hive_dbs = args(0)hive_tables = args(1)dt = args(2)dt1 = args(3)}val spark: SparkSession = builder.appName("clean_process").getOrCreate()HiveUtil.openDynamicPartition(spark)spark.sql("set spark.sql.shuffle.partitions=1")if ("all".equalsIgnoreCase(hive_dbs)) {val builder = new StringBuilder()val frame_db = spark.sql("show databases").select("databaseName")frame_db.show(false)frame_db.collect().foreach(db => {builder.append(db.toString().replace("[", "").replace("]", ","))})println("dbs:" + builder.toString())hive_dbs = builder.toString()}hive_dbs.split(",").foreach(db => {if (StringUtils.isNotBlank(db)) {if ("all".equalsIgnoreCase(hive_tables)) {compress_all_table(spark, db)} else {hive_tables.split(",").foreach(t => {compress_the_table(spark, db, t)})}}})spark.stop()}private def compress_the_table(spark: SparkSession, hive_db: String, table: String): Unit = {println("compress_the_table======>:" + hive_db + "." + table)spark.sql(s"use $hive_db")if (TableUtils.tableExists(spark, hive_db, table)) {try {new IDate {override def onDate(dt: String): Unit = {/*** 建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)*/val f1 = spark.sql(s"""||select * from $hive_db.$table where dt='$dt'|""".stripMargin).persist(StorageLevel.MEMORY_ONLY)val r_ck: (DataFrame, String) = SparkUtils.persistDataFrame(spark, f1)val f2 = r_ck._1println("f2 show===>")f2.show(false)val type_ = TableUtils.getCompressType(spark, hive_db, table)if ("HiveFileFormat".equalsIgnoreCase(type_)) {println("sink HiveFileFormat table:" + table)SinkUtil.sink_to_hive_HiveFileFormat(spark, f2, hive_db, table, null)} else {//spark表SinkUtil.sink_to_hive(dt, spark, f2, hive_db, table, type_, MySaveMode.OverWriteByDt, 1)}spark.sql(s"drop table ${r_ck._2} ")}}.invoke(dt, dt1)} catch {case e: org.apache.spark.sql.AnalysisException => {println("exception1:" + e)}case e: Exception => println("exception:" + e)}}}private def compress_all_table(spark: SparkSession, hive_db: String): Unit = {spark.sql(s"use $hive_db")val frame_table = spark.sql(s"show tables")frame_table.show(100, false)frame_table.printSchema()frame_table.filter(r => {!r.getAs[Boolean]("isTemporary")}).select("tableName").collect().foreach(r => {//r:[ads_order_topn]val table = r.toString().replace("[", "").replace("]", "")println("compress table:" + hive_db + "." + table)if (TableUtils.tableExists(spark, hive_db, table)) {try {new IDate {override def onDate(dt: String): Unit = {val f1 = spark.sql(s"""||select * from $hive_db.$table where dt='$dt'|""".stripMargin)SinkUtil.sink_to_hive(dt, spark, f1, hive_db, table, "orc", MySaveMode.OverWriteByDt, 1)}}.invoke(dt, dt1)} catch {case e: org.apache.spark.sql.AnalysisException => {println("exception1:" + e)}case e: Exception => println("exception:" + e)}}})}
}相关文章:

Hive小文件处理
MR任务 mr任务参考链接 set hive.exec.reducers.max3 set hive.exec.dynamic.partition.mode true; --使用动态分区时,设置为ture。 set hive.exec.dynamic.partition.mode nonstrict; --动态分区模式,默认值:strict,表示必须…...

go语言学习之旅之Go语言函数
学无止境,今天继续学习go语言的基础内容 Go语言函数 Go 语言函数定义格式如下 func function_name( [parameter list] ) [return_types] {函数体}函数定义解析 func:函数由 func 开始声明 function_name:函数名称,函数名和参数…...
mysql的联合索引最左匹配原则问题
MySQL的联合索引 联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配。 这个结论并不全对!去掉 「between 和 like 」这个结论就没问题了 经过实验的证明,我得出的结论是这样的: 联合索引的最…...
三层交换机实现不同VLAN间通讯
默认时,同一个VLAN中的主机才能彼此通信,那么交换机上的VLAN用户之间如何通信? 要实现VLAN之间用户的通信,就必须借助路由器或三层交换机来完成。 下面以三层交换机为例子说明: 注意: 1.交换机与三层交换…...

C#枚举的使用
在C#中经常会用到枚举,是比较常用的定义一组常量集合的数据类型。我们使用枚举可以更方便理解和阅读代码,增强代码可读性,也在某种程度上提升了编程逻辑和维度。 基本语法: enum MyEnum {Value1,Value2,Value3,//...…...
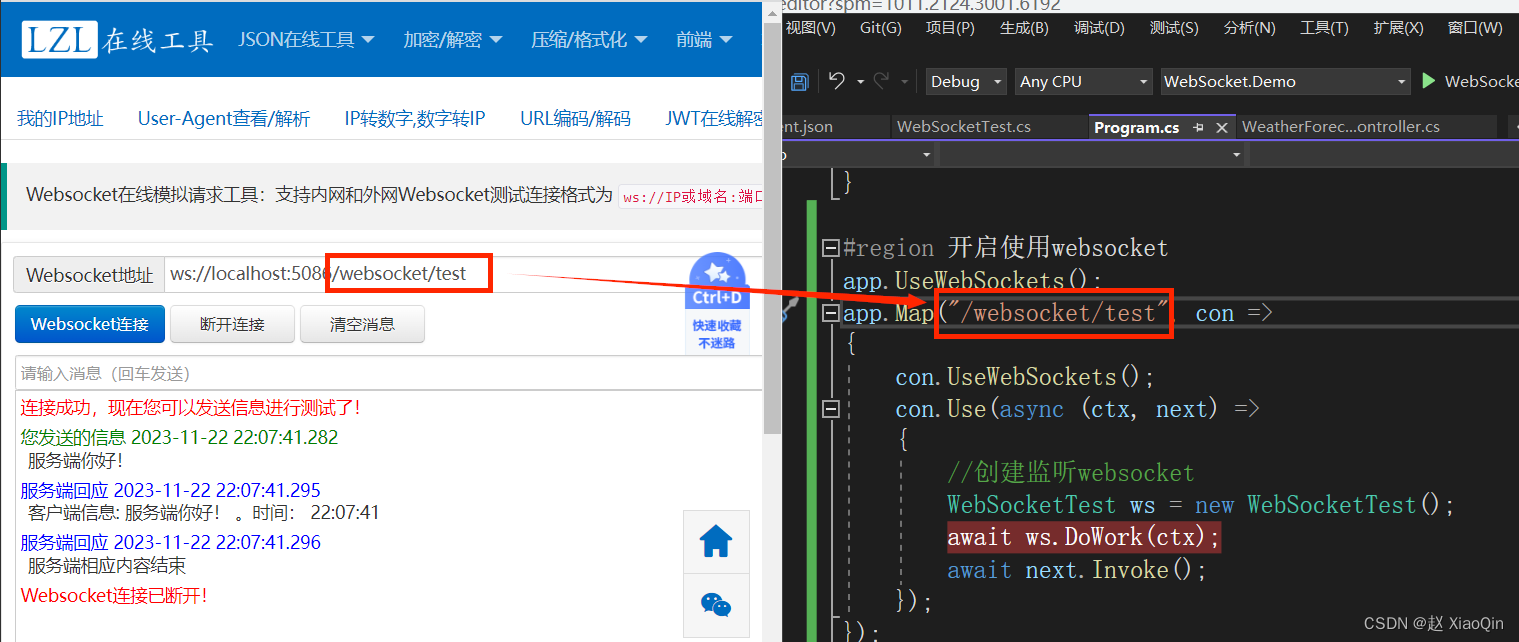
.Net6使用WebSocket与前端进行通信
1. 创建类WebSocketTest: using System.Net.WebSockets; using System.Text;namespace WebSocket.Demo {public class WebSocketTest{//当前请求实例System.Net.WebSockets.WebSocket socket null;public async Task DoWork(HttpContext ctx){socket await ctx.We…...
)
hadoop 编写开启关闭集群脚本, hadoop hdfs,yarn开启关闭脚本。傻瓜式hadoop脚本 hadoop(九)
1. 三台机器: hadoop22, hadoop23, hadoop24 2. hdfs在22机器启动,yarn在hadoop23机器 3. 脚本需要hadoop用户启动才可以 4. 脚本必须在hadoop22机器运行。如果想在所有机器都能运行,你可以自己修改脚本 4. 脚本: #!/bin/bas…...

ArrayList中放的是一个对象,如何同时根据对象中的三个字段对List进行排序
import java.util.ArrayList; import java.util.Collections; import java.util.Comparator;public class YourObject {private int field1;private String field2;private double field3;// 构造函数和其他代码public int getField1() {return field1;}public String getField…...

MONGODB 的基础 NOSQL注入基础
首先来学习一下nosql 这里安装就不进行介绍 只记录一下让自己了解mongodb ubuntu 安装后 进入 /usr/bin ./mongodb即可进入然后可通过 进入的url链接数据库 基本操作 show dbshow dbsshow tablesuse 数据库名插入数据db.admin.insert({json格式的数据})例如 db.admin.inse…...
单链表实现【队列】
目录 队列的概念及其结构 队列的实现 数组队列 链式队列 队列的常见接口的实现 主函数Test.c 头文件&函数声明Queue.h 头文件 函数声明 函数实现Queue.c 初始化QueueInit 创建节点Createnode 空间释放QueueDestroy 入队列QueuePush 出队列QueuePop 队头元…...
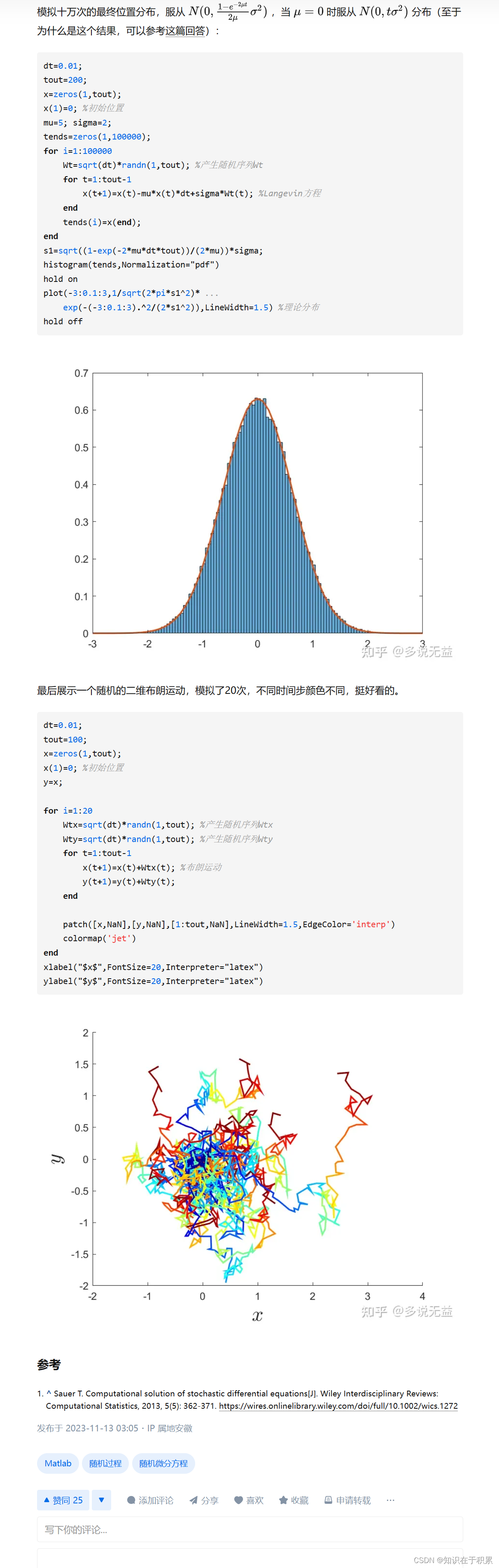
随机微分方程的MATLAB数值求解
dt0.01; tout200; %总时间为2 xzeros(1,tout); x(1)0.5; %初始位置 mu0.2; sigma1; Wtsqrt(dt)*randn(1,tout); %产生随机序列Wt for t1:tout-1x(t1)x(t)mu*x(t)*dtsigma*x(t)*Wt(t); end t11:10:tout; %对原时间序列进行抽样 xtzeros(1,length(t1)); i1; for tt1xt(i)0.5*exp(…...

ChatGPT 也并非万能,品牌如何搭上 AIGC「快班车」
内容即产品的时代,所见即所得,所得甚至超越所见。 无论是在公域的电商平台、社交媒体,还是品牌私域的官网、社群、小程序,品牌如果想与用户发生连接,内容永远是最前置的第一要素。 01 当内容被消费过,就…...

【JavaSE】不允许你不会使用String类
🎥 个人主页:深鱼~🔥收录专栏:JavaSE🌄欢迎 👍点赞✍评论⭐收藏 目录 前言: 一、常用方法 1.1 字符串构造 1.2 String对象的比较 (1)比较是否引用同一个对象 注意…...
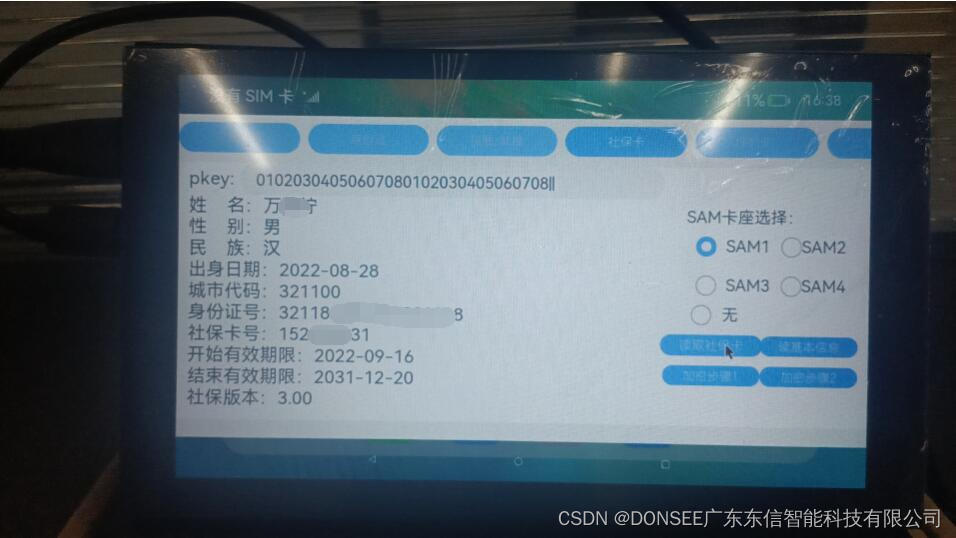
身份证阅读器和社保卡读卡器Harmony鸿蒙系统ArkTS语言SDK开发包
项目需求,用ArkTS新一代开发语言实现了在Harmony鸿蒙系统上面兼容身份证阅读器和社保卡读卡器,调用了DonseeDeviceLib.har这个读卡库。 需要注意的是,鸿蒙系统的app扩展名为.hap,本项目编译输出的应用为:entry-default…...

并发与并行
并发和并行是操作系统中的两个重要概念,它们在定义和处理任务的方式上有一些区别。 并发(concurrency)是指在一段时间内,有多个程序都处于启动运行到运行完毕之间,但任一时刻点上只有一个程序在处理机上运行。它是一种…...
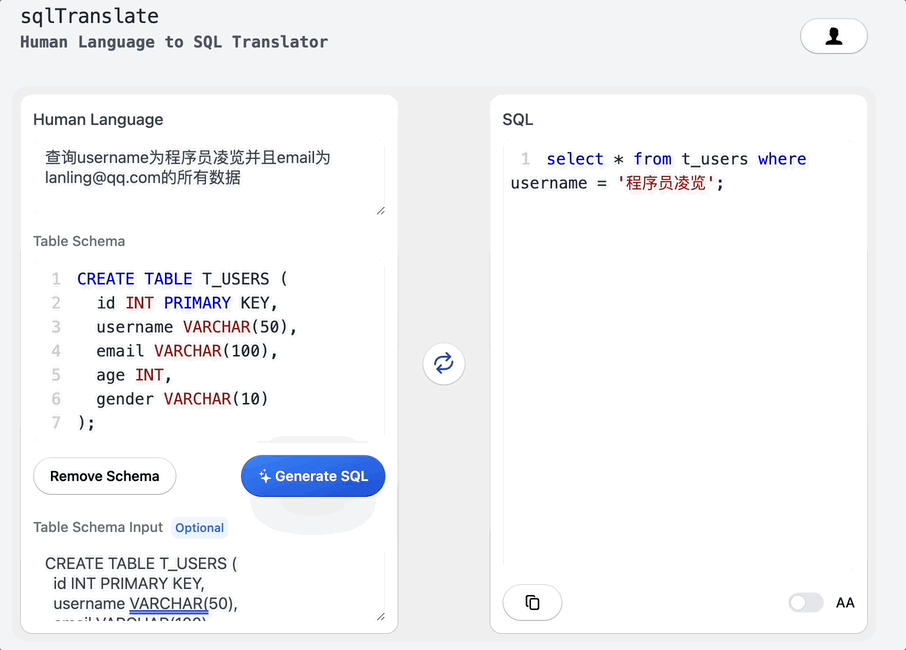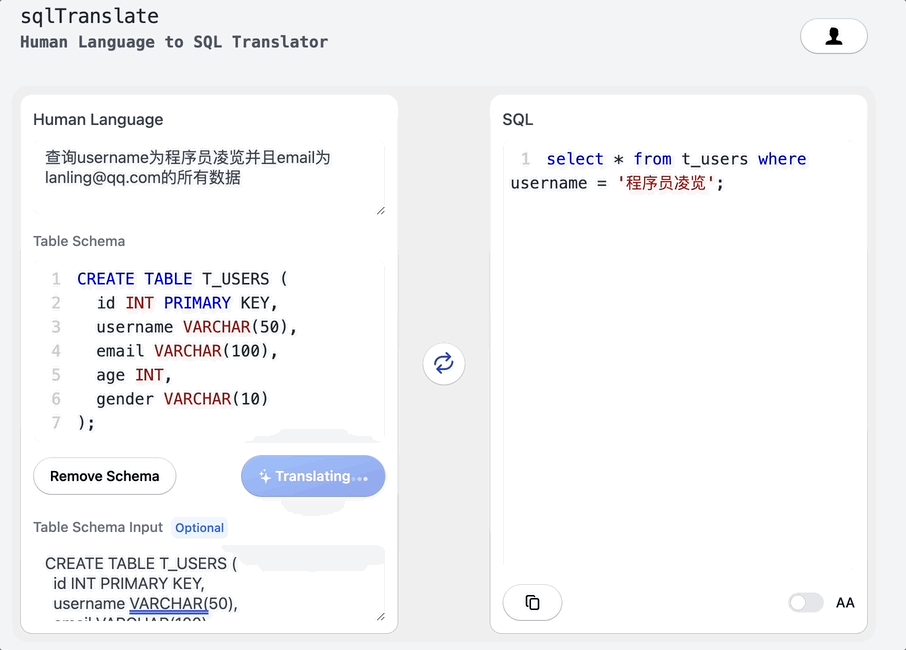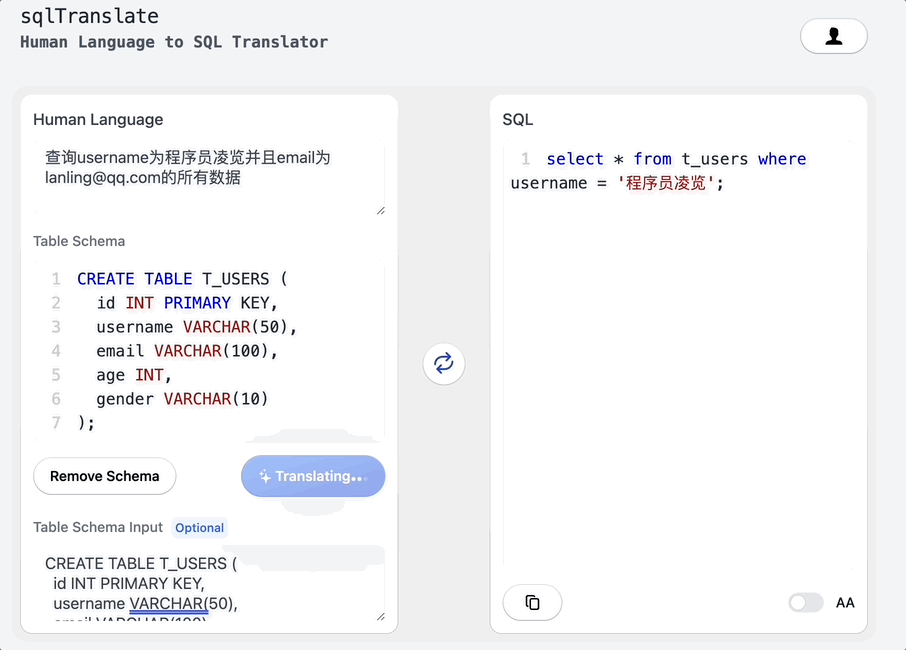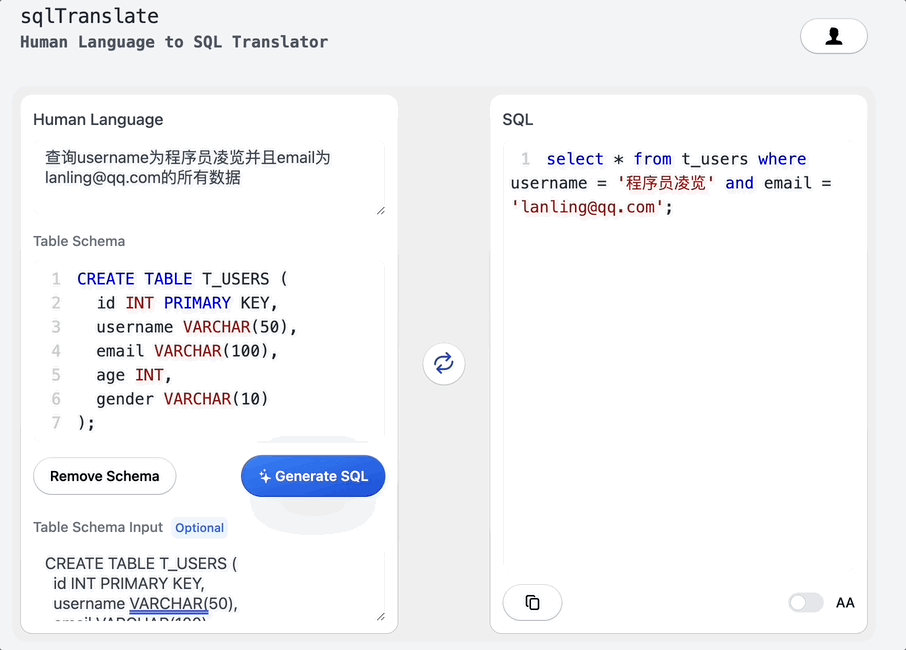
搭个网页应用,让ChatGPT帮我写SQL
大家好,我是凌览。 开门见山,我搭了一个网页应用名字叫sql-translate。访问链接挂在我的个人博客(https://linglan01.cn/about)导航栏,也可以访问https://www.linglan01.cn/c/sql-translate/直达sql-translate。 它的主要功能有:…...

实时云渲染 助力破解智慧园区痛点困局
智慧园区是运用先进的信息技术,如物联网(IoT)、大数据、云计算、人工智能、三维可视化等,对园区内的各类设施、资源以及管理进行智能化和数字化升级。其目标是通过科技手段提升园区的运营效率、资源利用率,提供更便捷、…...

计算机组成原理2
1.浮点数 2.IEEE 754 3.存储器的性能指标 4.存储器的层次化结构 主存类似手机运行内存8g ,辅存类似手机内存128g.... 辅存必须先通过主存才能被cpu接收,就例如微信打开那个月亮小人界面两三秒就是主存在读取辅存的程序然后被cpu接收运行。 5.主存储…...

Py之PyMuPDF:PyMuPDF的简介、安装、使用方法之详细攻略
Py之PyMuPDF:PyMuPDF的简介、安装、使用方法之详细攻略 目录 PyMuPDF的简介 PyMuPDF的安装 PyMuPDF的使用方法 1、基础用法 PyMuPDF的简介 PyMuPDF是一个高性能的Python库,用于PDF(和其他)文档的数据提取,分析,转换和操作。 …...

2023亚太杯数学建模A题B题C题思路模型代码论文指导
2023亚太地区数学建模A题思路:开赛后第一时间更新,获取见文末 名片 2023亚太地区数学建模B题思路:开赛后第一时间更新,获取见文末 名片 2023亚太地区数学建模C题思路:开赛后第一时间更新,获取见文末 名片…...

Koin 开发者炸了!7 条规则根治运行时错误,自动扫描太香了
编译零警告,测试全绿,上线直接炸。 用过 Koin 的人或多或少都经历过这种场景——NoBeanDefFoundException 在某个不起眼的页面突然蹦出来,而你根本不知道是哪个依赖没注册。 这不是 Bug,是 Koin 的"特性"。它的运行时解…...

为内部知识库问答系统接入Taotoken实现智能检索增强
为内部知识库问答系统接入Taotoken实现智能检索增强 1. 知识库智能检索的技术需求 企业内部知识库系统通常面临文档量大、检索效率低、自然语言理解能力不足等问题。传统关键词匹配方式难以准确理解员工提出的复杂问题,导致大量有价值的知识无法被有效利用。通过集…...

创业团队如何借助Taotoken实现多模型API的成本透明与统一管理
创业团队如何借助Taotoken实现多模型API的成本透明与统一管理 1. 多模型统一接入的痛点与解决方案 创业团队在开发AI应用时,往往需要同时调用多个大模型以适配不同场景需求。传统模式下,开发者需要分别对接各家厂商的API,管理多个平台的账号…...

【Dify 2026日志审计终极指南】:覆盖采集、脱敏、溯源、告警、留存5大环节的GDPR+等保3.0双合规落地方案
更多请点击: https://intelliparadigm.com 第一章:Dify 2026日志审计全链路合规治理总览 Dify 2026 版本将日志审计能力深度融入平台治理内核,构建覆盖采集、传输、存储、分析、告警与归档六大环节的全链路合规闭环。该体系严格遵循《GB/T 3…...

FortiGate-VM on KVM是什么
FGT-KVM(FortiGate-VM on KVM)是飞塔(Fortinet)推出的虚拟化下一代防火墙,核心是把硬件FortiGate的全量安全能力迁移到Linux KVM环境,兼顾虚拟化弹性与企业级防护。 一、核心安全功能(全量Forti…...
Translumo终极指南:如何用免费开源工具实现实时屏幕翻译?[特殊字符][特殊字符]
Translumo终极指南:如何用免费开源工具实现实时屏幕翻译?🎮📖 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.…...

详解C语言初阶之函数
.main函数第一个函数是我们的main函数,它无处不在,main函数被称之为我们的入口函数,程序在运行时,从main函数进入,从main函数出来,main函数其实就是整个程序功能的集合,所有的功能必须被包含在m…...

【matlab代码】基于粒子群算法的分布式电源选址定容多目标优化
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

不会写代码也能做项目?手把手教你用 Vibe Coding 快速落地 AI 项目
导读: 你是否曾经有过一个很棒的项目想法,却因为"不会写代码"而迟迟不敢开始?本文将通过一个真实案例——在 NanaDraw 中集成 MinerU PDF 解析功能,带你理解 Vibe Coding 这种全新的 AI 协作开发方式,让你从…...
)
别再傻傻分不清!给硬件小白的SSD、eMMC、UFS选购避坑指南(附手机/电脑场景推荐)
别再傻傻分不清!给硬件小白的SSD、eMMC、UFS选购避坑指南(附手机/电脑场景推荐) 当你站在数码卖场,面对琳琅满目的手机、电脑和平板,是否曾被"UFS 3.1"、"eMMC 5.1"这些专业术语搞得一头雾水&…...