R语言——taxize(第四部分)
taxize(第四部分)
- 3.39. get_wiki(获取维基分类群的页面名称)
- 3.40. get_wormsid(获取分类群名称的Worms ID)
- 3.41. gni_details(使用Global Names Index搜索分类学名称详情)
- 3.42. gni_parse(使用 EOL 的名称解析器解析科学名称)
- 3.43. gni_search(使用Global Names Index搜索分类学名称)
- 3.44. gnr_datasources(全球名称解析器数据源)
- 3.45. gnr_resolve(使用 Global Names Resolver 解析名称)
- 3.46. gn_parse(使用全球名称解析器解析科学名称)
- 3.47. id2name(将分类标识转换为分类名称)
- 3.48. ion(生物名称索引)
- 3.49. iplant_resolve(iPlant 名称解析)
- 3.50. ipni_search(在国际植物名称索引 (IPNI) 中搜索名称)
- 3.51. itis_acceptname(检索已接受的 TSN 和名称)
- 3.52. itis_downstream(检索给定 TSN 层次结构下游的所有类群名称或 TSN)
- 3.53. itis_getrecord(获取一个或多个 ITIS TSN 或 lsid 的完整 ITIS 记录)
- 3.54. itis_hierarchy(ITIS 层级结构)
- 3.55. itis_kingdomnames(获取界名)
- 3.56. itis_lsid(通过 LSID 获取 TSN(
- 3.57. itis_name(根据给定的分类名称查询获取分类名称)
- 3.58. itis_native(获取辖区数据,即在某个地区原生或非原生)
- 3.59. itis_refs(获取与 ITIS TSN 相关的参考文献)
- 3.60. itis_taxrank(从给定的 TSN 中检索分类等级名称)
- 3.61. itis_terms(获取 ITIS 术语,即 tsn、作者、俗名和学名)
- 3.62. iucn_getname(获取任何匹配的 IUCN 物种名称)
- 3.63. iucn_id(为世界自然保护联盟(IUCN)列出的分类群获取 ID)
- 3.64. iucn_status(iucn-class 的提取函数)
- 3.65. iucn_summary(从世界自然保护联盟红色名录中获取摘要)
- 3.66. key_helpers(为不同数据源设置身份验证的助手)
- 3.67. lowest_common(检索给定分类群名称或 ID 的最低常见分类群和等级)
- 3.68. names_list(随机获取物种名称向量)
- 3.69. nbn_classification(搜索英国国家生物多样性网络数据库中的生物分类)
- 3.70. nbn_search(搜索英国国家生物多样性网络)
3.39. get_wiki(获取维基分类群的页面名称)
用法:
get_wiki(sci_com, wiki_site = "species", wiki = "en", ask = TRUE, messages = TRUE, limit = 100, rows = NA, x = NULL, ...)as.wiki(x, check = TRUE, wiki_site = "species", wiki = "en")## S3 method for class 'wiki'
as.wiki(x, check = TRUE, wiki_site = "species", wiki = "en")## S3 method for class 'character'
as.wiki(x, check = TRUE, wiki_site = "species", wiki = "en")## S3 method for class 'list'
as.wiki(x, check = TRUE, wiki_site = "species", wiki = "en")## S3 method for class 'numeric'
as.wiki(x, check = TRUE, wiki_site = "species", wiki = "en")## S3 method for class 'data.frame'
as.wiki(x, check = TRUE, wiki_site = "species", wiki = "en")## S3 method for class 'wiki'
as.data.frame(x, ...)get_wiki_(x, messages = TRUE, wiki_site = "species", wiki = "en", limit = 100, rows = NA, ...)
参数:
- sci_com:(字符型)一个或多个学名或俗名。或taxon_state对象。
- wiki_site:(字符型)维基站点。species(默认)、pedia、commons其中之一。
- wiki:(字符型)语言。默认:英语(en)。
- ask:(逻辑型)get_wiki 是否应在交互模式下运行?如果 “true”(“正确”),且发现该物种有一个以上的 wiki,则会要求用户输入。如果为 FALSE,多个匹配项将返回 NA。
- messages:(逻辑型)是否应该输出进展情况?
- limit:(整数型)返回的结果数量。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NaN,则考虑所有行。需要注意的是,这个函数仍然只能返回一个包含一到多个标识符的 wiki类对象。请参阅 get_wiki_(),获取问询过程中显示的全部或部分原始数据。
- x:对get_wiki()而言已废弃,请使用sci_com。对于as.wiki而言可使用。
- …:请忽略。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅在 as.wiki() 中使用。
说明:对于 wiki_site = “pedia”,我们默认使用英语网站。wiki 参数设置不同的语言。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且行不等于 NA,则返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。有关属性和例外情况的更多详情,请参阅 get_id_details。
示例:get_wiki(sci_com = "Quercus douglasii")
3.40. get_wormsid(获取分类群名称的Worms ID)
用法:
get_wormsid(sci_com, searchtype = "scientific", marine_only = TRUE, fuzzy = NULL, accepted = FALSE, ask = TRUE, messages = TRUE, rows = NA, query = NULL, ...)as.wormsid(x, check = TRUE)## S3 method for class 'wormsid'
as.wormsid(x, check = TRUE)## S3 method for class 'character'
as.wormsid(x, check = TRUE)## S3 method for class 'list'
as.wormsid(x, check = TRUE)## S3 method for class 'numeric'
as.wormsid(x, check = TRUE)## S3 method for class 'data.frame'
as.wormsid(x, check = TRUE)## S3 method for class 'wormsid'
as.data.frame(x, ...)get_wormsid_(sci_com, messages = TRUE, searchtype = "scientific", marine_only = TRUE, fuzzy = NULL, accepted = TRUE, rows = NA, query = NULL, ...)
参数:
- sci_com:(字符型)一个学名或俗名向量。或taxon_state对象。
- searchtype:(字符型)“scientific”(默认)或 "common"或任意标准的缩写。
- marine_only:(逻辑型)仅用于海洋?TRUE(仅在 searchtype=“scientific” 时使用);传递给 worrms::wm_records_name()。
- fuzzy:(逻辑型)模糊搜索: NULL(searchtype="scientific "时为 TRUE,searchtype="common "时为 FALSE,以匹配 worrms 软件包中这些参数的默认值);传递给 worrms::wm_records_name() 或 worrms::wm_records_common()。
- accepted:(逻辑型)如果设置为 TRUE,则删除 WORMS 不接受的有效名称。设为 FALSE(默认值),则同时返回已接受和未接受的名称。
- ask:(逻辑型)是否应在交互模式下运行 get_tsn?如果为 “true”,并且为该物种找到了一个以上的 wormsid,则会要求用户输入。如果为 FALSE,多个匹配结果将返回 NA。
- messages:(逻辑型)是否应打印进度?
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个 wormsid类对象,其中包含一到多个标识符。请参阅 get_wormsid_(),获取问询过程中显示的全部或部分原始数据。
- query:已废弃,请使用sci_com。
- …:请忽略。
- x:传递给as.wormsid的参数。
- check:(逻辑型)检查 ID 是否与数据库中已有的 ID 匹配,仅用于 as.wormsid()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。请参阅 get_id_details,了解更多详细信息,包括属性和异常。
示例:get_wormsid('Pomatomus saltatrix')
3.41. gni_details(使用Global Names Index搜索分类学名称详情)
说明:使用《全球名称索引》,请参见 http://gni.globalnames.org/
用法:gni_details(id, all_records = 1, ...)
参数:
- id:名称id。必需参数。
- all_records:如果 all_records 为 1,GNI 会从所有资源库中返回名称为
字符串(取 0 或 1 [默认值])的所有记录。 - …:传递给crul::verb-GET的可选参数。
返回值:数据框。
示例:gni_details(id = 17802847)
3.42. gni_parse(使用 EOL 的名称解析器解析科学名称)
用法:gni_parse(names, ...)
参数:
- names:一个或多个科学名的向量。
- …:传递给crul::verb-GET的可选参数。
返回值:包含结果、提交的名称和解析后的名称及其附加信息的 data.frame 文件。
示例:gni_parse("Cyanistes caeruleus")
3.43. gni_search(使用Global Names Index搜索分类学名称)
用法:
gni_search(sci, per_page = NULL, page = NULL, justtotal = FALSE, parse_names = FALSE, search_term = NULL, ...)
参数:
-
sci:(字符型)必填。要搜索的名称模式。警告:不适用于普通名称。搜索词可包括以下选项(注意:can、uni、gen、sp、ssp、au、yr 仅对解析后的名称有效)。
- *通配符 - 按单词的一部分搜索。
- exact - 搜索完全匹配的字符串。
- ns - 从字面字符串开始搜索(其他修饰符将被忽略)。
- can - 搜索不含作者的名称(其他修饰词将被忽略)。
- uni - 搜索高等分类群。
- gen - 按物种名称的属名搜索。
- sp - 按物种名称搜索。
- ssp - 按种下特征词搜索。
- au - 按作者搜索。
- yr - 按年份搜索。
-
per_page:每页的条目数(大于 1000 的数字将减至 1000)(默认为 30)。
-
page:要查看的页码(默认为 1)。
-
justtotal:只返回找到的全部结果。
-
parse_names:如果为 TRUE,则使用 gni_parse()解析名称。默认值 FALSE。
-
search_term:已废弃,请使用sci。
-
…:传递给crul::verb-GET的可选参数。
说明:请注意,您可以使用模糊搜索,例如在搜索词末尾添加星号。
返回值:数据框。
示例:gni_search(sci = "ani*")
3.44. gnr_datasources(全球名称解析器数据源)
用法:gnr_datasources(..., todf)
参数:
- …:传递给crul::HttpClient的可选参数。
- todf:已失效,现在总能返回一个 data.frame。
返回值:数据框/堆。
示例:gnr_datasources()
3.45. gnr_resolve(使用 Global Names Resolver 解析名称)
用法:
gnr_resolve(sci, data_source_ids = NULL, resolve_once = FALSE, with_context = FALSE, canonical = FALSE, highestscore = TRUE, best_match_only = FALSE, preferred_data_sources = NULL, with_canonical_ranks = FALSE, http = "get", cap_first = TRUE, fields = "minimal", names = NULL, ...)
参数:
- sci:(字符型)要解决的分类名称。不适用于俗名/普通名称。
- data_source_ids:(字符型)ID 用于指定搜索的数据源。请参阅 gnr_datasources()。
- resolve_once:(逻辑型)查找第一个可用的匹配项,而不是在所有数据源中查找名称所有可能呈现的匹配项。TRUE 时,响应迅速但不完整。
- with_context:(逻辑型)降低与分类学同形异义词匹配的可能性。当 "true "时,将为所有提供的名称计算共同的分类背景,这些名称来自具有分类树路径的数据源中的匹配结果。在计算分数时,未确定上下文的名称将受到。
- canonical:(逻辑型)如果为 FALSE(默认值),将返回带有分类学权威的名称。如果为 “true”,则返回社会名称(不含分类机关和缩写)。
- highestscore:(逻辑型)返回每个搜索名称得分最高的那些名称?失效。
- best_match_only:(逻辑型)如果为 TRUE,则只返回最佳匹配结果。默认值 FALSE。
- preferred_data_sources:(字符型)一个或多个数据源 ID 的向量。
- with_canonical_ranks:(逻辑型)如果存在,返回带有种下等级的名称。如果为 TRUE,则强制执行 canonical=TRUE,否则该参数将不起作用。默认值 FALSE。
- http:要使用的 HTTP 方法,可选 "get "或 “post”。默认值:“get”。对于大型查询,请使用 http=“post”。大于 300 条记录的查询会自动使用 “post”,因为 "get "会失败。
- cap_first:(逻辑型)对每个名字进行修正,使名字的第一个部分大写,而其他部分不大写。该网络服务对大写字母很敏感,因此不同的大写字母会得到不同的结果。名字大写可能是你想要的,也是默认设置。如果为 FALSE,则不修改姓名。默认值: TRUE。
- fields:(字符型)minimal(默认)或all。最小化只返回四个字段,而全部返回所有字段。
- names:已弃用,请使用sci。
- …:传递给crul::HttpClient的可选参数。
返回值:带有一个属性 not_known 的 data.frame:全球名称索引未知类群的字符向量。访问方式如 attr(output, “not_known”) 或 attributes(output)$not_known。输出 data.frame 的列:
- user_supplied_name:你传入 names 参数的名称,保持不变。
- submitted_name:提交到 GNR 服务的实际名称。
- data_source_id:数据源 ID。
- data_source_title:数据源名称。
- gni_uuid:全球名称索引 UUID(又称标识符)。
- matched_name:在 GNR 服务中匹配的名称。
- matched_name2:如果 canonical=TRUE 则返回,否则不返回 matched_name。
- classification_path:分类树的名称,名称之间用管道 (|) 分隔。
- classification_path_ranks:分类树的等级,名称之间用管道 (|) 分隔。
- classification_path_ids:分类树的标识符,名称之间用管道 (|) 分隔。
- taxon_id:分类标识符。
- edit_distance:编辑距离。
- imported_at:输入日期。
- match_type:匹配模式。
- match_value:匹配模式的描述。
- prescore:预评分。
- score:评分。
- local_id:本地识别码。
- url:类群的链接。
- global_id:全球标识符。
- current_taxon_id:当前分类群 ID。
- current_name_string:当前名称字符串。
请注意,如果名称(即行)为 NA、长度为零的字符串、非字符矢量或应用程序接口未找到,则将被删除。
全球名称解析器中数据集的年代:全局名称解析器中使用的数据集的更新时间各不相同。请参阅 gnr_datasources() 输出中的 updated_at 字段,了解每个数据集的最后更新日期。
首选数据源:如果使用首选数据源,则只返回首选数据(如果有结果的话)。
示例:gnr_resolve(sci = c("Helianthus annuus", "Homo sapiens"))
3.46. gn_parse(使用全球名称解析器解析科学名称)
用法:gn_parse(names, ...)
参数:
- names:一个或多个科学名的向量。
- …:传递给crul::verb-GET的可选参数。
返回值:包含结果、提交的名称和解析后的名称及其附加信息的 data.frame 文件。
示例:gn_parse("Cyanistes caeruleus")
3.47. id2name(将分类标识转换为分类名称)
用法:
id2name(id, db = NULL, x = NULL, ...)## Default S3 method:
id2name(id, db = NULL, x = NULL, ...)## S3 method for class 'tolid'
id2name(id, ...)## S3 method for class 'tsn'
id2name(id, ...)## S3 method for class 'uid'
id2name(id, ...)## S3 method for class 'wormsid'
id2name(id, ...)## S3 method for class 'gbifid'
id2name(id, ...)## S3 method for class 'boldid'
id2name(id, ...)
参数:
- id:分类标识向量(字符型或数值型)。
- db:(字符型)要查询的数据库。TOL、ITS、NCBI、WORMS、GBIF 或bold中的一个或多个。请注意,每个分类数据源都有自己的标识符,因此 因此,如果您为标识符提供了错误的 db 值,您可能会得到一个结果、 但很可能是错误的(不是您所期望的)。如果使用 ncbi,我们建议您获取 API 密钥;请参阅 taxize-authentication。
- x:已弃用,请使用id。
- …:传递给l_id2name 或 itis_getrecord 或其他内部函数的其他参数。关于可以传递哪些参数,请参阅这些函数。
返回值:以输入的分类id命名的data.frame列表。
NCBI请求的HTTP版本:本方法硬编码了http_version=2L以便让HTTP请求使用HTTP/1.1访问Entrez API。详见curl::curl_symbols(“CURL_HTTP_VERSION”)。
示例:id2name(19322, db = "itis")
3.48. ion(生物名称索引)
用法:ion(x, ...)
参数:
- x:LSID 编号。必须填写。
- …:传递给crul::verb-GET的可选参数。
返回值:数据框。
示例:ion(155166)
3.49. iplant_resolve(iPlant 名称解析)
用法:iplant_resolve(sci, retrieve = "all", query = NULL, ...)
参数:
- sci:一个或多个分类名称向量(非俗名)。
- retrieve:指定是否检索所提交名称的所有匹配项。best (只检索提交的每个名字的单个最佳匹配项)或 all(检索所有匹配项)中的一个。
- query:已废弃,请使用sci。
- …:传递给crul::verb-GET的可选参数。
返回值:数据框。
示例:iplant_resolve(sci=c("Helianthus annuus", "Homo sapiens"))
3.50. ipni_search(在国际植物名称索引 (IPNI) 中搜索名称)
说明:全球地名索引(GNI)(http://gni.globalnames.org/data_sources)也提供了这一数据源。不过,这两种服务的数据接口有所不同。
用法:
ipni_search(family = NULL, infrafamily = NULL, genus = NULL, infragenus = NULL, species = NULL, infraspecies = NULL, publicationtitle = NULL, authorabbrev = NULL, includepublicationauthors = NULL, includebasionymauthors = NULL, geounit = NULL, addedsince = NULL, modifiedsince = NULL, isapnirecord = NULL, isgcirecord = NULL, isikrecord = NULL, ranktoreturn = NULL, output = "minimal", ...)
参数:
- family:科名。
- infrafamily:科下名。
- genus:属名。
- infragenus:属下名。
- species:种名。
- infraspecies:种下名。
- publicationtitle:要搜索的出版物名称或缩写。同样,用 "+"代替空格(例如 “J.+Bot.”)。
- authorabbrev:要搜索的作者标准格式(出版作者、词源作者或两者)。
- ·includepublicationauthors:TRUE(默认)表示在搜索中包含分类群作者,FALSE 表示不包含分类群作者。
- includebasionymauthors:TRUE(默认)表示在搜索中包含basionum作者,FALSE 表示不包含basionum作者。
- geounit:要搜索的国家名称或其他地理单元。
- addedsince:要搜索的日期,格式为 “yyyy-mm-dd”,例如,2005-08-01 表示自 2005 年 8 月 1 日以来添加的所有记录。如果提供,格式必须是 YYYY-MM-DD,且必须大于或等于 1984-01-01。
- modifiedsince:要搜索的日期,格式为 “yyyy-mm-dd”,例如,2005-08-01 表示自 2005 年 8 月 1 日以来编辑的所有记录。如果提供,格式必须为 YYYYMM-DD,且必须大于或等于 1993-01-01。
- isaprirecord:FALSE(默认)排除澳大利亚植物名称索引中的记录。
- isgcirecord:FALSE(默认)排除灰卡索引中的记录。
- isikrecord:FALSE(默认)排除《邱园索引》中的记录。
- ranktoreturn:选择返回的等级的几个选项之一。
- output:minimal (default), classic, short, or extended选项之一。
- …:传递给crul::verb-GET的可选参数。
说明:ranktoreturn的可选项有:
- all:所有记录。
- fam:科级记录。
- infrafam:科下记录。
- gen:属级记录。
- infragen:属下记录。
- spec:种级记录。
- infaspec:种下记录。
返回值:数据框/堆。
示例:ipni_search(genus='Brintonia', isapnirecord=TRUE, isgcirecord=TRUE, isikrecord=TRUE)
3.51. itis_acceptname(检索已接受的 TSN 和名称)
用法:itis_acceptname(searchtsn, ...)
参数:
- searchtsn:一个分类群的一个或多个 TSN。
- …:传递给crul::verb-GET的可选参数。
返回值:data.frame 的行数等于输入矢量长度,有三列:
- submittedtsn:提交的 TSN。
- acceptedname:接受的名称 - 如果提交的 TSN 是接受的 TSN,则为 NA_character_,因为如果 TSN 是接受的名称,ITIS 不会随 TSN 返回名称。我们可以向 ITIS 提出额外的 HTTP 请求,但这意味着需要额外的时间。
- acceptedtsn:接受的 TSN。
- author:命名人。
示例:itis_acceptname(searchtsn = 208527)
3.52. itis_downstream(检索给定 TSN 层次结构下游的所有类群名称或 TSN)
用法:itis_downstream(id, downto, intermediate = FALSE, tsns = NULL, ...)
参数:
- id:分类序列号。
- downto:您希望深入到的分类级别。分类级别区分大小写,必须拼写正确。拼写请参见 data(rank_ref)。
- intermediate:(逻辑型)如果为 “true”,则返回包含目标分类群等级名称的长度为 2 的列表,以及中间分类群的附加 data.frame 列表。默认值: FALSE。
- tsns:已弃用,请使用id。
- …:传递给 ritis::rank_name() 和 ritis:hierarchy_down() 的其他参数。
返回值:从目、类等到科的下游分类信息的 Data.frame,或者,如果 intermediated=TRUE,长度为 2 的列表,包含目标分类群等级名称和中间名称。
示例:itis_downstream(id = 846509, downto="genus")
3.53. itis_getrecord(获取一个或多个 ITIS TSN 或 lsid 的完整 ITIS 记录)
用法:itis_getrecord(values, by = "tsn", ...)
参数:
- values:(字符型)一个或多个分类群的 TSN(分类序号)或 lsid。
- by:(字符型)按 “tsn”(默认)或 “lsid”。
- …:传递给 ritis::full_record 的其他参数。
注意:只能在 tsn 参数或 lsid 中输入值,不能同时输入。
示例:itis_getrecord("urn:lsid:itis.gov:itis_tsn:202385", "lsid")
3.54. itis_hierarchy(ITIS 层级结构)
描述:从 TSN 值中获取层次结构,全层次结构、仅上游层次结构或仅直接下游层次结构。
用法:itis_hierarchy(tsn, what = "full", ...)
参数:
- tsn:一个或多个 TSN(分类序号)。必填。
- what:all(完整层次结构)、up(紧靠上游)或down(紧靠下游)之一。
- …:传递给 ritis::hierarchy_full() ritis::hierarchy_up() 或 ritis::hierarchy_down() 的其他参数。
说明:需要注意的是,itis_downstream() 获取的是下游某一等级的分类群,而该函数只获取下游的直接名称。
示例:itis_hierarchy(tsn=180543, "up")
3.55. itis_kingdomnames(获取界名)
用法:itis_kingdomnames(tsn = NULL, ...)
参数:
- tsn:一个或多个 TSN(分类序号)。
- …:传递给 getkingdomnamefromtsn 的其他参数。
示例:itis_kingdomnames(202385)
3.56. itis_lsid(通过 LSID 获取 TSN(
用法:itis_lsid(lsid = NULL, what = "tsn", ...)
参数:
- tsn:一个或多个 lsid。
- …:传递给 ritis::lsid2tsn()、ritis::record() 或 ritis::full_record() 的其他参数。
示例:itis_lsid("urn:lsid:itis.gov:itis_tsn:180543")
3.57. itis_name(根据给定的分类名称查询获取分类名称)
用法:itis_name(query = NULL, get = NULL)
参数:
- query:TSN 编号(分类序号)。
- get:要获取的分类名称的等级。
返回值:搜索到的分类群的分类学名称。
示例:itis_name(query="Helianthus annuus", get="family")
3.58. itis_native(获取辖区数据,即在某个地区原生或非原生)
用法:itis_native(tsn = NULL, what = "bytsn", ...)
参数:
- tsn:一个或多个 lsid。
- what:bytsn、values 或 originvalues 之一。
- …:传递给 ritis::jurisdiction_origin()、ritis::jurisdiction_values() 或 ritis:::jurisdiction_origin_values() 的其他参数。
示例:itis_native(what="values")
3.59. itis_refs(获取与 ITIS TSN 相关的参考文献)
用法:itis_refs(tsn, ...)
参数:
- tsn:一个或多个分类组的 TSN(分类序号)。
- …:传递给 getpublicationsfromtsn 的其他参数。
示例:itis_refs(202385)
3.60. itis_taxrank(从给定的 TSN 中检索分类等级名称)
用法:itis_taxrank(query = NULL, ...)
参数:
- query:分类群的 TSN(数值)。如果将查询设为默认值(NULL),则会得到所有可能的等级名称及其 TSN(使用函数 ritis::rank_names())。Monera vs. Plantae vs. Fungi vs. Animalia vs. Chromista的术语略有不同,因此每个类群都有单独的术语。
说明:您可以通过设置 verbose=FALSE来打印信息。
返回值:分类等级名称或所有等级的数据框。
示例:itis_taxrank(query=202385)
3.61. itis_terms(获取 ITIS 术语,即 tsn、作者、俗名和学名)
用法:itis_terms(query, what = "both", ...)
参数:
- query:一个或多个常用名、学名或部分名称。
- what:both(搜索常用名和学名)、common(只搜索常用名)或scientific(只搜索学名)。
示例;itis_terms(query='bear')
3.62. iucn_getname(获取任何匹配的 IUCN 物种名称)
用法:iucn_getname(name, verbose = TRUE, ...)
参数:
- name:类群名称。
- verbose:(逻辑型)是否应该打印信息?
- …:传递给 iucn_summary() 的其他参数,请注意您需要一个 API 密钥。
返回值:与《世界自然保护联盟》中的名称相匹配的字符向量。
示例:iucn_getname(name = "Cyanistes caeruleus")
3.63. iucn_id(为世界自然保护联盟(IUCN)列出的分类群获取 ID)
用法:iucn_id(sciname, key = NULL, ...)
参数:
- sciname:学名。应清晰明了,格式为 <属> <种>。一个或多个。
- key:您的 IUCN Redlist API 密钥。请参阅 rredlist::rredlist-package 以获取与世界自然保护联盟红名单进行身份验证的帮助。
- …:传递给crul::HttpClient的可选参数。
返回值:一个或多个世界自然保护联盟 ID 的命名列表(名称为输入分类群名称)。未找到的分类群将被静默删除。
示例:iucn_id("Branta canadensis")
3.64. iucn_status(iucn-class 的提取函数)
用法:iucn_status(x, ...)
参数:
- x:一个由iucn_summary 返回的iucn 对象。
- …:目前未使用
返回值:表示状态的字符向量。
示例:
ia <- iucn_summary(c("Panthera uncia", "Lynx lynx"))
iucn_status(ia)
3.65. iucn_summary(从世界自然保护联盟红色名录中获取摘要)
用法:iucn_summary(x, distr_detail = FALSE, key = NULL, ...)
参数:
- x:学名。应清晰明了,格式为 <属> <种>。
- distr_detail:如果为 “true”,则地理分布将作为一个向量列表返回,该向量列表对应于不同的分布类型:原生、引进等。
- key:Redlist API 密钥,从 https://apiv3.iucnredlist.org/api/v3/token 获取 iucn_summary 所需的密钥。默认为空,以防已存储密钥(请参阅下面的 Redlist Authentication)。
- …:传递给crul::verb-GET的可选参数。
说明:iucn_summary 有一个默认方法,当传入非字符或 iucn 类对象时会出错–iucn_summary.character 方法用于传入分类群名称–iucn_summary.iucn 方法用于传入 iucn 类对象作为 get_iucn() 或 as.iucn() 的输出。如果您已经有了 IUCN ID,则可通过 as.iucn(…, check = FALSE) 将其强制转换为 iucn 类。
返回值:列表(每个物种一个条目),包含以下项目:
- status:红色名录类别。
- history:历史状况(如果有)。
- distr:地理分布情况(如果有)。
- trend:种群数量趋势(如果有)。
红色名录认证:iucn_summary 使用新的 Redlist API 搜索世界自然保护联盟 ID,因此我们在内部使用了 rl_search()函数。该函数需要一个 API 密钥。请在 https://apiv3.iucnredlist.org/api/v3/token 获取密钥,并将其传递给 key 参数,或存储在 .Renviron 文件中,如 IUCN_REDLIST_KEY=yourkey 或存储在 .Rprofile 文件中,如 options(iucn_redlist_key=“yourkey”)。我们强烈建议你不要在函数调用中传递密钥,而是将其存储在这两个文件中的一个中。该密钥还将帮助您使用 rredlist 软件包。
注意:iucn_status() 是一个提取函数,可以轻松地将状态提取到矢量中。
示例:iucn_summary("Lutra lutra")
3.66. key_helpers(为不同数据源设置身份验证的助手)
用法:
use_tropicos()
use_entrez()
use_iucn()
详情:
- use_tropicos()
浏览 Tropicos API 密钥请求 URL,并提供如何存储密钥的说明。填写表格后,您将很快收到密钥,但不是立即收到。 - use_entrez()
浏览 NCBI Entrez 可帮助提出 API 密钥请求,并提供如何存储密钥的说明。没有直接请求密钥的 URL,首先需要登录或注册,然后从自己的账户生成密钥。请注意,NCBI Entrez 并不要求您使用 API 密钥,但有了密钥,您应该能获得更高的速率限制,因此请务必获得一个。 - use_iucn()
浏览世界自然保护同盟红色名录 API 密钥请求 URL,并提供如何存储密钥的说明。该函数封装了 rredlist 软件包中的 rredlist::rl_use_iucn()。填写表格后,你将很快获得密钥,但不是立即。
3.67. lowest_common(检索给定分类群名称或 ID 的最低常见分类群和等级)
用法:
lowest_common(...)## Default S3 method:
lowest_common(sci_id, db = NULL, rows = NA, class_list = NULL, low_rank = NULL, x = NULL, ...)## S3 method for class 'uid'
lowest_common(sci_id, class_list = NULL, low_rank = NULL, ...)## S3 method for class 'tsn'
lowest_common(sci_id, class_list = NULL, low_rank = NULL, ...)## S3 method for class 'gbifid'
lowest_common(sci_id, class_list = NULL, low_rank = NULL, ...)## S3 method for class 'tolid'
lowest_common(sci_id, class_list = NULL, low_rank = NULL, ...)
参数:
- …:传递给 get_tsn()、get_uid()、get_gbifid()、get_tolid() 的其他参数。
- sci_id:要查询的分类群名称(字符)或 ID(字符或数字)向量。
- db:要查询的数据库:ncbi、itis、gbif 或 tol。如果使用 ncbi,建议获取一个 API 密钥;请参阅 taxize-authentication。
- rows:从 1 到无穷大的任意数字。如果默认为 NA,则所有行都会被考虑。请注意,如果您输入的分类id属于可接受的类别:tsn、gbifid 和 tolid,则该参数将被忽略。NCBI 有一个用于此函数的方法,但rows不起作用。
- class_list:由 classification() 返回的分类列表。
- low_rank:要返回的分类等级,长度为 1。
- x:已弃用,请使用sci_id。
返回值:如果没有匹配项,则为 NA;如果有匹配项,则为带列的 data.frame。列有name,rank和id。
示例:
id <- c("9031", "9823", "9606", "9470")
lowest_common(id[2:4], db = "ncbi")
3.68. names_list(随机获取物种名称向量)
描述:科名和目名来自 APG 植物名称表。属和种名来自 Theplantlist.org。
用法:names_list(rank = "genus", size = 10)
参数:
- rank:分类等级,种、属(默认)、科、目之一。
- size:要获取的名称数量。最大值取决于等级。
返回值:分类名称的字符向量。
示例:names_list('species')
3.69. nbn_classification(搜索英国国家生物多样性网络数据库中的生物分类)
用法:nbn_classification(id, ...)
参数:
- id:一个NBN标识符。
- …:传递给 crul::verb-GET 的其他参数。
返回值:数据框。
示例:nbn_classification(id="NHMSYS0000376773")
3.70. nbn_search(搜索英国国家生物多样性网络)
用法:nbn_search( sci_com, fq = NULL, order = NULL, sort = NULL, start = 0, rows = 25, facets = NULL, q = NULL, ... )
参数:
- sci_com:查询术语、学名或俗名。
- fq:应用于原始查询的过滤器。这些是额外的 参数,例如 fq=rank:kingdom。参见 https://species-ws.nbnatlas.org/indexFields 可查询的所有字段。
- order:支持 "asc "或 “desc”。
- sort:按索引字段排序。
- start:记录偏移量,以启用分页功能。
- rows:返回的记录数。
- facets:用逗号分隔的字段列表,例如:facets=basis_of_record。
- q:已弃用,请使用sci。
- …:传递给 crul::HttpClient 的其他参数。
返回值:一个列表,其中的元数据 (meta) 插槽包含响应属性列表,数据 (data) 插槽包含结果的 data.frame。
示例:nbn_search(sci_com = "Vulpes")
相关文章:
)
R语言——taxize(第四部分)
taxize(第四部分) 3.39. get_wiki(获取维基分类群的页面名称)3.40. get_wormsid(获取分类群名称的Worms ID)3.41. gni_details(使用Global Names Index搜索分类学名称详情)3.42. gni…...

C++学习 --list
目录 1, 什么是list 2, 创建 2-1, 标准数据类型 2-2, 自定义数据类型 2-3, 其他创建方式 3, 操作list 3-1, 赋值 3-2, 添加元素 3-2-1, 添加元素(assign) 3-2-…...
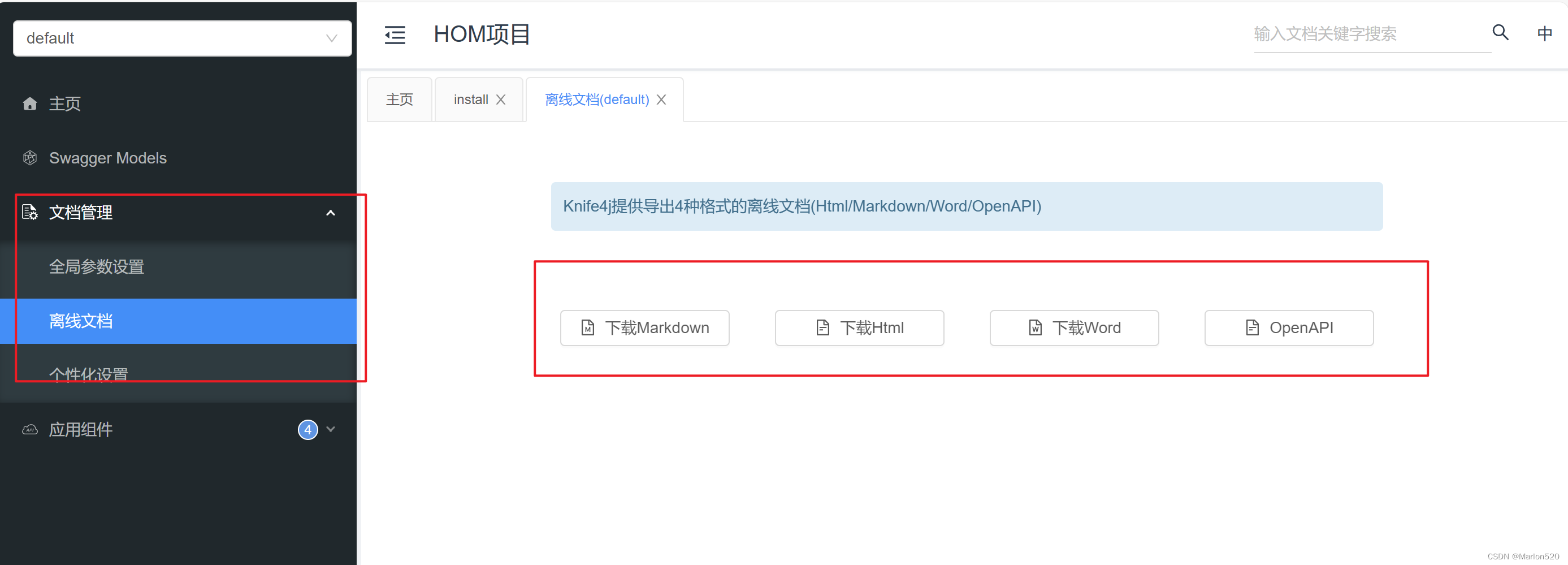
Springboot集成swagger之knife4j
knife4j的最终效果: 支持直观的入参介绍、在线调试及离线各种API文档下载。 1 引入pom <dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-starter</artifactId><version>3.0.2</ver…...

多线程 02
1.线程的常见构造方法 方法说明Thread()创建线程对象Thread(Runnable target)使用 Runnable 对象创建线程对象Thread(String name)创建线程对象,并命名Thread(Runnable target, String name)使用 Runnable 对象创建线程对象,并命名【了解】Thread(Threa…...
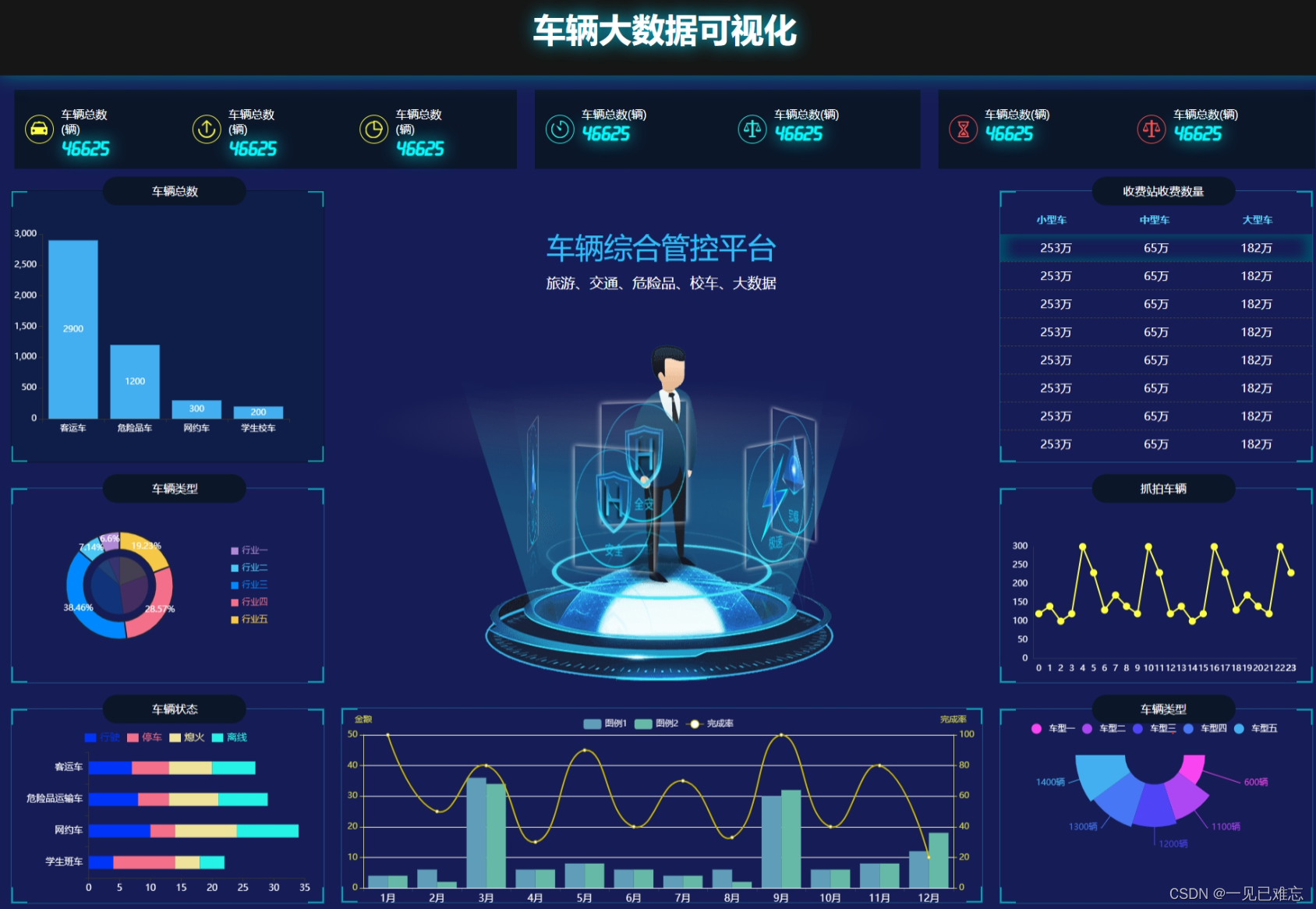
车辆管控大数据可视化平台案例源码分析【可视化项目案例-10】
🎉🎊🎉 你的技术旅程将在这里启航! 🚀🚀 本专栏包括但不限于大屏可视化、图表可视化等等。订阅专栏用户在文章底部可下载对应案例源码以供大家深入的学习研究。 🎓 每一个案例都会提供完整代码和详细的讲解,不论你是初学者还是资深开发者,这里都有适合你的内容。…...
链表的回文结构
题目描述 题目链接:链表的回文结构_牛客题霸_牛客网 (nowcoder.com) 题目分析 我们的思路是: 找到中间结点逆置后半段比对 我们可以简单画个图来表示一下: ‘ 奇数和偶数都是可以的 找中间结点 我们可以用快慢指针来找中:l…...

CSS特效017:球体涨水的效果
CSS常用示例100专栏目录 本专栏记录的是经常使用的CSS示例与技巧,主要包含CSS布局,CSS特效,CSS花边信息三部分内容。其中CSS布局主要是列出一些常用的CSS布局信息点,CSS特效主要是一些动画示例,CSS花边是描述了一些CSS…...
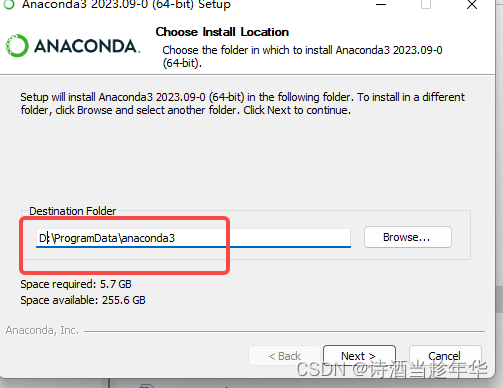
Windows下安装Anaconda3并使用JupyterNoteBook
下载安装包 Anaconda官网 进官网,点击下载 自动根据当前系统下载对应的包了,安装包大约1G,喝杯Java耐心等待。 安装 很多人安装C盘,我这里放D盘。 注意:你的文件夹目录一定要不能有空格 然后其他的直接默认install即…...

什么年代了,还不会 CI/CD 么?
目录 什么是 CI/CD? CI/CD 对业务有哪些好处? 一:确保卓越的代码质量 二:更快的发布速度 → 更快的交付 三:自动化降低成本 四:故障隔离 五:简化回滚 六:持续反馈 七&#…...

centos 7.7 安装Python-3.7.4
一、安装PYTHON 编译依赖包 1.1 首先安装gcc编译器,gcc有些系统版本已经默认安装,通过 gcc --version 查看,没安装的先安装gcc, yum -y install gcc glibc make1.2 安装其它依赖包,(注:不要缺…...
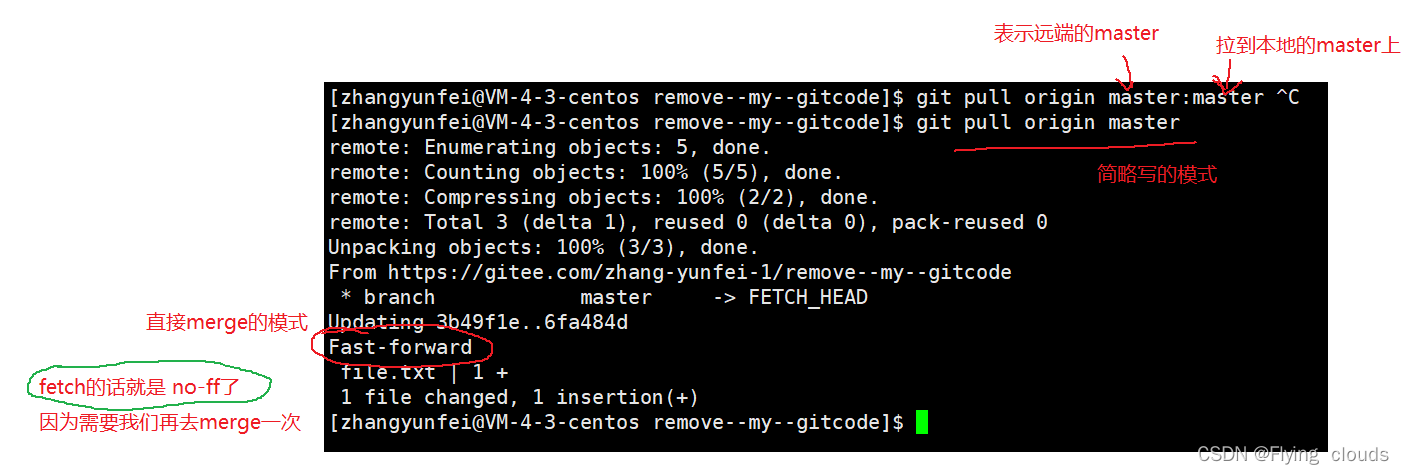
git的用法
目录 一、为什么需要git 二、git基本操作 2.1、初始化git仓库 2.2、配置本地仓库的name和email 2.3、认识工作区、暂存区、版本库 三、git的实际操作 3.1 提交文件 3.2 查看git状态以及具体的修改 3.3 git版本回退 git reset 3.1 撤销修改 四、git分支管理 4.…...

管道在Vue和Angular中的作用及React的替代方案
管道在Vue和Angular中的作用及React的替代方案 前言管道起源管道特点 前端中管道概念和作用概念作用 React关于管道的替代方案Vue和Angular管道的区别 前言 本文主要讲解管道在Vue和Angular中有哪些作用以及React对于管道概念的替代方案是什么。 管道起源 计算机中的Pipline…...
计算机基础知识57
前后端数据传输的编码格式(contentType) # 我们只研究post请求方式的编码格式: get请求方式没有编码格式-- index?useranme&password get请求方式没有请求体,参数直接在url地址的后面拼接着 # 有哪些方式可以提交post请求:f…...

Flutter 小技巧之 3.16 升级最坑 M3 默认适配技巧
如果要说 Flutter 3.16 升级里是最坑的是什么?那我肯定要说是 Material 3 default (M3)。 倒不是说 M3 bug 多,也不是 M3 在 3.16 上使用起来多麻烦,因为虽然从 3.16 开始,MaterialApp 里的 useMaterial3 …...
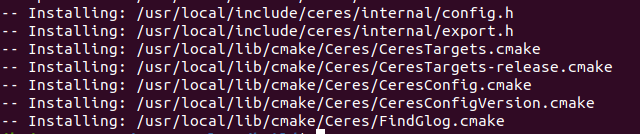
激光雷达与惯导标定 | Lidar_IMU_Init : 编译
激光雷达与惯导标定:Lidar_IMU_Init 编译 功能包安装安装ceres-solver-2.0.0 (注意安装2.2.0不行,必须要安装2.0.0) LI-Init是一种鲁棒、实时的激光雷达惯性系统初始化方法。该方法可校准激光雷达与IMU之间的时间偏移量和外部参数…...

进程池,线程池与跨进程数据共享爬取某岸网图片
看教程的时候看到一个,生产者跟消费者的概念比较有意思,但是给的代码有问题无法正常运行,于是我就捣鼓了一下。 基本概念就是: 生产者: 一个进程获取网页没页的图片连接(主进程…...

【 图片加载】Vue前端各种图片引用
文章目录 一、图片作为js常量(常作为配置项的值 )1、在线链接2、本地图片 二、图片img标签1、一般的src2、动态的src用require3、src可以接收二进制文件blob(如后端返回的、a-upload传的图片) 三、背景图片 一、图片作为js常量(常…...

thinkphp6生成PDF自动换行
composer安装 composer require tecnickcom/tcpdf 示例 use TCPDF;public function info($university,$performance,$grade,$major){//获取到当前域名$domain request()->domain();//实例化$pdf new TCPDF(P, mm, A4, true, UTF-8, false);// 设置文档信息$pdf->SetCr…...

wpf devexpress实现输入验证使用验证规则
打开此项目 目标是一个registration form行为像google registration form。打开Google registration form 研究它的行为。当form是第一次显示,它的“Register”按钮应该启动;编辑器没有提示任何输入错误。输入First Name编辑器字段,清理输入…...

Vue表单的整体处理
在前端的处理中,表单的处理永远是占高比例的。在BOMDOMjs的时候是这样,在Vue的时候也是这样。Vue的表单处理做了特别的优化,如值绑定、数据验证、错误提示、修饰符等。 表单组件的示例: <script setup lang"ts">…...

Flux2-Klein-9B-True-V2效果集:Proteus电路仿真与AI概念艺术设计的碰撞
Flux2-Klein-9B-True-V2效果集:Proteus电路仿真与AI概念艺术设计的碰撞 1. 当电路板遇见艺术想象力 打开Proteus软件,你看到的可能是冰冷的电路走线和规整的元器件布局。但通过Flux2-Klein-9B-True-V2模型的"眼睛",这些工程图纸突…...

Oracle11g服务端安装包
下载地址:https://pan.baidu.com/s/1coKaGW1z0aqtV6pZYYgs_w?pwdhaev 一、前言 在数据库学习、项目本地测试、内网环境部署场景中,Oracle 11g 凭借稳定性强、占用资源低、企业普及率高,一直是开发与运维人员常用的经典版本。 很多新手在搭…...

【VS Code MCP插件生态搭建权威指南】:20年IDE架构师亲授7大核心组件选型逻辑与避坑清单
更多请点击: https://intelliparadigm.com 第一章:VS Code MCP 插件生态搭建手册对比评测报告全景概览 MCP 协议与 VS Code 集成背景 MCP(Model Communication Protocol)作为新兴的 AI 工具链通信标准,正快速被主流开…...

Arm A-profile架构缓存子系统与写回机制解析
1. Arm A-profile架构缓存子系统深度解析在处理器架构设计中,缓存子系统对系统性能有着决定性影响。Arm A-profile架构作为移动计算和嵌入式领域的标杆,其缓存设计哲学体现了性能与能效的完美平衡。最新发布的Arm Architecture Reference Manual for A-p…...

Unsloth Sglang Vllm核心区别和使用场景
(一)核心总结 Unsloth:主打「微调/训练加速」,推理只是附带 vLLM:通用推理引擎,主打「高吞吐、高显存利用率」 SGLang:推理引擎,主打「前缀复用、结构化输出、低延迟」 下面从定位、核心技术、性能、适用场景四个维度拆开讲。 一、定位 1. Unsloth 定位:微调优先、推…...

Linux USB驱动架构与性能优化实战
1. Linux USB驱动架构深度解析在嵌入式系统开发中,USB驱动作为连接主机与外围设备的关键桥梁,其性能直接影响整个系统的I/O效率。以TI的DaVinci平台为例,其USB驱动实现展现了Linux内核中USB子系统的典型架构与优化技巧。1.1 核心架构分层Linu…...

caj2pdf:3个技巧让知网CAJ文献在Linux上重获新生
caj2pdf:3个技巧让知网CAJ文献在Linux上重获新生 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/gh_mirr…...

AI率检测工具到底有何不同?10款主流aigc检测工具横评告诉你ai查重的真相!
2026年答辩季临近,AIGC检测已经成为大多数高校论文审核的标配流程。不管你有没有用过A论文,学校都可能会查一遍AI率。很多同学的第一反应就是:ai率查重要多少钱?有没有能免费查AI率的工具? 有免费的aigc检测工具&…...

为Open WebUI构建安全代码执行沙箱:基于gVisor的本地LLM增强方案
1. 项目概述:为Open WebUI构建安全的代码执行沙箱如果你正在本地部署大语言模型,比如用Ollama跑Llama 3或者Qwen,并且通过Open WebUI这个漂亮的Web界面来交互,那你可能遇到过这样的场景:你问模型“帮我写个Python脚本来…...

手把手教你搞定移远EC200U/EC25的Linux驱动:从硬件检查到串口映射的保姆级教程
手把手教你搞定移远EC200U/EC25的Linux驱动:从硬件检查到串口映射的保姆级教程 刚接触移远4G模块的开发者,往往会在Linux驱动适配环节遇到各种"坑"。本文将以EC200U和EC25为例,带你完整走通从硬件检查到功能稳定的全流程。不同于零…...