ES 万条以外分页检索功能实现及注意事项
背景
以 ES 存储日志,且需要对日志进行分页检索,当数据量过大时,就面临 ES 万条以外的数据检索问题,如何利用滚动检索实现这个需求呢?本文介绍 ES 分页检索万条以外的数据实现方法及注意事项。
需求分析
用 ES 存储数据,分页检索,当 ES 数据量过大时,在页面上直接点击最后一页时,怎么保证请求能正常返回?
常规思路就是,超过万条以后,使用滚动检索,但需要注意:编写滚动检索的分页查询时,滚动请求的 size 一定不能用页面分页参数的 pageSize ,要能快速滚动到目标页所在的数据,最好以 ES 最大检索窗口值。
算法要点
第一,滚动检索的 Request 请求不能包含 from 属性, 且设置了 size 参数后,以后的每次滚动返回的数据量都以 size 为主。
第二,滚动获取数据的 size 选取。 滚动分页检索高效的关键是不能以页面分页参数 pageSize 作为滚动请求的 size ,而是以一个较大的数,或者直接以 ES 默认的滚动窗口最大值 10000 作为每批次获取的数据量。
第三,计算目标页的数据所在的位置。
- 根据分页参数计算出目标数据的位置是
[(pageSize-1)*pageSize, pageSize * pageNo],为了拿到目标页的数据,总共的数据量total = pageNo * pageSize。 - 目标数据在最终数据中的真正范围决定因素:
mode = total % 10000。 - 计算滚动请求几次能拿到目标数据。实际需要滚动请求的次数
scrollCount = mode == 0 ? total/ esWindowCount : (total/ esWindowCount + 1)。 - 目标页的数据有没有分布在两次请求中。当
10000 % pageSize !=0时,说明这一页的数据会横跨两次 ES 请求。例如pageSize =15,pageNo = 2667,total = 40005,目标页的数据包含在最后两次请求中,倒数第二次请求中有 10 条数据,最后一次请求中有 5 条数据,合起来才是一整页的 15 条数据。 - 最后一页数据不足 pageSize 时,最后一页数据真正的长度。
第四,分页数据所在范围处理。 当最后一批次获取到数据后,从中摘出目标页的数据时,需要考虑的四种情况,主要是 mode 和最终获取的数据总长度直接的关系:
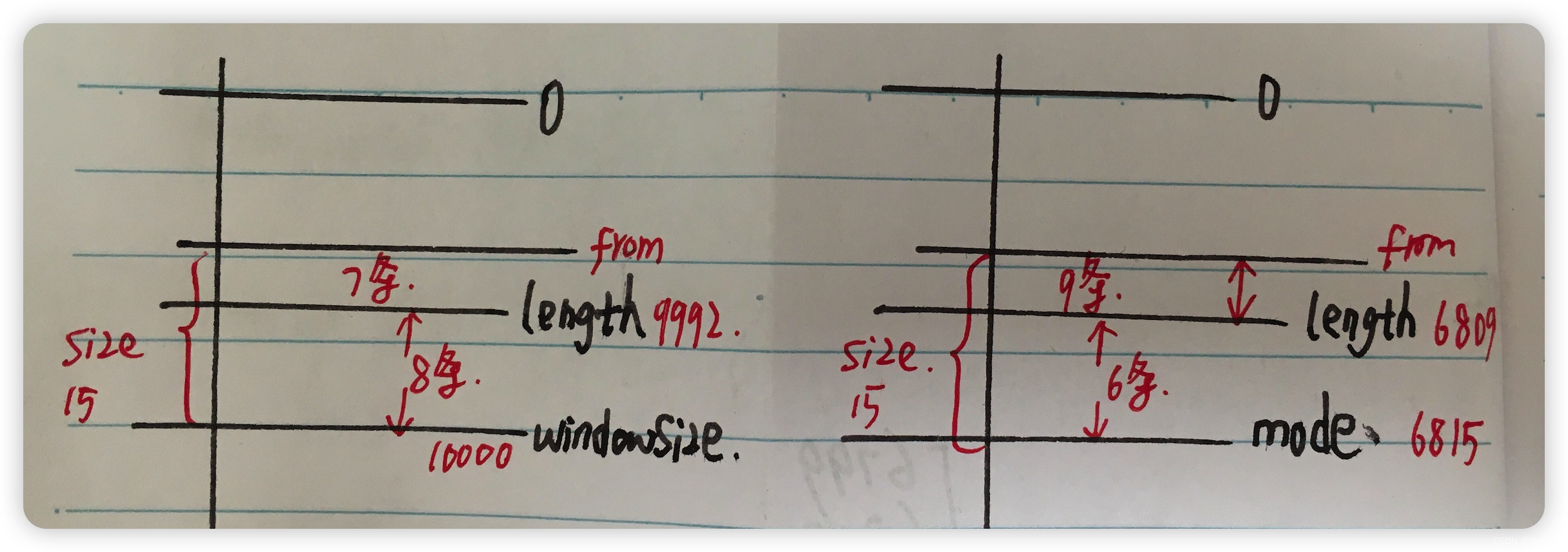
case 1:上图左,mode=0 时存在最后一页不足 size 的情况,realSize = size - (windowSize-length) 。
case 2:上图右,length < mode 时,最后一页不足 size 的情况,realSize = size - (mode -length) 。
最终的数据区间是 [from,to ] = [ length -realSize,length -1 ]。
数据总长度 = end -start +1 = realSize 。
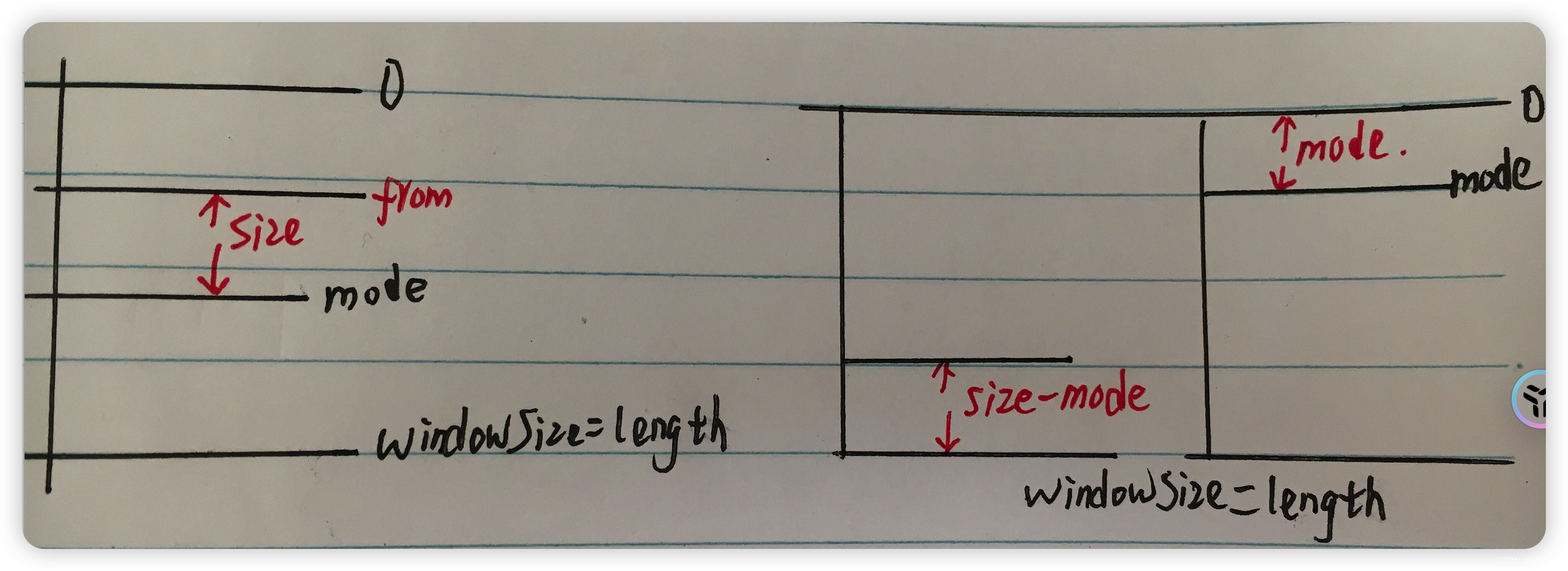
case 3 :上图左,分页数据在 mode 往前推 size 条。
case 4:上图右,分页数据横跨两次请求,两批数据组合成一页数据。
编码实现
编写 ES 滚动分页检索请求,处理超过万条之外的查询操作:
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.ClearScrollRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.*;
import org.elasticsearch.search.Scroll;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.SearchModule;
import org.elasticsearch.search.builder.SearchSourceBuilder;import java.io.IOException;
import java.util.*;@Slf4j
public class EsPageUtil {/*** 真正的 ES 连接对象*/private RestHighLevelClient client;public void initClient() {// TODO 初始化 client 对象}/*** 使用 DSL JSON 配置创建检索请求 Builder* @param queryJson* @return*/public SearchSourceBuilder createSearchSource(String queryJson) {if (StringUtils.isEmpty(queryJson)) {log.error("ElasticSearch dsl config is empty.");return null;}SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();try {SearchModule searchModule = new SearchModule(Settings.EMPTY, false, Collections.emptyList());NamedXContentRegistry registry = new NamedXContentRegistry(searchModule.getNamedXContents());XContentParser parser = XContentFactory.xContent(XContentType.JSON).createParser(registry, LoggingDeprecationHandler.INSTANCE, queryJson);searchSourceBuilder.parseXContent(parser);return searchSourceBuilder;} catch (Exception e) {log.error("Parse dsl error.", e);return null;}}/*** ES 分页查询:区分万条以内还是万条以外* @param pageSize 分页size* @param pageNo 查询页数* @param indices 目标索引* @param queryJson 查询 DSL JSON 格式字符串* @return*/public Map<String, Object> queryByPage(int pageSize, int pageNo, String[] indices, String queryJson) {SearchSourceBuilder searchSourceBuilder = createSearchSource(queryJson);if (searchSourceBuilder == null) {return null;}// 创建请求对象SearchRequest searchRequest = new SearchRequest(indices).source(searchSourceBuilder);Map<String, Object> result = new HashMap<>();List<Map<String, Object>> data = null;int total = pageSize * pageNo ;int maxEsWindow = 10000;try {if (total <= 10000) {// 万条以内,直接查询:设置 from , size 属性searchSourceBuilder .from((pageNo - 1) * pageSize) .size(pageSize);SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);data = parseResponseToListData(response);} else {// 万条以外,以 ES 最大窗口值查询:只设置size 属性searchSourceBuilder.size(maxEsWindow);data = scrollQuery(maxEsWindow, pageSize, total, searchRequest);}} catch (IOException e) {log.error("ElasticSearch query error.", e);}result.put("total" , 0);result.put("data" , data);return result;}/*** 滚动查询** @param esWindowCount* @param pageSize* @param total* @param searchRequest* @return*/private List scrollQuery(int esWindowCount, int pageSize, int total , SearchRequest searchRequest) {List pageData = new ArrayList(pageSize);//创建滚动,指定滚动查询保持的时间final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(10L));//添加滚动searchRequest.scroll(scroll);//提交第一次请求SearchResponse searchResponse = null;String scrollId = null;try {searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//获取滚动查询idscrollId = searchResponse.getScrollId();} catch (IOException e) {log.error("Elasticsearch request error.", e);return pageData;}int counter = 2;int mode = total % esWindowCount;int realPageCount = mode == 0 ? total/ esWindowCount : (total/ esWindowCount + 1);while (counter <= realPageCount) {// 设置滚动查询id,从id开始继续向下查询SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);// 重置查询时间,若不进行重置,则在提交的第一次请求中设置的时间结束,滚动查询将失效scrollRequest.scroll(scroll);// 提交请求,获取结果try {searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);} catch (IOException e) {log.error("Elasticsearch scroll request error.", e);}// size 非 10 的整数,则当前页数据横跨两个 Scroll 请求if (mode != 0 && mode < pageSize && counter == (realPageCount -1)) {collectFirstPart(searchResponse, pageData, mode, pageSize);}// 更新滚动查询idscrollId = searchResponse.getScrollId();counter++;}// 收集最后一次响应结果中的数据collectPageData(searchResponse, pageData, mode, pageSize, esWindowCount);// 滚动查询结束时,清除滚动ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.addScrollId(scrollId);try {client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);} catch (IOException e) {log.error("Elasticsearch clear scroll info error.", e);}return pageData;}/*** @param searchResponse* @param mode* @param size* @return*/public void collectFirstPart(SearchResponse searchResponse, List<Map<String, Object>> firstPartData, int mode, int size) {int firstPartCount = size - mode;// 只截取响应结果中的 结尾 size - mode 部分的内容SearchHits hits = searchResponse.getHits();SearchHit[] dataList = hits.getHits();int from = dataList.length - firstPartCount;for (int i = from; i < dataList.length; i++) {firstPartData.add(dataList[i].getSourceAsMap());}log.info("Mode less than size, first part data is here {} .", firstPartCount);}/*** 滚动到最后一组数据中包含目标页的数据,从中摘出来* @param searchResponse* @param mode* @param size* @param esWindowCount* @return*/public void collectPageData(SearchResponse searchResponse, List<Map<String, Object>> pageData, int mode, int size, int esWindowCount) {SearchHits hits = searchResponse.getHits();SearchHit[] dataList = hits.getHits();int from = 0;int length = dataList.length;if (mode == 0) { // 刚好在万条结尾// 不够一页if (length < esWindowCount) {int realSize = size - (esWindowCount - length);from = (length - realSize ) >= 0 ? (length - realSize ) : 0;} else {// 总长够一页from = length == esWindowCount ? (length - size) : 0;}} else if (length < mode){ // 最后一页且总长不足 sizeint realSize = size - (mode - length);from = (length - realSize) >= 0 ? (length - realSize) : 0;} else if (mode > size){ // 中间部分from = (mode - size) >= 0 ? (mode -size) : 0;} else { // mode < size ,说明是一页数据的下半部分from = 0;size = mode;log.info("Page data is across two request ,this response has {} .", mode);}// 收集目标数据for (int i = from; i< from + size && i < length; i++) {pageData.add(dataList[i].getSourceAsMap());}}/*** 解析 ES 响应结果为数据集合* @param response* @return*/public static List<Map<String, Object>> parseResponseToListData(SearchResponse response){List<Map<String, Object>> listData = new ArrayList<>();if (response == null) {return listData;}// 遍历响应结果SearchHits hits = response.getHits();SearchHit[] hitArray = hits.getHits();listData = new ArrayList<>(hitArray.length);for (SearchHit hit : hitArray) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();listData.add(sourceAsMap);}// 返回结果return listData;}
}
启示录
滚动查询时优化了 size 用一万,相比用页面的分页参数 pageSize ,可以解决数据量过大时,直接从页面点击最后一页导致页面卡死长时间无响应的问题。
页面分页参数最大不过 100,当总数量几百万、pageSize=10,分页跳转查询后面某页 如 3000 时,ES 的滚动请求次数 是 3000 次,而优化后滚动请求 3次,第三次中的一万条数据的最后10条即本页的数据。
话说回来,ES 数据量过大时,用分页查询靠后的数据时,也没多大的价值了,列表宽泛条件查询结果过大时,谁看得过来呢?
相关文章:
ES 万条以外分页检索功能实现及注意事项
背景 以 ES 存储日志,且需要对日志进行分页检索,当数据量过大时,就面临 ES 万条以外的数据检索问题,如何利用滚动检索实现这个需求呢?本文介绍 ES 分页检索万条以外的数据实现方法及注意事项。 需求分析 用 ES 存储数…...
【MySQL】mysql中不推荐使用uuid或者雪花id作为主键的原因以及差异化对比
文章目录 前言什么是UUID?什么是雪花ID?什么是MySql自增ID?优缺点对比UUID:优点1.全球唯一性2.无需数据库支持 缺点1.存储空间大2.索引效率低3.查询效率低 雪花ID:优点1.分布式环境下唯一性 缺点1.依赖于机器时钟2.存储空间较大3.查询效率低 MYSQL自增:优点1.简单…...
【Unity细节】Default clip could not be found in attached animations list.(动画机报错)
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...
VsCode连接远程Linux编译环境的便捷处理
1.免输登录密码 免输命令的正确方法是使用公钥和私鈅在研发设备,和linux服务器上校验身份。公钥和私钥可在windows系统上生成。公钥要发送到linux服务器。私钥需要通知给本地的ssh客户端程序,相关的操作如下: 生成 SSH Key: 打开…...
【UE】用样条线实现测距功能(下)
目录 效果 步骤 一、实现多次测距功能 二、通过控件蓝图来进行测距 在上一篇(【UE】用样条线实现测距功能(上))文章基础上继续实现多次测距和清除功能。 效果 步骤 一、实现多次测距功能 打开蓝图“BP_Spline”,…...
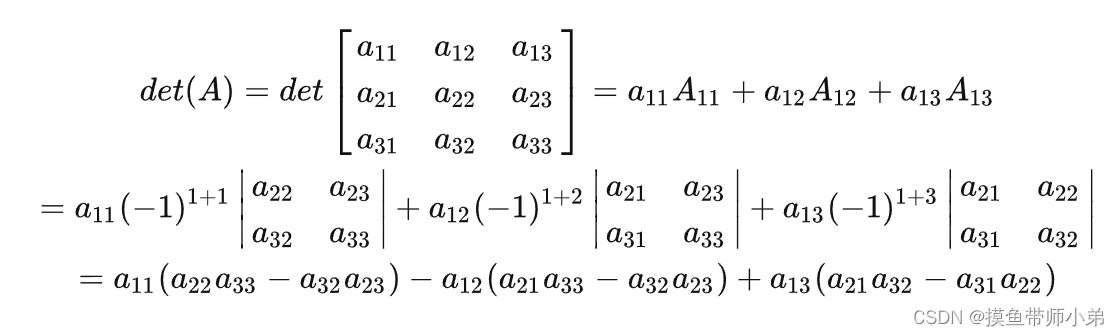
矩阵知识补充
正交矩阵 定义: 正交矩阵是一种满足 A T A E A^{T}AE ATAE的方阵 正交矩阵具有以下几个重要性质: A的逆等于A的转置,即 A − 1 A T A^{-1}A^{T} A−1AT**A的行列式的绝对值等于1,即 ∣ d e t ( A ) ∣ 1 |det(A)|1 ∣det(A)∣…...

机器学习之数据清洗和预处理
目录 Box_Cox Box_Cox Box-Cox变换是一种用于数据预处理和清洗的方法,旨在使数据更符合统计模型的假设,特别是对于线性回归模型。这种变换通过调整数据的尺度和形状,使其更加正态分布。 Box-Cox变换的定义是: y ( λ ) { y λ − 1 λ , i…...

【SpringBoot系列】SpringBoot日志配置
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

庖丁解牛:NIO核心概念与机制详解 06 _ 连网和异步 I/O
文章目录 Pre概述异步 I/OSelectors打开一个 ServerSocketChannel选择键内部循环监听新连接接受新的连接删除处理过的 SelectionKey传入的 I/O回到主循环 Pre 庖丁解牛:NIO核心概念与机制详解 01 庖丁解牛:NIO核心概念与机制详解 02 _ 缓冲区的细节实现…...
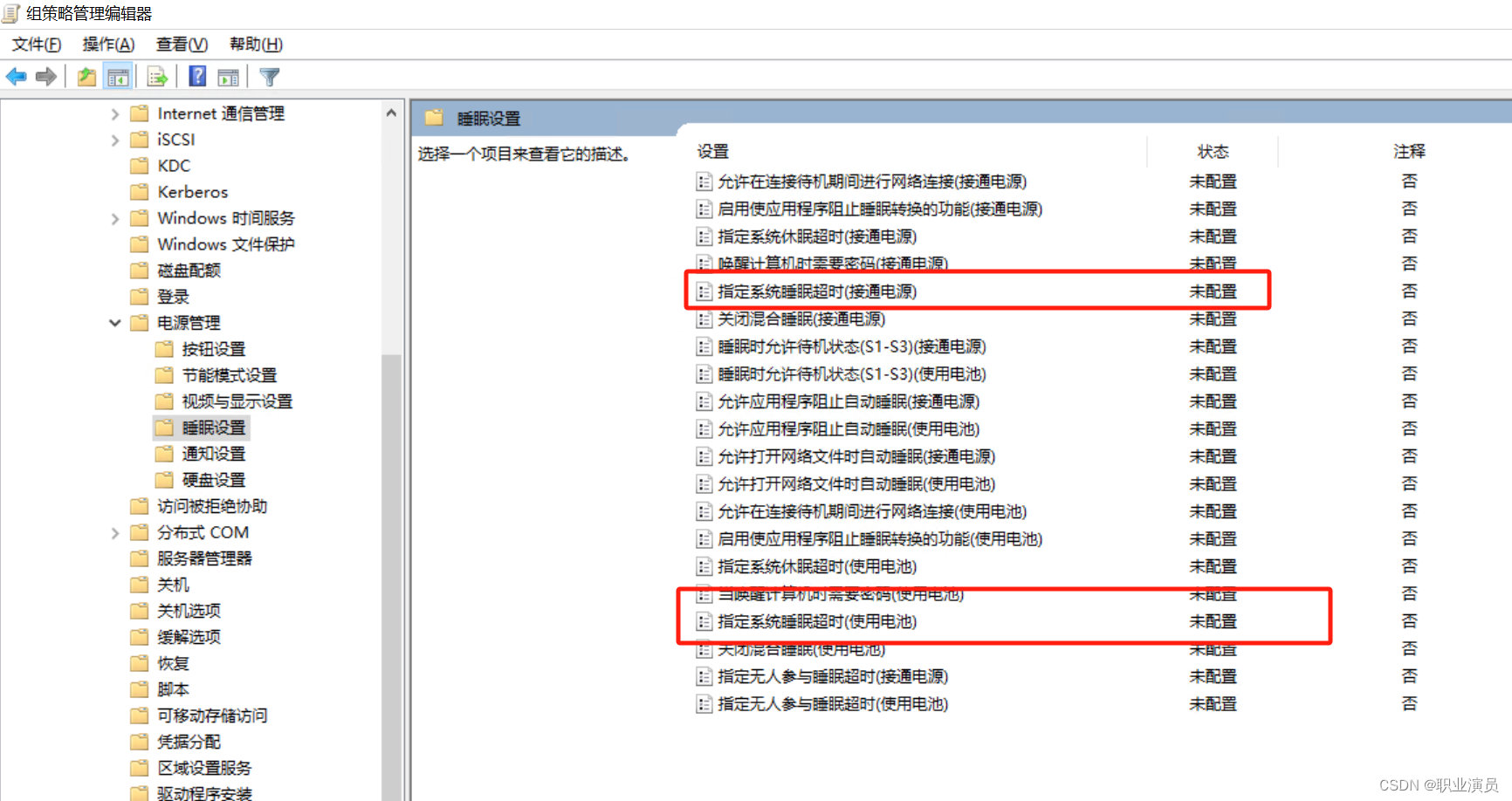
域控操作五:统一熄屏睡眠时间
直接看图路径,我只设置了熄屏,如果要睡眠就下面那个启用设置时间...

2023APMCM亚太杯数学建模选题建议及初步思路
大家好呀,亚太杯数学建模开始了,来说一下初步的选题建议吧: 首先定下主基调,本次亚太杯推荐选择B题。 C题如果想做好,搜集数据难度并不低,并且模型比较简单,此外目前选择的人数过多,…...

ORA-28003: password verification for the specified password failed,取消oracl密码复杂度
自己在测试环境想要使自己的Oracle数据库用户使用简单的密码方便测试,结果指定密码的密码验证失败 SQL> alter user zzw identified by zzw; alter user zzw identified by zzw * ERROR at line 1: ORA-28003: password verification for the specified password…...

【DevOps】Git 图文详解(九):工作中的 Git 实践
本系列包含: Git 图文详解(一):简介及基础概念Git 图文详解(二):Git 安装及配置Git 图文详解(三):常用的 Git GUIGit 图文详解(四)&a…...

外贸自建站服务器怎么选?网站搭建的工具?
外贸自建站服务器用哪个好?如何选海洋建站的服务器? 外贸自建站是企业拓展海外市场的重要手段之一。而在这个过程中,选择一个适合的服务器对于网站的稳定运行和优化至关重要。海洋建站将为您介绍如何选择适合的外贸自建站服务器。 外贸自建…...

010 OpenCV中的4种平滑滤波
目录 一、环境 二、平滑滤波 2.1、均值滤波 2.2、高斯滤波 2.3、中值滤波 2.4、双边滤波 三、完整代码 一、环境 本文使用环境为: Windows10Python 3.9.17opencv-python 4.8.0.74 二、平滑滤波 2.1、均值滤波 在OpenCV库中,blur函数是一种简…...

Oracle-客户端连接报错ORA-12545问题
问题背景: 用户在客户端服务器通过sqlplus通过scan ip登陆访问数据库时,偶尔会出现连接报错ORA-12545: Connect failed because target host or object does not exist的情况。 问题分析: 首先,登陆到连接有问题的客户端数据库上,…...
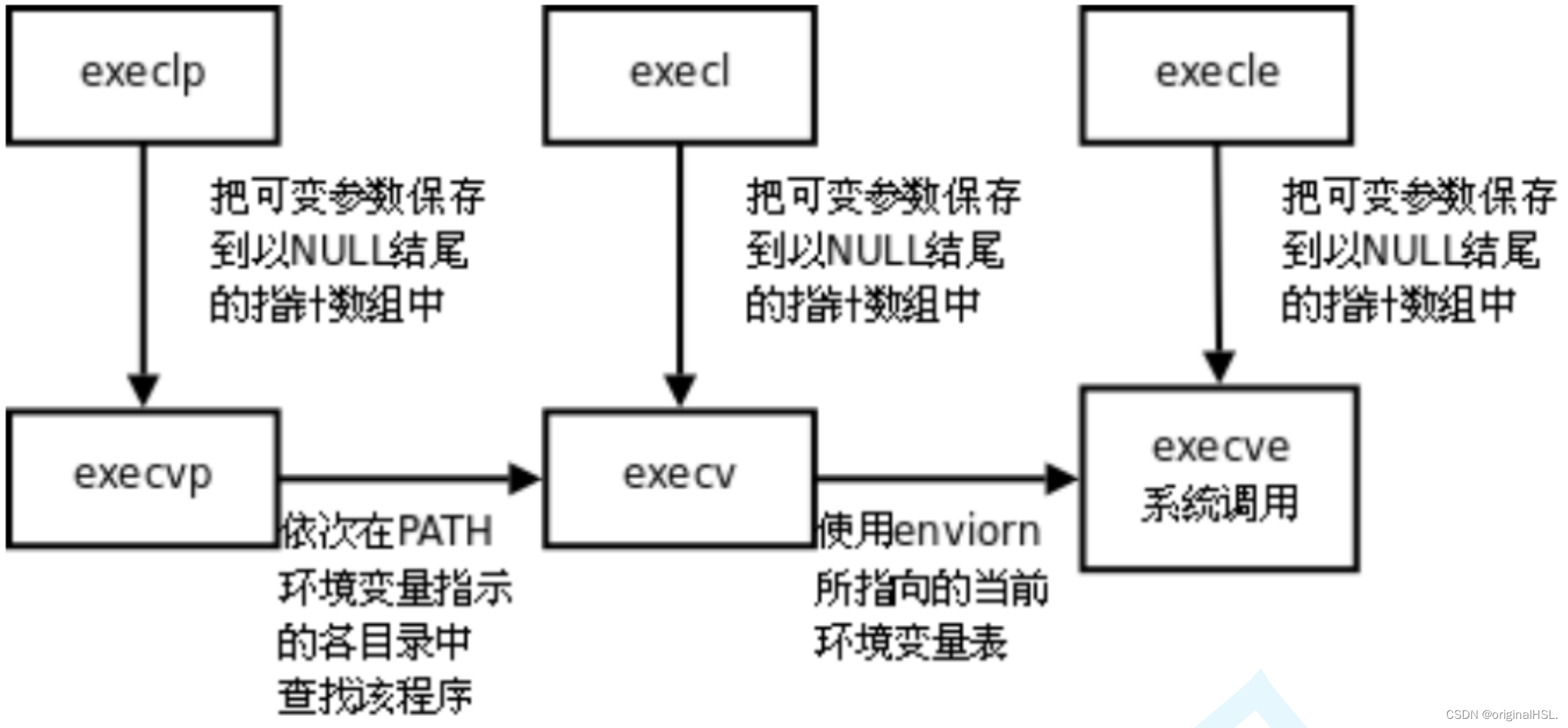
Linux中的进程程序替换
Linux中的进程程序替换 1. 替换原理2. 替换函数3. 函数解释4. 命名理解程序替换的意义 1. 替换原理 替换原理 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的…...
)
MIT6.824-Raft笔记:脑裂、Majority Vote(过半投票/过半选举)
本部分主要是问题引入,以及给出一个解决方案 1 脑裂(Split Brain) replication system的共同点:单点 前面几个容错特性(fault-tolerant)的系统,有一个共同的特点。 MapReduce复制了计算&…...

vuex中的常用属性有哪些?
在 Vuex 中,有一些常用的属性可以帮助你管理应用程序的状态。这些属性包括 state、getters、mutations 和 actions。 state: 用于存储应用程序的状态数据,是 Vuex 存储数据的地方。当应用程序中的多个组件需要共享状态时,就可以将这些共享的状…...
oracle面试相关的,Oracle基本操作的SQL命令
文章目录 数据库-Oracle〇、Oracle用户管理一、Oracle数据库操作二、Oracle表操作1、创建表2、删除表3、重命名表4、增加字段5、修改字段6、重名字段7、删除字段8、添加主键9、删除主键10、创建索引11、删除索引12、创建视图13、删除视图 三、Oracle操作数据1、数据查询2、插入…...

LLMStack:低代码AI应用构建平台,快速实现RAG与智能体工作流
1. 项目概述:一个面向所有人的AI应用构建平台 最近在折腾AI应用落地的朋友,估计都绕不开一个核心痛点:想法很多,但要把一个AI驱动的功能或者一个完整的应用做出来,门槛实在不低。你得懂点后端开发,知道怎么…...

Android WebView开发痛点与AgentWeb解决方案全解析
1. 项目概述如果你在Android开发中用过原生的WebView,大概率经历过一些“至暗时刻”:页面加载缓慢、文件上传功能残缺、JavaScript交互繁琐、Cookie管理混乱,还有那个时不时就冒出来的“Webpage not available”... 这些问题就像房间里的大象…...

【4】为什么Go能挂住成千上万个goroutine,线程却没爆?一次讲透GMP调度模型
如果你写 Go 写的久了,很容易对一件事习以为常:请求来了,起一个 goroutine;后台任务想并发跑,再起几个 goroutine;网络连接一多,程序里挂着成千上万个 goroutine,好像也不算什么稀奇…...

基于Python与LLM API构建轻量级命令行问答工具
1. 项目概述:一个轻量级命令行问答工具最近在折腾一些自动化脚本,经常需要在终端里快速查询一些信息,比如某个命令的用法、一个概念的简单解释,或者把一段代码从Python翻译成Go。每次都打开浏览器、切换标签页、输入关键词&#x…...

Web Proofs与TEE代理:构建可信API交互的技术解析
1. Web Proofs与TEE代理的技术背景解析在当今API驱动的分布式系统中,确保远程服务交互的可验证性已成为关键挑战。特别是在LLM(大语言模型)代理场景中,代理需要频繁调用外部API工具,而这些交互的真实性直接关系到整个系…...

GPTeam多智能体协作框架:从原理到实战部署指南
1. 项目概述:当AI学会“拉群”协作 如果你对AutoGPT这类单智能体工具已经玩得有点腻了,觉得一个AI自己跟自己玩效率有限,那么GPTeam这个项目可能会让你眼前一亮。简单来说,GPTeam是一个基于GPT-4(也支持GPT-3.5-turbo…...
)
营业执照识别OCR API实战:1行代码完成企业信息自动提取(附Python/Java/PHP/JS完整示例)
导读:在企业资质管理、金融风控、商家入驻审核等场景中,营业执照信息的手动录入一直是效率瓶颈。本文将手把手教您用1行核心代码调用营业执照识别OCR API,自动提取企业名称、统一社会信用代码、法定代表人等全部关键字段,附4种主流…...

自动化工作流开发:OCR识别致PDF信息提取、数学计算与Word计算书生成
自动化工作流开发:OCR识别致PDF信息提取、数学计算与Word计算书生成 一、项目概要与应用场景分析 在当下数字化转型全面加速的进程中,各类工程计算、财务核算、学术分析等工作场景中,存在大量从文档中提取结构化信息、执行数学计算并生成标准化报告的需求。以工程领域为例…...

Go语言变量与数据类型完全指南
概述Go语言以其简洁的类型系统著称,变量声明方式多样,数据类型清晰明了。本文详细介绍Go语言中的变量声明、基本数据类型、类型转换以及可见性规则,帮助读者打下坚实的类型基础。一、变量声明1.1 var 声明标准的变量声明使用 var 关键字&…...

原生Web Components组件库beads-ui:轻量、框架无关的UI开发实践
1. 项目概述:一个被低估的Web组件化UI框架如果你在React、Vue或Svelte的生态里待久了,偶尔会怀念那种纯粹用原生Web组件(Web Components)来构建界面的感觉。没有复杂的编译工具链,没有庞大的node_modules,一…...