chatGPT2:如何构建一个可以回答有关您网站问题的 AI 嵌入(embeddings)
感觉这个目前没有什么用,因为客户可以直接问通用chatGPT,实时了解你网站内的信息,除非你的网站chatGPT无法访问。
不过自动预订、买票等用嵌入还是挺有用的。
什么是嵌入?
OpenAI的嵌入(embeddings)是一种技术,它能够将文本、代码或者其他类型的数据转换成数值向量。这些数值向量捕捉了原始数据的关键特征和含义,使得计算机和算法能更有效地处理和分析数据。
将数据传递给模型的过程通常涉及以下几个步骤:
-
数据准备:首先,您需要准备您想要分析或处理的数据。这可能是文本、图片、音频或其他类型的数据。
-
格式转换:将数据转换成模型能够理解的格式。对于文本数据,这通常意味着将其转换为字符串形式。
-
使用API:如果您使用OpenAI的API,您需要按照API的要求格式化您的数据,并通过HTTP请求将其发送给API。这通常涉及到编写一些代码,使用像Python这样的编程语言。
-
处理响应:模型会处理您的数据,并以某种形式返回结果。这个结果通常也是一个数值向量,或者是其他类型的数据,例如生成的文本、图片等。
-
后处理:根据您的需求,您可能需要对模型的输出进行进一步的处理或分析。
对于不同类型的数据和不同的应用场景,这个过程可能会有所不同,但基本的原则是相似的。如果您具体想知道如何使用某个特定的OpenAI模型或API,通常最好的做法是查阅该模型或API的官方文档,那里会有详细的说明和示例代码。
构建一个可以回答有关您网站问题的 AI步骤:
1抓取网站
从根 URL 开始,访问每个页面,查找其他链接,并访问这些页面。
爬网程序遍历所有可访问的链接并将这些页面转换为文本文件(去掉html的tag)。
(内容如果太长,需分解成更小的块)
转为csv结构。
2使用 Embeddings API 将抓取的页面转换为嵌入
第一步是将嵌入转换为 NumPy 数组(基它形式的也可以)
import numpy as np
from openai.embeddings_utils import distances_from_embeddingsdf=pd.read_csv('processed/embeddings.csv', index_col=0)
df['embeddings'] = df['embeddings'].apply(eval).apply(np.array)df.head()
关于NumPy 数组 Certainly! Here’s a simple example using NumPy, a powerful
library for numerical processing in Python. This example will
demonstrate how to create a NumPy array and perform some basic
operations:# Creating a simple NumPy array array = np.array([1, 2, 3, 4, 5]) print("Original Array:", array)# Performing basic operations # Adding a constant to each element added_array = array + 10 print("Array after adding 10 to each element:", added_array)# Multiplying each element by 2 multiplied_array = array * 2 print("Array after multiplying each element by 2:", multiplied_array)# Computing the mean of the array mean_value = np.mean(array) print("Mean of the array:", mean_value)# Reshaping the array into a 2x3 matrix # Note: The total number of elements must remain the same. reshaped_array = np.reshape(array, (2, 2)) # Only possible with an array of 4 elements print("Reshaped array into a 2x2 matrix:\n", reshaped_array) ```In this example, we first import the NumPy library. Then, we create a basic array and perform operations like addition, multiplication, and calculating the mean. Finally, we reshape the array into a 2x2 matrix. Keep in mind that the reshape function requires the total number of elements to remain the same, so in this example, you would need to modify the original array or the shape to ensure they match.
3创建一个基本的搜索功能,允许用户询问有关嵌入信息的问题
现在数据已经准备好了,根据检索到的文本生成一个自然的答案。
def create_context(question, df, max_len=1800, size="ada"
):"""Create a context for a question by finding the most similar context from the dataframe"""# Get the embeddings for the questionq_embeddings = client.embeddings.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']# Get the distances from the embeddingsdf['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine')returns = []cur_len = 0# Sort by distance and add the text to the context until the context is too longfor i, row in df.sort_values('distances', ascending=True).iterrows():# Add the length of the text to the current lengthcur_len += row['n_tokens'] + 4# If the context is too long, breakif cur_len > max_len:break# Else add it to the text that is being returnedreturns.append(row["text"])# Return the contextreturn "\n\n###\n\n".join(returns)
回答提示将尝试从检索到的上下文中提取相关事实,以制定连贯的答案。如果没有相关答案,提示将返回“我不知道”。
def answer_question(df,model="gpt-3.5-turbo",question="Am I allowed to publish model outputs to Twitter, without a human review?",max_len=1800,size="ada",debug=False,max_tokens=150,stop_sequence=None
):"""Answer a question based on the most similar context from the dataframe texts"""context = create_context(question,df,max_len=max_len,size=size,)# If debug, print the raw model responseif debug:print("Context:\n" + context)print("\n\n")try:# Create a chat completion using the question and contextresponse = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": "Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\n"},{"role": "user", f"content": "Context: {context}\n\n---\n\nQuestion: {question}\nAnswer:"}],temperature=0,max_tokens=max_tokens,top_p=1,frequency_penalty=0,presence_penalty=0,stop=stop_sequence,)return response.choices[0].message.strip()except Exception as e:print(e)return ""
测试问答系统
测试来查看输出的质量。
如果系统无法回答预期的问题,则值得搜索原始文本文件,以查看预期已知的信息是否实际上最终被嵌入。
相关文章:
)
chatGPT2:如何构建一个可以回答有关您网站问题的 AI 嵌入(embeddings)
感觉这个目前没有什么用,因为客户可以直接问通用chatGPT,实时了解你网站内的信息,除非你的网站chatGPT无法访问。 不过自动预订、买票等用嵌入还是挺有用的。 什么是嵌入? OpenAI的嵌入(embeddings)是一种…...

Vue3-新特性defineOptions和defineModel
defineOptions 问题:用了<script setup>后,就无法添加与其平级的属性了,比如定义组件的name或其他自定义的属性。 为了解决这一问题,引入了defineProps与defineEmits这两个宏,但这只解决了props与emits这两个属…...
【计算机基础】通过插件plantuml,实现在VScode里面绘制状态机
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
Linux常用基础命令及重要目录,配置文件功能介绍
目录 一,Linux常用必备基础命令 1,网络类命令 2,文件目录类命令 3,操作类命令 4,关机重启命令 5,帮助命令 6,查看显示类命令 7,命令常用快捷键 二,Linux重要目录…...

Oracle登录认证方式详解
文章目录 一、简介二、OS认证三、口令认证四、remote_login_passwordfile 详解 一、简介 在数据库管理中,登录认证是确保数据库安全性的重要环节。Oracle数据库提供 了两种认证方式,一种是“操作系统认证”,一种是“口令文件认证,…...

ate测试原理及ate测试系统(软件)知识科普 -纳米软件
ATE(Automatic Test Equipment)测试也叫自动化测试,通过计算机控制测试仪器对被测对象进行测试。以计算机编程代替人工测试,基于测试程序控制仪器并对待测品进行输入和输出信号检测分析,从而判断待测品的性能是否符合要求。 ATE测试需要根据测…...
Linux | 创建 | 删除 | 查看 | 基本命名详解
Linux | 创建 | 删除 | 查看 | 基本命名详解 文章目录 Linux | 创建 | 删除 | 查看 | 基本命名详解前言一、安装Linux1.1 方法一:云服务器方式1.2 方法二:虚拟机方式 二、ls2.2 ll 三、which3.1 ls -ld 四、pwd五、cd5.1 cd .\.5.2 ls -al5.3 重新认识命…...

搭配:基于OpenCV的边缘检测实战
引言 计算机中的目标检测与人类识别物体的方式相似。作为人类,我们可以分辨出狗的形象,因为狗的特征是独特的。尾巴、形状、鼻子、舌头等特征综合在一起,帮助我们把狗和牛区分开来。 同样,计算机能够通过检测与估计物体的结构和性…...

AI大发展:人机交互、智能生活全解析
目录 编辑 人工智能对我们的生活影响有多大 人工智能的应用领域 一、机器学习与深度学习 二、计算机视觉 三、自然语言处理 四、机器人技术 五、智能推荐系统 六、智能城市和智能家居 编辑 自己对人工智能的应用 自己的人工智能看法:以ChatGPT为例 …...
Django DRF序列化器serializer
以下案例由浅到深,逐步深入,通过实例介绍了序列化器的使用方法,和遇到的常见问题的解决方法。 一、序列化器serializers.Serializer 1、urls.py urlpatterns [path("api/<str:version>/depart/",views.DepartView.as_vie…...

【开源】基于JAVA的衣物搭配系统
项目编号: S 016 ,文末获取源码。 \color{red}{项目编号:S016,文末获取源码。} 项目编号:S016,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、研究内容2.1 衣物档案模块2.2 衣物搭配模块2.3 衣…...
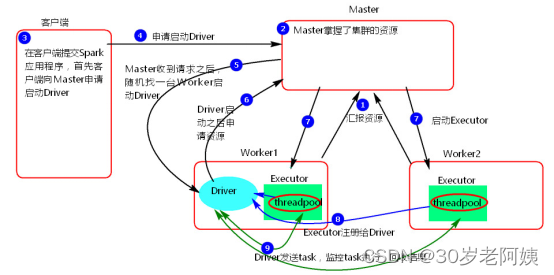
Spark---基于Standalone模式提交任务
Standalone模式两种提交任务方式 一、Standalone-client提交任务方式 1、提交命令 ./spark-submit --master spark://mynode1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 100 或者 ./spark-submit --master spark…...

webrtc的RTCPeerConnection使用
背景: 平时我们很少会需要使用到点对点单独的通讯,即p2p,一般都是点对服务端通讯,但p2p也有自己的好处,即通讯不经过服务端,从服务端角度这个省了带宽和压力,从客户端角度,通讯是安全,且快速的,当然有些情况下可能速度并不一定快。那么如何实现p2p呢? 解决办法: …...

【视觉SLAM十四讲学习笔记】第三讲——Eigen库
专栏系列文章如下: 【视觉SLAM十四讲学习笔记】第一讲——SLAM介绍 【视觉SLAM十四讲学习笔记】第二讲——初识SLAM 【视觉SLAM十四讲学习笔记】第三讲——旋转矩阵 本章将介绍视觉SLAM的基本问题之一:如何描述刚体在三维空间中的运动? Eigen…...
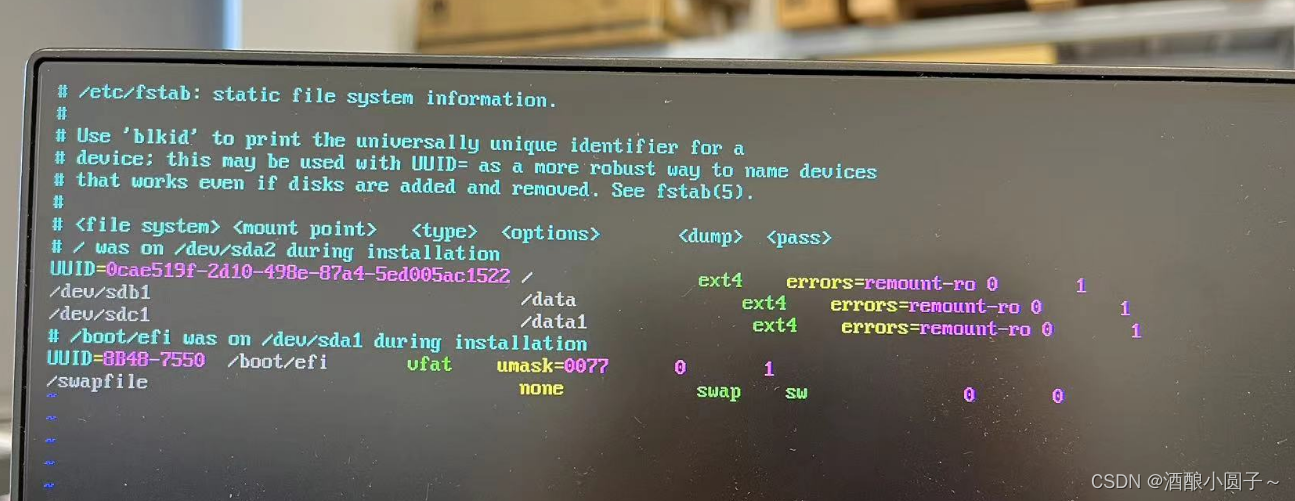
Ubuntu开机显示recovering journal,进入emergency mode
在一次正常的shutdown -r now之后,服务器启动不起来了,登录界面显示recovering journal,主要报错信息如下所示: /dev/sda2:recovering journal /dev/sda2:Clearn... You are in emergency mode. After logging in, type journalc…...

C++_String增删查改模拟实现
C_String增删查改模拟实现 前言一、string默认构造、析构函数、拷贝构造、赋值重载1.1 默认构造1.2 析构函数1.3 拷贝构造1.4 赋值重载 二、迭代器和范围for三、元素相关:operator[ ]四、容量相关:size、resize、capacity、reserve4.1 size、capacity4.2…...
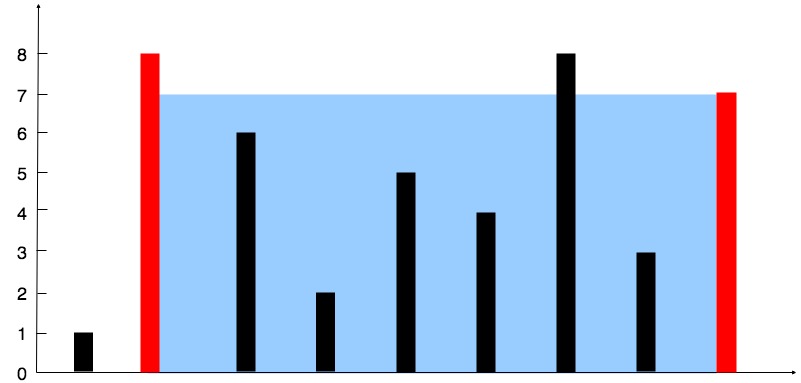
LeeCode前端算法基础100题(2)- 最多水的容器
一、问题详情: 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:…...

排序算法--归并排序
实现逻辑 ① 将序列每相邻两个数字进行归并操作,形成floor(n/2)个序列,排序后每个序列包含两个元素 ② 将上述序列再次归并,形成floor(n/4)个序列,每个序列包含四个元素 ③ 重复步骤②,直到所有元素排序完毕 void pri…...

【LeetCode:1410. HTML 实体解析器 | 模拟+哈希表+字符串+库函数】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
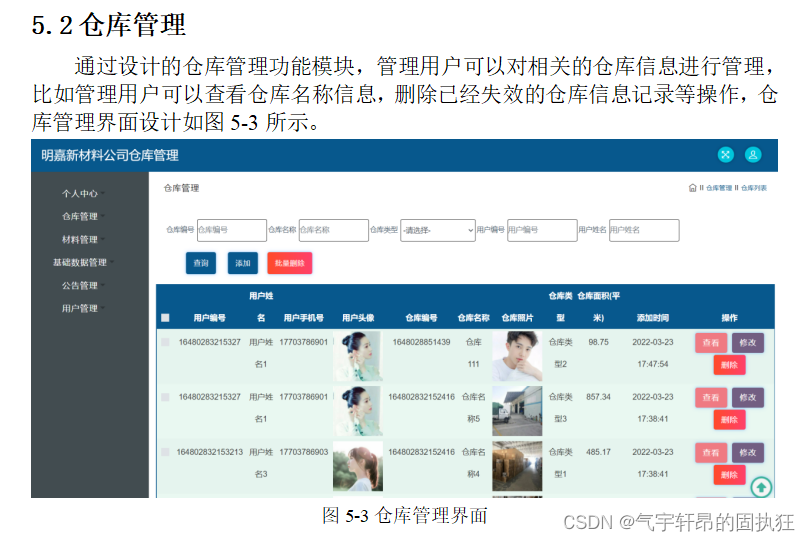
基于SSM的公司仓库管理系统(有报告)。Javaee项目
演示视频: 基于SSM的公司仓库管理系统(有报告)。Javaee项目 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring SpringMvc …...
)
编程初学者学习:句柄(二)
上篇文章,我们学习了指针。这篇文章,我们来学习一下句柄。相同点句柄和指针都是通过一种间接的方式去操作我们的目标资源。其在代码中的表现方式都是一种整型数值的表现方式(地址值本质是一个整型数值)。不同点指针在多数语言中是…...
方案)
nli-MiniLM2-L6-H768保姆级教程:NLI服务接入企业统一认证(LDAP/OAuth2)方案
nli-MiniLM2-L6-H768保姆级教程:NLI服务接入企业统一认证(LDAP/OAuth2)方案 1. 引言 nli-MiniLM2-L6-H768是一个专为自然语言推理(NLI)与零样本分类设计的轻量级交叉编码器(Cross-Encoder)模型。它具备以下核心优势: 精度高&am…...

keysight N9040B是德 UXA 频谱分析仪 2 Hz 至 50 GHz
N9040B UXA信号分析仪的性能让您能够表征当今*挑战性的信号,包括5G、802 .11ax /ay、电子战等应用中的快速跳频、宽带和瞬态信号。通过优异的相位噪声性能和宽广的无杂散动态范围,您可以全面了解您的设计纯度。 Keysight N9040B UXA信号分析仪 主要特性和…...

如何快速掌握JetBrains IDE试用期重置:开发者的完整指南
如何快速掌握JetBrains IDE试用期重置:开发者的完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目关键时刻被IDE试用期到期弹窗打断?或者因为试用期结束而不得不切换…...

实测FireRed-OCR Engine:一键将PDF/图片表格公式转成Markdown
实测FireRed-OCR Engine:一键将PDF/图片表格公式转成Markdown 1. 引言:文档解析的新选择 在日常工作和学习中,我们经常需要处理各种文档格式转换的问题。特别是当遇到PDF文件、扫描图片中的表格和数学公式时,手动转录不仅耗时耗…...

百度文库智能打印工具:突破文档获取限制的完整指南
百度文库智能打印工具:突破文档获取限制的完整指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 百度文库智能打印工具是一款专为技术爱好者和普通用户设计的实用工具,通…...

Blender glTF插件实战指南:解决3D资产跨平台兼容的5大核心挑战
Blender glTF插件实战指南:解决3D资产跨平台兼容的5大核心挑战 【免费下载链接】glTF-Blender-IO Blender glTF 2.0 importer and exporter 项目地址: https://gitcode.com/gh_mirrors/gl/glTF-Blender-IO 如何在Blender中创建3D内容,却面临跨平台…...

EldenRingSaveCopier:5步实现艾尔登法环存档角色无损迁移
EldenRingSaveCopier:5步实现艾尔登法环存档角色无损迁移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 你是否曾在不同电脑间转移《艾尔登法环》进度时遇到困扰?或者想要将好友存档中…...

【FAQ】HP Anyware文章汇总列表
方案原理 【方案原理】什么是PCoIP技术 【方案原理】什么是PCoIP Ultra协议增强 Anyware Agent Win10 22H2物理机安装总结 物理机消费级NVIDIA GPU的说明 PCoIP 会话后物理工作站本地显示器黑屏 【组件安装】Ubuntu 22.04.5 desktop 安装 Anyware Agent 【FAQ】安装Agent的…...

VRM4U与LiveLinkFace:打造实时面部动画的终极解决方案
VRM4U与LiveLinkFace:打造实时面部动画的终极解决方案 【免费下载链接】VRM4U Runtime VRM loader for UnrealEngine5 项目地址: https://gitcode.com/gh_mirrors/vr/VRM4U VRM4U是专为Unreal Engine设计的运行时VRM加载器,能够将VRM虚拟角色模型…...