时间序列预测实战(十七)PyTorch实现LSTM-GRU模型长期预测并可视化结果(附代码+数据集+详细讲解)

一、本文介绍
本文给大家带来的实战内容是利用PyTorch实现LSTM-GRU模型,LSTM和GRU都分别是RNN中最常用Cell之一,也都是时间序列预测中最常见的结构单元之一,本文的内容将会从实战的角度带你分析LSTM和GRU的机制和效果,同时如果你是时间序列中的新手,这篇文章会带你了解整个时间序列的建模过程,同时本文的实战代码支持多元预测单元、单元预测单元、多元预测多元,本文的实战内容通过时间序列领域最经典的数据集——电力负荷数据集为例进行预测。
内容回顾->时间序列预测专栏——包含上百种时间序列模型带你从入门到精通时间序列预测
预测类型->单元预测、多元预测、长期预测
目录
一、本文介绍
二、LSTM和GRU的机制原理
2.1LSTM的机制原理
2.2.1忘记门
2.2.2输入门
2.2.3输出门
2.2GRU的机制原理
2.2.1GRU的基本原理
2.2.1GRU的基本框架
2.3 融合思想
三、数据集介绍
四、参数讲解
五、模型实战
5.1 模型完整代码
5.2 模型训练
5.3 模型预测
5.4 结果分析
六、全文总结
二、LSTM和GRU的机制原理
2.1LSTM的机制原理
LSTM(长短期记忆,Long Short-Term Memory)是一种用于处理序列数据的深度学习模型,属于循环神经网络(RNN)的一种变体,其使用一种类似于搭桥术结构的RNN单元。相对于普通的RNN,LSTM引入了门控机制,能够更有效地处理长期依赖和短期记忆问题,是RNN网络中最常使用的Cell之一。
LSTM通过刻意的设计来实现学习序列关系的同时,又能够避免长期依赖的问题。它的结构示意图如下所示。

在LSTM的结构示意图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。其中“+”号代表着运算操作(如矢量的和),而矩形代表着学习到的神经网络层。汇合在一起的线表示向量的连接,分叉的线表示内容被复制,然后分发到不同的位置。
如果上面的LSTM结构图你看着很难理解,但是其实LSTM的本质就是一个带有tanh激活函数的简单RNN,如下图所示。

LSTM这种结构的原理是引入一个称为细胞状态的连接。这个状态细胞用来存放想要的记忆的东西(对应简单LSTM结构中的h,只不过这里面不再只保存上一次状态了,而是通过网络学习存放那些有用的状态),同时在加入三个门,分别是。
忘记门:决定什么时候将以前的状态忘记。
输入门:决定什么时候将新的状态加进来。
输出门:决定什么时候需要把状态和输入放在一起输出。
从字面上可以看出,由于三个门的操作,LSTM在状态的更新和状态是否要作为输入,全部交给了神经网络的训练机制来选择。
下面分别来介绍一下三个门的结构和作用。
2.2.1忘记门
下图所示为忘记门的操作,忘记门决定模型会从细胞状态中丢弃什么信息。
忘记门会读取前一序列模型的输出和当前模型的输入
来控制细胞状态中的每个数是否保留。
例如:在一个语言模型的例子中,假设细胞状态会包含当前主语的性别,于是根据这个状态便可以选择正确的代词。当我们看到新的主语时,应该把新的主语在记忆中更新。忘记们的功能就是先去记忆中找到一千那个旧的主语(并没有真正执行忘记的操作,只是找到而已。

在上图的LSTM的忘记门中,代表忘记门的输出, α代表激活函数,
代表忘记门的权重,
代表当前模型的输入,
代表前一个序列模型的输出,
代表忘记门的偏置。
2.2.2输入门
输入门可以分为两部分功能,一部分是找到那些需要更新的细胞状态。另一部分是把需要更新的信息更新到细胞状态里
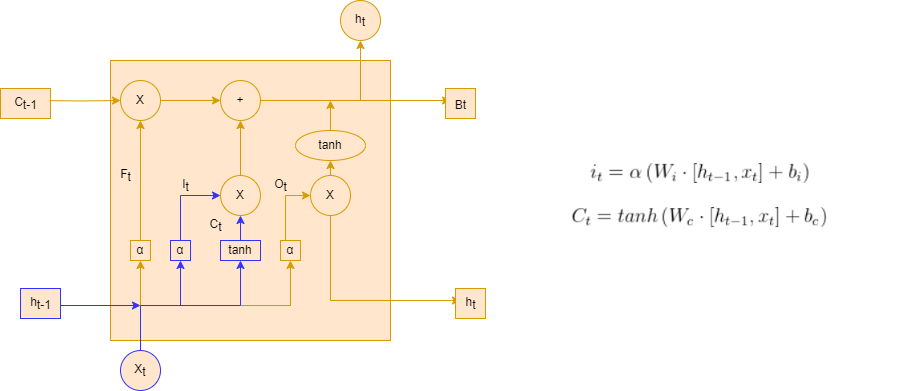
在上面输入门的结构中,代表要更新的细胞状态,α代表激活函数,
代表当前模型的输入,
代表前一个序列模型的输出,
代表计算
的权重,
代表计算
的偏置,
代表使用tanh所创建的新细胞状态,
代表计算
的权重,
代表计算
的偏置。
忘记门找到了需要忘掉的信息后,在将它与旧状态相乘,丢弃确定需要丢弃的信息。(如果需要丢弃对应位置权重设置为0),然后,将结果加上
*
使细胞状态获得新的信息。这样就完成了细胞状态的更新,如下图输入门的更新图所示。
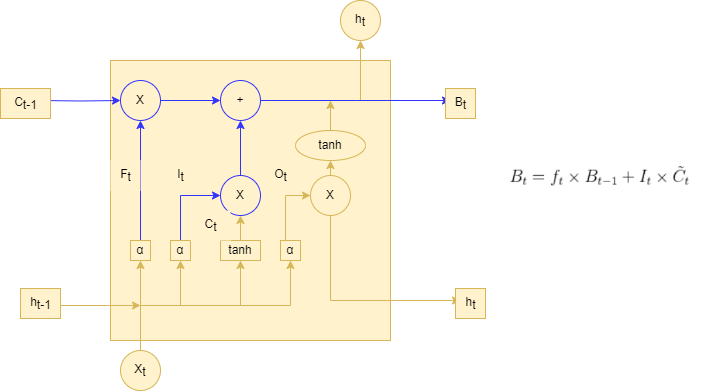
再上图LSTM输入门的更新图中,代表忘记门的输出结果,
代表忘记门的输出结果,
代表前一个序列模型的细胞状态,
代表要更新的细胞状态,
代表使用tanh所创建的新细胞状态。
2.2.3输出门
如下图LSTM的输出门结构图所示,在输出门中,通过一个激活函数层(实际使用的是Sigmoid激活函数)来确定哪个部分的信息将输出,接着把细胞状态通过tanh进行处理(得到一个在-1~1的值),并将它和Sigmoid门的输出相乘,得出最终想要输出的那个部分,例如,在语言模型中,假设已经输入了一个代词,便会计算出需要输出一个与该代词相关的信息(词向量)

在LSTM的输出门结构图中,代表要输出的信息,α代表激活函数,
代表计算
的权重,
代表计算
的偏置,
代表更新后的细胞状态,
代表当前序列模型的输出结果。
2.2GRU的机制原理
2.2.1GRU的基本原理
GRU(门控循环单元)是一种循环神经网络(RNN)的变体,主要用于处理序列数据,它的基本原理可以概括如下:
门控机制:GRU的核心是门控机制,包括更新门(update gate)和重置门(reset gate)。这些门控制着信息的流动,即决定哪些信息应该被保留,哪些应该被遗忘。
更新门:更新门帮助模型决定过去的信息有多少需要保留到当前状态。它是通过当前输入和前一个隐状态计算得出的,用于调节隐状态的更新程度。
重置门:重置门决定了多少过去的信息需要被忘记。它同样依赖于当前输入和前一个隐状态的信息。当重置门接近0时,模型会“忘记”过去的隐状态,只依赖于当前输入。
当前隐状态的计算:利用更新门和重置门的输出,结合前一隐状态和当前输入,GRU计算出当前的隐状态。这个隐状态包含了序列到目前为止的重要信息。
输出:GRU的最终输出通常是在序列的每个时间步上产生的,或者在序列的最后一个时间步产生,取决于具体的应用场景。
总结:GRU相较于传统的RNN,其优势在于能够更有效地处理长序列数据,减轻了梯度消失的问题。同时,它通常比LSTM(长短期记忆网络)更简单,因为它有更少的参数。
2.2.1GRU的基本框架

上面的图片为一个GRU的基本结构图,解释如下->
- 更新门(z) 在决定是否用新的隐藏状态更新当前隐藏状态时扮演重要角色。
- 重置门(r) 决定是否忽略之前的隐藏状态。
这些部分是GRU的核心组成,它们共同决定了网络如何在序列数据中传递和更新信息,这对于时间序列分析至关重要。
2.3 融合思想
三、数据集介绍
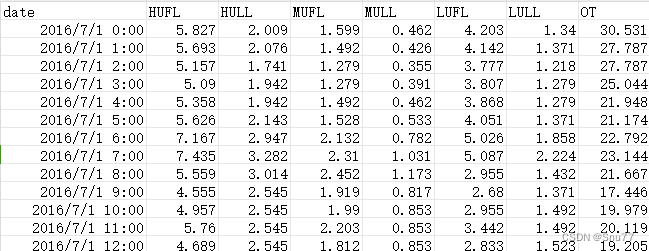
我们本文用到的数据集是官方的ETTh1.csv ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、参数讲解
下面的代码是我定义的所有参数,目前只有这些,这个框架我会进行补充,后期也会在这里进行更新。
parser = argparse.ArgumentParser(description='Time Series forecast')parser.add_argument('-model', type=str, default='LSTM-GRU', help="模型持续更新")parser.add_argument('-window_size', type=int, default=48, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=15, help="训练轮次")parser.add_argument('-batch_size', type=int, default=128, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden-size', type=int, default=64, help="隐藏层单元数")parser.add_argument('-kernel-sizes', type=str, default='3')# deviceparser.add_argument('-use_gpu', type=bool, default=False)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-test', action='store_true', default=False)parser.add_argument('-lr-scheduler', type=bool, default=True)args = parser.parse_args()参数的详细讲解->
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 1 | model | str | 模型名称 |
| 2 | window_size | int | 时间窗口大小大小需要注意window_size需要大于pre_len |
| 3 | pre_len | int | 预测未来数据的长度 |
| 4 | shuffle | bool | 是否打乱dataloader中的数据 |
| 5 | data_path | str | 你的数据地址 |
| 6 | target | str | 你需要预测的特征列,这个值最后会保存在csv的文件里 |
| 7 | input_size | int | 你的特征列个数不算时间那一列 |
| 8 | feature | str | [M, S, MS],多元预测多元,单元预测单元,多元预测单元 |
| 9 | lr | float | 学习率大小, |
| 10 | drop_out | float | 随机丢弃概率,不要太大 |
| 11 | epochs | int | 训练轮次,小于30一般比较合理 |
| 12 | batch_size | int | 一个批次的大小 |
| 13 | svae_path | str | 模型的保存的路径 |
| 14 | hidden_size | int | 隐藏层的单元个数 |
| 15 | kernel_sizes | int | 卷积核大小 |
| 16 | use_gpu | bool | 是否使用GPU |
| 17 | device | int | GPU的编号 |
| 18 | train | bool | 是否进行训练 |
| 19 | predict | bool | 是否进行预测 |
| 20 | lr_scheduler | bool | 是否使用学习率计划。 |
五、模型实战
5.1 模型完整代码
下面是模型的暂时代码,后期会持续更新内容,以后的实战也会基于这个版本的框架下进行。
我们将下面的代码创建一个py文件复制进去即可运行。
import argparse
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset
import torch.nn.functional as F
# 随机数种子
np.random.seed(0)class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def create_inout_sequences(input_data, tw, pre_len):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + pre_len) > len(input_data):breaktrain_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seqdef calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return maedef create_dataloader(config, device):print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")df = pd.read_csv(config.data_path) # 填你自己的数据地址,自动选取你最后一列数据为特征列 # 添加你想要预测的特征列pre_len = config.pre_len # 预测未来数据的长度train_window = config.window_size # 观测窗口# 将特征列移到末尾target_data = df[[config.target]]df = df.drop(config.target, axis=1)df = pd.concat((df, target_data), axis=1)cols_data = df.columns[1:]df_data = df[cols_data]# 这里加一些数据的预处理, 最后需要的格式是pd.seriestrue_data = df_data.values# 定义标准化优化器scaler_train = MinMaxScaler(feature_range=(0, 1))scaler_valid = MinMaxScaler(feature_range=(0, 1))scaler_test = MinMaxScaler(feature_range=(0, 1))# 训练集、验证集、测试集划分train_data = true_data[:int(0.75 * len(true_data))]valid_data = true_data[int(0.75 * len(true_data)):int(0.80 * len(true_data))]test_data = true_data[int(0.80 * len(true_data)):]print("训练集尺寸:", len(train_data), "测试集尺寸:", len(test_data), "验证集尺寸:", len(valid_data))# 进行标准化处理train_data_normalized = scaler_train.fit_transform(train_data)test_data_normalized = scaler_test.fit_transform(test_data)valid_data_normalized = scaler_valid.fit_transform(valid_data)# 转化为深度学习模型需要的类型Tensortrain_data_normalized = torch.FloatTensor(train_data_normalized).to(device)test_data_normalized = torch.FloatTensor(test_data_normalized).to(device)valid_data_normalized = torch.FloatTensor(valid_data_normalized).to(device)# 定义训练器的的输入train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)valid_inout_seq = create_inout_sequences(valid_data_normalized, train_window, pre_len)# 创建数据集train_dataset = TimeSeriesDataset(train_inout_seq)test_dataset = TimeSeriesDataset(test_inout_seq)valid_dataset = TimeSeriesDataset(valid_inout_seq)# 创建 DataLoadertrain_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)print("通过滑动窗口共有训练集数据:", len(train_loader))print("通过滑动窗口共有测试集数据:", len(test_loader))print("通过滑动窗口共有验证集数据:", len(test_loader))print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器完成<<<<<<<<<<<<<<<<<<<<<<<<<<<")return train_loader, test_loader, valid_loader, scaler_testclass LSTM_GRU(nn.Module):def __init__(self, args, device):super(LSTM_GRU, self).__init__()self.args = argsself.device = deviceself.dropout = nn.Dropout(args.drop_out)self.lstm = nn.LSTM(args.input_size, args.hidden_size , batch_first=True)self.gru = nn.GRU(input_size=args.hidden_size , hidden_size=args.hidden_size, num_layers=1, batch_first=True)self.linearOut = nn.Linear(args.hidden_size, args.input_size)def forward(self, x):hidden = ((torch.zeros(1, x.size(0), self.args.hidden_size ).to(self.device)),(torch.zeros(1, x.size(0), self.args.hidden_size ).to(self.device)))x, lstm_h = self.lstm(x, hidden)x = self.dropout(x)x = F.tanh(torch.transpose(x, 1, 2))x = x.permute(0, 2, 1)x, gru_ = self.gru(x)x = self.dropout(x)x = F.tanh(torch.transpose(x, 1, 2))x = x.permute(0, 2, 1)x = self.linearOut(x)x = x[:, -args.pre_len:, :]return xdef train(model, args, device, scaler):losss = []lstm_model = modelloss_function = nn.MSELoss()optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)epochs = args.epochslstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")test(model, args, scaler)# valid()def test(model, args, scaler):lstm_model = model# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式results = []reals = []losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy(), np.array(labels.detach())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)for j in range(args.batch_size):for i in range(args.pre_len):reals.append(labels[j][i].detach().numpy())results.append(pred[j][i].detach().numpy())reals = scaler.inverse_transform(np.array(reals))results = scaler.inverse_transform(np.array(results))print("测试集预测结果:", results)print("测试集误差MAE:", losss)plt.figure()plt.style.use('ggplot')# 创建折线图plt.plot(reals[:, -1], label='real', color='blue') # 实际值plt.plot(results[:, -1], label='forecast', color='red', linestyle='--') # 预测值# 增强视觉效果plt.grid(True)plt.title('real vs forecast')plt.xlabel('time')plt.ylabel('value')plt.legend()plt.savefig('test——results.png')def pre_dict():# 后期补充预测功能passif __name__ == '__main__':parser = argparse.ArgumentParser(description='Time Series forecast')parser.add_argument('-model', type=str, default='LSTM-GRU', help="模型持续更新")parser.add_argument('-window_size', type=int, default=48, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=15, help="训练轮次")parser.add_argument('-batch_size', type=int, default=128, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden-size', type=int, default=64, help="隐藏层单元数")parser.add_argument('-kernel-sizes', type=str, default='3')# deviceparser.add_argument('-use_gpu', type=bool, default=False)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)args = parser.parse_args()if isinstance(args.device, int) and args.use_gpu:device = torch.device("cuda:" + f'{args.device}')else:device = torch.device("cpu")# 读取数据地址,创建数据加载器train_loader, test_loader, valid_loader, scaler = create_dataloader(args, device)# 实例化模型model = LSTM_GRU(args, device).to(device)# 训练模型if args.train:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型训练<<<<<<<<<<<<<<<<<<<<<<<<<<<")train(model, args, device, scaler)if args.predict:print(f">>>>>>>>>>>>>>>>>>>>>>>>>预测未来{args.pre_len}条数据<<<<<<<<<<<<<<<<<<<<<<<<<<<")pre_dict()5.2 模型训练
当我们通过章节四配置好所有的参数之后,我们就可以运行我们创建的py文件了,控制台就会进行训练,输出如下内容->

5.3 模型预测
下面的图片是模型在测试集上的表现, 可以看到效果还可以吧只能说一般,毕竟这两个结构单元只是最普通的,也没有在其中加入任何的其它高等级机制。
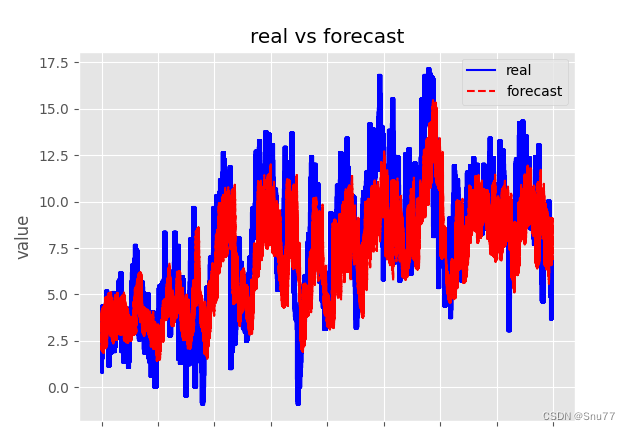
5.4 结果分析
当我们预测完成之后,会进行测试集验证同时会输出测试集的表现情况,后期我会添加个绘图功能在这里。

六、全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。

相关文章:
时间序列预测实战(十七)PyTorch实现LSTM-GRU模型长期预测并可视化结果(附代码+数据集+详细讲解)
一、本文介绍 本文给大家带来的实战内容是利用PyTorch实现LSTM-GRU模型,LSTM和GRU都分别是RNN中最常用Cell之一,也都是时间序列预测中最常见的结构单元之一,本文的内容将会从实战的角度带你分析LSTM和GRU的机制和效果,同时如果你…...

【免费使用】基于PaddleSeg开源项目开发的人像抠图Web API接口
基于PaddleSeg开源项目开发的人像抠图API接口,服务器不存储照片大家可放心使用。 1、请求接口 请求地址:http://apiseg.hysys.cn/predict_img 请求方式:POST 请求参数:{"image":"/9j/4AAQ..."} 参数是jso…...

Centos7 Python环境和yum修复
1、删除现有残余包 [rootlocalhost ]# rpm -qa|grep python|xargs rpm -ev --allmatches --nodeps[rootlocalhost ]# rpm -qa|grep yum|xargs rpm -ev --allmatches --nodeps[rootlocalhost ]# whereis python |xargs rm -frv[rootlocalhost ]# whereis python ##验证清除&…...
Ubuntu下使用protoBuf
一、protobuf简介: 1.1 protobuf的定义: protobuf是用来干嘛的? protobuf是一种用于 对结构数据进行序列化的工具,从而实现 数据存储和交换。 (主要用于网络通信中 收发两端进行消息交互。所谓的“结构数据”是指类…...
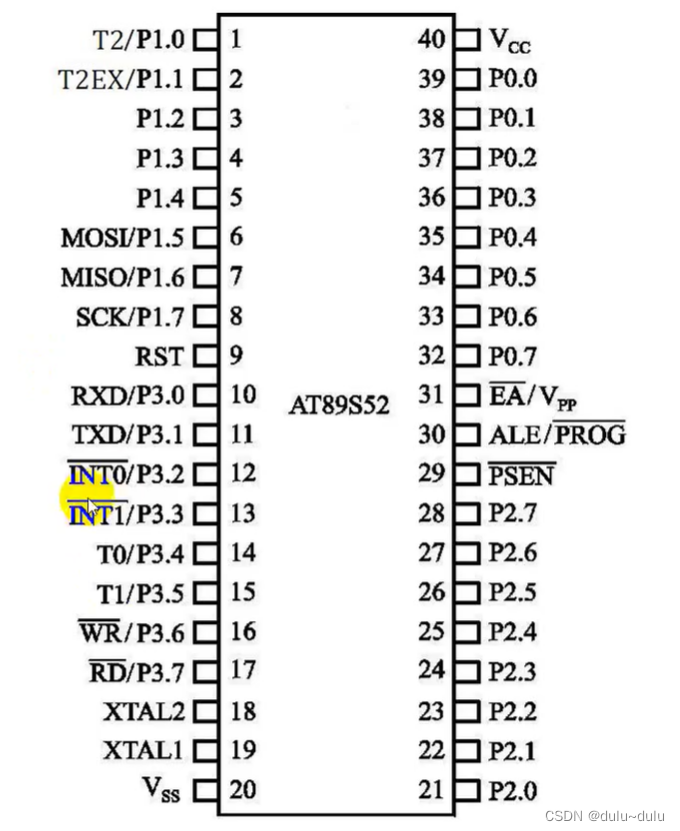
AT89S52单片机
目录 一.AT89S52单片机的硬件组成 1.CPU(微处理器) (1)运算器 (2)控制器 2.数据存储器 (RAM) (1)片内数据存储器 (2)片外数据存储器 3.程序存储器(Flash ROM) 4.定时器/计数器 5.中断系统 6.串行口 7.P0口、P1口、P2口和P3口 8.特殊功能寄存器 (SFR) 常用的特殊功…...
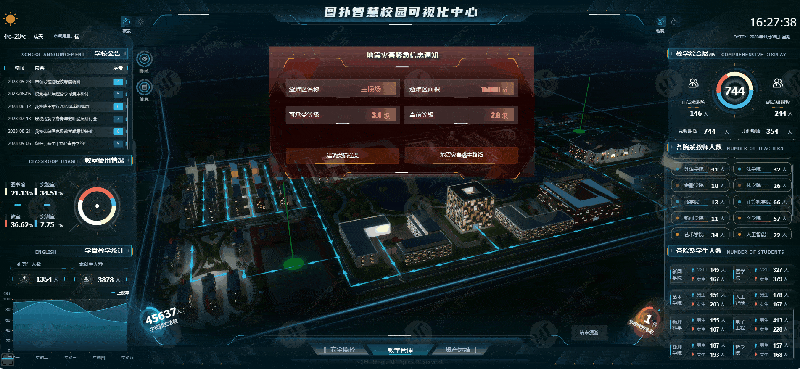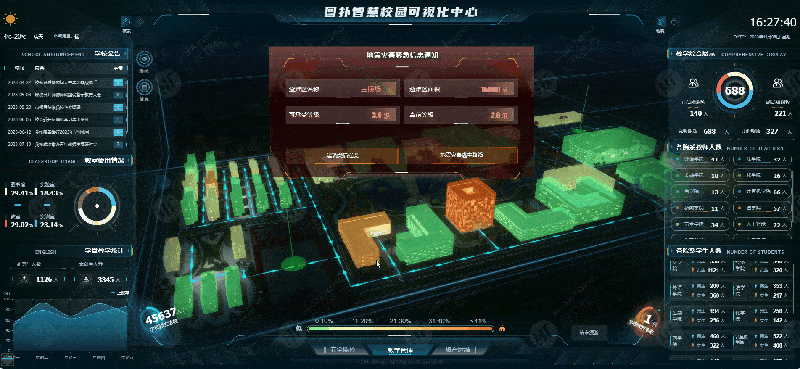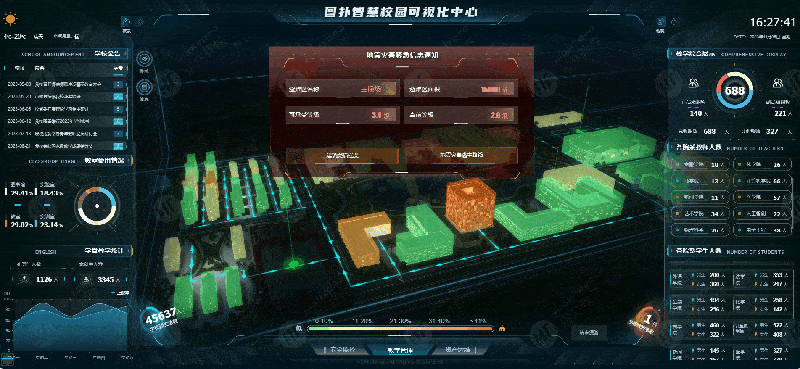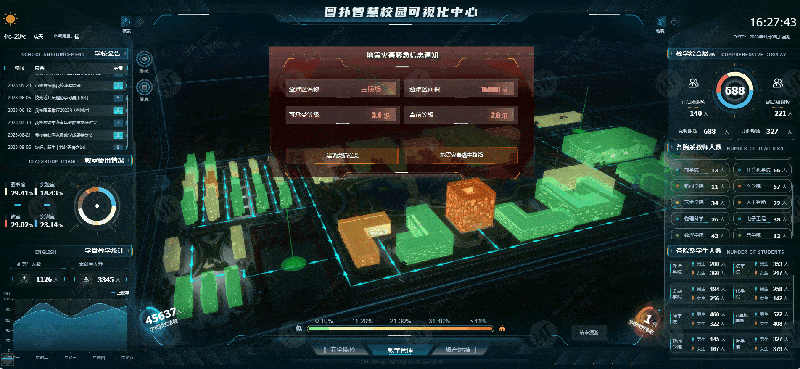
数字孪生智慧校园 Web 3D 可视化监测
当今,智慧校园发展阶段亟需推动信息可视化建设与发展,将大数据、云计算、可视化等高新技术相融合,为校园师生创造科学智能的学习环境,并实现教学资源最大化和信息服务智能化。帮助学校更好地应用校园可视化技术,提升校…...
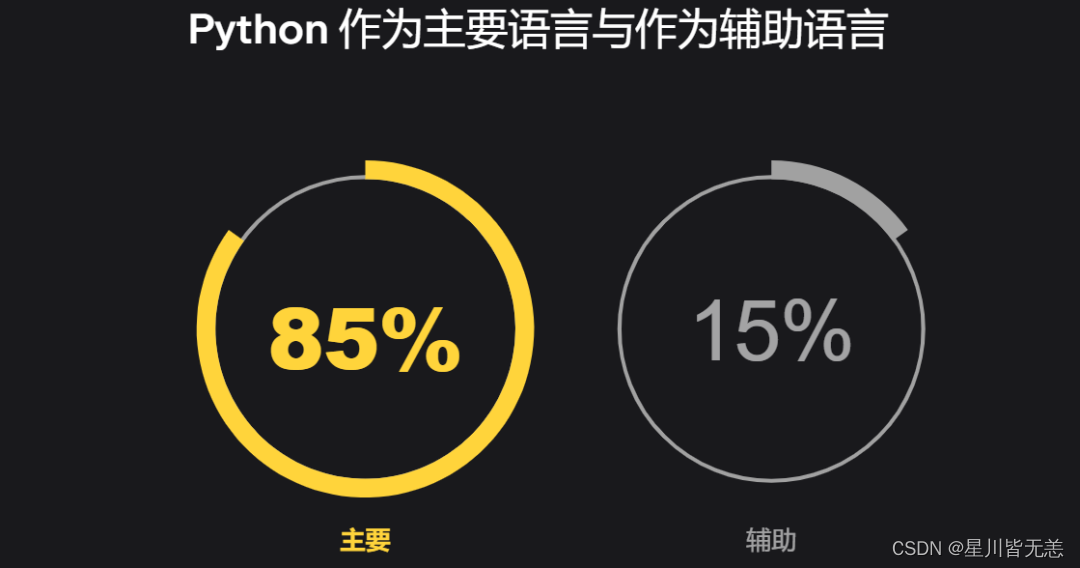
Python Web框架的三强之争:Flask、Django和FastAPI
JetBrains 公布 2022 Python 开发者调查结果。 完整报告地址:https://lp.jetbrains.com/zh-cn/python-developers-survey-2022/ 这是由 Python 软件基金会 (PSF) 和 JetBrains 共同开展的第六次官方年度 Python 开发者调查,回复于 2022 年 10 月至 12 …...

本地缓存与分布式缓存
一、缓存的概念 在服务端编程当中,缓存主要是指将数据库的数据加载到内存中,之后对该数据的访问都在内存中完成,从而减少了对数据库的访问,解决了高并发场景中数据库容易成为性能瓶颈的问题;以及基于内存的访问速度高…...
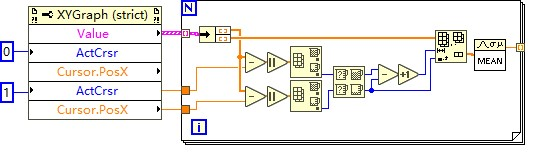
LabVIEW如何获取波形图上游标所在位置的数值
LabVIEW如何获取波形图上游标所在位置的数值 获取游标所在位置数值的一种方法是利用波形图的游标列表属性。 在VI的程序框图中,右键单击波形图并选择创建引用 ,然后将创建的引用节点放在程序框图上。 在程序框图上放置一个属性节点,并将其…...
八股文面试day6
什么是代理?为什么要用动态代理? 代理模式大概意思是:为其他对象提供一个代理项或者是占位符,以控制对这个对象的访问 代理模式核心思想:创建一个代理对象,在客户端和目标对象之间的一个中介,…...

【Unity】EventSystem.current.IsPointerOverGameObject()对碰撞体起作用
本来我是用 EventSystem.current.IsPointerOverGameObject()来检测是否点击在UI上的,但是发现,他对我的碰撞体也是返回ture,研究半天。。。。找不出问题,然后发现我的相机上挂载了PhysicsRaycaster,去掉之后就好了,至于…...

形态学操作—闭运算
闭运算(Closing)是图像形态学中的一种操作,它结合了膨胀(Dilation)和腐蚀(Erosion)操作。闭运算的原理是先对图像执行腐蚀操作,然后再进行膨胀操作。这个过程能够消除图像中的小孔洞…...

HEVC-SCC rgb file input
关键字 csc allocateCSCBuffer()-> m_apcPicYuvCSC xCheckRDCostIntraCSC():更简单, enum ACTRDTestTypes { ACT_TWO_CLR 0, //two color space ACT_TRAN_CLR 1, //transformed color space ACT_ORG_CL…...
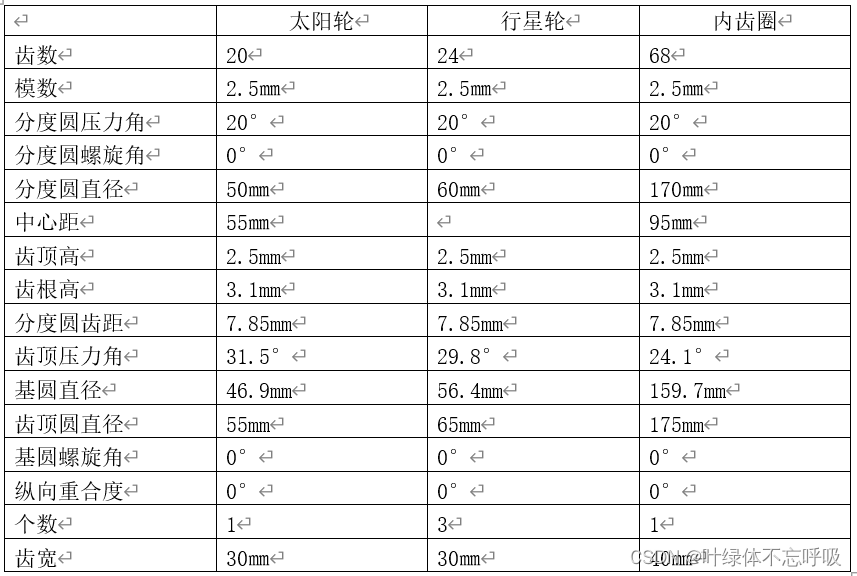
XG916Ⅱ轮式装载机后驱动桥设计机械设计CAD
wx供重浩:创享日记 对话框发送:装载机 获取完整论文报告工程源文件 本次设计内容为XG916Ⅱ装载机后驱动桥设计,大致上分为主传动的设计,差速器的设计,半轴的设计,最终传动的设计四大部分。其中主传动锥齿轮…...
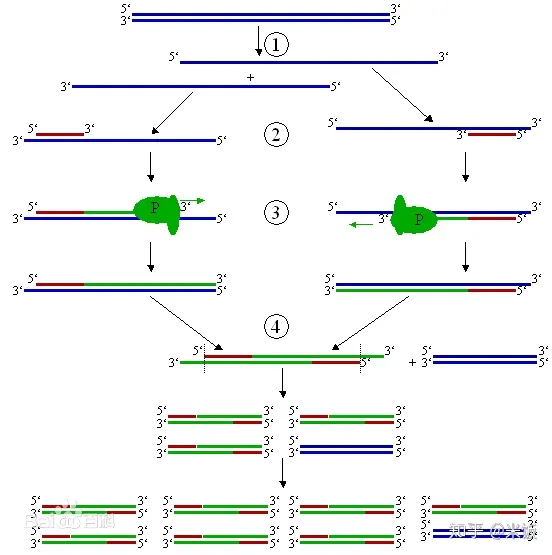
pcr扩增原理中的变性 退火 延申扩增
一、PCR简介 聚合酶链式反应(PCR)是一种用于放大扩增特定的DNA片段的分子生物学技术,它可看作是生物体外的特殊DNA复制,PCR的最大特点是能将微量的DNA大幅增加。 二、PCR原理 1.背景 DNA的半保留复制是生物进化和传代的重要途…...

C语言——输入一个4位正整数,输出其逆数。
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> int main() {int i,j 0;int a1,a2,a3,a4;printf("输入一个4位正整数:\n");scanf("%d",&i);a1 i/1000; a2 i/100%10; a3 i/10%10; a4 i%10; printf("千位a1%d,百位a…...
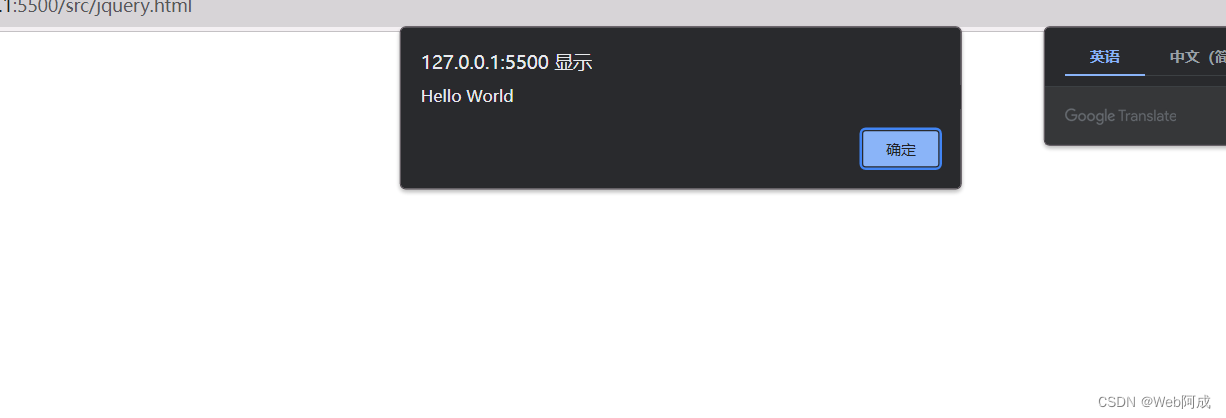
jQuery_02 引入jQuery,初试牛刀
引入jquery文件 我们在官网上点击dowmload那个 会发现进入了一个网页,里面全部是代码,你可能还在想为什么下载不了,其实jquery不跟vue一样,整个jquery就是一个js文件而已,所以直接ctrla 全选 ctrlc复制 ,然…...

pandas获取年月第一天、最后一天,加一秒、加一天、午夜时间
Timestamp对象 # ts = pandas.Timestamp(year=2023, month=10, day=15, # hour=15, minute=5, second=50, tz="Asia/Shanghai") ts = pandas.Timestamp("2023-10-15 15:05:50", tz="Asia/Shanghai") # 2023-10-15 15:05…...
Unsupervised Condition GAN
Unsupervised Condition GAN主要有两种做法: Direct Transformation 直接输入domain X图片,经过Generator后生成对应的domain Y的图像。这种转化input和output不能够差太多。通常只能实现较小的转化,比如改变颜色等。 Projection to Commo…...
HECTF-rsarsa(明文存在线性关系))
Crypto(11)HECTF-rsarsa(明文存在线性关系)
题目如下: from functools import reduce from Crypto.Util.number import * import random from secret import flag,hintdef generate_PQ(bits):x getPrime(bits) >> bits//2 << bits//2#右移bit//2位后左移bit//2位while True:p x random.getran…...

DolphinScheduler Switch组件避坑指南:从配置依赖关系到条件表达式,新手最易踩的3个坑
DolphinScheduler Switch组件实战避坑指南:从表达式陷阱到分支逻辑的深度解析 第一次在DolphinScheduler里拖入Switch组件时,那种"拖拽即完成"的错觉很快就会被现实击碎。我清楚地记得凌晨三点盯着屏幕上那个顽固的红色失败标记,明…...
核心原理与应用实践指南)
大语言模型(LLM)核心原理与应用实践指南
1. 大语言模型入门指南:从零理解LLM的核心原理作为一名长期跟踪自然语言处理技术发展的从业者,我见证了大型语言模型(LLM)如何从实验室走向大众视野。记得2018年第一次接触GPT-2时,需要专门配置计算环境才能运行简化版模型,而今天…...

从康复评估到手势识别:sEMG特征在实际项目里到底怎么选?
从康复评估到手势识别:sEMG特征在实际项目中的选择策略 当你在开发一款基于表面肌电信号(sEMG)的假肢控制系统时,面对RMS、MAV、ZC等十几种特征参数,是否曾陷入选择困难?不同的应用场景对特征的需求差异巨大…...

DNA复制中的酶学:从大肠杆菌到人类,这些酶如何精准合成遗传密码?
DNA复制的分子交响曲:从大肠杆菌到人类的酶协作密码 在显微镜下,DNA复制过程如同一场精密编排的交响乐——数十种酶分子在纳米尺度上协同工作,以每秒上千个碱基的速度合成遗传信息。这场分子芭蕾的每个动作都关乎生命延续的准确性:…...

Mathpix与Simpletex:数学公式识别工具实战横评
1. 数学公式识别工具的选择困境 作为一名经常需要处理数学公式的学生或研究人员,你一定遇到过这样的烦恼:手写笔记需要转为电子版、纸质试卷要整理成文档、论文参考文献中的公式需要引用。传统的手动输入LaTeX或MathType不仅效率低下,还容易出…...

智慧树刷课插件技术解析:自动化学习助手的设计与实现
智慧树刷课插件技术解析:自动化学习助手的设计与实现 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 智慧树刷课插件是一款专为智慧树在线学习平台设计的Ch…...

在STM32F4上用FreeRTOS和LWIP搞个多端口TCP服务器,我踩过的那些坑
STM32F4FreeRTOSLWIP多端口TCP服务器实战避坑指南 去年接手一个工业数据采集项目时,需要基于STM32F407实现同时处理6个端口TCP连接的数据中转服务。本以为用FreeRTOSLWIP组合是稳妥方案,结果从内存泄漏到任务阻塞,踩遍了能想到的所有坑。今天…...
机器学习入门概念)
【机器学习】(一)机器学习入门概念
一、什么是机器学习?机器学习 让计算机从数据里自己学会规律,而不是靠人一行行写死规则。传统编程:人写规则 → 输入数据 → 输出结果机器学习:给数据 给答案 → 机器自己学规则 → 以后自己预测新数据就像教小孩:你…...

B站视频下载终极指南:轻松保存大会员4K高清内容
B站视频下载终极指南:轻松保存大会员4K高清内容 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为无法离线观看B站精彩…...

学习网安-二刷之SSRF
SSRF(服务器端请求伪造)概述SSRF是一种攻击者通过服务器发起恶意请求的安全漏洞,通常用于访问内部系统或绕过防火墙限制。攻击者利用目标服务器作为代理,请求内网资源或第三方服务。SSRF常见利用场景访问内部服务:扫描…...