Redis高并发缓存架构
前言:
针对缓存我们并不陌生,而今天所讲的是使用redis作为缓存工具进行缓存数据。redis缓存是将数据保存在内存中的,而内存的珍贵性是不可否认的。所以在缓存之前,我们需要明确缓存的对象,是否有必要缓存,怎么做好缓存,怎样避免缓存失效。
处理Redis常见问题与提高Redis缓存性能
一、Redis作为缓存常见问题及其处理方案
1)缓存穿透
根源:请求不断的查询一个不存在的key,缓存层和存储层都不会命中。
解决方案:
- 对接口参数进行校验、防止出现恶意攻击;
- 查询不到值时,将value设置成一个标记为加入缓存中,下次再查询就返回一个标记数而不必经过数据库,例如查询id为5的商品,不存在则返回一个-9999,然后在做逻辑判断,但是需要设置一个较短的缓存有效时间,防止以后key对应的value有数据的时候仍然返回空造成错误。
- 使用bitmap类型定义一个可以访问的白名单,id作为偏移量。
- 采用布隆过滤器
2)缓存击穿
根源:缓存击穿是指对于一些设置了过期时间的key,这些key可能在某些时间被超高并发访问,是一种’热点‘数据,然后在这个数据被访问前正好key失效了,那么对这个key的查询会全部转到数据库上,造成数据库压力增大导致卡顿崩溃的现象。
解决方案:
- 设置热点数据永不过期;
- 加锁,大量并发只让一个人去查,其他人等待,直到以后释放锁,其他人读取到锁先查缓存。
3)缓存雪崩
根源:大量的热数据key同时过期,过期之后涌入大量请求,导致请求直接访问数据库,骤增数据库压力。
解决方案:
- 设置热点数据永不过期;
- 将缓存过期时间设置成某一段时间内的随机数,这样就不会同时过期;
- 分布式处理缓存,将缓存存在不同的地方
- 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件
4)缓存与数据不一致问题
1、双写不一致情况(修改数据更新缓存)
线程1先写入了数据库,这时候准备更新缓存,但是因为某原因导致出现延迟,此时线程二快速将新数据写入数据库,并且成功更新了缓存,完事之后线程1恢复了速度开始更新缓存,就导致了线程2是最后写入数据的,但是缓存的内容还是旧值,从而达到双写不一致的错误场景
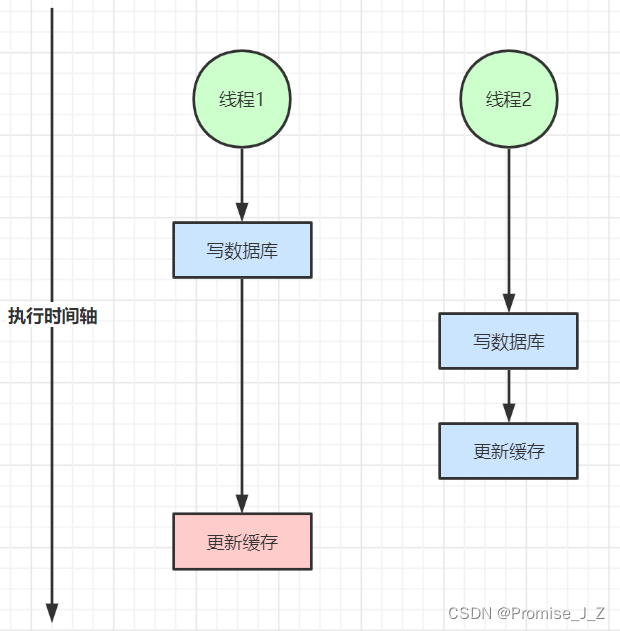
2、读写并发不一致(修改数据删除缓存)
线程一先写入数据10,并删除了缓存,之后线程三读取数据,发现缓存为空,于是去查询数据库,而此时查询数据库的时间较长,与此同时线程二写入数据6,又删除了缓存,在这之后线程三也读成功更新了缓存,造成了数据库的结果是6而缓存的结果是10这种错误情况
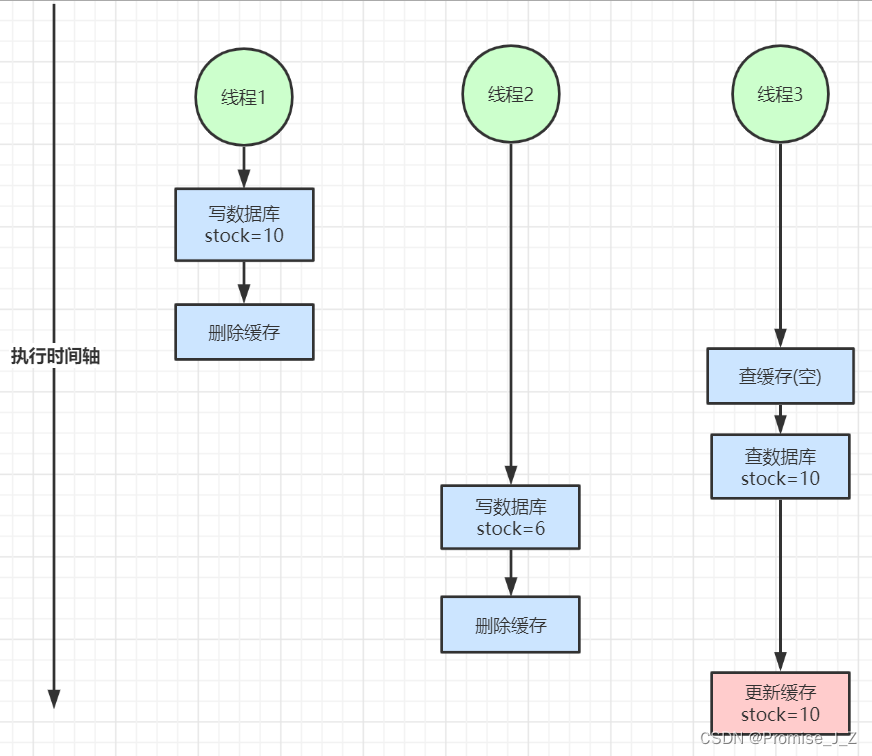
解决方案:
1、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
2、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
3、如果不能容忍缓存数据不一致,可以通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
4、也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。
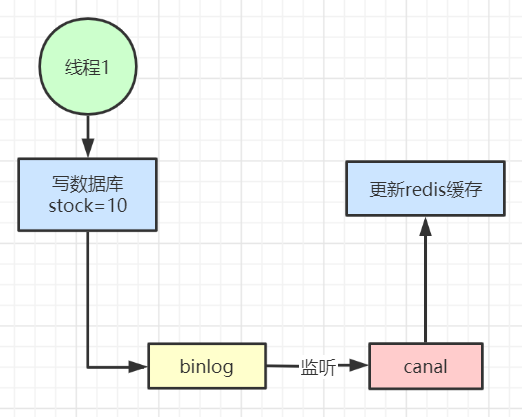
二、针对不同热度的数据采用不同的处理方式
1)热点数据
处理方案:
1、缓存永不过期
2、缓存读延期功能
当命中缓存的时候,设置key的过期时间为默认时间,相当于时间设满,设置过期时间所需要的时间是非常非常少的,对性能的影响也是微乎其微。对于热数据的获取可以实现无线续期的效果
2)冷门数据
处理方案:
针对冷门数据最好不进行缓存,避免内存浪费以及无意义的缓存在过期
基础缓存代码分析
源码与图示
很基础的Redis工具类
@Component
public class RedisUtil {@Autowiredprivate RedisTemplate redisTemplate;public void set(String key, Object value) {redisTemplate.opsForValue().set(key, value);}public void set(String key, Object value, long timeout, TimeUnit unit) {redisTemplate.opsForValue().set(key, value, timeout, unit);}public boolean setIfAbsent(String key, Object value, long timeout, TimeUnit unit) {return redisTemplate.opsForValue().setIfAbsent(key, value, timeout, unit);}public <T> T get(String key, Class<?> T) {return (T) redisTemplate.opsForValue().get(key);}public String get(String key) {return (String) redisTemplate.opsForValue().get(key);}public Long decr(String key) {return redisTemplate.opsForValue().decrement(key);}public Long decr(String key, long delta) {return redisTemplate.opsForValue().decrement(key, delta);}public Long incr(String key) {return redisTemplate.opsForValue().increment(key);}public Long incr(String key, long delta) {return redisTemplate.opsForValue().increment(key, delta);}public void expire(String key, long time, TimeUnit unit) {redisTemplate.expire(key, time, unit);}}代码:
@Service
public class ProductService {@Autowiredprivate ProductDao productDao;@Autowiredprivate RedisUtil redisUtil;@Autowiredprivate Redisson redisson;public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;public static final String EMPTY_CACHE = "{}";public static final String LOCK_PRODUCT_HOT_CACHE_PREFIX = "lock:product:hot_cache:";public static final String LOCK_PRODUCT_UPDATE_PREFIX = "lock:product:update:";//新增数据@Transactionalpublic Product create(Product product) {Product productResult = productDao.create(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);return productResult;}//修改数据@Transactionalpublic Product update(Product product) {Product productResult = null;RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId());RLock writeLock = readWriteLock.writeLock();writeLock.lock();try {productResult = productDao.update(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);} finally {writeLock.unlock();}return productResult;}//读数据方法public Product get(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;//读取缓存中的数据,具体方法实现看源码 getProductFromCacheproduct = getProductFromCache(productCacheKey);if (product != null) {//此处需要和前端进行约定,如果对象的ID为空,则需要提示商品不存在return product;}//DCL 如果存在很高的并发量,导致竞争锁耗时过程可以采用定时阻塞的型式//需要精确预估执行完后面代码所需要的时候,然后将该值设置为过期时间,时间一过线程就可以继续执行RLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId);hotCacheLock.lock();try {//再次尝试从缓存中获取数据,避免其他线程已经读取过db而这边线程又重复读取product = getProductFromCache(productCacheKey);if (product != null) {return product;}//从数据库中读取数据product = productDao.get(productId);//读取到的数据不为空,则将数据存入redis中。if (product != null) {redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);} else {//当数据为空,则存入一个特俗字符,代表空数据,避免缓存穿透//针对特俗key使用较短的过期时间,可以避免短时间黑客反复攻击,看能避免长时间造成的内存浪费redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);}} finally {hotCacheLock.unlock();}return product;}//从缓存中读取数据private Product getProductFromCache(String productCacheKey) {Product product = null;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {//未查询到数据,需要设置一个空对象返回,并设置较短的过期时间redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return new Product();}//如果真是查询到数据,设置读延期product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期}return product;}//设置较长的过期时间private Integer genProductCacheTimeout() {return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60;}//设置较短的过期时间private Integer genEmptyCacheTimeout() {return 60 + new Random().nextInt(30);}}良好的Redis使用习惯
一、键值设计
1)key名设计
- (1)【建议】: 可读性和可管理性
以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如业务名:表名:id
trade:order:1
- (2)【建议】:简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视,例如:
user:{uid}:friends:messages:{mid} 简化为 u:{uid}:fr:m:{mid}
- (3)【强制】:不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
2) value设计
(1)【强制】:拒绝bigkey(防止网卡流量、慢查询)
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,但实际中如果下面两种情况,我就会认为它是bigkey。
- 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
- 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
反例:一个包含200万个元素的list。
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞)
bigkey的危害:
1.导致redis阻塞
2.网络拥塞
bigkey也就意味着每次获取要产生的网络流量较大,假[[设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例也造成影响,其后果不堪设想。
3.过期删除
有个bigkey,它安分守己(只执行简单的命令,例如hget、lpop、zscore等),但它设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
bigkey的产生:
一般来说,bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
(1) 社交类:粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
(2) 统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
(3) 缓存类:将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需要注意,第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
优化bigkey
1. 拆
- big list: list1、list2、...listN
- big hash:可以讲数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
- 如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall),删除也是一样,尽量使用优雅的方式来处理。
(2)【推荐】:选择适合的数据类型。
例如:实体类型(要合理控制和使用数据结构,但也要注意节省内存和性能之间的平衡)
反例:
set user:1:name tom set user:1:age 19 set user:1:favor football
正例:
hmset user:1 name tom age 19 favor football
(3)【推荐】:控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期)。
二、命令使用
1. O(N)命令关注N的数量
例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
2.:禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
3.合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
4.使用批量操作提高效率
原生命令:例如mget、mset。 非原生命令:可以使用pipeline提高效率。
但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
注意两者不同:
1. 原生命令是原子操作,pipeline是非原子操作。 2. pipeline可以打包不同的命令,原生命令做不到 3. pipeline需要客户端和服务端同时支持。
5.Redis事务功能较弱,不建议过多使用,可以用lua替代
三、客户端处理
1.避免多个应用使用一个Redis实例
正例:不相干的业务拆分,公共数据做服务化。
2.使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式:
1 JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
2 jedisPoolConfig.setMaxTotal(5);
3 jedisPoolConfig.setMaxIdle(2);
4 jedisPoolConfig.setTestOnBorrow(true);
5
6 JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.0.60", 6379, 3000, null);
7
8 Jedis jedis = null;
9 try {
10 jedis = jedisPool.getResource();
11 //具体的命令
12 jedis.executeCommand()
13 } catch (Exception e) {
14 logger.error("op key {} error: " + e.getMessage(), key, e);
15 } finally {
16 //注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
17 if (jedis != null)
18 jedis.close();
19 }连接池参数含义:
序号
参数名
含义
默认值
使用建议
1
maxTotal
资源池中最大连接数
8
设置建议见下面
2
maxIdle
资源池允许最大空闲的连接数
8
设置建议见下面
3
minIdle
资源池确保最少空闲的连接数
0
设置建议见下面
4
blockWhenExhausted
当资源池用尽后,调用者是否要等待。只有当为true时,下面的maxWaitMillis才会生效
true
建议使用默认值
5
maxWaitMillis
当资源池连接用尽后,调用者的最大等待时间(单位为毫秒)
-1:表示永不超时
不建议使用默认值
6
testOnBorrow
向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除
false
业务量很大时候建议设置为false(多一次ping的开销)。
7
testOnReturn
向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除
false
业务量很大时候建议设置为false(多一次ping的开销)。
8
jmxEnabled
是否开启jmx监控,可用于监控
true
建议开启,但应用本身也要开启
优化建议:
1)maxTotal:最大连接数,早期的版本叫maxActive
实际上这个是一个很难回答的问题,考虑的因素比较多:
- 业务希望Redis并发量
- 客户端执行命令时间
- Redis资源:例如 nodes(例如应用个数) * maxTotal 是不能超过redis的最大连接数maxclients。
- 资源开销:例如虽然希望控制空闲连接(连接池此刻可马上使用的连接),但是不希望因为连接池的频繁释放创建连接造成不必靠开销。
以一个例子说明,假设:
- 一次命令时间(borrow|return resource + Jedis执行命令(含网络) )的平均耗时约为1ms,一个连接的QPS大约是1000
- 业务期望的QPS是50000
那么理论上需要的资源池大小是50000 / 1000 = 50个。但事实上这是个理论值,还要考虑到要比理论值预留一些资源,通常来讲maxTotal可以比理论值大一些。
但这个值不是越大越好,一方面连接太多占用客户端和服务端资源,另一方面对于Redis这种高QPS的服务器,一个大命令的阻塞即使设置再大资源池仍然会无济于事。
2)maxIdle和minIdle
maxIdle实际上才是业务需要的最大连接数,maxTotal是为了给出余量,所以maxIdle不要设置过小,否则会有new Jedis(新连接)开销。
连接池的最佳性能是maxTotal = maxIdle,这样就避免连接池伸缩带来的性能干扰。但是如果并发量不大或者maxTotal设置过高,会导致不必要的连接资源浪费。一般推荐maxIdle可以设置为按上面的业务期望QPS计算出来的理论连接数,maxTotal可以再放大一倍。
minIdle(最小空闲连接数),与其说是最小空闲连接数,不如说是"至少需要保持的空闲连接数",在使用连接的过程中,如果连接数超过了minIdle,那么继续建立连接,如果超过了maxIdle,当超过的连接执行完业务后会慢慢被移出连接池释放掉。
如果系统启动完马上就会有很多的请求过来,那么可以给redis连接池做预热,比如快速的创建一些redis连接,执行简单命令,类似ping(),快速的将连接池里的空闲连接提升到minIdle的数量。
连接池预热示例代码:
List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle()); 2 3 for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) { 4 Jedis jedis = null; 5 try { 6 jedis = pool.getResource(); 7 minIdleJedisList.add(jedis); 8 jedis.ping(); 9 } catch (Exception e) { 10 logger.error(e.getMessage(), e); 11 } finally { 12 //注意,这里不能马上close将连接还回连接池,否则最后连接池里只会建立1个连接。。 13 //jedis.close(); 14 } 15 } 16 //统一将预热的连接还回连接池 17 for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) { 18 Jedis jedis = null; 19 try { 20 jedis = minIdleJedisList.get(i); 21 //将连接归还回连接池 22 jedis.close(); 23 } catch (Exception e) { 24 logger.error(e.getMessage(), e); 25 } finally { 26 } 27 }总之,要根据实际系统的QPS和调用redis客户端的规模整体评估每个节点所使用的连接池大小。
3.高并发下建议客户端添加熔断功能(例如sentinel、hystrix)
4.设置合理的密码,如有必要可以使用SSL加密访问
5.Redis对于过期键有三种清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期(默认每100ms)主动淘汰一批已过期的key,这里的一批只是部分过期key,所以可能会出现部分key已经过期但还没有被清理掉的情况,导致内存并没有被释放
- 当前已用内存超过maxmemory限定时,触发主动清理策略
主动清理策略在Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略,总共8种:
a) 针对设置了过期时间的key做处理:
- volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
b) 针对所有的key做处理:
- allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
- allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
c) 不处理:
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作。
LRU 算法(Least Recently Used,最近最少使用)
淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
LFU 算法(Least Frequently Used,最不经常使用)
淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。这时使用LFU可能更好点。
根据自身业务类型,配置好maxmemory-policy(默认是noeviction),推荐使用volatile-lru。如果不设置最大内存,当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap),会让 Redis 的性能急剧下降。
当Redis运行在主从模式时,只有主结点才会执行过期删除策略,然后把删除操作”del key”同步到从结点删除数据。
相关文章:
Redis高并发缓存架构
前言: 针对缓存我们并不陌生,而今天所讲的是使用redis作为缓存工具进行缓存数据。redis缓存是将数据保存在内存中的,而内存的珍贵性是不可否认的。所以在缓存之前,我们需要明确缓存的对象,是否有必要缓存,怎…...

谨防利用Redis未授权访问漏洞入侵服务器
说明: Redis是一个开源的,由C语言编写的高性能NoSQL数据库,因其高性能、可扩展、兼容性强,被各大小互联网公司或个人作为内存型存储组件使用。 但是其中有小部分公司或个人开发者,为了方便调试或忽略了安全风险&#…...

关于一些bug的解决1、el-input的输入无效2、搜索之后发现数据不对3、el多选框、单选框点击无用4、
el-input输入无效 原来的代码是 var test null 但是我发现不能输入任何值 反倒修改test的初始值为123是可以的 于是我确定绑定没问题 就是修改的问题 于是改成 var test ref() v-model绑定的值改成test.value就可以了 因为ref是相应式的 可以通过输入…...

使用 JavaScript 进行 API 测试的综合教程
说明 API 测试是软件测试的一种形式,涉及直接测试 API 并作为集成测试的一部分,以确定它们是否满足功能、可靠性、性能和安全性的预期。 先决条件: JavaScript 基础知识。Node.js 安装在您的计算机上。如果没有,请在此处下载。npm…...
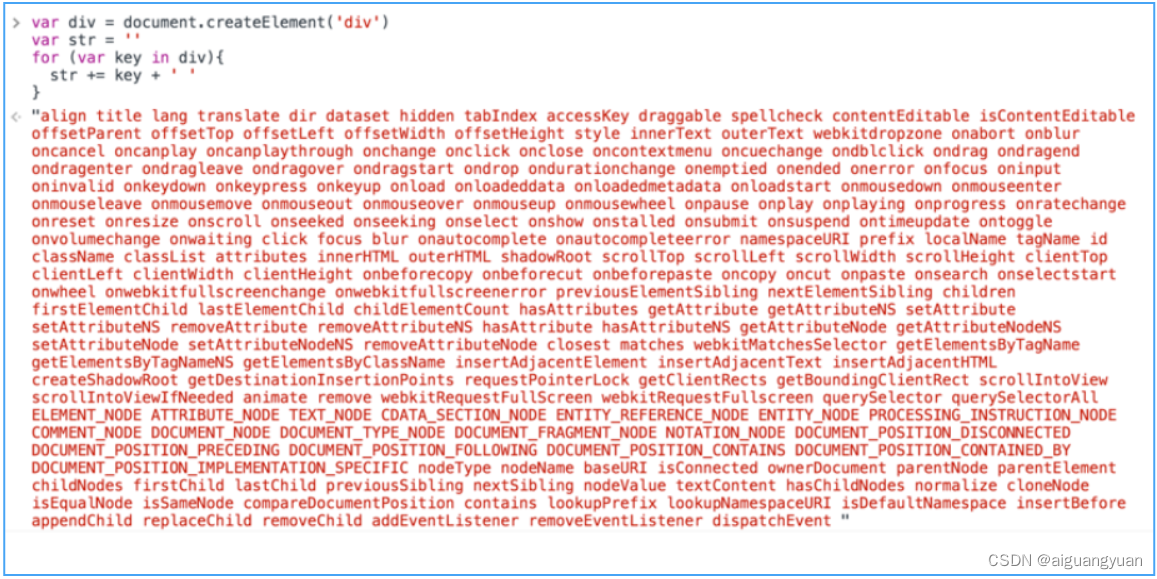
Vue 2.0源码分析-Virtual DOM
Virtual DOM 这个概念相信大部分人都不会陌生,它产生的前提是浏览器中的 DOM 是很“昂贵"的,为了更直观的感受,我们可以简单的把一个简单的 div 元素的属性都打印出来,如图所示: 可以看到,真正的 DOM …...
freeRTOS移植STMF103)
(HAL库版)freeRTOS移植STMF103
正点原子关于freeRTOS的教程是比较好的,可惜移植的是标准库,但是我学的是Hal库,因为开发速度更快,从最后那个修改SYSTEM文件夹的地方开始替换为下面的内容就可以了 5.修改Systick中断、SVC中断、PendSV中断 将SVC中断、P…...

vue2-axios
下载axios 开发版本:axios.js 生产版本:axios.min.js 搭建服务器:json-server npm i -g json-serverjson-server --watch db.json(启动服务并读取文件,db.json文件目录下启动) json-server --watch db.j…...
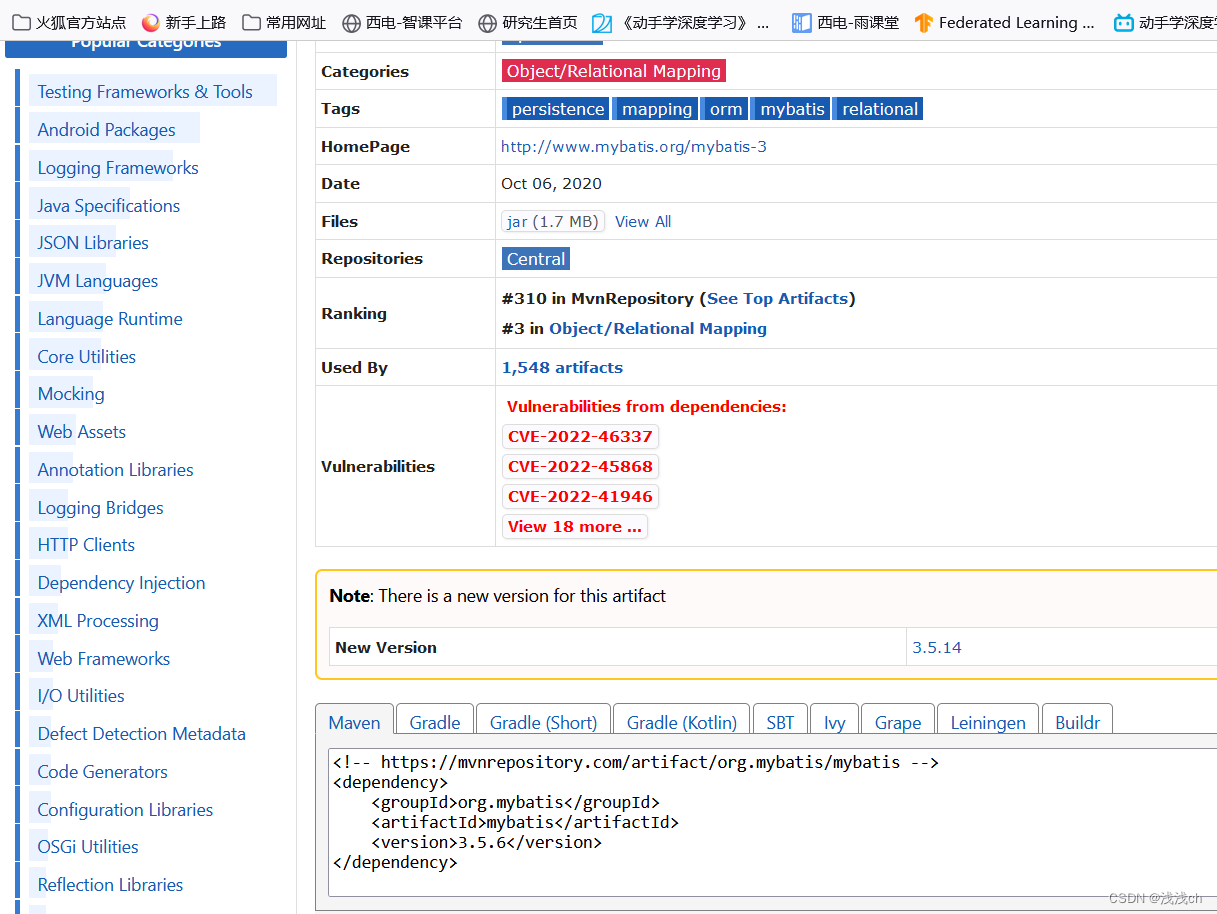
创建maven的web项目
(一)创建maven的web项目 Step1、创建一个普通的maven项目 (1)新建一个empty project,命名为SSM2。 点击项目名,右键new,选择Module,左侧选择“Maven archetype”,可以给…...

使用uniapp开发系统懒加载图片效果
1、创建一个Vue组件 在uniapp项目中,我们可以创建一个独立的Vue组件来实现懒加载图片效果。打开uniapp项目,进入components文件夹,创建一个名为"LazeImage"的组件。 2、编写组件模板 在"LazeImage"组件中,…...

导入PIL时报错
在导入PIL时,报以下错误: 查找原因 参考博客 Could not find a version that satisfies the requirement PIL (from versions: ) No matching distributi-CSDN博客,按照wheel后,安装PIL时,报如下的错误。 查找说是python版本与wheel文件版本不同,确认本机python版本 …...
MyBatis Generator 插件 详解自动生成代码
MyBatis Generator(MBG)是MyBatis和iBATIS的代码生成器。可以生成简单CRUD操作的XML配置文件、Mapper文件(DAO接口)、实体类。实际开发中能够有效减少程序员的工作量,甚至不用程序员手动写sql。 它将为所有版本的MyBatis以及版本2.2.0之后的i…...

SkyWalking全景解析:从原理到实现的分布式追踪之旅
🎏:你只管努力,剩下的交给时间 🏠 :小破站 SkyWalking全景解析:从原理到实现的分布式追踪之旅 前言第一:SkyWalking简介第二:实现原理概览第三:主键与架构第四࿱…...

新手如何买卖可转债,可转债投资基础入门
一、教程描述 什么是可转债?可转债是可转换债券的二次简称,原始全称是可转换公司债券,这是一种可以在特定时间、按特定条件,转换为普通股票的特殊企业债券,可转换债券兼具债权和股权的特征,其英文为conver…...

研习代码 day39 | 动态规划——完全背包的应用
一、爬楼梯(进阶版) 1.1 题目 题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬至多m (1 < m < n)个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 输入描述 输入共一…...
 - 流控制语句)
Rust语言入门教程(五) - 流控制语句
if 表达式 在Rust中, if语句的判断条件不需要用( )括起来, 它会认为所有在if 和 {之间的表达式就是判断条件,例如: if num 5 {msg "five"; }判断条件的表达式必须返回一个bool型的值, 因为Rust是一个不喜…...

字符串:leetcode1410. HTML 实体解析器
1410. HTML 实体解析器 「HTML 实体解析器」 是一种特殊的解析器,它将 HTML 代码作为输入,并用字符本身替换掉所有这些特殊的字符实体。 HTML 里这些特殊字符和它们对应的字符实体包括: 双引号:字符实体为 " ÿ…...
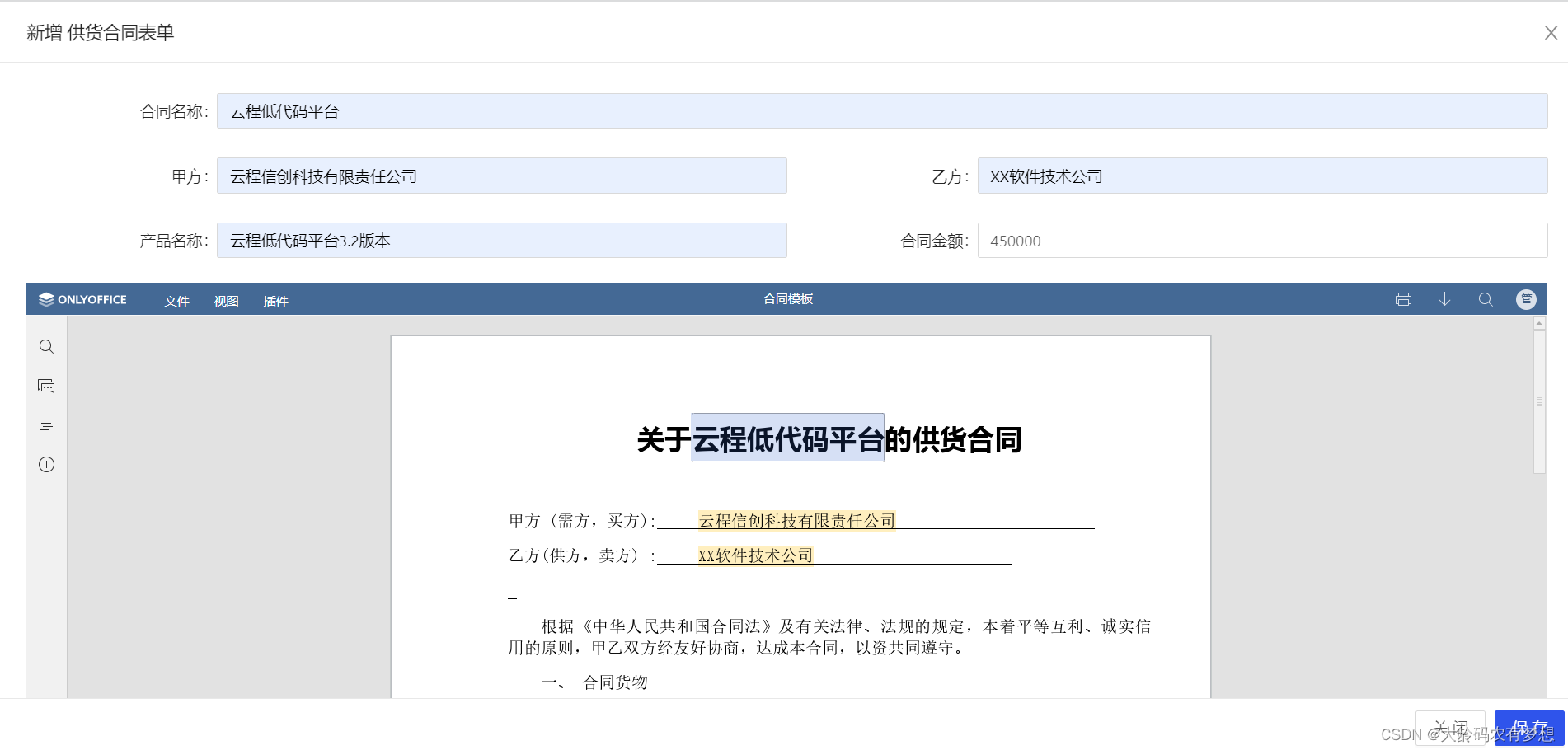
springboot+vue项目如何集成onlyoffice开源文档组件
一、onlyoffice是什么 ONLYOFFICE 是一个开源的办公套件,适合多人在线协作。由总部位于总部在拉脱维亚的 IT 公司Acensio System SIA 开发。它提供在线协作文档编辑器(包括文档、电子表格、演示文稿和表单),适用于 Windows、Linu…...

Android okhttp3.0配置https信任所有证书
参考: Android okhttp3.0配置https的自签证书和信任所有证书 private OkHttpClient getHttpsClient() {OkHttpClient.Builder okhttpClient new OkHttpClient().newBuilder();//信任所有服务器地址okhttpClient.hostnameVerifier(new HostnameVerifier() {Overridepublic boo…...
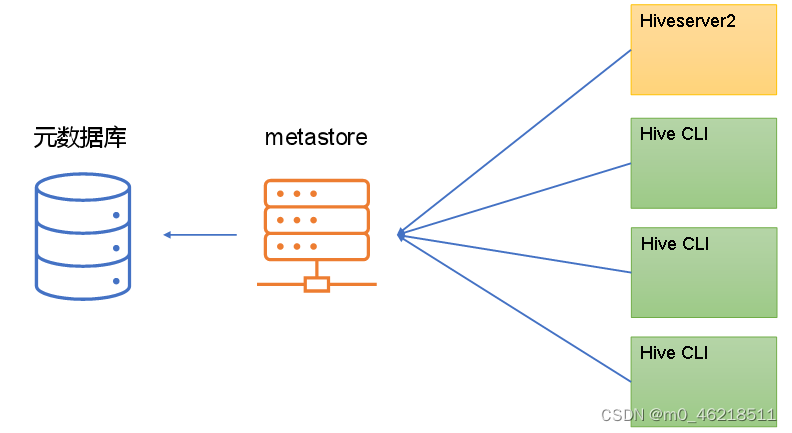
大数据基础设施搭建 - Hive
文章目录 一、上传压缩包二、解压压缩包三、配置环境变量四、初始化元数据库4.1 配置MySQL地址4.2 拷贝MySQL驱动4.3 初始化元数据库4.3.1 创建数据库4.3.2 初始化元数据库 五、启动元数据服务metastore5.1 修改配置文件5.2 启动/关闭metastore服务 六、启动hiveserver2服务6.1…...
手把手教你安装 Visual Studio 2022 及其简单使用
软件下载 打开 Visual Studio 官网,个人选择免费的Community社区版就够用了。 软件安装 双击运行安装程序: 点击继续 即可: 等待加载完成: 可以看到 Visual Studio 2022 对应不同的开发需求提供了若干工作负载,这里以…...

为FLUX.1-Krea-Extracted-LoRA 构建Web界面:JavaScript前端交互开发指南
为FLUX.1-Krea-Extracted-LoRA构建Web界面:JavaScript前端交互开发指南 1. 项目概述与准备工作 FLUX.1-Krea-Extracted-LoRA是一种轻量化的图像生成模型,通过星图GPU平台部署后,需要一个直观的Web界面来简化用户操作。我们将使用现代JavaSc…...

OCAD应用:利用OCAD进行一般光学系统的设计
填写完对光学系统的设计技术要求之后就可以在窗体右侧的绘图框内绘制光学系统方案草图。绘图框的基本尺寸默认为一张横排的A4图纸。如果根据系统总体尺寸的要求需要调整绘图框图纸图幅的尺寸,可以利用界面是文字框从 “图幅选择”中选择,点击“图幅选择”…...

告别盲调!用CubeMX图形化配置STM32F4时钟树,并自动生成HAL代码
图形化配置STM32F4时钟树的实战指南:从CubeMX到代码生成 第一次接触STM32的时钟树配置时,我盯着参考手册里密密麻麻的时钟路径图和一堆分频系数发愣。作为从51单片机转过来的开发者,这种复杂度让我一度想放弃HAL库。直到发现了CubeMX这个神器…...

机器人协议设计核心:架构、安全与性能优化
1. 机器人协议设计概述在自动化系统开发领域,机器人协议(Bot Protocol)是决定系统间通信质量和效率的核心要素。一个设计良好的机器人协议需要兼顾可扩展性、安全性和易用性,就像为不同语言使用者设计一套通用交流规则。我在金融交…...

1688商品详情API应用之无货源铺货 SAAS:合规采集、多平台一键上架、SKU / 库存 / 价格自动同步
1688商品详情接口:item_get,item_get_pro通过商品id获取商品详情信息,包括商品标题、价格、url,商品主图、详情图,sku信息等。公共参数名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中&#…...

从YOLOv1到v3全解析:原理演进+PyTorch实战训练(超详细
YOLO(You Only Look Once)作为单阶段目标检测的开山之作,凭借速度快、端到端、工程友好的优势,成为实时检测领域的标配算法。本文从v1→v2→v3梳理核心演进逻辑,并手把手带你用YOLOv3完成自定义数据集训练,…...

三、vs code快捷键
1.设置Ctrl,2.还原整个窗口布局命令面板 Ctrl Shift P → 输入 View: Reset View Locations → 回车,所有面板回归默认位置。...

告别Keil/IAR:用Ozone+J-Trace调试STM32F407,这些隐藏功能真香了
从Keil到Ozone:STM32F407VG调试效率的全面升级 调试嵌入式系统时,传统IDE如Keil和IAR已经无法满足现代开发对效率和深度的需求。当我第一次尝试将STM32F407VG项目迁移到OzoneJ-Trace组合时,那种"降维打击"般的调试体验彻底改变了我…...

用像素语言·跨维传送门,5步搭建你的专属多语言翻译像素工坊
用像素语言跨维传送门,5步搭建你的专属多语言翻译像素工坊 1. 像素冒险工坊初探 1.1 打破次元壁的翻译体验 像素语言跨维传送门(Pixel Language Portal)彻底颠覆了传统翻译工具的刻板印象。这款基于腾讯混元MT-7B引擎的翻译终端࿰…...
TranslucentTB开机自启动终极指南:彻底告别手动启动的烦恼
TranslucentTB开机自启动终极指南:彻底告别手动启动的烦恼 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 还在为每次开机都要…...