NLP学习
参考:NLP发展之路I - 从词袋模型到Transformer - 知乎 (zhihu.com)
NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。
NLP技术,全称为Natural language Processing,即自然语言处理技术,也就是用计算机来处理人类语言的学科。
这一时期最有代表性的方法是词袋模型(Bag of Words, or BOW),即统计文章中每个词出现的频率,然后对这个频率的向量进行各种各样的统计分析。比如可以根据正向词汇和负向词汇在文中出现的频率对比,来判断文章的情感倾向。或者用词频向量去训练一个分类器,做文本分类任务。

词袋模型是一个简单有效的办法。即使在普遍使用深度学习的今天,这个方法仍有时候被作为快速验证或比较基准来使用。
词频向量实际上是将人类语言翻译成了一种机器能看懂的方式,有两项信息损失最为突出:第一个是词袋模型中,每个词都是独立的,没有相对的语义关系,无法使用词与词之间的关联来更好地帮助分析。第二个是词袋模型完全忽视了语序信息。例如,“我,很不好”和“不,我很好”两句的词频向量完全相同,但语义却相反。
不过在深度学习出现之后,这两个问题都得到了解决。
WordEmbedding: 深度学习解决语义问题
2012年,深度学习在ImageNet比赛中碾压了其它传统的机器学习方法,拉开了划时代的大幕。
深度学习无需手写任何规则,而是依赖大量的数据进行训练。简单来说,深度学习,也就是神经网络,是通过给模型看大量的数据,并对每次模型输出的结果与正确答案比对,让模型自己慢慢调整到正确的方向。由于神经网络的参数远多于一般机器学习模型,在较大数据量的训练下,可以对数据中复杂的隐含的关系进行更精确的建模,因此能够实现其他方法达不到的准确度。
2013年,谷歌的研究员Mikolov使用神经网络训练了词向量(word embedding,有些文献又称“词嵌入”,但还是“词向量”更直观一些)。研究者使用一个简单的一层全连接的神经网络,通过“给出一句话的上文,让模型去预测下一个词”的方式去训练。在看过了大量文章之后,这个神经网络便可将语言中隐含的语义信息”记“在自己的参数中。比如“我想喝一杯”,后文是“水”或是”茶“的概率差不多,那么模型对这两个词的参数也会差不多,即输出的的词向量也是相似的。这样,模型便学会了同义词。
词向量的一个重要性质就是,这个向量在高维空间中的位置关系即可代表语义的关系。比如相似的词可能会聚拢在一起,甚至“法国“与”巴黎”的距离和”英国”与”伦敦”之间的距离都是相似的。
Word2Vec词向量可以抓住不同词之间的相对语义关系 (source: NCAA word2vec lecture notes)
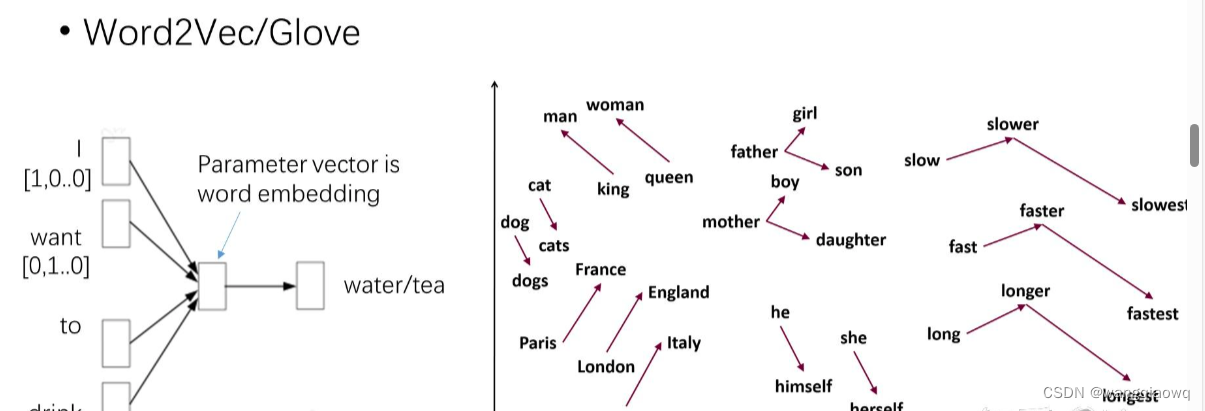
这种给模型喂上文,让模型去预测下文的训练方式,被称为Language Modeling,也就是语言模型或语言建模。这种训练方式不需要人工标注,模型结果可以直接和原文对比,从而能够利用到海量的数据。这种语言建模的方法后面还会一次又一次地被用到,目前实现技术突破的大语言模型也是应用此方法。
RNN: 循环神经网络解决语序问题
语义的问题解决之后,RNN的出现又解决了语序问题。
全连接神经网络是最简单的神经网络模型,在此之上又发展出两类主要的变体,一个是卷积神经网络(Convolutional Neural Network, or CNN) 和循环神经网络(Recurrent Neural Network, or RNN) 。CNN的输入采用滑动一个固定窗口的方式,每次只考虑附近的信息,适合处理图像问题,能做到又快又好。而RNN的输入是按顺序一个一个接收的,在处理完上一个信息之后才会处理下一个信息,天然是阅读文章的一把好手。
LSTM(RNN的一种模型)示意图 (source: Modeling Genome Data Using Bidirectional LSTM)
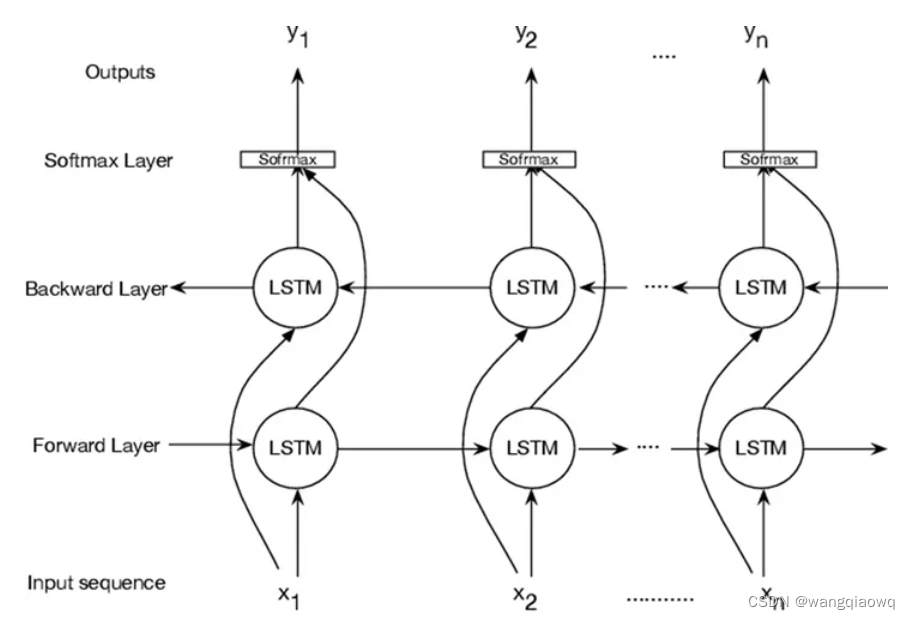
使用词向量(语义)+RNN(语序)的方法成为这一时期的王者,在各项NLP通用任务上表现颇为亮眼。
研究者们在这一时期的主要工作是在词向量+RNN的基本思想上,对网络架构进行各种各样的改动,用叠加各种buff方式来提升模型的表现。
词向量+RNN这样的NLP已经相对比较接近人脑处理语言的方式了。然而还是有一个显著的缺陷,那就是无法像人一样根据上下文处理多义词的含义。由于词向量的训练方式,每个词只能有一个固定的词向量。如果一个词有两个同样常用的,但毫不相关的含义,那么这个词向量在高维空间内只能处于这两个位置的中间点,实际效果就是两边都没法准确建模。
语言模型解决上下文问题
ELMo的作者大开脑洞,谁说没法处理上下文含义啊,语言模型不就是一个天然的、考虑了上下文的模型吗?当RNN一个一个吸收完前文,再吐出来的最后一个词,这个输出显然已经是包含了上文信息的。于是ELMo的作者训练了一个双向的LSTM模型(LSTM是RNN的一种)。这个模型通过把文章从前往后读一遍,再从后往前读一遍,来接收上文和下文的信息。然后作者将这个过程中的三层输出进行组合,就变成了ELMo词向量(Embeddings from Language Models)从此,我们把文本放进ELMo模型里,拿到的输出就可以作为词向量使用。而每次的输入句子不同时,即使同一个词的词向量也会有所不同,因为ELMo的输出是考虑到了整个句子的信息的。
LSTM(Long Short-Term Memory,长短期记忆)是一种特殊的循环神经网络(RNN),它被广泛用于解决一些与序列和时序相关的深度学习问题。传统的RNN在处理长序列时,会出现梯度消失或梯度爆炸的问题,这使得它们无法有效地记住序列中的长期依赖关系。为了解决这个问题,LSTM被设计出来。
LSTM的核心思想是通过引入一种称为“门”的机制来控制信息的流动。它有三个主要的门:输入门、遗忘门和输出门。这些门可以学习在何时让信息进入、何时让信息保留、何时让信息输出,从而有效地解决了长期依赖的问题。
具体来说,LSTM的工作流程如下:
- 遗忘门:这个门决定上一时刻的单元状态有多少保留到当前时刻。它会读取上一时刻的输出和当前时刻的输入,然后通过一个sigmoid函数输出0到1之间的数值,表示保留的比例。
- 输入门:这个门决定当前时刻网络的输入有多少保存到单元状态。首先,一个sigmoid函数决定哪些值需要更新,然后一个tanh函数生成新的候选值,这些新的候选值可以被添加到状态中。
- 单元状态:这个状态负责在网络中传递信息。首先,我们将上一时刻的状态和遗忘门的输出相乘,丢弃不需要的信息。然后,将输入门的输出和候选值相乘,添加到状态中。这样,我们就得到了新的单元状态。
- 输出门:这个门决定单元状态有多少输出到LSTM的当前输出值。首先,一个sigmoid函数决定哪些部分的状态需要输出,然后将单元状态通过tanh函数进行处理(得到一个在-1到1之间的值),并将它和sigmoid函数的输出相乘,最终得到LSTM的输出。
通过这种方式,LSTM可以选择性地记住或遗忘序列中的信息,从而可以有效地处理具有长期依赖关系的序列数据。这使得LSTM在许多任务中都取得了很好的效果,例如语音识别、自然语言处理(NLP)、时间序列预测等。
Elmo的三层组合词向量 (source: Analytics Vidhya)
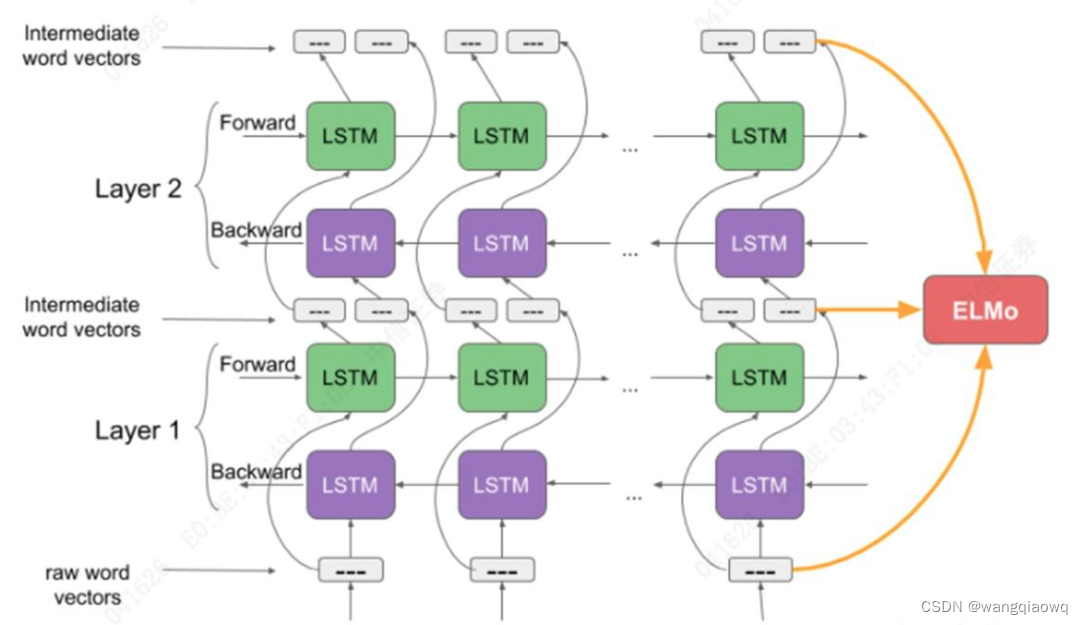
语义解决了,语序解决了,甚至上下文含义也解决了。从思想上看,这时NLP模型越来越接近人类处理语言的方式。RNN需要一个词一个词地处理,在处理大数据时,这个时间差异就十分巨大。RNN的长期记忆还不太好。因为RNN把信息存储在一个固定纬度的向量里,就好比一个打包盒,每多加一个词,就往这个打包盒里压缩一次。到输出层,需要把这个打包盒打开、找到相关的信息的时候,恐怕最开始输入的信息都已经被压缩得面目全非了,很难解码。
Transformer大幅提升效果
2018年,本世纪NLP界最大的外挂诞生了。这就是Transformer。
先说一下注意力机制(attention)
人们发现如果能让输入和输出直接建立一个连接,让模型去学习特定的目标词应该更关注哪些输入词,而不是只从RNN压缩的打包盒里解码,会非常好地提升翻译的表现。attention被作为一种增强手段,用在循环或卷积神经网络上。其中一个重要的点是,attention能非常有效地解决RNN长期记忆不好的缺点,输入序列的任何两个词之间都有联系关系,真正实现了“天涯若比邻”。
**Attention(注意力机制)**是深度学习中的一个重要概念,它的核心思想是在处理复杂数据时,允许模型集中关注于最相关的部分,而忽视其他不太相关的信息。
在深度学习的上下文中,特别是在处理序列数据(如文本、时间序列等)时,注意力机制允许模型在处理一个序列的元素时,将更多的“注意力”放在与该元素更相关的其他元素上。这使得模型可以更有效地处理长序列,并捕获序列中的长期依赖关系。
注意力机制的实现方式有很多种,但大多数都涉及到计算一个权重分布,这个分布决定了在处理一个序列的元素时,应该如何关注其他元素。这个权重分布通常是通过计算元素之间的相似性或相关性得到的。
自注意力机制(Self-Attention)是注意力机制的一种特殊形式,它允许模型在处理一个序列时,关注该序列中的其他位置。自注意力机制的一个关键优点是它能够捕获序列中的长期依赖关系,而且它的计算复杂度不随序列长度的增加而线性增长,这使得它能够更有效地处理长序列。
Transformer模型就是完全基于自注意力机制的深度学习架构,它在NLP领域取得了很好的效果。在Transformer中,注意力和前馈神经网络是其主要的构成部分,而传统的RNN和CNN结构被完全摒弃。
总的来说,注意力机制是一种强大的工具,它允许深度学习模型更有效地处理复杂数据,特别是序列数据。
Transformer的创新之处在于,将attention的输入与输出之间的连接,变为输入与输入自己的连接,这相当于在做任务时,把每个词都在上下文的语境中理解一次。作者称为自注意力机制(self-attention)。使用时将语义信息(词向量)和语序信息(序号)作为输入。由于自注意力模型之下词与词之间的联系变得很直接,这种模型能更好地编码输入的上下文信息,训练的反馈也能得到很好的传导。
Transformer的另一个厉害之处在于它可以毫无压力地进行并行计算。虽然它的计算量相比RNN大大增加了,但由于可以并行计算,在拥有足够算力的情况下,需要的时间反而变少了。
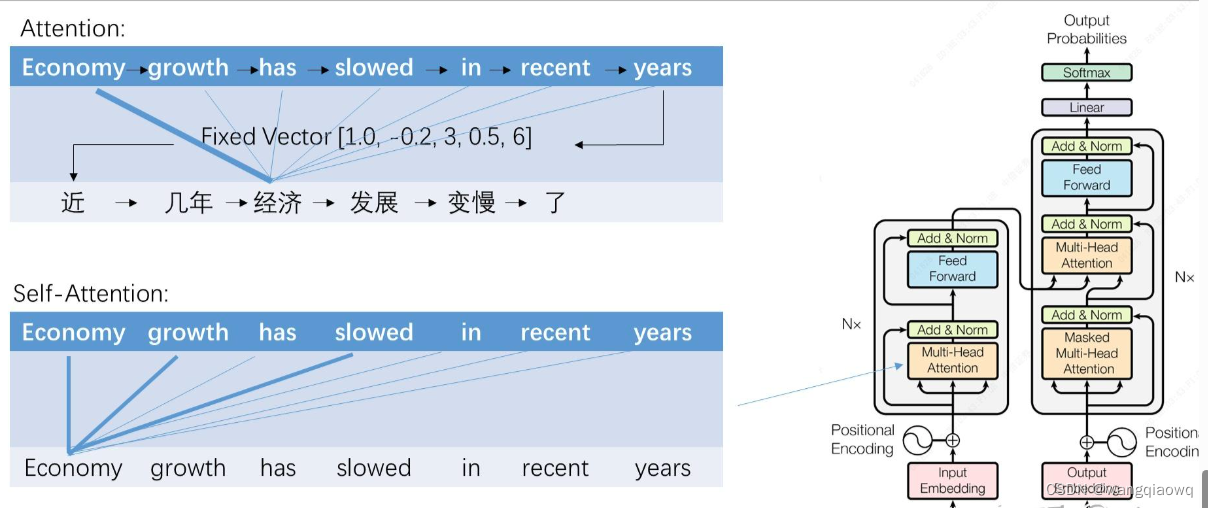
Transformer出现之后,由于效果太好,大家几乎完全抛弃了其他的架构。如果说RNN时代是百花齐放的春秋战国,Transformer就是秦王扫六合,一举统一了整个NLP模型江湖。Transformer的性能使整个NLP界从蒸汽时代迈入了内燃机时代,也使得后续效果超群的大模型的出现成为可能。
参考:NLP发展之路II - 从BERT到ChatGPT - 知乎 (zhihu.com)
预训练-微调时代
2018年,BERT和初代GPT几乎在同一时间出现。BERT由谷歌开发,GPT由OpenAI开发
首先,它们都采用了Transformer,甚至层数也相同。
其次,它们都使用了当时几乎所有开源的、较高质量的NLP数据,如wikipedia, 书籍等。
最后,它们的训练方法都是语言建模Language Modeling,即给模型输入上文,令其预测下文的方法。从而可以使用大量文本而无需人工标注。
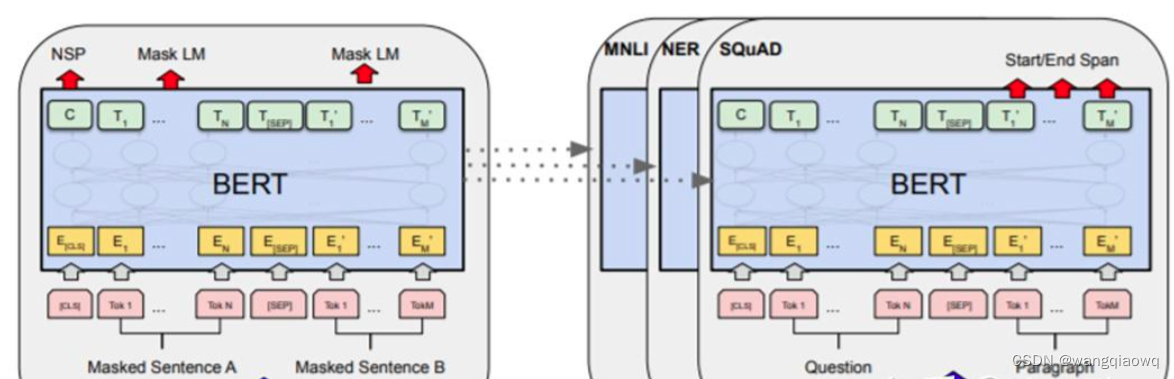
BERT和GPT的参数量大约在亿级,在当时已经是从未出现过的“大模型”了。加上使用了当时可获得的几乎所有高质量文本数据训练,研究者发现,这两个模型在大量数据中学到了对语言的基本理解和一些通用的世界知识,并且将这些知识被储存在模型的参数中。有了这样的“义务教育”打底,在此基础上,只需针对各个专业下游任务(如情感分析、对话生成)进行一个小范围的基于监督学习的微调,比如只调整模型最后一层的参数,居然可以打败很多专门针对这些任务开发的模型。这就是‘’预训练-微调‘’模式。
BERT的预训练模型可以用来做不同的下游任务 (source: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
GPT是一个单向模型。OpenAI采用标准的Language Modeling方式进行训练,模型根据上文来推测下文。
BERT是一个双向模型。Google在训练BERT的时候,挖掉输入文本中15%的词,让模型去完成类似完形填空的任务
BERT和GPT架构的区别 (source: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
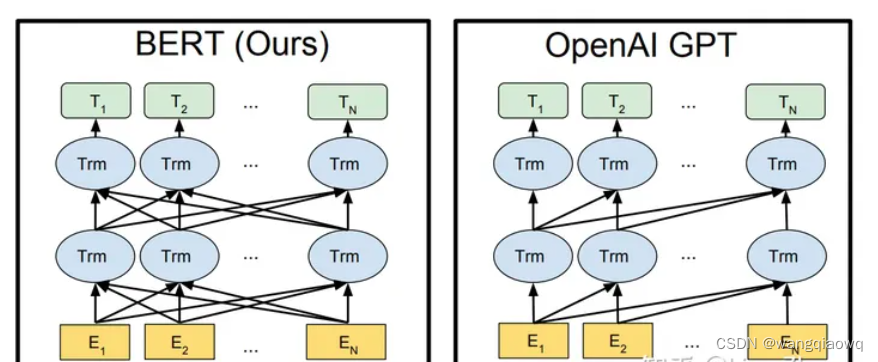
ERT模型由于同时可以看到目标词上下文的信息,一般在理解类任务上表现较好。而GPT模型只能看到上文,在此类任务上表现略逊一筹。但是这类单向模型天然更适合生成类任务,表现也稍好。
这一时期的流行做法是,无论什么任务,先来一个BERT打底,再换掉最后一层,用自己的数据进行微调,让模型产出成为自己需要的格式。尤其是在自己的数据不多的情况下,这样做普遍比自己从头训练Transformer效果要好。
大语言模型时代:Prompt代替微调
OpenAI提出了非常巧妙的办法来忽悠模型完成任务——小样本提示词(Few Shot Prompt),也就是先给模型一些问答的例子,最后留出一个问题。因为作为预测下文的语言模型,GPT-2的目标是续写我们提供的输入,而在这个过程中,就正好回答了我们最后留出的问题。使用这样的方法,GPT-2就可以在未经微调的情况下来完成各种它并没有被专门训练过的任务。
利用提示Prompt和大语言模型互动 (Source: GPT-3: Language Models are Few-Shot Learners)

Prompt模式本质是文本生成,刚好是GPT这样单向模型更为擅长的。因此在目前大语言模型的训练中,研究者们变成了更多采用GPT而不是BERT。
大模型的涌现能力:大力出奇迹
OpenAI继续沿着大力出奇迹的道路前行,发布了GPT-3。
GPT-3与GPT-2在模型架构上没有区别,只是采用了更大的模型和更多的数据,将参数提升到千亿级别,是BERT的五百倍。在标准NLP任务的测试中,又展现出了不小的提升,而且人们发现了这个模型出现了一些之前模型没有的,处理复杂任务能力。
模型解决某些相对简单直接的任务能力是随着模型的增大逐渐线性增长的,而解决另外一些较复杂任务的能力,则是在模型达到某个量级之后突然出现的,我们称之为涌现能力(Emergent Ability)。
大模型的涌现能力(source: Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models)
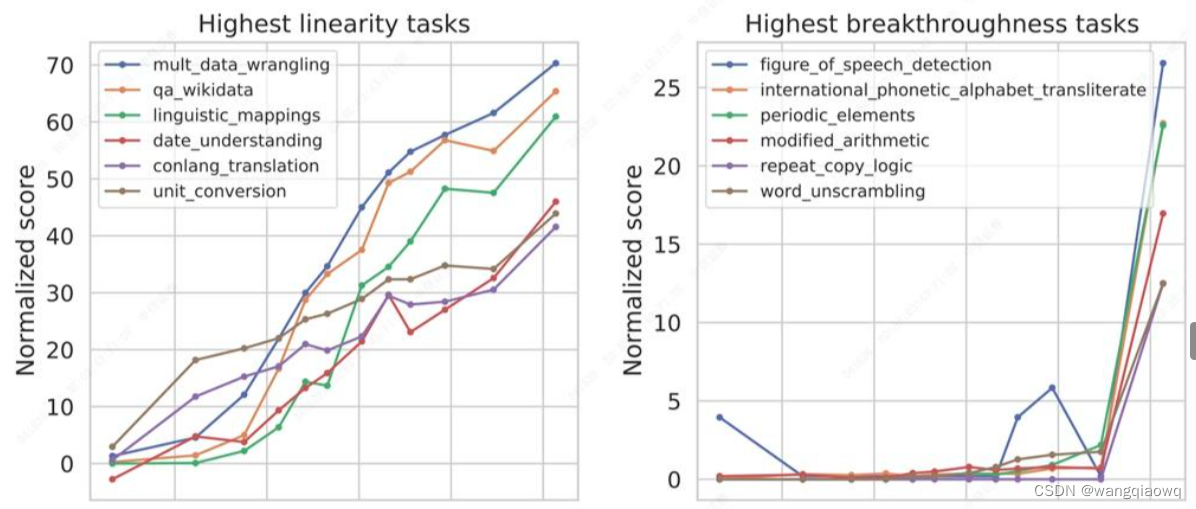
这类涌现能力有一些共同的特点:比如任务是需要多步骤解决,逻辑推理能力比较重要等等。
一个突出的涌现能力叫做思维链能力(Chain-of-Thought,简写为CoT)。这个现象是:如果在prompt当中加入一个一步步推理的例子,然后再问问题,能够提高模型的准确率,把以前做不对的题做对。一个可能的猜想是思维链prompt中给出了与目标答案更加相关的文本(也就是人工写的相似的例子),这些文本会激发模型中的相似记忆,帮助它找到更相关的答案。
引爆全球:逻辑思维和对话能力的增强
Codex 增加GitHub上所有的代码作为训练数据的模型
InstructGPT,这里OpenAI使用了一种基于强化学习的方法RLHF(Reinforcement Learning from Human Feedback with dialogue)RLHF的具体方法是首先让人类标注员来写一些prompt和对应的答案,然后用这个数据集去微调GPT-3,然后再让人工为这个新GPT-3的输出排序,用这个排序信息训练一个reward模型来辨别什么样的回答是人类喜欢的,最后再用这个reward模型和强化学习的方法去继续训练GPT-3。
ChatGPT在GPT-3的架构和训练数据基础上,增加代码数据,再加上RLHF指令微调训练而成,内部代号GPT-3.5。
其能力分解开来大致就是GPT-3提供语言理解能力和世界知识,Codex增强逻辑推理能力,InstructGPT提供对话能力。OpenAI又对后端基础模型进行了升级,从最开始的GPT-3.5升级到了GPT-4,性能上又有大幅提升,而且可以接受图像作为输入。
至此,我们已经回顾完了NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。
ChatGPT(Chat Generative Pre-training Transformer)是自然语言处理(Natural Language Processing,NLP)领域的一种AI模型。
OpenAI 还发布了支持语音转文本的 Whisper API。
相关文章:
NLP学习
参考:NLP发展之路I - 从词袋模型到Transformer - 知乎 (zhihu.com) NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的…...

Linux-Ubuntu环境下搭建SVN服务器
Linux-Ubuntu环境下搭建SVN服务器 一、背景二、前置工作2.1确定IP地址保持不变2.2关闭防火墙 三、安装SVN服务器四、修改SVN服务器版本库目录五、调整SVN配置5.1查看需要修改的配置文件5.2修改svnserve.conf文件5.3修改passwd文件,添加账号和密码(window…...
)
python tkinter使用(四)
本篇文章主要讲下tkinter 的文本框相关. tkinter中用Entry来实现输入框,类似于android中的edittext. 具体的用法如下: 1:空白输入框 如下: name tk.Entry(window) name.pack()2: 设置输入框的默认文案 name tk.Entry(window) name.pack() name.insert(tk.END, "请…...
记录ruoyi-plus-vue部署的问题
ruoyi-vue-plus5.x 后端 ruoyi-vue-plus5.x 前端 前端本地启动命令 # 克隆项目 git clone https://gitee.com/JavaLionLi/plus-ui.git# 安装依赖 npm install --registryhttps://registry.npmmirror.com# 启动服务 npm run dev# 构建生产环境 yarn build:prod # 前端访问地址…...

如何在springboot项目中使用minio上传下载删除文件
引入maven依赖 <!-- minio --> <dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.2.2</version> </dependency>申请 bucket | access_key | secret_key 项目中配置相关参数 mini…...
SSM个性化旅游管理系统开发mysql数据库web结构java编程计算机网页源码eclipse项目
一、源码特点 SSM 个性化旅游管理系统是一套完善的信息系统,结合springMVC框架完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码和数据库 ,系统主要采用B…...

4-Docker命令之docker version
1.docker version介绍 docker version命令是用于查看docker容器的版本信息 2.docker version用法 docker version [参数] [root@centos79 ~]# docker version --helpUsage: docker version [OPTIONS]Show the Docker version informationOptions:-f, --format string Fo…...
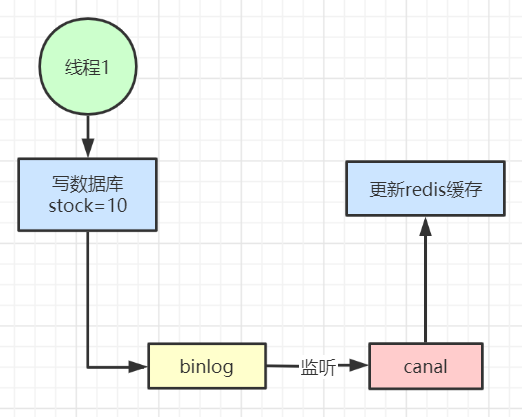
Redis高并发缓存架构
前言: 针对缓存我们并不陌生,而今天所讲的是使用redis作为缓存工具进行缓存数据。redis缓存是将数据保存在内存中的,而内存的珍贵性是不可否认的。所以在缓存之前,我们需要明确缓存的对象,是否有必要缓存,怎…...

谨防利用Redis未授权访问漏洞入侵服务器
说明: Redis是一个开源的,由C语言编写的高性能NoSQL数据库,因其高性能、可扩展、兼容性强,被各大小互联网公司或个人作为内存型存储组件使用。 但是其中有小部分公司或个人开发者,为了方便调试或忽略了安全风险&#…...

关于一些bug的解决1、el-input的输入无效2、搜索之后发现数据不对3、el多选框、单选框点击无用4、
el-input输入无效 原来的代码是 var test null 但是我发现不能输入任何值 反倒修改test的初始值为123是可以的 于是我确定绑定没问题 就是修改的问题 于是改成 var test ref() v-model绑定的值改成test.value就可以了 因为ref是相应式的 可以通过输入…...

使用 JavaScript 进行 API 测试的综合教程
说明 API 测试是软件测试的一种形式,涉及直接测试 API 并作为集成测试的一部分,以确定它们是否满足功能、可靠性、性能和安全性的预期。 先决条件: JavaScript 基础知识。Node.js 安装在您的计算机上。如果没有,请在此处下载。npm…...
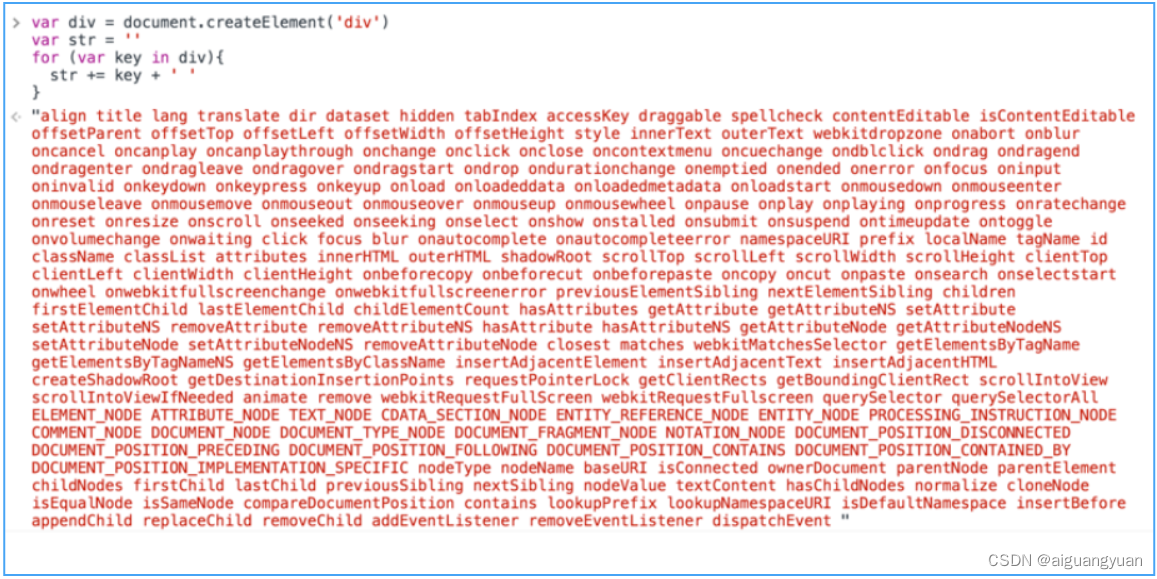
Vue 2.0源码分析-Virtual DOM
Virtual DOM 这个概念相信大部分人都不会陌生,它产生的前提是浏览器中的 DOM 是很“昂贵"的,为了更直观的感受,我们可以简单的把一个简单的 div 元素的属性都打印出来,如图所示: 可以看到,真正的 DOM …...
freeRTOS移植STMF103)
(HAL库版)freeRTOS移植STMF103
正点原子关于freeRTOS的教程是比较好的,可惜移植的是标准库,但是我学的是Hal库,因为开发速度更快,从最后那个修改SYSTEM文件夹的地方开始替换为下面的内容就可以了 5.修改Systick中断、SVC中断、PendSV中断 将SVC中断、P…...

vue2-axios
下载axios 开发版本:axios.js 生产版本:axios.min.js 搭建服务器:json-server npm i -g json-serverjson-server --watch db.json(启动服务并读取文件,db.json文件目录下启动) json-server --watch db.j…...
创建maven的web项目
(一)创建maven的web项目 Step1、创建一个普通的maven项目 (1)新建一个empty project,命名为SSM2。 点击项目名,右键new,选择Module,左侧选择“Maven archetype”,可以给…...

使用uniapp开发系统懒加载图片效果
1、创建一个Vue组件 在uniapp项目中,我们可以创建一个独立的Vue组件来实现懒加载图片效果。打开uniapp项目,进入components文件夹,创建一个名为"LazeImage"的组件。 2、编写组件模板 在"LazeImage"组件中,…...

导入PIL时报错
在导入PIL时,报以下错误: 查找原因 参考博客 Could not find a version that satisfies the requirement PIL (from versions: ) No matching distributi-CSDN博客,按照wheel后,安装PIL时,报如下的错误。 查找说是python版本与wheel文件版本不同,确认本机python版本 …...
MyBatis Generator 插件 详解自动生成代码
MyBatis Generator(MBG)是MyBatis和iBATIS的代码生成器。可以生成简单CRUD操作的XML配置文件、Mapper文件(DAO接口)、实体类。实际开发中能够有效减少程序员的工作量,甚至不用程序员手动写sql。 它将为所有版本的MyBatis以及版本2.2.0之后的i…...

SkyWalking全景解析:从原理到实现的分布式追踪之旅
🎏:你只管努力,剩下的交给时间 🏠 :小破站 SkyWalking全景解析:从原理到实现的分布式追踪之旅 前言第一:SkyWalking简介第二:实现原理概览第三:主键与架构第四࿱…...

新手如何买卖可转债,可转债投资基础入门
一、教程描述 什么是可转债?可转债是可转换债券的二次简称,原始全称是可转换公司债券,这是一种可以在特定时间、按特定条件,转换为普通股票的特殊企业债券,可转换债券兼具债权和股权的特征,其英文为conver…...

Spring Boot 4.0 Agent集成必踩的7个隐形陷阱:JVM Attach失败、字节码污染、Metrics失真——实测修复清单已验证
第一章:Spring Boot 4.0 Agent-Ready 架构演进与核心挑战Spring Boot 4.0 将 JVM Agent 集成能力提升为一等公民,其核心目标是实现“零侵入可观测性”与“运行时可编程增强”。这一演进并非简单叠加 Java Agent 支持,而是重构了启动生命周期、…...

DSP28035串口升级方案:含Bootloader源码、测试App工程源码、上位机源码及说明...
DSP28035串口升级方案 带bootloader源码,测试app工程源码,上位机源码,说明文档。 上位机采用vs2013开发,c#。 工程采用ccs10.3.1开发。DSP28035 串口 IAP 升级方案(标志位版)—— 从 BootLoader…...

Rust的匹配中的模式
Rust的匹配模式:代码逻辑的优雅表达 在编程语言中,模式匹配是一种强大的工具,能够以简洁的方式处理复杂的数据结构。Rust的模式匹配不仅功能丰富,还能在编译时确保安全性,避免常见的运行时错误。无论是处理枚举、解构…...

AI失业倒计时:2026岗位灭绝
站在质效革命的十字路口2026年,并非一个遥远的科幻节点,而是软件测试行业结构性变革的临界点。当AI从“辅助工具”进化为驱动测试流程的“基础架构”,一场关于岗位定义、核心价值与生存逻辑的深度重构正在悄然发生。对每一位软件测试从业者而…...

FEBio生物力学模拟中缓存性能优化策略
1. 缓存性能对FEBio生物力学模拟的影响机制在生物力学有限元分析领域,FEBio作为主流仿真工具,其性能表现与底层硬件架构的匹配度密切相关。通过gem5仿真平台对6种典型FEBio工作负载(ar、co、dm、ma、rj、tu)的测试数据显示&#x…...
)
别再傻等HAL_Delay了!手把手教你给STM32写个精准的微秒延时函数(附GPIO驱动避坑指南)
突破HAL库限制:STM32微秒级延时实战指南与GPIO时序优化 从HAL_Delay的局限到精准时序控制 在嵌入式开发中,精确的时序控制往往是成败的关键。当我们需要驱动WS2812全彩LED、超声波传感器或实现软件串口通信时,微秒级的延时精度变得至关重要。…...

避开这3个坑!GD32 SPI配置CKPH/CKPL时序详解与示波器实测对比
GD32 SPI时序配置实战:从波形分析到避坑指南 调试SPI接口时,最令人头疼的莫过于配置一切正常,但数据就是传不对。上周在调试一个温湿度传感器时,我遇到了类似问题——明明按照手册配置了CPOL和CPHA参数,示波器上的波形…...

【Docker镜像签名实战指南】:20年DevSecOps专家亲授,从零构建可信软件供应链
第一章:Docker镜像签名的核心价值与可信供应链全景图在容器化生产环境中,未经验证的镜像可能引入恶意代码、后门或配置漂移,导致集群级安全事件。Docker镜像签名通过数字签名机制,将镜像内容(manifest 配置层哈希&…...

解决Express服务器文件上传大小限制问题
在开发Web应用时,文件上传功能是常见的需求之一。然而,许多开发者在处理文件上传时会遇到文件大小限制的问题。本文将通过一个具体的案例,详细讲解如何在Express服务器上解决文件上传时遇到的文件大小限制问题。 背景 假设你正在开发一个文档管理系统,用户需要上传PDF文件…...

Anthropic测试将Claude Code从Pro计划中移除后开发者的反应
Anthropic已从其Pro订阅计划中移除了Claude Code,这一变化体现在该公司的部分对外网页上,但公司表示,这只是针对少数用户进行的测试。周一,该公司的定价页面还写明Pro计划"包含Claude Code"。到了周二,这句话…...