Hadoop学习总结(MapReduce的数据去重)
现在假设有两个数据文件
| file1.txt | file2.txt |
|---|---|
| 2018-3-1 a 2018-3-2 b 2018-3-3 c 2018-3-4 d 2018-3-5 a 2018-3-6 b 2018-3-7 c 2018-3-3 c | 2018-3-1 b 2018-3-2 a 2018-3-3 b 2018-3-4 d 2018-3-5 a 2018-3-6 c 2018-3-7 d 2018-3-3 c |
上述文件 file1.txt 本身包含重复数据,并且与 file2.txt 同样出现重复数据,现要求使用 Hadoop 大数据相关技术对这两个文件进行去重操作,并最终将结果汇总到一个文件中。
一、MapReduce 的数据去重
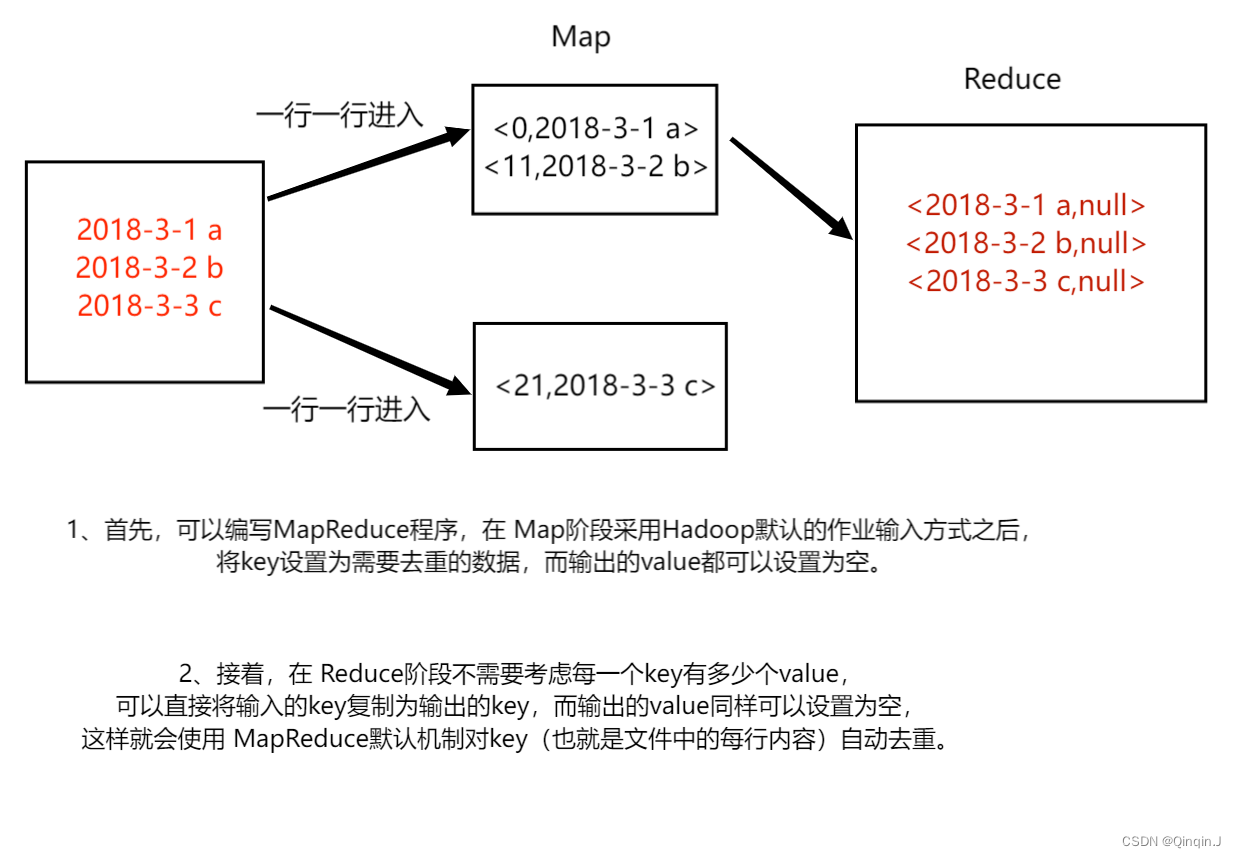
二、案例实现
1、Map 阶段实现
DedupMapper.java
package com.itcast.dedup;//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class DedupMapper extends Mapper<LongWritable, Text,Text, NullWritable> {//重写Ctrl+o@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// <0,2018-3-1 a> <11,2018-3-2 b>
// NullWritable.get() 方法设置空值context.write(value, NullWritable.get());}
}
该代码的作用是为了读取数据集文件将 TextInputFormat 默认组件解析的类似 <0,2018-3-1 a> 键值对修改 <2018-3-1 a,null>
2、Reduce 阶段实现
DedupReducer.java
package com.itcast.dedup;//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class DedupReducer extends Reducer<Text, NullWritable,Text,NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {//<2018-3-1 a,null> <11,2018-3-2 b,null> <11,2018-3-3 c,null>context.write(key,NullWritable.get());}
}
该代码的作用仅仅是接受 Map 阶段传递来的数据,根据 Shuffle 工作原理,键值 key 相同的数据就不会被合并,因此输出数据就不会出现重复数据了。
3、Dtuver 程序主类实现
DedupDriver.java
package com.itcast.dedup;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class DedupDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//通过 Job 来封装本次 MR 的相关信息Configuration conf = new Configuration();//System.setProperty("HADOOP_USER_NAME","root");//配置 MR 运行模式,使用 local 表示本地模式,可以省略
// conf.set("mapreduce.framework.name","local");Job job = Job.getInstance(conf);//指定 MR Job jar 包运行主类job.setJarByClass(DedupDriver.class);//指定本次 MR 所有的 Mapper Reducer 类job.setMapperClass(DedupMapper.class);job.setReducerClass(DedupReducer.class);//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);//使用本地模式指定处理的数据所在的位置//{input2\*} 表示读取该路径下所有的文件FileInputFormat.setInputPaths(job,"D:\\homework2\\Hadoop\\mr\\{input2\\*}");//使用本地模式指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("D:\\homework2\\Hadoop\\mr\\output"));//提交程序并且监控打印程序执行情况boolean res = job.waitForCompletion(true);//执行成功输出 0 ,不成功输出 1System.exit(res ? 0 : 1);}
}
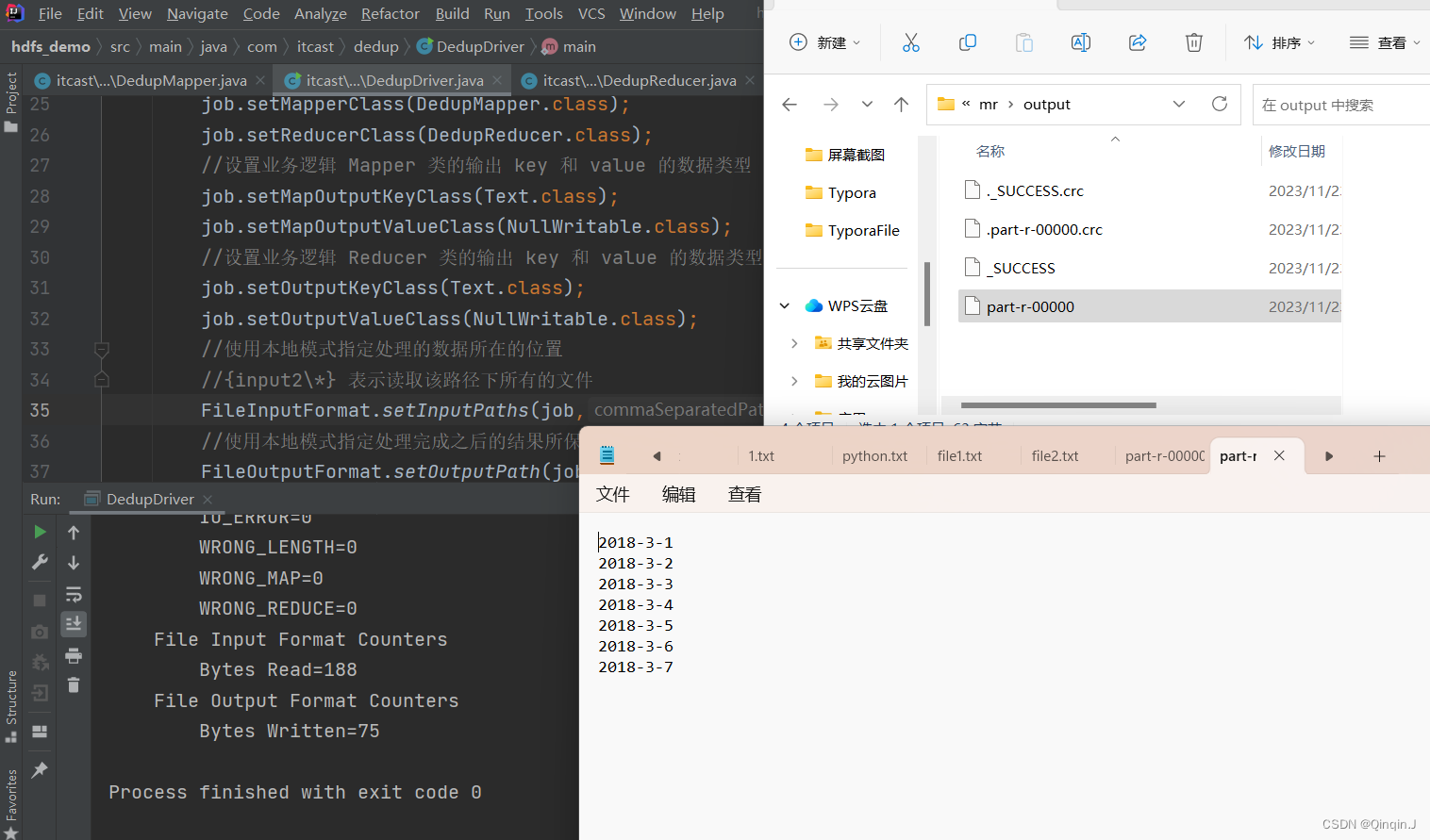
运行结果:

三、拓展
只要日期相同,就判定为相同,最后结果输出日期即可
只需要修改DedupMapper.java文件
package com.itcast.dedup;//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class DedupMapper extends Mapper<LongWritable, Text,Text, NullWritable> {//重写Ctrl+o@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//输出日期// 把 hadoop 类型转换为 java 类型(接收传入进来的一行文本,把数据类型转换为 String 类型)String line = value.toString();// 把字符串拆分为单词String[] words = line.split(" ");// 输出前面的内容String wo = words[0];context.write(new Text(wo), NullWritable.get());}
}
运行结果:
相关文章:
Hadoop学习总结(MapReduce的数据去重)
现在假设有两个数据文件 file1.txtfile2.txt2018-3-1 a 2018-3-2 b 2018-3-3 c 2018-3-4 d 2018-3-5 a 2018-3-6 b 2018-3-7 c 2018-3-3 c2018-3-1 b 2018-3-2 a 2018-3-3 b 2018-3-4 d 2018-3-5 a 2018-3-6 c 2018-3-7 d 2018-3-3 c 上述文件 file1.txt 本身包含重复数据&…...

ctfshow sql
180 过滤%23 %23被过滤,没办法注释了,还可以用’1’1来闭合后边。 或者使用--%0c-- 1%0corder%0cby%0c3--%0c--1%0cunion%0cselect%0c1,2,database()--%0c--1%0cunion%0cselect%0c1,2,table_name%0cfrom%0cinformation_schema.tables%0cwhere%0ctable_…...

Java实现求最大值
1 问题 接收用户输入的3个整数,如何将最大值作为结果输出。 2 方法 采用“截图文字代码”的方式描述。 引入输入包调用main()函数,提示并接收用户输入的3个整数,并交由变量a b c来保存。对接收的3个数据进行比较,先比较a和b&#…...

NX二次开发UF_CURVE_ask_curve_inflections 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CURVE_ask_curve_inflections Defined in: uf_curve.h int UF_CURVE_ask_curve_inflections(tag_t curve_eid, double proj_matrx [ 9 ] , double range [ 2 ] , int * num_infpt…...

一个基于RedisTemplate静态工具类
每次是用RedisTemplate的时候都需要进行自动注入实在是太麻烦了,于是找到一个讨巧的办法。 import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.stereotype.…...
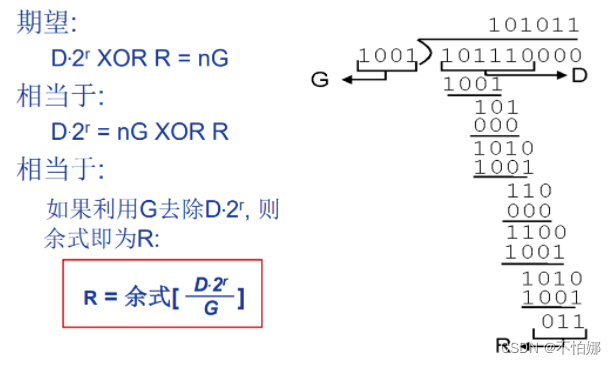
【计算机网络笔记】数据链路层——差错编码
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

js生成pdf并自动上传
1.生成pdf前要让js选中生成pdf部分的dom <div id"printPageFirst"> pdf内容区 </div> 2.使用两个插件,import到项目里,然后是获取dom进行生成pdf操作 import html2canvas from html2canvas import JsPDF from jspdf function cr…...

高品质MP3音频解码语音芯片WT2003Hx的特征优势与应用场景
在现代化科技快速发展的时代,高品质音频语音芯片在各个领域的应用越来越广泛。唯创知音推出的高品质MP3音频语音芯片WT2003Hx,凭借其出色的特性与优势,赢得了市场的广泛认可。本文将详细介绍WT2003Hx的特征优势以及其在各个领域的应用场景。 …...
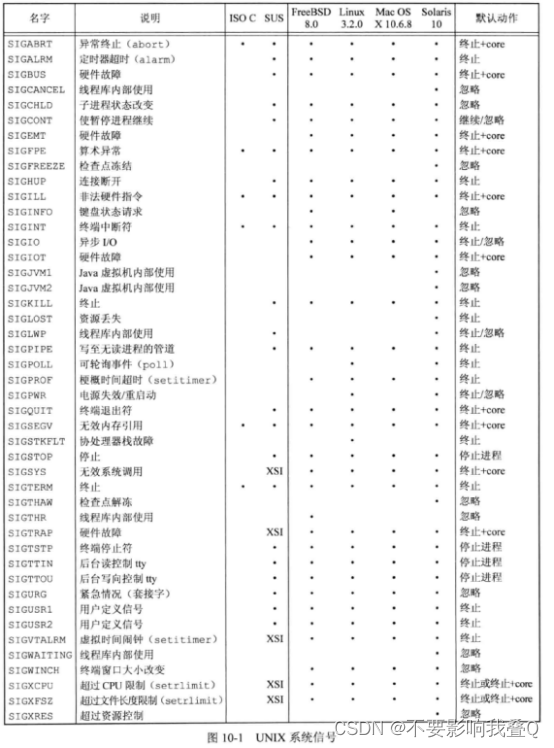
浅析linux中的信号
人们往往将信号称为“软件中断”,它提供了异步事件的处理机制,这些事件可以来自系统外部(如用户按下ctrlc产生中断符),也可能来自程序或者内核内部的执行动作(如进程除零操作)。进程收到信号&am…...

从0开始学习JavaScript--JavaScript数据类型与数据结构
JavaScript作为一门动态、弱类型的脚本语言,拥有丰富的数据类型和数据结构,这些构建了语言的基础,为开发者提供了灵活性和表达力。本文将深入探讨JavaScript中的各种数据类型,包括基本数据类型和复杂数据类型,并介绍常…...

数据结构与算法编程题20
统计二叉树的叶结点个数。 #define _CRT_SECURE_NO_WARNINGS#include <iostream> using namespace std;typedef char ElemType; #define ERROR 0 #define OK 1 typedef struct BiNode {ElemType data;BiNode* lchild, * rchild; }BiNode,*BiTree;bool Create_tree(BiTre…...

FreeRTOS源码阅读笔记5--mutex
互斥量是一种特殊的二值信号量,拥有优先级继承的机制,所以适合用在临界资源互斥访问。 5.1创建互斥量xSemaphoreCreateMutex() 5.1.1函数原型 5.1.2函数框架 5.2创建递归互斥量xSemaphoreCreateRecursiveMutex() 5.2.1函数原型 5.2.2函数框架 xSemaph…...
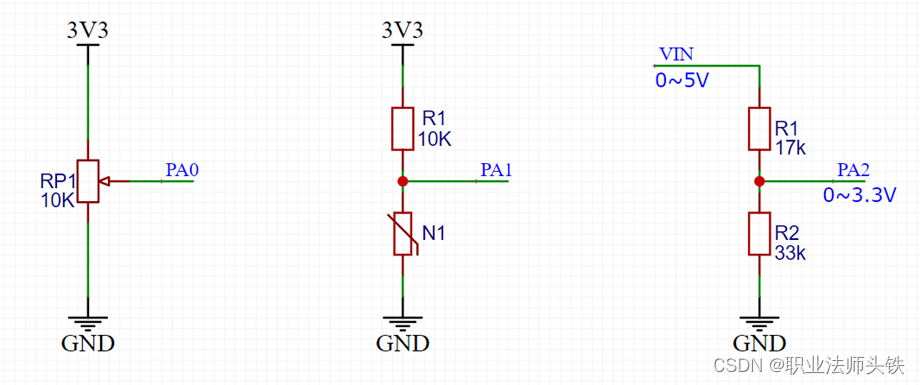
STM32_7(ADC)
一、ADC ADC(Analog-Digital Converter)模拟-数字转换器ADC可以将引脚上连续变化的模拟电压转换为内存中存储的数字变量,建立模拟电路到数字电路的桥梁12位逐次逼近型ADC,1us转换时间输入电压范围:0~3.3V,…...
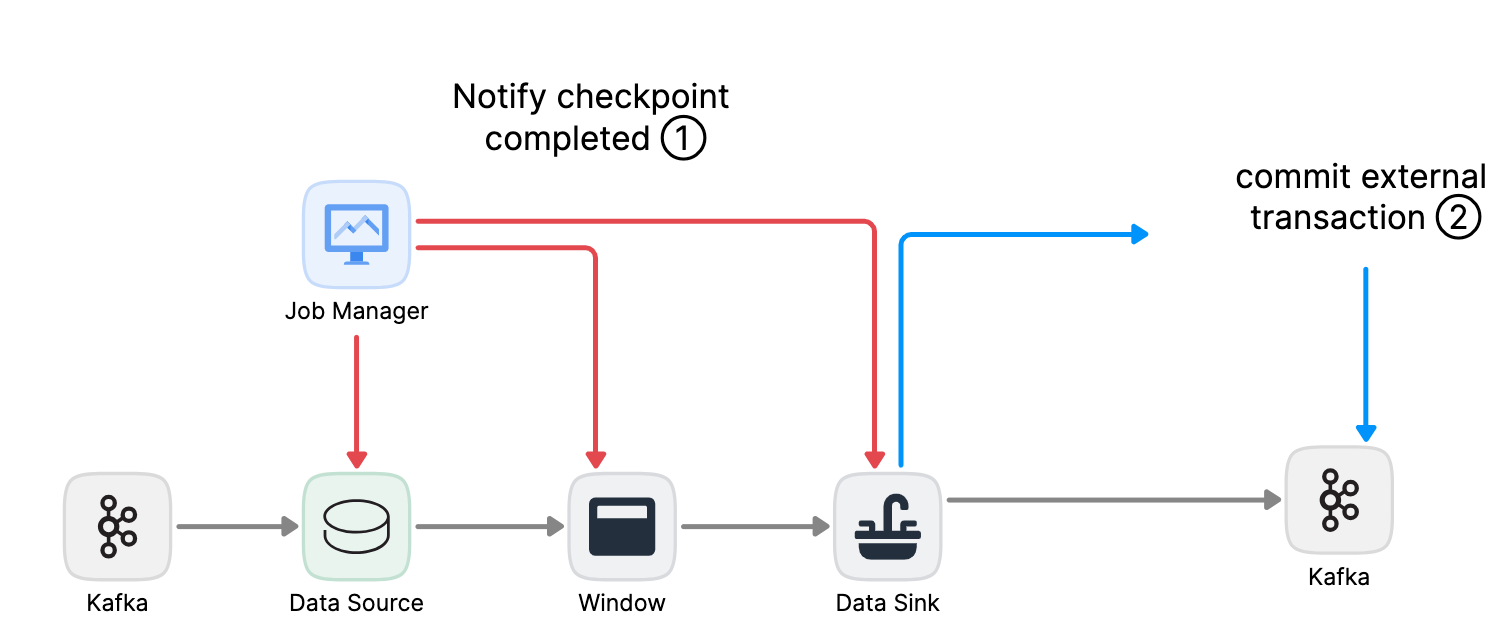
Flink实战(11)-Exactly-Once语义之两阶段提交
0 大纲 [Apache Flink]2017年12月发布的1.4.0版本开始,为流计算引入里程碑特性:TwoPhaseCommitSinkFunction。它提取了两阶段提交协议的通用逻辑,使得通过Flink来构建端到端的Exactly-Once程序成为可能。同时支持: 数据源&#…...
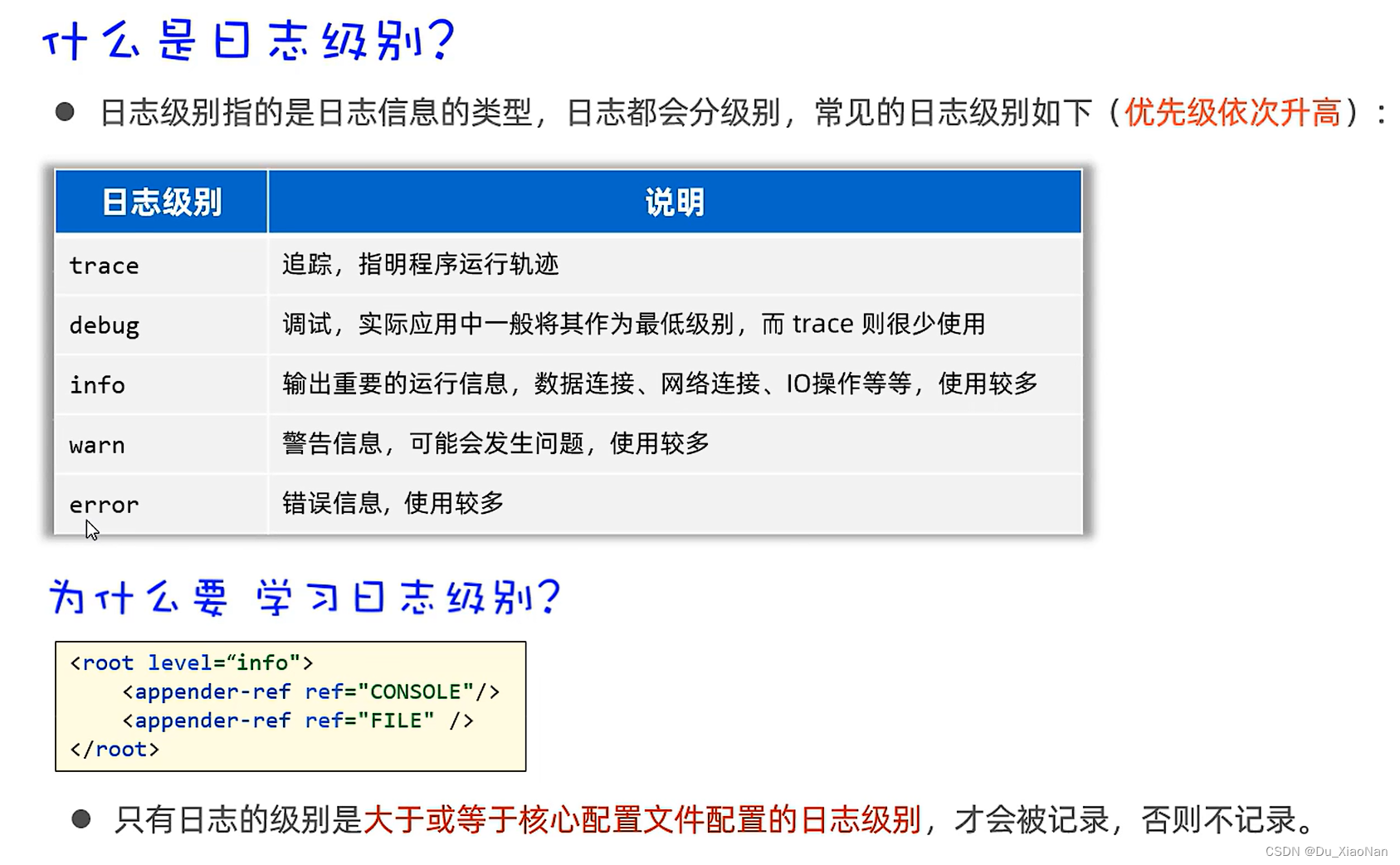
日志技术logback
一,日志概括 二,日志技术的特点 三,日志技术的体系 三,入门 四,案例 package XinZheng;import org.slf4j.Logger; import org.slf4j.LoggerFactory;public class Main58 {//1,创建一个Logger日志对象public static fi…...
之build构建系统基础(一))
linux(1)之build构建系统基础(一)
Linux(1)之buildroot构建系统(一) Author:Onceday Date:2023年11月12日 漫漫长路,才刚刚开始… 参考文档: The Yocto ProjectBuildroot - Making Embedded Linux Easy 文章目录 Linux(1)之buildroot构建系统(一)1. 概述1.1 如…...
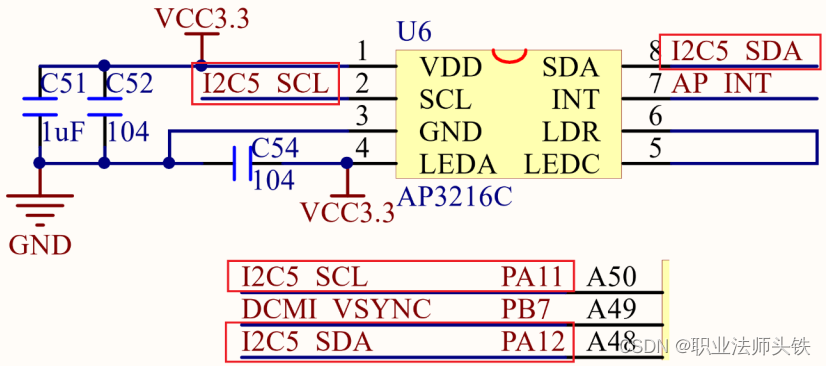
25 Linux I2C 驱动
一、I2C简介 I2C老朋友了,在单片机里面也学过,现在再复习一下。I2C使用两条线在主控制器和从机之间进行数据通信。一条是 SCL(串行时钟线),另外一条是 SDA(串行数据线),这两条数据线需要接上拉电阻,总线空闲的时候 SCL…...

API 设计:使用 Node.js 和 Express.js 的综合教程
API(应用程序编程接口)设计涉及创建一个高效而强大的接口,允许不同的软件应用程序相互交互。 说明 本教程将指导您使用 Node.js 和 Express.js 作为核心技术来规划、设计和构建 API。但是,这些原则可以应用于任何语言或框架。我们…...

vite和webpack的区别和练习
Vite和Webpack都是现代化的前端构建工具,但它们之间存在一些区别: 构建性能:Vite使用ES Modules提高了构建性能,可以在构建时只构建需要的部分,而Webpack则需要在构建时处理整个应用程序。 开发体验:Vite具…...

Python与设计模式--装饰器模式
6-Python与设计模式–装饰器模式 一、快餐点餐系统 又提到了那个快餐点餐系统,不过今天我们只以其中的一个类作为主角:饮料类。 首先,回忆下饮料类: class Beverage():name ""price 0.0type "BEVERAGE"…...

科技领袖警示:AI、生物工程与气候危机的未来风险
1. 科技领袖的警示:我们为何需要关注未来风险那天我在整理书架时,偶然翻到一本2015年的《时代》杂志,封面正是比尔盖茨、埃隆马斯克和霍金三人的合影,标题赫然写着"他们警告的世界"。这让我想起过去十年间,这…...

Python自动化控制Comsol多物理场仿真的5个核心技术
Python自动化控制Comsol多物理场仿真的5个核心技术 【免费下载链接】MPh Pythonic scripting interface for Comsol Multiphysics 项目地址: https://gitcode.com/gh_mirrors/mp/MPh 你是否曾为重复的Comsol图形界面操作感到疲惫?是否梦想着用Python的强大功…...

Three.js 透明贴图实战:告别模型白边与异常透明的深度调优指南
1. 透明贴图问题的典型表现与诊断 第一次在Three.js里加载带透明贴图的模型时,我盯着屏幕上那些锯齿状的白边发呆了半小时。明明在Blender里渲染正常的树叶模型,导入后边缘却像被劣质PS抠过图一样。更诡异的是,某些应该实心的部分竟然变成了半…...

PageAdmin平台化:多业务系统动态构建技术
以下是针对“PageAdmin应用系统平台化”的技术实现方案,聚焦于将传统单应用后台管理系统改造为可无限创建业务系统的低代码平台,仅涉及技术架构与实现步骤。 一、平台化核心架构设计 将PageAdmin从“单个后台系统”改造为多业务系统托管平台,…...

全志D1s/F133 RISC-V处理器架构与应用解析
1. Allwinner D1s/F133 RISC-V处理器深度解析全志科技最新推出的D1s(又称F133)处理器,作为D1 RISC-V处理器的精简版本,在保持核心功能的同时通过集成64MB DDR2内存显著降低了成本。这款处理器主要面向智能摄像头和显示屏市场&…...
)
从‘Hello World’到‘Hello AI’:用ESP32和TensorFlow Lite做个会呼吸的灯(附完整代码)
从‘Hello World’到‘Hello AI’:用ESP32和TensorFlow Lite打造智能呼吸灯实战指南 1. 为什么嵌入式开发者需要尝试TinyML? 记得第一次点亮LED时的兴奋吗?那种"Hello World"级别的成就感,正是推动我们不断探索技术的原…...

别再只盯着CNN了!用ViT的cls token搞定图像分类,保姆级原理拆解
从会议主持人到图像分类:ViT中cls token的全局智慧 想象你正在组织一场跨部门会议,每个参会者都带着自己的专业见解。作为主持人,你需要倾听所有人的发言,提炼关键信息,最终形成一份综合报告——这正是Vision Transfor…...

避开WS2812B的坑:STM32的PWM频率与DMA缓冲区大小到底怎么算?
STM32驱动WS2812B的实战避坑指南:从时序解析到DMA优化 当你在深夜调试WS2812B灯带时,是否经历过这样的崩溃瞬间——代码明明照着教程一字不差,灯珠却像叛逆期的少年,要么闪烁不定,要么集体罢工,甚至上演&qu…...

Phi-3.5-Mini-Instruct惊艳效果展示:7GB显存下媲美Qwen2.5的逻辑与代码能力
Phi-3.5-Mini-Instruct惊艳效果展示:7GB显存下媲美Qwen2.5的逻辑与代码能力 1. 开篇亮点 Phi-3.5-Mini-Instruct作为微软最新推出的轻量级大模型,在仅需7GB显存的条件下,展现出令人惊叹的逻辑推理和代码生成能力。这款专为本地运行优化的模…...

3步掌握暗黑2存档编辑器:轻松修改角色与物品
3步掌握暗黑2存档编辑器:轻松修改角色与物品 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾经在暗黑破坏神2中,因为角色属性分配不当而懊恼?是否想尝试不同的装备组合却苦于没有合适…...