卷积神经网络(CNN)识别验证码
文章目录
- 一、前言
- 二、前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 2. 导入数据
- 3. 查看数据
- 4.标签数字化
- 二、构建一个tf.data.Dataset
- 1.预处理函数
- 2.加载数据
- 3.配置数据
- 三、搭建网络模型
- 四、编译
- 五、训练
- 六、模型评估
- 七、保存和加载模型
- 八、预测
一、前言
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
往期精彩内容:
- 卷积神经网络(CNN)实现mnist手写数字识别
- 卷积神经网络(CNN)多种图片分类的实现
- 卷积神经网络(CNN)衣服图像分类的实现
- 卷积神经网络(CNN)鲜花识别
- 卷积神经网络(CNN)天气识别
- 卷积神经网络(VGG-16)识别海贼王草帽一伙
- 卷积神经网络(ResNet-50)鸟类识别
- 卷积神经网络(AlexNet)鸟类识别
来自专栏:机器学习与深度学习算法推荐
二、前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")
2. 导入数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL,random,pathlib# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
data_dir = "code"
data_dir = pathlib.Path(data_dir)all_image_paths = list(data_dir.glob('*'))
all_image_paths = [str(path) for path in all_image_paths]# 打乱数据
random.shuffle(all_image_paths)# 获取数据标签
all_label_names = [path.split("\\")[5].split(".")[0] for path in all_image_paths]image_count = len(all_image_paths)
print("图片总数为:",image_count)
3. 查看数据
plt.figure(figsize=(10,5))for i in range(20):plt.subplot(5,4,i+1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片images = plt.imread(all_image_paths[i])plt.imshow(images)# 显示标签plt.xlabel(all_label_names[i])plt.show()

4.标签数字化
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
char_set = number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])# 将字符串数字化
def text2vec(text):vector = np.zeros([label_name_len, char_set_len])for i, c in enumerate(text):idx = char_set.index(c)vector[i][idx] = 1.0return vectorall_labels = [text2vec(i) for i in all_label_names]
二、构建一个tf.data.Dataset
1.预处理函数
def preprocess_image(image):image = tf.image.decode_jpeg(image, channels=1)image = tf.image.resize(image, [50, 200])return image/255.0def load_and_preprocess_image(path):image = tf.io.read_file(path)return preprocess_image(image)
2.加载数据
构建 tf.data.Dataset 最简单的方法就是使用 from_tensor_slices 方法。
AUTOTUNE = tf.data.experimental.AUTOTUNEpath_ds = tf.data.Dataset.from_tensor_slices(all_image_paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
image_label_ds
<ZipDataset shapes: ((50, 200, 1), (5, 36)), types: (tf.float32, tf.float64)>
train_ds = image_label_ds.take(1000) # 前1000个batch
val_ds = image_label_ds.skip(1000) # 跳过前1000,选取后面的
3.配置数据
先复习一下prefetch()函数。prefetch()功能详细介绍:CPU 正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU 处于空闲状态。因此,训练所用的时间是 CPU 预处理时间和加速器训练时间的总和。prefetch()将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第 N 个训练步时,CPU 正在准备第 N+1 步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态:
BATCH_SIZE = 16train_ds = train_ds.batch(BATCH_SIZE)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
val_ds
三、搭建网络模型
from tensorflow.keras import datasets, layers, modelsmodel = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1)),#卷积层1,卷积核3*3layers.MaxPooling2D((2, 2)), #池化层1,2*2采样layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3layers.MaxPooling2D((2, 2)), #池化层2,2*2采样layers.Flatten(), #Flatten层,连接卷积层与全连接层layers.Dense(1000, activation='relu'), #全连接层,特征进一步提取layers.Dense(label_name_len * char_set_len),layers.Reshape([label_name_len, char_set_len]),layers.Softmax() #输出层,输出预期结果
])
# 打印网络结构
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 48, 198, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 24, 99, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 22, 97, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 11, 48, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 33792) 0
_________________________________________________________________
dense (Dense) (None, 1000) 33793000
_________________________________________________________________
dense_1 (Dense) (None, 180) 180180
_________________________________________________________________
reshape (Reshape) (None, 5, 36) 0
_________________________________________________________________
softmax (Softmax) (None, 5, 36) 0
=================================================================
Total params: 33,991,996
Trainable params: 33,991,996
Non-trainable params: 0
_________________________________________________________________
四、编译
model.compile(optimizer="adam",loss='categorical_crossentropy',metrics=['accuracy'])
五、训练
epochs = 20history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
Epoch 1/20
63/63 [==============================] - 4s 21ms/step - loss: 3.2998 - accuracy: 0.0934 - val_loss: 2.2876 - val_accuracy: 0.2943
Epoch 2/20
63/63 [==============================] - 1s 9ms/step - loss: 1.7016 - accuracy: 0.5195 - val_loss: 1.2014 - val_accuracy: 0.6314
Epoch 3/20
63/63 [==============================] - 1s 10ms/step - loss: 0.5267 - accuracy: 0.8379 - val_loss: 0.9039 - val_accuracy: 0.7286
Epoch 4/20
63/63 [==============================] - 1s 10ms/step - loss: 0.1911 - accuracy: 0.9442 - val_loss: 0.8609 - val_accuracy: 0.7457
Epoch 5/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0916 - accuracy: 0.9714 - val_loss: 0.8937 - val_accuracy: 0.7886
Epoch 6/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0680 - accuracy: 0.9798 - val_loss: 0.5842 - val_accuracy: 0.8429
Epoch 7/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0443 - accuracy: 0.9900 - val_loss: 0.6235 - val_accuracy: 0.8200
Epoch 8/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0203 - accuracy: 0.9947 - val_loss: 0.7697 - val_accuracy: 0.8029
Epoch 9/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0131 - accuracy: 0.9975 - val_loss: 0.6660 - val_accuracy: 0.8314
Epoch 10/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0227 - accuracy: 0.9940 - val_loss: 0.6018 - val_accuracy: 0.8229
Epoch 11/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0093 - accuracy: 0.9985 - val_loss: 0.5714 - val_accuracy: 0.8429
Epoch 12/20
63/63 [==============================] - 1s 10ms/step - loss: 0.0010 - accuracy: 1.0000 - val_loss: 0.5793 - val_accuracy: 0.8571
Epoch 13/20
63/63 [==============================] - 1s 10ms/step - loss: 2.6284e-04 - accuracy: 1.0000 - val_loss: 0.5920 - val_accuracy: 0.8571
Epoch 14/20
63/63 [==============================] - 1s 10ms/step - loss: 1.8502e-04 - accuracy: 1.0000 - val_loss: 0.6031 - val_accuracy: 0.8571
Epoch 15/20
63/63 [==============================] - 1s 10ms/step - loss: 1.4164e-04 - accuracy: 1.0000 - val_loss: 0.6120 - val_accuracy: 0.8571
Epoch 16/20
63/63 [==============================] - 1s 10ms/step - loss: 1.1334e-04 - accuracy: 1.0000 - val_loss: 0.6198 - val_accuracy: 0.8571
Epoch 17/20
63/63 [==============================] - 1s 10ms/step - loss: 9.4027e-05 - accuracy: 1.0000 - val_loss: 0.6269 - val_accuracy: 0.8571
Epoch 18/20
63/63 [==============================] - 1s 10ms/step - loss: 8.0025e-05 - accuracy: 1.0000 - val_loss: 0.6335 - val_accuracy: 0.8514
Epoch 19/20
63/63 [==============================] - 1s 9ms/step - loss: 6.9294e-05 - accuracy: 1.0000 - val_loss: 0.6396 - val_accuracy: 0.8486
Epoch 20/20
63/63 [==============================] - 1s 10ms/step - loss: 6.0775e-05 - accuracy: 1.0000 - val_loss: 0.6448 - val_accuracy: 0.8486
六、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
七、保存和加载模型
# 保存模型
model.save('model/12_model.h5')
# 加载模型
new_model = tf.keras.models.load_model('model/12_model.h5')
八、预测
def vec2text(vec):"""还原标签(向量->字符串)"""text = []for i, c in enumerate(vec):text.append(char_set[c])return "".join(text)plt.figure(figsize=(10, 8)) # 图形的宽为10高为8for images, labels in val_ds.take(1):for i in range(6):ax = plt.subplot(5, 2, i + 1) # 显示图片plt.imshow(images[i])# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0) # 使用模型预测验证码predictions = model.predict(img_array)plt.title(vec2text(np.argmax(predictions, axis=2)[0]))plt.axis("off")

相关文章:
卷积神经网络(CNN)识别验证码
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据4.标签数字化 二、构建一个tf.data.Dataset1.预处理函数2.加载数据3.配置数据 三、搭建网络模型四、编译五、训练六、模型评估七、保存和加载模型八、预测 …...
使用 PyODPS 采集神策事件数据
文章目录 一、前言二、数据采集、处理和入库2.1 获取神策 token2.2 请求神策数据2.3 数据处理-面向数组2.4 测试阿里云 DataFrame 入库2.5 调度设计与配置2.6 项目代码整合 三、小结四、花絮-避坑指南第一坑:阿里云仅深圳节点支持神策数据第二坑:神策 To…...
罗技M590鼠标usb优联连接不上
手里有一个罗技M590鼠标从18年4月一直用到现在,质量很好,除了滚轮有些松别的没毛病。最近一台笔记本电脑办公不太够用,又领了一个台式机,就想到M590支持双模连接,并且支持Flow,就把usb优联接收器从电池仓拿…...
: 基于逻辑回归的分类预测)
天池 机器学习算法(一): 基于逻辑回归的分类预测
pytorch实战 课时7 神经网络 MSE的缺点:偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练时,偏导值几乎消失,模型速度非常慢。 交叉熵损失函数:平方损失则过于严格,需要使用更合…...
45岁后,3部位“越干净”,往往身体越健康,占一个也要恭喜!
众所周知,人的生命有长有短,而我们的身体健康状态,也同样会受到年龄的影响,就身体的年龄层次而言,往往需要我们用身体内部的干净程度来维持,换句话说就是:若是你的身体内部越干净,那…...
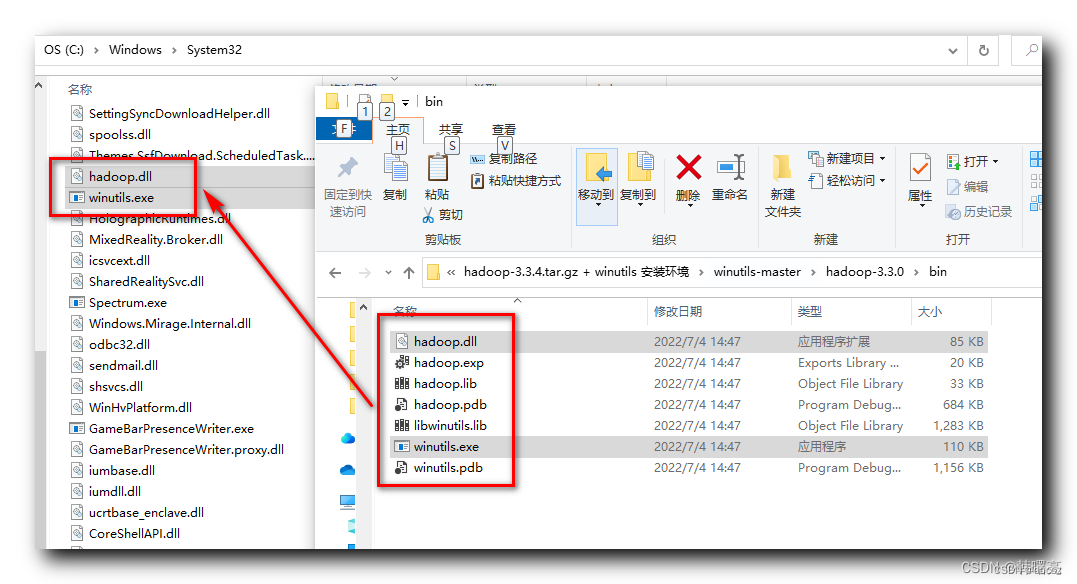
Windows安装Hadoop运行环境
1、下载Hadoop 2、解压Hadoop tar zxvf hadoop-3.1.1.tar.gz3、设置Hadoop环境变量 3.1.1、系统环境变量 # HADOOP_HOME D:\software\hadoop-3.1.13.1.2、Path 环境变量 %HADOOP_HOME%\bin %HADOOP_HOME%\sbin3.1.3、修改Hadoop文件JAVA_HOME 注 : 路径中不要出现空格 ,…...
软件测试 | MySQL 主键约束详解:保障数据完整性与性能优化
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...

深入了解Linux中的scp命令及高级用法
Linux操作系统中,scp(Secure Copy Protocol)命令是一个用于在本地系统和远程系统之间安全复制文件的强大工具。通过基于SSH的加密通信,scp提供了安全的文件传输方式。在本文中,我们将深入介绍scp命令的基本语法以及一些…...

moviepy 视频剪切,拼接,音频处理
官网 使用matplotlib — moviepy-cn 文档 案例 from moviepy.editor import * from moviepy.video.fx import resize from PIL import Imagefile1r"D:\xy_fs_try\video_to_deal\spider_video\file\vedeo3.mp4" file2r"D:\xy_fs_try\video_to_deal\spider_video\…...
ubuntu搭建phpmyadmin+wordpress
Ubuntu搭建phpmyadmin wordpress Linux系统设置:Ubuntu 22配置apache2搭建phpmyadmin配置Nginx环境,搭建wordpress Linux系统设置:Ubuntu 22 配置apache2 安装apache2 sudo apt -y install apache2设置端口号为8080 sudo vim /etc/apache…...
linux网络之网络层与数据链路层
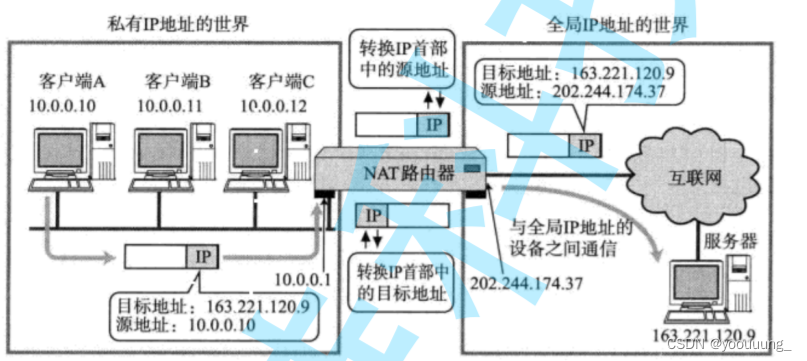
文章目录 一、网络层 1.IP协议 2.IP协议头格式 3.网段划分 4.特殊ip地址 5.IP地址的数量限制 6.私有ip和公网IP 7.路由 二、数据链路层 1.以太网 2.以太网帧格式 3.MAC地址 4.对比理解MAC地址和IP地址 5.MTU 6.ARP协议 ARP协议的工作流程 ARP数据报的格式 7.DNS 8.ICMP协议 9.N…...

python数学建模之Numpy、Pandas学习与应用介绍
文章目录 Numpy学习1 Numpy 介绍与应用1-1Numpy是什么 2 NumPy Ndarray 对象3 Numpy 数据类型4 Numpy 数组属性 Pandas学习1 pandas新增数据列2 Pandas数据统计函数3 Pandas对缺失值的处理 总结关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品P…...

LiveVIS视图库1400-如何切换数据库?默认使用的数据库是什么?如何切换到Mysql/MariaDB?
LiveVIS视图库1400-如何切换数据库?默认使用的数据库是什么?如何切换到Mysql/MariaDB? 1、切换成Mysql/Mariadb数据库1.1 连接数据库1.2 创建数据库实例1.3 配置.ini文件1.4 重启完成切换 1、切换成Mysql/Mariadb数据库 LiveVIS 默认使用 sqlite3 文件…...
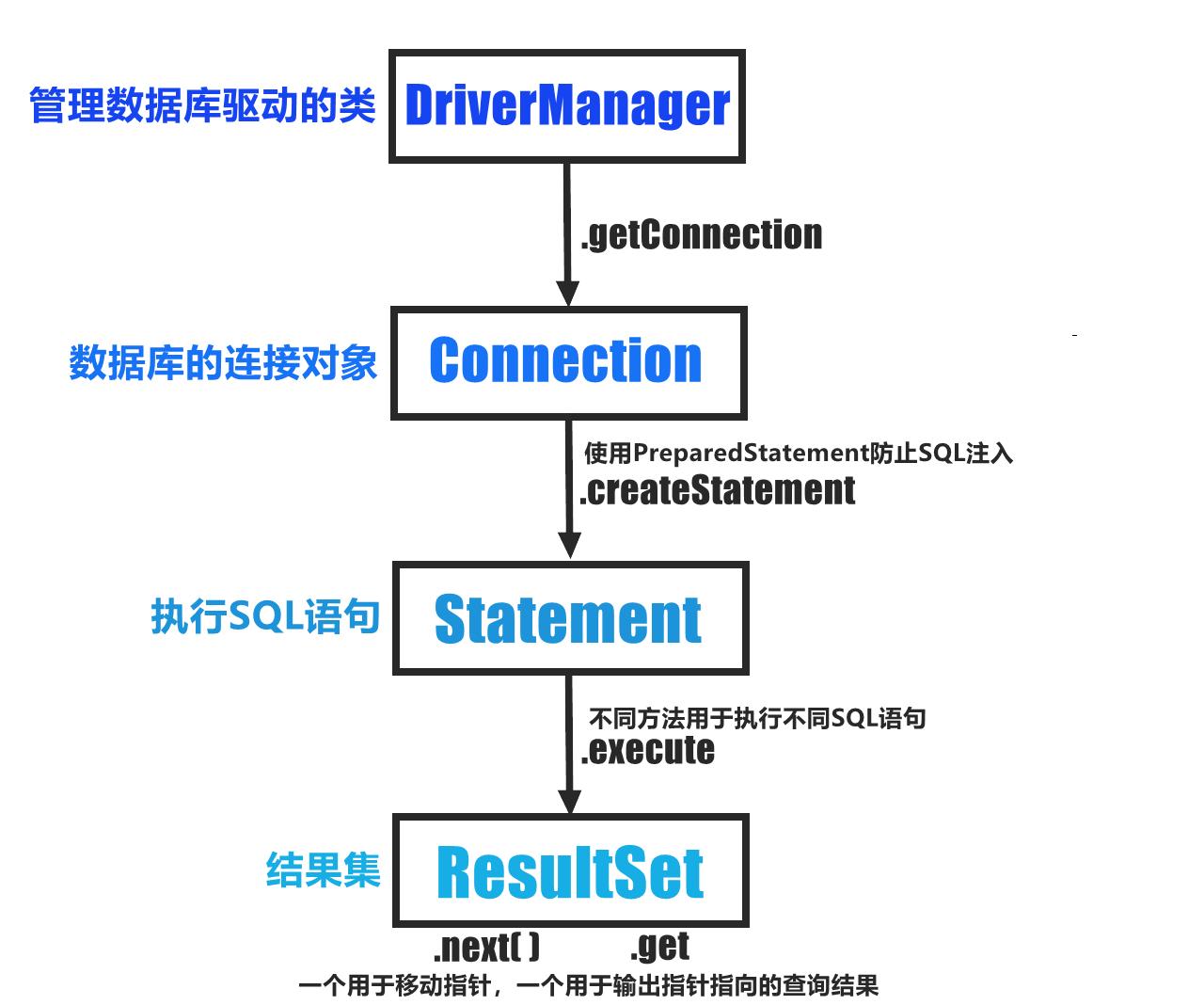
【2023.11.24】Mybatis基本连接语法学习➹
基本配置 1.如果使用Maven管理项目,需要在pom.xml中配置依赖。 2.安装Mybatis-3.5.7.jar包 3.进行XML配置:这里将文件命名为mybatis-config.xml 配置数据库连接XML文件 <?xml version"1.0" encoding"UTF-8" ?> <!DO…...
如何防止网络被入侵?
随着互联网的普及,网络安全问题越来越受到人们的关注。其中,如何防止网络被入侵是一个重要的问题。本文将介绍一些防止网络被入侵的方法,帮助大家保护自己的网络安全。 一、使用强密码 强密码是防止网络被入侵的第一道防线。一个好的密码应该…...

【Linux】常见指令及周边知识(一)
【Linux】常见指令及周边知识(一) 一、初始Linux操作系统1.Linux背景2.如何使用Linux 二、学习Linux之前的预备周边知识(重点):1.什么叫做文件?2. Linux下的路径分隔符3.在Linux中为什么会存在路径…...
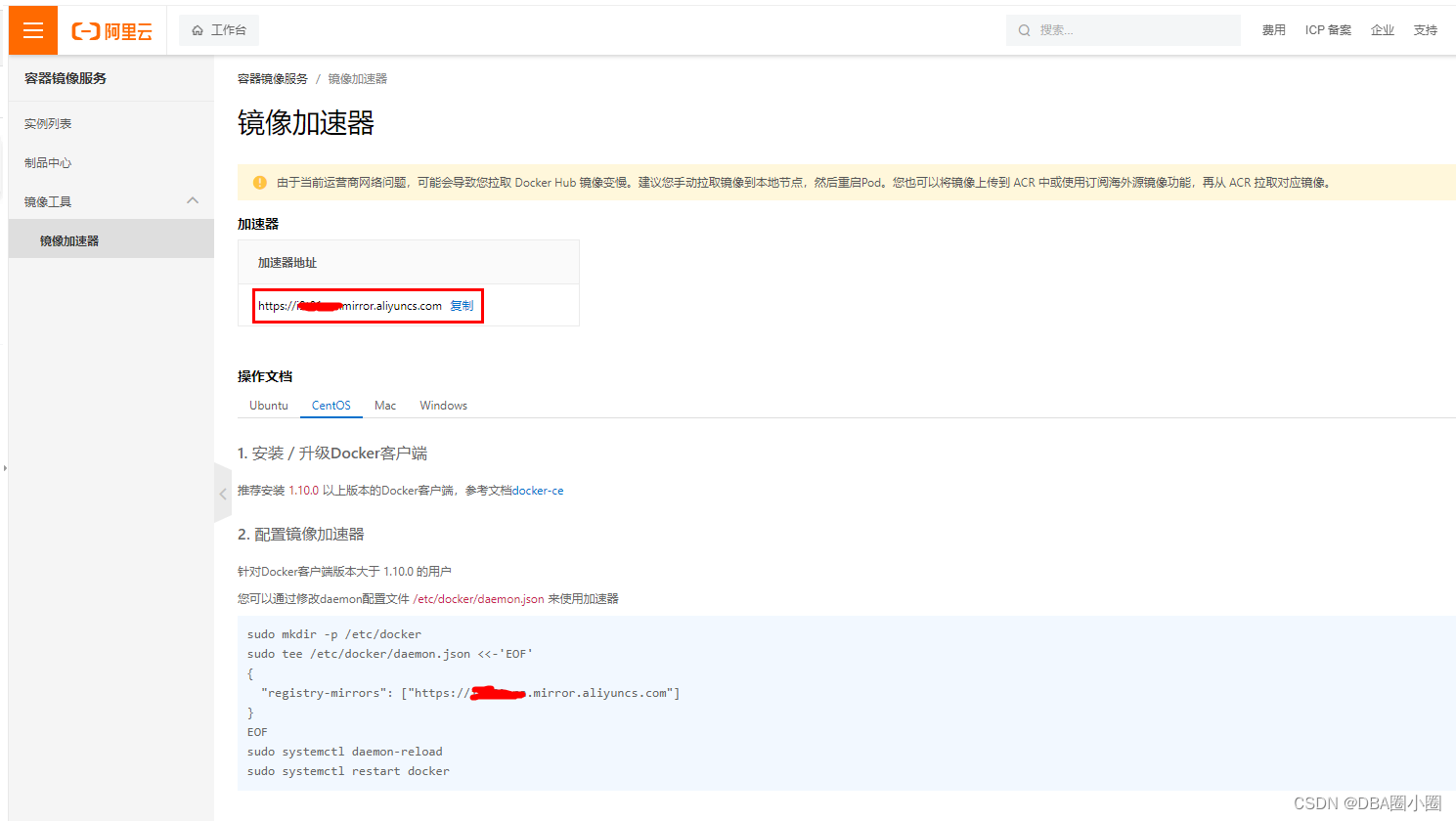
【Docker】从零开始:6.配置镜像加速器
【Docker】从零开始:5.配置镜像加速器 什么是镜像加速器?为什么要配置docker镜像加速器?常见的Docker镜像加速器有哪些?如何申请Docker镜像加速器如何配置Docker镜像加速器 什么是镜像加速器? 镜像加速器是一个位于Docker Hub之…...

The Bridge:从临床数据到临床应用(预测模型总结)
The Bridge:从临床数据到临床应用(预测模型总结) 如果说把临床预测模型比作临床数据和临床应用之间的一座“桥梁”,那它应该包括这样几个环节:模型的构建和评价、模型的概率矫正、模型决策阈值的确定和模型的局部再评价。 模型的构…...
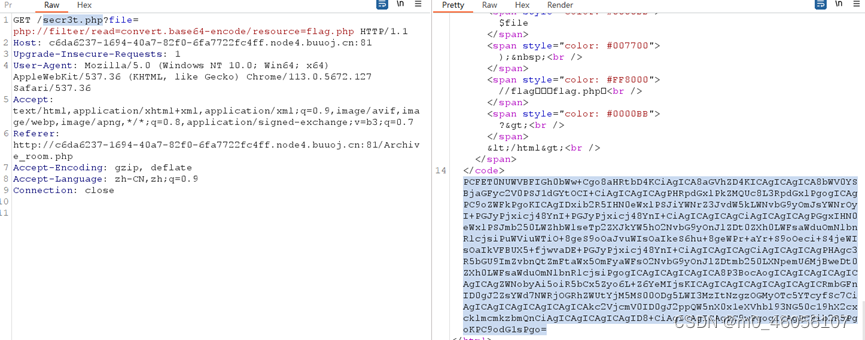
[极客大挑战 2019]Secret File1
[极客大挑战 2019]Secret File1 在bp里面发现secr3t.php 将secr3t.php 直接加在网站后面,发现了有关flag的信息,一个flag.php文件 在遇到flag.php时候,联想到php伪协议,构造伪协议方式 secr3t.php?filephp://filter/readconver…...

如何评估一个论坛或峰会值不值得参加?
现在的论坛和峰会非常多,且都宣传的非常高端,很多人为了不错过机会像赶场一样总在参会路上。但究竟什么样的论坛或峰会才值得一去呢? 评估一个论坛或峰会是否值得参加,需要考虑多个因素。 1、主题与你的兴趣或职业相关性…...

鱼音频生成 API 集成指南
在这篇文章中,我们将介绍如何集成鱼音频生成 API,该 API 能够通过输入提示词来克隆您的声音。这项技术的应用场景包括语音合成、自动化语音助手、以及任何需要个性化语音输出的应用。 环境准备 在使用鱼音频生成 API 之前,您需要先申请相应…...
)
Elasticsearch 实战:使用 boost 参数提高字段相关性得分(全文检索权重优化)
Elasticsearch 实战:使用 boost 参数提高字段相关性得分(全文检索权重优化)前言Elasticsearch boost 参数:提高字段相关性权重完整实战一、核心概念:boost 参数是什么?1.1 定义1.2 作用1.3 boost 工作流程图…...

保姆级教程:用SwitchyOmega+GFWList规则,5分钟搞定Chrome/Firefox代理自动切换
浏览器智能代理管理工具SwitchyOmega的配置与优化指南 在当今互联网环境下,许多用户面临着不同网络资源访问需求的变化。作为一款功能强大的浏览器代理管理扩展,SwitchyOmega能够帮助用户实现智能化的网络访问策略。本文将详细介绍如何从零开始配置这款工…...
)
别再让LaTeX表格乱跑了!用[h]和[htbp]参数精准控制表格位置(附Overleaf实战)
LaTeX表格浮动控制完全指南:从基础参数到高级布局技巧 第一次在LaTeX中插入表格时,很多人都会遇到这样的困惑:明明代码中表格写在某段文字之后,编译后却跑到了页面顶部。这种"表格乱跑"的现象其实是LaTeX浮动体机制在起…...

2026最稳代练创业项目:三角洲护航系统——全端部署+智能匹配,破解获客与信任难题
一、项目核心价值:低成本搭建,100%利润掌控 传统代练模式依赖第三方平台抽成(20%-50%),利润被严重压缩。而三角洲护航系统基于UniAppThinkPHP6架构,支持微信小程序、H5、APP、PC端多端同步,创业…...

Harmonyos状态管理6:@Watch
物联网设备监控系统 - @Watch 演示 核心功能 @Watch 装饰器使用: 为 device 状态添加 @Watch(onDeviceStatusChange) 监听 当设备状态变化时自动触发回调函数 物联网设备数据: 设备信息:ID、名称、类型 状态信息:在线状态、信号强度 传感器数据:温度、湿度、气压 时间信息…...

风险管理化技术风险预警与应急预案
风险管理化技术风险预警与应急预案:构建安全防线 在数字化与智能化快速发展的今天,技术风险已成为企业运营和项目管理中的关键挑战。无论是数据泄露、系统故障,还是网络攻击,技术风险的突发性和破坏性都可能带来巨大损失。风险管…...

JDK1.8环境下的传统系统AI升级:忍者像素绘卷与Java老项目集成
JDK1.8环境下的传统系统AI升级:忍者像素绘卷与Java老项目集成 1. 老系统AI升级的痛点与机遇 很多企业还在使用JDK1.8这样的老版本Java环境运行核心业务系统。这些系统通常已经稳定运行多年,但面临智能化升级的需求。传统系统引入AI能力时,常…...

不止于聊天:用Ollama API和Python打造你的第一个AI小工具
不止于聊天:用Ollama API和Python打造你的第一个AI小工具 当大多数人还在用大语言模型进行简单对话时,聪明的开发者已经将这些能力转化为生产力工具。想象一下:每天重复的代码注释工作可以自动完成,海量技术文档能即时问答&#x…...

从timerfd到epoll:手把手教你打造Linux C++高性能定时器管理器
从timerfd到epoll:构建Linux C高性能定时器管理器的工程实践 在游戏服务器、物联网网关或高频交易系统中,定时器管理往往是性能瓶颈的关键所在。想象一下,当你的服务器需要同时处理数万个玩家技能冷却、状态刷新或订单超时检测时,…...