Kotlin基础——Lambda和函数式编程
Lambda
使用 { } 定义Lamba,调用run运行
run { println(1) }
更常用的为 { 参数 -> 操作 },还可以存储到变量中,把变量作为普通函数对待
val sum = { x: Int, y: Int -> x + y }
println(sum(1, 2))
maxBy()接收一个Lambda,传递如下
class Person(val name: String, val age: Int)
val people = listOf(Person("A", 18), Person("B", 19))println(people.maxBy({ p: Person -> p.age }))
println(people.maxBy() { p: Person -> p.age })println(people.maxBy { p: Person -> p.age }) //只有一个参数,可省略()
println(people.maxBy() { p -> p.age }) //可推导出类型
println(people.maxBy() { it.age }) //只有一个参数且可推导出类型,会自动生成it
Lambda可使用函数参数和局部变量
fun printProblemCounts(response: Collection<String>) {var clientErrors = 0var serverErrors = 0response.forEach {if (it.startsWith("4")) {clientErrors++} else if (it.startsWith("5")) {serverErrors++}}}
成员引用
上面通过Lambda将代码块作为参数传递给函数,若要传递代码块已被封装成函数,则需要传递一个调用该函数的Lambda,如下计算虚岁
class Person(val name: String, val age: Int) {fun getNominalAge(): Int {return age + 1}
}val people = listOf(Person("A", 18), Person("B", 19))
println(people.maxBy { p: Person -> p.getNominalAge() })println(people.maxBy(Person::getNominalAge)) //成员引用,可以省略多余的函数调用
上面是系统为fun getNominalAge()自动生成的成员引用,实际定义应该如下,把函数转换为一个值,从而可以传递它
- 把函数age + 1传递给getNominalAge,通过Person::getNominalAge引用函数
- 直接通过Person::age引用成员
class Person(val name: String, val age: Int) {val getNominalAge = age + 1}val people = listOf(Person("A", 18), Person("B", 19))println(people.maxBy(Person::getNominalAge))println(people.maxBy(Person::age))
若引用顶层函数,则可以省略类名称,以::开头
fun salute() = println("Salute")run(::salute)
集合的函数式API
filter和map
filter遍历集合并筛选指定Lambda返回true的元素,如下遍历偶数
val list = listOf(1, 2, 3, 4)
println(list.filter { it % 2 == 0 })data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 29), Person("B", 31))
println(people.filter { it.age > 30 })
map对集合中的每一个元素应用给定的函数并把结果收集到一个新的集合
val list = listOf(1, 2, 3, 4)
println(list.map { it * it })data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 29), Person("B", 31))
println(people.map(Person::name))
Lambda会隐藏底层操作,如寻找最大年龄,第一种方式会执行100遍,应该避免
data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 29), Person("B", 31))
people.filter { it.age == people.maxBy(Person::age)!!.age }val maxAge = people.maxBy(Person::age)!!.age
people.filter { it.age == maxAge }
对于Map,可调用filterKeys/mapKeys、filterValues/mapValues
val numbers = mapOf(0 to "zero", 1 to "one")
println(numbers.mapValues { it.value.toUpperCase() })
all、any、count、find
all判断集合所有元素是否都满足条件,any判断至少存在一个满足条件的元素
data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 26), Person("B", 27))val max27 = { p: Person -> p.age >= 27 }
println(people.all(max27))
println(people.any(max27))
!all()表示不是所有符合条件,可用any对条件取反来代替,后者更容易理解
val list = listOf(1, 2, 3)
println(!list.all { it == 3 })
println(list.any { it != 3 })
count用于获取满足条件元素的个数,其通过跟踪匹配元素的数量,不关心元素本身,更加高效,若使用size则会创建临时集合存储所有满足条件的元素
data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 26), Person("B", 27))
val max27 = { p: Person -> p.age >= 27 }println(people.count(max27))
println(people.filter(max27).size)
find找到一个满足条件的元素,若有多个则返回第一个,否则返回null,同义函数firstOrNull
data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 26), Person("B", 27))
val max27 = { p: Person -> p.age >= 27 }println(people.find(max27))
println(people.firstOrNull(max27))
groupby
groupby把列表转成分组的map
data class Person(val name: String, val age: Int)val people = listOf(Person("A", 26), Person("B", 27), Person("C", 27))
println(people.groupBy { it.age })
如上打印
{
26=[Person(name=A, age=26)],
27=[Person(name=B, age=27), Person(name=C, age=27)]
}
flatMap、flatten
flatMap根据给定的函数对集合中的每个元素做映射,然后将集合合并,如下打印 [A, 1, B, 2, C, 3]
val strings = listOf("A1", "B2", "C3")
println(strings.flatMap { it.toList() })
如统计图书馆书籍的所有作者,使用Set去除重复元素
data class Book(val title: String, val authors: List<String>)
val books = listOf(Book("A", listOf("Tom")),Book("B", listOf("john")),Book("C", listOf("Tom", "john"))
)
println(books.flatMap { it.authors }.toSet())
flatten用于合并集合,如下打印 [A1, B2, C3]
val strings = listOf("A1", "B2", "C3")
println(listOf(strings).flatten())
序列
序列的好处
map / filter 会创建临时的中间集合,如下就创建了2个
data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 26), Person("B", 27))
println(people.map(Person::age).filter { it > 26 })
而使用序列可以避免创建
println(people.asSequence().map(Person::age).filter { it > 26 }.toList())
惰性操作及性能
序列的中间操作都是惰性的,如下不会有输出
listOf(1, 2, 3, 4).asSequence().map { println("map($it)"); it * it }.filter { println("filter($it)");it % 2 == 0 }
只有当末端操作时才会被调用,如toList()
listOf(1, 2, 3, 4).asSequence().map { println("map($it)"); it * it }.filter { println("filter($it)");it % 2 == 0 }.toList()
- 序列先处理第一个元素,然后再处理第二个元素,故可能有些元素不会被处理,或轮到它们之前就已经返回
- 若不使用序列,则会先求出map的中间集合,对其调用find
println(listOf(1, 2, 3, 4).asSequence().map { print(" map($it)");it * it }.find { it > 3 })
println(listOf(1, 2, 3, 4).map { print(" map($it)");it * it }.find { it > 3 })
如上都打印4,但序列运行到第二个时已找到满足条件,后面不会再执行
map(1) map(2)4
map(1) map(2) map(3) map(4)4
序列的顺序也会影响性能,第二种方式先filter再map,所执行的变换次数更少
data class Person(val name: String, val age: Int)
val people = listOf(Person("A", 26), Person("AB", 27), Person("ABC", 26), Person("AB", 27))println(people.asSequence().map(Person::name).filter { it.length < 2 }.toList())println(people.asSequence().filter { it.name.length < 2 }.map(Person::name).toList())
创建序列
generateSequence根据前一个元素计算下一个元素
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it <= 100 }
println(numbersTo100.sum())
和Java一起使用
函数式接口(SAM接口)
若存在如下Java函数
public class Test {public static void run(int delay, Runnable runnable) {try {Thread.sleep(delay);} catch (InterruptedException e) {e.printStackTrace();}runnable.run();}
}
对于上面接受Runnable的接口,可以传递Lambda或创建实例,前者不会创建新的实例,后者每次都会创建
Test.run(1000, Runnable { println("Kotlin") })
Test.run(1000, { println("Kotlin") })
Test.run(1000) { println("Kotlin") } //最优Test.run(1000, object : Runnable {override fun run() {println("Kotlin")}
})
若Lambda捕捉到了变量,每次调用会创建一个新对象,存储被捕捉变量的值
- 若捕捉了变量,则Lambda会被编译成一个匿名类,否则编译成单例
- 若将Lambda传递给inline函数,则不会创建任何匿名类
fun handleRun(msg: String) {Test.run(1000) { println(msg) }
}
SAM构造方法
大多数情况下,Lambda到函数式接口实例的转换都是自动的,但有时候也需要显示转换,即使用SAM构造方法,其名称和函数式接口一样,接收一个用于函数式接口的Lambda,并返回这个函数式接口的实例
val runnable = Runnable { println("Kotlin") } //SAMrunnable.run()
如下使用SAM构造方法简化监听事件
val listener = View.OnClickListener { view ->val text = when (view.id) {1 -> "1"else -> "-1"}println(text)
}
带接收者的Lambda
with
fun alphabet(): String {val result = StringBuilder()for (letter in 'A'..'Z') {result.append(letter)}result.append("\nover")return result.toString()
}
上面代码多次重复result这个名称,使用with可以简化,内部可用this调用方法或省略
- with接收两个参数,下面例子参数为StringBuilder和Lambda,但把Lambda放在外面
- with把第一个参数转换成第二个参数Lambda的接收者
fun alphabet(): String {val result = StringBuilder()return with(result) {for (letter in 'A'..'Z') {this.append(letter)}append("\nover")toString()}
}
还可以进一步优化
fun alphabet() = with(StringBuilder()) {for (letter in 'A'..'Z') {this.append(letter)}append("\nover")toString()
}
apply
with返回的是接收者对象,而不是执行Lambda的结果,而使用apply()会返回接收者对象,可以对任意对象上使用创建对象实例,还能代替Java的Builder
fun alphabet() = StringBuilder().apply {for (letter in 'A'..'Z') {this.append(letter)}append("\nover")
}.toString()
使用库函数buildString还可以简化上述操作
fun alphabet() = buildString {for (letter in 'A'..'Z') {this.append(letter)}append("\nover")
}
相关文章:

Kotlin基础——Lambda和函数式编程
Lambda 使用 { } 定义Lamba,调用run运行 run { println(1) }更常用的为 { 参数 -> 操作 },还可以存储到变量中,把变量作为普通函数对待 val sum { x: Int, y: Int -> x y } println(sum(1, 2))maxBy()接收一个Lambda,传…...
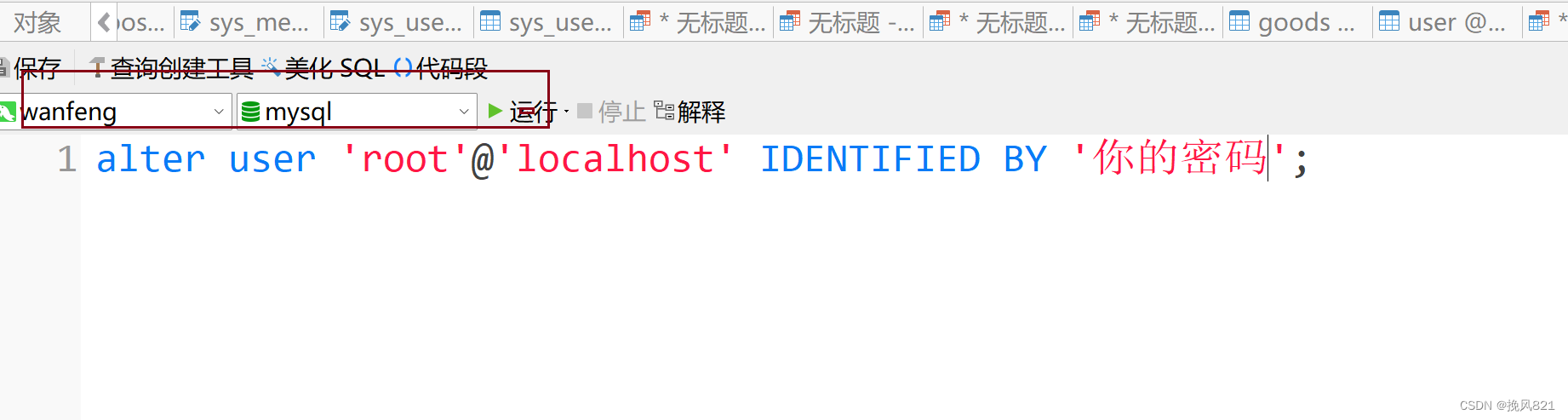
mysql忘记密码,然后重置
数据库版本8.0.26 只针对以下情况 mysql忘记了密码,但是你navicat之前连接上了 解决方法: 第一步,选中mysql这个数据库,点击新建查询 第二步:重置密码 alter user rootlocalhost IDENTIFIED BY 你的密码; 然后就可…...

linux centos系统命令安装
Zip unzip 命令安装下载 centos 命令常用常用下载 https://rpmfind.net/linux/rpm2html/search.php?queryzip%28x86-64%29&submitSearch…&system&arch 在线安装zip命令 Centos用yum安装的话用下面的命令安装 yum install -y unzip zipUbuntu的的系统可以用下…...
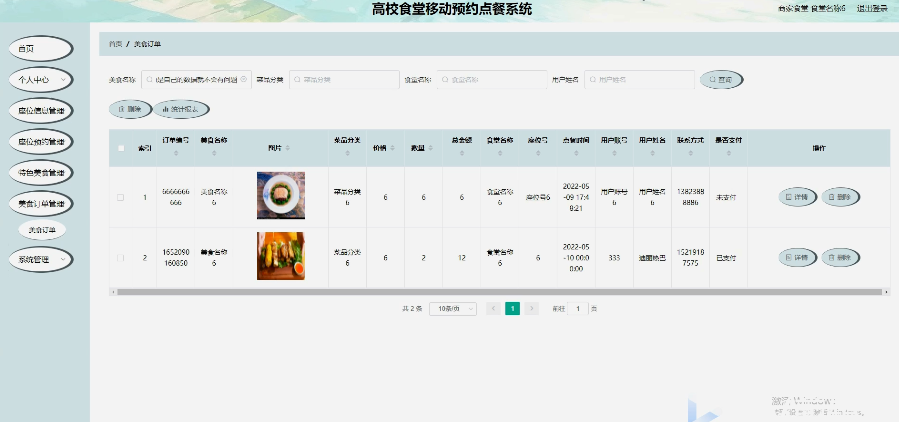
基于springboot实现高校食堂移动预约点餐系统【项目源码】计算机毕业设计
基于springboot实现高校食堂移动预约点餐系统演示 Java语言简介 Java是由SUN公司推出,该公司于2010年被oracle公司收购。Java本是印度尼西亚的一个叫做爪洼岛的英文名称,也因此得来java是一杯正冒着热气咖啡的标识。Java语言在移动互联网的大背景下具备…...

栈和队列OJ题目——C语言
目录 LeetCode 20、有效的括号 题目描述: 思路解析: 解题代码: 通过代码: LeetCode 225、用队列实现栈 题目描述: 思路解析: 解题代码: 通过代码: LeetCode 232、用栈…...

System-V共享内存和基于管道通信实现的进程池
文章目录 一.进程间通信:进程间通信的本质: 二.Linux管道通信匿名管道:关于管道通信的要点:基于匿名管道构建进程池: 三.System-V共享内存共享内存和命名管道协同通信 参考Linux内核源码版本------linux-2.4.3 一.进程间通信: 操作系统中,为了保证安全性,进程之间具有严格的独…...

Python武器库开发-前端篇之CSS基本语法(三十)
前端篇之CSS基本语法(三十) CSS简介 CSS(层叠样式表)是一种用于描述网页外观和布局的样式表语言。它与 HTML 一起,帮助开发者对网页进行美化和布局。CSS通过定义网页元素的颜色、字体、大小、背景、边框等属性,使网页变得更加美…...
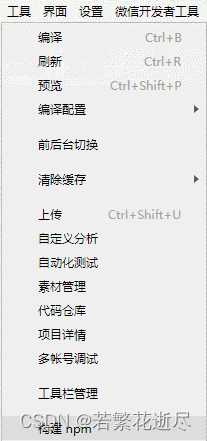
微信小程序实现类似Vue中的computed、watch功能
微信小程序实现类似Vue中的computed、watch功能 构建npm使用 构建npm 创建包管理器 进入小程序后,打开终端,点击顶部“视图” - “终端” 新建终端 使用 npm init -y初始化包管理器,生成一个package.json文件 安装 npm 包 npm install --…...

[JVM] 美团二面,说一下JVM数据区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。这些区域有不同的用途。 文章目录 线程私有的数据区域1. 程序计数器2. Java 虚拟机栈3. 本地方法栈 线程共享的数据区域1. Java 堆2. 方法区3. 运行时常量池4. 直接内存 线程私有的数据区域 …...

【React】useReducer
让 React 管理多个相对关联的状态数据 import { useReducer } from "react" // 1. 定义reducer函数,根据不同的action返回不同的状态 function reducer(state, action) {switch (action.type) {case ADD:return state action.payloadcase SUB:return st…...

leetcode刷题详解二
160. 相交链表 本质上是走过自己的路,再走过对方的路,这是求两个链表相交的方法 ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {//本质上是走过自己的路,再走过对方的路if(headA NULL|| headB NULL){return NULL;}Lis…...

利用opencv/暗通道方法检测图像是否有雾-利用opencv/暗通道方法对深度学习目标检测算法结果进行二次识别提高准确率
目录 1 Python版本 2 C++版本 本来利用yolov5检测浓雾的,但是发现yolov5的检测结果会把一些正常天气检测成雾天,这种时候其实可以通过增加正常类,也就是将正常天气被误检成浓雾的图片当成一个正常类别去训练,但是不想标注图片,也不想重新训练算法了,因此想是不是可以用…...
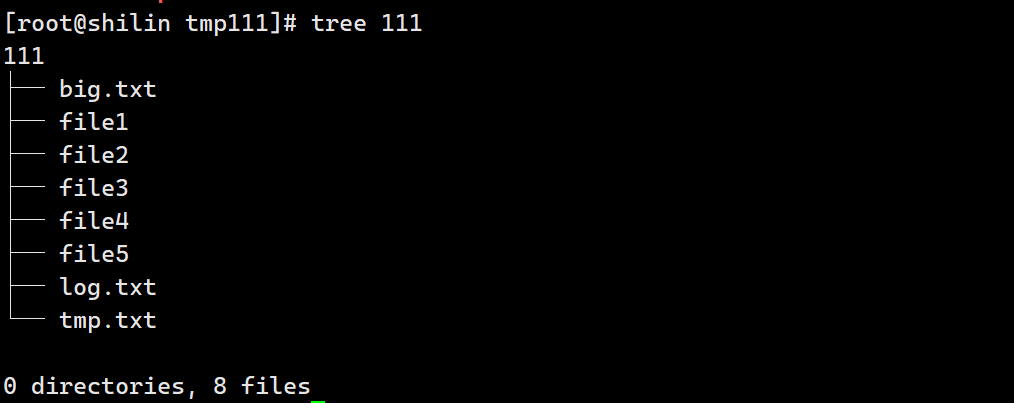
Linux | 重定向 | 文件概念 | 查看文件 | 查看时间 | 查找文件 | zip
Linux | 重定向 | 文件概念 | 查看文件 | 查看时间 | 查找文件 | zip 文章目录 Linux | 重定向 | 文件概念 | 查看文件 | 查看时间 | 查找文件 | zip一、more1.1 输出重定向>和>>1.2 输入重定向< 二、 再谈一切皆文件三、less指令【重要】四、head指令五、tail指令…...

【广州华锐互动】利用VR体验环保低碳生活能带来哪些教育意义?
随着科技的不断发展,虚拟现实(VR)技术已经逐渐走进了我们的生活。从游戏娱乐到教育培训,VR技术的应用范围越来越广泛。而在这个追求绿色、环保的时代,VR技术也为我们带来了一种全新的环保低碳生活方式。让我们一起走进…...

python爬虫中 HTTP 到 HTTPS 的自动转换
前言 在当今互联网世界中,随着网络安全的重要性日益增加,越来越多的网站采用了 HTTPS 协议来保护用户数据的安全。然而,许多网站仍然支持 HTTP 协议,这就给我们的网络爬虫项目带来了一些挑战。为了应对这种情况,我们需…...

卷积神经网络(CNN)识别验证码
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据4.标签数字化 二、构建一个tf.data.Dataset1.预处理函数2.加载数据3.配置数据 三、搭建网络模型四、编译五、训练六、模型评估七、保存和加载模型八、预测 …...
使用 PyODPS 采集神策事件数据
文章目录 一、前言二、数据采集、处理和入库2.1 获取神策 token2.2 请求神策数据2.3 数据处理-面向数组2.4 测试阿里云 DataFrame 入库2.5 调度设计与配置2.6 项目代码整合 三、小结四、花絮-避坑指南第一坑:阿里云仅深圳节点支持神策数据第二坑:神策 To…...
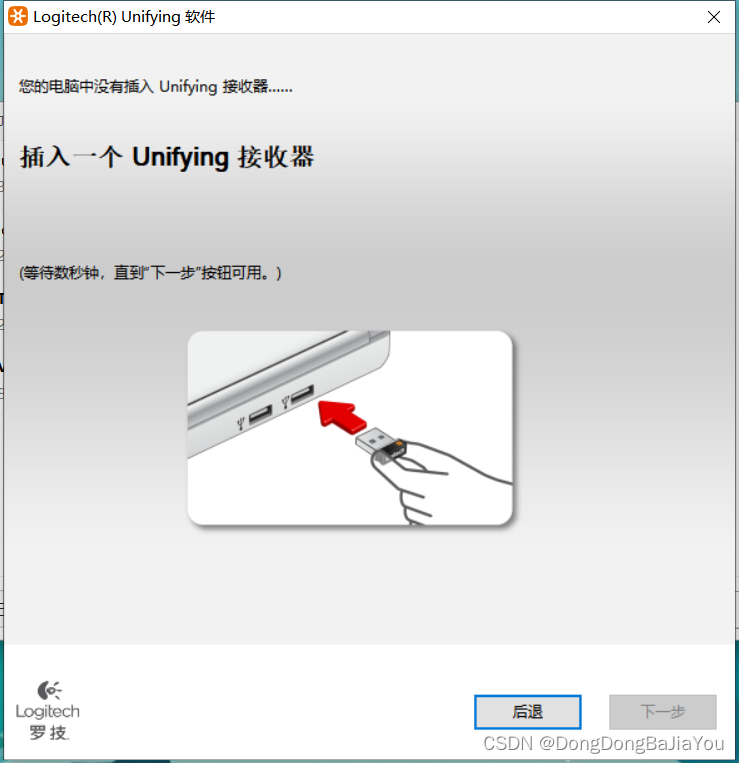
罗技M590鼠标usb优联连接不上
手里有一个罗技M590鼠标从18年4月一直用到现在,质量很好,除了滚轮有些松别的没毛病。最近一台笔记本电脑办公不太够用,又领了一个台式机,就想到M590支持双模连接,并且支持Flow,就把usb优联接收器从电池仓拿…...
: 基于逻辑回归的分类预测)
天池 机器学习算法(一): 基于逻辑回归的分类预测
pytorch实战 课时7 神经网络 MSE的缺点:偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练时,偏导值几乎消失,模型速度非常慢。 交叉熵损失函数:平方损失则过于严格,需要使用更合…...
45岁后,3部位“越干净”,往往身体越健康,占一个也要恭喜!
众所周知,人的生命有长有短,而我们的身体健康状态,也同样会受到年龄的影响,就身体的年龄层次而言,往往需要我们用身体内部的干净程度来维持,换句话说就是:若是你的身体内部越干净,那…...

像素史诗·智识终端Java开发环境快速配置:基于镜像的一站式解决方案
像素史诗智识终端Java开发环境快速配置:基于镜像的一站式解决方案 1. 为什么选择镜像部署Java开发环境 对于Java开发者来说,环境配置一直是个头疼的问题。不同版本的JDK、Maven仓库配置、IDE插件安装...这些繁琐的准备工作往往要耗费半天甚至更长时间。…...

Unity网络开发革命:Netcode for GameObjects完整入门指南
Unity网络开发革命:Netcode for GameObjects完整入门指南 【免费下载链接】com.unity.netcode.gameobjects Netcode for GameObjects is a high-level netcode SDK that provides networking capabilities to GameObject/MonoBehaviour workflows within Unity and …...

从“特洛伊咖啡壶”到华为LiteOS:一个技术博主眼中的物联网发展简史与实战入门
从“特洛伊咖啡壶”到华为LiteOS:一个技术博主眼中的物联网发展简史与实战入门 1991年剑桥大学计算机实验室的咖啡壶,可能连它的发明者都没想到会成为物联网史上的里程碑。那台通过摄像头监控咖啡状态的简陋装置,如今看来像极了物联网的"…...

解决Leaflet加载天地图的最大痛点:突破17级缩放限制的两种实战方案
突破Leaflet中天地图17级缩放限制的工程实践 第一次在项目中集成天地图时,那种流畅的加载体验让人印象深刻——直到用户突然问:"为什么这个区域无法继续放大了?"这才发现Leaflet默认的17级缩放限制成了项目交付的绊脚石。作为国内主…...

【Dify 2026微调实战白皮书】:首发业内唯一支持LoRA+QLoRA+Adapter三模协同的端到端微调框架
第一章:Dify 2026微调框架全景概览Dify 2026 是面向企业级大模型应用落地的下一代低代码微调框架,聚焦于“可解释性微调”与“多粒度适配”两大核心能力。它不再将微调视为黑盒参数更新过程,而是通过声明式配置、运行时干预和反馈闭环机制&am…...

SVG 文本:设计与实现详解
SVG 文本:设计与实现详解 引言 SVG(可缩放矢量图形)文本是网页设计中常用的元素之一,它允许开发者创建可缩放的文本,并具有丰富的样式和动画效果。本文将详细介绍SVG文本的设计与实现,包括其基本概念、使用方法以及在实际项目中的应用。 SVG文本的基本概念 1. SVG简介…...
)
别再手动算权重了!用Java实现PCA自动赋权,搞定多指标评价(附完整代码)
Java实战:用PCA算法实现多指标自动赋权系统 电商平台商品排序、员工绩效考核、金融风险评估...这些场景都需要对多个指标进行综合评价。传统手动赋权方法不仅耗时耗力,还容易带入主观偏差。今天我们就用Java实现一套基于PCA(主成分分析&#…...

Bruno Simon Folio 2019音效设计:终极空间音频与交互反馈指南
Bruno Simon Folio 2019音效设计:终极空间音频与交互反馈指南 【免费下载链接】folio-2019 项目地址: https://gitcode.com/gh_mirrors/fo/folio-2019 Bruno Simon Folio 2019是一个融合视觉与听觉体验的创新项目,其音效设计系统通过精准的交互反…...

从特征提取到微调:为什么你的BERT在MELD情感分类上效果差?我来帮你诊断
从特征提取到微调:为什么你的BERT在MELD情感分类上效果差?我来帮你诊断 当你第一次尝试用BERT处理MELD情感分类任务时,是否遇到过这样的困惑:明明使用了强大的预训练模型,F1分数却比论文报告的低了10%甚至更多…...

Bootcamp数据模型设计:如何构建高效的企业社交关系网络
Bootcamp数据模型设计:如何构建高效的企业社交关系网络 【免费下载链接】bootcamp An enterprise social network 项目地址: https://gitcode.com/gh_mirrors/bo/bootcamp Bootcamp作为企业社交网络平台,其核心价值在于构建高效的信息交流与协作关…...