回归算法优化过程推导
假设存在一个数据集,包含工资、年龄及贷款额度三个维度的数据。我们需要根据这个数据集进行建模,从而在给定工资和年龄的情况下,实现对贷款额度的预测。其中,工资和年龄是模型构建时的两个特征,额度是模型输出的目标值。
| 工资 | 年龄 | 额度 |
|---|---|---|
| 4000 | 25 | 20000 |
| 8000 | 30 | 70000 |
| 5000 | 28 | 35000 |
| 7500 | 33 | 50000 |
| 12000 | 40 | 85000 |
| … | … | … |
我们可以根据数据集和相关需求进行公式建模:
y = θ 0 + θ 1 x 1 + θ 2 x 2 + ε = θ T x + ε y = {\theta }_{0} + {\theta }_{1}x_1 + {\theta }_{2}x_2 + \varepsilon = {\theta }^{T}x + \varepsilon y=θ0+θ1x1+θ2x2+ε=θTx+ε
其中, θ 0 \theta _0 θ0 为偏置项, θ 1 \theta _1 θ1、 θ 2 \theta _2 θ2 为两个特征 x 1 x_1 x1、 x 2 x_2 x2 的权重项, ε \varepsilon ε 为误差项; θ T \theta ^T θT 为一个行向量, x x x 为包含特征 x 1 x_1 x1、 x 2 x_2 x2 的矩阵。
θ 1 x 1 + θ 2 x 2 {\theta }_{1}x_1 + {\theta }_{2}x_2 θ1x1+θ2x2 在三维空间中表示的平面会尽可能去拟合所有数据点(目标值),但是这个平面并不一定是拟合度最高的,也许该平面沿着 y y y 维度向上或向下平移一点距离所得到的新平面才是拟合度最高的,因此我们会在该拟合表达式中加上一个偏置项 θ 0 \theta _0 θ0。
θ 0 + θ 1 x 1 + θ 2 x 2 {\theta }_{0} + {\theta }_{1}x_1 + {\theta }_{2}x_2 θ0+θ1x1+θ2x2 是给定 x 1 x_1 x1、 x 2 x_2 x2 值时,对目标值的预测,预测值与真实值之间必然会存在一个误差,因此我们在该表达式中还需加上一个误差项 ε \varepsilon ε。

对于一个样本而言,公式可以写成如下形式:
y ( i ) = θ T x ( i ) + ε ( i ) ⇒ ε ( i ) = y ( i ) − θ T x ( i ) y^{(i)} = {\theta }^{T}x^{(i)} + \varepsilon ^{(i)} \Rightarrow \varepsilon ^{(i)} = y^{(i)} - {\theta }^{T}x^{(i)} y(i)=θTx(i)+ε(i)⇒ε(i)=y(i)−θTx(i)
其中,每个样本的误差 ε ( i ) \varepsilon ^{(i)} ε(i) 都是独立同分布的,服从均值为 0 0 0 的高斯分布。
高斯分布的概率密度函数如下所示:
f ( x ) = 1 2 π σ ⋅ e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sqrt{2\pi }\sigma }·{e}^{-\frac{{(x-\mu )}^{2}}{2{\sigma }^{2}}} f(x)=2πσ1⋅e−2σ2(x−μ)2
把误差带入进去,可得到公式:
f ( ε ( i ) ) = 1 2 π σ ⋅ e − ( ε ( i ) ) 2 2 σ 2 = 1 2 π σ ⋅ e − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 f({\varepsilon }^{(i)}) = \frac{1}{\sqrt{2\pi }\sigma }·{e}^{-\frac{{({\varepsilon }^{(i)})}^{2}}{2{\sigma }^{2}}} = \frac{1}{\sqrt{2\pi }\sigma }·{e}^{-\frac{{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2}}{2{\sigma }^{2}}} f(ε(i))=2πσ1⋅e−2σ2(ε(i))2=2πσ1⋅e−2σ2(y(i)−θTx(i))2
该公式表示误差趋于 0 0 0 的概率,或者说预测值 θ T x ( i ) {\theta }^{T}x^{(i)} θTx(i) 趋近于真实值的概率,这个概率自然是越大越好。

我们的最终目的是要求出最合适的 θ 0 \theta _0 θ0、 θ 1 \theta _1 θ1、 θ 2 \theta _2 θ2,而似然函数是统计学中用于估计参数的一个函数。因此在给出观测数据的前提下,我们可以利用似然函数来推断出未知的参数值。
构建的似然函数如下所示:
L ( θ ) = ∏ i = 1 m 1 2 π σ ⋅ e − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 L(\theta ) = \displaystyle\prod_{i=1}^{m}\frac{1}{\sqrt{2\pi }\sigma }·{e}^{-\frac{{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2}}{2{\sigma }^{2}}} L(θ)=i=1∏m2πσ1⋅e−2σ2(y(i)−θTx(i))2
其中,在各个样本都符合独立同分布的情况下,联合概率密度就等于各样本概率密度的乘积,因此这里用了累乘。
想在乘法中求解出参数 θ \theta θ,也许是一个比较难的事,但如果能把乘法转换成加法,对于参数的求解可能就容易了许多。鉴于此,我们可以使用对数似然函数来进行参数的求解。
构建的对数似然函数如下所示:
l o g L ( θ ) = l o g ∏ i = 1 m 1 2 π σ ⋅ e − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 logL(\theta ) = log\displaystyle\prod_{i=1}^{m}\frac{1}{\sqrt{2\pi }\sigma }·{e}^{-\frac{{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2}}{2{\sigma }^{2}}} logL(θ)=logi=1∏m2πσ1⋅e−2σ2(y(i)−θTx(i))2
将上述公式进行展开化简:
l o g L ( θ ) = ∑ i = 1 m l o g 1 2 π σ ⋅ e − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 = m l o g 1 2 π σ + ∑ i = 1 m l o g e − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 = m l o g 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 m ( y ( i ) − θ T x ( i ) ) 2 logL(\theta ) = \displaystyle\sum_{i=1}^{m}log\frac{1}{\sqrt{2\pi }\sigma }·{e}^{-\frac{{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2}}{2{\sigma }^{2}}} \\= mlog\frac{1}{\sqrt{2\pi }\sigma } + \displaystyle\sum_{i=1}^{m}log{e}^{-\frac{{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2}}{2{\sigma }^{2}}} \\= mlog\frac{1}{\sqrt{2\pi }\sigma } - \frac{1}{{\sigma }^{2}}·\frac{1}{2}\displaystyle\sum_{i=1}^{m}{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2} logL(θ)=i=1∑mlog2πσ1⋅e−2σ2(y(i)−θTx(i))2=mlog2πσ1+i=1∑mloge−2σ2(y(i)−θTx(i))2=mlog2πσ1−σ21⋅21i=1∑m(y(i)−θTx(i))2
我们要让似然函数越大越好,因此上述公式等价于让下述目标函数的目标值越小越好:
J ( θ ) = 1 2 ∑ i = 1 m ( y ( i ) − θ T x ( i ) ) 2 J(\theta ) = \frac{1}{2}\displaystyle\sum_{i=1}^{m}{(y^{(i)} - {\theta }^{T}x^{(i)})}^{2} J(θ)=21i=1∑m(y(i)−θTx(i))2
我们首先对上述目标函数进行展开:
J ( θ ) = 1 2 ( X θ − y ) T ( X θ − y ) = 1 2 ( θ T X T − y T ) ( X θ − y ) = 1 2 ( θ T X T X θ − θ T X T y − y T X θ + y T y ) = 1 2 ( 2 X T X θ − X T y − ( y T X ) T ) = X T X θ − X T y J(\theta ) = \frac{1}{2}{(X\theta - y)}^{T}(X\theta - y) \\ = \frac{1}{2}{(\theta ^TX^T - y^T)}(X\theta - y) \\ = \frac{1}{2}(\theta ^TX^TX\theta - \theta ^TX^Ty - y^TX\theta + y^Ty) \\ = \frac{1}{2}(2X^TX\theta - X^Ty - (y^TX)^T) \\ = X^TX\theta - X^Ty J(θ)=21(Xθ−y)T(Xθ−y)=21(θTXT−yT)(Xθ−y)=21(θTXTXθ−θTXTy−yTXθ+yTy)=21(2XTXθ−XTy−(yTX)T)=XTXθ−XTy
根据展开的公式推出参数值:
θ = ( X T X ) − 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)−1XTy
通过这种方法可以进行参数值 θ \theta θ 的求解,但是在上式中, X T X X^TX XTX 不一定是可逆的,也就是说不一定能求解出参数值 θ \theta θ。
鉴于上述问题,我们需要考虑使用其他方法来求解合适的 θ \theta θ,而机器学习就是非常好的方法。一个常规的思路是,我们喂给机器一堆数据,然后告诉它该用什么样的方式学习,并让它朝着这个方向去做(目标/损失函数),每一次学习一点,经过多次迭代优化后,最终收敛至一个稳定的状态。
在对目标函数进行求解时,通常会用到梯度下降法来进行优化。梯度下降是一种常用的优化算法,用于求解目标函数的最小值或最大值。它的基本思想是通过迭代的方式,沿着目标函数的负梯度方向逐步更新参数,以逐渐接近最优解。具体来说,对于一个可微的目标函数,我们希望找到使其取得最小值的参数。梯度下降通过以下步骤进行迭代更新:
- 初始化参数:选择初始参数值作为起点
- 计算梯度:计算目标函数关于参数的梯度(导数)
- 更新参数:将当前参数值沿着负梯度方向移动一小步,更新参数值
- 重复步骤 2 和步骤 3,直到满足停止条件(如达到最大迭代次数或梯度变化很小)
梯度方向指示了函数上升最快的方向,而负梯度方向则指示了函数下降最快的方向。因此,通过不断更新参数,梯度下降算法可以朝着函数取得最小值的方向逐渐迭代,最终接近或达到最优解。
梯度下降算法有多种变体,如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-Batch Gradient Descent),它们在每次更新参数时所使用的样本数量不同。这些变体具有不同的优缺点,适用于不同的问题和数据集规模。
回到上面的问题,此时的目标/损失函数如下所示:
J ( θ ) = 1 2 m ∑ i = 1 m ( y i − θ T x i ) 2 J(\theta ) = \frac{1}{2m}\displaystyle\sum_{i=1}^{m}(y^i - \theta ^Tx^i)^2 J(θ)=2m1i=1∑m(yi−θTxi)2
当使用批量梯度下降时,目标函数关于第 j j j 个参数的梯度可以写成如下形式:
δ J ( θ ) δ θ j = − 1 m ∑ i = 1 m ( y i − θ T x i ) x j i \frac{\delta J(\theta)}{\delta \theta _j} = -\frac{1}{m}\displaystyle\sum_{i=1}^{m}(y^i - \theta ^Tx^i){x}_{j}^{i} δθjδJ(θ)=−m1i=1∑m(yi−θTxi)xji
更新参数后,新的参数可以表示成如下形式:
θ j ′ = θ j + α ⋅ 1 m ∑ i = 1 m ( y i − θ T x i ) x j i {\theta }_{j}^{'} = \theta _j + \alpha · \frac{1}{m}\displaystyle\sum_{i=1}^{m}(y^i - \theta ^Tx^i){x}_{j}^{i} θj′=θj+α⋅m1i=1∑m(yi−θTxi)xji
当使用随机梯度下降时,目标函数关于第 j j j 个参数的梯度可以写成如下形式:
δ J ( θ ) δ θ j = − ( y i − θ T x i ) x j i \frac{\delta J(\theta)}{\delta \theta _j} = -(y^i - \theta ^Tx^i){x}_{j}^{i} δθjδJ(θ)=−(yi−θTxi)xji
更新参数后,新的参数可以表示成如下形式:
θ j ′ = θ j + α ⋅ ( y i − θ T x i ) x j i {\theta }_{j}^{'} = \theta _j + \alpha · (y^i - \theta ^Tx^i){x}_{j}^{i} θj′=θj+α⋅(yi−θTxi)xji
当使用小批量梯度下降时,目标函数关于第 j j j 个参数的梯度可以写成如下形式:
δ J ( θ ) δ θ j = 1 10 ∑ k = i i + 9 ( θ T x k − y k ) x j k \frac{\delta J(\theta)}{\delta \theta _j} = \frac{1}{10}\displaystyle\sum_{k=i}^{i+9}(\theta ^Tx^k - y^k){x}_{j}^{k} δθjδJ(θ)=101k=i∑i+9(θTxk−yk)xjk
更新参数后,新的参数可以表示成如下形式:
θ j ′ = θ j − α ⋅ 1 10 ∑ k = i i + 9 ( θ T x k − y k ) x j k {\theta }_{j}^{'} = \theta _j - \alpha · \frac{1}{10}\displaystyle\sum_{k=i}^{i+9}(\theta ^Tx^k - y^k){x}_{j}^{k} θj′=θj−α⋅101k=i∑i+9(θTxk−yk)xjk
批量梯度下降容易得到最优解,但是由于每次都要考虑所有样本,因此速度很慢;随机梯度下降每次找一个样本,迭代速度快,但不一定每次都朝着收敛的方向前进(存在离群点、噪声点等干扰);小批量梯度下降比较实用,用的也比较多。
相关文章:
回归算法优化过程推导
假设存在一个数据集,包含工资、年龄及贷款额度三个维度的数据。我们需要根据这个数据集进行建模,从而在给定工资和年龄的情况下,实现对贷款额度的预测。其中,工资和年龄是模型构建时的两个特征,额度是模型输出的目标值…...
某高品质房产企业:借助NineData平台,统一数据库访问权限,保障业务安全
该企业是中国领先的优质房产品开发及生活综合服务供应商。在 2022 年取得了亮眼的业绩表现,销售额市场占有率跻身全国前五。业务涵盖房产开发、房产代建、城市更新、科技装修等多个领域。 2023 年,该企业和玖章算术(浙江)科技有限…...
Arduio开发STM32所面临的风险
据说micro_ros用到了arduino,然后用arduino搞stm32需要用到这个Arduino STM32的东西,然后这里申明了:这些代码没有经过严格测试,如果是向心脏起搏器,自动驾驶这样要求严格的的情况下,这个东西不能保证100%不发生问题&a…...

精准人脉引流软件的开发流程与涉及到的技术
一、精准人脉引流软件的开发流程 1. 确定需求:首先,我们需要明确软件的需求,包括目标用户、功能需求、性能需求等。这些需求将直接影响到软件的开发方向和最终效果。 2. 系统设计:根据需求,进行系统设计,…...
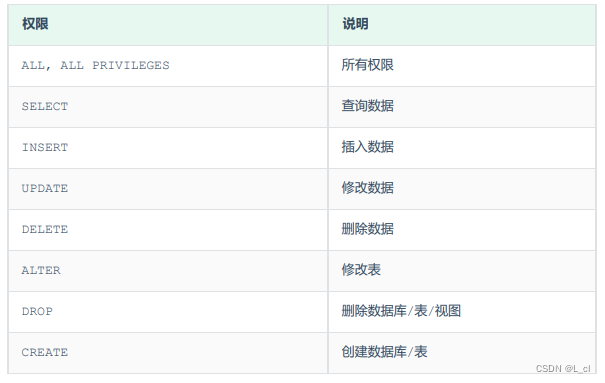
Mysql数据库 20.DCL数据控制语言
因这类SQL语言开发人员操作较少,主要是数据库管理员(DBA)使用,所以前文没有提及,这篇文章进行补充说明 DCL数据控制语言 用来管理数据库用户,控制数据库的访问权限 1.管理用户 1.1 查询用户 select * f…...

使用CMake交叉编译Arm Linux程序
下载安装aarch64-linux-gnu-gcc arm交叉编译工具链 apt-get install aarch64-linux-gnu-gccapt-get install aarch64-linux-gnu-gcc创建编译目录构建makefle 注意,工具链文件的指定一定要紧跟cmake命令之后,不能放到 … 后面构建arm架构cmake mkdir arm…...
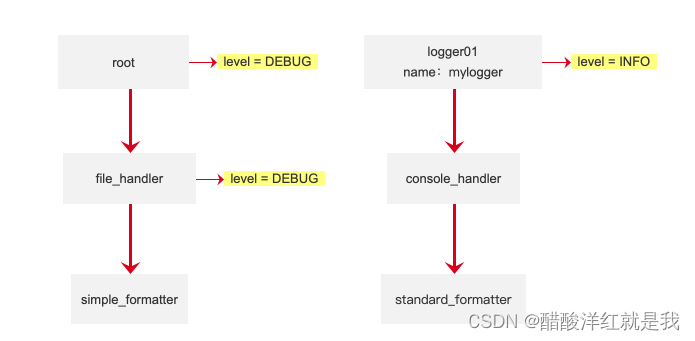
训练日志——logging
目录 基础使用日志的6个级别打印日志修改打印级别 高级应用logging的组成记录器Loggers处理器Handlers过滤器Filterformatter格式创建关联打印日志 配置文件参考 基础使用 日志的6个级别 打印日志 import logginglogging.debug(调试日志) logging.info(消息日志) logging.war…...
尺度为什么是sigma?
我们先看中值滤波和均值滤波。 以前,我认为是一样的,没有区分过。 他们说,均值滤波有使图像模糊的效果。 中值滤波有使图像去椒盐的效果。为什么不同呢?试了一下,果然不同,然后追踪了一下定义。 12345&…...

迭代器模式
自定义 Counter 结构体类型,并实现迭代器。其他语言的场景,读取数据库行数据时,使用的就是迭代器。我们使用for语言遍历数组,也是一种迭代。 结构体对象实现 Iterator trait,创建自定义的迭代器,只需要实现…...

C++ 修饰符、存储类、运算符、循环、判断
一、C修饰符类型: C允许在char、int、double数据类型前放置修饰符。 数据类型修饰符: ◆ signed:表示变量可以存储负数。对于整型变量来说,signed 可以省略,因为整型变量默认为有符号类型。 ◆ unsigned࿱…...
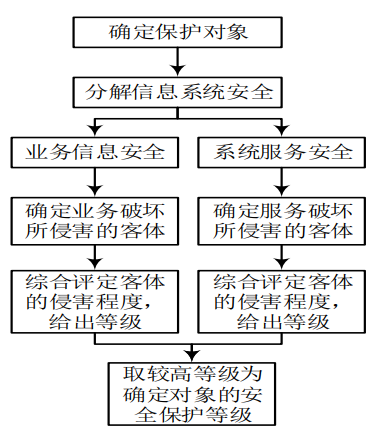
2023 hnust 湖南科技大学 信息安全管理课程 期中考试 复习资料
前言 ※老师没画重点的补充内容★往年试卷中多次出现或老师提过的,很可能考该笔记是奔着及格线去的,不是奔着90由于没有听过课,部分知识点不一定全,答案不一定完全正确 题型 试卷有很多题是原题 判断题(PPTÿ…...

N皇后问题解的个数
暴力递归 #include <stdio.h>int count0,a[15],flag; void queen(int,int); int main(){int n;scanf("%d",&n);queen(n,n);printf("%d",count); } void queen(int n,int n0){if(n<1){flag1;for(int i1;i<n0;i){for(int j1;j<n0;j){if(…...
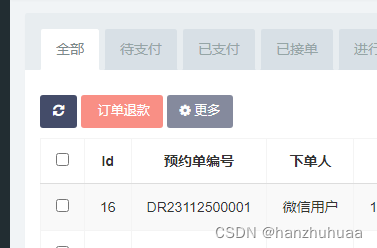
php订单发起退款(余额和微信支付)
index.html <a class="btn btn-danger btn-change btn-tuikuan btn-disabled" href="javascript:;"><i class="fa fa-tuikuan"></i> 订单退款</a>-->order.js // 为表格绑定事件Table.api.bindevent(table);//退款…...
【SpringCloud】认识微服务、服务拆分以及远程调用
SpringCloud 1.认识微服务 1.1单体架构 单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署 单体架构的优缺点: 优点: 架构简单,部署成本低 缺点: 耦合度高(维护困难&#x…...
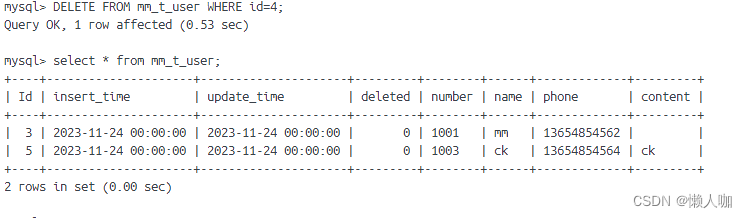
Mysql基础操作(命令行)
文章目录 Mysql基础操作(命令行)背景创建数据库选择数据库查看所有表查看表结构向表插入数据插入第一条插入第二条插入第三条 查询表数据修改表数据删除表数据 Mysql基础操作(命令行) 背景 docker安装mysql8,映射本地…...

网站遇到DDOS攻击怎么办?
最近我的网站不幸又遇到了几乎是我见到过的最大一次 DDoS 攻击,并且几乎是没有反映的时间,直接接到腾讯云的短信通知“运营商封堵”,直接造成几个小时无法访问,解封后再次遭受到大流量 DDoS 攻击,再次被“腾讯云平台封…...

中间件渗透测试-Server2131(解析+环境)
B-10:中间件渗透测试 需要环境的加qq 任务环境说明: 服务器场景:Server2131(关闭链接) 服务器场景操作系统:Linux Flag值格式:Flag{Xxxx123},括…...

探究Kafka原理-2.Kafka基本命令实操
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

Linux网卡没有eth0显示ens33原因以及解决办法
原因 首先说明一下eth0 与 ens33的关系: 目前的主流网卡为使用以太网络协定所开发出来的以太网卡(Ethernet),因此我们Linux就称呼这种网络接口为ethN(N为数字)。 举个栗子:就是说主机上面有一张以太网卡,因此主机的网络接口就是…...
1.前端--基本概念【2023.11.25】
1.网站与网页 网站是网页集合。 网页是网站中的一“页”,通常是 HTML 格式的文件,它要通过浏览器来阅读。 2.Web的构成 主要包括结构(Structure) 、表现(Presentation)和行为(Behaviorÿ…...

告别VNC和TeamViewer?用向日葵命令行版远程管理Linux服务器的另类思路
Linux服务器远程管理新选择:向日葵命令行版深度评测与实战指南 在Linux服务器管理领域,远程控制工具的选择往往决定了运维效率的高低。传统方案如VNC和TeamViewer虽然广为人知,但它们在资源占用、连接稳定性以及功能完整性方面存在明显短板。…...
)
从VOC到YOLO:一文搞懂目标检测数据集格式转换(附Python脚本详解与YOLOv5配置)
从VOC到YOLO:目标检测数据集格式转换实战指南 1. 理解数据集格式差异的本质 目标检测任务中,数据标注格式直接影响模型训练效果。Pascal VOC和YOLO采用完全不同的标注逻辑,这种差异源于它们设计时的不同考量。 VOC格式采用XML结构存储标注信息…...

TikTok评论数据采集工具:三步轻松获取完整评论信息
TikTok评论数据采集工具:三步轻松获取完整评论信息 【免费下载链接】TikTokCommentScraper 项目地址: https://gitcode.com/gh_mirrors/ti/TikTokCommentScraper TikTokCommentScraper是一款专为抖音/TikTok用户设计的评论数据提取工具,能够帮助…...
)
告别错位检测!用S2A-Net搞定航拍图像中的任意方向目标(附PyTorch代码实战)
航拍图像目标检测实战:S2A-Net从原理到PyTorch实现 航拍图像中的目标检测一直是计算机视觉领域的难点——密集排列的车辆、任意角度的建筑物、形态各异的自然景观,这些目标在传统检测框架下常常出现特征错位问题。今天我们要深入探讨的S2A-Net࿰…...

RK3588项目实战:手把手教你集成RTL8188EU驱动并优化WiFi连接稳定性
RK3588项目实战:手把手教你集成RTL8188EU驱动并优化WiFi连接稳定性 在智能硬件开发中,稳定可靠的无线网络连接往往是产品体验的关键。RK3588作为一款高性能处理器,搭配经济高效的RTL8188EUS USB WiFi模块,成为许多嵌入式设备的理想…...

Edge Impulse实战:用Arduino Nano 33 BLE Sense的IMU数据,做个“手势识别”分类器
用Arduino Nano 33 BLE Sense实现手势识别的全流程实战 当Arduino Nano 33 BLE Sense开发板遇上Edge Impulse平台,内置的IMU传感器突然拥有了理解手势的能力。本文将带你完整实现从原始传感器数据采集到嵌入式AI模型部署的全过程,让一块普通开发板学会识…...

如何在3天内快速上手OpenSPG知识图谱引擎?完整实战指南 [特殊字符]
如何在3天内快速上手OpenSPG知识图谱引擎?完整实战指南 🚀 【免费下载链接】openspg OpenSPG is a Knowledge Graph Engine developed by Ant Group in collaboration with OpenKG, based on the SPG (Semantic-enhanced Programmable Graph) framework.…...

如何快速上手NVIDIA Profile Inspector:新手必看的完整显卡优化教程
如何快速上手NVIDIA Profile Inspector:新手必看的完整显卡优化教程 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 想彻底释放你的NVIDIA显卡性能吗?NVIDIA Profile Inspector正…...

【仅限首批200名开发者开放】AGI情感交互沙盒环境正式解封:含7类真实社交冲突场景数据集与动态共情评分API
第一章:AGI情感交互能力的范式跃迁 2026奇点智能技术大会(https://ml-summit.org) 传统人机交互长期受限于意图识别与响应生成的符号化闭环,而AGI情感交互正突破“识别—分类—应答”的浅层映射逻辑,转向具备共情建模、情绪状态持续追踪与反…...

电子元件知识汇总4-采购与真伪识别
目录: 一、电阻R 二、电容C 1、钽电容 三、电感L 四、二极管D 1、MB10M、MB10S与MB10F 2、ES2A THRU ES2M 3、KBJ3510、GBJ3510 五、三极管与场效益管Q 1、PBSS4160DPN三极管...