探究Kafka原理-2.Kafka基本命令实操
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring源码、JUC源码、Kafka原理
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- 安装部署
- 安装 zookeeper 集群
- 安装 kafka 集群
- Kafka 运维监控
- Kafka-Eagle 简介
- Kafka-Eagle 安装
- 启动 KafkaEagle
- 访问 web 界面
- 命令行工具
- 概述
- topic 管理操作:kafka-topics
- 查看 topic 列
- 查看 topic 状态信息
- 创建 topic
- 删除 topic
- 增加分区数
- 动态配置 topic 参数
- 生产者:kafka-console-producer
- 消费者:kafka-console-consumer
- 消费组
- 消费位移的记录
- 配置管理 kafka-config
- 动态配置 topic 参数
- kafka是如何做到可以动态修改配置的?
安装部署
安装 zookeeper 集群
配置zookeeper集群的核心就是,以下每个zookeeper都要有
vi zoo.cfg
dataDir=/opt/apps/data/zkdata
server.1=doitedu01:2888:3888
server.2=doitedu02:2888:3888
server.3=doitedu03:2888:3888
安装 kafka 集群
核心操作如下:
vi server.properties#为依次增长的:0、1、2、3、4,集群中唯一 id
broker.id=0# 数据存储的⽬录
# 每一个broker都把自己所管理的数据存储在自己的本地磁盘
log.dirs=/opt/data/kafkadata#底层存储的数据(日志)留存时长(默认 7 天)
log.retention.hours=168#底层存储的数据(日志)留存量(默认 1G)
log.retention.bytes=1073741824#指定 zk 集群地址
zookeeper.connect=doitedu01:2181,doitedu02:2181,doitedu03:2181
查看框架兼容的版本:查看依赖的pom / 要去查看对应框架的源码,然后进入查看
Kafka 运维监控
kafka 自身并没有集成监控管理系统,因此对 kafka 的监控管理比较不便,好在有大量的第三方监控管
理系统来使用,比如Kafka Eagle
Kafka-Eagle 简介

Kafka-Eagle 安装
官方文档地址:https://docs.kafka-eagle.org/
其中修改最核心的配置
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
####################################### 给kafka集群起一个名字
efak.zk.cluster.alias=cluster1
# 告诉它kafka集群所连接的zookeeper在哪里
cluster1.zk.list=doit01:2181,doit02:2181,doit03:2181######################################
# broker size online list
######################################
# 告诉集群broker服务器有多少台
cluster1.efak.broker.size=3# 还需要一种数据库,可以针对性的选择######################################
# kafka sqlite jdbc driver address 本地的嵌入式数据库
######################################
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/opt/data/kafka-eagle/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org######################################
# kafka mysql jdbc driver address
######################################
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior
=convertToNull
#efak.username=root
#efak.password=123456如上,数据库选择的是 sqlite,需要手动创建所配置的 db 文件存放目录:/opt/data/kafka-eagle/db/
如果,数据库选择的是 mysql,则要放一个 mysql 的 jdbc 驱动 jar 包到 kafka-eagle 的 lib 目录中
启动 KafkaEagle

访问 web 界面


初始是一个快速看板,快速得到一些最要紧的信息。
启动,先启动zookeeper,再kafka
kafka默认对客户端暴漏的连接端口是 9092、zookeeper默认暴漏的端口是2181


显示信息比如说有多少分区、分布的均匀率、数据倾斜的比例、Leader倾斜的比例等参数。


Kafka-Eagle的意义:
1.对生产力的提升。
2.监控Kafka集群的手段。
命令行工具
概述
Kafka 中提供了许多命令行工具(位于$KAFKA HOME/bin 目录下)用于管理集群的变更。
| 命令 | 描述 |
|---|---|
| kafka-console-consumer.sh | 用于消费消息 |
| kafka-console-producer.sh | 用于生产消息 |
| kafka-topics.sh | 用于管理主题 |
| kafka-server-stop.sh | 用于关闭 Kafka 服务 |
| kafka-server-start.sh | 用于启动 Kafka 服务 |
| kafka-configs.sh | 用于配置管理 |
| kafka-consumer-perf-test.sh | 用于测试消费性能 |
| kafka-producer-perf-test.sh | 用于测试生产性能 |
| kafka-dump-log.sh | 用于查看数据日志内容 |
| kafka-preferred-replica-election.sh | 用于优先副本的选举 |
| kafka-reassign-partitions.sh | 用于分区重分配 |
topic 管理操作:kafka-topics
查看 topic 列
bin/kafka-topics.sh --list --zookeeper doit01:2181
查看 topic 状态信息
(1)查看 topic 详细信息
bin/kafka-topics.sh --zookeeper doitedu01:2181 --describe --topic topic-doit29

从上面的结果中,可以看出,topic 的分区数量,以及每个分区的副本数量,Configs:compression.type=gzip 代表着我们topic的数据是压缩的。
创建 topic
./kafka-topics.sh --zookeeper doitedu01:2181 --create --replication-factor 3
--partitions 3 --topic test
参数解释:
--replication-factor 副本数量
--partitions 分区数量
--topic topic 名称
本方式,副本的存储位置是系统自动决定的;
手动指定分配方案:分区数,副本数,存储位置
bin/kafka-topics.sh --create --topic tpc-1 --zookeeper doitedu01:2181
--replica-assignment 0:1:3,1:2:6
该 topic,将有如下 partition:
partition0 ,所在节点: broker0、broker1、broker3
partition1 ,所在节点: broker1、broker2、broker6而顺序的不同有可能导致leader位置的不同
删除 topic
bin/kafka-topics.sh --zookeeper doitedu01:2181 --delete --topic test
删除 topic,server.properties 中需要一个参数处于启用状态: delete.topic.enable = true
使用 kafka-topics .sh 脚本删除主题的行为本质上只是在 ZooKeeper 中的 /admin/delete_topics 路径
下建一个与待删除主题同名的节点,以标记该主题为待删除的状态。然后由 Kafka 控制器异步完成。
增加分区数
kafka-topics.sh --zookeeper doit01:2181 --alter --topic doitedu-tpc2 --partitions 3
Kafka 只支持增加分区,不支持减少分区(增加分区,不涉及历史数据的合并,是一个轻量级的操作,而减少分区,必然涉及到历史数据的转移合并,代价太大)
原因是:减少分区,代价太大(数据的转移,日志段拼接合并)
如果真的需要实现此功能,则完全可以重新创建一个分区数较小的主题,然后将现有主题中的消息按
照既定的逻辑复制过去;
动态配置 topic 参数
通过管理命令,可以为已创建的 topic 增加、修改、删除 topic level 参数
添加/修改 指定 topic 的配置参数:
kafka-topics.sh --alter --topic tpc2 --config compression.type=gzip --zookeeper doit01:2181
# --config compression.type=gzip 修改或添加参数配置
# --add-config compression.type=gzip 添加参数配置
# --delete-config compression.type 删除配置参
topic 配置参数文档地址: https://kafka.apache.org/documentation/#topicconfigs
当然其核心的配置参数有蛮多的
- broker的配置参数
- consumer的配置参数
- producer的配置参数
- topic的配置参数
生产者:kafka-console-producer
bin/kafka-console-producer.sh --broker-list doitedu01:9092 --topic test
>hello word
>kafka
>nihao
其实存在着一些思考和问题,比如我们根本不知道到底是不是写进去了,那么我们应该怎么办?
消费者:kafka-console-consumer
消费者在消费的时候,需要指定要订阅的主题,还可以指定消费的起始偏移量
起始偏移量的指定策略有 3 种:
earliest 从最早的开始消费
latest 从最新的开始消费
指定的 offset( 分区号:偏移量) 从你指定的位置开始消费
从之前所记录的偏移量开始消费
kafka 的 topic 中的消息,是有序号的(序号叫消息偏移量),而且消息的偏移量是在各个 partition 中
独立维护的,在各个分区内,都是从 0 开始递增编号!
消费消息(从开始的开始消费)
bin/kafka-console-consumer.sh --bootstrap-server doitedu01:9092 --from-beginning
--topic test
但是会存在一种情况,比如说 先生产了很多消息进集群中,然后开始消费的话,可能不会保证有序,因为数据是存储在不同的分区中的,消费者在消费的时候,是先把一个分区的数据消费完,然后再去消息其他分区。所以这也就导致了全局顺序不一致的情况。

如果不加 --from-beginning 默认从最新的开始消费 当再次执行消费者的时候,会返回0条,因为已经没有最新的了,已经存在的都叫老数据了。
如果此时还想让消费者 消费到数据,那就去生产新的数据。
指定要消费的分区,和要消费的起始 offset
bin/kafka-console-consumer.sh --bootstrap-server
doitedu01:9092,doitedu02:9092,doitedu03:9092 --topic doit14 --offset 2 --partition 0
在这里其实要明白的一个点就是,生产者把数据写入topic的时候,默认是把数据在多个分区间轮询写入。
每一个消息都有一个序号,对应的消息的序号(offset)递增都是每个分区内管理的,消息的offset在topic中并不会有全局的递增号。所以offset是在各个分区内独立维护的,那么也就意味着每个分区中,都有offset=0的消息
消费组
消费组是 kafka 为了提高消费并行度的一种机制!
如果只有一个消费者,那么就会是这样

消费者轮询消费对应的分区。
而如果topic中数据量太大,而你需要多个并行处理任务去处理topic中的数据,那么就需要消费组。
消费组内的各个消费者之间,分担数据读取任务的最小单位是分区。
同一个分区只会被消费组内某一个消费者来负责读取。

而如果出现,消费者组 中消费者 大于 分区数,那么就会剩下来。

在kafka的底层逻辑中,任何一个消费者都有自己所属的组
组和组之间,没有任何关系,大家都可以消费到目标topic中所有的数据,但是组内的各个消费者,就只能读到自己所分配的 分区

如何让多个消费者组成一个组: 就是让这些消费者的 groupId 相同即可!
KAFKA 中的消费组,可以动态增减消费者
而且消费组中的消费者数量发生任意变动,都会重新分配分区消费任务
消费位移的记录
kafka 的消费者,可以记录自己所消费到的消息偏移量,记录的这个偏移量就叫(消费位移);
记录这个消费到的位置,作用就在于消费者重启后可以接续上一次消费到位置来继续往后面消费;
其实讲白了就是为了断点续传。

例如上图 消费者A,正在读,突然消费者组里新增了一个消费者,那么这个程序,读的进程会被中断,先停,重新分配一下分区,然后再来。
kafka消费者是有这个功能的,它会自己去记消费到那条消息了,万一消费者崩了,重启也知道从哪里继续消费。
其消费的本质是按照组来记偏移量,整个偏移量组内共享,并不是按照单个消费者来记,毕竟消费者组里的消费者可以动态收缩!!!
如果此时又来了一个新的消费者组来消费 topic,那么就没有对应的偏移量。
有一个比较经典的问题:
如果我们消费一个数据,已经读到了,但是还没有来得及更新偏移量,正要更新偏移量的时候,崩溃了,那么此时重启之后会发生什么?
此时就会被重复消费。
该模式主要是 先读后记,如果是先记后读,可能连读都读不到!!!
但是还有另外的一个情况,就是可能重复的数据不止一条。
比如 消费了好几条,再记录!一次去读一批,然后去更新偏移量。
kafka的消费者去读取数据,是消费者主动向broker去请求拉取,而不是broker服务器来推送(具体拉取多少条是有参数配置的)
如果拉取的速度比进行的速度要快的话,那么消费者就经常的处于饥饿的状态,如果进来的速度比我拉取的要快,那么就会造成数据大量的积压。
如果在不同机器启动同一个消费者组里的消息者,还是能够共享偏移量的
是因为偏移量数据并没有存储在本地磁盘上,在0.11.x之前,消费者确实是把自己消费到的位置(消费位移)记录到zk上,之后,是记录在kafka的一个内部的topic中( __consumer_offsets)。
类似于mysql,也是一样的逻辑,内部也有一些系统内部表

通过指定 formatter 工具类,来对__consumer_offsets 主题中的数据进行解析;
bin/kafka-console-consumer.sh --bootstrap-server doitedu01:9092 --topic __consumer_offsets --formatter
"kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"

consumer去记录偏移量的时候,不是 读到一批数据就记录一次,也不是记录一次后再去读数据,而是周期性定期去提交当前的位移。
如果真的发生了更新,那就去改数字,没发生更新,就和原来一样。(周期性 5s 去提交当前的位移)
其实也可以从上面的记录中就可以看到,kafka的消费者,记录新的消费位移,并不是去修改上一次的,而是重新记录(追加新记录,像日志一样)。
所以就像之前说的kafka的配置文件里面,数据存储目录,不叫data.dirs 而是叫 log.dirs,kafka之所以把自己的数据存储目录称之为 log目录,是因为,他底层存储数据的特性,类似于 “日志” 数据只能不断追加。
这种日志也不能删除,只能将超过日期的日志进行截断,留下的各个消费者组的都有。当然针对这一点,因为消费者组再启动消费的时候,是可以显示指定起始偏移量,也就是说,可以忽略之前所记录的偏移量。
如果需要获取某个特定 consumer-group 的消费偏移量信息,则需要计算该消费组的偏移量记录所在
分区: Math.abs(groupID.hashCode()) % numPartitions __consumer_offsets 的分区数为:50
配置管理 kafka-config
kafka-configs.sh 脚本是专门用来进行动态参数配置操作的,这里的操作是运行状态修改原有的配置,
如此可以达到动态变更的目的;
动态配置的参数,会被存储在 zookeeper 上,因而是持久生效的
可用参数的查阅地址: https://kafka.apache.org/documentation/#configuration
kafka-configs.sh 脚本包含:变更 alter、查看 describe 这两种指令类型;
kafka-configs. sh 支持主题、 broker 、用户和客户端这 4 个类型的配置。
kafka-configs.sh 脚本使用 entity-type 参数来指定操作配置的类型,并且使 entity-name 参数来指定操
作配置的名称。
比如查看 topic 的配置可以按如下方式执行
bin/kafka-configs.sh --zookeeper doit01:2181 --describe --entity-type topics --entity-name tpc_2
比如查看 broker 的动态配置可以按如下方式执行:
bin/kafka-configs.sh --describe --entity-type brokers --entity-name 0 --zookeeper doit01:2181
entity-type 和 entity-name 的对应关系

示例:添加 topic 级别参数
bin/kafka-configs.sh --zookeeper doit:2181 --alter --entity-type topics --entity-name tpc22 --add-config
cleanup.policy=compact,max.message.bytes=10000
使用 kafka-configs.sh 脚本来变更( alter )配置时,会在 ZooKeeper 中创建一个命名形式为:
/config//的节点,并将变更的配置写入这个节点
示例:添加 broker
kafka-configs.sh --entity-type brokers --entity-name 0 --alter --add-config log.flush.interval.ms=1000
--bootstrap-server doit01:9092,doit02:9092,doit03:9092
动态配置 topic 参数
通过管理命令,可以为已创建的 topic 增加、修改、删除 topic level 参
添加/修改 指定 topic 的配置参数:
kafka-topics.sh --topic doitedu-tpc2 --alter --config compression.type=gzip --zookeeper doit01:2181
如果利用 kafka-configs.sh 脚本来对 topic、producer、consumer、broker 等进行参数动态
添加、修改配置参数
bin/kafka-configs.sh --zookeeper doitedu01:2181 --entity-type topics --entity-name tpc_1
--alter --add-config compression.type=gzip
删除配置参数
bin/kafka-configs.sh --zookeeper doitedu01:2181 --entity-type topics --entity-name tpc_1
--alter --delete-config compression.type
kafka是如何做到可以动态修改配置的?
Kafka之所以能够动态配置,是因为它设计时考虑到了在运行时动态更改配置的需求。Kafka的配置信息存储在Zookeeper中,而不是像传统的配置文件那样静态地存储在本地磁盘上。这样一来,当需要更改配置时,只需要在Zookeeper上修改对应的配置节点,Kafka会自动检测到变化并按照新的配置进行运行。
Kafka实现动态配置的原理是基于Zookeeper的Watcher机制。当Kafka启动时,会将配置信息存储在Zookeeper的一个特定目录下,并且通过Watcher监听该目录的变化。当配置信息发生变化时,Zookeeper会通知Kafka,Kafka会重新加载新的配置并应用到运行中的服务。
以下是一个简化的伪代码示例,展示了Kafka动态配置的实现原理:
# Kafka启动时初始化配置
def initialize_config():config = load_config_from_zookeeper() # 从Zookeeper加载配置apply_config(config) # 应用配置# 从Zookeeper加载配置
def load_config_from_zookeeper():config_data = zookeeper.get('/kafka/config') # 从Zookeeper获取配置数据return parse_config(config_data) # 解析配置数据# 解析配置数据
def parse_config(config_data):# 将配置数据解析为可用的配置对象config = Config()config.load_from_dict(config_data)return config# 应用配置
def apply_config(config):# 根据配置更新Kafka的运行时参数update_kafka_config(config)# 监听配置变化
def watch_config_changes():while True:changes = zookeeper.watch('/kafka/config') # 监听配置目录config = parse_config(changes) # 解析配置变化apply_config(config) # 应用配置# 修改配置
def modify_config(config_changes):zookeeper.set('/kafka/config', config_changes) # 更新Zookeeper上的配置数据# Kafka启动时初始化配置
initialize_config()# 启动监听配置变化的线程
start_thread(watch_config_changes)# 修改配置的示例
modify_config(new_config_changes)
相关文章:
探究Kafka原理-2.Kafka基本命令实操
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

Linux网卡没有eth0显示ens33原因以及解决办法
原因 首先说明一下eth0 与 ens33的关系: 目前的主流网卡为使用以太网络协定所开发出来的以太网卡(Ethernet),因此我们Linux就称呼这种网络接口为ethN(N为数字)。 举个栗子:就是说主机上面有一张以太网卡,因此主机的网络接口就是…...
1.前端--基本概念【2023.11.25】
1.网站与网页 网站是网页集合。 网页是网站中的一“页”,通常是 HTML 格式的文件,它要通过浏览器来阅读。 2.Web的构成 主要包括结构(Structure) 、表现(Presentation)和行为(Behaviorÿ…...

计算机视觉面试题-01
计算机视觉面试通常涉及广泛的主题,包括图像处理、深度学习、目标检测、特征提取、图像分类等。以下是一些可能在计算机视觉面试中遇到的常见问题: 图像处理和计算机视觉基础 图像是如何表示的? 图像在计算机中可以通过不同的表示方法&…...

108. 将有序数组转换为二叉搜索树 --力扣 --JAVA
题目 给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。 高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。 解题思路 可以采用二分法,每次选数组中间值为…...
Springboot实现增删改差
一、包结构 二、各层代码 (1)数据User public class User {private Integer id;private String userName;private String note;public User() {super();}public User(Integer i, String userName, String note) {super();this.id i;this.userName userName;this.note note;…...
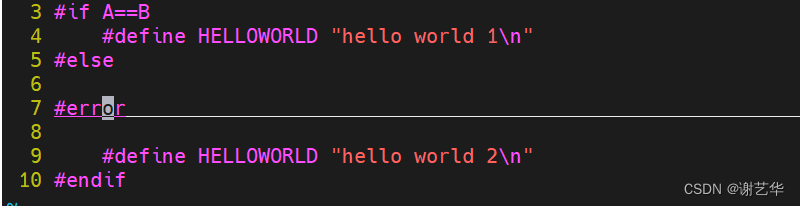
【程序员的自我修养01】编译流程概述
绪论 大家好,欢迎来到【程序员的自我修养】专栏。正如其专栏名,本专栏主要分享学习《程序员的自我修养——链接、装载与库》的知识点以及结合自己的工作经验以及思考。编译原理相关知识本身就比较有难度,我会尽自己最大的努力,争取…...
在PyCharm中正确设置Python项目
大家好,在Mac和Linux都支持Python,但许多开发者发现正确设置Python项目很困难。本文汇总了多平台中运行Python的方法,提高编程的效率,如下所示: 使用命令行运行Python。 在PyCharm(免费社区版)…...
)
scoop bucket qq脚本分析(qq绿色安装包制作)
url字段 以qq.json为例,其对应的scoop配置文件在$env:scoop\buckets\extras\bucket\qq.json 其中的url字段 "url":"https://webcdn.m.qq.com/spcmgr/download/QQ9.7.17.29230.exe#/dl.7z"为qq安装包下载地址,后缀#/dl.7z为自行添加…...
Elasticsearch:将最大内积引入 Lucene
作者:Benjamin Trent 目前,Lucene 限制 dot_product (点积) 只能在标准化向量上使用。 归一化迫使所有向量幅度等于一。 虽然在许多情况下这是可以接受的,但它可能会导致某些数据集的相关性问题。 一个典型的例子是 Cohere 构建的嵌入&#x…...
YOLOV7主干改进,使用fasternet轻量化改进主干(完整教程)
1,Pconv(来自Fasternet)(可作为模型中的基础卷积模块使用) 论文链接:https://arxiv.org/abs/2303.03667 2,为了大家方便的使用,这里我对原本的PConv的代码做了部分的改动࿰…...
DALSA.SaperaLT.SapClassBasic无法加载,试图加载格式不正确的程序,c#
情景:用c#wpf写DALSA线扫相机的项目,生成时不报错,运行到DALSA相关的代码就报错找不到dll(DALSA的技术支持没给到任何支持 ) 一.根据框架选择dll 如果是.net framework框架(比如说.net480)&am…...
设计模式-创建型模式-工厂方法模式
一、什么是工厂方法模式 工厂模式又称工厂方法模式,是一种创建型设计模式,其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。工厂方法模式是目标是定义一个创建产品对象的工厂接口,将实际创建工作推迟到子类中。…...
科研/比赛必备工具及系列笔记集合
科研/比赛必备工具及系列笔记集合 零、前言一、常用工具系列1.1 笔记平台使用感受系列1.2 常用开发平台系列 二、论文系列2.1 检索工具系列2.2 投稿调研系列2.3 常见国际期刊/会议2.4 常见中文核心期刊/会议 三、文献系列3.1 画图工具系列3.2 翻译工具系列3.3 英文纠正系列3.4 …...

萨科微举办工作交流和业务分享会
萨科微(www.slkoric.com)举办工作交流和业务分享会,狠抓人才培养团队的基本功建设。萨科微总经理宋仕强先生认为,当下市场经济形势复杂多变,给公司经营带来巨大压力,同时考验着企业自身的发展韧性。萨科微公…...

一篇文章让你入门python集合和字典
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 一、集合: 增加 add 删除 del 删除集合 discard(常用)删除集合中的元素 ,删除一个不存在的元素不会报错 remove 删除一个不存在的元素会报错 pop随…...
各种工具的快捷键或命令
前言 这里就存放自己存有的一些小工具的地址以及工具的命令。 正文 零、各种小工具 1、wizTree:磁盘分析工具-分析磁盘的文件夹存储 2、稻壳阅读器:有黑色背景 3、youtube 视频下载:https://zh.savefrom.net/226/ 4、视频录制:Bandica…...

【Web】preg_match绕过相关例题wp
目录 ①[FBCTF 2019]rceservice ②[ctfshow]web130 ③[ctfshow]web131 ④[NISACTF 2022]middlerce 简单回顾一下基础 参考文章 p牛神文 preg_match绕过总的来讲就三块可利用 数组绕过、PCRE回溯次数限制、换行符 ①[FBCTF 2019]rceservice 先贴出附件给的源码 &l…...
)
XSLVGL2.0 User Manual 主题管理器(v2.0)
XSLVGL2.0 开发手册 XSLVGL2.0 Brief 1、概述2、特性3、APIs3.1、xs_page_theme_register3.2、xs_page_get_theme_current3.3、xs_page_set_theme_current3.4、xs_page_get_theme_count3.5、xs_page_get_theme_id3.6、xs_page_get_theme_name3.7、xs_page_get_theme4、使用方法…...

visionOS空间计算实战开发教程Day 2 使用RealityKit显示3D素材
我们在Day1中学习了如何创建一个visionOS应用,但在第一个Demo应用中我们的界面内容还是2D的,看起来和其它应用并没有什么区别。接下来我们先学习如何展示3D素材,苹果为方便开发人员,推出了RealityKit,接下来看…...

ZLibrary架构揭秘:数字资源分发的技术前沿
从ZLibrary入口看数字资源分发架构的技术文章大纲引言数字资源分发在互联网时代的核心作用ZLibrary作为典型案例的背景介绍文章结构概述ZLibrary的技术架构分析前端入口设计:域名系统与访问路由负载均衡与高可用性实现方案分布式存储系统的数据组织方式资源分发关键…...
)
在银河麒麟V10+FT2000服务器上,我踩过的那些软件安装的坑(附完整避坑指南)
银河麒麟V10FT2000服务器软件安装避坑实战指南 第一次在银河麒麟V10操作系统上部署服务时,我盯着那个不断闪烁的光标,意识到国产化平台的软件生态与x86体系存在诸多微妙差异。FT2000处理器的架构特性、操作系统的权限管理机制、软件包的依赖关系——每一…...

ChemCrow实战指南:用AI大模型解决复杂化学问题的终极方案
ChemCrow实战指南:用AI大模型解决复杂化学问题的终极方案 【免费下载链接】chemcrow-public Chemcrow 项目地址: https://gitcode.com/gh_mirrors/ch/chemcrow-public 你是否曾为复杂的化学计算感到头疼?需要计算分子量、预测反应产物,…...

胡桃工具箱:5分钟掌握原神最强数据助手,告别角色培养烦恼
胡桃工具箱:5分钟掌握原神最强数据助手,告别角色培养烦恼 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trendi…...
)
别再死记硬背SVD了!用Python从零手搓一个共现矩阵(附完整代码与可视化)
从零构建共现矩阵:Python实战与可视化解析 在自然语言处理领域,词向量表示一直是核心课题。传统方法如TF-IDF虽然简单有效,但无法捕捉词语间的语义关系。共现矩阵(Co-Occurrence Matrix)通过统计词语在上下文窗口中的共…...

从源码到CFG:深入解析编译中间表示的转换链路
1. 源码到AST:从文本到树形结构的蜕变 当你用Java或Python写下一行代码时,计算机看到的其实只是一堆字符。就像读一本外文书,首先要把它翻译成自己能理解的结构。这就是编译器的第一个任务——把源码变成AST(抽象语法树࿰…...

如何轻松运行Flash游戏和网页?这款免费浏览器让你一键搞定!
如何轻松运行Flash游戏和网页?这款免费浏览器让你一键搞定! 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否曾经想重温经典的Flash游戏,却发现现…...
)
电路分析的基石:深入理解基尔霍夫定律(KCL与KVL)
1. 从零开始认识基尔霍夫定律 第一次接触电路分析时,我盯着密密麻麻的电路图完全无从下手。直到老师画出几个红色圆圈说:"记住这两个定律,它们就像电路世界的交通规则。"这两个定律就是基尔霍夫电流定律(KCL)…...

统一过程原型深入分析和总结
统一过程(Rational Unified Process,RUP)是一种用例驱动、架构为中心、迭代增量的软件工程过程,由 Rational Software 公司(现属于 IBM)开发,并在其过程框架中广泛推广。RUP 融合了多种最佳实践,是一种可裁剪的通用过程框架。 一、核心思想 RUP 的核心原则可概括为: …...

抖音批量下载终极指南:3步轻松获取无水印视频素材
抖音批量下载终极指南:3步轻松获取无水印视频素材 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...