利用 NVIDIATAO 和 WeightBias 加速AI开发
利用 NVIDIATAO 和 Weight&Bias 加速AI开发

利用图像分类、对象检测、自动语音识别 (ASR) 和其他形式的 AI 可以推动公司和商业部门内部的大规模转型。 然而,从头开始构建人工智能和深度学习模型是一项艰巨的任务。
构建这些模型的一个共同先决条件是拥有大量高质量的训练数据和准备数据、构建神经网络以及持续微调模型以优化性能的正确专业知识。 对于开始机器学习 (ML) 之旅的组织来说,这通常是一个挑战。 尽管 AI 可以提供明确且可衡量的好处,但高准入门槛往往成为各种规模企业采用 AI 的障碍。
这篇文章讨论了 NVIDIA TAO 工具包和 Weights & Biases MLOps 平台的结合如何帮助启动组织利用 AI 和加速常见 AI 任务的旅程。 开发人员现在可以使用 NVIDIA TAO (Train-Adapt-Optimize) Toolkit 和 Weights & Biases (W&B) 可视化和比较多次训练运行。 此外,我们还将介绍一个用于构建对象检测模型的示例工作流程。
NVIDIA TAO 工具包
NVIDIA TAO Toolkit 是一种低代码解决方案,使开发人员和企业能够加速模型训练和优化过程。 NVIDIA TAO 工具包通过抽象化 AI 模型和深度学习框架的复杂性,降低了 AI 入门者的入门门槛。 借助 NVIDIA TAO 工具包,您可以利用迁移学习的强大功能,使用您自己的数据微调 NVIDIA 预训练模型,并优化推理模型以满足您的业务需求。
NVIDIA TAO Toolkit 支持广泛的计算机视觉任务,例如分类、对象检测、分割、关键点估计、OCR 等。 它提供交钥匙推理优化,可降低模型的复杂性和大小并提高推理吞吐量。
Weights & Biases
Weights & Biases MLOps 平台可帮助 ML 团队更快地构建更好的模型。 只需在笔记本中添加几行代码,您就可以立即调试、比较和重现您的模型——架构、超参数、git 提交、模型权重、GPU 使用、数据集和预测——所有这一切都与您的团队成员协作。
显示 W&B 平台的五个模块的图表:工件、表格、实验、扫描和评估。

W&B 受到来自世界上一些最具创新性的公司和研究组织的超过 400,000 名 ML 从业者的信任。 要免费试用,请在 Weights & Biases 注册。
集成 NVIDIA TAO 工具包和 Weights & Biases
NVIDIA TAO 工具包使您能够可视化权重和偏差中的所有实验数据。 可视化、比较和对比多个训练运行,以确定哪些候选模型最适合项目的需求,以及哪些超参数对模型性能的影响最大。
集成还将展示每个模型训练如何使用底层硬件以确保资源得到充分利用。 要了解有关如何配置 NVIDIA TAO 工具包并将实验记录到 W&B 的更多信息,请参阅 NVIDIA TAO 工具包 W&B 集成文档。
| Image classification | Object detection | Segmentation |
|---|---|---|
| EfficientNet B0-B5 | DetectNet-v2 | Unet |
| FasterRCNN | MaskRCNN | |
| RetinaNet | ||
| YOLOv4/v4-Tiny/v3 | ||
| SSD/DSSD | ||
| EfficientDet |
如何通过 NVIDIA TAO 工具包利用 W&B
以下部分将指导您通过一个示例在 NVIDIA TAO 工具包中调整预训练对象检测模型,利用权重和偏差。 首先,设置工具包并将您的 W&B 帐户连接到实例。 然后将工具包中的指标记录到 W&B,并利用实验跟踪、数据可视化和工件跟踪功能。
设置 W&B 帐户
- 创建 W&B 帐户(请注意,企业用户应咨询您的 W&B 管理员。)
- 复制您的 API 密钥
安装和设置 NVIDIA TAO 工具包
- 使用下面的调用下载 NVIDIA TAO Toolkit 资源。 此软件包包含用于安装工具包容器和 Jupyter 笔记本以运行 NVIDIA TAO 工具包的启动脚本。
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/tao-getting-started/versions/4.0.0/zip -O getting_started_v4.0.0.zip
unzip -u getting_started_v4.0.0.zip -d ./getting_started_v4.0.0 && rm -rf getting_started_v4.0.0.zip && cd ./getting_started_v4.0.0
- NVIDIA TAO Toolkit 有多种训练方式。 有关每个的详细说明,请参阅 TAO 工具包入门指南。
- Launcher CLI:您可以使用轻量级 Python CLI 应用程序运行 TAO。 启动器基本上充当基于 PyTorch 和 TensorFlow 构建的多个 NVIDIA TAO 工具包容器的前端。 将根据您计划用于计算机视觉或对话式 AI 用例的模型类型自动启动适当的容器。
- 直接从容器:您还可以选择直接使用 Docker 容器运行 NVIDIA TAO Toolkit。 要直接使用容器,您需要知道要拉取哪个容器。 TAO Toolkit下有多个容器。 根据您要训练的模型,您需要拉取适当的容器。 使用 Launcher CLI 时不需要这样做。
- TAO API:您还可以使用 NVIDIA TAO Toolkit API 使用 REST API 运行,这是一种 Kubernetes 服务,可以使用 REST API 构建 AI 模型。 API 服务可以使用 Helm chart 以及最小依赖项安装在 Kubernetes 集群(本地/AWS EKS)上。
配置 NVIDIA TAO Toolkit 以登录 W&B
- 配置 W&B API 密钥:要从本地计算单元传输数据并在 W&B 服务器仪表板上渲染数据,必须登录 NVIDIA TAO 工具包容器中的 W&B 客户端并与您的配置文件同步。 要在容器登录中包含 W&B 客户端,请使用您在设置 W&B 帐户时收到的 API 密钥在 NVIDIA TAO 工具包容器中设置 WANDB_API_KEY 环境变量。 有关其他资源,请参阅 TAO 工具包 W&B 集成文档。
Launcher CLI:如果您使用的是 Launcher CLI,请使用下面的示例 json 片段并将 Envs 元素下的值字段替换为 ~/.tao_mounts.json 文件中的 W&B API 密钥。
{"Mounts": [{"source": "/path/to/your/data","destination": "/workspace/tao-experiments/data"},{"source": "/path/to/your/local/results","destination": "/workspace/tao-experiments/results"},{"source": "/path/to/config/files","destination": "/workspace/tao-experiments/specs"}],"Envs": [{"variable": "WANDB_API_KEY","value": "<api_key_value_from_wandb>"}],"DockerOptions": {"shm_size": "16G","ulimits": {"memlock": -1,"stack": 67108864},"ports": {"8888": 8888}}
}
直接从 Docker:如果您直接通过容器运行,请使用 docker 命令的 -e 标志。 例如,要直接通过容器运行带有 W&B 的 detectnet_v2,请使用以下脚本:
docker run -it --rm --gpus all \-v /path/in/host:/path/in/docker \-e WANDB_API_KEY=<api_key_value>nvcr.io/nvidia/tao/tao-toolkit:4.0.0-tf1.15.5 \detectnet_v2 train -e /path/to/experiment/spec.txt \-r /path/to/results/dir \-k $KEY --gpus 4
NVIDIA TAO API:对于 API,将以下代码片段添加到 TAO Toolkit Helm 图表中的 values.yaml 文件:
# Optional MLOPS setting for Weights And Biases
wandbApiKey: <wandb_api_key>
- 运行 NVIDIA TAO Toolkit 并将您的指标记录到 W&B。
实例化下载示例目录中存在的 detectnet_v2.ipynb 笔记本:notebooks/tao_launcher_starter_kit/detectnet_v2/detectnet_v2.ipynb。
使用以下脚本取消注释 MLOPS 集成部分下的第一个单元格:
# Uncomment this code block to enable wandb integration with TAO.# # you can get the wandb api key by logging into https://wandb.ai# !pip install wandb## os.environ[\"WANDB_API_KEY\"] = FIXME# import wandb# WANDB_LOGGED_IN = wandb.login()# if WANDB_LOGGED_IN:# print(\"WANDB successfully logged in.将下一行中的 FIXME 替换为复制的 W&B 密钥。
os.environ["WANDB_API_KEY"] = FIXME
一旦您传入 API 密钥,W&B 日志记录将默认启用。 有关集成 NVIDIA TAO 工具包和 W&B 的更多详细信息,请参阅 NVIDIA TAO 工具包 W&B 集成文档。
下图显示了通过运行笔记本自动生成的页面示例。

相关文章:
利用 NVIDIATAO 和 WeightBias 加速AI开发
利用 NVIDIATAO 和 Weight&Bias 加速AI开发 利用图像分类、对象检测、自动语音识别 (ASR) 和其他形式的 AI 可以推动公司和商业部门内部的大规模转型。 然而,从头开始构建人工智能和深度学习模型是一项艰巨的任务。 构建这些模型的一个共同先决条件是拥有大量高…...

token - 令牌
文章目录token - 令牌学前须知:1,base64 防君子不防小人2,SHA-256 安全散列算法的一种(hash)3,HMAC-SHA2564,RSA256 非对称加密2.1 JWT - json-web-token1,三大组成2,jwt…...
应用模型开发指南上新介绍
Module、HAP、Ability、AbilitySta-ge、Context……您是否曾经被这些搞不懂又绕不开的知识点困扰? 现在,全新的《应用程序包基础知识》及《应用模型开发指南》为您答疑解惑! 这里有您关注的概念解析、原理机制阐述,也有丰富的…...
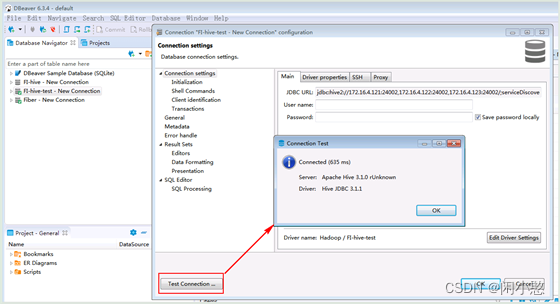
Dbeaver连接Hive数据库操作指导
背景:由于工作需要,当前分析研究的数据基于Hadoop的Hive数据库中,且Hadoop服务端无权限进行操作且使用安全模式,在研究了Dbeaver、Squirrel和Hue三种连接Hive的工具,在无法绕开useKey认证的情况下,只能使用…...
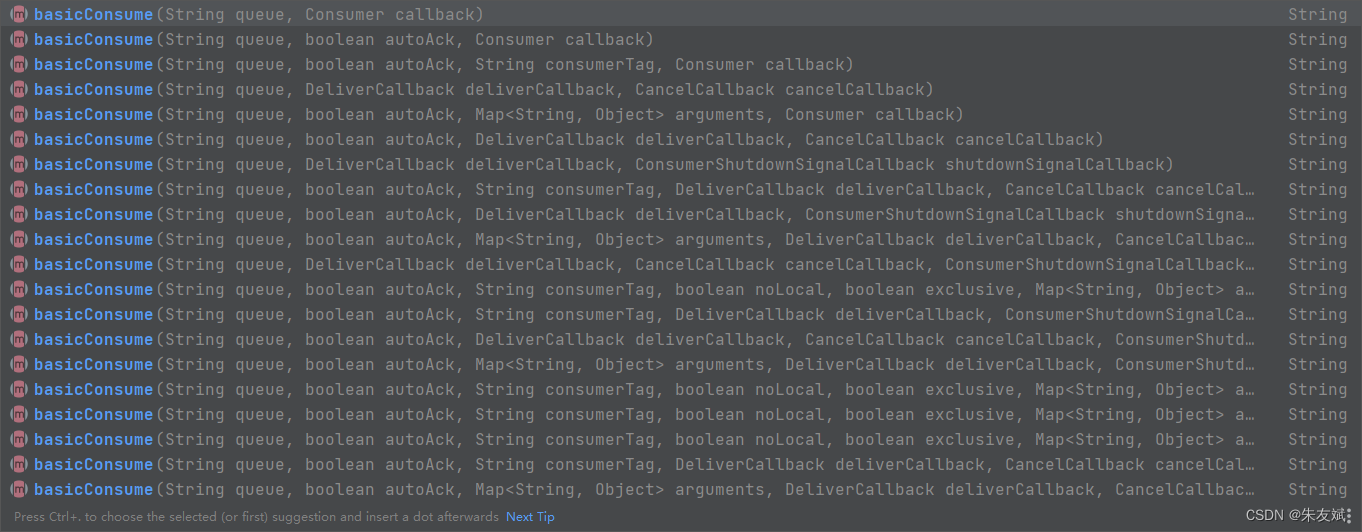
【RabbitMQ笔记09】消息队列RabbitMQ之常见方法的使用
这篇文章,主要介绍消息队列RabbitMQ之常见方法的使用。 目录 一、消息队列常见方法 1.1、连接工厂ConnectionFactory 1.2、连接Connection 1.3、通道Channel 1.4、交换机相关方法 (1)exchangeDeclare()声明交换机 1.5、队列相关方法 …...
Linux字符设备驱动模型之设备号
从上文中可知,在Linux用户空间中,如若需要操作硬件设备,均通过/dev目录下的设备文件节点进行操作,基本上每一种设备都会存在一个或者多个的设备节点。 并且在Linux内核中,其表示字符设备的结构成员也提供了相应的设备号…...

C++多态原理
请看下面的程序,该程序演示了多态类对象存储空间的大小。 #include <iostream> using namespace std; class A {public:int i;virtual void func() {}virtual void func2() {} }; class B : public A {int j;void func() {} }; int main() {cout << si…...

PMP认证与NPDP认证哪个含金量高?
两个证涉及的领域不一样的,一个是项目管理,对应的是项目经理;一个是产品管理,对应的是产品经理。含金量不能相比,但在各自的领域的含金量是很高的,至少专业程度或者知名度是最高的。 我来分别说一下PMP认证…...

改进YOLOv7-Tiny系列:首发改进结合BiFPN结构的特征融合网络,网络融合更多有效特征,高效涨点
💡该教程为改进进阶指南,属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 内容出品:CSDN博客独家更新 @CSDN芒果汁没有芒果 💡本篇文章 基于 YOLOv5、YOLOv7芒果改进YOLO系列:芒果改进YOLOv7-Tiny系列:首发改进结合BiFPN结…...

PPC Insights系列:洞见安全多方图联邦
开放隐私计算开放隐私计算开放隐私计算OpenMPC是国内第一个且影响力最大的隐私计算开放社区。社区秉承开放共享的精神,专注于隐私计算行业的研究与布道。社区致力于隐私计算技术的传播,愿成为中国 “隐私计算最后一公里的服务区”。183篇原创内容公众号知…...
)
SQLite注入记录(目前最全、核心函数用法、布尔盲注、时间盲注、webshell、动态库,绕过方式)
目录 与Mysql区别 全部核心函数 普通注入 查询所有列 查看所有表名...
Java简单的生成/解析二维码(zxing qrcode)
Hi I’m Shendi Java简单的生成/解析二维码(zxing qrcode) 在之前使用 qrcode.js 方式生成二维码,但在不同设备上难免会有一些兼容问题,于是改为后端(Java)生成二维码图片 这里使用 Google 的 zxing包 Jar…...
若依项目导出后端响应的Excel文件流处理
若依开源项目:http://doc.ruoyi.vip/ruoyi-vue 问题 前端 1. download.js 添加自定义方法 /*** 自定义方法:导出后端响应的 excel 文件流* param url 请求后端的接口地址 例如:"/downloadExcel"* param name 响应后的文件名称&…...

华为OD机试【独家】提供C语言题解 - 数组排序
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明数组…...
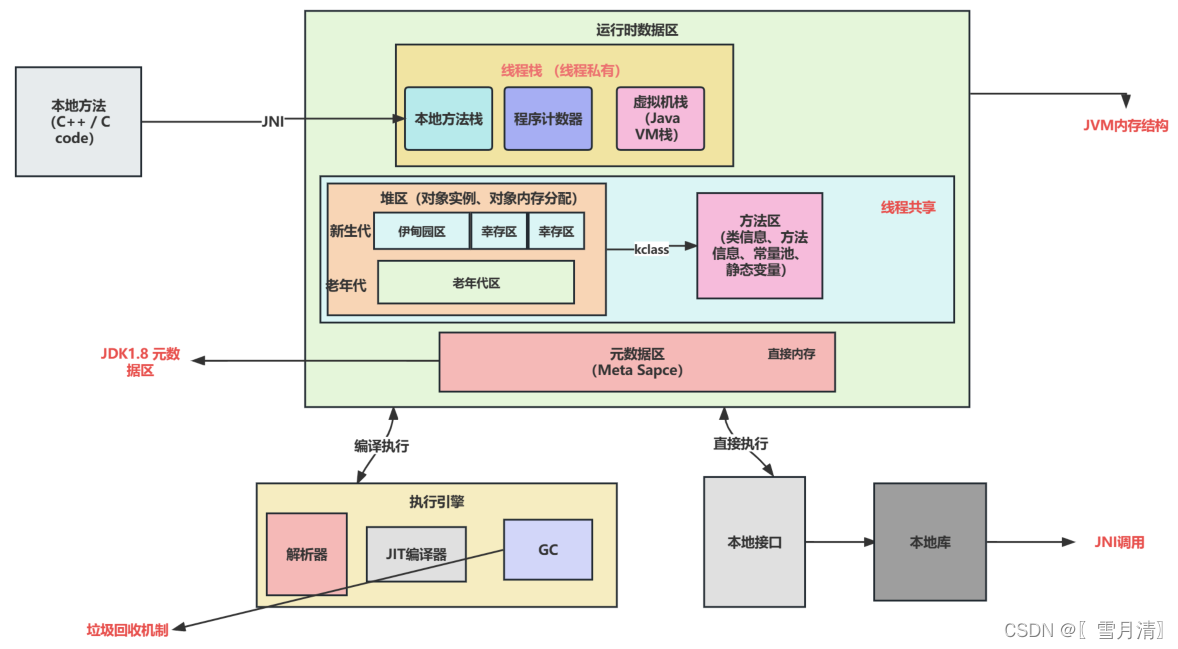
JVM详解——内存结构
文章目录内存结构1、 运行时数据区2、虚拟机栈3、本地方法栈4、程序计数器5、 堆6、方法区7、运行时常量池8、内存溢出和内存泄漏9、 堆溢出内存结构 1、 运行时数据区 Java虚拟机在运行Java程序期间将管理的内存划分为不同的数据区,不同的区域负责不同的职能&…...
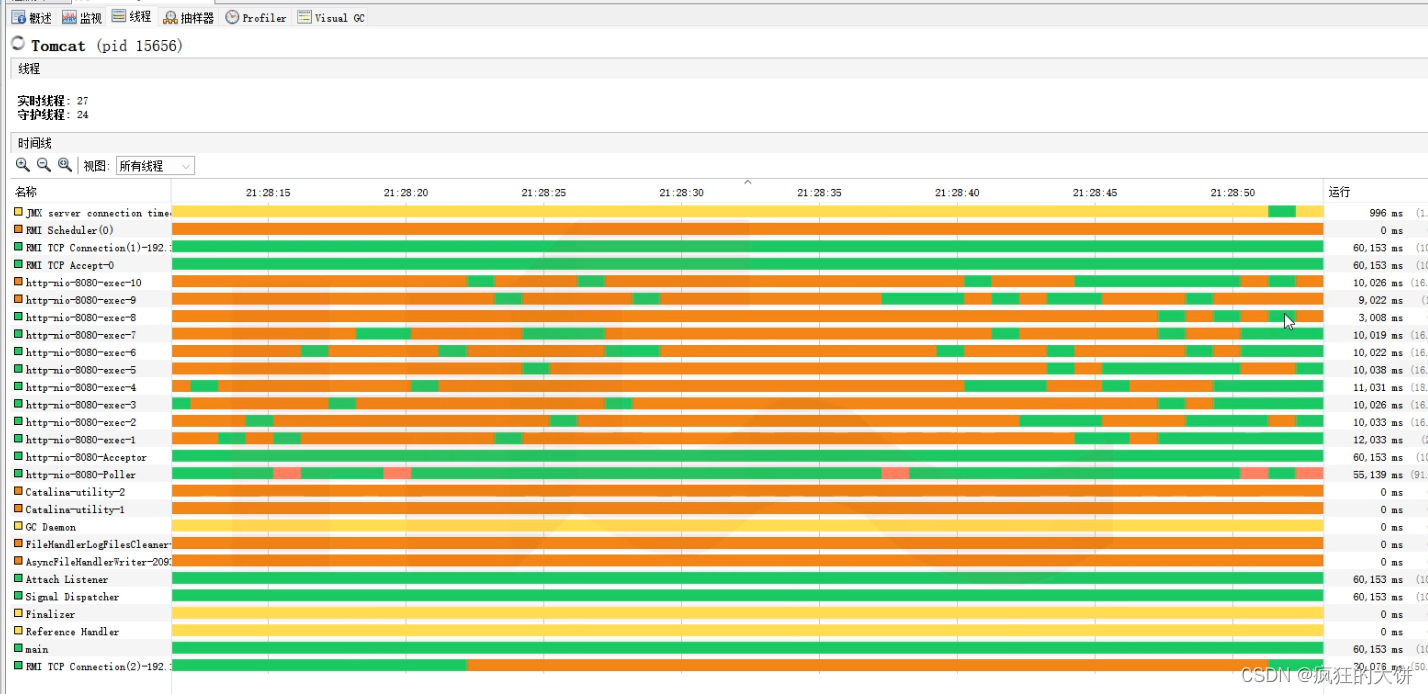
Jvisualvm监控Tomcat以及相关参数优化
Tomcat阻塞模式 阻塞模式(BIO) 客户端和服务器创建一个连接,它就会创建一个线程来处理这个连接,以为这客户端创建了几个连接,服务端就需要创建几个线程来处理你,导致线程会产生很多,有很多线程…...
界面组件DevExpress WinForms v22.2 - 全面升级数据展示功能
DevExpress WinForms拥有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。DevExpress WinForms能完美构建流畅、美观且易于使用的应用程序,无论是Office风格的界面,还是分析处理大批量的业务数据,它都能轻松胜…...
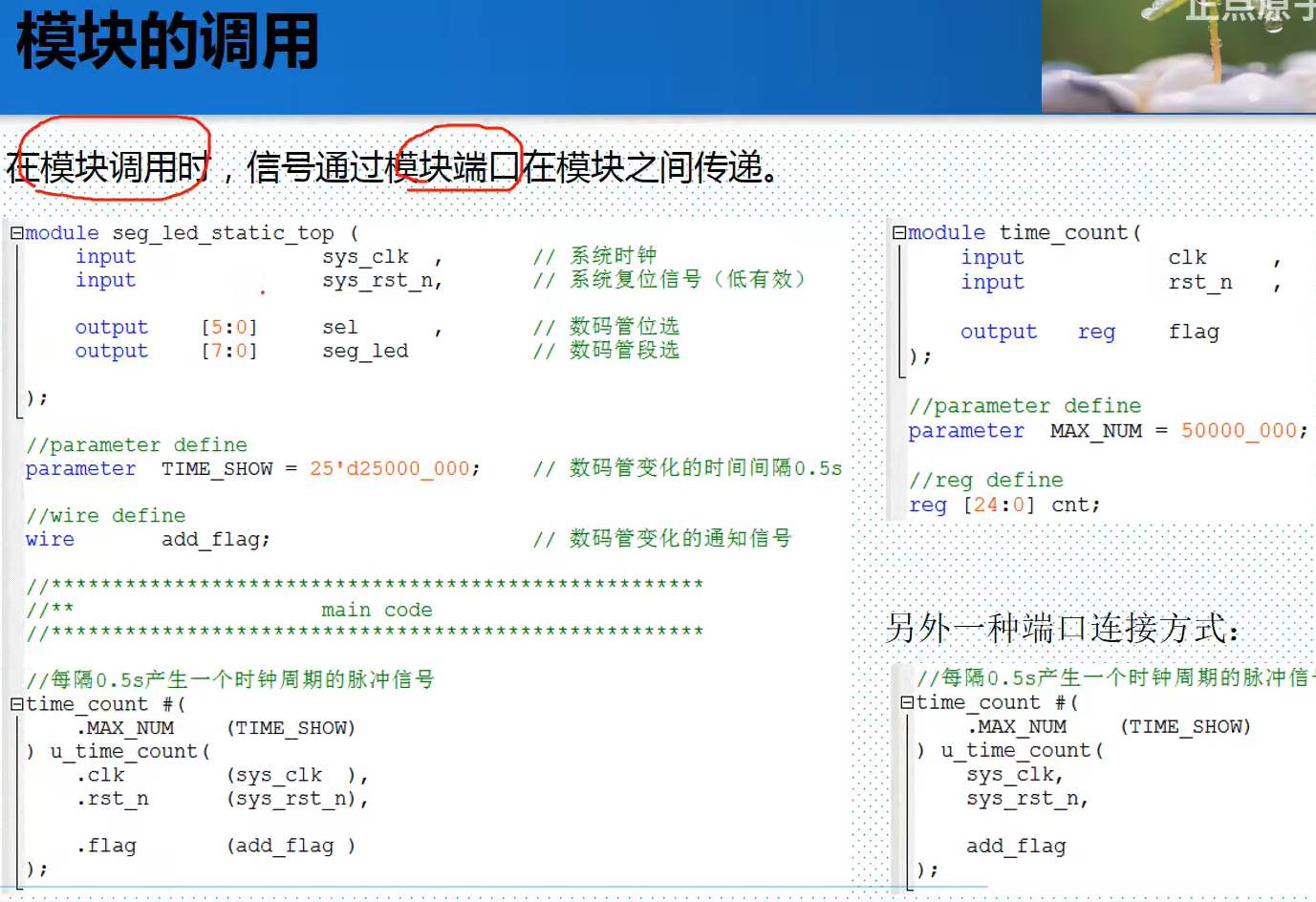
正点原子第一期
ZYNQ是一个fpga用来硬件编程,外加一个软件编程 FPGA是可通过编程来修改其逻辑功能的数字集成电路 第三篇语法篇 第七章 verilog HDL语法 Verilog的简介 可编程逻辑电路:允许用户自行修改内部连接的集成电路,其内部的电路结构可以通过编程数…...
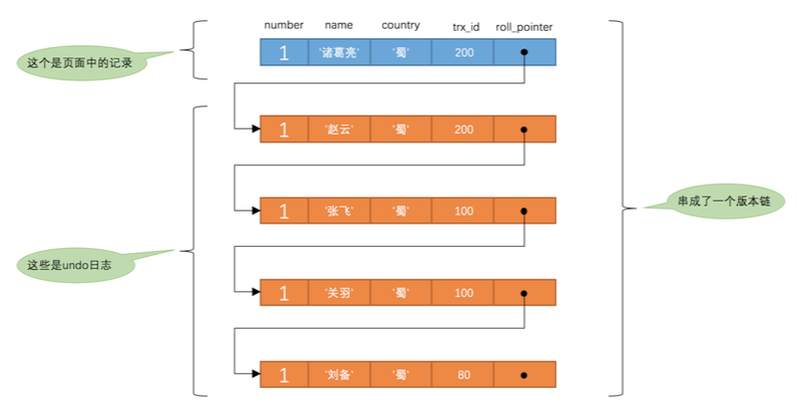
「mysql是怎样运行的」第24章 一条记录的多幅面孔---事务的隔离级别与MVCC
「mysql是怎样运行的」第24章 一条记录的多幅面孔—事务的隔离级别与MVCC 文章目录「mysql是怎样运行的」第24章 一条记录的多幅面孔---事务的隔离级别与MVCC一、事前准备二、事务的隔离级别事务并发执行遇到的问题SQL标准中的四种隔离级别MySQL中支持的四种隔离级别三、MVCC原…...
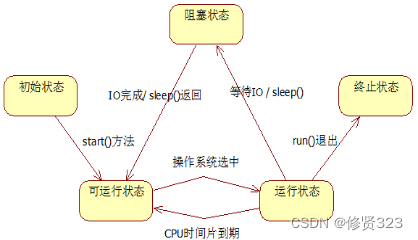
入门Java第十五天 线程
一、多线程 1.1进程和线程 进程:进程就是操作系统中运行的每一个应用程序。例如:微信,QQ 线程:线程是进程中的每一个任务。 多线程:在一个进程中,可以同时执行多个线程。同时完成多个任务。 并发&#x…...

AntiDupl.NET:告别数字杂乱,让图片管理回归优雅
AntiDupl.NET:告别数字杂乱,让图片管理回归优雅 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾经在整理照片时,发现手机里…...

智能图像去重引擎:解放数字存储空间的完整解决方案
智能图像去重引擎:解放数字存储空间的完整解决方案 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 在数字内容爆炸的时代,重复图片问题已成为技…...

Swift原生大语言模型推理引擎llmfarm_core.swift集成与优化指南
1. 项目概述:一个为Swift生态打造的本地大语言模型推理引擎 最近在折腾一个iOS上的AI应用,想把一些轻量级的开源大语言模型(LLM)直接跑在手机端。大家都知道,现在主流的LLM推理框架,像llama.cpp、ollama&am…...

AI小白必看:手把手教你开发大模型智能体,附收藏指南!
本文深入解析AI Agent(智能体)的核心概念与技术架构,通过实战案例展示如何使用LangChain等工具开发智能客服Agent。文章涵盖自主任务拆解、工具调用、多轮交互等关键点,并分享避免“模型幻觉”的实践技巧及性能优化方法。适合程序…...

如何将Android电视变身全能上网终端:TV Bro电视浏览器终极指南
如何将Android电视变身全能上网终端:TV Bro电视浏览器终极指南 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网操作困难而烦恼吗…...

3个步骤搭建Sunshine游戏串流服务器:从零到一的完整指南
3个步骤搭建Sunshine游戏串流服务器:从零到一的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在客厅的电视上玩书房电脑里的3A大作…...

从理论到仿真:深入解读Walker星座设计,用STK验证你的卫星通信作业
从理论到仿真:深入解读Walker星座设计,用STK验证你的卫星通信作业 卫星通信系统的设计从来不是纸上谈兵。当你在教科书上看到那些优美的轨道方程和覆盖计算公式时,是否想过如何将它们转化为真实的系统性能验证?这正是STKÿ…...

Raw Accel终极指南:Windows鼠标加速的完整解决方案
Raw Accel终极指南:Windows鼠标加速的完整解决方案 【免费下载链接】rawaccel kernel mode mouse accel 项目地址: https://gitcode.com/gh_mirrors/ra/rawaccel 你是否厌倦了Windows系统自带的鼠标加速功能?是否在游戏和设计工作中需要更精准的鼠…...

软件开发加速安全审查滞后:“查找 - 修复”与“防御 - 推迟”难敌新风险!
ZDNET的关键要点持续部署让旧安全模型过时,漏洞积压令开发团队不堪重负,应用程序安全需向代码创建阶段转移。锻炼时在跑步机上反复踏步,付出努力却原地不动,毫无成就感,第二天再重复就更觉沮丧。应用程序安全也类似&am…...

MCP协议与n8n集成:构建标准化AI自动化工作流
1. 项目概述:当MCP遇见n8n,一个自动化新范式的诞生最近在折腾自动化工作流,特别是想把不同AI模型的能力串联起来,发现了一个挺有意思的项目:brunopelatieri/mcp-n8n-bruia。这名字乍一看有点复杂,拆开来看&…...