【机器学习】聚类(三):原型聚类:高斯混合聚类
文章目录
- 一、实验介绍
- 1. 算法流程
- 2. 算法解释
- 3. 算法特点
- 4. 应用场景
- 5. 注意事项
- 二、实验环境
- 1. 配置虚拟环境
- 2. 库版本介绍
- 三、实验内容
- 0. 导入必要的库
- 1. 全局调试变量
- 2. 调试函数
- 3. 高斯密度函数(phi)
- 4. E步(getExpectation)
- 5. M步(maximize)
- 6. 数据缩放函数
- 7. 初始化参数
- 8. GMM EM算法函数
- 9. 主函数
- 四、代码整合
高斯混合聚类是一种基于概率模型的聚类方法,采用多个高斯分布的线性组合来表示数据的聚类结构。通过对每个样本的多个高斯分布进行加权组合,该算法能够更灵活地适应不同形状的聚类。
一、实验介绍
1. 算法流程
- 初始化:
初始化高斯混合分布的模型参数,包括每个高斯混合成分的均值向量 μ i \mu_i μi、协方差矩阵 Σ i \Sigma_i Σi 和混合系数 π i \pi_i πi。
{ ( μ 1 , Σ 1 , π 1 ) , ( μ 2 , Σ 2 , π 2 ) , . . . , ( μ k , Σ k , π k ) } \{(\mu_1, \Sigma_1, \pi_1), (\mu_2, \Sigma_2, \pi_2), ..., (\mu_k, \Sigma_k, \pi_k)\} {(μ1,Σ1,π1),(μ2,Σ2,π2),...,(μk,Σk,πk)}
-
迭代过程(EM算法):
- Expectation (E) 步骤:
对于每个样本 X j X_j Xj 计算其由各混合成分生成的后验概率 γ i j \gamma_{ij} γij,表示样本属于第 i i i 个混合成分的概率。
γ i j = π i ⋅ N ( X j ∣ μ i , Σ i ) ∑ l = 1 k π l ⋅ N ( X j ∣ μ l , Σ l ) \gamma_{ij} = \frac{\pi_i \cdot \mathcal{N}(X_j | \mu_i, \Sigma_i)}{\sum_{l=1}^{k} \pi_l \cdot \mathcal{N}(X_j | \mu_l, \Sigma_l)} γij=∑l=1kπl⋅N(Xj∣μl,Σl)πi⋅N(Xj∣μi,Σi)
- Maximization (M) 步骤:
更新模型参数:- 新均值向量 μ i \mu_i μi 的更新: μ i = ∑ j = 1 m γ i j X j ∑ j = 1 m γ i j \mu_i = \frac{\sum_{j=1}^{m} \gamma_{ij} X_j}{\sum_{j=1}^{m} \gamma_{ij}} μi=∑j=1mγij∑j=1mγijXj
- 新协方差矩阵 Σ i \Sigma_i Σi 的更新: Σ i = ∑ j = 1 m γ i j ( X j − μ i ) ( X j − μ i ) T ∑ j = 1 m γ i j \Sigma_i = \frac{\sum_{j=1}^{m} \gamma_{ij} (X_j - \mu_i)(X_j - \mu_i)^T}{\sum_{j=1}^{m} \gamma_{ij}} Σi=∑j=1mγij∑j=1mγij(Xj−μi)(Xj−μi)T
- 新混合系数 π i \pi_i πi 的更新: π i = 1 m ∑ j = 1 m γ i j \pi_i = \frac{1}{m} \sum_{j=1}^{m} \gamma_{ij} πi=m1∑j=1mγij
- Expectation (E) 步骤:
-
停止条件:
根据设定的停止条件,比如达到最大迭代轮数或模型参数的变化小于某一阈值。 -
簇划分:
根据得到的后验概率 γ i j \gamma_{ij} γij 确定每个样本的簇标记,将样本划入概率最大的簇中。C i = { X j ∣ argmax i γ i j , 1 ≤ i ≤ k } C_i = \{X_j | \text{argmax}_i \gamma_{ij}, 1 \leq i \leq k\} Ci={Xj∣argmaxiγij,1≤i≤k}
-
输出:
返回最终的簇划分 C = { C 1 , C 2 , . . . , C k } C = \{C_1, C_2, ..., C_k\} C={C1,C2,...,Ck}。
高斯混合聚类采用了迭代优化的方式,通过不断更新均值向量、协方差矩阵和混合系数,使得模型对数据的拟合更好。EM算法的E步骤计算后验概率,M步骤更新模型参数,整个过程不断迭代直至满足停止条件。最后,将每个样本划分到概率最大的簇中。
2. 算法解释
- 通过EM算法的E步骤,计算每个样本属于每个混合成分的后验概率。
- 通过EM算法的M步骤,更新每个混合成分的均值向量、协方差矩阵和混合系数,优化模型对数据的拟合。
- 算法通过迭代过程,不断调整模型参数,使得混合分布更好地刻画数据的分布。
3. 算法特点
- 通过多个高斯分布的组合,适用于不同形状的聚类结构。
- 采用EM算法进行迭代优化,灵活适应数据的复杂分布。
4. 应用场景
- 适用于数据具有多个分布的情况,且每个分布可以用高斯分布来描述。
- 在图像分割、语音识别等领域广泛应用。
5. 注意事项
- 初始参数的选择可能影响最终聚类效果,因此需要进行多次运行选择最优结果。
- 算法对异常值不敏感,但在特定场景下可能需要考虑异常值的处理。
二、实验环境
1. 配置虚拟环境
conda create -n ML python==3.9
conda activate ML
conda install scikit-learn matplotlib
2. 库版本介绍
| 软件包 | 本实验版本 |
|---|---|
| matplotlib | 3.5.2 |
| numpy | 1.21.5 |
| python | 3.9.13 |
| scikit-learn | 1.0.2 |
三、实验内容
0. 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
from sklearn.datasets import load_iris
1. 全局调试变量
DEBUG = True
- 该变量控制是否在执行过程中打印调试信息。
2. 调试函数
def debug(*args, **kwargs):global DEBUGif DEBUG:print(*args, **kwargs)
- 用于打印调试信息的函数。在整个代码中都使用了它以进行调试。
3. 高斯密度函数(phi)
def phi(Y, mu_k, cov_k):# Check for and handle infinite or NaN values in Ynorm = multivariate_normal(mean=mu_k, cov=cov_k)return norm.pdf(Y)
- 计算多元高斯分布的概率密度函数。
4. E步(getExpectation)
def getExpectation(Y, mu, cov, alpha):N = Y.shape[0]K = alpha.shape[0]assert N > 1, "There must be more than one sample!"assert K > 1, "There must be more than one gaussian model!"gamma = np.mat(np.zeros((N, K)))prob = np.zeros((N, K))for k in range(K):prob[:, k] = phi(Y, mu[k], cov[k]) * alpha[k]prob = np.mat(prob)for k in range(K):gamma[:, k] = prob[:, k] / np.sum(prob, axis=1)return gamma
- EM算法的E步骤,计算每个数据点属于每个簇的概率。主要步骤包括:
- 初始化一个零矩阵
gamma用于存储响应度。 - 对于每个簇,计算每个数据点属于该簇的概率(通过
phi函数计算),然后乘以该簇的混合系数。 - 归一化概率以得到响应度矩阵
gamma。
- 初始化一个零矩阵
5. M步(maximize)
def maximize(Y, gamma):N, D = Y.shapeK = gamma.shape[1]mu = np.zeros((K, D))cov = []alpha = np.zeros(K)for k in range(K):Nk = np.sum(gamma[:, k])mu[k, :] = np.sum(np.multiply(Y, gamma[:, k]), axis=0) / Nkdiff = Y - mu[k]cov_k = np.dot(diff.T, np.multiply(diff, gamma[:, k])) / Nkcov_k += 1e-6 * np.identity(D) # Adding a small value to the diagonal for stabilitycov.append(cov_k)alpha[k] = Nk / Ncov = np.array(cov)return mu, cov, alpha- EM算法的M步骤,即更新模型参数,主要步骤包括:
- 初始化均值
mu、协方差矩阵列表cov和混合系数alpha。 - 对于每个簇,计算新的均值、协方差矩阵和混合系数。均值的更新是通过加权平均计算的,协方差矩阵的更新考虑了数据的权重(响应度),混合系数的更新是每个簇中数据点的权重之和。
- 初始化均值
6. 数据缩放函数
def scale_data(Y):for i in range(Y.shape[1]):max_ = Y[:, i].max()min_ = Y[:, i].min()Y[:, i] = (Y[:, i] - min_) / (max_ - min_)debug("Data scaled.")return Y
- 将数据集中的每个特征缩放到 [0, 1] 范围内。
7. 初始化参数
def init_params(shape, K):N, D = shapemu = np.random.rand(K, D)cov = np.array([np.eye(D)] * K)alpha = np.array([1.0 / K] * K)debug("Parameters initialized.")debug("mu:", mu, "cov:", cov, "alpha:", alpha, sep="\n")return mu, cov, alpha- 初始化GMM的参数(均值、协方差和混合系数)。
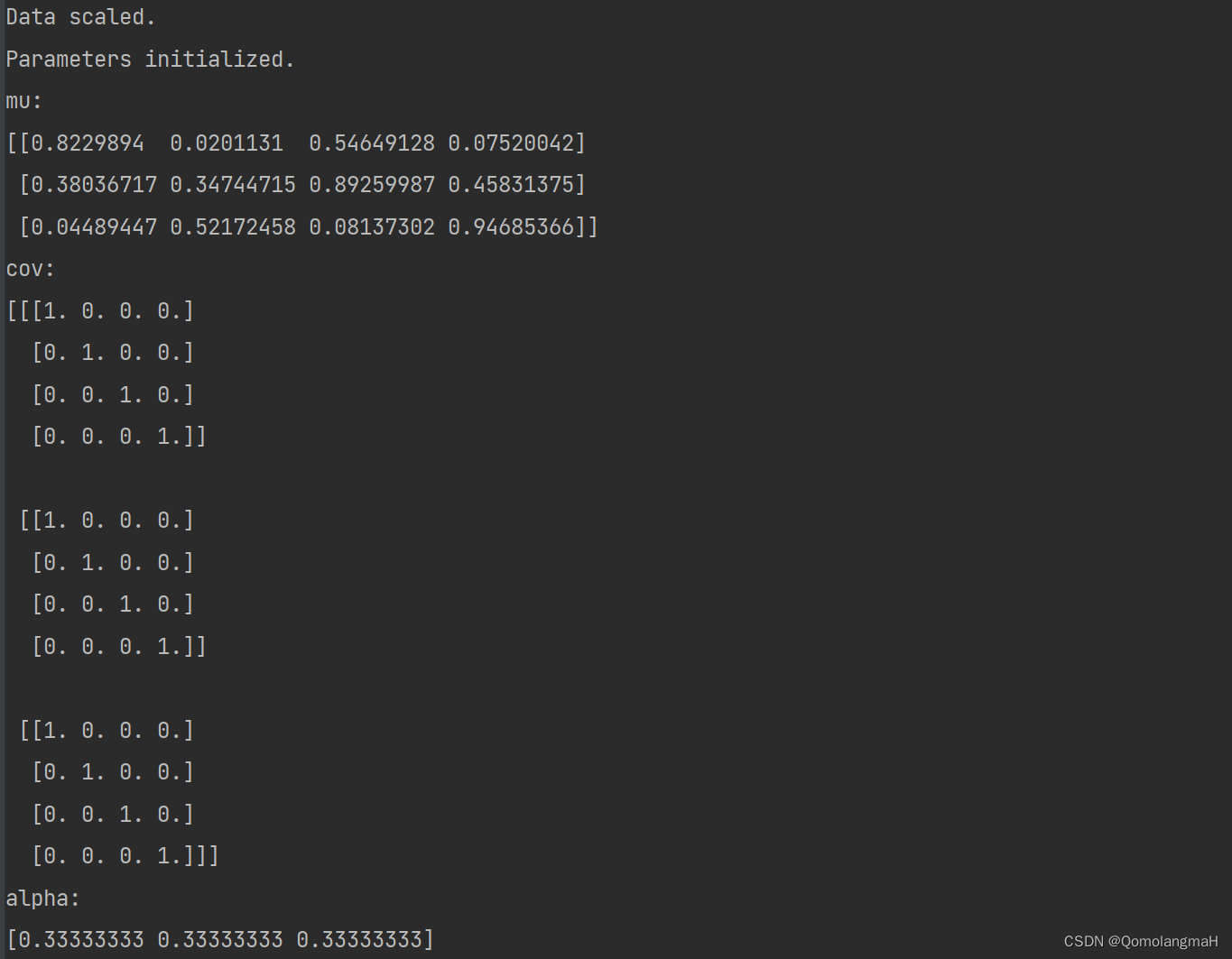
8. GMM EM算法函数
def GMM_EM(Y, K, times):Y = scale_data(Y)mu, cov, alpha = init_params(Y.shape, K)for i in range(times):gamma = getExpectation(Y, mu, cov, alpha)mu, cov, alpha = maximize(Y, gamma)debug("{sep} Result {sep}".format(sep="-" * 20))debug("mu:", mu, "cov:", cov, "alpha:", alpha, sep="\n")return mu, cov, alpha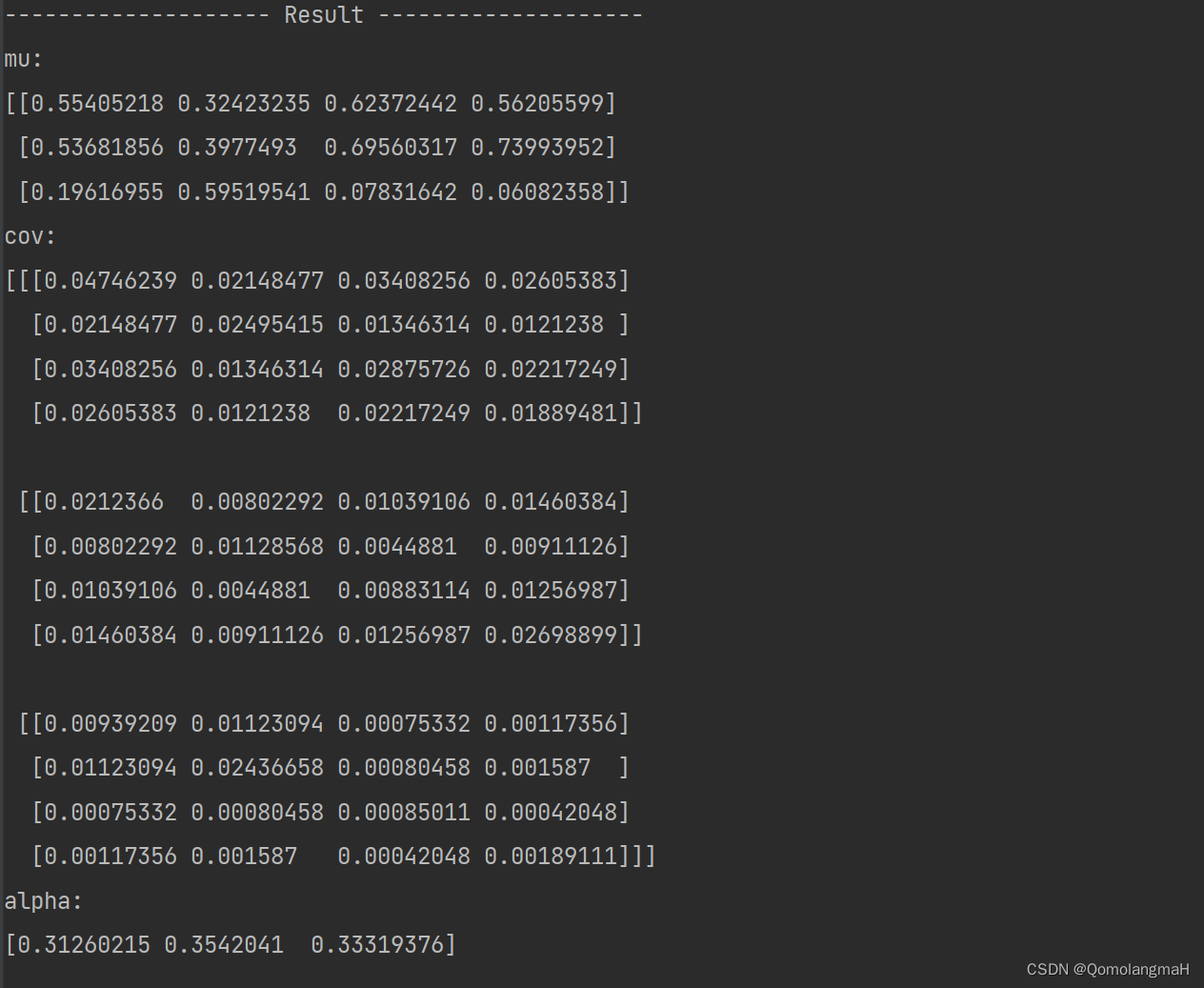
9. 主函数
if __name__ == '__main__':# Load Iris datasetiris = load_iris()Y = iris.data# Model parametersK = 3 # number of clustersiterations = 100# Run GMM EM algorithmmu, cov, alpha = GMM_EM(Y, K, iterations)# Clustering based on the trained modelN = Y.shape[0]gamma = getExpectation(Y, mu, cov, alpha)category = gamma.argmax(axis=1).flatten().tolist()[0]# Plotting the resultsfor i in range(K):cluster_data = np.array([Y[j] for j in range(N) if category[j] == i])plt.scatter(cluster_data[:, 0], cluster_data[:, 1], label=f'Cluster {i + 1}')plt.legend()plt.title("GMM Clustering By EM Algorithm")plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.show()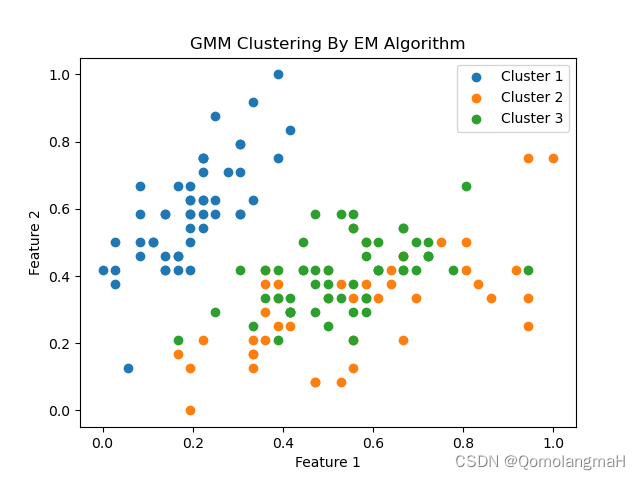
四、代码整合
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
from sklearn.datasets import load_irisDEBUG = Truedef debug(*args, **kwargs):global DEBUGif DEBUG:print(*args, **kwargs)def phi(Y, mu_k, cov_k):# Check for and handle infinite or NaN values in Ynorm = multivariate_normal(mean=mu_k, cov=cov_k)return norm.pdf(Y)def getExpectation(Y, mu, cov, alpha):N = Y.shape[0]K = alpha.shape[0]assert N > 1, "There must be more than one sample!"assert K > 1, "There must be more than one gaussian model!"gamma = np.mat(np.zeros((N, K)))prob = np.zeros((N, K))for k in range(K):prob[:, k] = phi(Y, mu[k], cov[k]) * alpha[k]prob = np.mat(prob)for k in range(K):gamma[:, k] = prob[:, k] / np.sum(prob, axis=1)return gammadef maximize(Y, gamma):N, D = Y.shapeK = gamma.shape[1]mu = np.zeros((K, D))cov = []alpha = np.zeros(K)for k in range(K):Nk = np.sum(gamma[:, k])mu[k, :] = np.sum(np.multiply(Y, gamma[:, k]), axis=0) / Nkdiff = Y - mu[k]cov_k = np.dot(diff.T, np.multiply(diff, gamma[:, k])) / Nkcov_k += 1e-6 * np.identity(D) # Adding a small value to the diagonal for stabilitycov.append(cov_k)alpha[k] = Nk / Ncov = np.array(cov)return mu, cov, alphadef scale_data(Y):for i in range(Y.shape[1]):max_ = Y[:, i].max()min_ = Y[:, i].min()Y[:, i] = (Y[:, i] - min_) / (max_ - min_)debug("Data scaled.")return Ydef init_params(shape, K):N, D = shapemu = np.random.rand(K, D)cov = np.array([np.eye(D)] * K)alpha = np.array([1.0 / K] * K)debug("Parameters initialized.")debug("mu:", mu, "cov:", cov, "alpha:", alpha, sep="\n")return mu, cov, alphadef GMM_EM(Y, K, times):Y = scale_data(Y)mu, cov, alpha = init_params(Y.shape, K)for i in range(times):gamma = getExpectation(Y, mu, cov, alpha)mu, cov, alpha = maximize(Y, gamma)debug("{sep} Result {sep}".format(sep="-" * 20))debug("mu:", mu, "cov:", cov, "alpha:", alpha, sep="\n")return mu, cov, alphaif __name__ == '__main__':# Load Iris datasetiris = load_iris()Y = iris.data# Model parametersK = 3 # number of clustersiterations = 100# Run GMM EM algorithmmu, cov, alpha = GMM_EM(Y, K, iterations)# Clustering based on the trained modelN = Y.shape[0]gamma = getExpectation(Y, mu, cov, alpha)category = gamma.argmax(axis=1).flatten().tolist()[0]# Plotting the resultsfor i in range(K):cluster_data = np.array([Y[j] for j in range(N) if category[j] == i])plt.scatter(cluster_data[:, 0], cluster_data[:, 1], label=f'Cluster {i + 1}')plt.legend()plt.title("GMM Clustering By EM Algorithm")plt.xlabel("Feature 1")plt.ylabel("Feature 2")plt.show()相关文章:
【机器学习】聚类(三):原型聚类:高斯混合聚类
文章目录 一、实验介绍1. 算法流程2. 算法解释3. 算法特点4. 应用场景5. 注意事项 二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 全局调试变量2. 调试函数3. 高斯密度函数(phi)4. E步(getExpectation)…...
线上ES集群参数配置引起的业务异常案例分析
本文介绍了一次排查Elasticsearch node_concurrent_recoveries 引发的性能问题的过程。 一、故障描述 1.1 故障现象 1. 业务反馈 业务部分读请求抛出请求超时的错误。 2. 故障定位信息获取 故障开始时间 19:30左右开始 故障抛出异常日志 错误日志抛出timeout错误。 故障之前…...
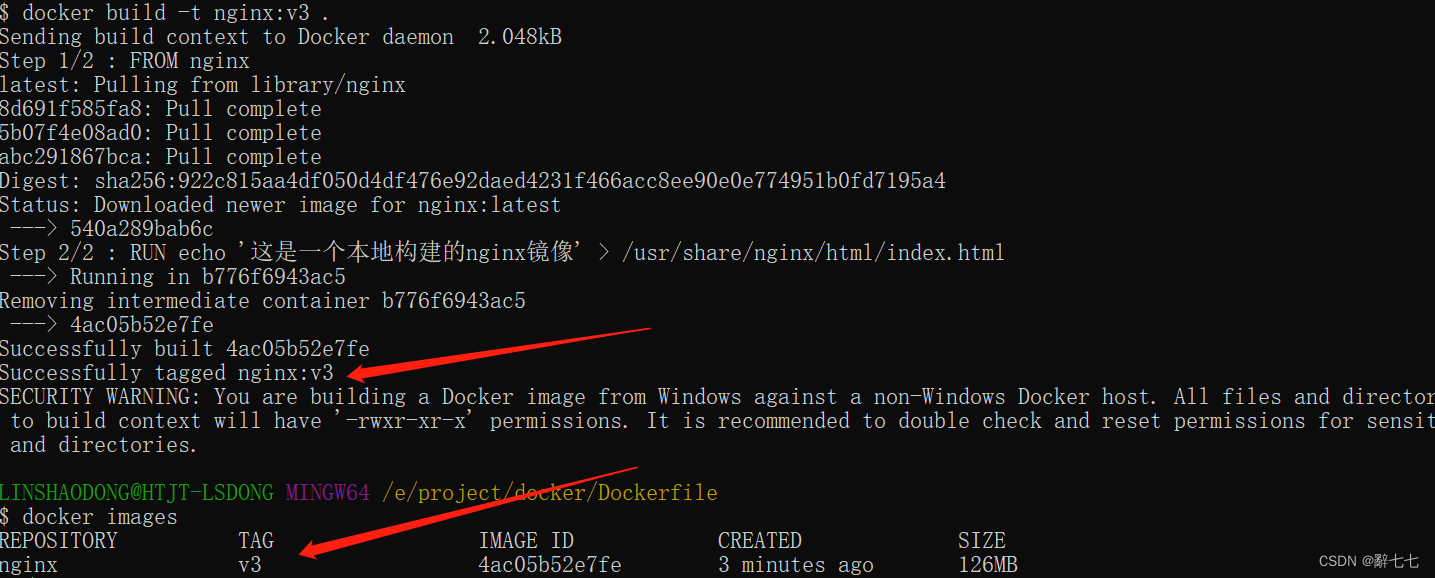
【Docker】Docker 仓库管理和Docker Dockerfile
作者简介: 辭七七,目前大二,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖…...

面试必问:如何快速定位BUG?BUG定位技巧及N板斧!
01 定位问题的重要性 很多测试人员可能会说,我的职责就是找到bug,至于找原因并修复,那是开发的事情,关我什么事? 好,我的回答是,如果您只想做一个测试人员最基本最本分的事情,那么可…...
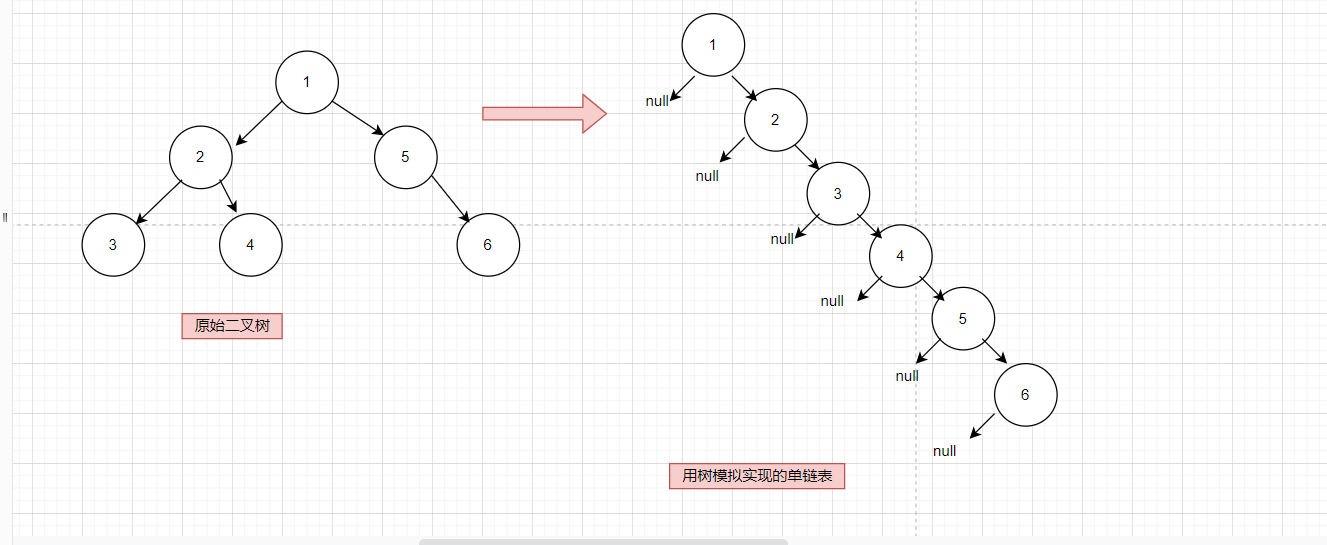
力扣114. 二叉树展开为链表(java,用树模拟链表)
Problem: 114. 二叉树展开为链表 文章目录 题目描述思路解题方法复杂度Code 题目描述 给你二叉树的根结点 root ,请你将它展开为一个单链表: 1.展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左…...
)
学生成绩管理系统(python实现)
学生成绩表信息包括学号、姓名、各科课程成绩(语文、数学、英语、政治)和总分。用带头结点的单链表管理学生成绩表,每个学生的信息依次从键盘输入,并根据需要进行插入、删除、排序、输出等操作。 import json# 初始化系统 studen…...

【Leetcode合集】1410. HTML 实体解析器
1410. HTML 实体解析器 1410. HTML 实体解析器 代码仓库地址: https://github.com/slience-me/Leetcode 个人博客 :https://slienceme.xyz 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 ""…...

04-React脚手架 集成Axios
初始化React脚手架 前期准备 1.脚手架: 用来帮助程序员快速创建一个基于xxx库的模板项目 1.包含了所有需要的配置(语法检查、jsx编译、devServer…)2.下载好了所有相关的依赖3.可以直接运行一个简单效果 2.react提供了一个用于创建react项目的脚手架库…...

时序预测 | MATLAB实现基于BiLSTM-AdaBoost双向长短期记忆网络结合AdaBoost时间序列预测
时序预测 | MATLAB实现基于BiLSTM-AdaBoost双向长短期记忆网络结合AdaBoost时间序列预测 目录 时序预测 | MATLAB实现基于BiLSTM-AdaBoost双向长短期记忆网络结合AdaBoost时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.Matlab实现BiLSTM-Adaboost…...

【nlp】3.6 Tansformer模型构建(编码器与解码器模块耦合)
Tansformer模型构建(编码器与解码器模块耦合) 1. 模型构建介绍2 编码器-解码器结构的代码实现3 Tansformer模型构建过程的代码实现4 小结1. 模型构建介绍 通过上面的小节, 我们已经完成了所有组成部分的实现, 接下来就来实现完整的编码器-解码器结构耦合. Transformer总体架…...
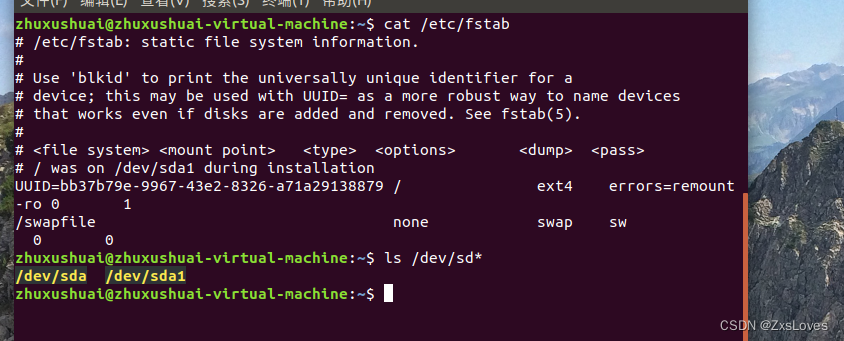
【【Linux系统下常用指令学习 之 二 】】
Linux系统下常用指令学习 之 二 文件查询和搜索 文件的查询和搜索也是最常用的操作,在嵌入式 Linux 开发中常常需要在 Linux 源码文件中查询某个文件是否存在,或者搜索哪些文件都调用了某个函数等等。 1、命令 find find 命令用于在目录结构中查找文件…...

Git-将指定文件回退到指定版本
场景1:修改了文件/path/to/file,没有提交,但是觉得改的不好,想还原。 解决: git checkout -- /path/to/file 场景2:修改了文件/path/to/file,已经提交,但是觉得改的不好,…...

docker环境安装
环境 主机环境 1. 宿主机环境 ubuntu-22.04.3-live-server-amd64 ,下载地址: https://mirrors.aliyun.com/ubuntu-releases/22.04.3/ubuntu-22.04.3-live-server-amd64.iso 2. apt 包管理器,镜像源修改 : 将 http://cn.archive.ubunt…...

【Java】智慧工地云平台源码(APP+SaaS模式)
在谈论“智慧工地”之前,我们首先得知道传统工地为什么跟不上时代了。 说起传统工地,总有一些很突出的问题:比如工友多且杂,他们是否入场、身体状况如何,管理人员只能依靠巡查、手工纪录来判断,耗时耗力&am…...

2016年11月10日 Go生态洞察:七年的Go语言旅程
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

深入了解Java中SQL优化的关键技巧与实践
引言 介绍SQL优化对于Java应用性能的重要性,并概述本文将要讨论的内容。 1. 编写高效的SQL语句 - **索引的类型与使用:** 解释B-Tree索引、哈希索引等类型的区别,以及如何根据查询需求合理创建和使用索引。 - **查询优化器:** 说明…...
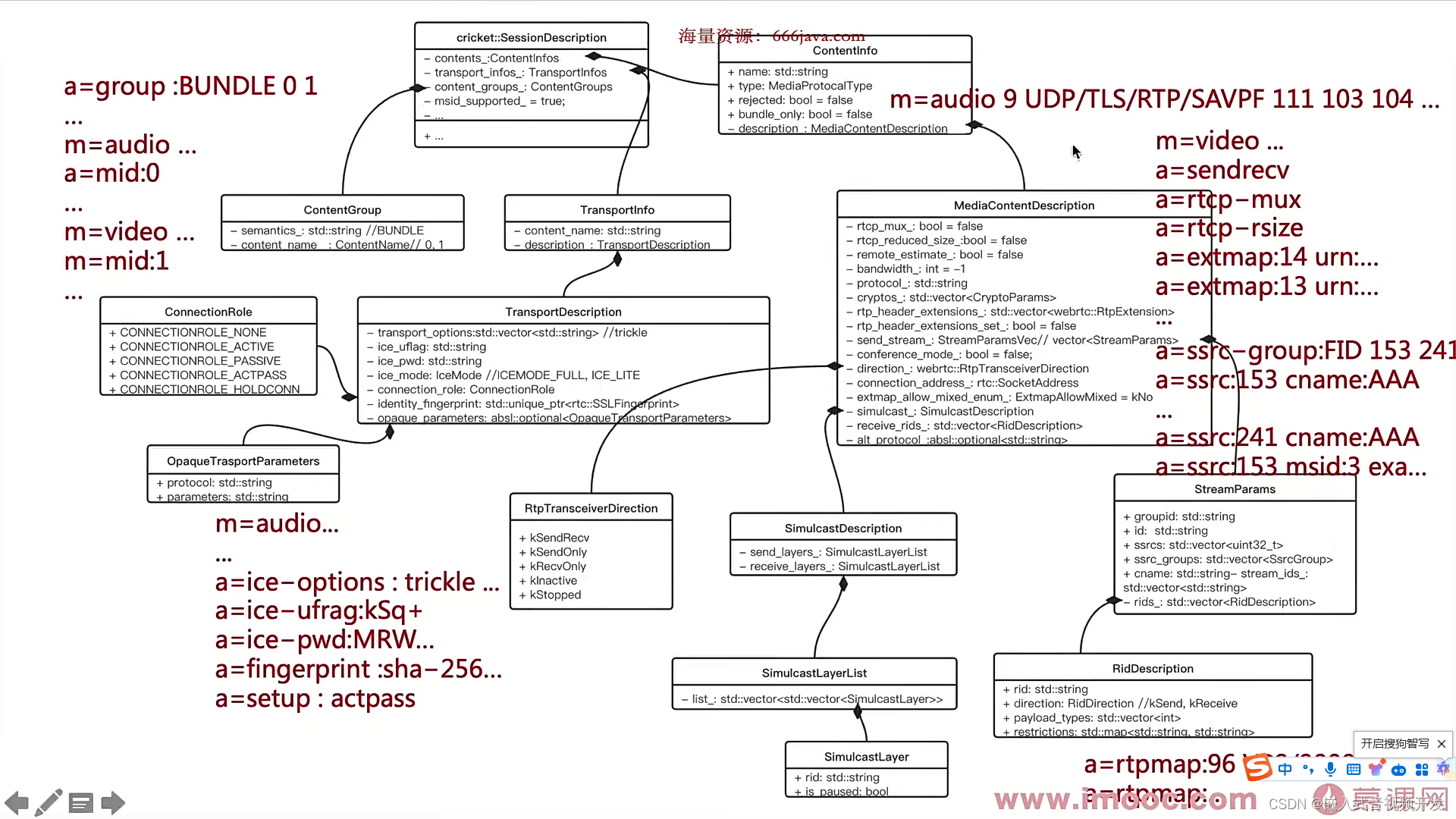
6.3.WebRTC中的SDP类的结构
在上节课中呢,我向你介绍了sdp协议, 那这节课呢,我们再来看看web rtc中。是如何存储sdp的?也就是sdp的类结构,那在此之前呢?我们先对sdp的内容啊,做一下分类。因为在上节课中呢,虽然…...
ArcGis如何用点连线?
这里指的是根据已有坐标点手动连线,类似于mapgis中的“用点连线”,线的每个拐点是可以自动捕捉到坐标点的,比直接画精确。 我也相信这么强大的软件一定可以实现类似于比我的软件上坐标时自动生成的线,但是目前我还没接触到那里&a…...

自定义精美商品分类列表组件 侧边栏商品分类组件 category组件(适配vue3)
随着技术的发展,开发的复杂度也越来越高,传统开发方式将一个系统做成了整块应用,经常出现的情况就是一个小小的改动或者一个小功能的增加可能会引起整体逻辑的修改,造成牵一发而动全身。通过组件化开发,可以有效实现单…...
)
造一个float类型二维矩阵,并将二维矩阵存快速储到一个float*中(memcpy)
// 创建并初始化一个二维数组 std::vector<std::vector<float>> createAndInitializeArray(int rows, int cols) {std::vector<std::vector<float>> array(rows, std::vector<float>(cols));float value 0.0f;for (int i 0; i < rows; i) {…...

瑞士市政邮件服务提供商地图:基于多信号分类,助力数字主权洞察
【导语:目前有研究项目在完善瑞士市政电子邮件服务提供商地图。该地图涵盖约2100个瑞士municipalities,依据公开网络信号展示官方邮件服务提供商格局,代码和数据开源。】瑞士市政邮件服务提供商地图亮相这张地图涵盖了约 2100 个 瑞士 munici…...

野火指南者STM32F103VET6上,用FreeModbus v1.6实现Modbus RTU从站,这5个文件是关键
野火指南者STM32F103VET6上FreeModbus移植的五个核心文件解析 移植FreeModbus协议栈到嵌入式平台时,很多开发者都会遇到相似的困惑——明明按照教程一步步操作,却总是卡在某些关键环节无法正常工作。本文将深入剖析野火指南者开发板(STM32F10…...

00华夏之光永存:黄大年茶思屋榜文解法 鸿蒙生态全场景通信核心卡脖子难题前瞻解析
华夏之光永存:黄大年茶思屋榜文解法「难题揭榜第9期 全5题」 鸿蒙生态全场景通信核心卡脖子难题深度解析 ——第0篇:题目全貌、卡脖子定位与技术价值前瞻 一、摘要 本文为华为黄大年茶思屋难题揭榜第9期前瞻解析篇(第0篇)…...

保姆级教学:Qwen3-4B-Instruct-2507镜像部署,vLLM服务+Chainlit调用一步到位
保姆级教学:Qwen3-4B-Instruct-2507镜像部署,vLLM服务Chainlit调用一步到位 1. 环境准备与快速部署 1.1 镜像获取与启动 Qwen3-4B-Instruct-2507镜像已预装vLLM推理框架和Chainlit交互界面,部署过程简单高效。启动步骤如下: 在…...

三步掌握NS-USBLoader:Switch游戏管理的终极利器
三步掌握NS-USBLoader:Switch游戏管理的终极利器 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.com/gh_mirrors/ns…...

QQ空间说说备份终极指南:5分钟免费导出所有历史记录
QQ空间说说备份终极指南:5分钟免费导出所有历史记录 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心QQ空间里那些珍贵的青春记忆会随着时间流逝而消失?…...

【OpenCV 实战】LBP 统计直方图:从纹理特征到图像识别的关键一步
1. 为什么LBP统计直方图是图像识别的秘密武器? 第一次接触LBP(局部二值模式)时,我盯着那些黑白相间的纹理图看了半天——这不就是把像素点变成01编码吗?直到把统计直方图加进去,才发现这个组合简直是纹理识…...

题解:洛谷 AT_abc391_b [ABC391B] Seek Grid
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大家订阅我的专栏:算法…...
Pixel Couplet Gen 实战:为“黑马点评”APP添加春节AI春联分享功能
Pixel Couplet Gen 实战:为"黑马点评"APP添加春节AI春联分享功能 1. 场景需求与痛点分析 春节将至,本地生活类APP"黑马点评"希望增加节日特色功能来提升用户活跃度。传统做法是设计几套固定模板的春联供用户选择,但这种…...

招聘类 Android 应用开发全栈实践与性能优化
引言 移动互联网时代,招聘平台已成为连接人才与企业的核心桥梁。作为 Android 开发工程师,负责招聘类应用的研发工作,不仅要求扎实的底层技术功底,更需要深刻理解招聘场景下的业务逻辑、用户交互特性以及对性能与稳定性的极致追求。本文将围绕一个招聘类 Android 应用从 0…...