线上ES集群参数配置引起的业务异常案例分析
本文介绍了一次排查Elasticsearch node_concurrent_recoveries 引发的性能问题的过程。
一、故障描述
1.1 故障现象
1. 业务反馈
业务部分读请求抛出请求超时的错误。
2. 故障定位信息获取
-
故障开始时间
19:30左右开始
-
故障抛出异常日志
错误日志抛出timeout错误。
-
故障之前的几个小时业务是否有进行发版迭代。
未进行相关的发版迭代。
-
故障的时候流量是否有出现抖动和突刺情况。
内部监控平台观察业务侧并没有出现流量抖动和突刺情况。
-
故障之前的几个小时Elasticsearch集群是否有出现相关的变更操作。
Elasticsearch集群没有做任何相关的变更操作。
1.2 环境
-
Elaticsearch的版本:6.x。
-
集群规模:集群数据节点超过30+。
二、故障定位
我们都知道Elasticsearch是一个分布式的数据库,一般情况下每一次查询请求协调节点会将请求分别路由到具有查询索引的各个分片的实例上,然后实例本身进行相关的query和fetch,然后将查询结果汇总到协调节点返回给客户端,因此存在木桶效应问题,查询的整体性能则是取决于是查询最慢的实例上。所以我们需要确认导致该故障是集群整体的问题还是某些实例的问题导致的。
2.1 集群还是实例的问题
1. 查看所有实例的关键监控指标
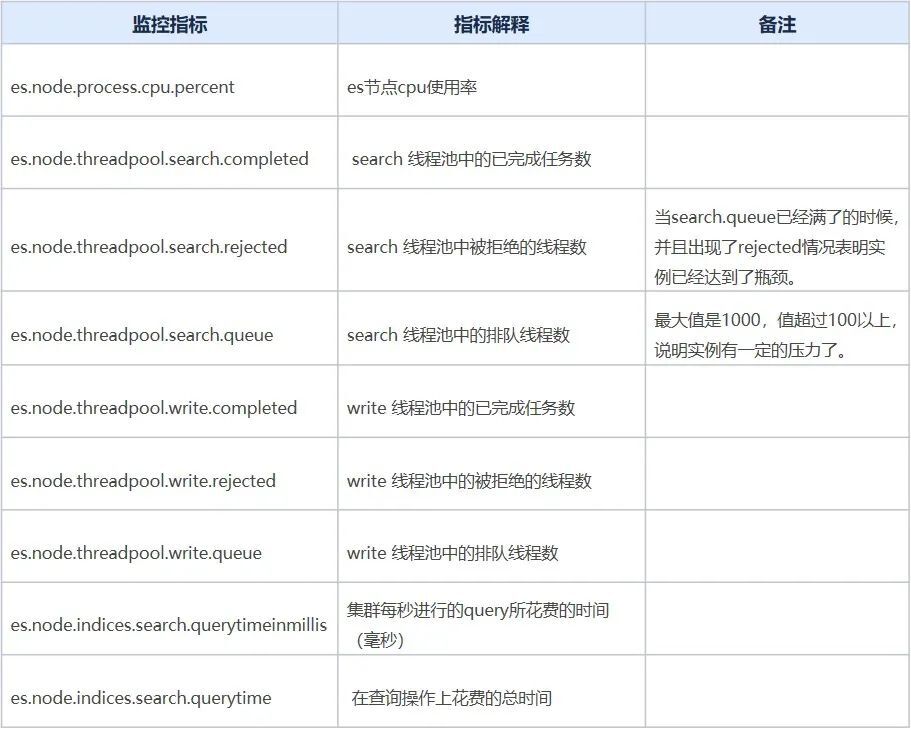
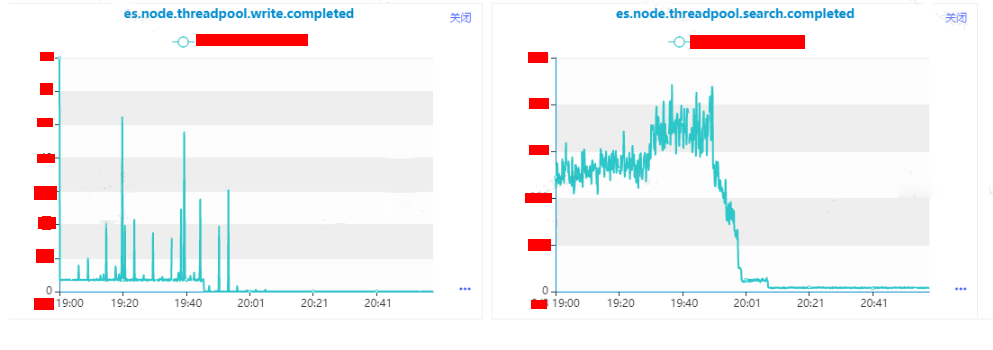
从监控图可以很明显的绿色监控指标代表的实例在19:30左右开始是存在异常现象,在这里我们假设该实例叫做A。
-
实例A的指标es.node.threadpool.search.queue的值长时间达到了1000,说明读请求的队列已经满了。
-
实例A的指标es.node.threadpool.search.rejected的值高峰期到了100+,说明实例A无法处理来自于业务的所有请求,有部分请求是失败的。
-
集群整体的指标es.node.threadpool.search.completed有出现增长,经过业务沟通和内部平台监控指标的观察,业务流量平缓,并没有出现抖动现象,但是客户端有进行异常重试机制,因此出现增长是因为重试导致。
-
实例A的指标es.node.threadpool.search.completed相比集群其他实例高50%以上,说明实例A上存在一个到多个热点索引。
-
实例A的指标es.node.threadpool.cpu.percent的值有50%以上的增长。
-
可通过指标es.node.indices.search.querytime和es.node.indices.search.querytimeinmillis的趋势可实例级别的请求耗时大致情况。
通过上面的分析,我们能给确认的是实例A是存在异常,但是导致业务请求超时是否是实例A异常导致,还需进一步分析确认。
2.2 实例异常的原因
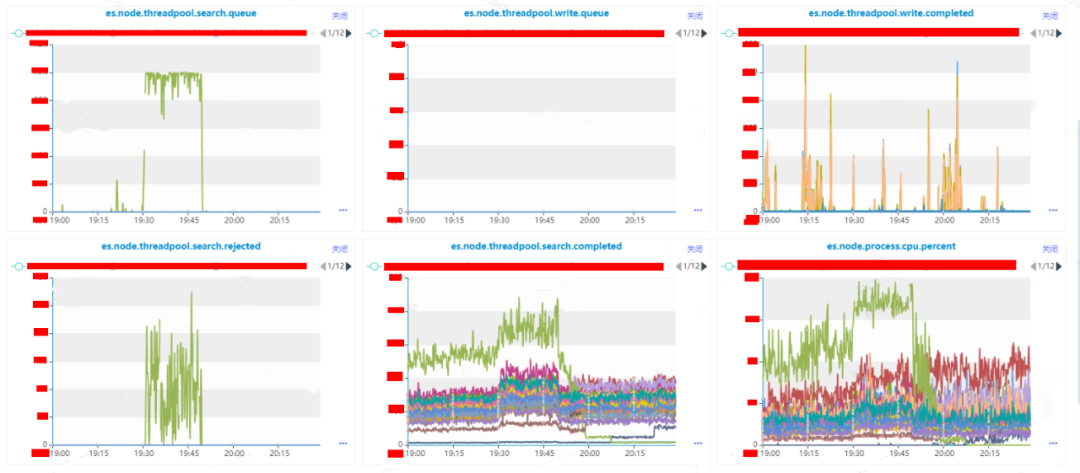
到了这一步,我们能够非常明确实例是存在异常情况,接下来我们需要定位是什么导致实例异常。在这里我们观察下实例所在机器的MEM.CACHED、DISK.nvme0n1.IO.UTIL、CPU.SERVER.LOADAVG.PERCORE、CPU.IDLE这些CPU、MEMMORY、DISK IO等指标。
1. CPU or IO
通过监控,我们可以很明显的看得到,DISK.nvme0n1.IO.UTIL、CPU.SERVER.LOADAVG.PERCORE、CPU.IDLE这三个监控指标上是存在异常情况的。
DISK.nvme0n1.IO.UTIL上深红色和深褐色指标代表的机器IO使用率存在异常,在这里我们假设深红色的机器叫做X,深褐色的机器叫做Y。
CPU.SERVER.LOADAVG.PERCORE和CPU.IDLE这俩个反应CPU使用情况的指标上代表绿色的机器在存在异常,在这里我们假设绿色的机器叫做Z。
-
机器X的IO在故障时间之前就处于满载情况,机器X在整个过程当中是没有出现波动,因此可移除机器X可能导致集群受到影响。
-
机器Y的IO在故障时间之前是处于满载情况,但是在故障期间IO使用率差不多下降到了50%,因此可移除机器Y可能导致集群受到影响。
-
机器Z的CPU使用率在在故障期间直线下降,CPU.IDLE直接下降到个位数;CPU.SERVER.LOADAVG.PERCORE(是单核CPU的平均负载,2.5表示当前负载是CPU核数*2.5)直接增长了4倍,此时整个机器几乎都是处于阻塞的情况;DISK.nvme0n1.IO.UTIL则是从20%增长到了50%左右。其中CPU的指标是直线增长,IO的指标则是一个曲线增长。
异常实例A所在的机器是Z,目前机器Z的CPU和IO都存在增长情况,其中CPU已经到了系统的瓶颈,系统已经受到了阻塞,IO的利用率从20%增长到了50%,虽然有所增长,但是还未到达磁盘的瓶颈。
通过上面的分析,我们比较倾向于机器Z的CPU的异常导致了实例A的异常。这个时候我们需要确认是什么原因导致了机器Z的CPU异常,这个时候可通过内部监控平台的快照查看机器Z的快照信息。
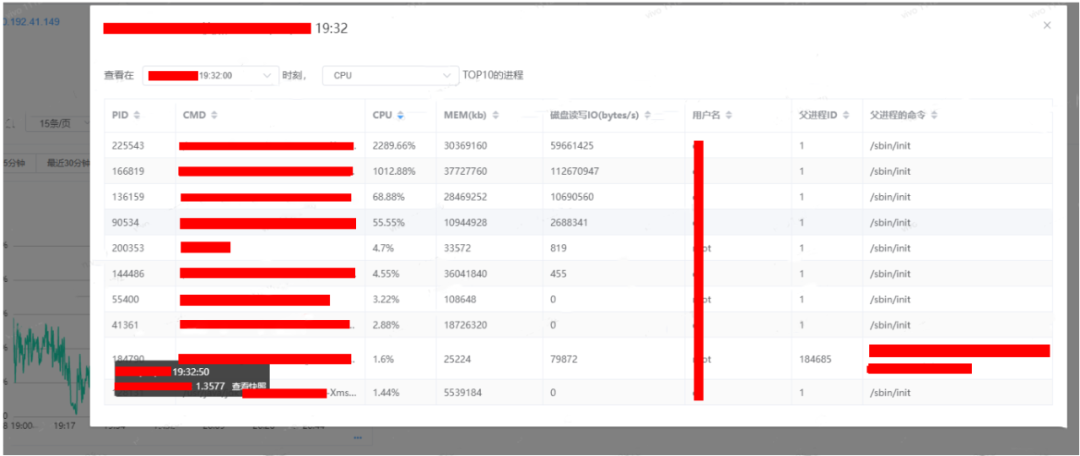
通过内部监控平台的快照,我们可以看到PID为225543的CPU使用率是2289.66%,166819的CPU的使用率是1012.88%。需要注意的是我们机器Z的逻辑核是32C,因此我们可认为CPU机器CPU的使用率理论上最高是3200%。但是使用率CPU最高的俩个实例的值加起来已经是超过了这个值,说明CPU资源已经是完全被使用完毕了的。
通过登陆机器Z,查询获取得到PID为225543的进程就是实例A的elasticsearch进程。
2. 实例CPU异常的原因
其实Elasticsearch本身是有接口提供获取实例上的热点进程,但是当时执行接口命令的时候长时间没有获取到结果,因此只能从其他方案想办法了。
获取实例上的热点进程:
curl -XGET /_nodes/xx.xx.xx.xx/hot_threads?pretty -s实例A的CPU使用率高一般导致这个情况原因一个是并发过高导致实例处理不过来,另外一个则是存在任务长时间占据了进程资源,导致无多余的资源处理其他的请求。所以我们首先基于这俩个情形进行分析。
(1)是否并发度过高引起实例CPU异常
从之前的分析我们可以得知业务侧的流量是没有出现突增,search.completed的增长只是因为业务重试机制导致的,因此排除并发过高的原因了,那么剩下的就只有存在长任务的原因了。
(2)是否长任务导致实例CPU异常
根据_cat/tasks查看当前正在执行的任务,默认会根据时间进行排序,任务running时间越长,那么就会排到最前面,上面我们得知异常的实例只有A,因此我们可以只匹配实例A上的任务信息。
curl -XGET '/_cat/tasks?v&s=store' -s | grep A一般情况下大部分任务都是在秒级以下,若是出现任务执行已超过秒级或者分钟级的任务,那么这个肯定就是属于长任务。
(3)什么长任务比较多
根据接口可以看得到耗时较长的都是relocate任务,这个时候使用查看接口/_cat/shards查看分片迁移信息,并且并发任务还很多,持续时间相较于其他任务来说很长。
curl -XGET '/_cat/shards?v&s=store' -s | grep A由于当时是优先恢复业务,因此没有截图,最后只能从监控获取得到这个时间是有进行relocate分片的迁移操作:
-
es.node.indices.segment.count:实例级别segment的个数。
-
es.cluster.relocatingshards:集群级别正在进行relocate的分片数量。
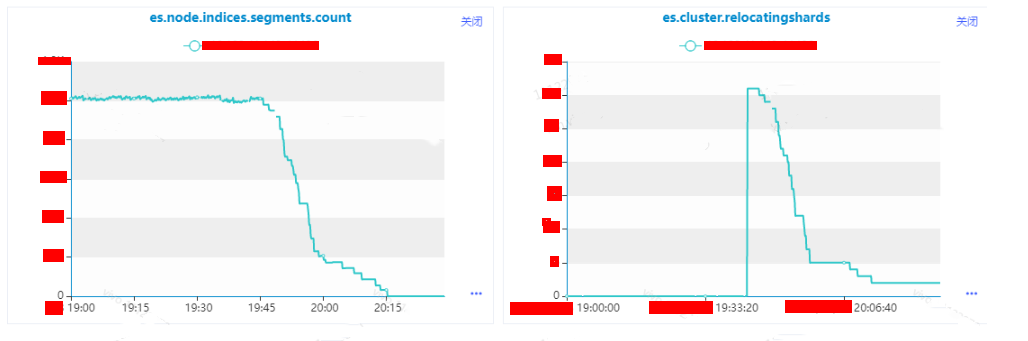
(4)什么原因导致了分片迁移变多
根据日常的运维,一般出现分片迁移的情况有:
-
实例故障。
-
人工进行分片迁移或者节点剔除。
-
磁盘使用率达到了高水平位。
根据后续的定位,可以排除实例故障和人工操作这俩项,那么进一步定位是否由于磁盘高水平位导致的。
查看实例级别的监控:
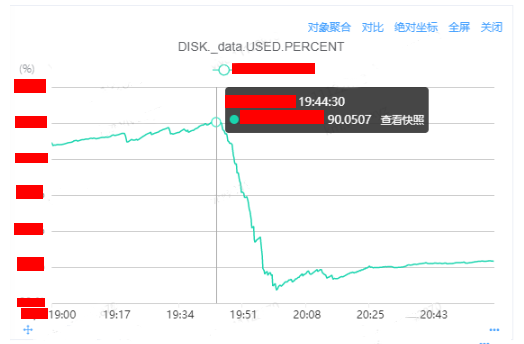
查看master的日志:
[xxxx-xx-xxT19:43:28,389][WARN ][o.e.c.r.a.DiskThresholdMonitor] [master] high disk watermark [90%] exceeded on [ZcphiDnnStCYQXqnc_3Exg][A][/xxxx/data/nodes/0] free: xxxgb[9.9%], shards will be relocated away from this node
[xxxx-xx-xxT19:43:28,389][INFO ][o.e.c.r.a.DiskThresholdMonitor] [$B] rerouting shards: [high disk watermark exceeded on one or more nodes]根据监控和日志能够进一步确认是磁盘使用率达到了高水平位从而导致的迁移问题。
(5)确认引起磁盘上涨的实例
通过内部监控平台的DB监控,查看机器级别上所有实例的监控指标
es.instance.data_size:
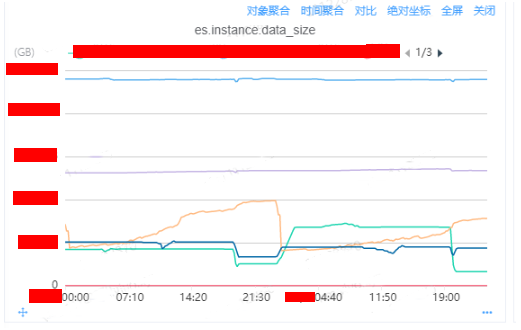
通过监控我们分析可以得到浅黄色、深蓝色、浅绿色三个实例是存在较大的磁盘数据量大小的增长情况,可以比较明显导出磁盘增长到90%的原因是浅黄色线代表的实例导致的原因。
2.3 根因分析
针对实例A磁盘波动情况进行分析:
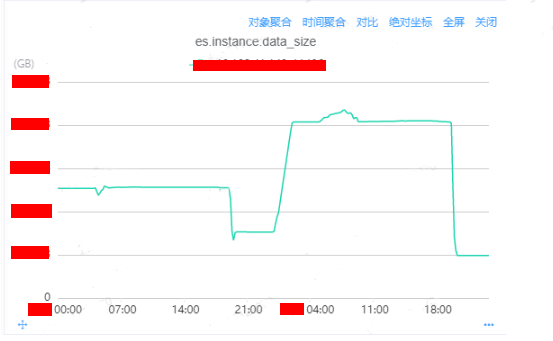
查看这个监控图,你会发现存在异常:
-
磁盘数据量的下降和上升并不是一个缓慢的曲线。
-
2023-02-07 19:20左右也发生过磁盘下降的情况。
出现磁盘的下降和趋势一次性比较多的情况,根据以往的经验存在:
-
大规模的刷数据。
-
relocate的分片是一个大分片。
-
relocate并发数比较大。
第一个排除了,大规模的刷数据只会导致数据上升,并不会出现数据下降的情况,因此要么就是大分片,要么就是并发较大。
查看是否存在大分片:
# curl -XGET '/_cat/shards?v&s=store' -s | tail
index_name 4 r STARTED 10366880 23.2gb
index_name 4 p STARTED 10366880 23.2gb
index_name 0 r STARTED 10366301 23.2gb
index_name 0 p STARTED 10366301 23.2gb
index_name 3 p STARTED 10347791 23.3gb
index_name 3 r STARTED 10347791 23.3gb
index_name 2 p STARTED 10342674 23.3gb
index_name 2 r STARTED 10342674 23.3gb
index_name 1 r STARTED 10328206 23.4gb
index_name 1 p STARTED 10328206 23.4gb查看是否存在重定向并发数较大:
# curl -XGET '/_cluster/settings?pretty'
{
... ..."transient" : {"cluster" : {"routing" : {"allocation" : {"node_concurrent_recoveries" : "5","enable" : "all"}}}}
}发现参数cluster.allocation.node_concurrent_recoveries设置成了5,我们看下官方针对这个参数的解释:Cluster Level Shard Allocation | Elasticsearch Guide [6.3] | Elastic
大致意思是同一个时间允许多个的分片可以并发的进行relocate或者recovery,我们就按照较大的分片数量20G*5,差不多就是100G左右,这个就解释了为什么data_size的增长和下降短时间内非常大的数据量的原因了。
到目前为止,我们能够确认的是因为分片迁移的问题消耗了实例A很大的CPU资源,从而导致实例A的CPU指标非常的高。
三、解决方案
基于上面的分析,我们假设由于实例A的异常导致集群整的异常;基于这种假设,我们尝试将实例A剔除集群,观察集群和业务的请求是否能够恢复。
3.1 猜想验证
将实例的分片迁移到其他的实例上,执行以下命令之后,可以明显的发现实例上的请求基本上下降为零了,并且业务反馈超时也在逐步的减少,基于这个情况验证了我们的猜想,是实例A的异常导致了业务的请求超时的情况。
curl -XPUT /_cluster/settings?pretty -H 'Content-Type:application/json' -d '{"transient":{"cluster.routing.allocation.exclude._ip": "xx.xx.xx.xx"}
}'
3.2 根本解决
猜想验证确认之后,那我们现在基于实例A的CPU的异常结果进行相关的优化:
修改参数cluster.routing.allocation.node_concurrent_recoveries
-
该参数默认值是2,一般是不建议修改这个参数,但是有需要快速迁移要求的业务可以动态修改这个参数,建议不要太激进,开启之后需要观察实例、机器级别的CPU、磁盘IO、网络IO的情况。
修改参数cluster.routing.use_adaptive_replica_selection
-
开启该参数之后,业务针对分片的读取会根据请求的耗时的响应情况选择下次请求是选择主分片还是副分片。
-
6.3.2版本默认是关闭了该参数,业务默认会轮询查询主副分片,这在部分实例异常的情况会影响集群的整体性能。针对生产环境、单机多实例混合部署的情况下,建议开启该参数,对集群的性能有一定的提高。
-
7.x的版本默认是开启了这个参数。
curl -XPUT /_cluster/settings?pretty -H 'Content-Type:application/json' -d '{"transient":{"cluster.routing.allocation.node_concurrent_recoveries": 2,"cluster.routing.use_adaptive_replica_selection":true }
}'直接扩容或者迁移实例也是比较合适的。
四、总结
在本次故障,是由于集群参数配置不正确,导致集群的一个实例出现异常从而导致了业务的请求异常。但是在我们在进行故障分析的时候,不能仅仅只是局限于数据库侧,需要基于整个请求链路的分析,从业务侧、网络、数据库三个方面进行分析:
-
业务侧:需确认业务的所在的机器的CPU、网络和磁盘IO、内存是否使用正常,是否有出现资源争用的情况;确认JVM的gc情况,确认是否是因为gc阻塞导致了请求阻塞;确认流量是否有出现增长,导致Elasticsearch的瓶颈。
-
网络侧:需确认是否有网络抖动的情况。
-
数据库侧:确认是Elasticsearch是否是基于集群级别还是基于实例级别的异常;确认集群的整体请求量是否有出现突增的情况;确认异常的实例的机器是否有出现CPU、网络和磁盘IO、内存的使用情况。
确认哪方面的具体故障之后,就可以进一步的分析导致故障的原因。
参数控制:
Elasticsearch本身也有一些参数在磁盘使用率达到一定的情况下来控制分片的分配策略,默认该策略是开启的,其中比较重要的参数:
-
cluster.routing.allocation.disk.threshold_enabled:默认值是true,开启磁盘分分配决策程序。
-
cluster.routing.allocation.disk.watermark.low:默认值85%,磁盘使用低水位线。达到该水位线之后,集群默认不会将分片分配达到该水平线的机器的实例上,但是新创建的索引的主分片可以被分配上去,副分片则不允许。
-
cluster.routing.allocation.disk.watermark.high:默认值90%,磁盘使用高水位线。达到该水位线之后,集群会触发分片的迁移操作,将磁盘使用率超过90%实例上的分片迁移到其他分片上。
-
cluster.routing.allocation.disk.watermark.high:默认值95%。磁盘使用率超过95%之后,集群会设置所有的索引开启参数read_only_allow_delete,此时索引是只允许search和delete请求。
补充:
一旦一台机器上的磁盘使用率超过了90%,那么这台机器上所有的ES实例所在的集群都会发起分片的迁移操作,那么同一时间发起并发的最大可能是:ES实例数*cluster.routing.allocation.node_concurrent_recoveries,这个也会导致机器的CPU、IO等机器资源进一步被消耗,从而所在的实例性能会更差,从而导致路由到机器上实例的分片的性能会更差。
一旦一台机器上磁盘使用率超过95%,那么这台机器上所有的实例所在的集群都会开启集群级别的参数read_only_allow_delete,此时不仅仅是一个集群,而是一个或者多个集群都无法写入,只能进行search和delete。
文章转载自:vivo互联网技术
原文链接:https://www.cnblogs.com/vivotech/p/17851197.html
相关文章:
线上ES集群参数配置引起的业务异常案例分析
本文介绍了一次排查Elasticsearch node_concurrent_recoveries 引发的性能问题的过程。 一、故障描述 1.1 故障现象 1. 业务反馈 业务部分读请求抛出请求超时的错误。 2. 故障定位信息获取 故障开始时间 19:30左右开始 故障抛出异常日志 错误日志抛出timeout错误。 故障之前…...
【Docker】Docker 仓库管理和Docker Dockerfile
作者简介: 辭七七,目前大二,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖…...

面试必问:如何快速定位BUG?BUG定位技巧及N板斧!
01 定位问题的重要性 很多测试人员可能会说,我的职责就是找到bug,至于找原因并修复,那是开发的事情,关我什么事? 好,我的回答是,如果您只想做一个测试人员最基本最本分的事情,那么可…...
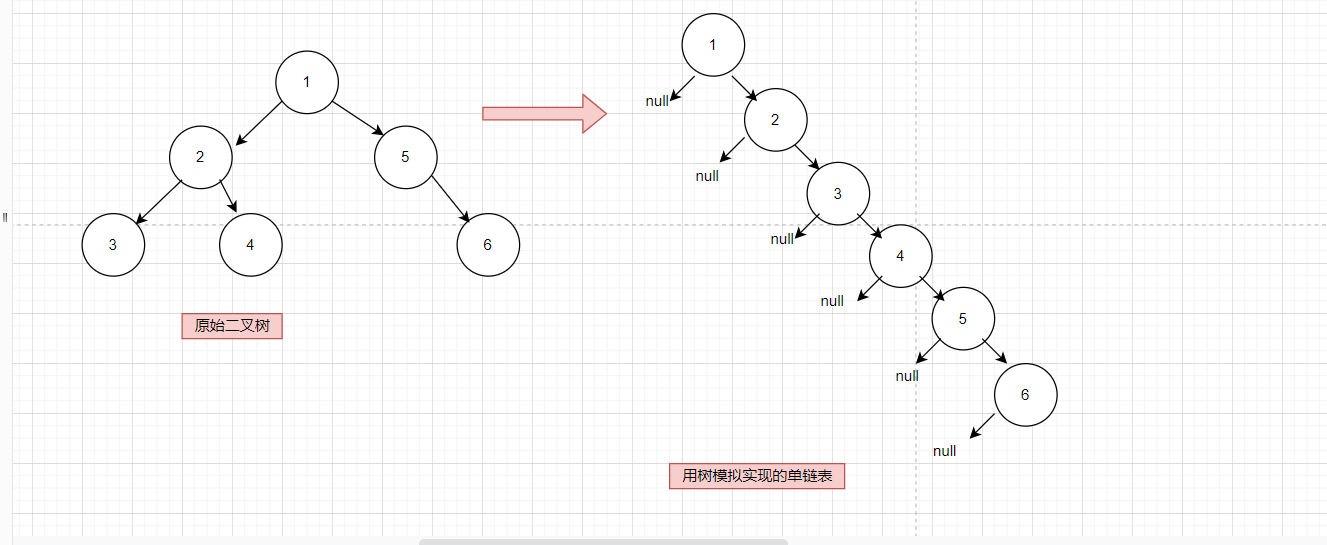
力扣114. 二叉树展开为链表(java,用树模拟链表)
Problem: 114. 二叉树展开为链表 文章目录 题目描述思路解题方法复杂度Code 题目描述 给你二叉树的根结点 root ,请你将它展开为一个单链表: 1.展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左…...
)
学生成绩管理系统(python实现)
学生成绩表信息包括学号、姓名、各科课程成绩(语文、数学、英语、政治)和总分。用带头结点的单链表管理学生成绩表,每个学生的信息依次从键盘输入,并根据需要进行插入、删除、排序、输出等操作。 import json# 初始化系统 studen…...

【Leetcode合集】1410. HTML 实体解析器
1410. HTML 实体解析器 1410. HTML 实体解析器 代码仓库地址: https://github.com/slience-me/Leetcode 个人博客 :https://slienceme.xyz 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 ""…...

04-React脚手架 集成Axios
初始化React脚手架 前期准备 1.脚手架: 用来帮助程序员快速创建一个基于xxx库的模板项目 1.包含了所有需要的配置(语法检查、jsx编译、devServer…)2.下载好了所有相关的依赖3.可以直接运行一个简单效果 2.react提供了一个用于创建react项目的脚手架库…...

时序预测 | MATLAB实现基于BiLSTM-AdaBoost双向长短期记忆网络结合AdaBoost时间序列预测
时序预测 | MATLAB实现基于BiLSTM-AdaBoost双向长短期记忆网络结合AdaBoost时间序列预测 目录 时序预测 | MATLAB实现基于BiLSTM-AdaBoost双向长短期记忆网络结合AdaBoost时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.Matlab实现BiLSTM-Adaboost…...

【nlp】3.6 Tansformer模型构建(编码器与解码器模块耦合)
Tansformer模型构建(编码器与解码器模块耦合) 1. 模型构建介绍2 编码器-解码器结构的代码实现3 Tansformer模型构建过程的代码实现4 小结1. 模型构建介绍 通过上面的小节, 我们已经完成了所有组成部分的实现, 接下来就来实现完整的编码器-解码器结构耦合. Transformer总体架…...
【【Linux系统下常用指令学习 之 二 】】
Linux系统下常用指令学习 之 二 文件查询和搜索 文件的查询和搜索也是最常用的操作,在嵌入式 Linux 开发中常常需要在 Linux 源码文件中查询某个文件是否存在,或者搜索哪些文件都调用了某个函数等等。 1、命令 find find 命令用于在目录结构中查找文件…...

Git-将指定文件回退到指定版本
场景1:修改了文件/path/to/file,没有提交,但是觉得改的不好,想还原。 解决: git checkout -- /path/to/file 场景2:修改了文件/path/to/file,已经提交,但是觉得改的不好,…...

docker环境安装
环境 主机环境 1. 宿主机环境 ubuntu-22.04.3-live-server-amd64 ,下载地址: https://mirrors.aliyun.com/ubuntu-releases/22.04.3/ubuntu-22.04.3-live-server-amd64.iso 2. apt 包管理器,镜像源修改 : 将 http://cn.archive.ubunt…...

【Java】智慧工地云平台源码(APP+SaaS模式)
在谈论“智慧工地”之前,我们首先得知道传统工地为什么跟不上时代了。 说起传统工地,总有一些很突出的问题:比如工友多且杂,他们是否入场、身体状况如何,管理人员只能依靠巡查、手工纪录来判断,耗时耗力&am…...

2016年11月10日 Go生态洞察:七年的Go语言旅程
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

深入了解Java中SQL优化的关键技巧与实践
引言 介绍SQL优化对于Java应用性能的重要性,并概述本文将要讨论的内容。 1. 编写高效的SQL语句 - **索引的类型与使用:** 解释B-Tree索引、哈希索引等类型的区别,以及如何根据查询需求合理创建和使用索引。 - **查询优化器:** 说明…...
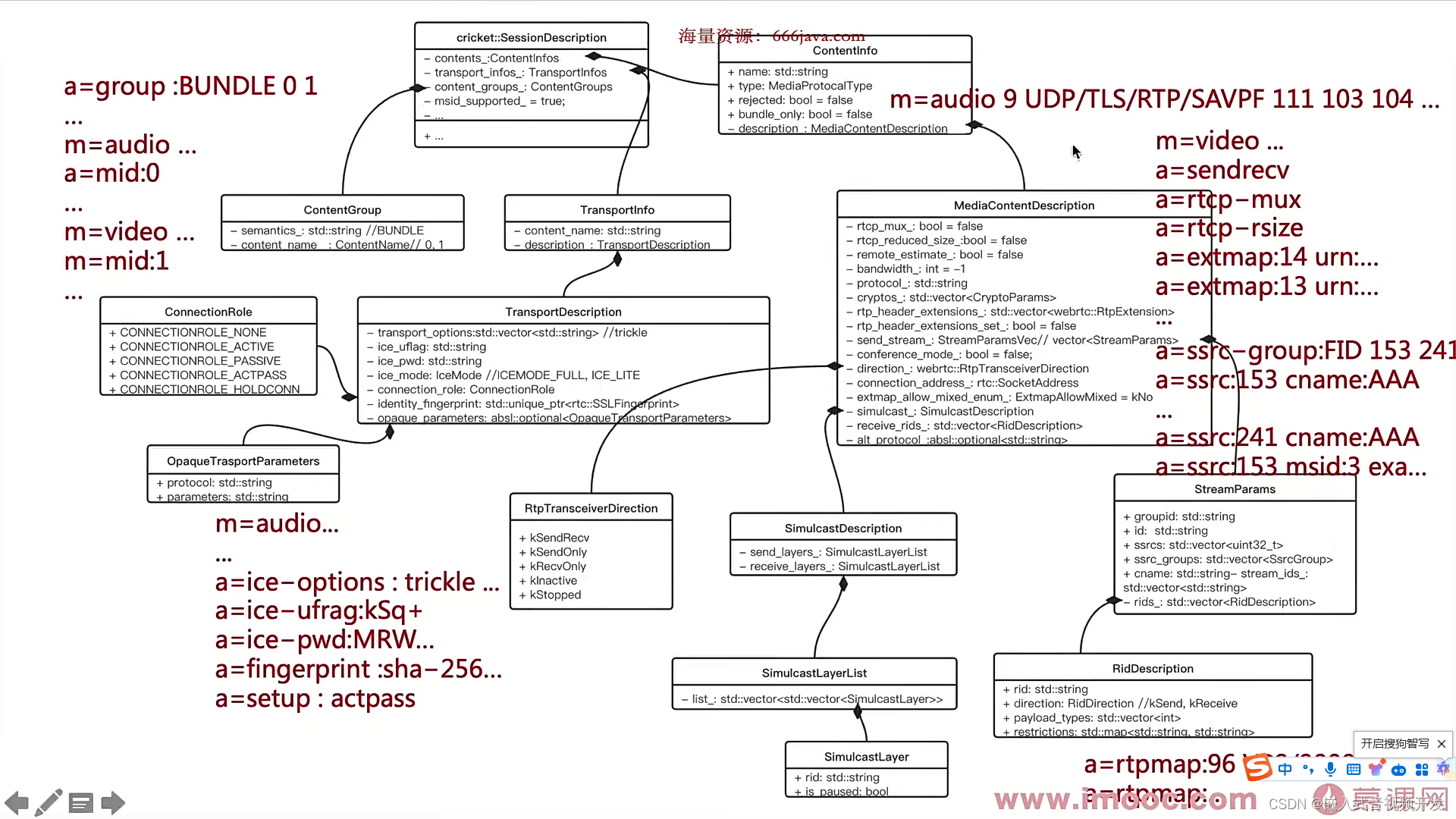
6.3.WebRTC中的SDP类的结构
在上节课中呢,我向你介绍了sdp协议, 那这节课呢,我们再来看看web rtc中。是如何存储sdp的?也就是sdp的类结构,那在此之前呢?我们先对sdp的内容啊,做一下分类。因为在上节课中呢,虽然…...
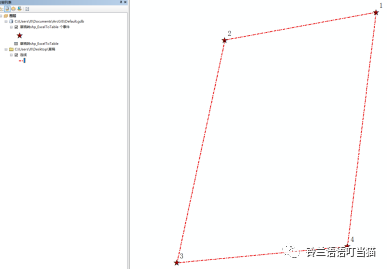
ArcGis如何用点连线?
这里指的是根据已有坐标点手动连线,类似于mapgis中的“用点连线”,线的每个拐点是可以自动捕捉到坐标点的,比直接画精确。 我也相信这么强大的软件一定可以实现类似于比我的软件上坐标时自动生成的线,但是目前我还没接触到那里&a…...

自定义精美商品分类列表组件 侧边栏商品分类组件 category组件(适配vue3)
随着技术的发展,开发的复杂度也越来越高,传统开发方式将一个系统做成了整块应用,经常出现的情况就是一个小小的改动或者一个小功能的增加可能会引起整体逻辑的修改,造成牵一发而动全身。通过组件化开发,可以有效实现单…...
)
造一个float类型二维矩阵,并将二维矩阵存快速储到一个float*中(memcpy)
// 创建并初始化一个二维数组 std::vector<std::vector<float>> createAndInitializeArray(int rows, int cols) {std::vector<std::vector<float>> array(rows, std::vector<float>(cols));float value 0.0f;for (int i 0; i < rows; i) {…...

python通过继承、组合、委托组织类
1 python通过继承、组合、委托组织类 #概念描述1继承属性查找X.name2多态方法调用X.method,取决于X的类型3封装方法和运算符实现行为 通常来说,独特的运算使用独特的方法名称,不要依赖于调用标记。 python组织类结构的方式包括:…...

告别轮询!用Java-WebSocket库在Android上5分钟搞定WebSocket实时通信
告别轮询!用Java-WebSocket库在Android上5分钟搞定WebSocket实时通信 在移动应用开发中,实时数据同步一直是个棘手的问题。想象一下这样的场景:用户A发送了一条消息,用户B需要等待几秒甚至更久才能收到;股票行情数据延…...

intv_ai_mk11开发者指南:supervisorctl status/restart/tail日志三命令速查表
intv_ai_mk11开发者指南:supervisorctl status/restart/tail日志三命令速查表 1. 引言 作为一名AI对话机器人的开发者或运维人员,掌握基本的服务管理命令是日常工作必备技能。intv_ai_mk11作为一款基于Llama架构的7B参数AI对话模型,在GPU服…...

codex app每次打开重连5次Reconnecting问题解决
原因: 默认是使用websocket协议,在websocket重连等待五次(并且每次的超时时间足足有20s)之后才会切换到可以正常通信的HTTP协议,至于websocket协议为什么不通,可能是代理不支持websocket协议. 方案1: 在.c…...

栈与队列的巧妙运用:Complete-DSA-Preparation中的经典算法模式
栈与队列的巧妙运用:Complete-DSA-Preparation中的经典算法模式 【免费下载链接】Complete-DSA-Preparation This is A complete DSA preparation Course. A DSA self-paced course for ultimate Interview and Placement Preparation 项目地址: https://gitcode.…...

Claude Design 来了:设计师的第二双手还是替代者?
2026年4月17日,Anthropic 正式发布 Claude Design。官方的定义是:一款通过与 Claude 对话来创建设计、原型、幻灯片、单页的工具。翻译成人话就是——你说话,它出图;你说「再瘦一点」「换个莫兰迪色系」「按钮往左挪」,…...

EspoCRM终极指南:如何通过开源CRM系统快速构建企业级客户关系管理平台
EspoCRM终极指南:如何通过开源CRM系统快速构建企业级客户关系管理平台 【免费下载链接】espocrm EspoCRM – Open Source CRM Application 项目地址: https://gitcode.com/GitHub_Trending/es/espocrm EspoCRM是一款功能强大且完全免费的开源客户关系管理系统…...

CSS如何引入CSS暗黑模式配置_通过媒体特性实现主题自动化
直接用 media (prefers-color-scheme: dark) 媒体查询响应系统主题,支持 Chrome 76 等现代浏览器;需配合 no-preference 回退规则,并与 JS 主题控制协同:媒体查询管首次加载默认态,JS 管后续手动切换,避免冲…...

OpenClaw近期生态安全事件解读:从RCE漏洞到Skill供应链投毒分析
引言 2025年底至2026年初,AI领域从对话式大模型向自主式智能代理(Agentic AI)发生了重大转变。在这一浪潮中,由开发者Peter Steinberger主导的开源项目OpenClaw(早期名为Clawdbot与Moltbot)成为最具颠覆性…...
的微电网分布式低碳优化运行策略matlab-yalmip-cplex/gurobi)
【代码】基于交替方向乘子法(admm)的微电网分布式低碳优化运行策略matlab-yalmip-cplex/gurobi
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

台积电法说会:AI需求强劲异常,供不应求态势将延续至至少2027年
2026年Q1绩后,台积电召开法说会。台积电首席执行官魏哲家宣称“AI需求极为强劲”,并指出全球正置身于“AI大趋势”之中。财报显示,台积电今年第一季度营收(以美元计)环比增长6.4%,达359亿美元,略…...