PaddleOCR学习笔记
Paddle
功能特性
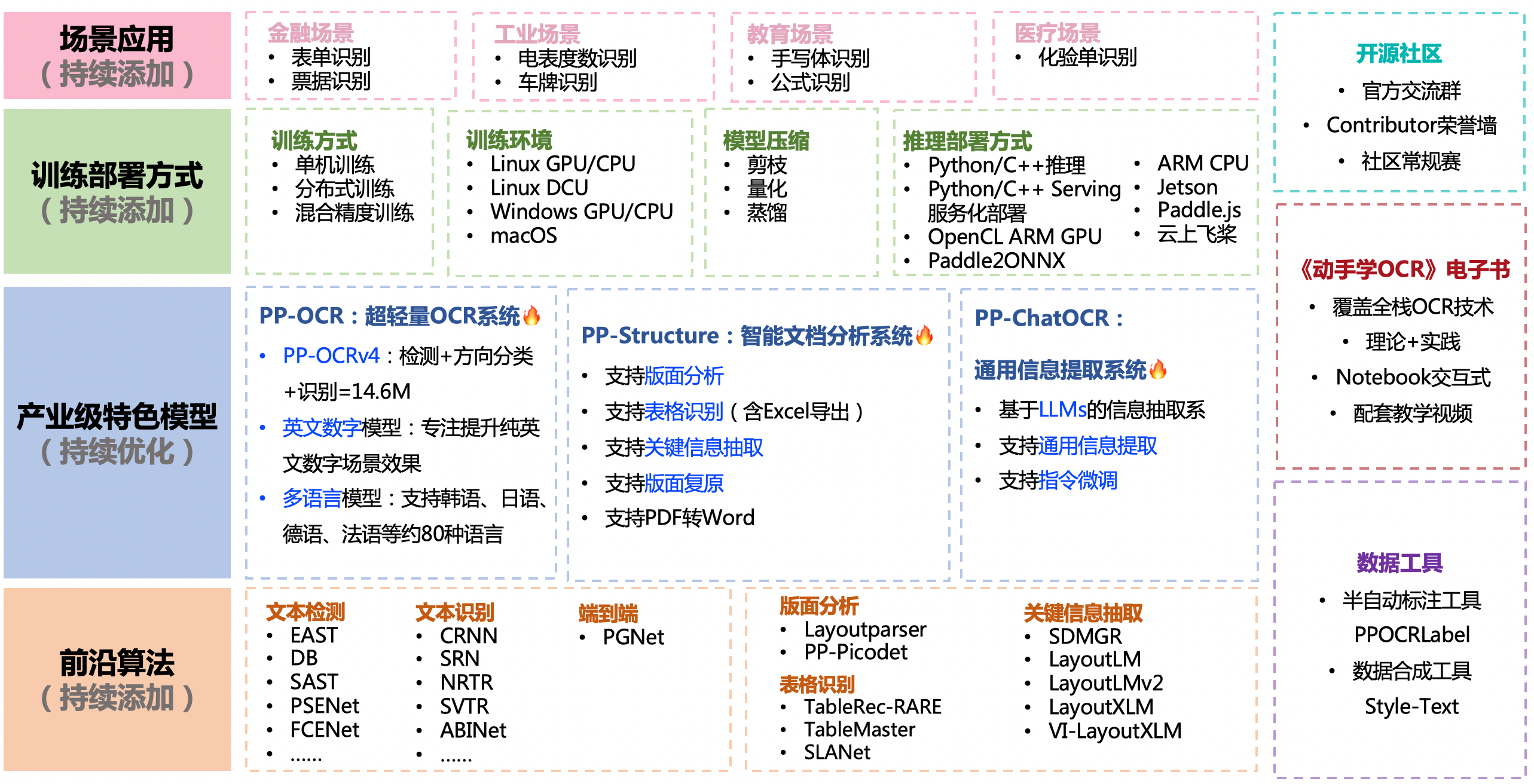
PP-OCR系列模型列表
https://github.com/PaddlePaddle/PaddleOCR#%EF%B8%8F-pp-ocr%E7%B3%BB%E5%88%97%E6%A8%A1%E5%9E%8B%E5%88%97%E8%A1%A8%E6%9B%B4%E6%96%B0%E4%B8%AD
PP-OCR系列模型列表(V4,2023年8月1日更新)
配置文件内容与生成
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/config.md
文字检测
关键要点: 配置文件、预训练模型、数据加载
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/detection.md
实际使用过程中,建议加载官方提供的预训练模型,在自己的数据集中进行微调,关于检测模型的微调方法,请参考:模型微调教程
也可以选择加载backbone预训练模型再训练,不过收敛速度会很慢
微调指令(推荐):
python3 tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \-o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_det_distill_train/ch_PP-OCRv3_det_distill_train/student.pdparams
有两种预测方式:
1.直接加载checkpoints模型做预测
python3 tools/infer_det.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/ch_PP-OCR_V3_det/latest"
2.先导出模型再加载inference模型做预测
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True
文本识别
微调指令(推荐):
python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \-o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams
有两种预测方式:
1.直接加载checkpoints模型做预测
python3 tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.infer_img="./train_data/ic15_rec/train/word_34.png" Global.pretrained_model="./output/rec_ppocr_v3_distillation/latest"
2.先导出模型再加载inference模型做预测
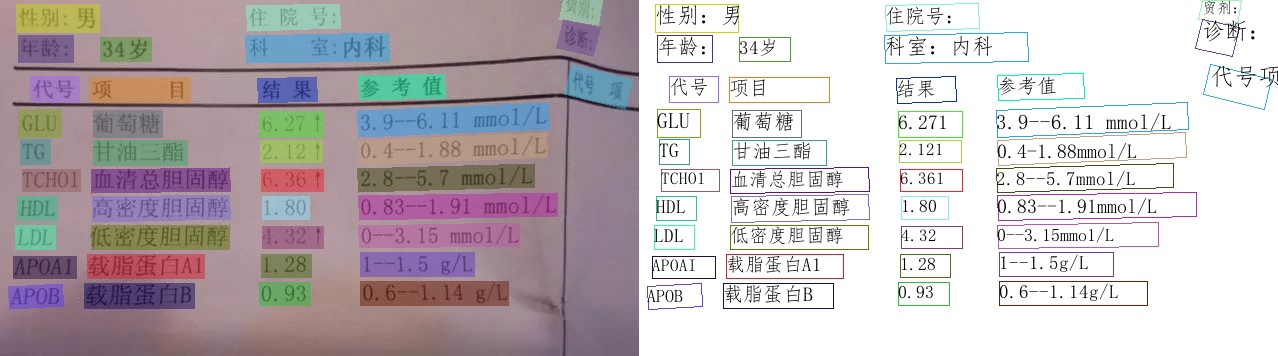
关键信息抽取
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/ppstructure/kie/README_ch.md
简介
文本检测、识别、端到端识别、结构化分析四种方向
中英文超轻量PP-OCRv3模型:
- 总模型大小仅17M,仅1个检测模型(3.8M)+方向分类器(1.4M)+1个识别模型(12M)组成
- 同时支持中英文识别
- 支持倾斜、竖排等多种方向文字识别
- 支持GPU(T4 卡平均预测耗时87ms)、CPU预测
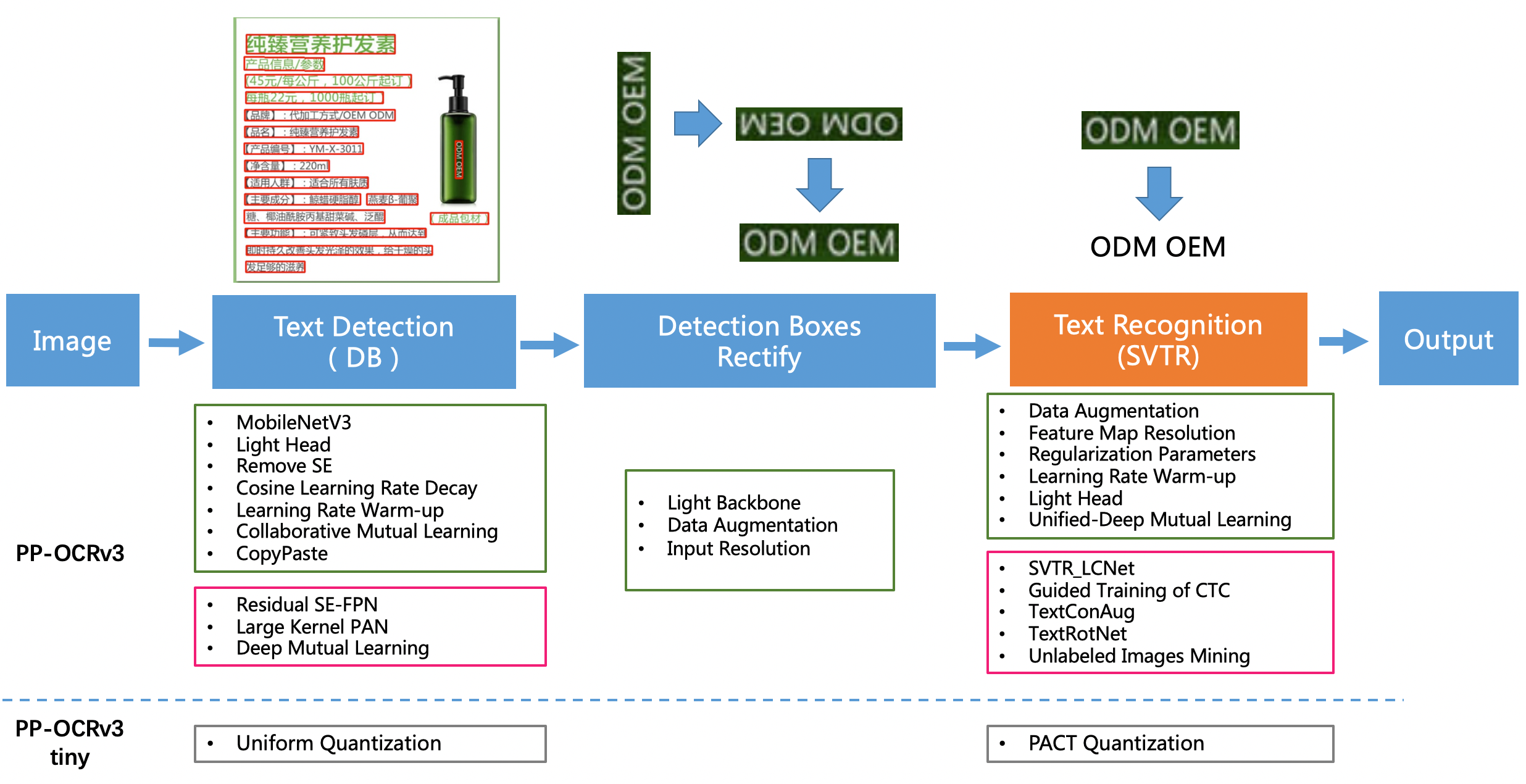
PaddleOCR发布的PP-OCRv3超轻量模型由1个文本检测模型(3.8M)、1个方向分类器(1.4M)和1个文本识别模型(12.0M)组成,共17M。其中,文本检测模型是基于2020年发表于AAAI上的DB[1]算法进行改进得到的,文本识别模型基于2022年发表于IJCAI上的SVTR[4]算法进行改进得到的
PaddleOCR
1、检测
PaddleOCR提供了EAST、DB、SAST、PSE和FCE五种文本检测算法
2、方向分类
3、识别
PaddleOCR提供了CRNN、Rosseta、StarNet、RARE、SRN、NRTR、SAR、SEED八种文本识别算法
中文OCR数据集
ICDAR2019-LSVT:共45w中文街景图像,包含5w(2w测试+3w训练)全标注数据(文本坐标+文本内容),40w弱标注数据(仅文本内容)。
ICDAR2017-RCTW-17:共包含12,000+图像,大部分图片是通过手机摄像头在野外采集的,有些是截图。这些图片展示了各种各样的场景,包括街景、海报、菜单、室内场景和手机应用程序的截图。
中文街景文字识别:ICDAR2019-LSVT行识别任务的数据集,共包括29万张图片,其中21万张图片作为训练集(带标注),8万张作为测试集(无标注)。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片。
中文文档文字识别:共约364万张图片,按照99:1划分成训练集和验证集。数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成。包含汉字、英文字母、数字和标点共5990个字符。
ICDAR2019-ArT:共包含10,166张图像,训练集5603图,测试集4563图。由Total-Text、SCUT-CTW1500、Baidu Curved Scene Text (ICDAR2019-LSVT部分弯曲数据) 三部分组成,包含水平、多方向和弯曲等多种形状的文本。
拉取镜像
docker pull registry.baidubce.com/paddlepaddle/paddle:2.5.2-gpu-cuda11.2-cudnn8.2-trt8.0
启动容器
docker run --gpus all --shm-size=4g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --name paddle -it -v $PWD:/paddle registry.baidubce.com/paddlepaddle/paddle:2.5.2-gpu-cuda11.2-cudnn8.2-trt8.0-v1 /bin/bash
教程
https://www.paddlepaddle.org.cn/tutorials/projectdetail/3977289
准备运行环境
conda create --name paddle python=3.8
conda activate paddle
python -m pip install paddlepaddle==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
git clone https://github.com/PaddlePaddle/PaddleOCR
cd PaddleOCR
pip install -r requirements.txt
pip install jupyter notebook
pip install Pillow==9.5.0
下载模型
download_model.sh
#!/bin/bash# 创建inference目录
mkdir inference# 进入inference目录
cd inference# 下载中英文检测模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
tar xf ch_PP-OCRv3_det_infer.tar# 下载中英文方向分类器模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
tar xf ch_ppocr_mobile_v2.0_cls_infer.tar# 下载中英文识别模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
tar xf ch_PP-OCRv3_rec_infer.tar
推理指令
检测+识别
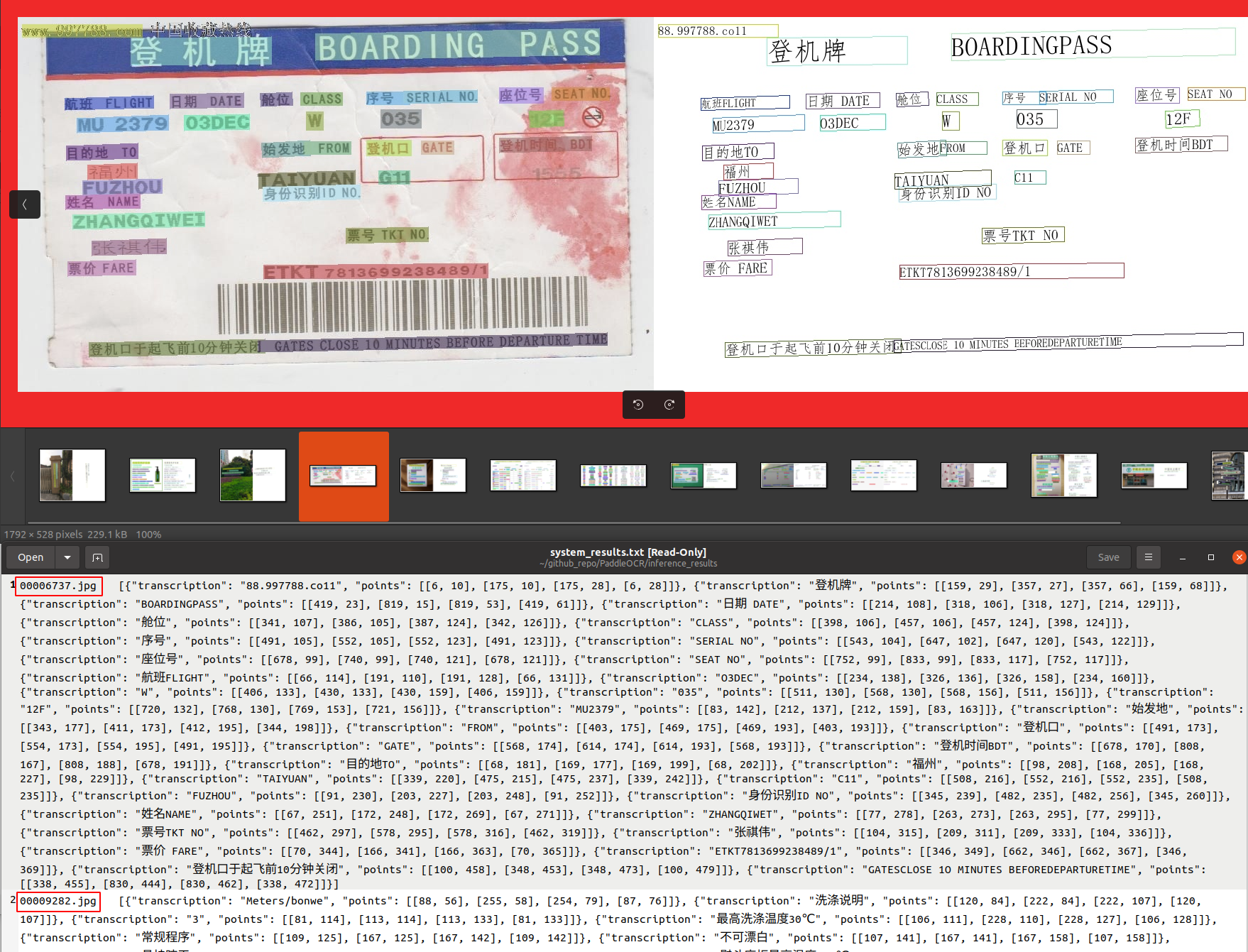
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_PP-OCRv3_det_infer/" --rec_model_dir="./inference/ch_PP-OCRv3_rec_infer/" --rec_image_shape="3,48,320"
说明:
image_dir支持传入单张图像和图像所在的文件目录,当image_dir指定的是图像目录时,运行上述指令会预测当前文件夹下的所有图像中的文字,并将预测的可视化结果保存在inference_results文件夹下
预测结果示例如下:
训练自定义模型
生产自定义的模型可分为三步:训练文本检测模型、训练文本识别模型、模型串联预测
训练文字检测模型
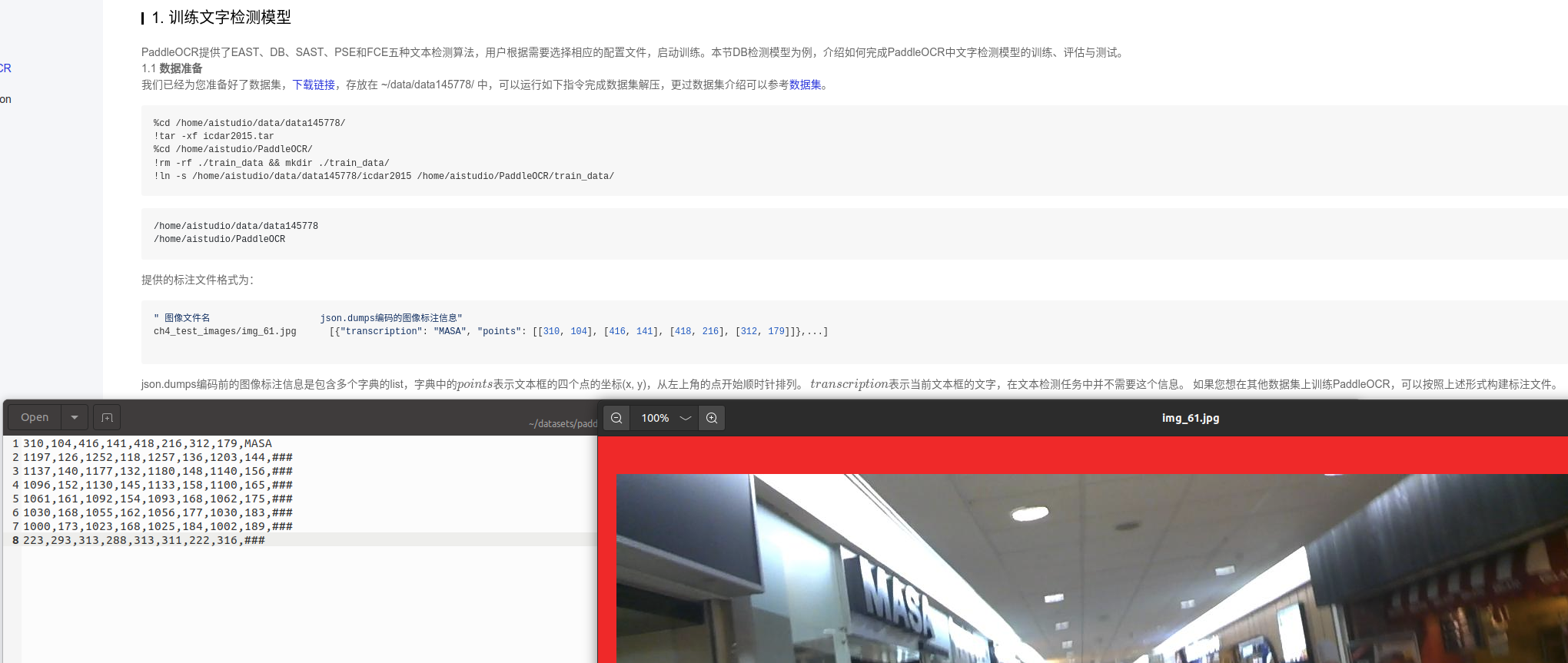
下载预训练的backbone模型
mkdir pretrain_models
wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams
wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/ResNet50_vd_ssld_pretrained.pdparams
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.epoch_num=1 Global.eval_batch_step=[0,50]
测试文字检测模型
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.checkpoints="./output/db_mv3/best_accuracy"
训练文字识别模型

下载预训练的backbone模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_mv3_none_bilstm_ctc.tar
cd pretrain_models && tar -xf rec_mv3_none_bilstm_ctc.tar && rm -rf rec_mv3_none_bilstm_ctc.tar && cd ..
python3 tools/train.py -c configs/rec/rec_icdar15_train.yml -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc/best_accuracy Global.eval_batch_step=[0,200]
测试文字识别模型
python3 tools/infer_rec.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./output/rec/ic15/best_accuracy Global.infer_img=./doc/imgs_words/en/word_1.png
测试
PP-ChatOCRv2在线识别效果测试: https://aistudio.baidu.com/application/detail/10368
PP-OCRv4在线识别效果测试: https://aistudio.baidu.com/application/detail/7658
思考问题
不确定预训练的backbone是否导入成功,感觉收敛速度很慢
回答: 是导入成功了的,想要收敛快,最好是进行微调训练
还没有在自己制作的数据集上训练过
思考关键词、LLM进行结构化分析的可能性
回答: LLM确实很不错,但是我看了下关键信息抽取也是一个不错的选择,数据构建可以借助LLM来制作
用的是v3还没接触v4
回答: 两者的使用方式差别不大,主要还是配置文件的切换
开源的ocr识别项目: https://github.com/tesseract-ocr/tesseract
回答: 可以再多了解下除Paddle之外的一些OCR开源项目
可以拿飞机票来测试LLM结构化分析的效果
回答: 脑洞开大点儿,让LLM模型去学习实体关联,我只需要准备相应形式的数据就可以,从数据中自动学习模式
训练配置yaml文件
推理py代码
PP-ChatOCRv2
一个SDK,覆盖20+高频应用场景,支持5种文本图像智能分析能力和部署,包括通用场景关键信息抽取(快递单、营业执照和机动车行驶证等)、复杂文档场景关键信息抽取(解决生僻字、特殊标点、多页pdf、表格等难点问题)、通用OCR、文档场景专用OCR、通用表格识别。针对垂类业务场景,也支持模型训练、微调和Prompt优化
PP-OCRv4
提供mobile和server两种模型
PP-OCRv4-mobile:速度可比情况下,中文场景效果相比于PP-OCRv3再提升4.5%,英文场景提升10%,80语种多语言模型平均识别准确率提升8%以上
PP-OCRv4-server:发布了目前精度最高的OCR模型,中英文场景上检测模型精度提升4.9%, 识别模型精度提升2% 可参考快速开始 一行命令快速使用,同时也可在飞桨AI套件(PaddleX)中的通用OCR产业方案中低代码完成模型训练、推理、高性能部署全流程
相关文章:
PaddleOCR学习笔记
Paddle 功能特性 PP-OCR系列模型列表 https://github.com/PaddlePaddle/PaddleOCR#%EF%B8%8F-pp-ocr%E7%B3%BB%E5%88%97%E6%A8%A1%E5%9E%8B%E5%88%97%E8%A1%A8%E6%9B%B4%E6%96%B0%E4%B8%AD PP-OCR系列模型列表(V4,2023年8月1日更新) 配置文…...
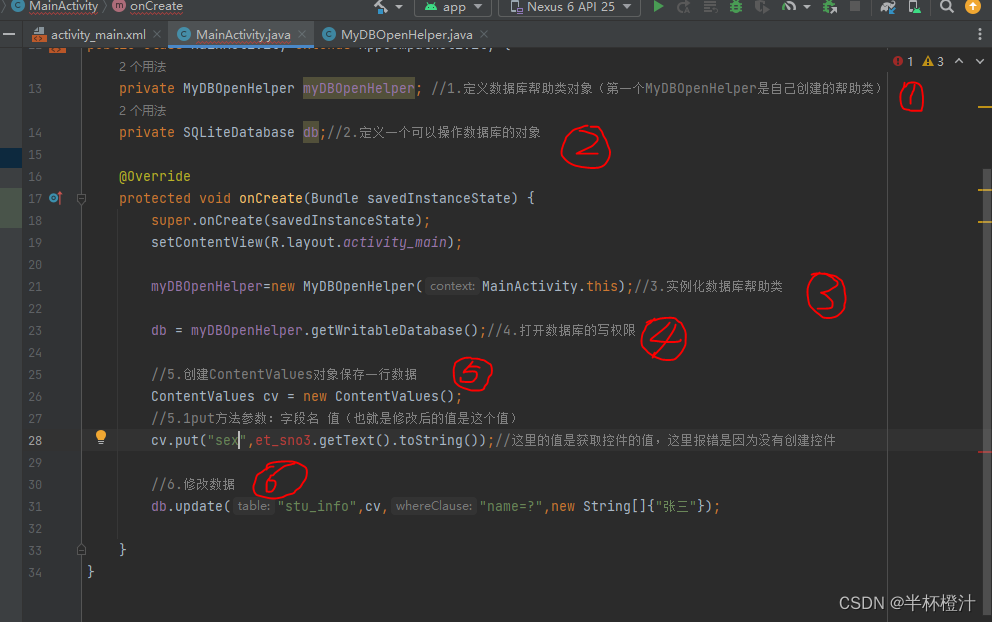
安卓用SQLite数据库存储数据
什么是SQLite? SQLite是安卓中的轻量级内置数据库,不需要设置用户名和密码就可以使用。资源占用较少,运算速度也比较快。 SQLite支持:null(空)、integer(整形)、real(小…...
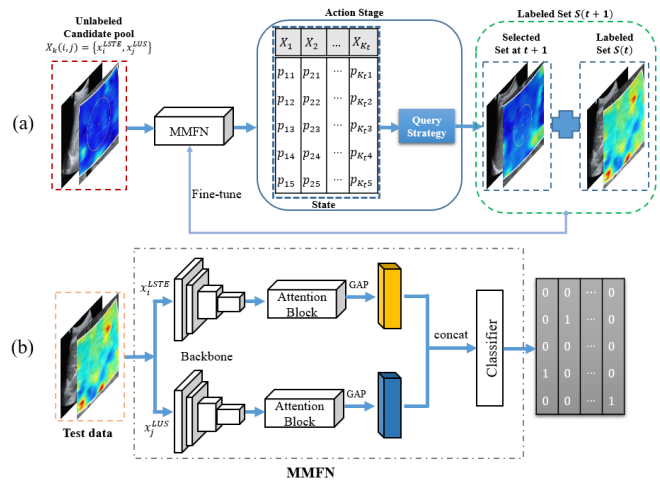
MMFN-AL
MMFN means ‘multi-modal fusion network’ 辅助信息 作者未提供代码...

7、独立按键控制LED状态
按键的抖动 对于机械开关,当机械触点断开、闭合时,由于机械触点的弹性作用,一个开关在闭合时不回马上稳定地接通,在断开时也不会一下子断开,所以在开关闭合及断开的瞬间会伴随一连串的抖动 #include <REGX52.H…...

香蕉派BPI-M4 Zero单板计算机采用全志H618,板载2GRAM内存
Banana Pi BPI-M4 Zero 香蕉派 BPI-M4 Zero是BPI-M2 Zero的最新升级版本。它在性能上有很大的提高。主控芯片升级为全志科技H618 四核A53, CPU主频提升25%。内存升级为2G LPDDR4,板载8G eMMC存储。它支持5G WiFi 和蓝牙, USB接口也升级为type-C。 它具有与树莓派 …...

微信小程序内部跳到外部小程序
要在微信小程序中跳转到外部小程序,可以使用wx.navigateToMiniProgram函数。以下是一个示例: wx.navigateToMiniProgram({appId: 外部小程序的appId,path: 外部小程序的路径,extraData: {id: xxx},success(res) {// 跳转成功} })在这个示例中࿰…...

Spring Boot中设置文件上传大小限制
在Spring Boot中,可以通过以下步骤来设置上传文件的大小: 在application.properties或application.yml文件中,添加以下配置: 对于application.properties: spring.servlet.multipart.max-file-size128MB spring.se…...

8、独立按键控制LED显示二进制
独立按键控制LED显示二进制 #include <REGX52.H>void Delay(unsigned int xms) //12.000MHz {unsigned char i, j;while(xms--){i 2;j 239;do{while (--j);} while (--i);} }void main() {//数据类型刚好是8位与51单片机IO口寄存器位数相同(默认高电平&am…...
命名空间、字符串、布尔类型、nullptr、类型推导
面向过程语言:C ——> 重视求解过程 面向对象语言:C ——> 重视求解的方法 面向对象的三大特征:封装、继承和多态 C 和 C 在语法上的区别 1、命名空间(用于解决命名冲突问题) 2、函数重载和运算符重载…...

力控软件与多台PLC之间ModbusTCP/IP无线通信
Modbus TCP/IP 是对成熟的 Modbus 协议的改编, 因其开放性、简单性和广泛接受性而在工业自动化系统中发挥着举足轻重的作用。它作为连接各种工业设备的通用通信协议,包括可编程逻辑控制器 (PLC)、远程终端单元 (RTU) 和传感器。它提供标准化的 TCP 接口&…...

第96步 深度学习图像目标检测:FCOS建模
基于WIN10的64位系统演示 一、写在前面 本期开始,我们继续学习深度学习图像目标检测系列,FCOS(Fully Convolutional One-Stage Object Detection)模型。 二、FCOS简介 FCOS(Fully Convolutional One-Stage Object D…...

常用的git命令完整详细109条
Git是一个很强大的分布式版本控制系统,以下是一些常用的git命令: git init:在当前目录下创建一个新的Git仓库。git add 文件名:将指定的文件添加到暂存区,准备提交。git commit -m “备注”:提交暂存区的文…...

Ansible的错误处理
环境 管理节点:Ubuntu 22.04控制节点:CentOS 8Ansible:2.15.6 ignore_errors 使用 ignore_errors: true 来让Ansible忽略错误(运行结果是 failed ): --- - hosts: alltasks:- name: task1shell: cat /t…...
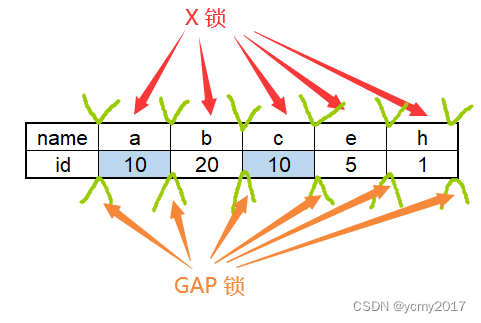
MySQL-04-InnoDB存储引擎锁和加锁分析
Latch一般称为闩锁(轻量级锁),因为其要求锁定的时间必须非常短。在InnoDB存储引擎中,latch又分为mutex(互斥量)和rwlock(读写锁)。 Lock的对象是事务,用来锁定的是…...

tcp/ip协议2实现的插图,数据结构2 (19 - 章)
(68) 68 十九1 选路请求与消息 函rtalloc,rtalloc1,rtfree (69) 69 十九2 选路请求与消息 函rtrequest (70)...
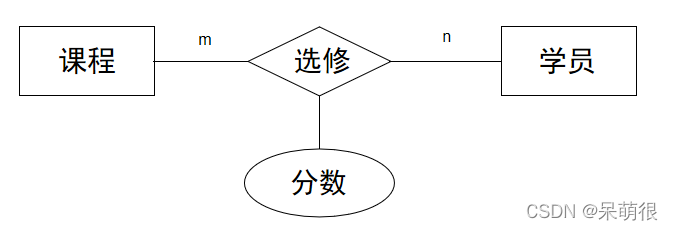
2023.11.22 -数据仓库的概念和发展
目录 https://blog.csdn.net/m0_49956154/article/details/134320307?spm1001.2014.3001.5501 1经典传统数仓架构 2离线大数据数仓架构 3数据仓库三层 数据运营层,源数据层(ODS)(Operational Data Store) 数据仓库层&#…...
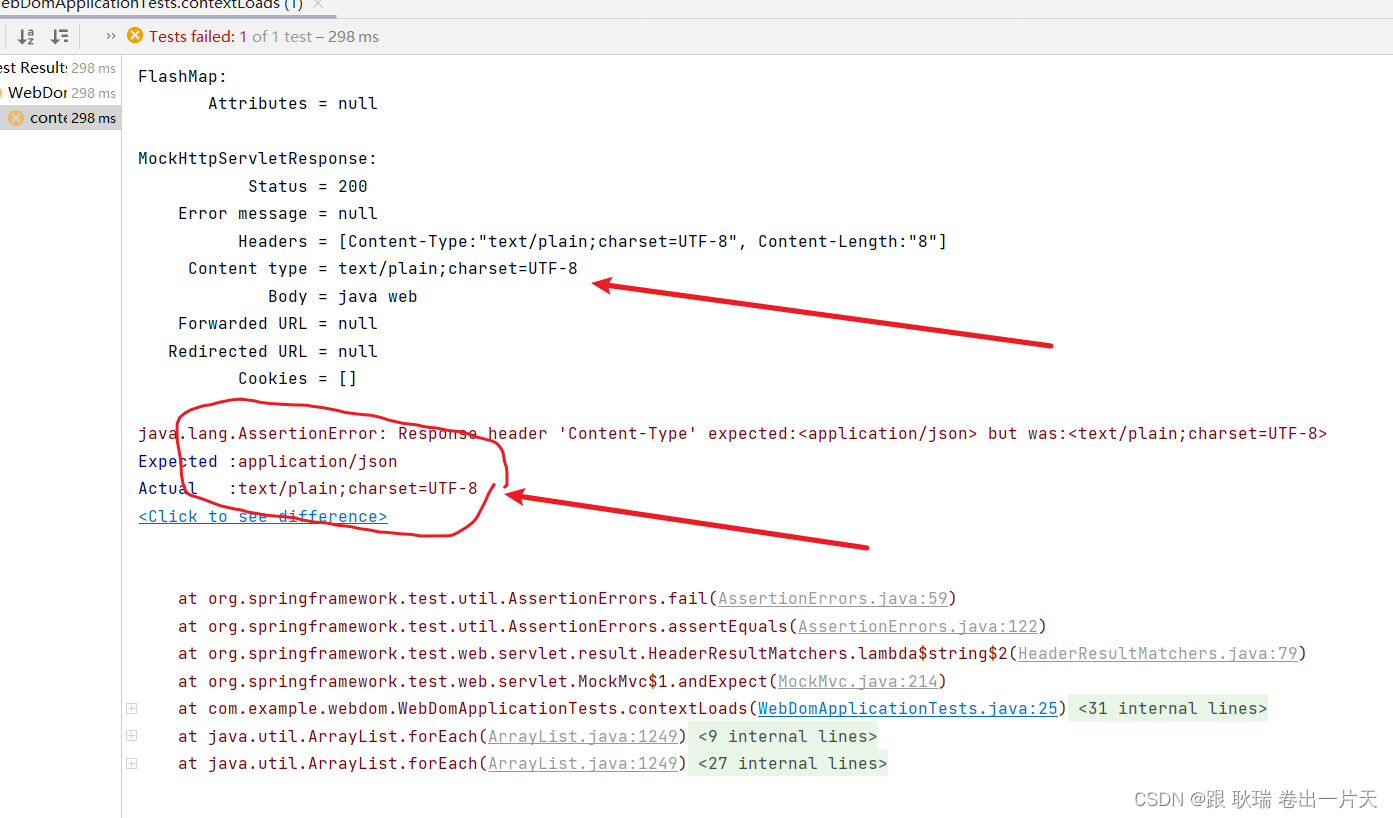
java springboot测试类虚拟MVC环境 匹配请求头指定key与预期值是否相同
上文 java springboot测试类虚拟MVC环境 匹配返回值与预期内容是否相同 (JSON数据格式) 版 中 我们展示 json匹配内容的方式 那么 本文我们来看看Content-Type属性的匹配方式 首先 我们从返回体可以看出 Content-Type 在请求头信息 Headers 中 我们直接将测试类代码更改如下 …...

Rust生态系统:探索常用的库和框架
大家好!我是lincyang。 今天我们来探索Rust的生态系统,特别是其中的一些常用库和框架。 Rust生态系统虽然相比于一些更成熟的语言还在成长阶段,但已经有很多强大的工具和库支持各种应用的开发。 常用的Rust库和框架 Serde:一个…...

01-了解微服务架构的演变过程和微服务技术栈
微服务 微服务架构演变 单体架构:将业务的所有功能集中在一个项目中开发最后打成一个包部署 优点: 架构简单, 部署成本低,适合小型项目缺点: 耦合度高, 升级维护困难 分布式架构:根据业务功能对系统做拆分,每个业务功能模块作为独立项目开发称为一个服务 优点: 降低服务耦合…...

阿里入局鸿蒙!鸿蒙原生应用再添两员新丁
今日HarmonyOS微博称,阿里钉钉、蚂蚁集团旗下的移动开发平台mPaaS与华为达成合作,宣布启动鸿蒙原生应用的开发!相关应用将以原生方式适配#HarmonyOS NEXT#系统。 #HarmonyOS#市场或迎来爆发式增长! 阿里钉钉 阿里钉钉与华为达成合…...

Qwen3-14B企业级API网关设计:实现高可用、可扩展的AI服务
Qwen3-14B企业级API网关设计:实现高可用、可扩展的AI服务 1. 企业级AI服务的挑战与机遇 在数字化转型浪潮中,大型语言模型如Qwen3-14B正成为企业智能化转型的核心引擎。然而,直接将模型暴露给业务系统会面临诸多挑战:突发流量可…...

PHP8.3新特性对AI开发影响_最新功能应用【解答】
PHP 8.3 不直接支持 AI 开发,但通过 json_validate() 预检 JSON、命名参数与联合类型提升 API 封装健壮性、readonly 类深拷贝保障会话安全、non-static callable 与管道操作符优化流水线编排,显著增强 AI 应用后端稳定性与可维护性。PHP 8.3 对 AI 开发…...

腾兴热点 | 马斯克打造超级计算机集群 小鹏从车企到AI集团 游宝阁用户突破5千万 Sora负责人离职
2026 全球 AI 与科技产业深度观察:算力军备竞赛、企业战略重构与行业格局重塑2026 年,全球科技产业正迎来新一轮变革浪潮,AI 算力竞赛持续白热化,传统车企加速向科技生态转型,AI 赛道战略收缩与技术落地并行推进&#…...

安立Anritsu MS9740B台式光谱分析仪概述
安立Anritsu MS9740B台式光谱分析仪概述安立MS9740B是一款高性能台式光谱分析仪,广泛应用于光通信、激光器测试、光纤传感等领域。其设计兼顾高精度与操作便捷性,支持波长范围覆盖600至1750 nm,分辨率带宽可达0.05 nm。主要技术参数波长范围&…...

启动瓶颈定位实战:Perfetto + Macrobenchmark 一套组合拳
上一篇我们画了一张完整的冷启动全景图,从 Launcher 点击到 Fully Drawn 的七个阶段都拆开看了一遍。理解全景图是前提,但只有全景图是不够的——你知道时间花在了"某个阶段",但具体是哪行代码、哪个初始化拖慢了整个链路ÿ…...

从设计系统角度看Element UI按钮:如何用el-button构建统一且高效的Vue界面
从设计系统视角重构Element UI按钮:打造高可维护的Vue组件规范 在2023年Ant Design发布的开发者调研报告中,超过62%的中大型项目团队反馈"UI组件滥用导致的维护成本"是前端技术债的主要来源。当我们审视一个日均PV过百万的Vue项目时࿰…...

CockroachDB/errors网络传输原理:Protobuf编码与解码机制详解
CockroachDB/errors网络传输原理:Protobuf编码与解码机制详解 【免费下载链接】errors Go error library with error portability over the network 项目地址: https://gitcode.com/gh_mirrors/err/errors 在分布式系统开发中,错误信息的可靠传输…...

Windows 安装云崽
安装LLBot 下载安装包 前往 GitHub Release 页面 下载最新版本的 LLBot-Desktop-win-x64.zip 解压文件 将下载的 zip 文件解压到任意目录,建议选择一个固定的位置(如 D:\LLBot) 启动程序 双击 llbot.exe 文件,然后在界面上点…...

STM32标准库开发步骤速览,适用于电赛入门学习
内容不全是还在完善,本文根据b站up主:江协科技总结得来(视频太长我没有全部看完,仅只阅读了相关例程的代码,只挑了部分视频观看,难免可能不全),既然是总结得来当然越精炼越好&#x…...

UEFI Setup界面开发避坑指南:grayoutif、suppressif条件控制与varstore变量存储的实战解析
UEFI Setup界面开发避坑指南:条件控制与变量存储的实战解析 在UEFI固件开发中,Setup界面作为用户与系统交互的重要桥梁,其开发质量直接影响用户体验和系统稳定性。本文将深入探讨如何避免UEFI Setup界面开发中的常见陷阱,特别是条…...