Django ORM查询之聚合函数、聚合查询(aggregate)、分组查询(annotate)
django 版本 3.2
python 3.6.8
一、聚合函数
常见的五个聚合函数:
- Avg (Average) : 平均值
- Max (Maximum) : 最大值
- Min (Minimum) : 最小值
- Sum (Summary) : 求和
- Count : 个数
导入语句:
from django.db.models import Avg, Max, Min, Sum, Count, Q, F
# Q查询和F查询也可以一起导入,一般会经常频繁使用
以上五个聚合函数都可以在 aggregate 和 annotate 中使用。
二、聚合查询 aggregate()
2.1 aggregate() 终止子句
aggregate()是QuerySet 的一个终止子句,也就是说在写QuerySet 查询语句时aggregate()后面不能再有其他查询语句,因为aggregate()会返回一个键值对的字典,不再是QuerySet 对象。
2.2 使用方法,可自定义变量key
使用方法如下:
from django.db.models import Avg, Max, Min, Sum, Count, Q, Fqueryset = MyModel.objects.aggregate(Avg('price'))
print(queryset)
# 打印结果: {'price__avg': Decimal('34.204000')} 系统会字典生产一个由“变量名_方法名”组成的字典key,这样并不方便,我们可以自定义key,如下:
queryset = MyModel.objects.aggregate(my_key=Avg('price'))
print(queryset)
# 打印结果: {'my_key': Decimal('34.204000')}
2.3 多个聚合函数一起查询
使用方法如下:
from django.db.models import Avg, Max, Min, Sum, Count, Q, Fqueryset = MyModel.objects.aggregate(Avg('price'),Max('price'),Min('price'),Sum('price')) 三、分组查询 annotate
上面的聚合查询其实经常需要先分组再查询,那么就会用到 annotate
3.1 annotate()不是终止子句但等于终止子句
annotate查询的结果不是键值对的字典,但是一个queryset列表对象,而列表中的元素是字典格式,可以向列表和字典一样取值,因此annotate的后面可以加其他查询语句,例如annotate(Avg(‘price’)) .values("***),但是这么写结果是annotate查询失效,比如:
queryset = models.MyModel.objects.annotate(Avg('price')) .values("***)
虽然这么写不会报错,但是这么写之后前面的annotate会失去作用!!! 所以网上很多帖子说values() 放前面是什么作用,放后面是什么作用,其实不然,放后面就失去了使用 annotate的意义了。而annotate的前面必须使用 .values().order_by() 先制定按哪个字段分组。
总结,annotate虽然返回的queryset对象,但是后面增加其他查询语句会导致annotate查询失效,因此说annotate()不是终止子句但是等于终止句子。(如果说法有误,欢迎试验后回复订正)
3.2 使用方法,queryset.values(‘**’).order_by() .annotate()
先声明一下django版本3.2; python版本3.6.9 下使用annotate必须按上面的固定写法,少一个都不行,可能不会报错,但是查询不到想要的结果。(可能之前的版本不需要如此,仅供思路参考)
使用方法如下:
from django.db.models import Avg, Max, Min, Sum, Count, Q, F# 写法一
queryset = MyModel.objects.values('price').order_by().annotate(Count('price'))
# 写法二
queryset = MyModel.objects.values('price').order_by('price').annotate(Count('price'))
从方法一和方法二看出,order_by() 中写不写参数都可以,推荐方法一省略order_by()中的参数即可,原因请继续往下看:3.3
3.3 多字段分组 queryset.values(‘price’,‘name’).order_by() .annotate()
写法参考上面两种(但是推荐第一种)
from django.db.models import Avg, Max, Min, Sum, Count, Q, F# 写法一
queryset = MyModel.objects.values('price','name').order_by().annotate(Count('price'))
# 写法二
queryset = MyModel.objects.values('price','name').order_by('price').annotate(Count('price'))
上面两种写法,本人开始也认为是按order_by()种的参数排序分组,其实不然。经过本人实验,order_by()中不管写什么都会去拿values()中的所有字段去分组,所以说values()的作用就是指定分组的字段,order_by() 不需要写任何参数,因为写了也不起作用。
3.4 查询结果字典
查询结果的键值对会包含values()中的参数和annotate()中聚合函数查询结果的key,例如:
from django.db.models import Avg, Max, Min, Sum, Count, Q, F# annotate 中不指定自定义key
queryset = MyModel.objects.values('price','name').order_by().annotate(Count('price'))
print(queryset )
# 打印结果:<QuerySet [{'price': '23', 'name': '张山', 'price_count': '23',}]># annotate 中指定自定义key
queryset = MyModel.objects.values('price','name').order_by().annotate(my_count = Count('price'))
print(queryset )
# 打印结果:<QuerySet [{'price': '23', 'name': '张山', 'my_count ': '23',}]>
3.5 关于annotate中多次使用聚合函数Count时的参数distinct=True
之前由帖子提到,一条查询语句annotate中多次Count查询要使用distinct=True 其实已经没有用了,因为前面已经使用了values().order_by()进行了精确分组,所以在django版本3.2; python版本3.6.9 之中甚至之后都没有用了,本人也亲自试验了一下,得到的queryset对象不是字典对象也拿不到想要查询的数据。
3.6 分组后去重查询
经常用到先分组再去重最后统计数量,之前去重都是用values().distinct() ,那么常规思路写法往往是:
# 先以authors去重后,再按 price和name分组,最后统计数量
queryset = MyModel.objects.values("authors").distinct().values('price','name' ).order_by().annotate(Count('price'))
经过实验,最后发现没有效果,但是单独测试去重:
MyModel.objects.values("user").distinct()models.MyModel.objects.values("authors").distinct()
这样是有效果的,结果后面把分组加上就没有效果了。其实annotate有自己的去重参数,解决方案:
queryset = MyModel.objects.values('price','name' ).order_by().annotate(Count('authors', distinct=True))
直接在 annotate 的聚合函数内,加参数distinct=True 即可按聚合函数参数字段进行去重
四、annotate 与 aggregate的区别
1、终止子句
aggregate 是终止子句,后面加任何查询语句都会报错。
annotate 不是终止子句,后面加任何查询虽然不会报错,但会导致annotate 查询失效。
2、
简单的说 annotate 是先分组再聚合查询,aggregate 是仅仅聚合查询,即便在 aggregate 前面加上 annotate 前面相同的分组条件 values(‘**’).order_by() 也不会分组。
from django.db.models import Avg, Max, Min, Sum, Count, Q, F# annotate 分组查询
queryset = MyModel.objects.values('price','name').order_by().annotate (my_count = Count('price'))
print(queryset )
# 打印结果:<QuerySet [{'price': '23', 'name': '张山', 'my_count ': '23',}]> 是个 QuerySet 列表对象,列表中的元素是字典格式,如果有多个分组,对象列表中会有多个字典元素# aggregate 聚合查询
queryset = MyModel.objects.values('price','name').order_by().aggregate(my_count = Count('price'))
print(queryset )
# 打印结果:{'price': '23', 'name': '张山', 'my_count ': '23'},直接就是个字典,即便有多个分组,也是相同的结果,aggregate只会统计相全部,不会按分组查询。因此上面的写法,等同于:
queryset = MyModel.objects.aggregate(my_count = Count('price'))
五 annotate 与 aggregate 组合使用
annotate()内可以嵌套aggregate()
# 先按 price和name分组,在计算作者数量的平均数
MyModel.objects.values('price','name').order_by().aggregate(my_count =Count('authors')).aggregate(Avg('my_count '))
六、orm查询终极解决方案
如果遇到查询没有得到想要的结果,那么又想追究原因,那就只能查看原生sql语句了:
queryset = MyModel.objects.aggregate(my_count = Count('price'))
print(queryset.query)
在查询对象的后面加上“.query” 即可在控制台查看原生sql语句。
相关文章:
、分组查询(annotate))
Django ORM查询之聚合函数、聚合查询(aggregate)、分组查询(annotate)
django 版本 3.2 python 3.6.8 一、聚合函数 常见的五个聚合函数: Avg (Average) : 平均值Max (Maximum) : 最大值Min (Minimum) : 最小值Sum (Summary) : 求和Count : 个数 导入语句: from django.db.models import Avg, Max, Min, Sum, Count, Q, …...

构建个性化预约服务:预约上门服务系统源码解读与实战
随着社会的发展,预约上门服务系统在满足用户需求、提升服务效率方面发挥着越来越重要的作用。在本文中,我们将深入研究预约上门服务系统的源码,通过实际的技术代码示例,揭示系统内部的关键机制,以及如何在实际项目中应…...

『RabbitMQ』入门指南(安装,配置,应用)
前言 RabbitMQ 是在 AMQP(Advanced Message Queuing Protocol) 协议标准基础上完整的,可复用的企业消息系统。它遵循 Mozilla Public License 开源协议,采用 Erlang 实现的工业级的消息队列(MQ)服务器,建立在 Erlang …...

2311skia,01渲染架构
一,渲染层级 从渲染流程上分,Skia可分为如下三个层级: 1,指令层:SkPicture,SkDeferredCanvas->SkCanvas 这一层决定要绘图的操作,绘图操作的预变换矩阵,当前裁剪区域,在哪些层上绘图,层的生成与合并. 2,解析层:SkBitmapDevice->SkDraw->SkScan,SkDraw1Glyph::Proc 这…...

天线的负载
在电磁学和通信工程领域,天线的负载(Load)通常指连接到天线的部分或元件,该部分在电学上对天线的输入产生影响。天线的负载可以是被连接到天线的阻抗元件、电感、电容、电阻或其他电性元件。 具体而言,天线的负载是指…...

Java学习路径:入门学习、深入学习、核心技术,操作案例和实际代码示例
学习路径:入门学习、深入学习、核心技术, 每个主题都包括很多的操作案例和实际代码示例。 a. 入门学习: 1. 基础语法: 变量和数据类型: // 定义和初始化变量 int age 25;// 不同数据类型的声明 double price 19.99…...
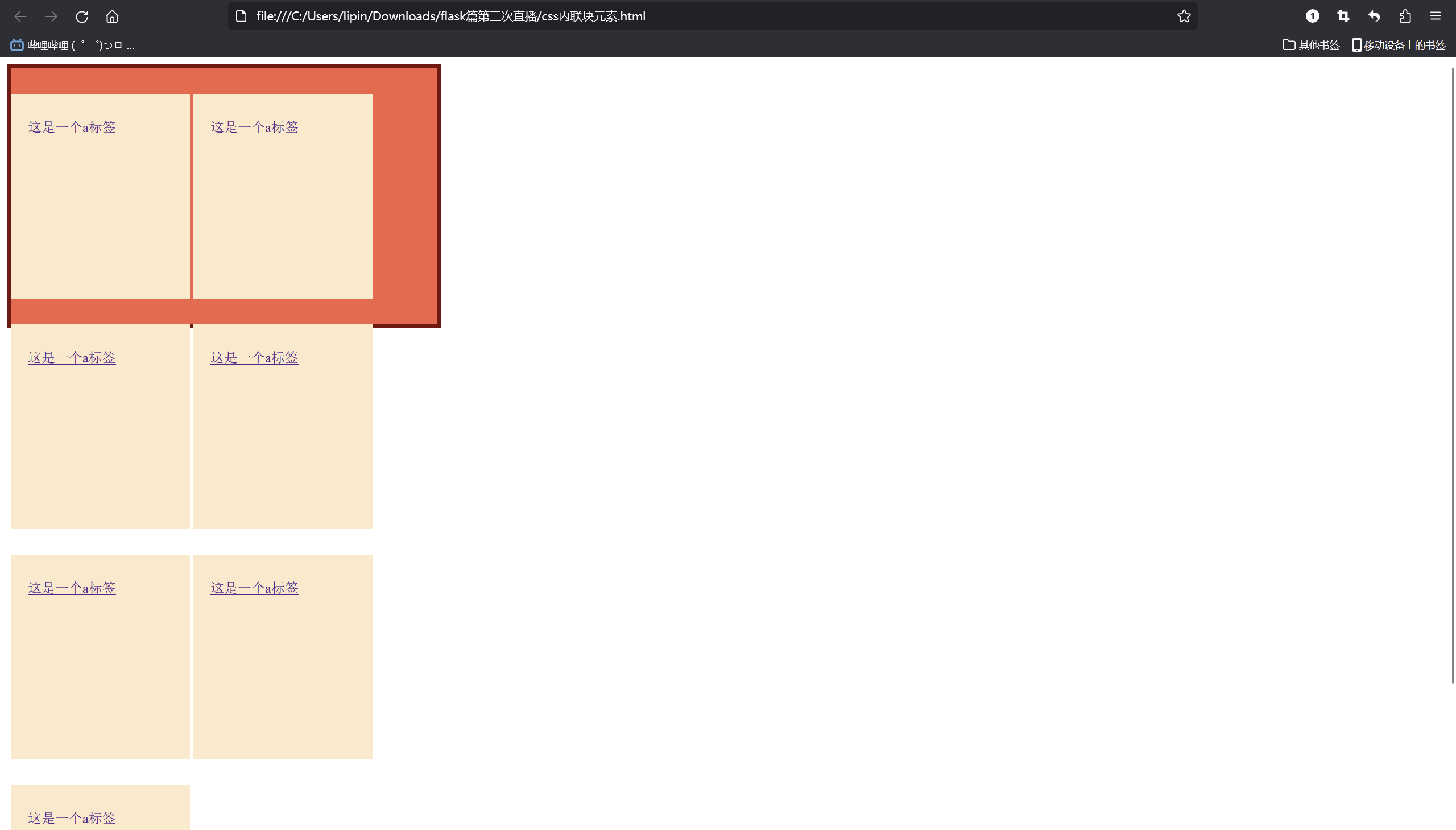
Python武器库开发-前端篇之CSS元素(三十二)
前端篇之CSS元素(三十二) CSS 元素是一个网页中的 HTML 元素,包括标签、类和 ID。它们可以通过 CSS 选择器选中并设置样式属性,以使网页呈现具有吸引力和良好的可读性。常见的 HTML 元素包括 div、p、h1、h2、span 等,它们可以使用 CSS 设置…...
作为Java初学者,如何快速学好Java?
作为Java初学者,如何快速学好Java? 开始的一些话 对于初学者来说,编程的学习曲线可能相对陡峭。这是正常现象,不要感到沮丧。逐步学习,循序渐进。 编程是一门实践性的技能,多写代码是提高的唯一途径。尽量…...
--pwm - PWM模块)
LuatOS-SOC接口文档(air780E)--pwm - PWM模块
pwm.open(channel, period, pulse, pnum, precision) 开启指定的PWM通道 参数 传入值类型 解释 int PWM通道 int 频率, 1-1000000hz int 占空比 0-分频精度 int 输出周期 0为持续输出, 1为单次输出, 其他为指定脉冲数输出 int 分频精度, 100/256/1000, 默认为100,…...

基于51单片机的人体追踪可控的电风扇系统
**单片机设计介绍, 基于51单片机超声波测距汽车避障系统 文章目录 一 概要概述硬件组成工作原理优势应用场景总结 二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 # 基于51单片机的人体追踪可控的电风扇系统介绍 概述 该系统是基于51…...

使用数据集对SegFormer模型进行微调以改进自动驾驶车辆的车道检测-附源码下载
SegFormer:细分严重影响了高级驾驶辅助系统的开发。它在自动驾驶汽车技术的快速发展中发挥了关键作用。它由多个复杂的组件组成。对于任何在道路上行驶的车辆来说,车道检测至关重要。车道是道路上的标记,有助于区分道路上的可行驶区域和不可行驶区域。当前一代有多种车道检测…...
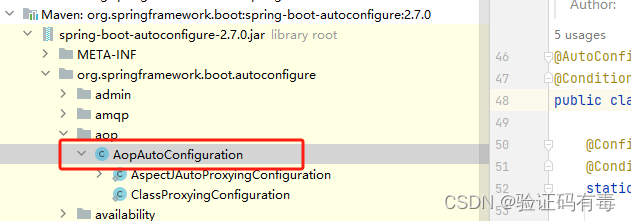
【微服务专题】SpringBoot自动配置简单源码解析
目录 前言阅读对象阅读导航前置知识什么是自动配置0.1 基本概念0.2 SpringBoot中的【约定大于配置】0.3 从SpringMVC看【约定大于配置】0.4 从Redis看【约定大于配置】0.5 小结 笔记正文一、EnableAutoConfiguration源码解析二、SpringBoot常用条件注解源码解析2.1 自定义条件注…...

分布式数据恢复-hbase+hive分布式存储误删除如何恢复数据?
hbasehive分布式存储数据恢复环境: 16台某品牌R730XD服务器节点,每台物理服务器节点上有数台虚拟机,虚拟机上配置的分布式,上层部署hbase数据库hive数据仓库。 hbasehive分布式存储故障&初检: 数据库文件被误删除…...

安卓系统修图软件(一)
平时我们会不时在朋友圈发自己的自拍照,或者是风景图等,许多小伙伴们此时会对照片进行一定的修理,比如添加滤镜等操作。在电脑上用ps修图比较繁琐,日常中大可不必用这把宰牛刀;而手机自带的编辑器,或者是QQ…...

截图转HTML代码,支持预览,前端不用浪费时间写html和css了
截图转代码 试用地址:https://picoapps.xyz/free-tools/screenshot-to-code 这个简单的应用可以将截图转换为HTML/Tailwind CSS代码。它使用GPT-4 Vision来生成代码,并使用DALL-E 3来生成类似的图像。现在你也可以输入一个URL来克隆一个现有的网站&#…...

Vite CSS Module 优雅的处理样式隔离
今天介绍的是我写的一个vite插件vite-plugin-oneof-css-module,该插件主要处理scss module,那它适用于什么场景呢? 1. 最大的特点就是使用scss module 可以不用写 .module.scss 了 2. 可以根据不同的文件夹或文件分别进行不同的处理&#x…...
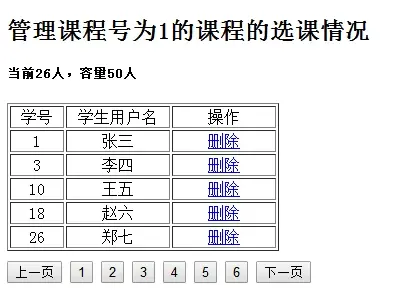
基于Springboot+Vue选课系统
选课系统要求 (1)数据库表:教师信息表、学生信息表、课程表、选课表 其中,教师信息表、学生信息表和选课表的数据需要提前设置,本题主要操作课程表 (2) 技术架构: 后台使用springboot 前端使用vue-admin-template (3) 考试时间&…...
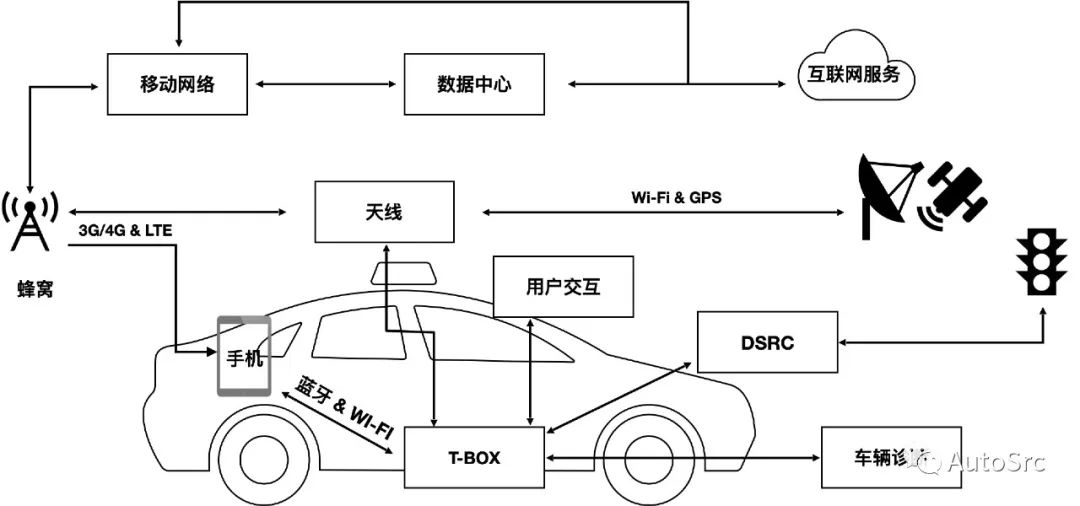
智能汽车十大网络安全攻击场景-《智能汽车网络安全权威指南》
引言 大家都很熟悉OWASP Top 10风险报告,这个报告不但总结了Web应用程序最可能、最常见、最危险的10大安全隐患,还包括了如何消除这些隐患的建议,这个“OWASP Top 10“差不多每隔三年更新一次。目前汽车网络安全攻击威胁隐患繁多,…...

递归方法来计算二叉树的双分支节点个数
1.递归方法来计算二叉树的双分支节点个数 首先,你需要定义二叉树的节点结构,然后编写递归函数 #include <stdio.h> #include <stdlib.h>// 定义二叉树的节点结构 struct TreeNode {int value;struct TreeNode* left;struct TreeNode* righ…...
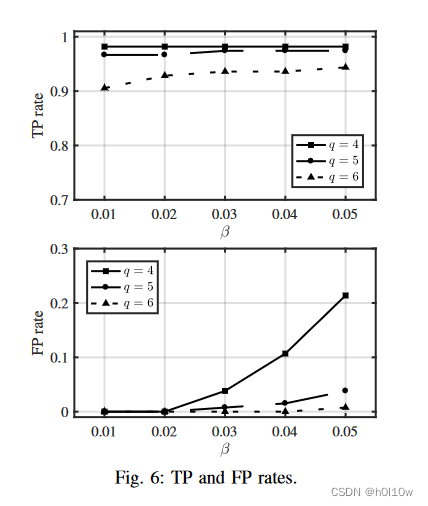
INFLOW:用于检测隐藏服务器的反向网络流水印
文章信息 论文题目:INFLOW: Inverse Network Flow Watermarking for Detecting Hidden Servers 期刊(会议):IEEE INFOCOM 2018 - IEEE Conference on Computer Communications 时间:2018 级别:CCF A 文章链…...

3分钟上手SVG路径编辑器:零代码玩转矢量图形编辑
3分钟上手SVG路径编辑器:零代码玩转矢量图形编辑 【免费下载链接】svg-path-editor Online editor to create and manipulate SVG paths 项目地址: https://gitcode.com/gh_mirrors/sv/svg-path-editor 还在为SVG路径代码头疼吗?SVG Path Editor是…...

猫抓浏览器扩展完整教程:网页媒体资源嗅探与下载终极指南
猫抓浏览器扩展完整教程:网页媒体资源嗅探与下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在当今数字化内容消费时代&am…...

赋能AR/VR应用:Lingbot-Depth-Pretrain-ViTL-14实现实时场景理解与交互
赋能AR/VR应用:Lingbot-Depth-Pretrain-ViTL-14实现实时场景理解与交互 最近几年,增强现实和虚拟现实的应用越来越多了,从手机上的趣味滤镜到专业的工业设计,都能看到它们的身影。但不知道你有没有发现,很多AR效果看起…...

告别闪退!用VirtualBox虚拟机在Win10上丝滑运行Xilinx ISE 14.7的保姆级教程
告别闪退!用VirtualBox虚拟机在Win10上丝滑运行Xilinx ISE 14.7的保姆级教程 FPGA开发者在Windows 10系统上运行Xilinx ISE 14.7时,最常遇到的噩梦莫过于软件频繁闪退。这种不稳定性不仅影响开发效率,更可能造成项目进度延误。本文将介绍一种…...

保姆级教程:在Ubuntu 20.04上从零配置ROS Noetic和MoveIt,搞定你的第一个机械臂仿真
从零搭建机械臂仿真环境:Ubuntu 20.04 ROS Noetic MoveIt全流程指南 当你第一次打开Ubuntu系统,面对空荡荡的终端窗口,想要把SolidWorks设计的机械臂变成可交互的仿真模型,这条路上布满的坑足以让任何新手望而却步。本文将带你穿…...

HEIF Utility:为Windows用户打通苹果照片格式壁垒的3大核心方案
HEIF Utility:为Windows用户打通苹果照片格式壁垒的3大核心方案 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility 你是否曾经从iPhone传输照片到Window…...

深度剖析ESP32蓝牙音频开发:实战优化方案与最佳实践
深度剖析ESP32蓝牙音频开发:实战优化方案与最佳实践 【免费下载链接】arduino-esp32 Arduino core for the ESP32 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 在物联网和智能音频设备快速发展的今天,ESP32凭借其强大的蓝牙…...

从‘地图管理’模块实战出发:手把手拆解一个Vue2 + Vuex的中后台项目store配置
从地图管理模块实战解析Vue2 Vuex状态管理架构设计 在构建中后台管理系统时,状态管理往往是决定项目可维护性的关键因素。以地图资源管理模块为例,我们将深入探讨如何基于Vue2和Vuex设计一个可扩展、易维护的状态管理架构。不同于简单的API调用示例&…...

51单片机按键控制LED的两种编程思路对比:数组映射 vs Switch语句,哪种更适合你?
51单片机按键控制LED的两种编程范式深度解析:数组映射与Switch语句的工程实践 当你在深夜调试一块布满LED的51单片机开发板时,是否曾为按键控制逻辑的代码结构纠结过?作为经历过数十个嵌入式项目的开发者,我发现数组映射和switch-…...

玻璃幕墙建筑节能技术分析及其经济评价
玻璃幕墙建筑节能技术分析及其经济评价 玻璃幕墙(以下简称“幕墙”)是现代化建筑的主要外围护结构之一,其节能已成为我国建筑节能的重要一环。 本文就幕墙的节能进行技术分析、计算,对节能效果进行经济评价。 1 幕墙建筑节能的设计原则本文提出下列措施,作为幕墙建筑节能…...