语音识别入门——常用软件及python运用
工具以及使用到的库
- ffmpeg
- sox
- audacity
- pydub
- scipy
- librosa
- pyAudioAnalysis
- plotly
本文分为两个部分:
P1:如何使用ffmpeg和sox处理音频文件
P2:如何编程处理音频文件并执行基本处理
P1 处理语音数据——命令行方式
格式转换
ffmpeg -i video.mkv audio.mp3
使用ffmpeg将输入mkv文件转为mp3文件
降采样、通道转换
ffmpeg -i audio.wav -ar 16000 -ac 1 audio_16K_mono.wav
- ar:声频采样率(audio rate)
- ac:声频通道(audio channel)
此处是将原来44.1kHz的双通道wav文件转为单通道wav文件
获取音频信息
ffmpeg -i audio_16K_mono.wav
将得到
Input #0, wav, from ‘audio_16K_mono.wav’:
Metadata:
encoder : Lavf57.71.100
Duration: 00:03:10.29, bitrate: 256 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz,
mono, s16, 256 kb/s
- #0表示只有一个通道
- encoder:为libavformat支持的一种容器
- Duration:时长
- bitrate:比特率256kb/s,表示音频每秒传输的数据量,高质量音频一般比较大
- Stram:流
- #0:0:单通道
- pcm_s16le:
- pcm(脉冲编码调制,pulse-code modulation)
- signed integer 16:(16位有符号整型)格式采样
- le表示小端(little endian),高位数据存地址高位,地位数据存地址地位,有如[1][0][0][0] / 0x0001。
- mono:单通道
小插曲
最近看到一道数据类型题
题目:为什么float类型 ( 1 e 10 + 3.14 ) − 1 e 10 = 0 ? \mathbf{(1e10+3.14)-1e10=0?} (1e10+3.14)−1e10=0?
解题如下:
1 e 10 \mathbf{1e10} 1e10二进制表示为:
001 0 ′ 010 1 ′ 010 0 ′ 000 0 ′ 101 1 ′ 111 0 ′ 010 0 ′ 000 0 ′ 0000 \mathbf{0010'0101'0100'0000'1011'1110'0100'0000'0000} 0010′0101′0100′0000′1011′1110′0100′0000′0000
或者表示为
1.001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 0 ′ 000 0 ′ 000 0 ′ 0 2 ∗ 2 33 \mathbf{1.0010'1010'0000'0101'1111'0010'0000'0000'0_2*2^{33}} 1.0010′1010′0000′0101′1111′0010′0000′0000′02∗233
浮点数三要素:
- 首位:0表示正数,1表示负数
- 中间位,8位,为科学计数法指数部分,上例为33与偏置量(127)的和,此例为160,二进制为1010’0000
- 尾部:23位,二进制表示的小数部分的前23位,此例为0010’1010’0000’0101’1111’001
故 1 e 10 \mathbf{1e10} 1e10的浮点数为:
0 ′ 101 0 ′ 000 0 ′ 001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 \mathbf{0'1010'0000'0010'1010'0000'0101'1111'001} 0′1010′0000′0010′1010′0000′0101′1111′001
到此为止,可知舍去了科学计数法中小数部分的后10位
小数的二进制表示两个要素:
- 整数部分:正常表示,3.14整数部分为0011
- 小数部分:乘以2取整数部分,
- 0.14*2=0.28 取0
- 0.28*2=0.56 取0
- 0.56*2=1.12 取1
- 0.12*2=0.24 取0
- 0.24*2=0.48 取0
- 0.48*2=0.96 取0
- 0.96*2=1.92 取1
- …
3.14的二进制表示为:
11.0010001... \mathbf{11.0010001...} 11.0010001...
综上, 1 e 10 + 3.14 \mathbf{1e10+3.14} 1e10+3.14的二进制表示为:
1.001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 0 ′ 000 0 ′ 000 1 ′ 1001 ’ 000 1 2 ∗ 2 33 \mathbf{1.0010'1010'0000'0101'1111'0010'0000'0001'1001’0001_2*2^{33}} 1.0010′1010′0000′0101′1111′0010′0000′0001′1001’00012∗233
转为浮点数,为
0 ′ 101 0 ′ 000 0 ′ 001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 \mathbf{0'1010'0000'0010'1010'0000'0101'1111'001} 0′1010′0000′0010′1010′0000′0101′1111′001
与 1 e 10 \mathbf{1e10} 1e10一样,故float类型 ( 1 e 10 + 3.14 ) − 1 e 10 = 0 \mathbf{(1e10+3.14)-1e10}=0 (1e10+3.14)−1e10=0
修剪音频
ffmpeg -i audio.wav -ss 60 -t 20 audio_small.wav
- i:输入音频audio.wav
- ss: 截取起始秒
- t:截取段时长
- audio_small.wav:输出文件
串联视频
新建一个list_of_files_to_concat的txt文档,内容如下:
file 'file1.wav'
file 'file2.wav'
file 'file3.wav'
采用以下命令行,可将三个文件串联输出,编码方式为复制
ffmpeg -f concat -i list_of_files_to_concat -c copy output.wav
分割视频
以下命令行将输入视频分割为1s一个
ffmpeg -i output.wav -f segment -segment_time 1 -c copy out%05d.wav
交换声道
ffmpeg -i stereo.wav -map_channel 0.0.1 -map_channel 0.0.0 stereo_inverted.wav
- 0.0.1输入文件音频流右声道
- 0.0.0输入文件音频流左声道
合并声道
ffmpeg -i left.wav -i right.wav -filter_complex "[0:a][1:a]join=inputs=2:channel_layout=stereo[a]" -map "[a]" mix_channels.wav
- filter_complex:复杂音频滤波器图
- [0:a],[1:a]:第一个和第二个文件的音频流
- join=inputs=2:表示两个输入流混合
- channel_layout=stereo:混合后输出为立体声
- [a]:输出音频流标签
- map ”[a]":将‘[a]'标签的音频流映射到输出文件
分割立体声音频为左右单声道文件
ffmpeg -i stereo.wav -map_channel 0.0.0 left.wav -map_channel 0.0.1 right.wav
- map_channel 0.0.0:将左声道映射到第一个输出文件
- map_channel 0.0.1:将右声道映射到第二个输出文件
将某个声道静音
ffmpeg -i stereo.wav -map_channel -1 -map_channel 0.0.1 muted.wav
- map_channel -1:忽略某声道
- map_channel 0.0.1:将右声道映射到输出文件
音量调节
ffmpeg -i data/music_44100.wav -filter:a “volume=0.5” data/music_44100_volume_50.wav
ffmpeg -i data/music_44100.wav -filter:a “volume=2.0” data/music_44100_volume_200.wav
- filter:a:使用音频过滤器
- “volume=0.5”:将音频音量变为原来一半
- “volume=2”:将音频音量变为原来两倍
sox音量调节
sox -v 0.5 data/music_44100.wav data/music_44100_volume_50_sox.wav
sox -v 2.0 data/music_44100.wav data/music_44100_volume_200_sox.wav
sox -v n \text{sox -v n} sox -v n 输入文件路径 输出文件路径
- v n:音量调节系数,n可理解为倍数。
P2 处理语音数据——编程方式
- wav: scipy.io.wavfile
- mp3:pydub
以数组形式加载音频文件
# 以数组形式读取wav和mp3
from pydub import AudioSegment
import numpy as np
from scipy.io import wavfile# 用 scipy.io.wavfile 读取wav文件
fs_wav, data_wav = wavfile.read("resampled.wav")# 用 pydub 读取mp3
audiofile = AudioSegment.from_file("resampled.mp3")
data_mp3 = np.array(audiofile.get_array_of_samples())
fs_mp3 = audiofile.frame_rateprint('Sq Error Between mp3 and wav data = {}'.format(((data_mp3 - data_wav)**2).sum()/len(data_wav)))
print('Signal Duration = {} seconds'.format(data_wav.shape[0] / fs_wav))
# 输出,我使用ffmpeg将wav转成MP3,比特率将为24kb
Sq Error Between mp3 and wav data = 3775.2859044790266
Signal Duration = 34.5513125 seconds
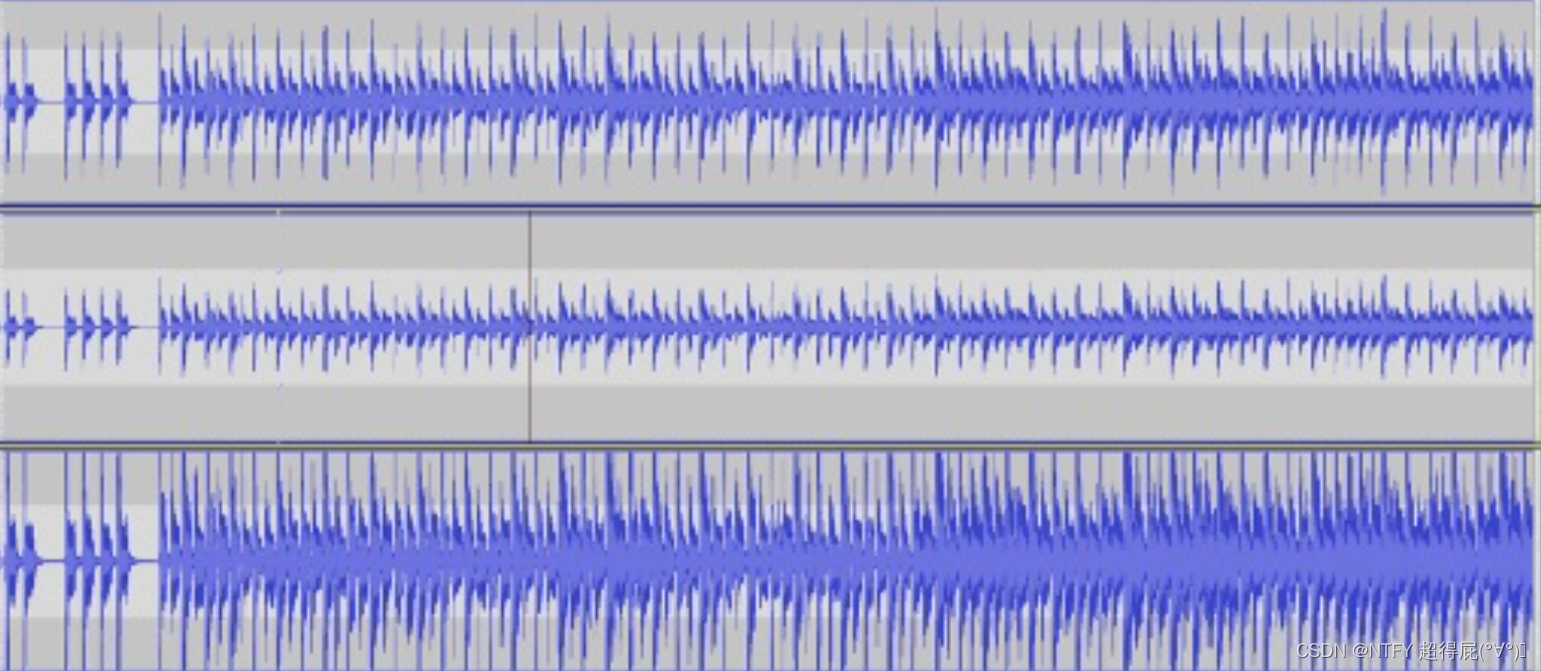
显示左右声道
import numpy as np
from scipy.io import wavfile
import matplotlib.pyplot as plt
fs,data=wavfile.read('resampled_double.wav')
time=np.arange(0,len(data))/fs
fig,axs=plt.subplots(2,1,figsize=(10,6),sharex=True)
axs[0].plot(time,data[:,0],label='Left Channel',color='blue')
axs[0].set_ylabel('Amplitude')
axs[0].legend()
axs[1].plot(time,data[:,1],label='Right Channel',color='orange')
axs[1].set_ylabel('Amplitute')
axs[1].set_xlabel('Time(seconds)')
axs[1].legend()
plt.suptitle("Stereo Audio Waveform")
plt.show()
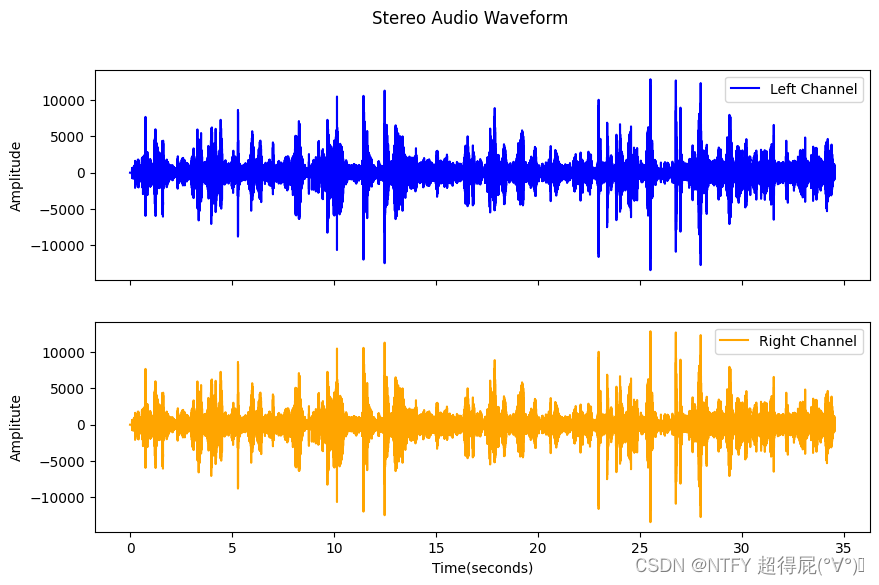
正则化
import matplotlib.pyplot as plt
from scipy.io import wavfile
import numpy as np
fs,data = wavfile.read("resampled_double.wav")
time=np.arange(0,len(data))/fs
plt.figure(figsize=(10,4))
plt.plot(time,data[:,0]/2^15)
plt.xlabel('Time(seconds)')
plt.ylabel('Amplitude')
plt.title('Stereo Audio Waveform')
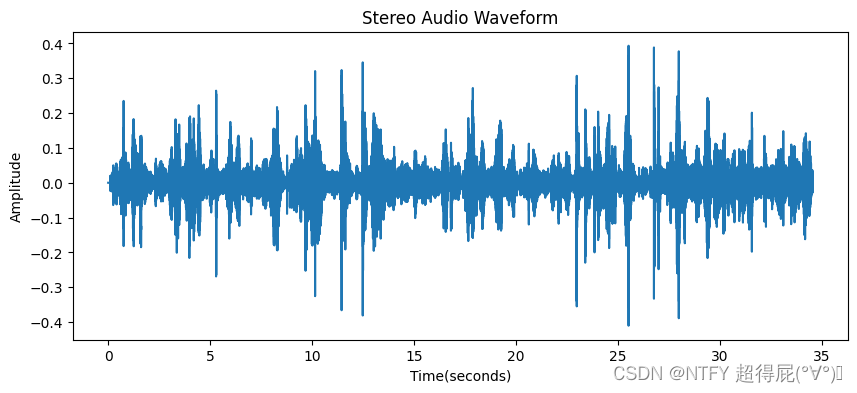
修剪音频
# 显示2到4秒的波形
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
fs,data=wavfile.read('resampled_double.wav')
time=np.arange(0,len(data[2*fs:4*fs]))/fs
plt.figure(figsize=(10,4))
plt.plot(time,data[2*fs:4*fs])
plt.xlabel('Time/s')
plt.ylabel('Amplitude')
plt.title('Stereo Audio Waveform')
plt.show()
分割为固定大小
import numpy as np
from scipy.io import wavfile
import IPython
fs,signal=wavfile.read("resampled.wav")
segment_size_t=1
segment_size=segment_size_t*fs
segments=[signal[x:x+segment_size]for x in range(0,len(signal),segment_size)]
for i,s in enumerate(segments):if len(s)<segment_size:s=np.pad(s,(0,(segment_size-len(s))),'constant') # 这里是为了每个clip都为1swavfile.write(f"resampled_segment_{i}_{i+1}.wav",fs,s)
IPython.display.display(IPython.display.Audio("resampled_segment_34_35.wav"))
# 输出,成功输出35个1s的wav文件
简单算法——删去无声片段
import IPython
import matplotlib.pyplot as plt
import numpy as np
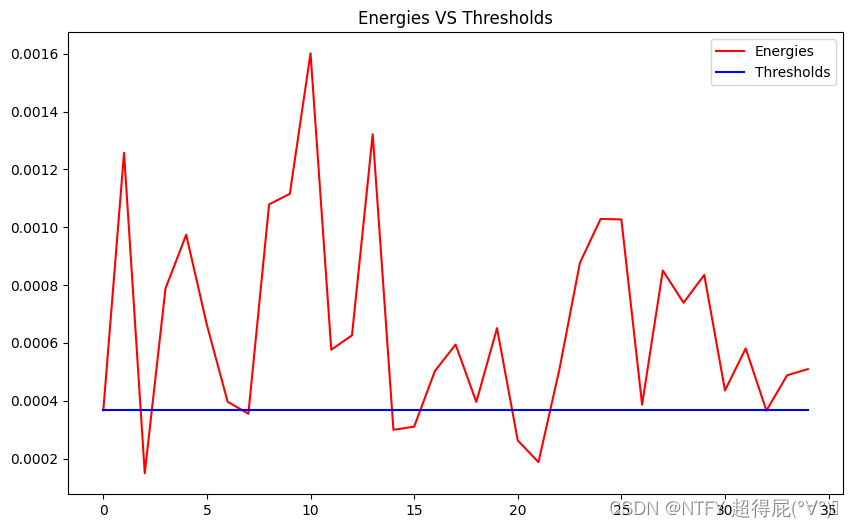
energies=[((s/2**15)**2).sum()/len(s) for s in segments] # 防止溢出
thres=np.percentile(energies,20)
indices_of_segments_to_keep=(np.where(energies>thres)[0])
segments2=np.array(segments)[indices_of_segments_to_keep]
new_signal=np.concatenate(segments2)
wavfile.write("processed_new.wav",fs,new_signal.astype(np.int16)) # 转成int
plt.figure(figsize=(10,6))
plt.plot(energies,label="Energies",color="red")
plt.plot(np.ones(len(energies))*thres,label="Thresholds",color="blue")
plt.title("Energies VS Thresholds")
plt.legend()
plt.show()
IPython.display.display(IPython.display.Audio("processed_new.wav"))
IPython.display.display(IPython.display.Audio("resampled.wav"))
往单声道音频中加入节拍
import numpy as np
import scipy.io.wavfile as wavfile
import librosa
import IPython
import matplotlib.pyplot as plt# 加载文件并提取节奏和节拍:
[Fs, s] = wavfile.read('resampled.wav')
tempo, beats = librosa.beat.beat_track(y=s.astype('float'), sr=Fs, units="time")
beats -= 0.05# 在每个节拍的第二个声道上添加小的220Hz声音
s = s.reshape(-1, 1)
s = np.array(np.concatenate((s, np.zeros(s.shape)), axis=1))
for ib, b in enumerate(beats):t = np.arange(0, 0.2, 1.0 / Fs)amp_mod = 0.2 / (np.sqrt(t)+0.2) - 0.2amp_mod[amp_mod < 0] = 0x = s.max() * np.cos(2 * np.pi * t * 220) * amp_mods[int(Fs * b): int(Fs * b) + int(x.shape[0]), 1] = x.astype('int16')# 写入一个wav文件,其中第二个声道具有估计的节奏:
wavfile.write("tempo.wav", Fs, np.int16(s))# 在笔记本中播放生成的文件:
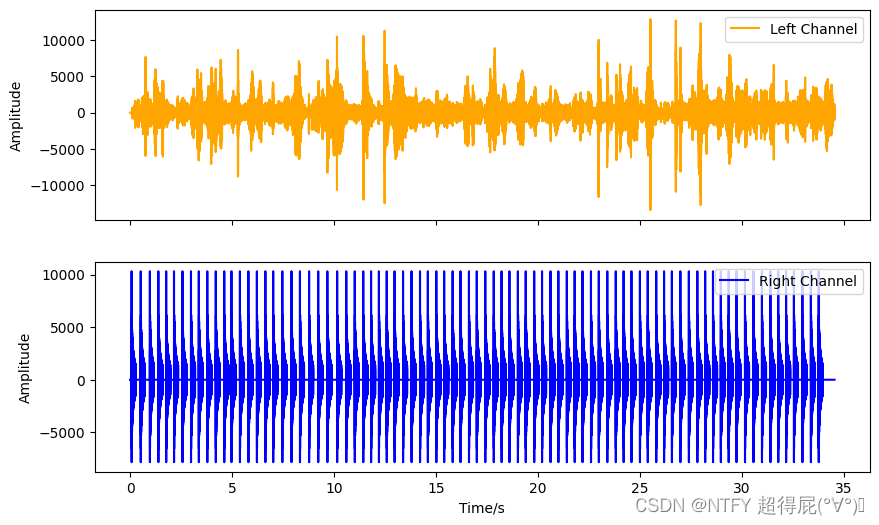
IPython.display.display(IPython.display.Audio("tempo.wav"))# 绘制波形图
time = np.arange(0, len(s)) / Fs
fig, axs = plt.subplots(2, 1, figsize=(10, 6), sharex=True)
axs[0].plot(time, s[:, 0], label='左声道', color='orange')
axs[0].set_ylabel('振幅')
axs[0].legend()
axs[1].plot(time, s[:, 1], label='右声道', color='blue')
axs[1].set_xlabel("时间/秒")
axs[1].set_ylabel("振幅")
axs[1].legend()
plt.show()
实时录制以及频率分析
# paura_lite:
# 一个超简单的命令行音频录制器,具有实时频谱可视化import numpy as np
import pyaudio
import struct
import scipy.fftpack as scp
import termplotlib as tpl
import os# 获取窗口尺寸
rows, columns = os.popen('stty size', 'r').read().split()buff_size = 0.2 # 窗口大小(秒)
wanted_num_of_bins = 40 # 要显示的频率分量数量# 初始化声卡进行录制:
fs = 8000
pa = pyaudio.PyAudio()
stream = pa.open(format=pyaudio.paInt16, channels=1, rate=fs,input=True, frames_per_buffer=int(fs * buff_size))while 1: # 对于每个录制的窗口(直到按下Ctrl+C)# 获取当前块并将其转换为short整数列表,block = stream.read(int(fs * buff_size))format = "%dh" % (len(block) / 2)shorts = struct.unpack(format, block)# 然后进行归一化并转换为numpy数组:x = np.double(list(shorts)) / (2**15)seg_len = len(x)# 获取当前窗口的总能量并计算归一化因子# 用于可视化最大频谱图值energy = np.mean(x ** 2)max_energy = 0.02 # 条形设置为最大的能量max_width_from_energy = int((energy / max_energy) * int(columns)) + 1if max_width_from_energy > int(columns) - 10:max_width_from_energy = int(columns) - 10# 获取FFT的幅度和相应的频率X = np.abs(scp.fft(x))[0:int(seg_len/2)]freqs = (np.arange(0, 1 + 1.0/len(X), 1.0 / len(X)) * fs / 2)# ... 并重新采样为固定数量的频率分量(用于可视化)wanted_step = (int(freqs.shape[0] / wanted_num_of_bins))freqs2 = freqs[0::wanted_step].astype('int')X2 = np.mean(X.reshape(-1, wanted_step), axis=1)# 将(频率,FFT)作为水平直方图绘制:fig = tpl.figure()fig.barh(X2, labels=[str(int(f)) + " Hz" for f in freqs2[0:-1]],show_vals=False, max_width=max_width_from_energy)fig.show()# 添加足够多的新行以清除屏幕在下一次迭代中:print("\n" * (int(rows) - freqs2.shape[0] - 1))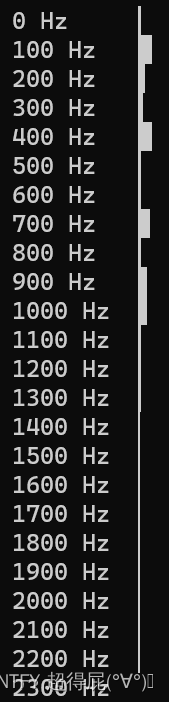
相关文章:
语音识别入门——常用软件及python运用
工具以及使用到的库 ffmpegsoxaudacitypydubscipylibrosapyAudioAnalysisplotly 本文分为两个部分: P1:如何使用ffmpeg和sox处理音频文件 P2:如何编程处理音频文件并执行基本处理 P1 处理语音数据——命令行方式 格式转换 ffmpeg -i video…...

maven 将Jar包安装到本地仓库
window系统: 注意事项:在windows中,使用mvn指令将jar安装到本地仓库时,一定要将相关资源使用“"”包裹上,不然会报下面的错: mvn install:install-file "-DfileD:\BaiduNetdiskDownload\qianzixi…...
、分组查询(annotate))
Django ORM查询之聚合函数、聚合查询(aggregate)、分组查询(annotate)
django 版本 3.2 python 3.6.8 一、聚合函数 常见的五个聚合函数: Avg (Average) : 平均值Max (Maximum) : 最大值Min (Minimum) : 最小值Sum (Summary) : 求和Count : 个数 导入语句: from django.db.models import Avg, Max, Min, Sum, Count, Q, …...

构建个性化预约服务:预约上门服务系统源码解读与实战
随着社会的发展,预约上门服务系统在满足用户需求、提升服务效率方面发挥着越来越重要的作用。在本文中,我们将深入研究预约上门服务系统的源码,通过实际的技术代码示例,揭示系统内部的关键机制,以及如何在实际项目中应…...

『RabbitMQ』入门指南(安装,配置,应用)
前言 RabbitMQ 是在 AMQP(Advanced Message Queuing Protocol) 协议标准基础上完整的,可复用的企业消息系统。它遵循 Mozilla Public License 开源协议,采用 Erlang 实现的工业级的消息队列(MQ)服务器,建立在 Erlang …...

2311skia,01渲染架构
一,渲染层级 从渲染流程上分,Skia可分为如下三个层级: 1,指令层:SkPicture,SkDeferredCanvas->SkCanvas 这一层决定要绘图的操作,绘图操作的预变换矩阵,当前裁剪区域,在哪些层上绘图,层的生成与合并. 2,解析层:SkBitmapDevice->SkDraw->SkScan,SkDraw1Glyph::Proc 这…...

天线的负载
在电磁学和通信工程领域,天线的负载(Load)通常指连接到天线的部分或元件,该部分在电学上对天线的输入产生影响。天线的负载可以是被连接到天线的阻抗元件、电感、电容、电阻或其他电性元件。 具体而言,天线的负载是指…...

Java学习路径:入门学习、深入学习、核心技术,操作案例和实际代码示例
学习路径:入门学习、深入学习、核心技术, 每个主题都包括很多的操作案例和实际代码示例。 a. 入门学习: 1. 基础语法: 变量和数据类型: // 定义和初始化变量 int age 25;// 不同数据类型的声明 double price 19.99…...
Python武器库开发-前端篇之CSS元素(三十二)
前端篇之CSS元素(三十二) CSS 元素是一个网页中的 HTML 元素,包括标签、类和 ID。它们可以通过 CSS 选择器选中并设置样式属性,以使网页呈现具有吸引力和良好的可读性。常见的 HTML 元素包括 div、p、h1、h2、span 等,它们可以使用 CSS 设置…...
作为Java初学者,如何快速学好Java?
作为Java初学者,如何快速学好Java? 开始的一些话 对于初学者来说,编程的学习曲线可能相对陡峭。这是正常现象,不要感到沮丧。逐步学习,循序渐进。 编程是一门实践性的技能,多写代码是提高的唯一途径。尽量…...
--pwm - PWM模块)
LuatOS-SOC接口文档(air780E)--pwm - PWM模块
pwm.open(channel, period, pulse, pnum, precision) 开启指定的PWM通道 参数 传入值类型 解释 int PWM通道 int 频率, 1-1000000hz int 占空比 0-分频精度 int 输出周期 0为持续输出, 1为单次输出, 其他为指定脉冲数输出 int 分频精度, 100/256/1000, 默认为100,…...

基于51单片机的人体追踪可控的电风扇系统
**单片机设计介绍, 基于51单片机超声波测距汽车避障系统 文章目录 一 概要概述硬件组成工作原理优势应用场景总结 二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 # 基于51单片机的人体追踪可控的电风扇系统介绍 概述 该系统是基于51…...

使用数据集对SegFormer模型进行微调以改进自动驾驶车辆的车道检测-附源码下载
SegFormer:细分严重影响了高级驾驶辅助系统的开发。它在自动驾驶汽车技术的快速发展中发挥了关键作用。它由多个复杂的组件组成。对于任何在道路上行驶的车辆来说,车道检测至关重要。车道是道路上的标记,有助于区分道路上的可行驶区域和不可行驶区域。当前一代有多种车道检测…...
【微服务专题】SpringBoot自动配置简单源码解析
目录 前言阅读对象阅读导航前置知识什么是自动配置0.1 基本概念0.2 SpringBoot中的【约定大于配置】0.3 从SpringMVC看【约定大于配置】0.4 从Redis看【约定大于配置】0.5 小结 笔记正文一、EnableAutoConfiguration源码解析二、SpringBoot常用条件注解源码解析2.1 自定义条件注…...

分布式数据恢复-hbase+hive分布式存储误删除如何恢复数据?
hbasehive分布式存储数据恢复环境: 16台某品牌R730XD服务器节点,每台物理服务器节点上有数台虚拟机,虚拟机上配置的分布式,上层部署hbase数据库hive数据仓库。 hbasehive分布式存储故障&初检: 数据库文件被误删除…...

安卓系统修图软件(一)
平时我们会不时在朋友圈发自己的自拍照,或者是风景图等,许多小伙伴们此时会对照片进行一定的修理,比如添加滤镜等操作。在电脑上用ps修图比较繁琐,日常中大可不必用这把宰牛刀;而手机自带的编辑器,或者是QQ…...

截图转HTML代码,支持预览,前端不用浪费时间写html和css了
截图转代码 试用地址:https://picoapps.xyz/free-tools/screenshot-to-code 这个简单的应用可以将截图转换为HTML/Tailwind CSS代码。它使用GPT-4 Vision来生成代码,并使用DALL-E 3来生成类似的图像。现在你也可以输入一个URL来克隆一个现有的网站&#…...

Vite CSS Module 优雅的处理样式隔离
今天介绍的是我写的一个vite插件vite-plugin-oneof-css-module,该插件主要处理scss module,那它适用于什么场景呢? 1. 最大的特点就是使用scss module 可以不用写 .module.scss 了 2. 可以根据不同的文件夹或文件分别进行不同的处理&#x…...
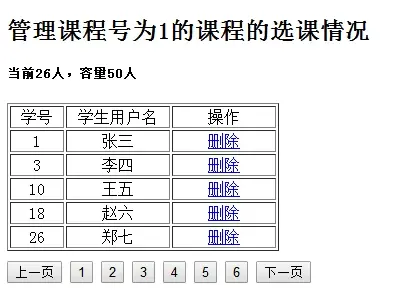
基于Springboot+Vue选课系统
选课系统要求 (1)数据库表:教师信息表、学生信息表、课程表、选课表 其中,教师信息表、学生信息表和选课表的数据需要提前设置,本题主要操作课程表 (2) 技术架构: 后台使用springboot 前端使用vue-admin-template (3) 考试时间&…...
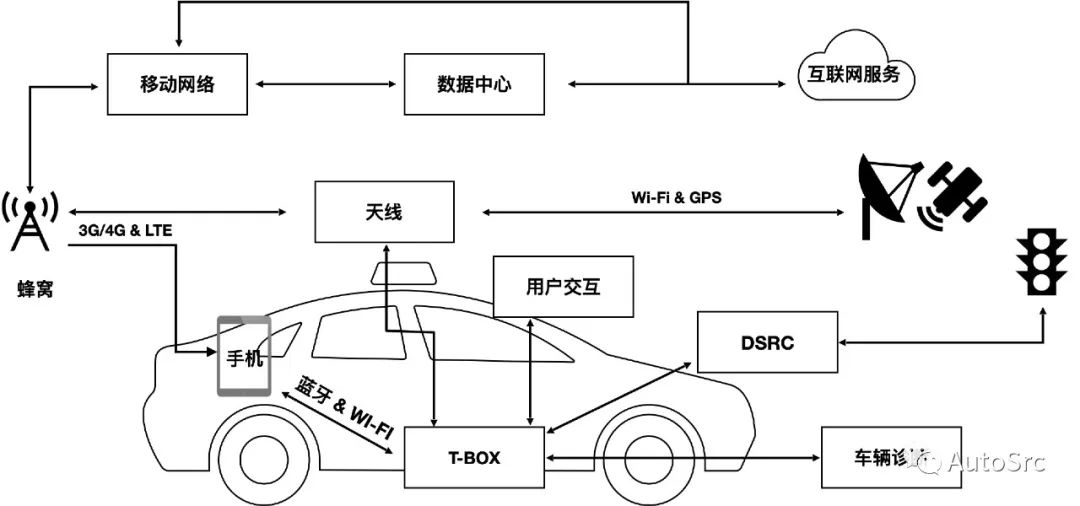
智能汽车十大网络安全攻击场景-《智能汽车网络安全权威指南》
引言 大家都很熟悉OWASP Top 10风险报告,这个报告不但总结了Web应用程序最可能、最常见、最危险的10大安全隐患,还包括了如何消除这些隐患的建议,这个“OWASP Top 10“差不多每隔三年更新一次。目前汽车网络安全攻击威胁隐患繁多,…...

终极Win11优化指南:用Win11Debloat让系统重获新生
终极Win11优化指南:用Win11Debloat让系统重获新生 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

如何快速免费解锁iPhone激活锁:applera1n完整使用指南
如何快速免费解锁iPhone激活锁:applera1n完整使用指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone,却因为原主人的Apple ID激活锁而无法使用&am…...

Qwen3-8B性能实测:在RTX 4090上跑出40 tokens/s,性价比之选
Qwen3-8B性能实测:在RTX 4090上跑出40 tokens/s,性价比之选 1. 引言:消费级显卡上的大模型新选择 当大语言模型逐渐成为AI应用的核心组件,一个现实问题摆在开发者面前:如何在有限的硬件资源上获得最佳的性能体验&…...
?)
PHP = 分配文件描述符 (FD)?
PHP 是“申请者”,操作系统内核才是“分配者”。** PHP 无法直接创建或分配文件描述符 (FD)。它只能通过调用标准库函数(如 fopen, curl_init, socket_create),向操作系统发起系统调用 (System Call),请求内核分配一个…...

从‘地图管理’模块实战出发:手把手拆解一个Vue2 + Vuex的中后台项目store配置
从地图管理模块实战解析Vue2 Vuex状态管理架构设计 在构建中后台管理系统时,状态管理往往是决定项目可维护性的关键因素。以地图资源管理模块为例,我们将深入探讨如何基于Vue2和Vuex设计一个可扩展、易维护的状态管理架构。不同于简单的API调用示例&…...

ncmdump:解锁网易云音乐加密文件的自由播放能力
ncmdump:解锁网易云音乐加密文件的自由播放能力 【免费下载链接】ncmdump 转换网易云音乐 ncm 到 mp3 / flac. Convert Netease Cloud Music ncm files to mp3/flac files. 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdump 你是否曾遇到过这样的情况&a…...

Path of Building PoE2:3步掌握流放之路2角色规划器的终极指南
Path of Building PoE2:3步掌握流放之路2角色规划器的终极指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 还在为《流放之路2》复杂的角色构建而烦恼吗?每次天赋加点都像在黑…...

UndertaleModTool:开启GameMaker游戏深度修改的艺术之旅
UndertaleModTool:开启GameMaker游戏深度修改的艺术之旅 【免费下载链接】UndertaleModTool The most complete tool for modding, decompiling and unpacking Undertale (and other GameMaker games!) 项目地址: https://gitcode.com/gh_mirrors/un/UndertaleMod…...

忍者像素绘卷部署案例:高校AI实验室构建面向本科生的像素艺术实践平台
忍者像素绘卷部署案例:高校AI实验室构建面向本科生的像素艺术实践平台 1. 项目背景与教育价值 在数字艺术教育领域,如何让本科生快速掌握AI辅助创作能力成为教学新课题。某高校AI实验室选择"忍者像素绘卷"作为教学平台,主要基于以…...

rtrvr.ai AI 子程序:零 token 成本自动化脚本,解决网络智能体认证难题!
rtrvr.ai 产品介绍rtrvr.ai 提供多种产品服务,包括博客、预约演示、定价、API 文档、扩展程序、云端服务等。AI 子程序功能特点只需录制一次浏览器任务,就能将其作为可调用工具进行回放,零 token 成本,100% 确定性,认证…...