Mysql面经
Select语句的执行顺序
1、from 子句组装来自不同数据源的数据;
2、where 子句基于指定的条件对记录行进行筛选;
3、group by 子句将数据划分为多个分组;
4、使用聚集函数进行计算;AVG() SUM() MAX() MIN() COUNT()
5、使用 having 子句筛选分组;
6、计算所有的表达式;
7、select 的字段;
8、使用 order by 对结果集进行排序。
where和having的区别
where是一个约束声明,使用where来约束来自数据库的数据;
where是在结果返回之前起作用的;
where中不能使用聚合函数。
having:
having是一个过滤声明;
在查询返回结果集以后,对查询结果进行的过滤操作;
在having中可以使用聚合函数。
where和having的执行顺序:where早于group by早于having。
count(*)和count(列名)的区别?
1、count(*)包含了所有的列,相当于行数,在统计结果的时候,不会忽略列值为空的情况;
2、count(1)在统计结果的时候也不会忽略列值为空的情况(即某个列为空时,仍进行统计);
3、count(列名)在统计的时候会忽略列名为空(null)的情况(即某个列为空时,不统计);
数据库一二三范式的作用?
第一范式就是属性不可分割,每个字段都应该是不可再拆分的。(姓名)
第二范式是在第一范式的基础上更进一步。第二范式就是要求表中要有主键,表中其他字段都依赖于主键,因此第二范式只要记住主键约束就好了。
第三范式就是确保数据表中的每一列数据都和主键直接相关,而不能间接相关。也就是要消除传递依赖,方便理解,可以看做是消除冗余,因此第三范式只要记住外键约束就好了。
范式可以避免数据冗余,减少数据库的空间,减轻维护数据完整性的麻烦。范式越高性能就会越差。一般在项目中,用得最多的也就是第三范式
InnoDB的Buffer Pool MySQL日志
redo log和undo log的区别
1.redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
2.undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。
redo log和二进制日志的区别
二进制日志是在存储引擎的上层产生的,不管是什么存储引擎,对数据库进行了修改都会产生二进制日志。而redo log是innodb层产生的,只记录该存储引擎中表的修改。并且二进制日志先于redo log被记录
二进制日志记录操作的方法是逻辑性的语句。即便它是基于行格式的记录方式,其本质也还是逻辑的SQL设置,如该行记录的每列的值是多少。而redo log是在物理格式上的日志,它记录的是数据库中每个页的修改。
(1)作用不同:redo log是用于crash recovery的,保证MySQL宕机也不会影响持久性;binlog是用于point-in-time recovery的,保证服务器可以基于时间点恢复数据,此外binlog还用于主从复制。
(2)层次不同:redo log是InnoDB存储引擎实现的,而binlog是MySQL的服务器层(可以参考文章前面对MySQL逻辑架构的介绍)实现的,同时支持InnoDB和其他存储引擎。
(3)内容不同:redo log是物理日志,内容基于磁盘的Page;binlog的内容是二进制的,根据binlog_format参数的不同,可能基于sql语句、基于数据本身或者二者的混合。
(4)写入时机不同:binlog在事务提交时写入;redo log的写入时机相对多元:
mysql中drop、truncate和delete的区别
delete和truncate只删除表的数据不删除表的结构 速度,一般来说: drop> truncate >delete delete语句是dml,这个操作会放到rollback segement中,事务提交之后才生效; 如果有相应的trigger,执行的时候将被触发.
truncate,drop是ddl, 操作立即生效,原数据不放到rollback segment中,不能回滚.
操作不触发trigger.
事务的ACID特性
acid,是指在数据库管理系统中事务所具有的四个特性:原子性、一致性、隔离性、持久性。
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
而对于这四大特性,实际上分为两个部分。 其中的原子性、一致性、持久化,实际上是由InnoDB中的两份日志来保证的,一份是redo log日志,一份是undo log日志。 而持久性是通过数据库的锁,加上MVCC来保证的。
说一下MySQL执行一条查询语句的内部执行?
1.首先使用登录命令登录 MySQL,登录后,输入一条查询语句;
2.执行后,会首先查询缓存,若缓存中有对应的数据,直接返回,若没有,则会找分析器进行下一步操作,注意,只有在开启查询缓存时才会执行这一步,MySQL 8.0 版本后就没有查询缓存了,语句会直接走分析器;
3.分析器首先对 SQL 语句进行词法分析,根据输入的 select,判断这条语句是查询语句,并将后面的字符串识别成对应的表名与列名,随后会对 SQL 语句进行语法分析,判断这条语句是否符合 MySQL 的语法规则,若符合,则会进入优化器阶段;
4.优化器会根据语句来选择这条语句的具体执行方案,然后交给执行器执行;
5.执行器会判断用户对要使用的表有没有执行查询的权限,若没有权限,就会返回没有权限的错误
innodb和myisam的特点与区别?
InnoDB支持事务,MyISAM不支持,
InnoDB支持外键,而MyISAM不支持
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的
MyISAM是非聚集索引,索引和数据文件是分离的,索引保存的是数据文件的指针。
InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。
MySQL建立索引方式简单说一下索引的优缺点
一、索引的优点
1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度;
2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性;
3)可以加速表与表之间的链接;
4)降低查询中分组和排序的时间。
二、索引的缺点
1)索引的存储需要占用磁盘空间;
2)当数据的量非常巨大时,索引的创建和维护所耗费的时间也是相当大的;
3)当每次执行CRU操作时,索引也需要动态维护,降低了数据的维护速度
索引的底层实现? B+树
所有的数据都会出现在叶子节点。
叶子节点形成一个单向链表。
非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
聚簇索引和非聚簇索引
含义:将数据存储与索引放一块,索引结构的叶子节点保存了行数据,将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键
特点:必须有,而且只有一个(如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索 引。) 可以存在多个
聚集索引的叶子节点下挂的是这一行的数据 。
二级索引的叶子节点下挂的是该字段值对应的主键值。
索引最左前缀/最左匹配了解吗?
最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在。不存在会导致联合索引不被使用。
mysql索引命中规则——最左匹配原则索引失效的情况
最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在。不存在会导致复合索引不被使用。
如何分析SQL语句的性能,要关注哪些字段?
1、查询语句中不要使用select *
2、尽量减少子查询,使用关联查询(left join,right join,inner join)替代
3、减少使用IN或者NOT IN ,使用exists,not exists或者关联查询语句替代
4、or 的查询尽量用 union或者union all 代替(在确认没有重复数据或者不用剔除重复数据时,
union all会更好)
5、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
6、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表
扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
什么是脏读,不可重复读和幻读?
脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提
交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数
据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结
束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数
据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
innodb引擎的4大特性
插入缓冲(insert buffer);
二次写(double write);
自适应哈希索引(ahi);
预读(read ahead)。
为什么Elasticsearch比MySql的检索快?
1)基于分词后的全文检索:例如select * from test where name like ‘%张三%’,对于mysql来说,因为索引失效,会进行全表检索;对es而言分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表,大大的提升了性能,减少了磁盘IO。
2)精确检索:进行精确检索,有些时候可能mysql要快一些,当mysql的非聚合索引引用上了聚合索引,无需回表,则速度上可能更快;es还是通过FST找到倒排索引的位置比获取文档id列表,再根据文档id获取文档并根据相关度进行排序。但是es还有个优势,就是es即天然的分布式能够在大量数据搜索时可以通过分片降低检索规模,并且可以通过并行检索提升效率,用filter时,更是可以直接跳过检索直接走缓存。
数据的锁的种类,加锁的方式InnoDB锁的有哪几种?
MySQL 中有共享锁和排它锁,也就是读锁和写锁。
- 共享锁:不堵塞,多个用户可以同一时刻读取同一个资源,相互之间没有影响。
- 排它锁:一个写操作阻塞其他的读锁和写锁,这样可以只允许一个用户进行写入,防止其他用户读取正在写入的资源。
- 表锁:系统开销最小,会锁定整张表,MyISAM 使用表锁。
- 行锁:容易出现死锁,发生冲突概率低,并发高,InnoDB 支持行锁(必须有索引才能实现,否则会自动锁全表,那么就不是行锁了)。
InnoDB怎么解决幻读的?
READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可
能会导致脏读、幻读或不可重复读。
READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
与 SQL 标准不同的地方在于 InnoDB 存储引擎在 REPEATABLE-READ(可重
读)事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生。
可重复读如何实现
可重复读的核心就是一致性读(consistent read);而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
乐观锁和MVCC的区别?
MVCC(Multi-Version Concurrent Control),基于快照隔离机制(Snapshot Isolations)进行多版本并发控制,是一种以乐观锁为理论基础的,用来解决读-写冲突的无锁并发控制。也就是为事务分配单向增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照,也就是说,事务开启时看到是哪个版本就看到这个版本,这样在读操作不用阻塞写操作,写操作不用阻塞读操作,提升性能的同时,避免了脏读和不可重复读
乐观锁(基于数据版本( Version )记录机制实现并发控制)是一种基础理论,在读写事务,在真正的提交之前,不加读/写锁,而是先看一下数据的版本/时间戳,等到真正提交的时候再看一下版本/时间戳,如果两次相同,说明别人期间没有对数据进行过修改,那么就可以放心提交;如果遇到冲突,则需要回退。
当前读和快照读
当前读:读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select … lock in share mode(共享锁),select …for update、update、insert、delete(排他锁)都是一种当前读。
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读
MVCC数据的锁的种类,加锁的方式数据库高并发的解决方案
分库分表有了解吗?依据什么原则
相关文章:

Mysql面经
Select语句的执行顺序 1、from 子句组装来自不同数据源的数据; 2、where 子句基于指定的条件对记录行进行筛选; 3、group by 子句将数据划分为多个分组; 4、使用聚集函数进行计算;AVG() SUM() MAX() MIN() COUNT() 5、使用 havin…...

1panel可视化Docker面板安装与使用
官网地址1Panel - 现代化、开源的 Linux 服务器运维管理面板 文章目录 目录 文章目录 前言 一、环境准备 二、使用步骤 1.安装命令 2.一些命令 3.使用 总结 前言 一、环境准备 虚拟机centos 已经安装好docker和 Docker Compose 或者都没安装 1panel会帮你自动安装 二、使用…...

es6中的import导入模块 和 export导出模块
es6中的import导入模块 和 export导出模块 一、定义二、使用1.默认导出导入2..命名导出导入3.命名导出(Named Export)与默认导出(Default Export)结合使用 三、总结 一、定义 功能:用于导入和导出模块的内容。 静态加载…...
)
WordPress插件开发教程手册 — 钩子(Hooks)
钩子是用一段代码添加/修改另外一段代码的方式,是 WordPress插件和主题与 WordPress 内核交互的基础,钩子在 WordPress 内核中也被广泛使用。WordPress 中有两种钩子,Action 和 Filter。使用钩子时,我们需要先编写一个自定义函数作…...

Python开发运维:Celery连接Redis
目录 一、理论 1.Celery 二、实验 1.Windows11安装Redis 2.Python3.8环境中配置Celery 3.celery的多目录结构异步执行 4.celery简单结构下的定时任务 三、问题 1.Celery命令报错 2.执行Celery命令报错 3.Win11启动Celery报ValueErro错误 4.Pycharm 无法 import 同目…...
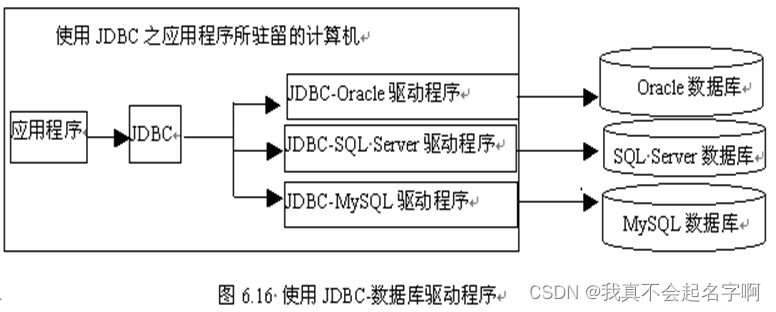
JSP:JDBC
JDBC(Java Data Base Connectivity的缩写)是Java程序操作数据库的API,也是Java程序与数据库相交互的一门技术。 JDBC是Java操作数据库的规范,由一组用Java语言编写的类和接口组成,它对数据库的操作提供基本方法&#…...

能否在一台电脑上安全地登录多个Facebook账号?
Facebook是一个流量大、用户多的平台,许多人可能需要在一台设备上管理多个Facebook账号,无论是出于个人或职业需求,都能带来极大地便利。然而,保持每个账号的安全性和隐私性却是一个挑战。本文将介绍如何在一台电脑上安全地登录多…...
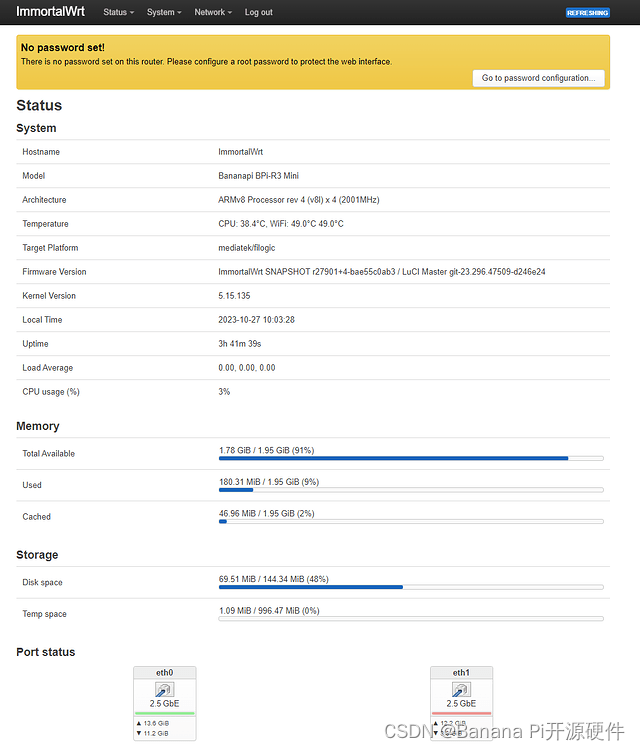
Banana Pi [BPi-R3-Mini] 回顾和主线 ImmortalWrt 固件支持
BananaPi BPi-R3 Mini 采用 MediaTek 830(4 个 A53,最高 2.0 GHz),具有 2 个 2.5 GbE、AX4200 2.4G/5G 无线和 USB 2.0 端口。它还具有两个 M.2 连接器,可用于 NVMe SSD 和 5G 模块(板上包含 Nano SIM 插槽…...
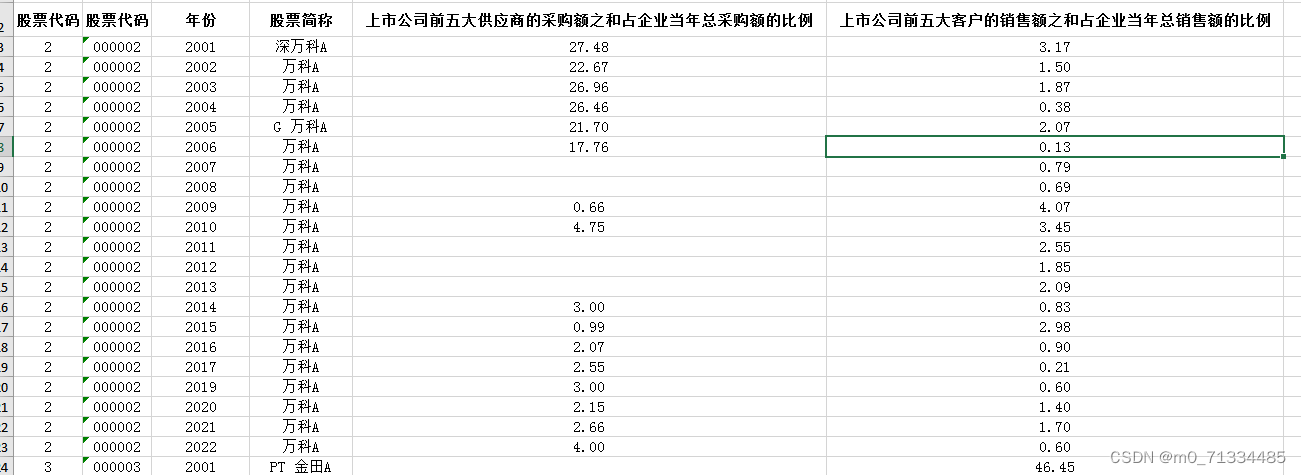
2001-2022年上市公-供应链话语权测算数据(原始数据+处理代码Stata do文档+结果)
2001-2022年上市公-供应链话语权测算数据(原始数据处理代码Stata do文档结果) 1、时间:2001-2022年 2、指标:企业代码、股票代码、年份、股票简称、上市公司前五大供应商的采购额之和占企业当年总采购额的比例、上市公司前五大客…...

如何通过ShardingJDBC进行读写分离
背景信息: 面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库。其中主库负责处理事务性的增删改操作,从库负责处理查询操作&#…...

【uniapp】部分图标点击事件无反应
比如:点击这个图标在h5都正常,在小程序上无反应 css:也设置z-index,padding 页面上也试过click.native.stop.prevent"changePassword()" 时而可以时而不行, 最后发现是手机里输入键盘的原因,输…...
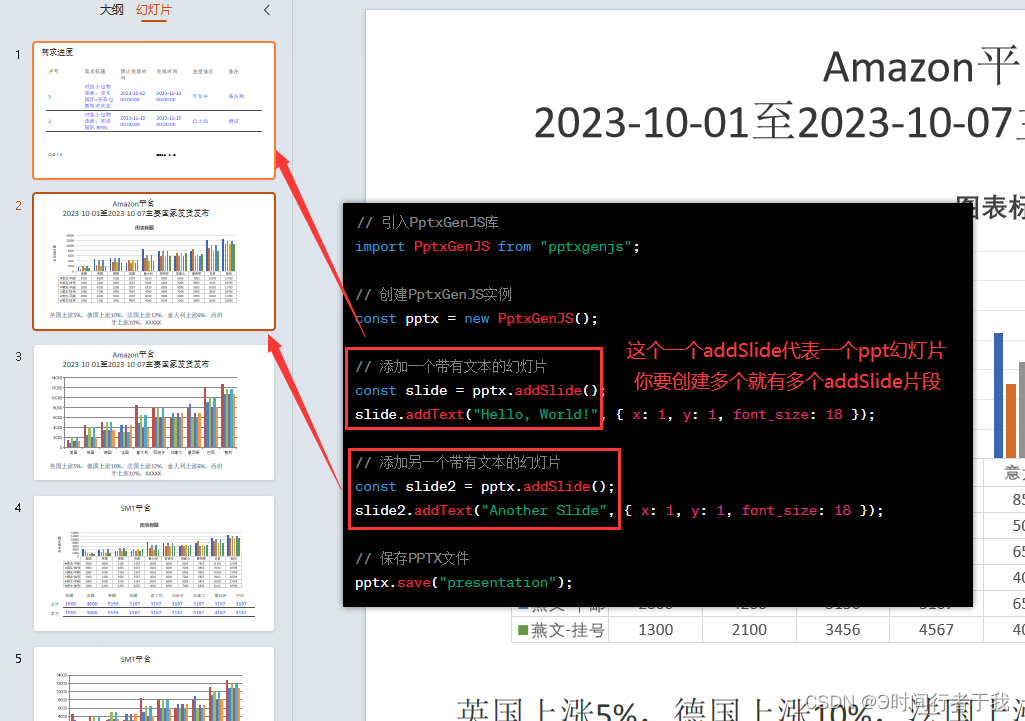
前端vue导出PPT,使用pptxgen.js
前言 公司新需求需要导出ppt给业务用,查阅资料后发现也挺简单的,记录一下。 如有不懂的可以留言!!! 1.安装包 npm install pptxgenjs --save2.引入包 在需要使用的文件中引入 import Pptxgenfrom "pptxgenjs&…...
JSP过滤器和监听器
什么是过滤器 Servlet过滤器与Servlet十分相似,但它具有拦截客户端(浏览器)请求的功能,Servlet过滤器可以改变请求中的内容,来满足实际开发中的需要。 对于程序开发人员而言,过滤器实质就是在Web应用服务…...
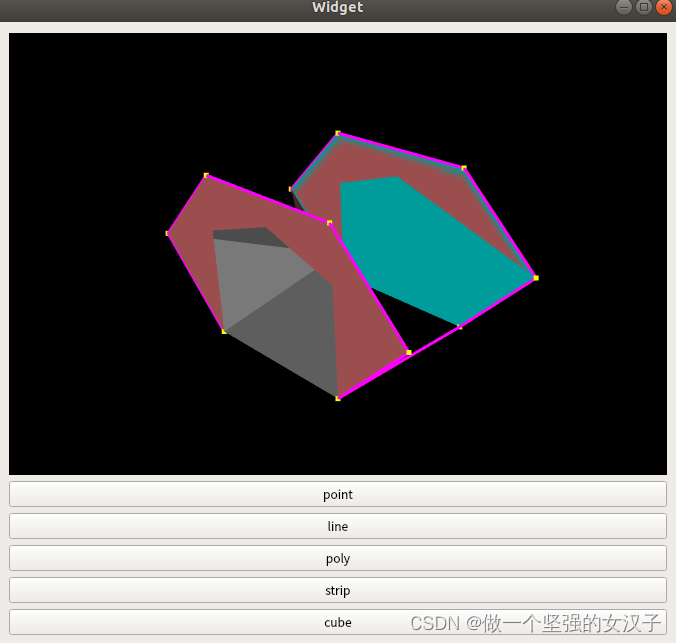
pcl+vtk(十二)使用vtkPolyData创建点、线、面(不规则面)、三角带
一、前言 vtkPlaneSource创建平面,只可以创建平行四边形的平面,根据一个起点和两个终点创建法向量创建平面。但是当有创建多个点围成不规则平面的需求时,该怎么创建显示呢? 在网上查了资料,可以使用vtkPolyData拓扑结…...
51单片机的智能浇花系统【含proteus仿真+程序+报告+原理图】
1、主要功能 该系统由AT89C51单片机LCD1602显示模块DHT11温湿度模块DS1302时间模块继电器驱动水泵模块光敏传感器等模块构成。适用于智能浇花、自动浇花、智能盆栽等相似项目。 可实现基本功能: 1、LCD1602实时显示北京时间、土壤温湿度、光照强度等信息 2、DHT11采集温湿度信…...

为什么 MQTT 对于构建联网汽车至关重要
汽车行业正在接受构建联网汽车的想法。他们看到了利用车辆遥测数据创造新收入机会并打造更好用户体验的机会。然而,实施可扩展以支持数百万辆汽车的联网汽车服务可能会带来一些挑战。 对于大多数联网汽车服务,汽车和云之间需要进行双向通信。汽车将遥测…...

CSIT883系统分析与项目管理——Lecture2重点概念
一、前言 这个是本人的学习笔记,如果大家喜欢可以多多关注吧! 二、重点概念 1.项目经理及其团队必须认识到任何项目对整个系统或组织的利益和需求的影响,而不是关注项目的直接问题。 2.系统愿景文件的目的是什么? 系统愿景文档是描述问题、解决方案、系统目标等的简短声…...
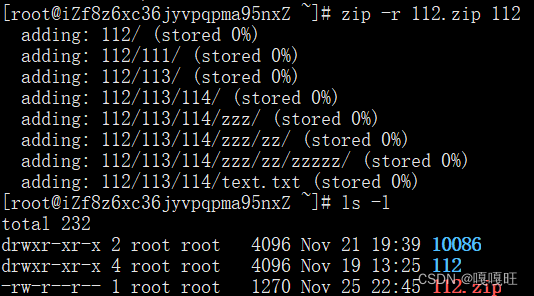
【linux】基本指令(中篇)
echo指令 将引号内容打印到显示屏上 输出的重定向 追加的重定向 输出的重定向 我们学习c语言的时候当以写的方式创建一个文件,就会覆盖掉该文件之前的内容 当我们以追加的方式打开文件的时候,原文件内容不会被覆盖而是追加 more指令 10.more指令…...

Centos Download
前言 CentOS Linux 是一个社区支持的发行版,源自 CentOS git for Red Hat Enterprise Linux (RHEL) 上免费提供给公众的源代码。因此,CentOS Linux 的目标是在功能上与 RHEL 兼容。CentOS 计划主要更改组件以删除上游供应商的品牌…...
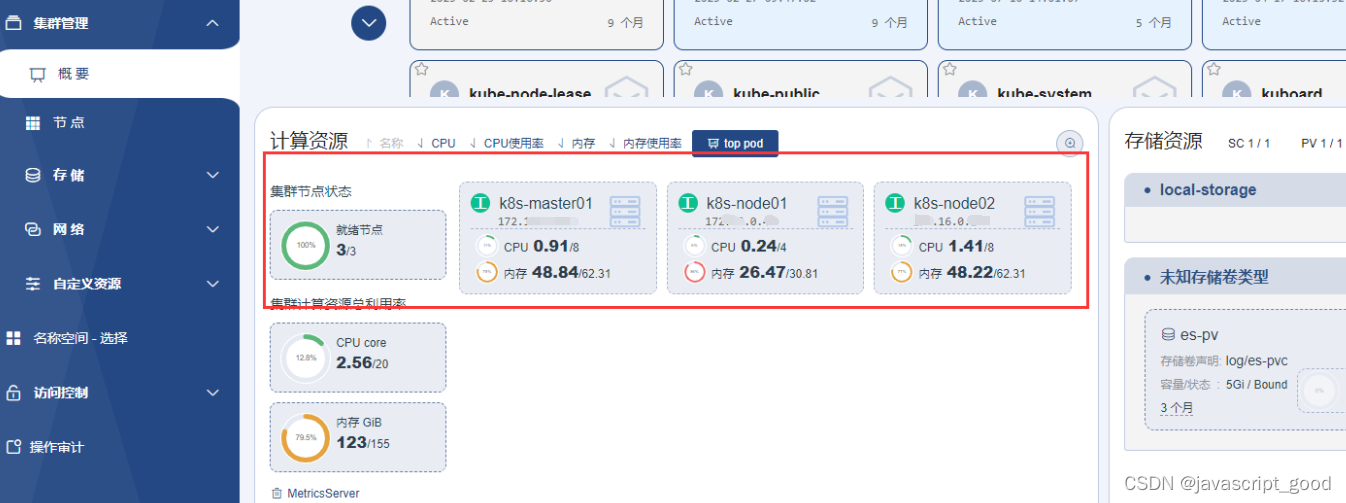
k8s集群资源监控工具metrics-server安装
1、下载镜像 docker pull swr.cn-east-2.myhuaweicloud.com/kuboard-dependency/metrics-server:v0.6.22、在任一一个主节点上创建角色,执行下面语句 kubectl create clusterrolebinding kube-proxy-cluster-admin --clusterrolecluster-admin --usersystem:kube-…...

Python篇---# -*- coding: utf-8 -*- 声明
简单来说,# -*- coding: utf-8 -*- 这行声明的作用,就是告诉Python解释器:“这个.py文件是用UTF-8编码保存的,请按这个规则来读取它。”关于Windows和Linux下的差异,最核心的原因在于Python 2与Python 3的默认编码不同…...

C++的std--ranges视图适配器组合与函数组合在表达力上的相似性
C20引入的std::ranges库彻底改变了序列操作的范式,其中视图适配器的链式组合与函数式编程中的函数组合展现出惊人的相似性。这种设计哲学上的共鸣,让开发者能够以声明式风格构建高效的数据处理管道。本文将从三个关键角度探讨两者在表达力上的异曲同工之…...

中小公司预算有限,如何按IPDRR框架一步步搭建安全防线?从免费工具到开源方案实战指南
中小企业零成本安全建设指南:基于IPDRR框架的实战路线图 当安全预算不足六位数时,如何用开源工具构建企业级防御体系?这可能是每位中小企业技术负责人最头疼的问题。我们曾为一家30人规模的电商公司做过安全评估——他们年营收近千万…...

别再只用默认字体了!Windows C/C++程序员必知的CONSOLE_FONT_INFOEX结构体详解与避坑指南
Windows控制台字体定制:CONSOLE_FONT_INFOEX深度解析与实战技巧 在开发需要特殊显示效果的控制台应用时,默认的字体配置往往难以满足需求。想象一下这样的场景:你的日志系统需要高亮关键信息,或者你的命令行工具需要支持多语言字符…...

Switch第三方手柄终极指南:如何让Xbox和PS手柄在Switch上即插即用
Switch第三方手柄终极指南:如何让Xbox和PS手柄在Switch上即插即用 【免费下载链接】sys-con Nintendo Switch sysmodule that allows support for third-party controllers 项目地址: https://gitcode.com/gh_mirrors/sy/sys-con 还在为Switch Pro手柄的价格…...

从选型到调试:恩智浦NXP单片机开发环境CodeWarrior实战指南
1. 认识恩智浦NXP单片机家族 第一次接触恩智浦NXP单片机时,我完全被它庞大的产品线搞晕了。作为全球第二大MCU供应商,NXP的产品覆盖从8位到32位,从汽车电子到工业控制各个领域。特别是2015年收购飞思卡尔后,产品线更加丰富。这里我…...

从CH344Q出发:打造高性能USB转4路TTL串口模块的设计实践
1. CH344Q芯片选型与核心优势 第一次接触CH344Q这颗芯片是在去年做一个工业数据采集项目的时候。当时需要同时连接4个不同波特率的传感器设备,市面上常见的USB转串口模块要么速度跟不上,要么稳定性堪忧。折腾了好几款方案后,同事推荐了沁恒的…...

别再为Standard Assets报错头疼了!Unity 2022导入官方资源包的完整避坑流程
Unity 2022导入Standard Assets终极指南:从报错修复到高效工作流 当你兴奋地打开Unity 2022准备使用Standard Assets加速开发时,迎面而来的却是一堆红色报错——GUITexture已废弃、MovieTexture不可用...这些官方资源包为何在新版本中变得"支离破碎…...

2026实测:物理级AI消痕神器!别再让你的网文被判“文本高熵”了
搞了两个小时,终于把这个坑填上了。 说实话,2026年了,如果你还在用那种“机里机气”的初级AI写小说,那真的是在“退婚流”的边缘反复横跳。 现在的审核平台可不傻,RAG和各种检测算法早就进化到了物理级。 你的稿子发上…...

AI编程革命:Codex自动化脚本实战指南
技术文章大纲:告别重复造轮子——Codex写脚本的高效实践核心主题通过OpenAI Codex等AI编程工具自动化生成脚本,减少重复开发工作,提升效率。理解Codex的能力与限制Codex是基于GPT-3的代码生成模型,擅长根据自然语言描述生成Python…...