Hive中常出现的错误(不定时更新)
1.加载数据失败
hive> load data local inpath '/home/user/hive.txt' into table studentl> ;
FAILED: SemanticException [Error 10001]: Line 1:56 Table not found 'studentl'
hive> load data local inpath '/home/user/hive.txt' into table student;
Loading data to table default.student
Failed with exception Unable to move source file:/home/user/hive.txt to destination hdfs://com.qiyu02:8020/user/hive/warehouse/student/hive.txt
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask在hive日志发现
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hive/warehouse/student/hive.txt could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and no node(s) are excluded in this operation.at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget(BlockManager.java:1503)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3124)at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:636)at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.addBlock(AuthorizationProviderProxyClientProtocol.java:188)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:476)at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:587)at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1026)at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007)at org.apache.hadoop.ipc.Client.call(Client.java:1411)at org.apache.hadoop.ipc.Client.call(Client.java:1364)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)at com.sun.proxy.$Proxy19.addBlock(Unknown Source)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:391)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccesThere are 1 datanode(s) running and no node(s) are excluded in this operation.at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget(BlockManager.java:1503)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3124)at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:636)at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.addBlock(AuthorizationProviderProxyClientProtocol.java:188)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:476)at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:587)at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1026)at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007)at org.apache.hadoop.ipc.Client.call(Client.java:1411)at org.apache.hadoop.ipc.Client.call(Client.java:1364)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)at com.sun.proxy.$Proxy19.addBlock(Unknown Source)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:391)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAcces<span style="color:#ff0000">There are 1 datanode(s) running and no node(s) are excluded in this operation.</span>
大概是datanode(s) 挂掉了 ,敲下jps验证一下,果真如此,不得不重启一下hadoop进程了
2.Hive中运行Mapredurce程序时:
错误:
Ended Job = job_1504575362948_0022 with errors Error during job, obtaining debugging information...
hive (person)> select password from user1; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1504575362948_0022, Tracking URL = http://com.qiyu02:8088/proxy/application_1504575362948_0022/ Kill Command = /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/hadoop job -kill job_1504575362948_0022 Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0 2017-09-05 11:44:53,804 Stage-1 map = 0%, reduce = 0% Ended Job = job_1504575362948_0022 with errors Error during job, obtaining debugging information... FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask MapReduce Jobs Launched: Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL Total MapReduce CPU Time Spent: 0 msec
网上说法一大堆!说什么内存不够啊、ResourceManger没成功启动啊....等等全试了一遍,还是没解决。。。后来猜测可能是内核的原因,改下内核,重新启动就好了
3. hive on tez ,yarn 任务一直都running 状态。
修改 tez :默认 tez.session.am.dag.submit.timeout.secs=600
改成 0
修改 hive : tez.session.am.dag.submit.timeout.secs = xxxx
改成 0
资源有限的话 改成 0,越早释放资源越好
相关文章:
)
Hive中常出现的错误(不定时更新)
1.加载数据失败 hive> load data local inpath /home/user/hive.txt into table studentl> ; FAILED: SemanticException [Error 10001]: Line 1:56 Table not found studentl hive> load data local inpath /home/user/hive.txt into table student; Loading data to…...

c++ 重写 多态
1 重写(继承后(拼接基类后)) 1.1 非虚函数 同名成员函数 (各自有一个xFunction() 内存 ) #include <iostream> #include <String> class BaseClass { public:void xFunction() {std::cout << "BaseClass::xFunction()\n"; } };class Subclass1 …...
用户名称(user.name)和邮箱(user.email))
Git如何修改提交(commit)用户名称(user.name)和邮箱(user.email)
Git用户名 Git查看用户名 git config user.name修改Git提交用户名 修改全局Git用户名 git config --global user.name "xx" 修改当前服务/项目Git用户名 git config user.name "xx"如果出现以下错误,解决方案如下: 错误案例&am…...
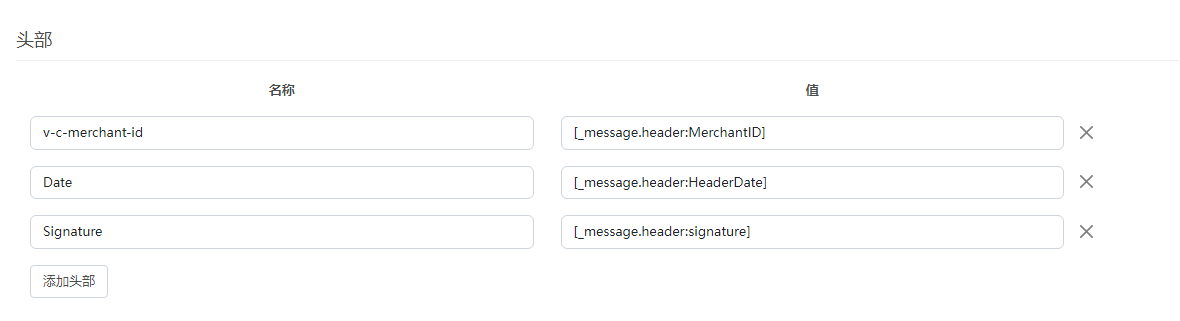
知行之桥EDI系统HTTP签名验证
本文简要概述如何在知行之桥EDI系统中使用 HTTP 签名身份验证,并将使用 CyberSource 作为该集成的示例。 API 概述 首字母缩略词 API 代表“应用程序编程接口”。这听起来可能很复杂,但真正归结为 API 是一种允许两个不同实体相互通信的软件。自开发以…...
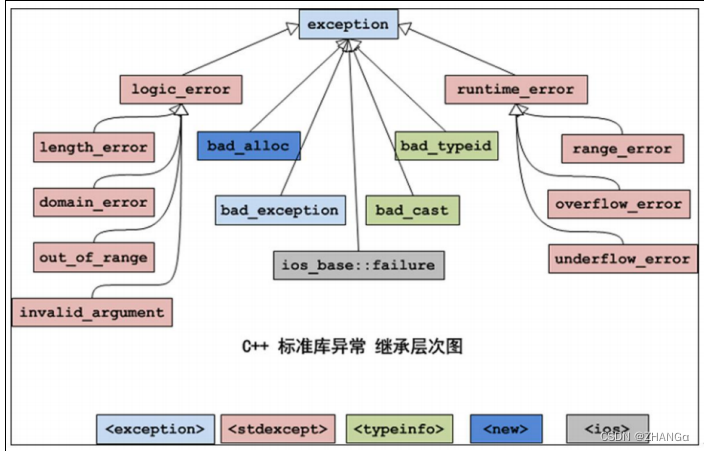
C++ DAY08 异常
概念 异常事件(如:除 0 溢出,数组下标越界,所要读取的文件不存在 , 空指针,内存不足 等等) 在 C 语言对错误的处理是两种方法: 一是使用整型的返回值标识错误; 二是使用 errn…...

vscode导入STM32CubeIDE工程文件夹未定义警告清除方法
0 前言 在我们使用vscode去编辑STM32CubeIDE的工程文件时,经常会出现一些类型未定义、头文件路径无效的问题,无法正常使用且非常影响观感。本文介绍如何设置vscode导入的STM32CubeIDE配置文件,解决这一问题。 1 vscode导入STM32CubeIDE工程…...
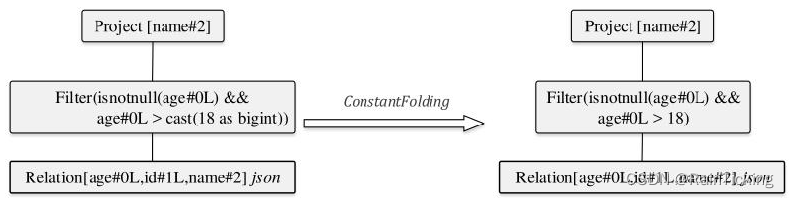
SparkSQL之Optimized LogicalPlan生成过程
经过Analyzer的处理,Unresolved LogicalPlan已经解析成为Analyzed LogicalPlan。Analyzed LogicalPlan中自底向上节点分别对应Relation、Subquery、Filter和Project算子。 Analyzed LogicalPlan基本上是根据Unresolved LogicalPlan一对一转换过来的,…...
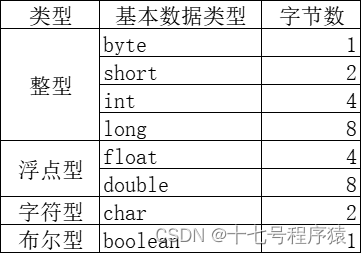
Java中有几种基本数据类型以及转换方式【Java面经(1)】
问:Java中有几种基本数据类型呢?以及它们之间的转换方式。详细介绍下 总共有8种基本数据类型 byte 、short 、long 、float 、double 、boolean 、char 详细类型以及字节数: 基本数据类型的转换方式 自动类型转换:小–>大 byt…...

JVM虚拟机:JVM调优第一步,了解JVM常用命令行参数
本文重点 从本文课程开始,我们将用几篇文章来介绍JVM中常用的命令行的参数,这个非常重要,第一我们可以通过参数了解JVM的配置,第二我们可以通过参数完成对JVM的调参。以及后面的JVM的调优也需要用到这些参数,所以我们…...

CSS特效019:图标图片悬浮旋转一周
CSS常用示例100专栏目录 本专栏记录的是经常使用的CSS示例与技巧,主要包含CSS布局,CSS特效,CSS花边信息三部分内容。其中CSS布局主要是列出一些常用的CSS布局信息点,CSS特效主要是一些动画示例,CSS花边是描述了一些CSS…...

requests请求django接口跨域问题处理
参考: https://zhuanlan.zhihu.com/p/416978320 https://blog.csdn.net/SweetHeartHuaZai/article/details/130983179 使用httpx代替requests import httpxheaders {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.3…...

#Js篇:Promise
定义 Promise是异步操作解决方案,为异步操作提供统一接口。 Promise英文意思是“承诺”,表示其他手段无法改变。 返回 所有异步任务都返回一个Promise实例。 Promise实例有一个then方法,用于指定下一步的回调函数。 状态 异步操作未完…...
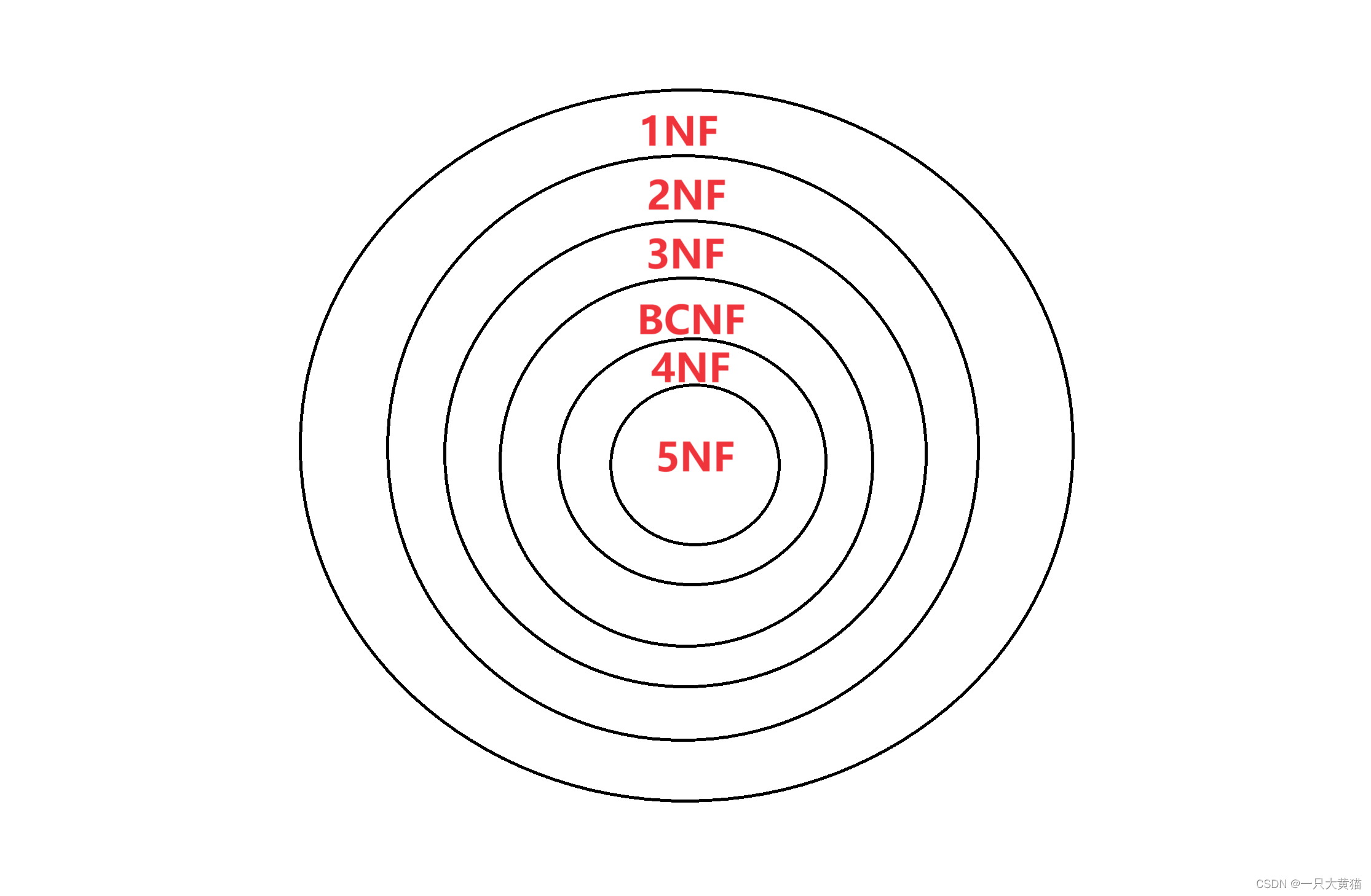
【数据库篇】关系模式的表示——(2)规范化
范式:范式是符合某一种级别的关系模式的集合 规范化:是指一个低一级的范式的关系模式,通过模式的分解转换为若干个高一级范式的关系模式的集合。 1NF 每个分量必须是不可分开的数据项,满足这个条件的关系模式就是1NF。 2NF 若…...

【C++那些事儿】类与对象(3)
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,我之前看过一套书叫做《明朝那些事儿》,把本来枯燥的历史讲的生动有趣。而C作为一门接近底层的语言,无疑是抽象且难度颇…...

spark的算子
spark的算子 1.spark的单Value算子 Spark中的单Value算子是指对一个RDD中的每个元素进行操作,并返回一个新的RDD。下面详细介绍一些常用的单Value算子及其功能: map:逐条映射,将RDD中的每个元素通过指定的函数转换成另一个值&am…...

【科技素养】蓝桥杯STEMA 科技素养组模拟练习试卷7
1、一袋小球中有15个白球,3个红球和2个黑球。在随机从袋子中拿出至少()个小球后,才可以保证至少拿出了5个白球 A、5 B、10 C、8 D、15 答案:B 2、以下选项中,数值最接近十进制数114的是( &…...
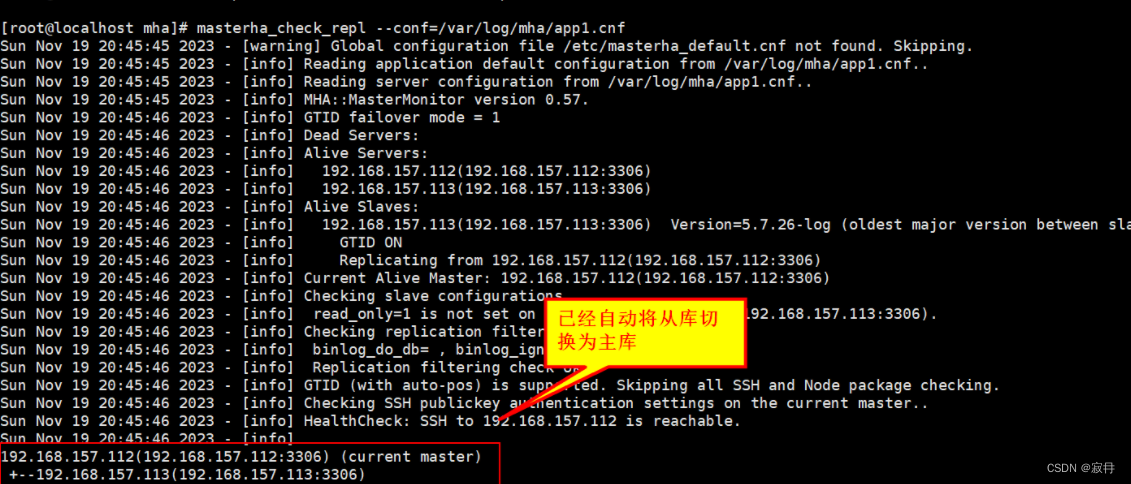
MySQL MHA高可用架构搭建
快捷查看指令 ctrlf 进行搜索会直接定位到需要的知识点和命令讲解(如有不正确的地方欢迎各位小伙伴在评论区提意见,博主会及时修改) MySQL MHA高可用架构搭建 MHA(Master HA)是一款开源的 MySQL 的高可用程序…...

UE小计:顶部工具栏按钮添加下拉列表,大纲列表、资源管理窗口右键添加按键
下拉列表 void FYouPluginsModule::StartupModule() {FYouToolStyle::Initialize();FYouToolStyle::ReloadTextures();FYouToolCommands::Register();PluginCommands MakeShareable(new FUICommandList);PluginCommands->MapAction(FYouToolCommands::Get().PackByCloudAc…...
git stash 用法总结
目录 1,介绍场景1:场景2: 2,常用命令2.1,基础2.2,进阶1,存储时指定备注2,通过索引来操作指定的存储3,修改存储规则 2.3,查看 stash 修改的具体内容 1…...
Linux操作系统之apt常用命令记录
文章目录 apt 命令apt 语法apt 常用命令列出所有可更新的软件清单命令升级软件包列出可更新的软件包及版本信息升级软件包,升级前先删除需要更新软件包安装指定的软件命令:安装多个软件包:更新指定的软件命令显示软件包具体信息,例如…...

多模态实时处理能力不是“算得快”,而是“判得准、切得稳、传得省”——详解动态分辨率感知+语义优先Token丢弃算法
第一章:多模态大模型实时处理能力 2026奇点智能技术大会(https://ml-summit.org) 多模态大模型的实时处理能力正成为边缘AI与工业智能落地的关键瓶颈。它不仅要求模型在毫秒级延迟下完成跨模态对齐(如视觉-语音-文本联合推理),还…...

Dify 社区版本地部署实战:从零到一的Docker Compose避坑指南
1. 为什么选择Docker Compose部署Dify社区版 第一次接触Dify社区版时,我被它"开箱即用"的特性吸引。作为一个长期在AI应用开发领域摸爬滚打的开发者,我深知搭建一个完整的LLM应用开发生态需要多少工作量。Dify把模型接入、Prompt工程、RAG流程…...

BCI Competition IV 2a数据集深度解析:除了读取.gdf,你更该关注这些实验设计与数据细节
BCI Competition IV 2a数据集深度解析:实验设计、数据质量与预处理实战指南 当你第一次打开BCI Competition IV 2a数据集的.gdf文件时,可能会被25个通道、数千个采样点和复杂的事件标记弄得晕头转向。这个数据集远不止是22个EEG通道加上3个EOG通道那么简…...

【ROS2实战笔记-3】RViz2图形底层与调试暗坑
RViz2是ROS2生态中使用频率最高的工具之一,每天都有大量开发者打开它、添加Display、调整视角,然后开始调试算法。但很少有人真正关心它的图形架构、渲染瓶颈,以及那些隐藏在配置文件里的行为逻辑。这篇文章不打算讲怎么添加一个Image Displa…...

告别字幕烦恼:B站CC字幕下载转换终极指南
告别字幕烦恼:B站CC字幕下载转换终极指南 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而苦恼吗?想要将精彩的…...
约束)
Mysql(8)约束
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录约束约束的作用约束的类型表级约束和列级约束约束和索引非空约束指定非空约束删除非空约束示例唯一性约束指定唯一键约束复合唯一查看唯一键约束删除唯一键约束主键约…...
的三种接入方式与安全机制)
从家庭WiFi到5G语音:手把手拆解VoWiFi(WiFi通话)的三种接入方式与安全机制
从家庭WiFi到5G语音:手把手拆解VoWiFi(WiFi通话)的三种接入方式与安全机制 走进一家咖啡厅,手机自动连上公共WiFi的瞬间,你是否想过——此刻拨出的电话可能正通过WiFi信号穿越半个城市,最终以运营商级的安…...

解放双手:3分钟打造你的Windows本地语音识别助手
解放双手:3分钟打造你的Windows本地语音识别助手 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录手忙脚乱?还在为视频字幕制作烦恼?今天我要向你介绍TMSpeech——一…...

测 LWDM 滤光片的光源怎么选?优峰技术专业方案满足高精度测试需求
在光通信高速迭代的背景下,LWDM滤光片作为中高速光模块的核心器件,其透射率、中心波长、隔离度等参数测试至关重要,而测LWDM滤光片的光源直接决定测试精度与效率。深圳优峰技术深耕光通信测试领域多年,针对LWDM滤光片测试场景打造…...

终极Visual C++运行库解决方案:VisualCppRedist AIO一键修复Windows软件兼容性问题
终极Visual C运行库解决方案:VisualCppRedist AIO一键修复Windows软件兼容性问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在安装新…...