04 _ 系统设计目标(二):系统怎样做到高可用?
这里将探讨高并发系统设计的第二个目标——高可用性。
高可用性(High Availability,HA)是你在系统设计时经常会听到的一个名词,它指的是系统具备较高的无故障运行的能力。
我们在很多开源组件的文档中看到的HA方案就是提升组件可用性,让系统免于宕机无法服务的方案。比如,你知道Hadoop 1.0中的NameNode是单点的,一旦发生故障则整个集群就会不可用;而在Hadoop2中提出的NameNode HA方案就是同时启动两个NameNode,一个处于Active状态,另一个处于Standby状态,两者共享存储,一旦Active NameNode发生故障,则可以将Standby NameNode切换成Active状态继续提供服务,这样就增强了Hadoop的持续无故障运行的能力,也就是提升了它的可用性。
通常来讲,一个高并发大流量的系统,系统出现故障比系统性能低更损伤用户的使用体验。想象一下,一个日活用户过百万的系统,一分钟的故障可能会影响到上千的用户。而且随着系统日活的增加,一分钟的故障时间影响到的用户数也随之增加,系统对于可用性的要求也会更高。所以今天,我就带你了解一下在高并发下,我们如何来保证系统的高可用性,以便给你的系统设计提供一些思路。
可用性的度量
可用性是一个抽象的概念,你需要知道要如何来度量它,与之相关的概念是:MTBF和MTTR。
MTBF(Mean Time Between Failure)是平均故障间隔的意思,代表两次故障的间隔时间,也就是系统正常运转的平均时间。这个时间越长,系统稳定性越高。
MTTR(Mean Time To Repair)表示故障的平均恢复时间,也可以理解为平均故障时间。这个值越小,故障对于用户的影响越小。
可用性与MTBF和MTTR的值息息相关,我们可以用下面的公式表示它们之间的关系:
Availability = MTBF / (MTBF + MTTR)
这个公式计算出的结果是一个比例,而这个比例代表着系统的可用性。一般来说,我们会使用几个九来描述系统的可用性。
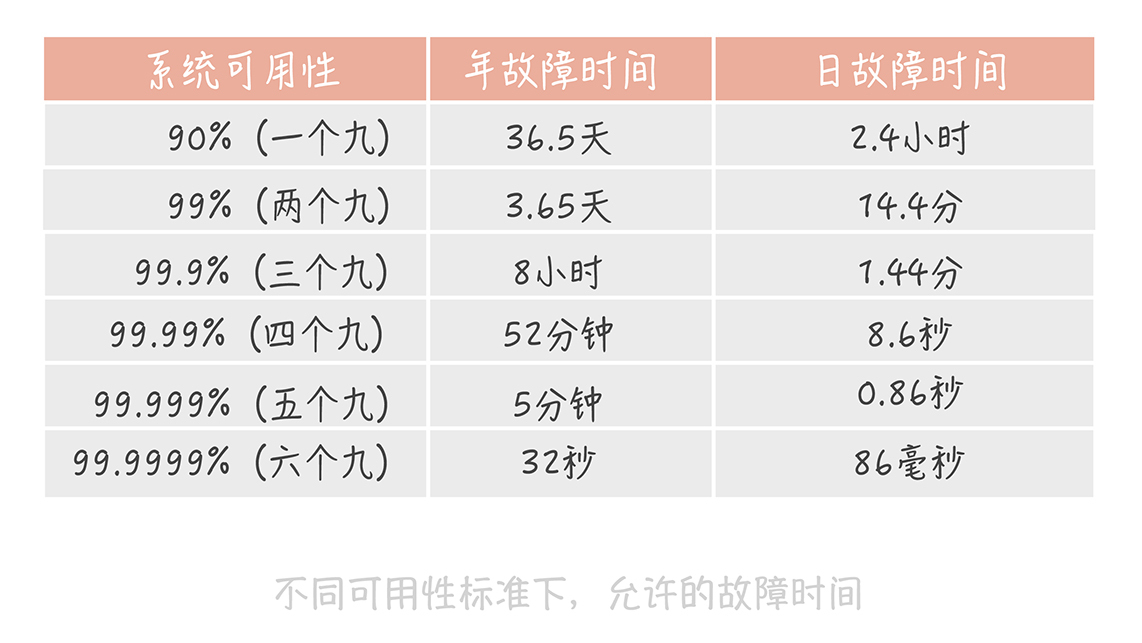
其实通过这张图你可以发现,一个九和两个九的可用性是很容易达到的,只要没有蓝翔技校的铲车搞破坏,基本上可以通过人肉运维的方式实现。
三个九之后,系统的年故障时间从3天锐减到8小时。到了四个九之后,年故障时间缩减到1小时之内。在这个级别的可用性下,你可能需要建立完善的运维值班体系、故障处理流程和业务变更流程。你可能还需要在系统设计上有更多的考虑。比如,在开发中你要考虑,如果发生故障,是否不用人工介入就能自动恢复。当然了,在工具建设方面,你也需要多加完善,以便快速排查故障原因,让系统快速恢复。
到达五个九之后,故障就不能靠人力恢复了。想象一下,从故障发生到你接收报警,再到你打开电脑登录服务器处理问题,时间可能早就过了十分钟了。所以这个级别的可用性考察的是系统的容灾和自动恢复的能力,让机器来处理故障,才会让可用性指标提升一个档次。
一般来说,我们的核心业务系统的可用性,需要达到四个九,非核心系统的可用性最多容忍到三个九。在实际工作中,你可能听到过类似的说法,只是不同级别,不同业务场景的系统对于可用性要求是不一样的。
目前,你已经对可用性的评估指标有了一定程度的了解了,接下来,我们来看一看高可用的系统设计需要考虑哪些因素。
高可用系统设计的思路
一个成熟系统的可用性需要从系统设计和系统运维两方面来做保障,两者共同作用,缺一不可。那么如何从这两方面入手,解决系统高可用的问题呢?
1.系统设计
“Design for failure”是我们做高可用系统设计时秉持的第一原则。在承担百万QPS的高并发系统中,集群中机器的数量成百上千台,单机的故障是常态,几乎每一天都有发生故障的可能。
未雨绸缪才能决胜千里。我们在做系统设计的时候,要把发生故障作为一个重要的考虑点,预先考虑如何自动化地发现故障,发生故障之后要如何解决。当然了,除了要有未雨绸缪的思维之外,我们还需要掌握一些具体的优化方法,比如failover(故障转移)、超时控制以及降级和限流。
一般来说,发生failover的节点可能有两种情况:
1.是在完全对等的节点之间做failover。
2.是在不对等的节点之间,即系统中存在主节点也存在备节点。
在对等节点之间做failover相对来说简单些。在这类系统中所有节点都承担读写流量,并且节点中不保存状态,每个节点都可以作为另一个节点的镜像。在这种情况下,如果访问某一个节点失败,那么简单地随机访问另一个节点就好了。
举个例子,Nginx可以配置当某一个Tomcat出现大于500的请求的时候,重试请求另一个Tomcat节点,就像下面这样:
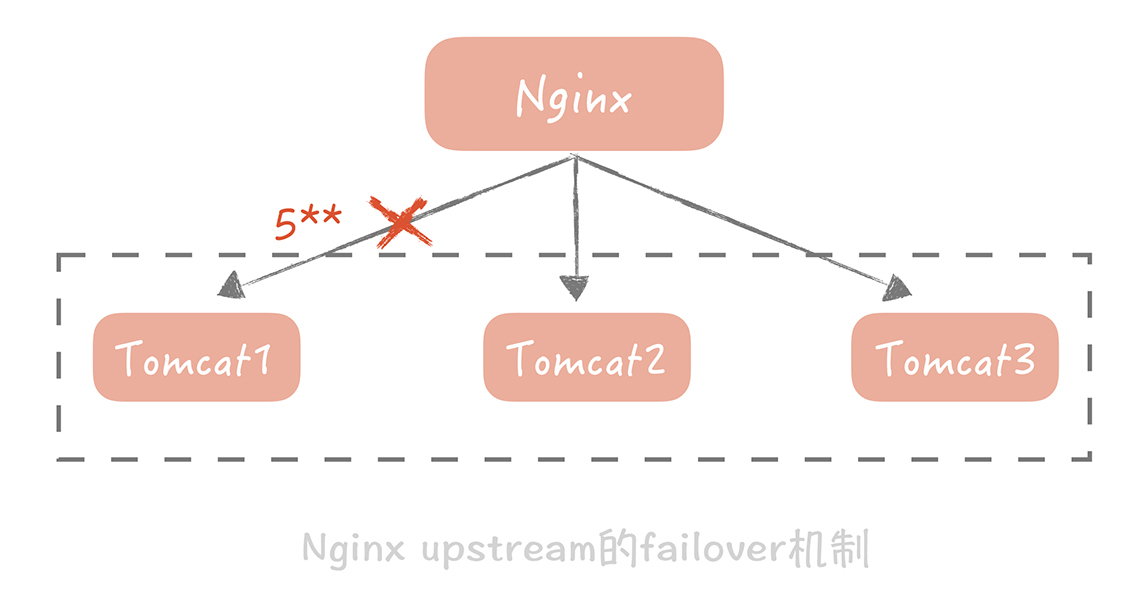
针对不对等节点的failover机制会复杂很多。比方说我们有一个主节点,有多台备用节点,这些备用节点可以是热备(同样在线提供服务的备用节点),也可以是冷备(只作为备份使用),那么我们就需要在代码中控制如何检测主备机器是否故障,以及如何做主备切换。
使用最广泛的故障检测机制是“心跳”。你可以在客户端上定期地向主节点发送心跳包,也可以从备份节点上定期发送心跳包。当一段时间内未收到心跳包,就可以认为主节点已经发生故障,可以触发选主的操作。
选主的结果需要在多个备份节点上达成一致,所以会使用某一种分布式一致性算法,比方说Paxos,Raft。
除了故障转移以外,对于系统间调用超时的控制也是高可用系统设计的一个重要考虑方面。
复杂的高并发系统通常会有很多的系统模块组成,同时也会依赖很多的组件和服务,比如说缓存组件,队列服务等等。它们之间的调用最怕的就是延迟而非失败,因为失败通常是瞬时的,可以通过重试的方式解决。而一旦调用某一个模块或者服务发生比较大的延迟,调用方就会阻塞在这次调用上,它已经占用的资源得不到释放。当存在大量这种阻塞请求时,调用方就会因为用尽资源而挂掉。
在系统开发的初期,超时控制通常不被重视,或者是没有方式来确定正确的超时时间。
我之前经历过一个项目,模块之间通过RPC框架来调用,超时时间是默认的30秒。平时系统运行得非常稳定,可是一旦遇到比较大的流量,RPC服务端出现一定数量慢请求的时候,RPC客户端线程就会大量阻塞在这些慢请求上长达30秒,造成RPC客户端用尽调用线程而挂掉。后面我们在故障复盘的时候发现这个问题后,调整了RPC,数据库,缓存以及调用第三方服务的超时时间,这样在出现慢请求的时候可以触发超时,就不会造成整体系统雪崩。
既然要做超时控制,那么我们怎么来确定超时时间呢?这是一个比较困难的问题。
超时时间短了,会造成大量的超时错误,对用户体验产生影响;超时时间长了,又起不到作用。我建议你通过收集系统之间的调用日志,统计比如说99%的响应时间是怎样的,然后依据这个时间来指定超时时间。如果没有调用的日志,那么你只能按照经验值来指定超时时间。不过,无论你使用哪种方式,超时时间都不是一成不变的,需要在后面的系统维护过程中不断地修改。
超时控制实际上就是不让请求一直保持,而是在经过一定时间之后让请求失败,释放资源给接下来的请求使用。这对于用户来说是有损的,但是却是必要的,因为它牺牲了少量的请求却保证了整体系统的可用性。而我们还有另外两种有损的方案能保证系统的高可用,它们就是降级和限流。
降级是为了保证核心服务的稳定而牺牲非核心服务的做法。比方说我们发一条微博会先经过反垃圾服务检测,检测内容是否是广告,通过后才会完成诸如写数据库等逻辑。
反垃圾的检测是一个相对比较重的操作,因为涉及到非常多的策略匹配,在日常流量下虽然会比较耗时却还能正常响应。但是当并发较高的情况下,它就有可能成为瓶颈,而且它也不是发布微博的主体流程,所以我们可以暂时关闭反垃圾服务检测,这样就可以保证主体的流程更加稳定。
限流完全是另外一种思路,它通过对并发的请求进行限速来保护系统。
比如对于Web应用,我限制单机只能处理每秒1000次的请求,超过的部分直接返回错误给客户端。虽然这种做法损害了用户的使用体验,但是它是在极端并发下的无奈之举,是短暂的行为,因此是可以接受的。
实际上,无论是降级还是限流,在细节上还有很多可供探讨的地方,我会在后面的课程中,随着系统的不断演进深入地剖析,在基础篇里就不多说了。
2.系统运维
在系统设计阶段为了保证系统的可用性可以采取上面的几种方法,那在系统运维的层面又能做哪些事情呢?其实,我们可以从灰度发布、故障演练两个方面来考虑如何提升系统的可用性。
你应该知道,在业务平稳运行过程中,系统是很少发生故障的,90%的故障是发生在上线变更阶段的。比方说,你上了一个新的功能,由于设计方案的问题,数据库的慢请求数翻了一倍,导致系统请求被拖慢而产生故障。
如果没有变更,数据库怎么会无缘无故地产生那么多的慢请求呢?因此,为了提升系统的可用性,重视变更管理尤为重要。而除了提供必要回滚方案,以便在出现问题时快速回滚恢复之外,另一个主要的手段就是灰度发布。
灰度发布指的是系统的变更不是一次性地推到线上的,而是按照一定比例逐步推进的。一般情况下,灰度发布是以机器维度进行的。比方说,我们先在10%的机器上进行变更,同时观察Dashboard上的系统性能指标以及错误日志。如果运行了一段时间之后系统指标比较平稳并且没有出现大量的错误日志,那么再推动全量变更。
灰度发布给了开发和运维同学绝佳的机会,让他们能在线上流量上观察变更带来的影响,是保证系统高可用的重要关卡。
灰度发布是在系统正常运行条件下,保证系统高可用的运维手段,那么我们如何知道发生故障时系统的表现呢?这里就要依靠另外一个手段:故障演练。
故障演练指的是对系统进行一些破坏性的手段,观察在出现局部故障时,整体的系统表现是怎样的,从而发现系统中存在的,潜在的可用性问题。
一个复杂的高并发系统依赖了太多的组件,比方说磁盘,数据库,网卡等,这些组件随时随地都可能会发生故障,而一旦它们发生故障,会不会如蝴蝶效应一般造成整体服务不可用呢?我们并不知道,因此,故障演练尤为重要。
在我来看,故障演练和时下比较流行的“混沌工程”的思路如出一辙,作为混沌工程的鼻祖,Netfix在2010年推出的“Chaos Monkey”工具就是故障演练绝佳的工具。它通过在线上系统上随机地关闭线上节点来模拟故障,让工程师可以了解,在出现此类故障时会有什么样的影响。
当然,这一切是以你的系统可以抵御一些异常情况为前提的。如果你的系统还没有做到这一点,那么我建议你另外搭建一套和线上部署结构一模一样的线下系统,然后在这套系统上做故障演练,从而避免对生产系统造成影响。
小结
说了这么多,你可以看到从开发和运维角度上来看,提升可用性的方法是不同的:
-
开发注重的是如何处理故障,关键词是冗余和取舍。冗余指的是有备用节点,集群来顶替出故障的服务,比如文中提到的故障转移,还有多活架构等等;取舍指的是丢卒保车,保障主体服务的安全。
-
从运维角度来看则更偏保守,注重的是如何避免故障的发生,比如更关注变更管理以及如何做故障的演练。
两者结合起来才能组成一套完善的高可用体系。
还需要注意的是,提高系统的可用性有时候是以牺牲用户体验或者是牺牲系统性能为前提的,也需要大量人力来建设相应的系统,完善机制。所以我们要把握一个度,不该做过度的优化。就像我在文中提到的,核心系统四个九的可用性已经可以满足需求,就没有必要一味地追求五个九甚至六个九的可用性。
另外,一般的系统或者组件都是追求极致的性能的,那么有没有不追求性能,只追求极致的可用性的呢?答案是有的。比如配置下发的系统,它只需要在其它系统启动时提供一份配置即可,所以秒级返回也可,十秒钟也OK,无非就是增加了其它系统的启动时间而已。但是,它对可用性的要求是极高的,甚至会到六个九,原因是配置可以获取的慢,但是不能获取不到。我给你举这个例子是想让你了解,可用性和性能有时候是需要做取舍的,但如何取舍就要视不同的系统而定,不能一概而论了。
相关文章:
04 _ 系统设计目标(二):系统怎样做到高可用?
这里将探讨高并发系统设计的第二个目标——高可用性。 高可用性(High Availability,HA)是你在系统设计时经常会听到的一个名词,它指的是系统具备较高的无故障运行的能力。 我们在很多开源组件的文档中看到的HA方案就是提升组件可…...
Android相机性能提高50%
文章目录 应用举例(可以不看这一part,直接跳过看具体怎么做):Snapchat 通过 Camera2 Extensions API 将新相机功能的集成速度提高了 50%**Camera2 扩展 API 可以访问高级功能更多设备上的更多机会 正文:开始使用扩展架…...
STM32F103C8T6第5天:独立看门狗、窗口看门狗、dma实验
1. 独立看门狗IWDG介绍(341.45) 什么是看门狗? 在由单片机构成的微型计算机系统中,由于单片机的工作常常会受到来自外界电磁场的干扰,造成程序的跑飞,而陷入死循环,程序的正常运行被打断&#…...
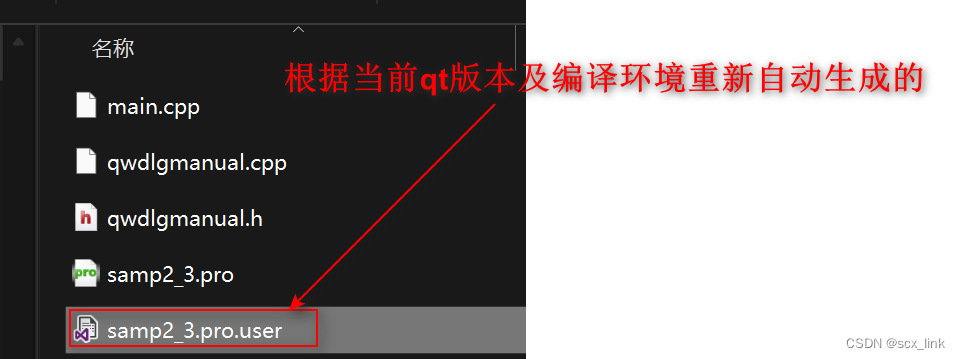
QT已有项目导入工程时注意事项
文章目录 从qt其他版本上开发的工程导入另一qt版本时 从qt其他版本上开发的工程导入另一qt版本时 这里以之前在qt5.12.2上开发的项目为例,现在到在qt6.5.3上运行。 不能直接导入IDE上,否则会报各种莫名奇妙的错误。 首先要把扩展名位.pro.user文件 删掉…...

Django视图层
一、请求与响应 视图函数 视图函数,简称视图,属于Django的视图层,默认定义在views.py文件中,是用来处理web请求信息以及返回响应信息的函数,所以研究视图函数只需熟练掌握两个对象即可:请求对象(HttpRequ…...
我在electron中集成了自己的ai大模型
同学们可以私信我加入学习群! 正文开始 前言一、大模型选择二、获取key三、调用api四、调用ai模型api时,解决跨域总结 前言 最近单位把gpt、文心一言、通义千问、星火等等等等你能想到的ai大模型都给禁掉了,简直丧心病狂。 不知道有多少感同…...

oracle rac环境归档日志清除
文章目录 一、处理步骤1、使用终端登录上服务器查看磁盘使用状态2、使用恢复备份管理工具RMAN删除归档日志 二、详细操作步骤三、定时任务自动清归档日志1、编写删除脚本4、测试脚本运行情况5、设置定时任务每周执行一次,并测试运行效果 昨天单位的所有系统都连不上…...
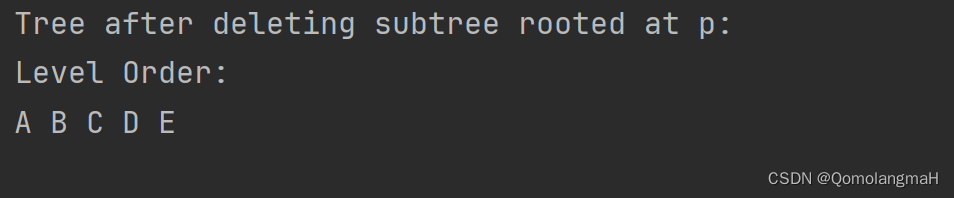
【数据结构】树与二叉树(廿六):树删除指定结点及其子树(算法DS)
文章目录 5.3.1 树的存储结构5. 左儿子右兄弟链接结构 5.3.2 获取结点的算法1. 获取大儿子、大兄弟结点2. 搜索给定结点的父亲3. 搜索指定数据域的结点4. 删除结点及其左右子树a. 逻辑删除与物理删除b. 算法DSTc. 算法解析d. 代码实现递归释放树算法DS e. 算法测试 5. 代码整合…...

交叉编译 和 软硬链接 的初识(面试重点)
目录 交叉编译的初认识Q&A Q1: 编译是什么? Q2: 交叉编译是什么? Q3: 为什么要交叉编译 Q3.1:树莓派相对于C51大得多,可以集成编译器比如gcc,那么树莓派就不需要交叉编译了吗? Q4: 什么是宿主机和…...

Docker attach 命令
docker attach:连接到正在运行中的容器。 语法 docker attach [OPTIONS] CONTAINER要attach上去的容器必须正在运行,可以同时连接上同一个container来共享屏幕(与screen命令的attach类似)。 官方文档中说attach后可以通过CTRL-…...
Keil5个性化设置及常用快捷键
Keil5个性化设置及常用快捷键 1.概述 这篇文章是Keil工具介绍的第三篇文章,主要介绍下Keil5优化配置,以及工作中常用的快捷键提高开发效率。 第一篇:《安装嵌入式单片机开发环境Keil5MDK以及整合C51开发环境》https://blog.csdn.net/m0_380…...
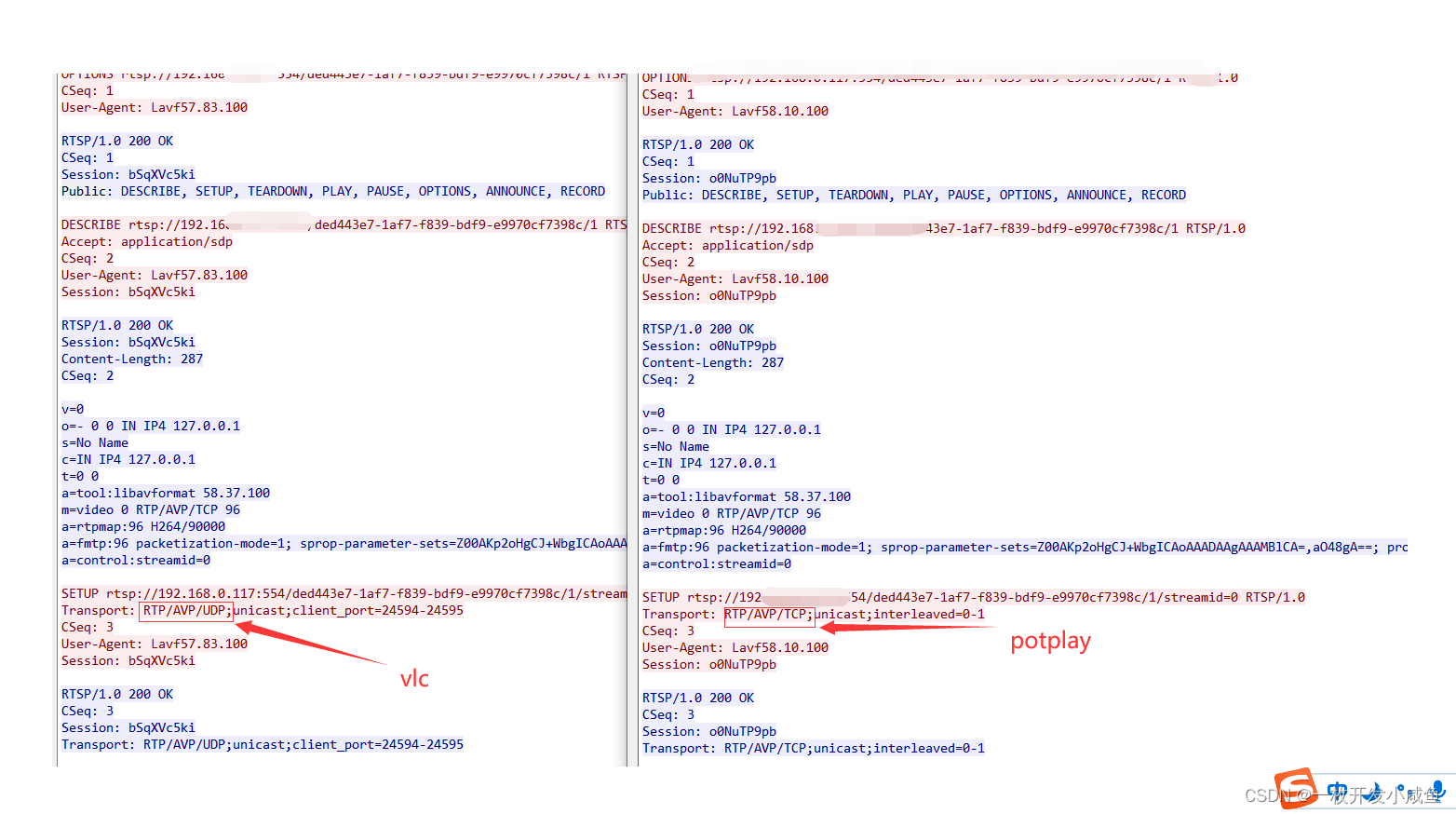
rtsp点播异常出现‘circluar_buffer_size‘ option was set but it is xx
先说现象: 我使用potplay播放器来点播rtsp码流的时候可以点播成功,同事使用vlc和FFplay来点播rtsp码流的时候异常。 排查思路: 1.开始怀疑是oss账号问题,因为ts切片数据是保存在oss中的,我使用的是自己的oss账号,同事使用的是公司…...

C++ Qt QString用法详解与代码演示
作者:令狐掌门 技术交流QQ群:675120140 csdn博客:https://mingshiqiang.blog.csdn.net/ 文章目录 创建和初始化长度和容量修改字符串字符串比较查找和提取数值转换arg格式化`arg` 的基本用法精确控制占位符多占位符的复杂替换使用大括号占位符注意事项迭代Unicode 和编码QSt…...

安全攻击及防范手册
目录 1 概述 1.1 简介 1.2 参考资料 2 安全隐患及预防措施 <...
Visual Studio 使用MFC 单文档工程绘制单一颜色直线和绘制渐变颜色的直线(实例分析)
Visual Studio 使用MFC 单文档工程从创建到实现绘制单一颜色直线和绘制渐变颜色的直线 本文主要从零开始创建一个MFC单文档工程然后逐步实现添加按键(事件响应函数),最后实现单一颜色直线的绘制与渐变色直线的绘制o( ̄▽࿾…...

一起学docker系列之八使用 Docker 安装配置 MySQL
目录 前言步骤 1:拉取 MySQL 镜像步骤 2:运行 MySQL 容器步骤 3:检查容器状态步骤 4:进入 MySQL 容器步骤 5:配置 MySQL 字符编码步骤 6:重启 MySQL 容器步骤 7:测试字符编码步骤 8:…...
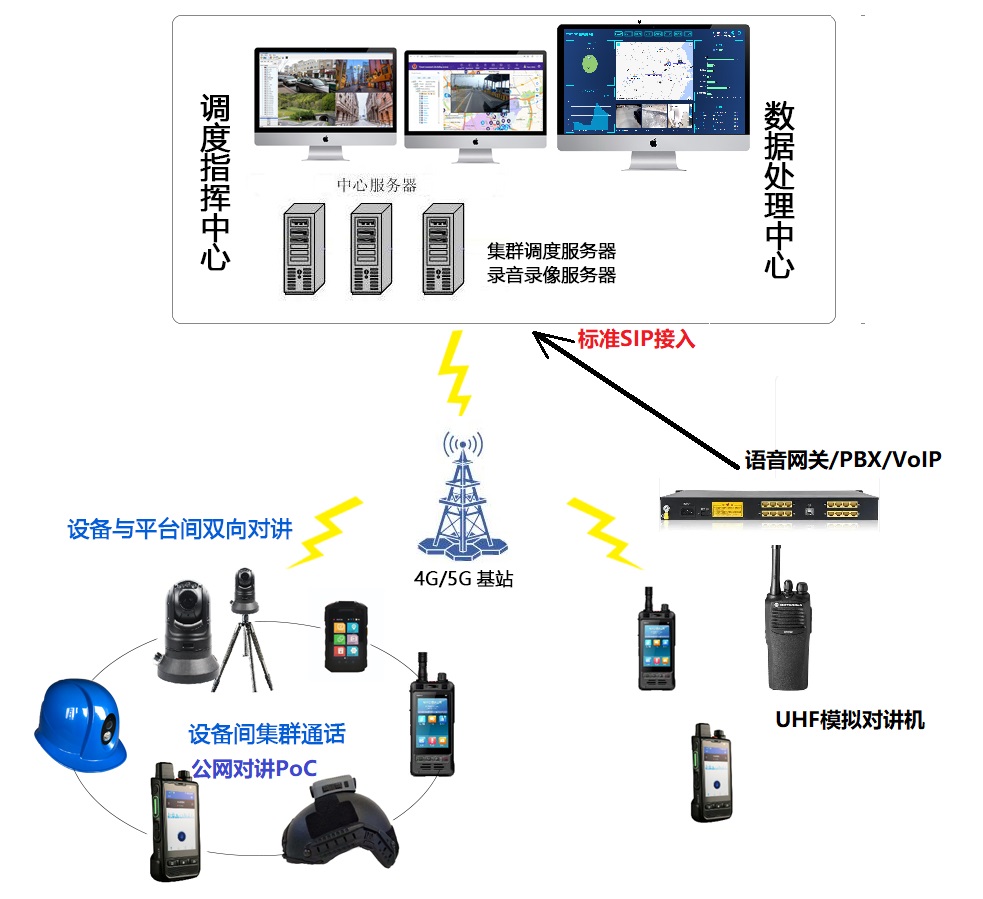
4G执法记录仪在大型安保集团,保安集团、蓝天救援队中的 应用,行为规范化,人员定位,考勤打卡,应急指挥调度
【智能化升级】揭秘4G/5G执法记录仪在安保与救援领域如何重塑行业标准与效率 在快速发展的社会当中,大型安保集团、保安集团和蓝天救援队所肩负的任务日益繁重与复杂。无论是在平时的治安巡查、安保执勤,还是在突发公共事件的应急响应中,如何…...

分布式事务,一致性理论, 两阶段提交(2PC), 三阶段提交(3PC),Seata分布式事务方案
文章目录 分布式事务:1、一致性理论2、两阶段提交(2PC)3、三阶段提交(3PC)4、Seata分布式事务方案 上一篇降到了 分布式锁,先来和大家聊一聊分布式事务, 分布式锁的链接如下: http…...
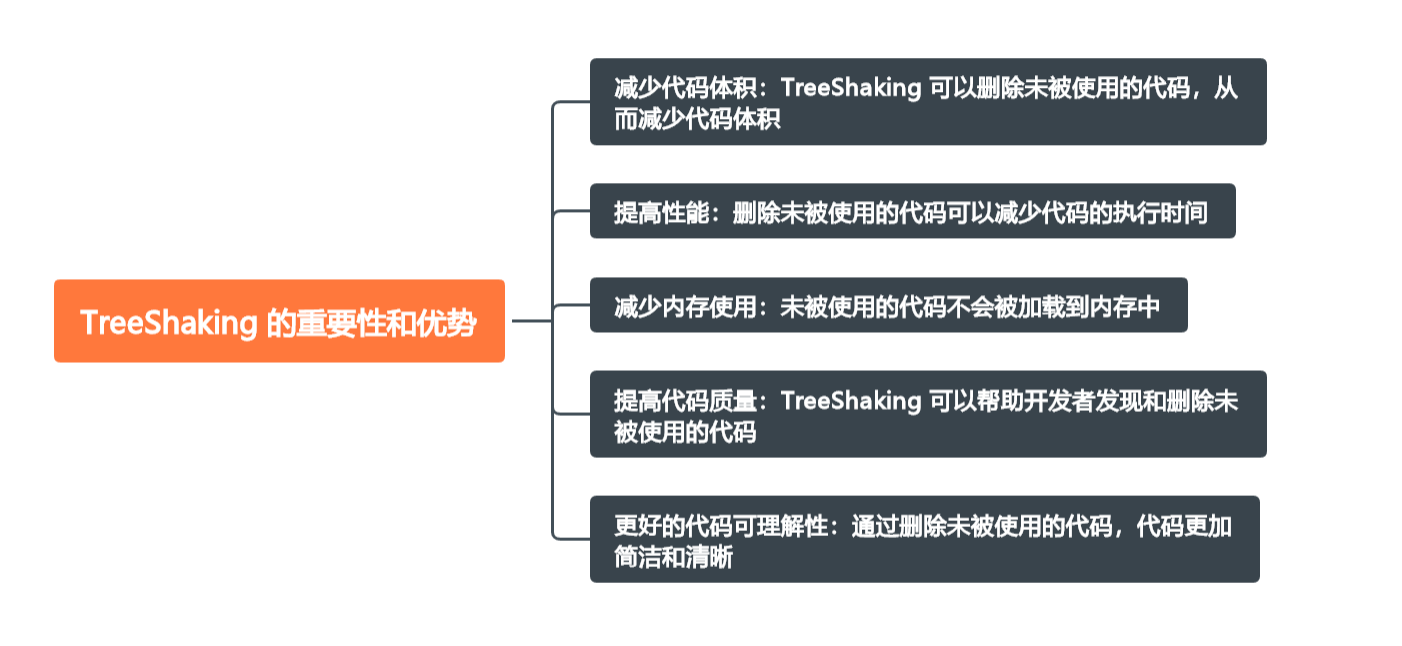
摆脱无用代码的负担:TreeShaking 的魔力
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
)
A-莲子的软件工程学【算法必会题目】(JavaPythonC++实现)
文章目录 A-莲子的软件工程学题目背景解题思路Python题解代码Java题解代码C++题解代码代码OJ评判结果代码讲解Python 代码解释:Java 代码解释:C++ 代码解释:寄语A-莲子的软件工程学 题目背景 在宇宙射线的轰击下,莲子电脑里的一些她自己预定义的函数被损坏了。 对于一名…...
)
山东大学软件学院创新实训——个人博客(三)
日期:2026 年 4 月 6 日——4 月 12 日项目:绘画 AI 博弈小游戏 —— 人机对抗绘画猜词与心理解读系统本周目标与产出本周完成了游戏数据库较为完整的设计与实现,对上周的models.py草稿文件进行了修改和完善,包括:✅ 7…...

伯明翰大学发布诗歌生成新标准:AI能否成为下一个莎士比亚?
诗歌被誉为人类文学艺术的巅峰,它需要将情感、智慧和技艺完美融合在有限的文字中。当我们谈到诗歌创作时,往往会想到那些伟大的诗人——从莎士比亚到艾略特,他们用文字创造了永恒的艺术品。但在人工智能快速发展的今天,一个令人着…...
)
z—算法基础:时空复杂度()
背景 在软件开发的漫长旅途中,"构建"这个词往往让人又爱又恨。爱的是,一键点击,代码变成产品,那是程序员最迷人的时刻;恨的是,维护那一堆乱糟糟的构建脚本,简直是噩梦。 在很多项目中…...

手术室里的实时多模态推理:达芬奇+超声+术中病理流式融合模型已进入II期临床,错过将滞后3年临床转化窗口期
第一章:多模态大模型在医疗中的应用 2026奇点智能技术大会(https://ml-summit.org) 多模态大模型正深刻重塑医疗AI的技术边界,其核心能力在于协同理解医学影像、电子病历文本、基因序列、病理切片及实时生理信号等异构数据源,从而支撑诊断辅…...

抖音无水印下载终极指南:免费批量下载视频、音乐和直播的完整方案
抖音无水印下载终极指南:免费批量下载视频、音乐和直播的完整方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fal…...

香橙派5 NPU实战:从零部署Yolov5模型并实现实时推理
1. 香橙派5与NPU加速的黄金组合 香橙派5作为一款高性能的单板计算机,搭载了Rockchip RK3588S芯片,这颗芯片内置了一颗3核的自研RKNN NPU(神经网络处理单元)。这个NPU专门为AI推理任务优化,能够显著提升Yolov5这类目标检…...

GraphPad Prism 入门指南:用途+基础使用全解析【附安装包】
作为科研领域公认的“绘图统计”神器,GraphPad Prism 凭借易用性和专业性,成为生物、医学、化学等领域科研者的必备工具。无需复杂代码,就能快速完成数据统计与期刊级图表绘制,今天就用通俗语言,讲清它的核心用途和新手…...

A律13折线PCM编码实战:从MATLAB代码到信号恢复全流程解析
A律13折线PCM编码实战:从MATLAB实现到信号保真度优化 在数字通信系统中,脉冲编码调制(PCM)是将模拟信号转换为数字信号的核心技术。A律13折线作为国际电信联盟(ITU-T)推荐的标准化非均匀量化方法࿰…...

借口的本质的庖丁解牛
它的本质是:一种为了维护“虚假自我形象”而构建的认知防火墙。借口是大脑为了保护自尊心(Ego)免受“我不够好”、“我失败了”这种痛苦真相的伤害,而临时编译的一段 错误处理逻辑 (Error Handling Logic) 。它将内部的“能力/意愿…...
)
深度学习机器学习基础最大似然与贝叶斯统计(十九)
1. 定位导航 前面几篇讲了怎么衡量一个模型好不好(偏差、方差、过拟合)。本篇回答更深层的问题:损失函数从哪里来? 答案是最大似然估计——训练神经网络的所有损失函数(MSE、交叉熵、NLL)本质上都是 MLE 在不同概率模型假设下的具体形式。 2. 最大似然估计(Maximum L…...