数据挖掘 K近邻
什么时候用K近邻?
交叉验证的时候。最常见的交叉验证方法是K折交叉验证,其中数据集被均匀分成K个子集,称为折,然后执行K次训练和测试,每次选择不同的折作为测试集,其余的作为训练集。最后,将K次测试结果的平均值作为模型的性能指标。
什么叫交叉验证?
交叉验证是一种常用的模型评估技术,用于评估机器学习模型的性能和泛化能力。在机器学习中,我们通常希望评估训练好的模型对未见过数据的表现情况,以确保模型可以泛化到新的数据上。
交叉验证的基本思想?
交叉验证的基本思想是将原始数据集分成若干个子集,然后进行多轮训练和测试。在每一轮中,选择一个子集作为测试集,其余子集作为训练集,然后训练模型并在测试集上进行评估。
交叉验证的子集会重复使用吗?
当K等于原始数据集大小时,这种交叉验证方法称为留一法(Leave-One-Out,简称LOO),即每个样本都被用作测试集一次,其余样本用于训练模型。在这种情况下,子集不会重复使用。但是,LOO计算代价较高,并且可能过度拟合训练数据,因此通常不是首选的交叉验证方法。总之,交叉验证中的子集会重复使用,以确保我们可以评估模型在不同数据集上的性能,并减少因数据集划分不合理而引入的偶然性。
K近邻通常用哪些头文件?
# 导入pandas和numpy库
import pandas as pd
import numpy as np
# 导入sklearn库中的KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
# 导入os库
import os
# 导入sklearn库中的GridSearchCV
from sklearn.model_selection import GridSearchCV
K近邻的头文件都是什么,都有什么用?
第一、二行:
数据处理库pandas和科学计算库numpy。通过这两个库,您可以进行各种数据操作和分析。一般来说,习惯上将pandas重命名为pd,numpy重命名为np,以方便在代码中使用。导入这两个库后,您可以使用它们提供的函数和方法进行数据读取、数据处理、数据分析等操作。例如,使用pandas的read_csv()函数读取CSV文件,使用numpy的array()函数创建数组等。
第三行:
from sklearn.neighbors import KNeighborsClassifier: 这一行代码导入了scikit-learn库中的KNeighborsClassifier类。K近邻分类器是一种基于实例的学习算法,通过基于最近邻居的投票来进行分类。
第四行:
import os: 这一行代码导入了Python的os模块,用于与操作系统进行交互,例如获取文件路径、创建目录等操作。
第五行:
from sklearn.model_selection import GridSearchCV: 这一行代码导入了scikit-learn库中的GridSearchCV类。GridSearchCV是一种用于自动化调优模型参数的方法,它会自动尝试不同的参数组合,并选择最佳参数组合以获得最佳模型性能。
综上所述:
这几个导入语句主要用于机器学习中的分类任务和参数调优操作。其中,KNeighborsClassifier用于构建K近邻分类器模型,os模块用于与操作系统进行交互,GridSearchCV用于自动化调优模型参数。这些工具可以帮助您更方便地进行机器学习模型的开发和优化。
具体案例-手写数字识别:
# 导入pandas和numpy库
import pandas as pd
import numpy as np
# 导入sklearn库中的KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
# 导入os库
import os
# 导入sklearn库中的GridSearchCV
from sklearn.model_selection import GridSearchCV# 获取训练数据路径
Train_data_path = os.listdir("./digits/trainingDigits") # os.listdir返回的是目录中所有的文件和文件夹的名称,而不包括子目录中的内容。
# 初始化训练集X和Y
Train_X = []
Train_Y = []
# 遍历训练数据路径
for data_file in Train_data_path:# 获取训练数据标签data_file.split("_")# data_file.split("_")会将文件名按照"_"进行分割,得到一个由多个字符串组成的列表,如["digit", "0.txt"]。# 通过索引[0]取出列表中的第一个元素"digit",即数据文件对应的标签部分。# Train_Y.append() 将提取出的标签部分添加到 Train_Y 列表中。这样,每次执行这段代码,Train_Y 列表都会逐步积累包含各个数据文件标签的元素。最终 Train_Y 列表可能会包含类似 ["digit", "digit", ...] 的内容,其中每个元素对应一个数据文件的标签信息。Train_Y.append(data_file.split("_")[0])# 打开训练数据文件with open(f"./digits/trainingDigits/{data_file}", "r") as f: # 建议别用open,用numpy.load(),因为老师真的会喷# 读取训练数据num = f.read().replace("\n", '') # 将无敌的换行符替换为空字符串,并所有数据转化为一个很长的字符串# 初始化xx = []# 遍历训练数据for i in num:# 将训练数据转换为整数x.append(int(i)) # x 列表中包含了训练数据中每个数字所对应的像素点信息,这些信息都以整数形式存储在列表中# 将x添加到训练集X中Train_X.append(x) # 通过添加操作,我们可以将所有的训练数据都存储在 Train_X 列表中,并且可以通过索引访问列表中的每个子列表来获取对应数字的像素点信息。# 打印x# print(x)# 打印x的长度# print(len(x))# 获取测试数据路径
Test_data_path = os.listdir("./digits/testDigits")
# 初始化测试集X和Y
Test_X = []
Test_Y = []
# 遍历测试数据路径
for data_file in Test_data_path:# 获取测试数据标签Test_Y.append(data_file.split("_")[0])# 打开测试数据文件with open(f"./digits/TestDigits/{data_file}", "r") as f:# 读取测试数据num = f.read().replace("\n", '')# 初始化xx = []# 遍历测试数据for i in num:# 将测试数据转换为整数x.append(int(i))# 将x添加到测试集X中Test_X.append(x)# 打印x# print(x)# 打印x的长度# print(len(x))# 定义参数网格
# list(range(1, 12)) 是一个列表,包含了从 1 到 11(不包括 12)的整数。这个列表是作为字典的值存储的,表示 K最近邻(K-Nearest Neighbors,KNN)需要测试的邻居数的范围。range(1, 12) 包含了从 1 到 11 的整数,因此 KNN 算法将会尝试从 1 到 11 的不同邻居数,来确定最佳的邻居数。也就是说,算法将会尝试使用 1 个邻居、2 个邻居、3 个邻居......直到 11 个邻居来进行分类。
param_grid = {'n_neighbors': list(range(1, 12))}
# 初始化KNeighborsClassifier
clf = KNeighborsClassifier() # 创建了一个 KNN(K-最近邻)分类器对象
# 使用GridSearchCV对KNeighborsClassifier进行参数搜索
# GridSearchCV 是 sklearn 库中用于执行网格搜索和交叉验证的类。它接受三个参数:
# clf:要使用的分类器对象,这里传入了之前创建的 KNN 分类器对象 clf。
# param_grid:一个字典,表示要搜索的参数空间。这里传入了之前定义的 param_grid 字典,用于指定 KNN 算法中的邻居数的范围。
# cv:整数或交叉验证迭代器,表示进行交叉验证的折数。这里设置为 10,表示使用 10 折交叉验证。老登说10折好用,有理论基础。
GS_model = GridSearchCV(clf, param_grid, cv=10)
# 对训练集进行参数搜索
GS_model.fit(Train_X, Train_Y)
# 打印最优参数和最优配置
# GS_model.best_params_:最佳的邻居数
# GS_model.best_score_:模型在训练数据集上分类正确的比例
print(f'模型的最优参数最优配置为{GS_model.best_params_},且训练精度为{GS_model.best_score_:.3f}')# 初始化最优模型
# 创建了一个 K 最近邻分类器(KNeighborsClassifier)的实例 Best_model,并使用了之前通过网格搜索得到的最佳参数配置中的最优邻居数量 'n_neighbors' 来初始化这个分类器。
Best_model = KNeighborsClassifier(GS_model.best_params_['n_neighbors'])
# 对训练集进行训练
Best_model.fit(Train_X, Train_Y)
# 计算测试集的分类精度
score = Best_model.score(Test_X, Test_Y)
# 打印测试集的分类精度
print(f'交叉验证得到模型的测试分类精度为{score:.3f}')
# 这段代码使用了一个循环来尝试不同的K值,然后训练KNN模型并输出每个K值对应的预测得分。这种方法可以帮助你找到最适合数据集的K值,从而提高模型的性能。在循环中,首先创建了一个KNN模型,并使用当前的K值进行初始化。然后,使用训练数据对模型进行训练,并计算模型在测试数据上的得分。最终,打印出每个K值对应的模型得分。通过这种方式,你可以比较不同K值下模型的性能表现,以便选择最佳的K值来构建最终的KNN模型。
# for i in range(1,11):
# model = KNeighborsClassifier(i)
# model.fit(Train_X,Train_Y)
# print(f"当K等于{i}时模型预测得分为:",model.score(Test_X,Test_Y))# K最近邻(K-Nearest Neighbors,KNN)算法是一种常用的监督学习方法,用于解决分类和回归问题。在KNN算法中,对于一个给定的未知数据点,根据其在特征空间中与其他已知数据点的距离来进行分类或回归预测。KNN算法的基本思想是,如果一个样本在特征空间中的k个最近邻中的大多数属于某个类别,则该样本也属于这个类别。在分类问题中,KNN算法会将未知数据点分配给与其最近邻居所属类别相同的类;在回归问题中,KNN算法会根据最近邻居的值来预测未知数据点的数值。KNN算法的优点之一是简单易理解,易于实现。然而,KNN算法的缺点包括对大规模数据集的计算成本较高,以及在处理高维数据时可能受到“维度灾难”的影响。在实际应用中,可以通过交叉验证等方法来选择最佳的K值,以及使用特征缩放等技术来提高KNN算法的性能。
结果:

有点小尬,但确实精度提高了,可能这个数据比较符合两种算法吧
让我们看一下下一个案例-海伦K近邻的头文件:
import pandas as pd
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
上面的头文件都是干嘛的呀?
pandas:pandas是一个数据处理和分析的库,提供了高效的数据结构和数据分析工具。通过pandas,你可以轻松地读取、处理和操作数据,例如加载数据集、数据清洗、特征选择等。
numpy:numpy是Python中用于科学计算的一个核心库,提供了高性能的多维数组对象和各种数学函数。在机器学习中,常使用numpy来处理和操作数组数据,例如矩阵运算、向量化操作等。
sklearn.model_selection.GridSearchCV:GridSearchCV是scikit-learn(sklearn)库中的一个模型选择工具,用于通过交叉验证来调整模型的超参数。通过GridSearchCV,你可以定义一个参数网格,它会自动尝试不同参数组合,并选择最佳的参数配置。
sklearn.preprocessing:sklearn.preprocessing是scikit-learn库中的一个数据预处理模块,提供了一系列用于数据预处理的函数和类。这些函数和类可以用来对数据进行缩放、归一化、标准化等操作,以便更好地适应机器学习模型的要求。
sklearn.neighbors.KNeighborsClassifier:KNeighborsClassifier是scikit-learn中的一个K近邻分类器模型。它是基于最近邻算法的一种分类器,用于解决分类问题。KNeighborsClassifier可以根据邻居的类别来预测未知数据点的类别,并具有简单易用的接口。
sklearn.model_selection模块中的cross_val_score函数用于执行交叉验证并计算模型的评分。它可以帮助你评估机器学习模型的性能。
对了,说句题外话,crtl+z撤销,ctrl+shift+z还原
批量注释:ctrl+/ ,取消批量注释: ctrl+/
批量缩进:tab ,取消批量缩进:shift+tab
import pandas as pd
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score# 读取数据
df = pd.read_csv("datingTestSet.txt", sep="\t",names=['每年获得的飞行常客里程数', '视频游戏所耗时间百分比', '每周消费的冰淇淋公升数', '喜爱程度'])
# print(df.head())#使用df.head()函数来查看数据集的前几行,以确保数据已正确加载。
# 将最后一列数据进行归一化处理
X = preprocessing.MinMaxScaler().fit_transform(df.iloc[:, :-1])
# iloc函数是pandas库中用于按照位置索引选取数据的函数。
Y = df.iloc[:, -1]
# 定义参数网格
param_grid = {'n_neighbors': np.arange(1, 10,1)} # param_grid定义了一个名为n_neighbors的超参数,它是KNN算法中k值(即最近邻居数)的取值范围。具体来说,np.arange(1, 10, 1)函数生成了一个从1到9的整数序列,其中步长为1,作为n_neighbors超参数的所有可能取值。也就是说,我们将在这个范围内寻找最佳的k值,以获得最好的模型性能。
# 定义KNN模型
clf = KNeighborsClassifier()
# 使用网格搜索模型
GS_model = GridSearchCV(clf, param_grid, cv=10)
# 训练模型
GS_model.fit(X, Y)
# 输出模型的最优参数最优配置以及训练精度
print(f'模型的最优参数最优配置为{GS_model.best_params_},且训练精度为{GS_model.best_score_:.3f}')Max_score = 0.0
# 定义KNN模型,找到最佳的K值
for K in range(1, 11):model = KNeighborsClassifier(K)model.fit(X, Y)# 十折验证 #求出其10折平均值score = cross_val_score(model, X, Y, cv=10).mean()if Max_score < score:Max_score = scoreBest_K = K
print("最好的K值为:", Best_K, "平均得分为:", Max_score)# 定义KNN模型
model = KNeighborsClassifier(Best_K)
# 训练模型
model.fit(X, Y)
# 测试样例
print(model.predict([[0.33193158, 0.41660188,0.24523407]])) # 输出结果['largeDoses']表示模型对输入的样本[0.33193158, 0.41660188, 0.24523407]进行了分类预测,并将其归类为"largeDoses"。在一些分类问题中,类别可能被编码为字符串形式,而不是数值。类别的具体含义取决于你的具体应用场景。例如,在某个社交网络应用中,"largeDoses"可能代表用户对某种活动的兴趣程度;在医疗诊断中,"largeDoses"可能代表患者疾病的严重程度等等。# 使用fit_transform函数进行拟合和转换操作。在拟合过程中,它会根据数据集中的最小值和最大值来计算每个特征的转换规则,然后将数据按照这些规则进行转换。具体地,它会将数据缩放到给定的特征范围内,通常是0到1之间。这个函数的作用是将数据集进行归一化,使得不同特征的取值范围都在相同的尺度上,避免了某些特征由于数值范围的差异而对建模产生较大的影响。这样,在进行后续的机器学习模型训练时,各个特征的权重更平衡,提高了模型的稳定性和准确性。总结起来,fit_transform函数的作用就是对数据进行归一化处理,并返回归一化后的结果。# 这段代码会报错,添加for item in s.items(),通过使用items()函数,你可以避免未来版本中对iteritems()函数的移除所带来的问题。
结果:

上下代码是一样的,上面是学生写的,下面是老登写的
相关文章:
数据挖掘 K近邻
什么时候用K近邻? 交叉验证的时候。最常见的交叉验证方法是K折交叉验证,其中数据集被均匀分成K个子集,称为折,然后执行K次训练和测试,每次选择不同的折作为测试集,其余的作为训练集。最后,将K次…...
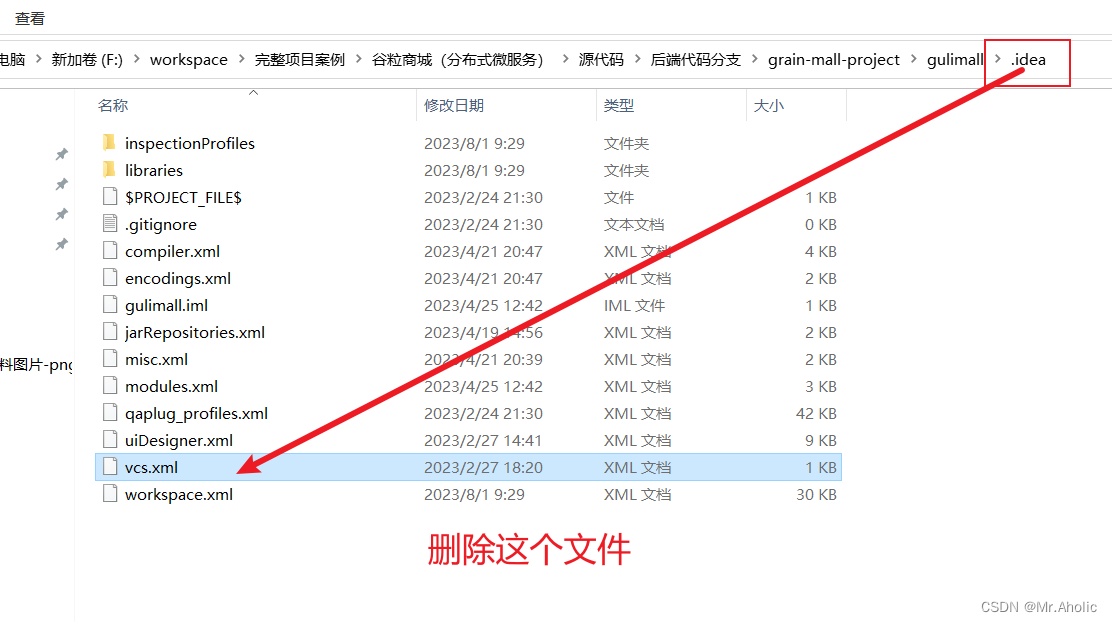
项目去除git版本控制
我 | 在这里 🕵️ 读书 | 长沙 ⭐软件工程 ⭐ 本科 🏠 工作 | 广州 ⭐ Java 全栈开发(软件工程师) 🎃 爱好 | 研究技术、旅游、阅读、运动、喜欢流行歌曲 ✈️已经旅游的地点 | 新疆-乌鲁木齐、新疆-吐鲁番、广东-广州…...

ICMPv6报文与邻居状态跟踪
ICMPv6报文 ICMPv6(Internet Control Message Protocol for the IPv6)是IPv6的基础协议之一。 在IPv4中,Internet控制报文协议ICMP(Internet Control Message Protocol)向源节点报告关于向目的地传输IP数据包过程中的错误和信息。它为诊断、信息和管理目的定义了一些消息…...
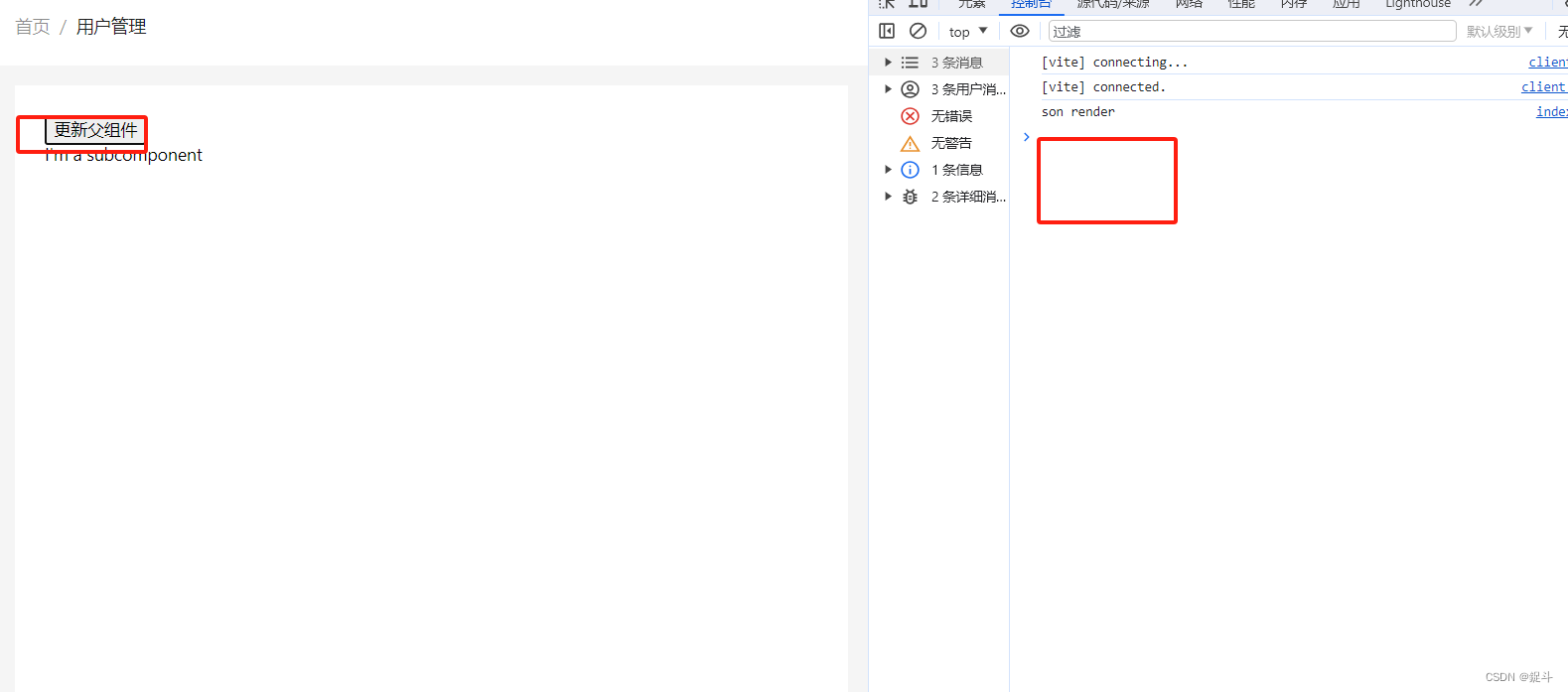
React中通过children prop或者React.memo来优化子组件渲染【react性能优化】
文章目录 前言未优化之前的代码问题解决方案一,通过children prop解决方案二,通过React.memo后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:react.js 🐱👓博主在前端领域还有很多知识和…...
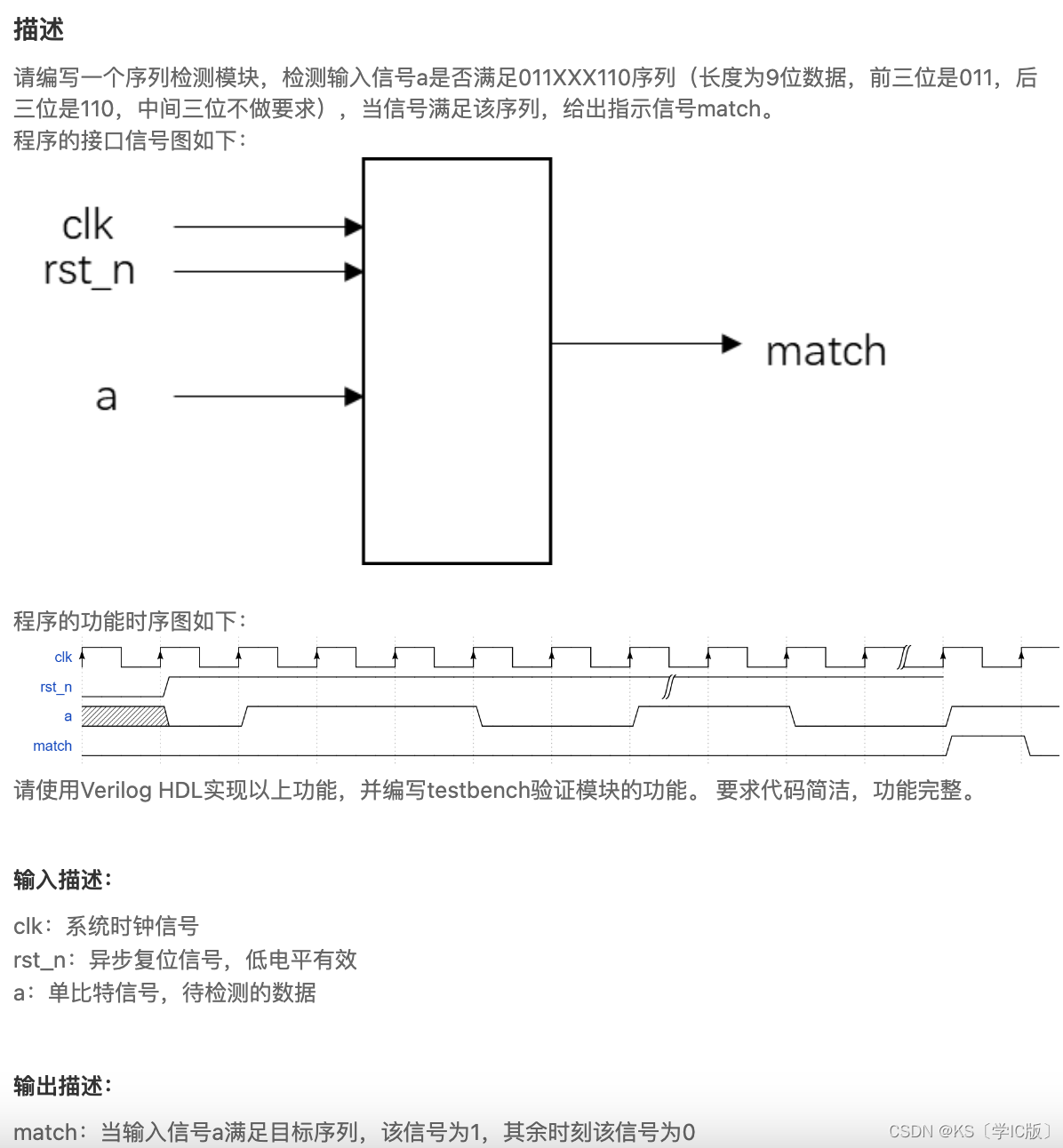
「Verilog学习笔记」含有无关项的序列检测
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 timescale 1ns/1ns module sequence_detect(input clk,input rst_n,input a,output reg match);reg [8:0] a_tem ; always (posedge clk or negedge rst_n) begin if (~rs…...
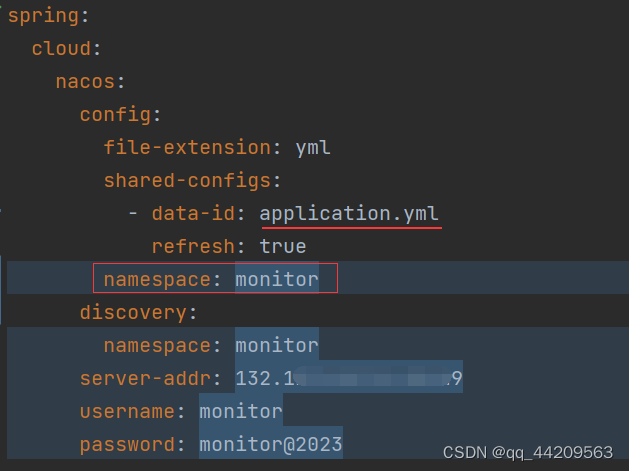
k8s部署的java服务查看连接nacos缓存的配置文件
一、问题描述 k8s部署的java服务,使用nacos中的配置文件,需要在缓存中查看该服务具体是使用到了哪些配置文件 二、解决 参考文档: https://nacos.io/zh-cn/docs/system-configurations.html 文档描述如下: 进入java服务容器进入用户目录下的nacos&a…...

【matlab程序】matlab给风速添加图例大小
【matlab程序】matlab给风速添加图例大小 clear;clc;close all; % load 加载风速数据。 load(matlab.mat) % 加载颜色包信息 gray load(D:\matlab_work\函数名为colormore的颜色索引表制作\R_color_txt\R_color_single\gray89.txt); brown load(D:\matlab_work\函数名为color…...
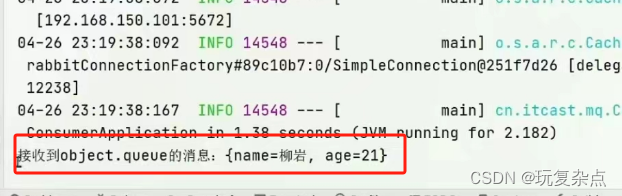
微服务学习|初识MQ、RabbitMQ快速入门、SpringAMQP
初识MQ 同步通讯和异步通讯 同步通讯是实时性质的,就好像你用手机与朋友打视频电话,但是,别人再想与你视频就不行了,异步通讯不要求实时性,就好像你用手机发短信,好多人都能同时给你发短信,你…...
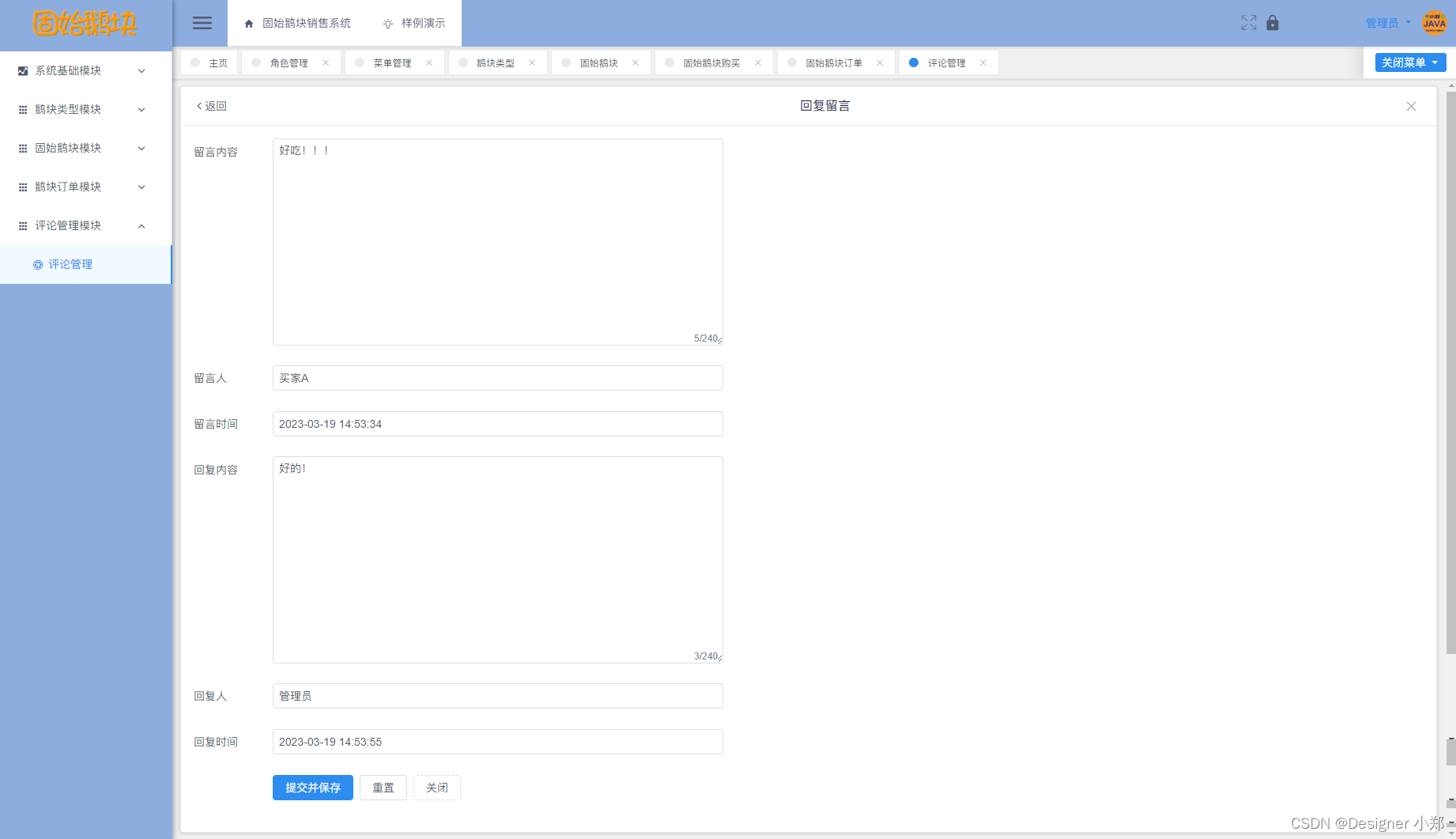
【开源】基于Vue.js的固始鹅块销售系统
项目编号: S 060 ,文末获取源码。 \color{red}{项目编号:S060,文末获取源码。} 项目编号:S060,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 鹅块类型模块2.3 固…...
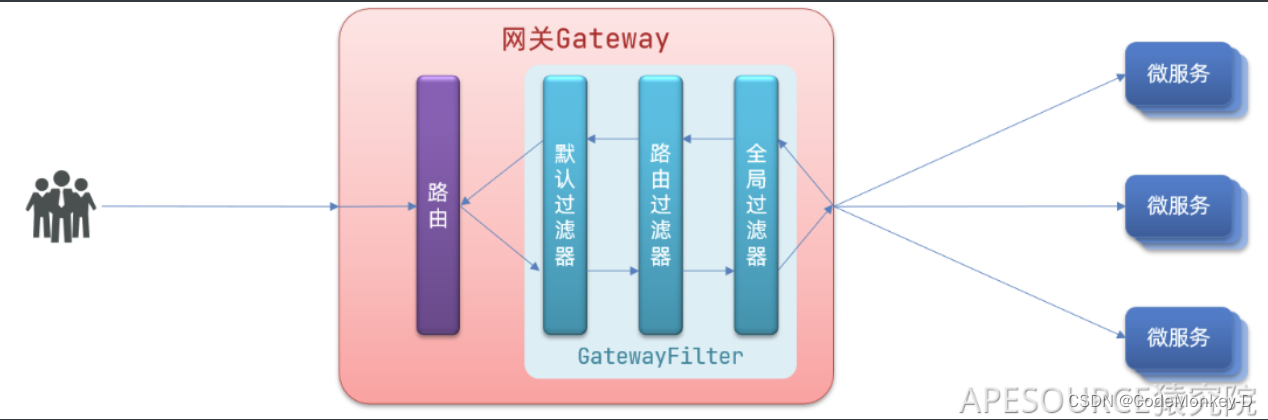
SpringCloud微服务网关Gateway:gateway基本实现、断言工厂、过滤器工厂、浏览器同源策略、跨域问题解决方案
Gateway网关 Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0和Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API路由管理方式 为什么…...

ArcGIS中如何建立土地利用规划数据库
一、建库步骤 - 收集土地利用规划资料,包括图件资料、数据资料和文本资料。 - 将收集到的数据进行整理和格式转换,使其符合ArcGIS 的数据格式要求。 - 在ArcGIS 中创建新的土地利用规划数据库,并定义相应的数据结构和字段。 - 将转换后的数据导入到新的土地利用规划数据库中…...

微信小程序 服务端返回富文本,图片无法显示
场景: 微信小程序开发中,需要从服务端拿取数据渲染到页面上,后台返回的富文本里,图片路径有时是没有带域名前缀的,导致图片无法正常显示。 解决方案: 在富文本返回时,用正则匹配&#…...

谈谈Redis持久化
目录 前言 RDB AOF 总结 前言 我们都知道Redis 是基于内存的数据库,一旦服务器的进程退出,数据库数据就会随之丢失,这不是我们想看到的,为了避免这个问题,Redis 为我们提供了俩种持久化方案,将数据保存…...

CentOS7中升级OpenSSL详细教程
文章目录 一. 引言二. 升级前的准备1.备份现有配置2. 检查系统版本3. 安装依赖 三. OpenSSL安装四. 验证 一. 引言 OpenSSL: 是用于保护数据安全的重要工具。它能提供加密,解密等多项功能。 然而,随着技术的发展和新的安全漏洞的出现,使用最…...

人工智能基础_机器学习050_对比sigmoid函数和softmax函数的区别_两种分类器算法的区别---人工智能工作笔记0090
可以看到最上面是softmax的函数对吧,但是如果当k = 2 那么这个时候softmax的函数就可以退化为sigmoid函数,也就是 逻辑斯蒂回归了对吧 我们来看一下推导过程,可以看到上面是softmax的函数 可以看到k=2 表示,只有两个类别对吧,两个类别的分类不就是sigmoid函数嘛对吧,所以说 …...
第十九章 解读利用pytorch可视化特征图以及卷积核参数(工具)
介绍一种可视化feaature maps以及kernel weights的方法 推荐可视化工具TensorBoard:可以查看整个计算图的数据流向,保存再训练过程中的损失信息,准确率信息等 学习视频: 使用pytorch查看中间层特征矩阵以及卷积核参数_哔哩哔哩…...
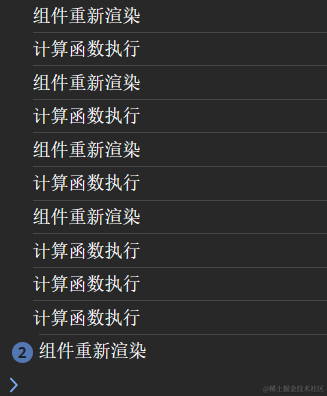
【React】Memo
组件重新渲染时缓存计算的结果。 实例:count1计算斐波那契数列,count2和count1可以触发数值变化。使用memo可以使只有在count1变化时触发斐波那契数列计算函数,而count2变化时不触发斐波那契数列计算函数。 import { useMemo } from "r…...

宣传技能培训1——《新闻摄影技巧》光影魔法:理解不同光线、角度、构图的摄影效果,以及相机实战操作 + 新闻摄影实例讲解
新闻摄影技巧 写在最前面摘要 构图与拍摄角度景别人物表情与叙事远景与特写 构图与拍摄角度案例 主体、陪体、前景、背景强调主体利用前景和背景层次感的创造 探索新闻摄影中的构图技巧基本构图技巧构图技巧的应用实例实例分析1. 黄金分割和九宫格2. 三角型构图3. 引导线构图4.…...

3 时间序列预测入门:TCN
0 引言 TCN(全称Temporal Convolutional Network),时序卷积网络,是在2018年提出的一个卷积模型,但是可以用来处理时间序列。 论文:https://arxiv.org/pdf/1803.01271.pdf 一维卷积:在时间步长方…...

Linux学习笔记-芯片性能检测
文章目录 概述Dhrystone(单核性能测试工具)简介:源码下载:源码编译:使用及输出结果 coremark(多核性能测试工具)简介:源码下载:源码编译:使用及输出结果&…...

ROS自定义全局路径规划插件:从预存轨迹到动态避障的融合实践
1. 为什么需要自定义全局路径规划插件 在仓储物流场景中,机器人经常需要在固定路线上往返行驶,比如沿着货架间的通道移动。传统全局路径规划算法(如A*、Dijkstra)每次都会重新计算路径,不仅消耗计算资源,而…...

html标签怎样居中文本_html中实现文本居中的常用方法【方法】
text-align: center仅对块级元素及内联内容生效,不能居中内联元素自身;居中内联元素需设display: inline-block或block,或用flex布局的justify-content。text-align: center 只对块级元素和内联内容生效直接给 <div> 或 <p> 加 t…...

SEONIB智能排期:让站点更新从偶然事件变成系统化的增长引擎
SEONIB智能排期:让站点更新从偶然事件变成系统化的增长引擎 我记得刚开始尝试用内容获取自然流量时,最困扰我的不是写不出文章,而是写出来的文章总像一场心血来潮的烟花表演——绚烂一阵,然后沉寂。我会因为一个热点,…...
)
解密昇腾ACL事件机制:如何用Event实现多Stream精准调度(避坑指南)
昇腾ACL事件机制深度解析:多Stream协同避坑实战 当你在昇腾平台上处理8路高清视频流分析时,是否遇到过这样的困境——明明硬件算力充足,但实际吞吐量却只有理论值的60%?问题的根源往往不在算法本身,而在于对ACL事件机制…...

Folcolor:告别视觉疲劳!14种色彩让你的Windows文件夹管理效率提升3倍
Folcolor:告别视觉疲劳!14种色彩让你的Windows文件夹管理效率提升3倍 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 你是否曾在成百上千个黄色文件夹中迷失方向&am…...

AI在网络安全中的5个实战应用:从渗透测试到异常检测
AI在网络安全中的5个实战应用:从渗透测试到异常检测 网络安全领域正经历一场由AI驱动的技术革命。想象一下,当黑客的攻击速度以毫秒计时,传统人工防御如同用算盘对抗超级计算机。去年某金融机构遭遇的零日攻击中,防御系统仅用0.3秒…...

FreeRTOS多任务系统看门狗监控策略与事件标志组实践
1. FreeRTOS多任务系统看门狗监控的必要性 在嵌入式系统开发中,系统稳定性是首要考虑的问题。我遇到过不少系统莫名其妙挂掉的案例,排查起来特别头疼。有一次项目交付前三天,设备在现场运行72小时后突然死机,当时用尽了各种调试手…...

测试工程师的“大家来找茬”职业病,在生活中有多可怕?
在软件测试领域,“大家来找茬”不仅是日常工作核心,更可能演变为一种无形的职业病——长期专注于缺陷发现,这种思维模式悄然渗透到生活各个角落,引发一系列连锁反应。软件测试工程师作为产品质量的守门人,习惯于在代码…...

从“相爱相杀”到“黄金三角”——将协同能力打造为个人与团队的核心竞争力
该文章同步至OneChan ——在芯片开发的复杂系统中,成为不可替代的连接者与放大器 当单个技术专家的个人英雄主义让位于系统性的团队协同,你所在的团队就具备了征服最复杂芯片挑战的终极武器。 引言:那个“全明星”团队的溃败 我曾见证过一个…...

uni-app中H5页面通过web-view跳转小程序的完整解决方案
1. 为什么H5页面跳转小程序会报错? 最近在做一个uni-app项目时,遇到了一个典型问题:在H5页面中通过web-view跳转小程序时,控制台报错"wx.miniProgram is undefined"或者"navigateTo is undefined"。这个问题困…...