RAC 下expdp impdp 并行 parallel FK
1. dump 文件非共享下的并行
Customer receives the following errors:
ORA-31693: Table data object "<SCHEMA_NAME>"."<TABLE_NAME>" failed to load/unload and is being skipped due to error:
ORA-31617: unable to open dump file "<dumpfile name and path>" for write
ORA-19505: failed to identify file "<dumpfile name and path>"
ORA-27037: unable to obtain file status
Solaris-AMD64 Error: 2: No such file or directory
Additional information: 3
Note:
It is possible for this to occur on other operating systems since it is a mount point. The OS specific errors may therefore be different.
CHANGES
CAUSE
The problem occurs when Datapump Export is being performed on a multi-node RAC where the dumpfile destination is not shared to all nodes for access. Since multiple nodes will be running the Datapump job, ALL nodes must have access to the mount point where the dump file will be written.
The issue is addressed in the following bug report which was closed with status 'Not a Bug':
Bug 11677316 - DATA PUMP UNABLE TO OPEN DUMP FILE ORA-31617 ORA-19505 ORA-27037
SOLUTION
1. Share/mount the dumpfile destination with all RAC nodes performing the expdp
- OR -
2. Use CLUSTER=N during Datapump so it will only run on the node which has the mount point and permissions to write to it.
2. FK imp默认没有先后顺序,需要手动disable FK
Errors like the following are reported in the DataPump import log:
ORA-31693: Table data object "<SCHEMA_NAME>"."<TABLE_NAME>" failed to load/unload and is being skipped due to error:
ORA-2291: integrity constraint ("<SCHEMA_NAME>"."<FK_CONSTRAINT_NAME>") violated - parent key not found
The issue can be reproduced with the following test case:
-- create tables (schema <SCHEMA_NAME>)
CREATE TABLE DEPT
(
DEPTNO NUMBER(2) CONSTRAINT PK_DEPT PRIMARY KEY,
DNAME VARCHAR2(14),
LOC VARCHAR2(13)
);
CREATE TABLE EMP
(
EMPNO NUMBER(4) CONSTRAINT PK_EMP PRIMARY KEY,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) CONSTRAINT FK_DEPTNO REFERENCES fDEPT
);
-- run the import
#> impdp dumpfile=const.dmp logfile=constimp.log REMAP_SCHEMA=<SOURCE_SCHEMA>:<TARGET_SCHEMA> TABLE_EXISTS_ACTION= APPEND
You may receive errors like:
ORA-31693: Table data object "<SCHEMA_NAME>"."<TABLE_NAME>" failed to load/unload and is being skipped due to error:
ORA-2291: integrity constraint ("<SCHEMA_NAME>"."<FK_CONSTRAINT_NAME>") violated - parent key not found
. . imported "<SCHEMA_NAME>"."<TABLE_NAME>" 5.656 KB 4 rows imported
CHANGES
CAUSE
This issue is documented in
Bug 6242277 - DATA PUMP IMPORTS FIRST CHILD ROWS AND THEN PARENT ROWS
closed with status 'Not a Bug'.
SOLUTION
This is an expected behavior already documented in Oracle utilities guide:
Data Pump Import
Please also refer to Oracle® Database Utilities 11g Release 2 (11.2)
Part Number E22490-04
To implement the solution, please use any of the following alternatives:
- If you have data that must be loaded but may cause constraint violations, consider disabling the constraints, loading the data, and then deleting the problem rows before reenabling the constraints
- OR -
- Import the tables separately
3 PARTITION_OPTIONS=MERGE分区表变non 分区表
How to convert a partitioned table to a non-partitioned table using DataPump.
SOLUTION
A new import DataPump parameter PARTITION_OPTIONS has been introduced with 11g. The allowed values are:
NONE - Creates tables as they existed on the system from which the export operation was performed. This is the default value.
DEPARTITION - Promotes each partition or subpartition to a new individual table. The default name of the new table will be the concatenation of the table and partition name or the table and subpartition name, as appropriate.
MERGE - Combines all partitions and subpartitions into one table.
The parameter PARTITION_OPTIONS specifies how table partitions should be created during an import operation. To convert a partitioned table to a non-partitoned table we have to use PARTITION_OPTIONS=MERGE during the process of import.
The below example illustrates how to convert partitioned table to a non-partitioned table using expdp/impdp.
1. Create a partitioned table and insert values into the partitioned table
connect scott/<PASSWORD>
create table part_tab
(
year number(4),
product varchar2(10),
amt number(10,2)
)
partition by range (year)
(
partition p1 values less than (1992) tablespace u1,
partition p2 values less than (1993) tablespace u2,
partition p3 values less than (1994) tablespace u3,
partition p4 values less than (1995) tablespace u4,
partition p5 values less than (MAXVALUE) tablespace u5
);
select * from PART_TAB;
YEAR PRODUCT AMT
---------- ---------- ----------
1992 p1 100
1993 p2 200
1994 p3 300
1995 p4 400
2010 p5 500
select OWNER, TABLE_NAME, PARTITIONED
from dba_tables
where table_name = 'PART_TAB' and owner = 'SCOTT';
OWNER TABLE_NAME PAR
------------------------------ ---------- ---
SCOTT PART_TAB YES
select TABLE_OWNER, TABLE_NAME, PARTITION_NAME, TABLESPACE_NAME
from dba_tab_partitions
where TABLE_NAME = 'PART_TAB' and TABLE_OWNER = 'SCOTT';
TABLE_OWNER TABLE_NAME PARTITION_ TABLESPACE
------------------------------ ---------- ---------- ----------
SCOTT PART_TAB P1 U1
SCOTT PART_TAB P2 U2
SCOTT PART_TAB P3 U3
SCOTT PART_TAB P4 U4
SCOTT PART_TAB P5 U5
2. Export the partitioned table:
#> expdp TABLES=scott.part_tab USERID="' / as sysdba'" DIRECTORY=test_dir DUMPFILE=part_tab.dmp LOGFILE=part_tab.log
Export: Release 11.2.0.2.0 - Production on Thu Dec 23 08:27:24 2010
Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
Starting "SYS"."SYS_EXPORT_TABLE_01": TABLES=scott.part_tab USERID="/******** AS SYSDBA" DIRECTORY=test_dir DUMPFILE=part_tab.dmp LOGFILE=part_tab.log
Estimate in progress using BLOCKS method...
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
Total estimation using BLOCKS method: 32 MB
Processing object type TABLE_EXPORT/TABLE/TABLE
. . exported "SCOTT"."PART_TAB":"P2" 5.898 KB 1 rows
. . exported "SCOTT"."PART_TAB":"P3" 5.898 KB 1 rows
. . exported "SCOTT"."PART_TAB":"P4" 5.898 KB 1 rows
. . exported "SCOTT"."PART_TAB":"P5" 5.914 KB 2 rows
. . exported "SCOTT"."PART_TAB":"P1" 0 KB 0 rows
Master table "SYS"."SYS_EXPORT_TABLE_01" successfully loaded/unloaded
******************************************************************************
Dump file set for SYS.SYS_EXPORT_TABLE_01 is:
/tmp/part_tab.dmp
Job "SYS"."SYS_EXPORT_TABLE_01" successfully completed at 08:28:02
3. Import the table in user "USER2" to convert the partitioned table into a non-partitioned table:
#> impdp USERID="'/ as sysdba'" TABLES=scott.part_tab DIRECTORY=test_dir DUMPFILE=part_tab.dmp LOGFILE=imp_part_tab.log REMAP_SCHEMA=scott:user2 PARTITION_OPTIONS=merge
Import: Release 11.2.0.2.0 - Production on Thu Dec 23 08:39:08 2010
Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
Master table "SYS"."SYS_IMPORT_TABLE_01" successfully loaded/unloaded
Starting "SYS"."SYS_IMPORT_TABLE_01": USERID="/******** AS SYSDBA" TABLES=scott.part_tab DIRECTORY=test_dir DUMPFILE=part_tab.dmp LOGFILE=imp_part_tab.log REMAP_SCHEMA=scott:user2 PARTITION_OPTIONS=merge
Processing object type TABLE_EXPORT/TABLE/TABLE
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
. . imported "USER2"."PART_TAB":"P2" 5.898 KB 1 rows
. . imported "USER2"."PART_TAB":"P3" 5.898 KB 1 rows
. . imported "USER2"."PART_TAB":"P4" 5.898 KB 1 rows
. . imported "USER2"."PART_TAB":"P5" 5.914 KB 2 rows
. . imported "USER2"."PART_TAB":"P1" 0 KB 0 rows
Job "SYS"."SYS_IMPORT_TABLE_01" successfully completed at 08:39:17
select * from user2.part_tab;
YEAR PRODUCT AMT
---------- ---------- ----------
1992 p1 100
1993 p2 200
1994 p3 300
1995 p4 400
2010 p5 500
select OWNER, TABLE_NAME, PARTITIONED
from dba_tables
where table_name = 'PART_TAB' and owner = 'USER2';
OWNER TABLE_NAME PAR
------------------------------ ---------- ---
USER2 PART_TAB NO
select TABLE_OWNER, TABLE_NAME, PARTITION_NAME, TABLESPACE_NAME
from dba_tab_partitions
where TABLE_NAME = 'PART_TAB' and TABLE_OWNER = 'USER2';
no rows selected
Note:
------
If there is a local or global prefixed index created on the partitioned table, import with PARTITION_OPTIONS=merge also converts the index to non-partitioned.
- local prefixed index:
CREATE INDEX part_tab_loc_idx ON part_tab(year) LOCAL;
After import with REMAP_SCHEMA=scott:user2 PARTITION_OPTIONS=merge, the local prefixed index is also converted to a non-partitioned index:
select OWNER, INDEX_NAME, PARTITIONED
from dba_indexes
where index_name='PART_TAB_GLOB_IDX';
OWNER INDEX_NAME PAR
---------- -------------------- ---
SCOTT PART_TAB_LOC_IDX YES
USER2 PART_TAB_LOC_IDX NO
-or-
- global prefixed index: global index 但是分区
CREATE INDEX part_tab_glob_idx ON part_tab(year)
GLOBAL PARTITION BY RANGE (year)
(partition p1 values less than (1992),
partition p2 values less than (1993),
partition p3 values less than (1994),
partition p4 values less than (1995),
partition p5 values less than (MAXVALUE)
);
After import with REMAP_SCHEMA=scott:user2 PARTITION_OPTIONS=merge, the local prefixed index is also converted to a non-partitioned index:
select OWNER, INDEX_NAME, PARTITIONED
from dba_indexes
where index_name='PART_TAB_GLOB_IDX';
OWNER INDEX_NAME PAR
---------- -------------------- ---
SCOTT PART_TAB_GLOB_IDX YES
USER2 PART_TAB_GLOB_IDX NO
-----------------------------
Describes the tablespace for objects created using PARTITION_OPTIONS=MERGE with IMPDP.
SOLUTION
Using PARTITION_OPTIONS=MERGE, all partitions and subpartitions are merged into a single table.
The tables and indexes will be created using the default tablespace of the import target user.
example:
# Object configuration of source DB
SQL> select username, default_tablespace from dba_users where username = 'TEST';
USERNAME DEFAULT_TABLESPACE
-------------------- --------------------
TEST USERS
SQL> select segment_name, partition_name, segment_type, tablespace_name from dba_segments where owner = 'TEST' order by 1,2;
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE TABLESPACE_NAME
-------------------- -------------------- -------------------- --------------------
T1 P1 TABLE PARTITION TESTTS
T1 P2 TABLE PARTITION TESTTS
T1_I_L P1 INDEX PARTITION TESTTS
T1_I_L P2 INDEX PARTITION TESTTS
# expdp command
expdp test/test directory=tmp_dir dumpfile=part.dmp
# impdp command
impdp test/test directory=tmp_dir dumpfile=part.dmp partition_options=merge
# Object configuration of target DB
SQL> select username, default_tablespace from dba_users where username = 'TEST';
USERNAME DEFAULT_TABLESPACE
-------------------- --------------------
TEST USERS
SQL> select segment_name, partition_name, segment_type, tablespace_name from dba_segments where owner = 'TEST' order by 1,2;
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE TABLESPACE_NAME
-------------------- -------------------- -------------------- --------------------
T1 TABLE USERS
T1_I_L INDEX USERS
If you want the tablespace use with objects to be other than the default tablespace for user, use one of the following options:
a)
a-1) Pre-create objects (tables and indexes) in a non-partitioned configuration
a-2) Run impdp
or
b)
b-1) Run impdp
b-2) Change the tablespace with "alter table ... move" and "alter index ... rebuild"
----------------------merge的坑
SYMPTOMS
If table gets loaded when target table pre-exists and PARTITION_OPTIONS=MERGE and TABLE_EXISTS_ACTION=SKIP is specified in par file or command line, duplicate rows are created.
Although IMPDP honors the skip request, the table data is imported again when PARTITION_OPTIONS=MERGE is specified.
Simple test case scenario :
+++ Create simple table, insert some data and export the table.
+++ Import the table using TABLE_EXISTS_ACTION=SKIP and PARTITION_OPTIONS=MERGE = One row is loaded
+++ Import the table again using TABLE_EXISTS_ACTION=SKIP and PARTITION_OPTIONS=MERGE = The rows is loaded again
+++ Duplicate rows are created if we import again from the same set of data.
Job IMPORT_1
============
impdp user/pwd@myinstance parfile=myfile.par
job_name=IMPORT_1
logfile=mylogfile.log
dumpfile=mydump.DMP
directory=data_pump_dir
TABLE_EXISTS_ACTION=SKIP <<<<<<<<<<<<<<<<<<<<
PARTITION_OPTIONS=MERGE <<<<<<<<<<<<<<<<<<<<
schemas=SCHEMA
include=TABLE:"='mytable'"
Import: Release 18.0.0.0.0 - Production on Tue Apr 2 17:38:21 2019
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production
Master table "USER"."IMPORT_1" successfully loaded/unloaded
Starting "USER"."IMPORT_1": USER/********@myinstance parfile=myfile.par
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
. . imported "SCHEMA"."mytable" 5.062 KB 1 rows <<<<<<<<<<<<<<<<< 1 row uploaded
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "USER"."IMPORT_1" successfully completed at Tue Apr 2 14:39:09 2019 elapsed 0 00:00:33
SQL> select * from SCHEMA.mytable;
V1
----------
RECORD 01 <<<<<<<<<<<<<<<<< one row
Job IMPORT_2 duplicates the row - the issue does reproduce
==========================================================
impdp user/pwd@myinstance parfile=myfile.par
job_name=IMPORT_2
logfile=mylogfile.log
dumpfile=mydump.DMP
directory=data_pump_dir
TABLE_EXISTS_ACTION=SKIP <<<<<<<<<<<<<<<<<<<<
PARTITION_OPTIONS=MERGE <<<<<<<<<<<<<<<<<<<<
schemas=SCHEMA
include=TABLE:"='mytable'"
Import: Release 18.0.0.0.0 - Production on Tue Apr 2 17:41:07 2019
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production
Master table "USER"."IMPORT_2" successfully loaded/unloaded
Starting "USER"."IMPORT_2": USER/********@myinstance parfile=myfile.par
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Table "SCHEMA"."mytable" exists. All dependent metadata and data will be skipped due to table_exists_action of skip <<<<<<<<
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
. . imported "SCHEMA"."mytable" 5.062 KB 1 rows <<<<<<<<<<<<<<<< again 1 row uploaded
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "USER"."IMPORT_2" successfully completed at Tue Apr 2 14:41:55 2019 elapsed 0 00:00:34
SQL> select * from SCHEMA.mytable;
V1
----------
RECORD 01 <<<<<<<<<<<<<<<<<<<<<<< duplicate record is inserted
RECORD 01
Job IMPORT_3 doesn't introduce the problem if PARTITION_OPTIONS=MERGE is skipped:
=======================================================================================
impdp user/pwd@myinstance parfile=myfile.par
job_name=IMPORT_3
logfile=mylogfile.log
dumpfile=mydump.DMP
directory=data_pump_dir
TABLE_EXISTS_ACTION=SKIP <<<<<<<<<<
schemas=SCHEMA
include=TABLE:"='mytable'"
Import: Release 18.0.0.0.0 - Production on Tue Apr 2 17:55:54 2019
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production
Master table "USER"."IMPORT_3" successfully loaded/unloaded
Starting "USER"."IMPORT_3": USER/********@myinstance parfile=myfile.par
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Table "SCHEMA"."mytable" exists. All dependent metadata and data will be skipped due to table_exists_action of skip
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "USER"."IMPORT_3" successfully completed at Tue Apr 2 14:56:39 2019 elapsed 0 00:00:31
Only two rows reported from previous IMPORT_2 job
Job IMPORT_3 did not upload any row
===================================================
SQL> select * from SCHEMA.mytable;
V1
----------
RECORD 01 <<<<<<<<
RECORD 01 <<<<<<<<
Job IMPORT_4 doesn't introduce the problem if using PARTITION_OPTIONS=MERGE and TABLE_EXISTS_ACTION=TRUNCATE:
=============================================================================================================
impdp user/pwd@myinstance parfile=myfile.par
job_name=IMPORT_4
logfile=mylogfile.log
dumpfile=mydump.DMP
directory=data_pump_dir
TABLE_EXISTS_ACTION=TRUNCATE <<<<<<<<<<<
PARTITION_OPTIONS=MERGE <<<<<<<<<<<
schemas=SCHEMA
include=TABLE:"='mytable'"
Import: Release 18.0.0.0.0 - Production on Tue Apr 2 18:29:08 2019
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production
Master table "USER"."IMPORT_4" successfully loaded/unloaded
Starting "USER"."IMPORT_4": USER/********@myinstance parfile=myfile.par
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Table "SCHEMA"."mytable" exists and has been truncated. Data will be loaded but all dependent metadata will be skipped due to table_exists_action of truncate
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
. . imported "SCHEMA"."mytable" 5.062 KB 1 rows <<<<<<<<<<<
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "USER"."IMPORT_4" successfully completed at Tue Apr 2 15:30:01 2019 elapsed 0 00:00:38
Only two rows reported from previous IMPORT_2 job
Job IMPORT_4 did not upload any row
===================================================
SQL> select * from SCHEMA.mytable;
V1
----------
RECORD 01 <<<<<<<<<
RECORD 01 <<<<<<<<<
CHANGES
N/a
CAUSE
This is due to unpublished BUG 27495407 - DP IMPORT LOADS INTO PRE-EXISTING TABLE WITH PARTITION_OPTIONS=MERGE.
SOLUTION
To solve this issue, use any of alternatives below:
1) Make sure the target table does not pre-exist before the import.
- or -
2) Remove PARTITION_OPTIONS=MERGE parameter.
- or -
3) Change table_exists_action to something other than SKIP(default). For example use TABLE_EXISTS_ACTION=TRUNCATE if feasible.
- or -
4) Apply one off < Patch 27495407> if available for your platform and version.
- or -
5) Upgrade to 20.1 where the fix for unpublished Bug 27495407 is included.
相关文章:

RAC 下expdp impdp 并行 parallel FK
1. dump 文件非共享下的并行 Customer receives the following errors: ORA-31693: Table data object "<SCHEMA_NAME>"."<TABLE_NAME>" failed to load/unload and is being skipped due to error: ORA-31617: unable to open dump file &qu…...
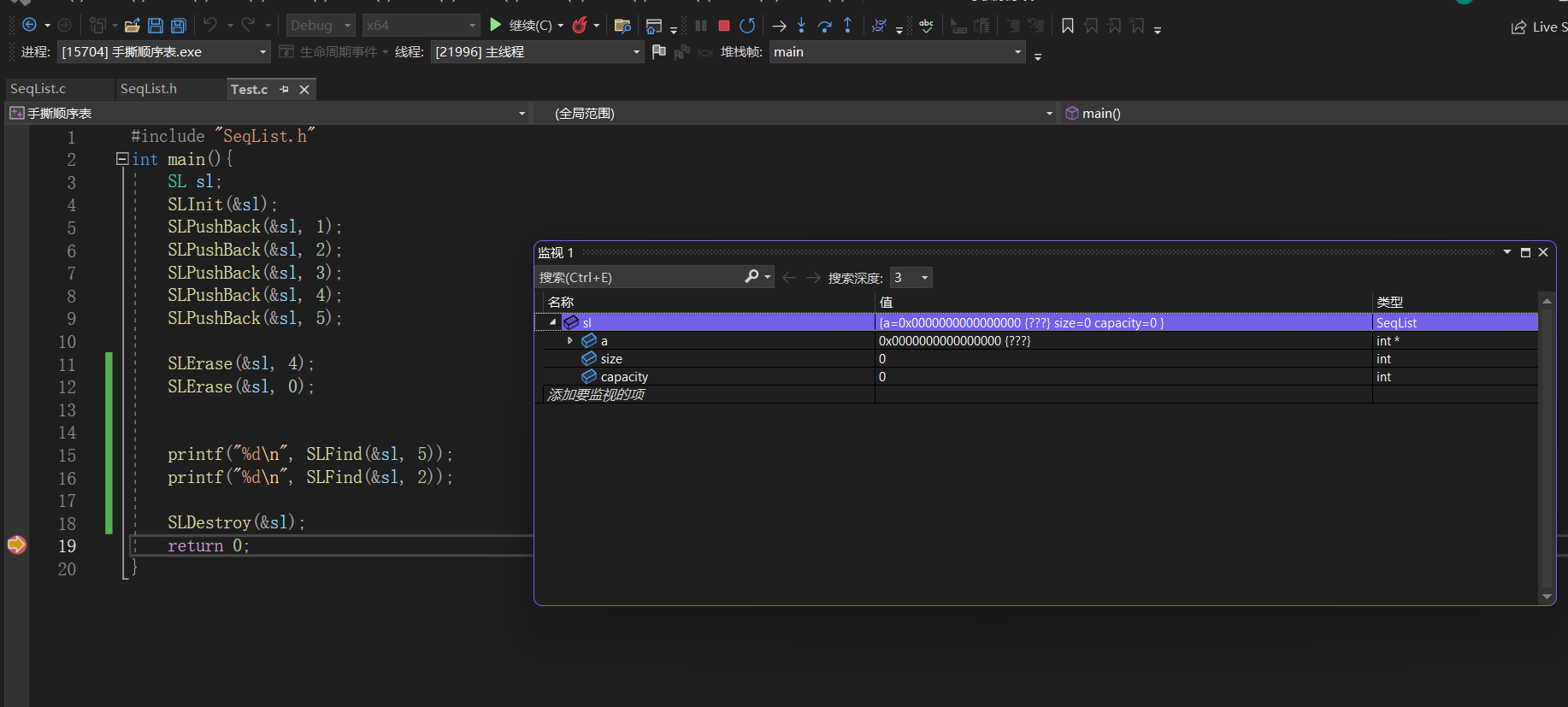
【数据结构】动态顺序表详解
目录 1.顺序表的概念及结构 2.动态顺序表的实现 2.1创建新项目 2.2动态顺序表的创建 2.3接口的实现及测其功能 2.3.1初始化 2.3.2尾插 2.3.3头插 2.3.4尾删&头删 2.3.5打印&从任意位置插入 2.3.6删除任意位置的数据 2.3.7查找 2.3.8销毁顺序表 3.结语 He…...

Nginx代理https请求的操作过程
理论很简单,过程很曲折,版本适配的问题要小心。 场景: 要和前端进行联调,我本地后端用了https,证书是自制的,主要是页面里面有一些oauth2认证的地方,需要跳转。 比如https://aaa.com/profile.h…...

Linux 面试题(一)
目录 1、绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令? 2、怎么查看当前进程?怎么执行退出?怎么查看当前路径? 3、怎么清屏?怎么退出当前命…...

HIVE SQL取整函数汇总
目录 int()round(double a)round(double a,int d)floor()ceil() int() 向零取整,即向接近零的方向取整。 int(5.6)输出:5 int(-5.6)输出:-5 round(double a) 四舍五入取整 select round(5.6)输出:6 select round(-5.6)输出&…...

VMware 虚拟机设置静态IP
1.桥接模式:无线网卡虚拟机可以桥接的,Vmware0是虚拟机默认进入的虚拟网络,打开虚拟网络编辑器把Vmware0桥接到具体的无线网卡上,再打开网卡设置选择桥接模式即可。 2、.NAT模式下 :window下VMnet8: IPv4 地址 . . . …...

pandas 如何获取dataframe的行的数量
pandas的dataframe提供了多种方法获取其中数据的行的数量,本偏文章就是介绍几种获取dataframe行和列出量的方法。 为了能够详细说明如何通过代码获取dataframe的行数和列数,需要先创建一个dataframe如下: import pandas as pdtechnologies …...

css实现图片绕中心旋转,鼠标悬浮按钮炫酷展示
vue模板中代码 <div class"contentBox clearfix home"><div class"circle"><img class"in-circle" src"../../assets/img/in-circle.png" alt""><img class"out-circle" src"../../as…...

C++11的线程
线程的创建 用std::thread创建线程非常简单,只需要提供线程函数或者线程对象即可,并可以同时指定线程函数的参数。下面是创建线程的示例: #include <thread> #include <iostream> using namespace std;void func() {cout <<…...

Deepmind开发音频模型Lyria 用于生成高品质音乐;创建亚马逊新产品评论摘要
🦉 AI新闻 🚀 Deepmind开发音频模型Lyria 用于生成高品质音乐 摘要:Deepmind推出名为Lyria的音频模型,可生成带有乐器和人声的高品质音乐。Lyria模型针对音乐生成的挑战,解决了音乐信息密度高、音乐序列中的连续性维…...
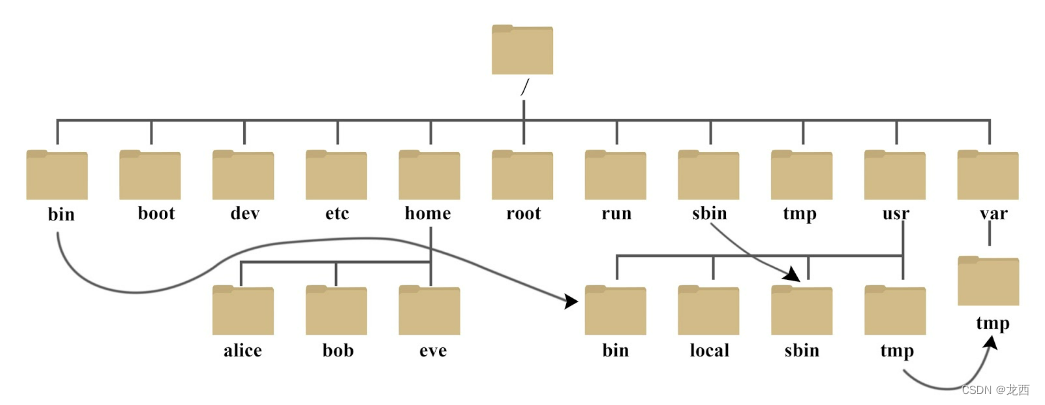
Liunx系统使用超详细(一)
目录 一、Liunx系统的认识 二、Liunx和Windows区别 三、Liunx命令提示符介绍 四、Liunx目录结构 一、Liunx系统的认识 Linux系统是一种开源的、类Unix操作系统内核的实现,它基于Unix的设计原理和思想,并在全球范围内广泛应用。以下是对Linux系统的详…...
C语言标准
1、概述 C语言标准是由ANSI(美国国家标准协会)和ISO(国际标准化组织)共同制定的一种语言规范。标准经历过如下更新: C89/C90标准C99标准C11标准C17标准 2、C89/C90标准 (1)这是1989年正式发布的C语言标准࿰…...

TI 毫米波雷达开发系列之mmWave Studio 和 Visuiallizer 的异同点雷达影响因素分析
TI 毫米波雷达开发之mmWave Studio 和 Visuiallizer 的异同点 引入整个雷达系统研究的目标分析影响这个目标的因素硬件影响因素 —— 雷达系统的硬件结构(主要是雷达收发机)AWR1642芯片硬件系统组成MSS 和 DSS 概述MSS 和 DSS 分工BSS的分工AWR1642 组成…...
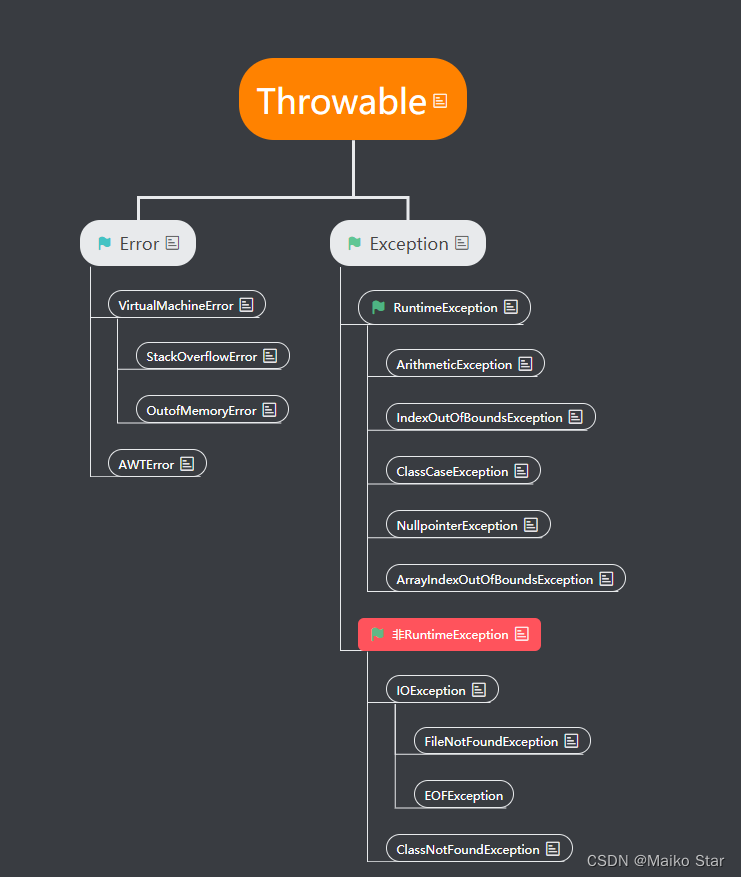
SpringBoot事务处理
一、事务回顾 回顾地址: 深入理解数据库事务(超详细)_数据库事务操作_Maiko Star的博客-CSDN博客 事务: 是一组操作的集合,是一个不可分割的工作单位,这些操作要么同时成功,要么同时失败 事…...

网络安全—自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...
)
首页以卡片形式来展示区块链列表数据(Web3项目一实战之五)
我们已然在 Web3 分布式存储 IPFS(Web3项目一实战之四) 介绍了什么是IPFS,以及在本地电脑如何安装它。虽然在上一篇讲解了该怎么安装IPFS,也做了相应的配置,但在本地开发阶段,前端总是无法避免跨域这个远程请求api的”家常便饭的通病“。 很显然,对于出现跨域这类常见问…...
)
opencv使用pyinstaller打包错误:‘can‘t find starting number (in the name of file)
使用Python语言和opencv模块在pycharm中编辑的代码运行没问题,但是在使用pyinstaller打包后出现错误can‘t find starting number (in the name of file) [ERROR:0] global C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-q3d_8t8e\opencv\modules\videoi…...

4.一维数组——用数组处理求Fibonacci数列前20项
文章目录 前言一、题目描述 二、题目分析 三、解题 程序运行代码 四、结果显示 前言 本系列为一维数组编程题,点滴成长,一起逆袭。 一、题目描述 用数组处理求Fibonacci数列前20项 二、题目分析 前两项:f[20]{1,1} 后18项:for(…...
讯飞星火知识库文档问答Web API的使用(二)
上一篇提到过星火spark大模型,现在有更新到3.0: 给ChuanhuChatGPT 配上讯飞星火spark大模型V2.0(一) 同时又看到有知识库问答的web api,于是就测试了一下。 下一篇是在ChuanhuChatGPT 中单独写一个基于星火知识库的内容…...
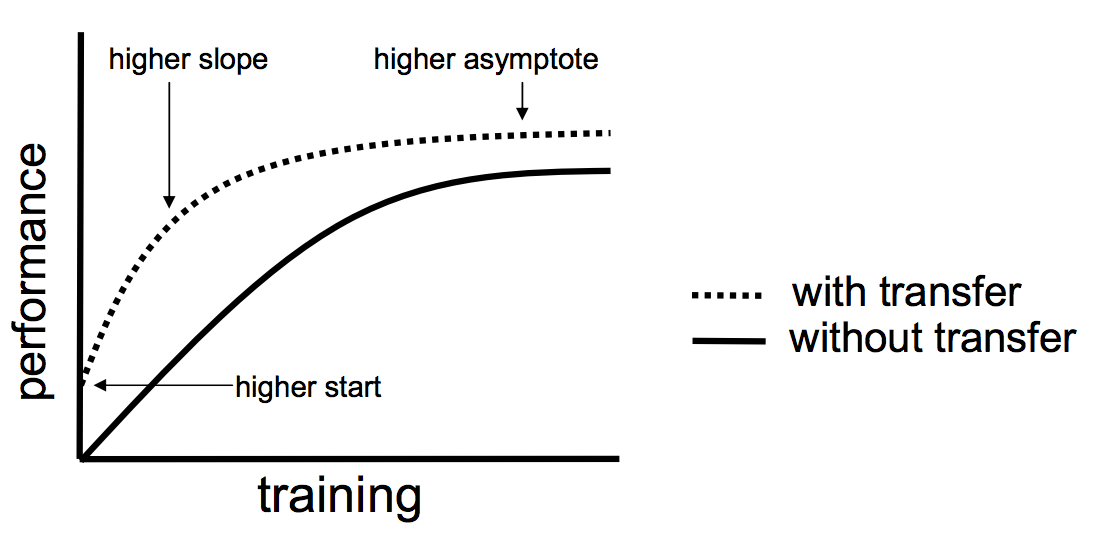
第十三章 深度解读预训练与微调迁移,模型冻结与解冻(工具)
一个完整的代码 pythonCopy codeimport torch import torchvision import torchvision.transforms as transforms import torch.nn as nn import torch.optim as optim # 设置设备(CPU或GPU) device torch.device("cuda" if torch.cuda.is_a…...

拆穿名词诈骗!用大白话理解晦涩难懂的AI概念褐
1. 架构背景与演进动力 1.1 从单体到碎片化:.NET 的开源征程 在.NET Framework 时代,构建系统主要围绕 Windows 操作系统紧密集成,采用传统的封闭式开发模式。然而,随着.NET Core 的推出,微软开启了彻底的开源与跨平台…...

嵌入式传感器抽象框架:ArduSensorPlatformCoreBase核心解析
1. ArduSensorPlatformCoreBase 框架核心组件深度解析ArduSensorPlatformCoreBase 是 ArdusensorPlatform 框架的底层基石模块,其定位并非通用传感器驱动集合,而是为构建可扩展、可复用、跨平台的嵌入式传感系统提供标准化抽象层与基础设施支撑。该模块不…...

5分钟搭建通义千问3-VL-Reranker:多模态重排序Web UI教程
5分钟搭建通义千问3-VL-Reranker:多模态重排序Web UI教程 1. 什么是多模态重排序?它能帮你解决什么问题? 想象一下这个场景:你在一个电商平台搜索“带花园的白色小房子”,搜索结果里蹦出来一堆东西——有商品描述文字…...
,错过再无官方授权分发)
【最后72小时解锁】SITS2026联邦学习工作坊原始代码包+训练轨迹可视化Dashboard(含PyTorch/FedNLP/SecureAgg三框架适配版),错过再无官方授权分发
第一章:SITS2026演讲:大模型联邦学习应用 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026主会场,来自MIT与华为诺亚方舟实验室的联合团队展示了基于LLaMA-3架构的大模型联邦学习新范式——FedLLM。该方案突破传统参数平均&#x…...

FastAPI项目半夜报警吵醒你?聊聊告警这事儿怎么搞!囤
Issue 概述 先来看看提交这个 Issue 的作者是为什么想到这个点子的,以及他初步的核心设计概念。?? 本 PR 实现了 Apache Gravitino 与 SeaTunnel 的集成,将其作为非关系型连接器的外部元数据服务。通过 Gravitino 的 REST API 自动获取表结构和元数据&…...

别再让CPU拖后腿!用CUDA Graph优化PyTorch/TensorFlow推理,实测性能提升5倍
解锁GPU潜能:用CUDA Graph重构深度学习推理流水线 当你的AI服务在高峰期响应延迟飙升时,很可能是CPU正在拖累GPU的算力发挥。想象一下这样的场景:每秒处理数百张图片的识别API,GPU利用率却始终徘徊在30%以下;或者一个本…...

Z-Image-Turbo_Sugar脸部Lora一文详解:Lora微调原理、基础模型关系与使用边界
Z-Image-Turbo_Sugar脸部Lora一文详解:Lora微调原理、基础模型关系与使用边界 你是不是也遇到过这样的烦恼:想用AI生成特定风格的人像,比如那种清透甜美的“糖系”脸蛋,但用通用的大模型试了半天,出来的效果总是不对味…...
)
Langchain实战:如何用ChatGLM-4搭建你的第一个AI对话机器人(附完整代码)
Langchain实战:如何用ChatGLM-4搭建你的第一个AI对话机器人(附完整代码) 最近两年,大模型技术以惊人的速度渗透到各个领域。从智能客服到内容创作,从代码生成到数据分析,AI对话机器人正在重塑人机交互的方式…...
小红背单词【牛客tracker 每日一题】
小红背单词 时间限制:1秒 空间限制:256M 知识点:小红书 哈希模拟 网页链接 牛客tracker 牛客tracker & 每日一题,完成每日打卡,即可获得牛币。获得相应数量的牛币,能在【牛币兑换中心】࿰…...

cMedQA2中文医疗问答数据集:构建智能医疗助手的完整实战指南
cMedQA2中文医疗问答数据集:构建智能医疗助手的完整实战指南 【免费下载链接】cMedQA2 This is updated version of the dataset for Chinese community medical question answering. 项目地址: https://gitcode.com/gh_mirrors/cm/cMedQA2 cMedQA2是一个专为…...