卷积神经网络(CNN)车牌识别
文章目录
- 一、前言
- 二、前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 2. 导入数据
- 3. 查看数据
- 3.数据可视化
- 4.标签数字化
- 二、构建一个tf.data.Dataset
- 1.预处理函数
- 2.加载数据
- 3.配置数据
- 三、搭建网络模型
- 四、设置动态学习率
- 五、编译
- 六、训练
- 八、保存和加载模型
- 九、预测
一、前言
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
往期精彩内容:
- 卷积神经网络(CNN)实现mnist手写数字识别
- 卷积神经网络(CNN)多种图片分类的实现
- 卷积神经网络(CNN)衣服图像分类的实现
- 卷积神经网络(CNN)鲜花识别
- 卷积神经网络(CNN)天气识别
- 卷积神经网络(VGG-16)识别海贼王草帽一伙
- 卷积神经网络(ResNet-50)鸟类识别
- 卷积神经网络(AlexNet)鸟类识别
- 卷积神经网络(CNN)识别验证码
- 卷积神经网络(Inception-ResNet-v2)交通标志识别
来自专栏:机器学习与深度学习算法推荐
二、前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")
2. 导入数据
数据集链接
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL,random,pathlib# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
data_dir = "015_licence_plate"
data_dir = pathlib.Path(data_dir)pictures_paths = list(data_dir.glob('*'))
pictures_paths = [str(path) for path in pictures_paths]
pictures_paths[:3]
3. 查看数据
image_count = len(list(pictures_paths))print("图片总数为:",image_count)
图片总数为: 13056
# 获取数据标签
all_label_names = [path.split("_")[-1].split(".")[0] for path in pictures_paths]
all_label_names[:3]
['川W9BR26', '沪E264UD', '浙E198UJ']
3.数据可视化
plt.figure(figsize=(10,5))
plt.suptitle("数据示例",fontsize=15)for i in range(20):plt.subplot(5,4,i+1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片images = plt.imread(pictures_paths[i])plt.imshow(images)# 显示标签plt.xlabel(all_label_names[i],fontsize=13)plt.show()

4.标签数字化
char_enum = ["京","沪","津","渝","冀","晋","蒙","辽","吉","黑","苏","浙","皖","闽","赣","鲁",\"豫","鄂","湘","粤","桂","琼","川","贵","云","藏","陕","甘","青","宁","新","军","使"]number = [str(i) for i in range(0, 10)] # 0 到 9 的数字
alphabet = [chr(i) for i in range(65, 91)] # A 到 Z 的字母char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(all_label_names[0])# 将字符串数字化
def text2vec(text):vector = np.zeros([label_name_len, char_set_len])for i, c in enumerate(text):idx = char_set.index(c)vector[i][idx] = 1.0return vectorall_labels = [text2vec(i) for i in all_label_names]
二、构建一个tf.data.Dataset
1.预处理函数
def preprocess_image(image):image = tf.image.decode_jpeg(image, channels=1)image = tf.image.resize(image, [50, 200])return image/255.0def load_and_preprocess_image(path):image = tf.io.read_file(path)return preprocess_image(image)
2.加载数据
构建 tf.data.Dataset 最简单的方法就是使用 from_tensor_slices 方法。
AUTOTUNE = tf.data.experimental.AUTOTUNEpath_ds = tf.data.Dataset.from_tensor_slices(pictures_paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
label_ds = tf.data.Dataset.from_tensor_slices(all_labels)image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
image_label_ds
train_ds = image_label_ds.take(5000).shuffle(5000) # 前1000个batch
val_ds = image_label_ds.skip(5000).shuffle(1000) # 跳过前1000,选取后面的
3.配置数据
BATCH_SIZE = 16train_ds = train_ds.batch(BATCH_SIZE)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
val_ds
三、搭建网络模型
目前这里主要是带大家跑通代码、整理一下思路,大家可以自行优化网络结构、调整模型参数。后续我也会针对性的出一些调优的案例的。
from tensorflow.keras import datasets, layers, modelsmodel = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(50, 200, 1)),#卷积层1,卷积核3*3layers.MaxPooling2D((2, 2)), #池化层1,2*2采样layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3layers.MaxPooling2D((2, 2)), #池化层2,2*2采样layers.Flatten(), #Flatten层,连接卷积层与全连接层
# layers.Dense(1000, activation='relu'), #全连接层,特征进一步提取layers.Dense(1000, activation='relu'), #全连接层,特征进一步提取layers.Dropout(0.3), layers.Dense(label_name_len * char_set_len),layers.Reshape([label_name_len, char_set_len]),layers.Softmax() #输出层,输出预期结果
])
# 打印网络结构
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 48, 198, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 24, 99, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 22, 97, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 11, 48, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 33792) 0
_________________________________________________________________
dense (Dense) (None, 1000) 33793000
_________________________________________________________________
dropout (Dropout) (None, 1000) 0
_________________________________________________________________
dense_1 (Dense) (None, 483) 483483
_________________________________________________________________
reshape (Reshape) (None, 7, 69) 0
_________________________________________________________________
softmax (Softmax) (None, 7, 69) 0
=================================================================
Total params: 34,295,299
Trainable params: 34,295,299
Non-trainable params: 0
_________________________________________________________________
四、设置动态学习率
这里先罗列一下学习率大与学习率小的优缺点。
- 学习率大
- 优点: 1、加快学习速率。 2、有助于跳出局部最优值。
- 缺点: 1、导致模型训练不收敛。 2、单单使用大学习率容易导致模型不精确。
- 学习率小
- 优点: 1、有助于模型收敛、模型细化。 2、提高模型精度。
- 缺点: 1、很难跳出局部最优值。 2、收敛缓慢。
注意:这里设置的动态学习率为:指数衰减型(ExponentialDecay)。在每一个epoch开始前,学习率(learning_rate)都将会重置为初始学习率(initial_learning_rate),然后再重新开始衰减。计算公式如下:
learning_rate = initial_learning_rate * decay_rate ^ (step / decay_steps)
# 设置初始学习率
initial_learning_rate = 1e-3lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate, decay_steps=50, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
五、编译
model.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
六、训练
epochs = 50history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
八、保存和加载模型
# 保存模型
model.save('model/15_model.h5')
# 加载模型
new_model = tf.keras.models.load_model('model/15_model.h5')
九、预测
def vec2text(vec):"""还原标签(向量->字符串)"""text = []for i, c in enumerate(vec):text.append(char_set[c])return "".join(text)plt.figure(figsize=(10, 8)) # 图形的宽为10高为8for images, labels in val_ds.take(1):for i in range(6):ax = plt.subplot(5, 2, i + 1) # 显示图片plt.imshow(images[i])# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0) # 使用模型预测验证码predictions = model.predict(img_array)plt.title(vec2text(np.argmax(predictions, axis=2)[0]),fontsize=15)plt.axis("off")

相关文章:
卷积神经网络(CNN)车牌识别
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据3.数据可视化4.标签数字化 二、构建一个tf.data.Dataset1.预处理函数2.加载数据3.配置数据 三、搭建网络模型四、设置动态学习率五、编译六、训练八、保存和…...
弹窗concrt140.dll丢失的解决方法,深度解析concrt140.dll丢失的原因
在计算机使用过程中,我们经常会遇到一些错误提示或者系统崩溃的情况。其中,concrt140.dll是一个常见的错误提示,这个错误通常会导致某些应用程序无法正常运行。为了解决这个问题,本文将介绍5种详细的解决方法,帮助您恢…...
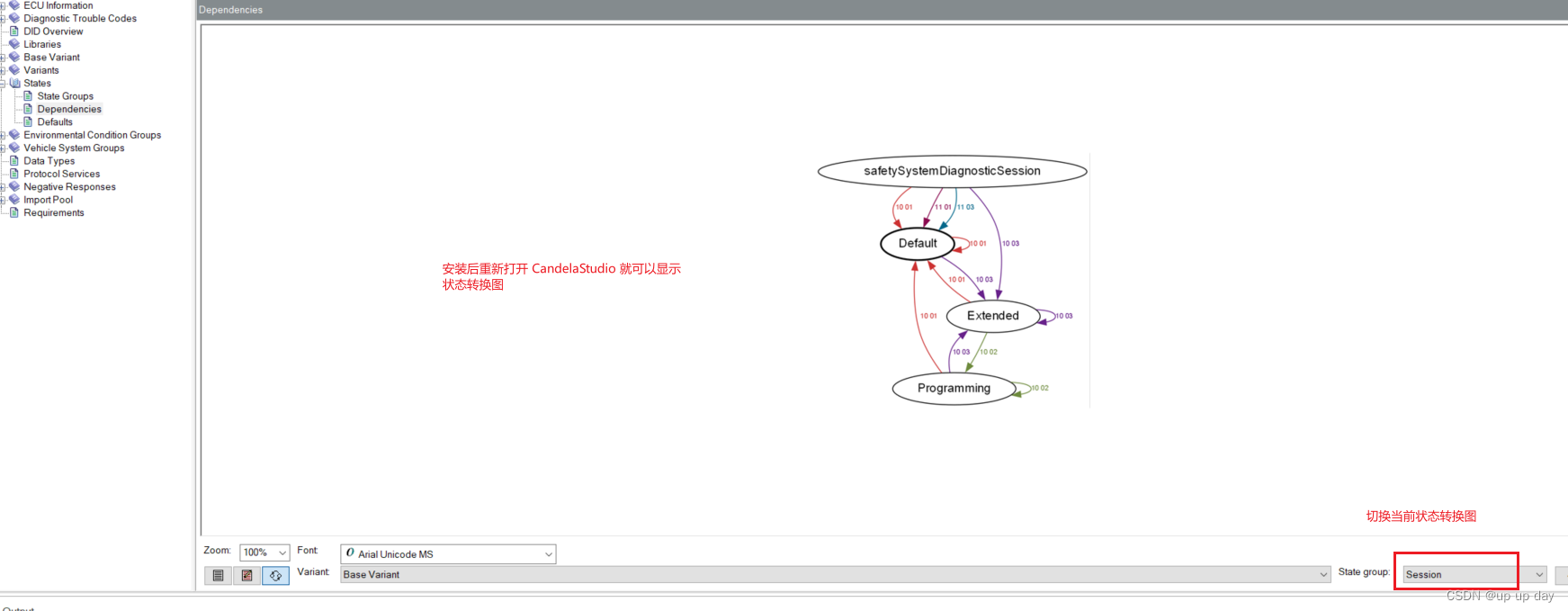
CANdelaStudio 使用教程4 编辑State
文章目录 简述1、State Groups2、Dependencies3、 Defaults State1、 会话状态2、 新增会话状态3、 编辑 服务对 State 的依赖关系 State Diagram 简述 1、State Groups 2、Dependencies 在这里,可以编辑现有服务在不同会话状态或安全访问状态的支持情况和状态转换…...
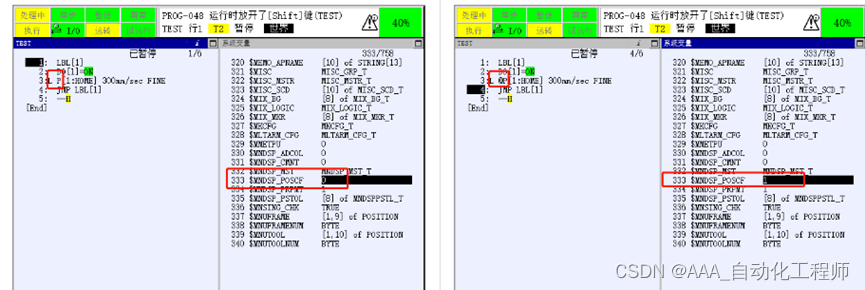
FANUC机器人到达某个点位时,为什么不显示@符号?
FANUC机器人到达某个点位时,为什么不显示@符号? 该功能由变量$MNDSP_POSCF = 0(不显示)/1(显示)/2(光标移动该行显示) 控制,该变量设置为不同的值,则启用对应的功能。 如下图所示,为该变量设置不同的值时的对比, 其他常用的系统变量可参考以下内容: 在R寄存器指定速度…...

JVM运行参数介绍 -Xms -Xmx -Xmn -Xss
文章目录 CharGPT问答Java运行参数“-Xmx2048m -Xms1024m -Xmn512m -Xss256k”如何调优jvm的运行参数 JVM相关介绍Java 虚拟机底层原理知识总结 CharGPT问答 Java运行参数“-Xmx2048m -Xms1024m -Xmn512m -Xss256k” 2023/11/26 20:30:27 这些参数是用于配置 Java 虚拟机&am…...

Hive删除符合条件的记录
Hive在使用中不支持update和delete操作,那么如果想删除部分条件的记录需要怎么操作?本文记录下解决方法。 思路:使用selectwhere选出想要保留的数据,使用insert overwrite向原表覆盖插入数据. insert overwrite table dbname.tab…...
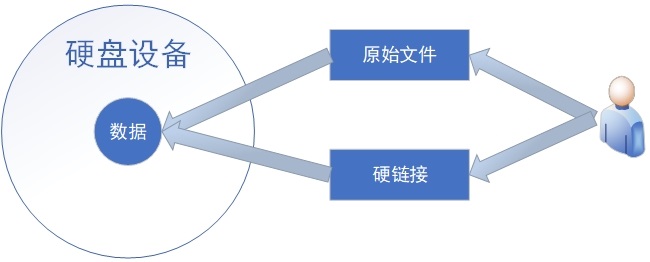
Linux加强篇006-存储结构与管理硬盘
目录 前言 1. 从“/”开始 2. 物理设备命名规则 3. 文件系统与数据资料 4. 挂载硬件设备 5. 添加硬盘设备 6. 添加交换分区 7. 磁盘容量配额 8. VDO虚拟数据优化 9. 软硬方式链接 前言 悟已往之不谏,知来者之可追。实迷途其未远,觉今是而昨非…...
GIT版本控制和常用命令使用介绍
GIT版本控制和常用命令使用介绍 1. 版本控制1.1 历史背景1.2 什么是版本控制1.3 常见版本控制工具1.4 版本控制的分类 2 Git介绍2.1 Git 工作流程2.2 基本概念2.3 文件的四种状态2.4 忽略文件2.5 Git命令2.5.1 查看本地git配置命令2.5.2 远程库信息查看命令2.5.3 分支交互命令2…...

微服务学习|初识Docker、使用Docker、自定义镜像、DockerCompose、Docker镜像仓库
初识Docker 项目部署的问题 大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题 依赖关系复杂,容易出现兼容性问题 开发、测试、生产环境有差异 Docker如何解决依赖的兼容问题的? 将应用的Libs (函数库)、Deps (依赖)配置与应用…...

蓝桥杯每日一题2023.11.24
题目描述 #include <stdio.h> #define N 100int connected(int* m, int p, int q) {return m[p]m[q]? 1 : 0; }void link(int* m, int p, int q) {int i;if(connected(m,p,q)) return;int pID m[p];int qID m[q];for(i0; i<N; i) ________________________________…...

内网穿透的应用-如何在本地安装Flask,以及将其web界面发布到公网上并进行远程访问
轻量级web开发框架:Flask本地部署及实现公网访问界面 文章目录 轻量级web开发框架:Flask本地部署及实现公网访问界面前言1. 安装部署Flask2. 安装Cpolar内网穿透3. 配置Flask的web界面公网访问地址4. 公网远程访问Flask的web界面 前言 本篇文章讲解如何…...

【重要】Splunk 的 Lookup Table能否被覆盖呢?
1: 背景: 用户自己的lookup table 可能需要被覆盖,因为用户自己会自动更新,但是如果不是用户自己更新,Deployer 上面发布的时候,用于没有用户的table ,那么默认是不能把客户的table overwite 的。如果用户要覆盖的话,如果客户有权限的话,客户可以自己更换lookup table…...
)
SELinux零知识学习三十、SELinux策略语言之角色和用户(1)
接前一篇文章:SELinux零知识学习二十九、SELinux策略语言之类型强制(14) 三、SELinux策略语言之类型强制 SELinux提供了一种依赖于类型强制(类型增强,TE)的基于角色的访问控制(Role-Based Access Control),角色用于组域类型和限制域类型与用户之间的关系,SELinux中的…...
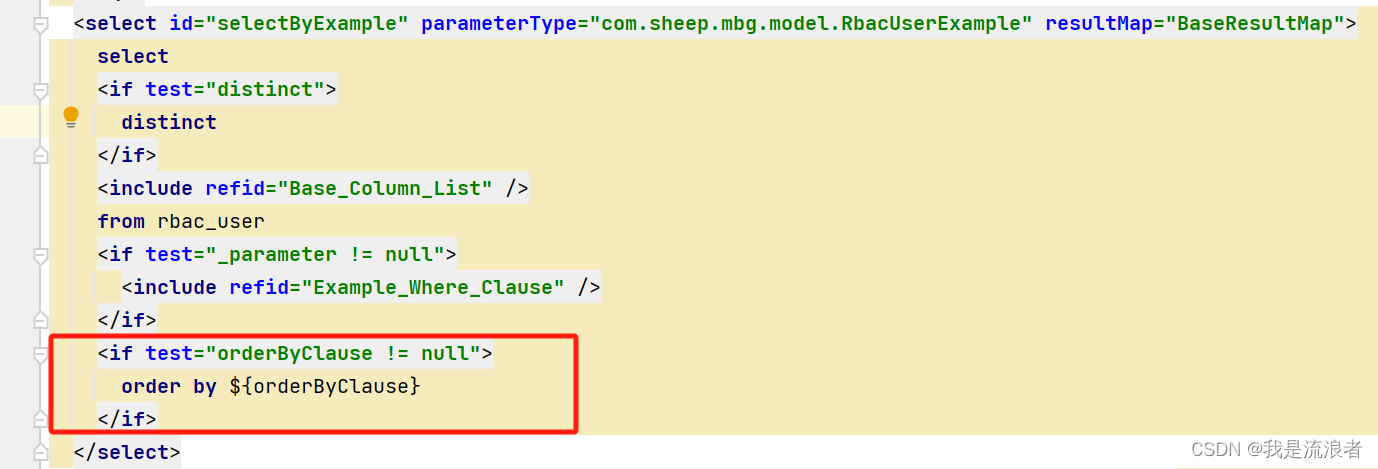
MyBatis Generator使用总结
MyBatis Generator使用总结 介绍具体使用数据准备插件引入配置条件构建讲解demo地址 介绍 MyBatis Generator (MBG) 是 MyBatis 的代码生成器。它能够根据数据库表,自动生成 java 实体类、dao 层接口(mapper 接口)及m…...

编程语言发展史:Ruby语言的发展和应用
介绍 Ruby是一种高级编程语言,最初由日本的松本行弘开发。它在20世纪90年代初首次发布,并在2000年代初开始变得流行。 Ruby是一种动态、面向对象的语言,具有简单、易于学习和使用的语法,因此被广泛应用于Web开发、数据分析、游戏…...
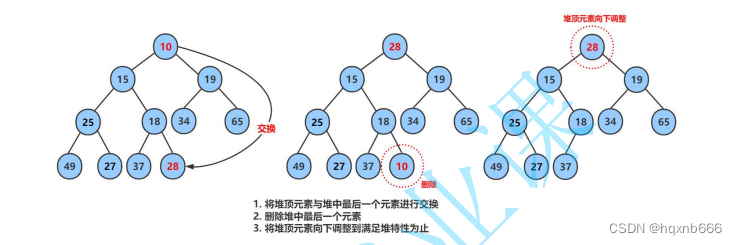
数据结构-树-二叉树-堆的实现
1.树概念及结构 树是一种 非线性 的数据结构,它是由 n ( n>0 )个有限结点组成一个具有层次关系的集合。 把它叫做树是因 为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的 。 有一个特殊的结点ÿ…...
两巨头Facebook 和 GitHub 联手推出 Atom-IDE
9月13日,GitHub 宣布与 Facebook 合作推出了 Atom-IDE —— 它包括一系列将类 IDE 功能带到 Atom 的可选工具包。初次发布的版本包括更智能、感知上下文的自动完成;导航功能,如大纲视图和定义跳转(outline view and goto-definition)…...

python生成邀请码,手机验证码
python生成邀请码,手机验证码 使用python生成邀请码,手机验证码,大小写字母,数字等,示例代码如下。 1、获取随机码 import randomdef get_random_code(is_digit=False, num=6):获取随机码:param is_digit: 是否为全数字:param num: 长度:return:if is_digit:sequence =…...

分布式链路追踪入门篇-基础原理与快速应用
为什么需要链路追踪? 我们程序员在日常工作中,最常做事情之一就是修bug了。如果程序只是运行在单机上,我们最常用的方式就是在程序上打日志,然后程序运行的过程中将日志输出到文件上,然后我们根据日志去推断程序是哪一…...
新的centos7.9安装jenkins—(一)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 因为是用java8,所以还是要最后java8版本的jenkins,版本号是2.346.3,后…...

终极指南:如何让Mac外接鼠标获得触控板般丝滑滚动体验
终极指南:如何让Mac外接鼠标获得触控板般丝滑滚动体验 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently f…...

DVWA1.9文件上传High级绕过实战:3种隐藏木马技巧与防御思路
DVWA1.9文件上传High级绕过实战:3种隐藏木马技巧与防御思路 在Web安全领域,文件上传漏洞始终是攻击者最青睐的攻击向量之一。DVWA(Damn Vulnerable Web Application)作为经典的漏洞演练平台,其High级别的文件上传防护机…...

Source Han Serif CN:免费开源宋体的7种字重完整使用教程
Source Han Serif CN:免费开源宋体的7种字重完整使用教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找高质量中文字体而烦恼吗?Source Ha…...

Qwen3.5-2B效果展示:上传PPT截图自动生成演讲备注与时间分配建议
Qwen3.5-2B效果展示:上传PPT截图自动生成演讲备注与时间分配建议 1. 模型简介 Qwen3.5-2B是一款轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这款模型主打低功耗和低门槛部署,特别适配端侧和边缘设…...

跨样本CellChat分析:解锁多组别细胞通讯的奥秘
1. 跨样本CellChat分析的核心价值 细胞通讯研究正在从单一样本分析向多组别比较转变,这种转变就像从观察单个社交网络发展到比较不同社交平台的互动模式。CellChat作为目前最强大的细胞通讯分析工具之一,其跨样本比较功能能够揭示不同生理或病理状态下细…...

Cursor VIP:创新共享模式让AI编程助手触手可及
Cursor VIP:创新共享模式让AI编程助手触手可及 【免费下载链接】cursor-vip cursor IDE enjoy VIP 项目地址: https://gitcode.com/gh_mirrors/cu/cursor-vip 你是否曾因AI编程工具的高昂费用而犹豫?或者因为所在地区无法购买官方服务而错失提升编…...
)
ZYNQ实战:AXI4-Stream FIFO跨时钟域传输的5个关键配置(附ADDA实验代码)
ZYNQ实战:AXI4-Stream FIFO跨时钟域传输的5个关键配置(附ADDA实验代码) 在FPGA开发中,跨时钟域数据传输一直是工程师面临的棘手问题之一。特别是当系统需要处理高速数据流时,如何确保数据在不同时钟域间安全、高效地传…...

二极管的温度特性
二极管的温度特性 例题 温度升高时,二极管的正向导通压降是 © A. 变大 B. 不变 C. 变小 正确答案:C 二极管的正向导通压降 (VDV_DVD) 概念:当二极管正向偏置(P极接高电位,N极接低电位)时&#x…...

我不是在用 AI 助手,我在把自己的能力沉淀成组织资产搜
1. 什么是 Apache SeaTunnel? Apache SeaTunnel 是一个非常易于使用、高性能、支持实时流式和离线批处理的海量数据集成平台。它的目标是解决常见的数据集成问题,如数据源多样性、同步场景复杂性以及资源消耗高的问题。 核心特性 丰富的数据源支持&#…...

Pixeval技术深度解析:构建现代化Pixiv客户端的技术实现与架构设计
Pixeval技术深度解析:构建现代化Pixiv客户端的技术实现与架构设计 【免费下载链接】Pixeval Wow. Yet another Pixiv client! 项目地址: https://gitcode.com/gh_mirrors/pi/Pixeval Pixeval是一款基于Windows App SDK和WinUI 3构建的高性能Pixiv第三方客户端…...