第二十章 解读PASCAL VOC2012与MS COCO数据集(工具)
PASCAL VOC2012数据集
Pascal VOC2012官网地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
官方发表关于介绍数据集的文章 《The PASCALVisual Object Classes Challenge: A Retrospective》:http://host.robots.ox.ac.uk/pascal/VOC/pubs/everingham15.pdf

1 简介
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等。
- 图像分类与目标检测任务

- 分割任务,注意,图像分割一般包括语义分割、实例分割和全景分割,实例分割是要把每个单独的目标用一种颜色表示(下图中间的图像),而语义分割只是把同一类别的所有目标用同一颜色表示(下图右侧的图片)。

- 行为识别任务

- 人体布局检测任务

2 Pascal VOC数据集目标类别
在Pascal VOC数据集中主要包含20个目标类别,下图展示了所有类别的名称以及所属超类。

3 数据集下载与目录结构
下载地址: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
打开链接后如下图所示,只用下载training/validation data (2GB tar file)文件即可。

下载后将文件进行解压,解压后的文件目录结构如下所示:
VOCdevkit└── VOC2012├── Annotations 所有的图像标注信息(XML文件)├── ImageSets │ ├── Action 人的行为动作图像信息│ ├── Layout 人的各个部位图像信息│ ││ ├── Main 目标检测分类图像信息│ │ ├── train.txt 训练集(5717)│ │ ├── val.txt 验证集(5823)│ │ └── trainval.txt 训练集+验证集(11540)│ ││ └── Segmentation 目标分割图像信息│ ├── train.txt 训练集(1464)│ ├── val.txt 验证集(1449)│ └── trainval.txt 训练集+验证集(2913)│ ├── JPEGImages 所有图像文件├── SegmentationClass 语义分割png图(基于类别)└── SegmentationObject 实例分割png图(基于目标)
注意,train.txt、val.txt和trainval.txt文件里记录的是对应标注文件的索引,每一行对应一个索引信息。如下图所示:

4 目标检测任务
接下来简单介绍下如何使用该数据集中目标检测的数据。
- 首先在Main文件中,读取对应的txt文件(注意,在
Main文件夹里除了train.txt、val.txt和trainval.txt文件外,还有针对每个类别的文件,例如bus_train.txt、bus_val.txt和bus_trainval.txt)。比如使用train.txt中的数据进行训练,那么读取该txt文件,解析每一行。上面说了每一行对应一个标签文件的索引。
├── Main 目标检测分类图像信息│ ├── train.txt 训练集(5717)│ ├── val.txt 验证集(5823)│ └── trainval.txt 训练集+验证集(11540)
- 接着通过索引在
Annotations文件夹下找到对应的标注文件(.xml)。比如索引为2007_000323,那么在Annotations文件夹中能够找到2007_000323.xml文件。如下图所示,在标注文件中包含了所有需要的信息,比如filename,通过在字段能够在JPEGImages文件夹中能够找到对应的图片。size记录了对应图像的宽、高以及channel信息。每一个object代表一个目标,其中的name记录了该目标的名称,pose表示目标的姿势(朝向),truncated表示目标是否被截断(目标是否完整),difficult表示该目标的检测难易程度(0代表简单,1表示困难),bndbox记录了该目标的边界框信息。

- 接着通过在标注文件中的
filename字段在JPEGImages文件夹中找到对应的图片。比如在2007_000323.xml文件中的filename字段为2007_000323.jpg,那么在JPEGImages文件夹中能够找到2007_000323.jpg文件。

5 语义分割任务
接下来简单介绍下如何使用该数据集中语义分割的数据。
- 首先在Segmentarion文件中,读取对应的txt文件。比如使用
train.txt中的数据进行训练,那么读取该txt文件,解析每一行,每一行对应一个图像的索引。
└── Segmentation 目标分割图像信息├── train.txt 训练集(1464)├── val.txt 验证集(1449)└── trainval.txt 训练集+验证集(2913)
- 根据索引在
JPEGImages文件夹中找到对应的图片。还是以2007_000323为例,可以找到2007_000323.jpg文件。
- 根据索引在
SegmentationClass文件夹中找到相应的标注图像(.png)。还是以2007_000323为例,可以找到2007_000323.png文件。

注意,在语义分割中对应的标注图像(.png)用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处用的像素值为255(训练时一般会忽略像素值为255的区域),目标区域内根据目标的类别索引信息进行填充,例如人对应的目标索引是15,所以目标区域的像素值用15填充。

6 实例分割任务
- 同样首先在Segmentarion文件中,读取对应的txt文件。比如使用
train.txt中的数据进行训练,那么读取该txt文件,解析每一行,每一行对应一个图像的索引。
└── Segmentation 目标分割图像信息├── train.txt 训练集(1464)├── val.txt 验证集(1449)└── trainval.txt 训练集+验证集(2913)
- 根据索引在
JPEGImages文件夹中找到对应的图片。这里以2007_000032为例,可以找到2007_000032.jpg文件,如下图所示。

- 再根据索引在
SegmentationObject文件夹中找到相应的标注图像(.png)。还是以2007_000032为例,可以找到2007_000032.png文件。

注意,在实例分割中对应的标注图像(.png)用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处或需要忽略的区域用的像素值为255(训练时一般会忽略像素值为255的区域)。然后在Annotations文件夹中找到对应的xml文件,解析xml文件后会得到每个目标的信息,而对应的标注文件(.png)的每个目标处的像素值是按照xml文件中目标顺序排列的。如下图所示,xml文件中每个目标的序号是与标注文件(.png)中目标像素值是对应的。
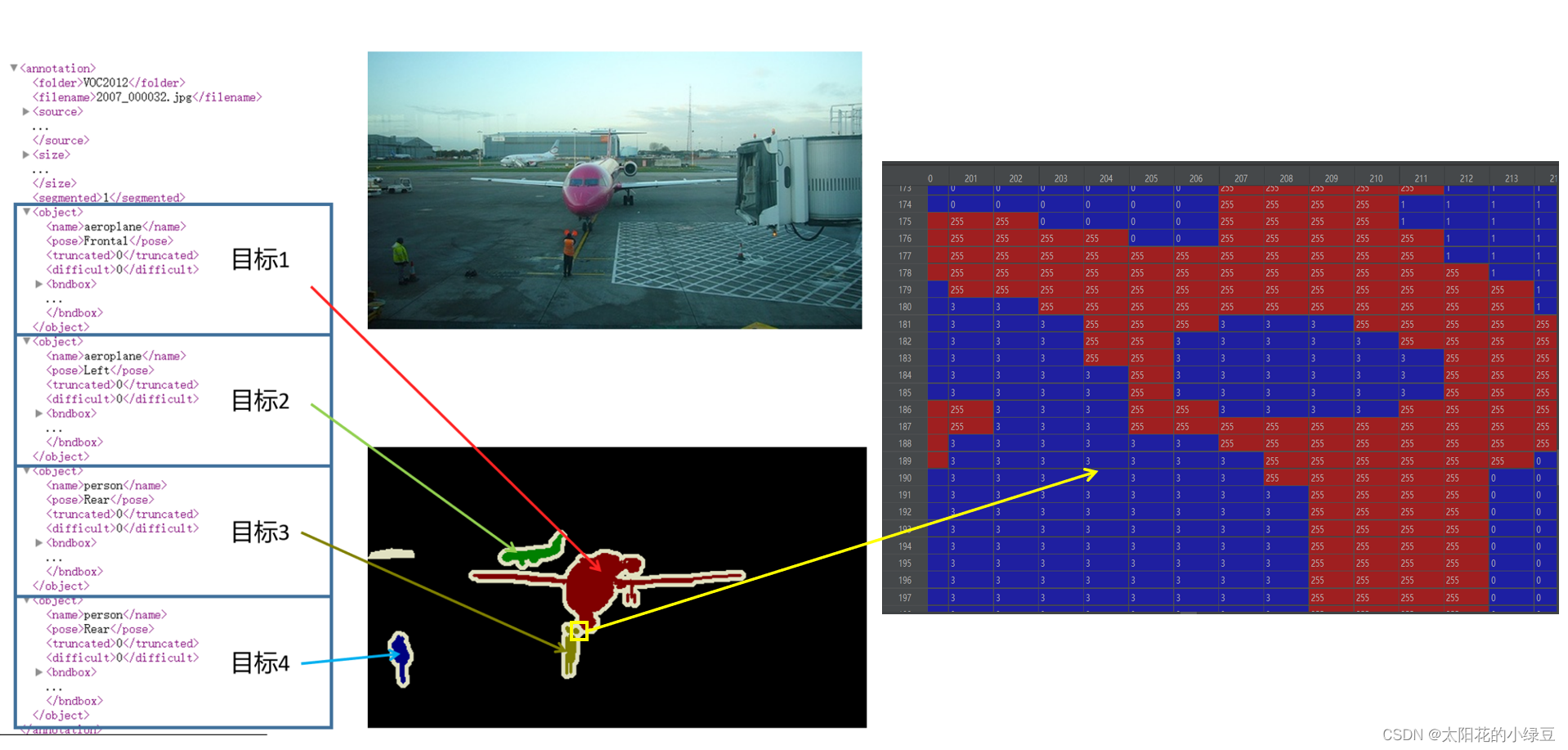
7 类别索引与名称对应关系
下面给出在Pascal VOC数据集中各目标类别名称与类别索引对应关系:
{"background": 0,"aeroplane": 1,"bicycle": 2,"bird": 3,"boat": 4,"bottle": 5,"bus": 6,"car": 7,"cat": 8,"chair": 9,"cow": 10,"diningtable": 11,"dog": 12,"horse": 13,"motorbike": 14,"person": 15,"pottedplant": 16,"sheep": 17,"sofa": 18,"train": 19,"tvmonitor": 20
}
MS COCO数据集
1. MS COCO数据集简介
- 官网地址
https://cocodataset.org/ - 简介
MS COCO是一个非常大型且常用的数据集,其中包括了目标检测,分割,图像描述等。其主要特性如下:Object segmentation: 目标级分割Recognition in context: 图像情景识别Superpixel stuff segmentation: 超像素分割330K images (>200K labeled): 超过33万张图像,标注过的图像超过20万张1.5 million object instances: 150万个对象实例80 object categories: 80个目标类别91 stuff categories: 91个材料类别5 captions per image: 每张图像有5段情景描述250,000 people with keypoints: 对25万个人进行了关键点标注

- 注意事项
- 这里需要注意的一个点是“什么是stuff类别”,在官方的介绍论文中是这么定义的:
where “stuff” categories include materials and objects with no clear boundaries (sky, street, grass)
简单的理解就是stuff中包含没有明确边界的材料和对象。 - object的80类与stuff中的91类的区别在哪?在官方的介绍论文中有如下说明:
Note that we have limited the 2014 release to a subset of 80 categories. We did not collect segmentations for the following 11 categories: hat, shoe, eyeglasses (too many instances), mirror, window, door, street sign (ambiguous and difficult to label), plate, desk (due to confusion with bowl and dining table, respectively) and blender, hair brush (too few instances).
简单的理解就是object80类是stuff91类的子集。对于我们自己使用,如果仅仅是做目标检测,基本只用object80类即可。
- 这里需要注意的一个点是“什么是stuff类别”,在官方的介绍论文中是这么定义的:
- 简单与PASCAL VOC数据集对比
下图是官方介绍论文中统计的对比图,通过对比很明显,不仅类别更多,每个类别标注的目标也更多。

如果想进一步了解该数据集,可以去阅读下官方的介绍论文:
Microsoft COCO: Common Objects in Context https://arxiv.org/pdf/1405.0312.pdf

2. MS COCO数据集下载
这里以下载coco2017数据集为例,主要下载三个文件:
2017 Train images [118K/18GB]:训练过程中使用到的所有图像文件2017 Val images [5K/1GB]:验证过程中使用到的所有图像文件2017 Train/Val annotations [241MB]:对应训练集和验证集的标注json文件
下载后都解压到coco2017目录下,可以得到如下目录结构:
├── coco2017: 数据集根目录├── train2017: 所有训练图像文件夹(118287张)├── val2017: 所有验证图像文件夹(5000张)└── annotations: 对应标注文件夹├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件├── captions_train2017.json: 对应图像描述的训练集标注文件├── captions_val2017.json: 对应图像描述的验证集标注文件├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹3. MS COCO标注文件格式
官网有给出一个关于标注文件的格式说明,可以通过以下链接查看:
https://cocodataset.org/#format-data
3.1 使用Python的json库查看
对着官方给的说明,我们可以自己用Python的json库自己读取看下,下面以读取instances_val2017.json为例:
import jsonjson_path = "/data/coco2017/annotations/instances_val2017.json"
json_labels = json.load(open(json_path, "r"))
print(json_labels["info"])
单步调试可以看到读入进来后是个字典的形式,包括了info、licenses、images、annotations以及categories信息:

其中:
images是一个列表(元素个数对应图像的张数),列表中每个元素都是一个dict,对应一张图片的相关信息。包括对应图像名称、图像宽度、高度等信息。

annotations是一个列表(元素个数对应数据集中所有标注的目标个数,注意不是图像的张数),列表中每个元素都是一个dict对应一个目标的标注信息。包括目标的分割信息(polygons多边形)、目标边界框信息[x,y,width,height](左上角x,y坐标,以及宽高)、目标面积、对应图像id以及类别id等。iscrowd参数只有0或1两种情况,一般0代表单个对象,1代表对象集合。

categories是一个列表(元素个数对应检测目标的类别数)列表中每个元素都是一个dict对应一个类别的目标信息。包括类别id、类别名称和所属超类。

3.2 使用官方cocoAPI查看
官方有给出一个读取MS COCO数据集信息的API(当然,该API还有其他重要功能),下面是对应github的连接,里面有关于该API的使用demo:
https://github.com/cocodataset/cocoapi
- Linux系统安装pycocotools:
pip install pycocotools
- Windows系统安装pycocotools:
pip install pycocotools-windows
读取每张图片的bbox信息
下面是使用pycocotools读取图像以及对应bbox信息的简单示例:
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as pltjson_path = "/data/coco2017/annotations/instances_val2017.json"
img_path = "/data/coco2017/val2017"# load coco data
coco = COCO(annotation_file=json_path)# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])# 遍历前三张图像
for img_id in ids[:3]:# 获取对应图像id的所有annotations idx信息ann_ids = coco.getAnnIds(imgIds=img_id)# 根据annotations idx信息获取所有标注信息targets = coco.loadAnns(ann_ids)# get image file namepath = coco.loadImgs(img_id)[0]['file_name']# read imageimg = Image.open(os.path.join(img_path, path)).convert('RGB')draw = ImageDraw.Draw(img)# draw box to imagefor target in targets:x, y, w, h = target["bbox"]x1, y1, x2, y2 = x, y, int(x + w), int(y + h)draw.rectangle((x1, y1, x2, y2))draw.text((x1, y1), coco_classes[target["category_id"]])# show imageplt.imshow(img)plt.show()
通过pycocotools读取的图像以及对应的targets信息,配合matplotlib库绘制标注图像如下:

读取每张图像的segmentation信息
下面是使用pycocotools读取图像segmentation信息的简单示例:
import os
import randomimport numpy as np
from pycocotools.coco import COCO
from pycocotools import mask as coco_mask
from PIL import Image, ImageDraw
import matplotlib.pyplot as pltrandom.seed(0)json_path = "/data/coco2017/annotations/instances_val2017.json"
img_path = "/data/coco2017/val2017"# random pallette
pallette = [0, 0, 0] + [random.randint(0, 255) for _ in range(255*3)]# load coco data
coco = COCO(annotation_file=json_path)# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])# 遍历前三张图像
for img_id in ids[:3]:# 获取对应图像id的所有annotations idx信息ann_ids = coco.getAnnIds(imgIds=img_id)# 根据annotations idx信息获取所有标注信息targets = coco.loadAnns(ann_ids)# get image file namepath = coco.loadImgs(img_id)[0]['file_name']# read imageimg = Image.open(os.path.join(img_path, path)).convert('RGB')img_w, img_h = img.sizemasks = []cats = []for target in targets:cats.append(target["category_id"]) # get object class idpolygons = target["segmentation"] # get object polygonsrles = coco_mask.frPyObjects(polygons, img_h, img_w)mask = coco_mask.decode(rles)if len(mask.shape) < 3:mask = mask[..., None]mask = mask.any(axis=2)masks.append(mask)cats = np.array(cats, dtype=np.int32)if masks:masks = np.stack(masks, axis=0)else:masks = np.zeros((0, height, width), dtype=np.uint8)# merge all instance masks into a single segmentation map# with its corresponding categoriestarget = (masks * cats[:, None, None]).max(axis=0)# discard overlapping instancestarget[masks.sum(0) > 1] = 255target = Image.fromarray(target.astype(np.uint8))target.putpalette(pallette)plt.imshow(target)plt.show()
通过pycocotools读取的图像segmentation信息,配合matplotlib库绘制标注图像如下:

读取人体关键点信息
在MS COCO任务中,对每个人体都标注了17的关键点,这17个关键点的部位分别如下:
["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"]
在COCO给出的标注文件中,针对每个人体的标注格式如下所示。其中每3个值为一个关键点的相关信息,因为有17个关键点所以总共有51个数值。按照3个一组进行划分,前2个值代表关键点的x,y坐标,第3个值代表该关键点的可见度,它只会取 { 0 , 1 , 2 } {0, 1, 2} {0,1,2}三个值。0表示该点一般是在图像外无法标注,1表示虽然该点不可见但大概能猜测出位置(比如人侧着站时虽然有一只耳朵被挡住了,但大概也能猜出位置),2表示该点可见。如果第3个值为0,那么对应的x,y也都等于0:
[427, 170, 1, 429, 169, 2, 0, 0, 0, 434, 168, 2, 0, 0, 0, 441, 177, 2, 446, 177, 2, 437, 200, 2, 430, 206, 2, 430, 220, 2, 420, 215, 2, 445, 226, 2, 452, 223, 2, 447, 260, 2, 454, 257, 2, 455, 290, 2, 459, 286, 2]
下面是使用pycocotools读取图像keypoints信息的简单示例:
import numpy as np
from pycocotools.coco import COCOjson_path = "/data/coco2017/annotations/person_keypoints_val2017.json"
coco = COCO(json_path)
img_ids = list(sorted(coco.imgs.keys()))# 遍历前5张图片中的人体关键点信息(注意,并不是每张图片里都有人体信息)
for img_id in img_ids[:5]:idx = 0img_info = coco.loadImgs(img_id)[0]ann_ids = coco.getAnnIds(imgIds=img_id)anns = coco.loadAnns(ann_ids)for ann in anns:xmin, ymin, w, h = ann['bbox']# 打印人体bbox信息print(f"[image id: {img_id}] person {idx} bbox: [{xmin:.2f}, {ymin:.2f}, {xmin + w:.2f}, {ymin + h:.2f}]")keypoints_info = np.array(ann["keypoints"]).reshape([-1, 3])visible = keypoints_info[:, 2]keypoints = keypoints_info[:, :2]# 打印关键点信息以及可见度信息print(f"[image id: {img_id}] person {idx} keypoints: {keypoints.tolist()}")print(f"[image id: {img_id}] person {idx} keypoints visible: {visible.tolist()}")idx += 1
终端输出信息如下,通过以下信息可知,验证集中前5张图片里只有一张图片包含人体关键点信息:
[image id: 139] person 0 bbox: [412.80, 157.61, 465.85, 295.62]
[image id: 139] person 0 keypoints: [[427, 170], [429, 169], [0, 0], [434, 168], [0, 0], [441, 177], [446, 177], [437, 200], [430, 206], [430, 220], [420, 215], [445, 226], [452, 223], [447, 260], [454, 257], [455, 290], [459, 286]]
[image id: 139] person 0 keypoints visible: [1, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
[image id: 139] person 1 bbox: [384.43, 172.21, 399.55, 207.95]
[image id: 139] person 1 keypoints: [[0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0]]
[image id: 139] person 1 keypoints visible: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
相关文章:
第二十章 解读PASCAL VOC2012与MS COCO数据集(工具)
PASCAL VOC2012数据集 Pascal VOC2012官网地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/ 官方发表关于介绍数据集的文章 《The PASCALVisual Object Classes Challenge: A Retrospective》:http://host.robots.ox.ac.uk/pascal/VOC/pubs/everi…...

FreeRTOS列表和列表项
目录 列表和列表项 关于列表的一些操作 初始化列表 初始化列表项 列表插入列表项 列表项末尾插入 重点 pxIndex指向的是什么 xItemValue存的是什么 vListInsertEnd()的插入位置 List的头尾在哪里? 通用链表的三种实现方式 方法一 方法二 方法三 总结 Fre…...

【go语言实现一个webSocket的一个demo】
go语言实现一个webSocket的一个demo 前端代码 <html lang"zh-CN"><head></head><body> <script type"text/javascript">// header(Access-Control-Allow-Origin:*);var sock null;var wsuri "ws://127.0.0.1:9999&…...

es6字符串模板之标签化模板
es6字符串模板 我们经常搞前端开发工作的都会用到。它可以保留字符串换行格式,还能接受变量。这个给前端的字符串拼接带来了非常大的方便。但是还有一种用法可能是我们平时还是没有怎么用到的。 styled-components 在项目中熟悉使用react的童鞋可能会用过styled-…...

opencv入门1.1:从视频或摄像头读取图像
cv::VideoCapture是 OpenCV 中用于从视频文件或摄像头捕获图像帧的类。它提供了各种方法和函数,用于读取和处理视频数据。 以下是对 cv::VideoCapture类的详细解释和说明: 1. 打开视频源 为了使用 cv::VideoCapture,我们首先需要打开一个视…...
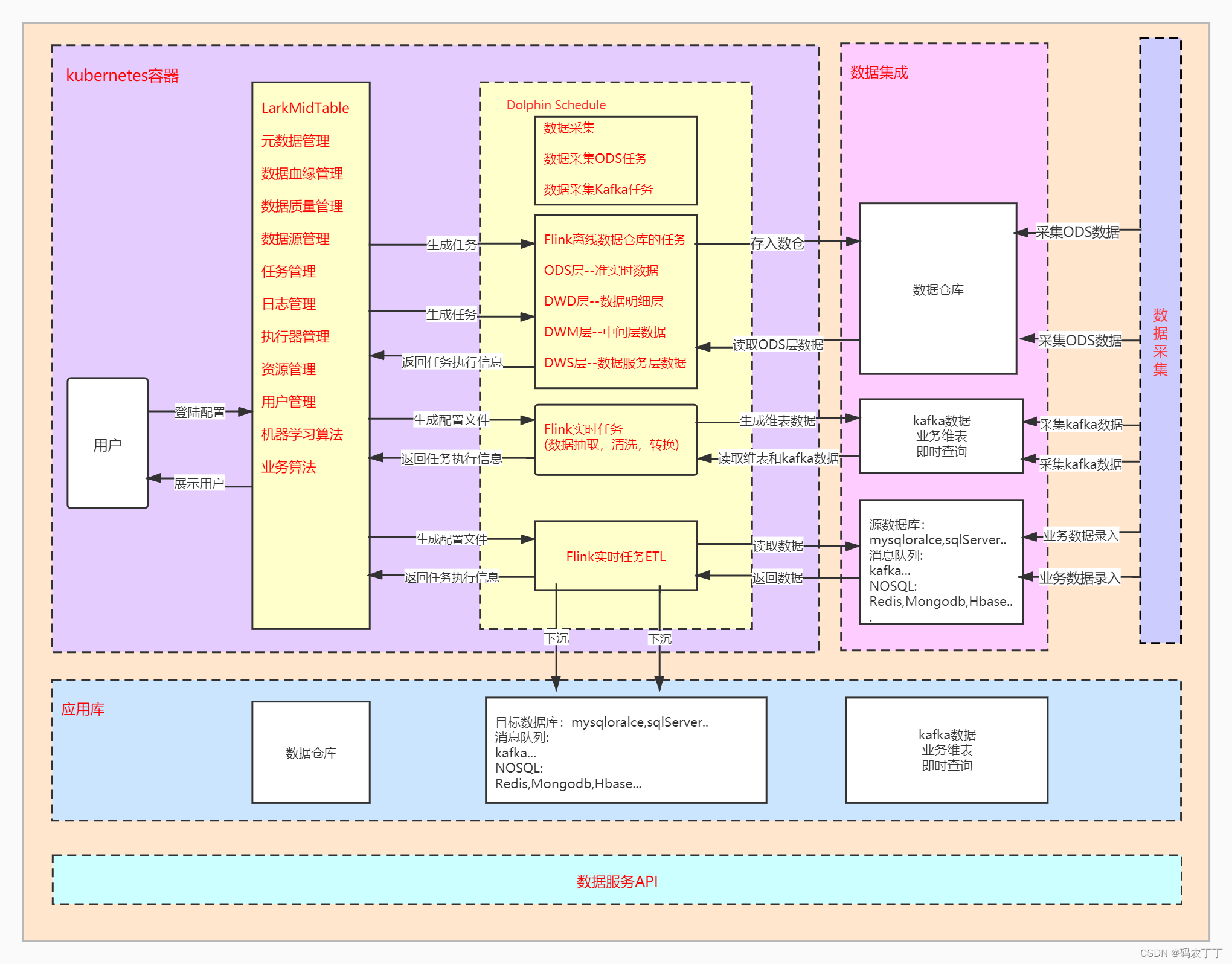
【数据中台】开源项目(1)-LarkMidTable
LarkMidTable 是一站式开源的数据中台,实现中台的 基础建设,数据治理,数据开发,监控告警,数据服务,数据的可视化,实现高效赋能数据前台并提供数据服务的产品。 系统演示地址 : www.l…...
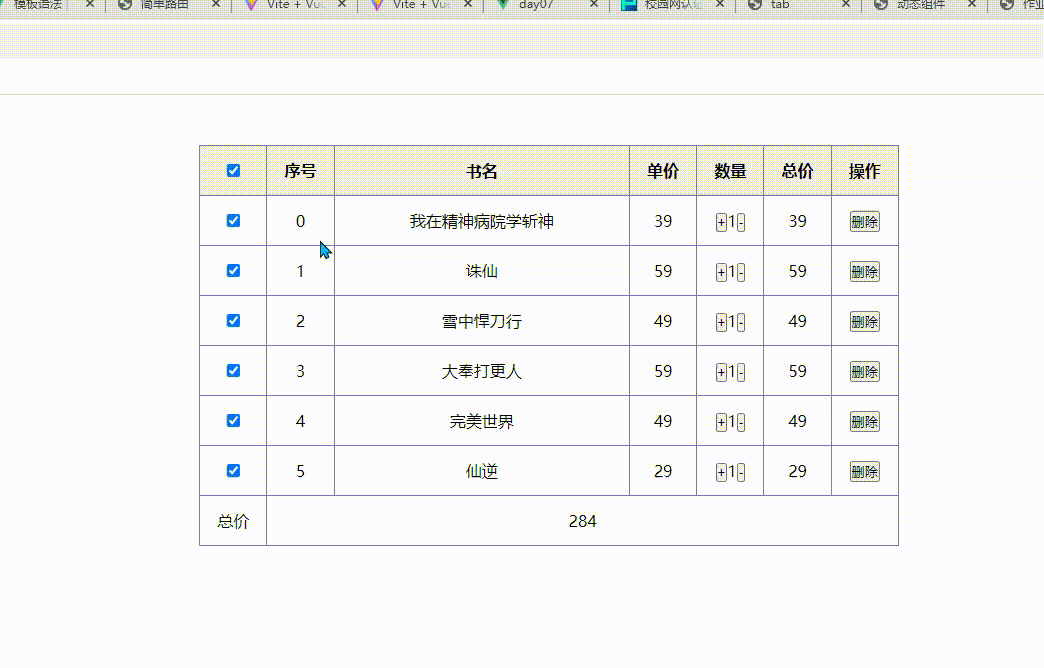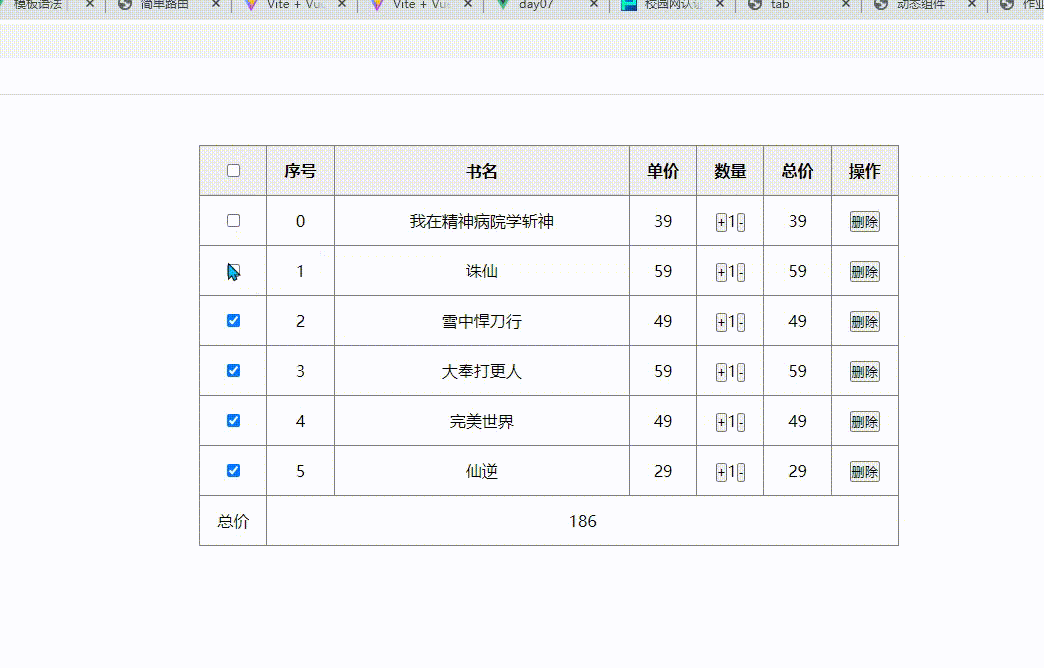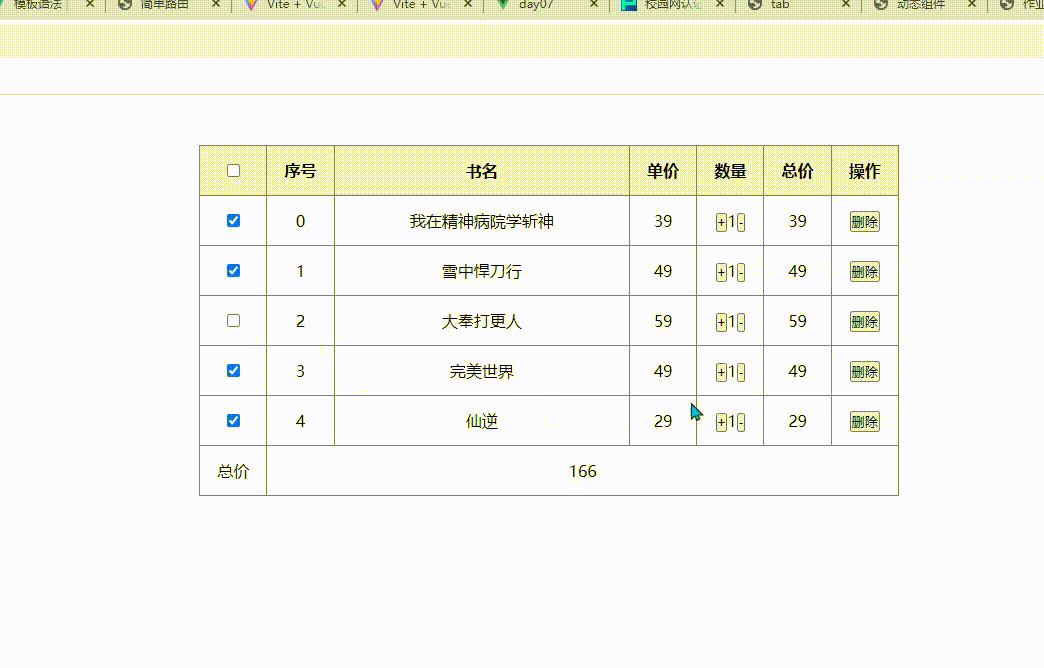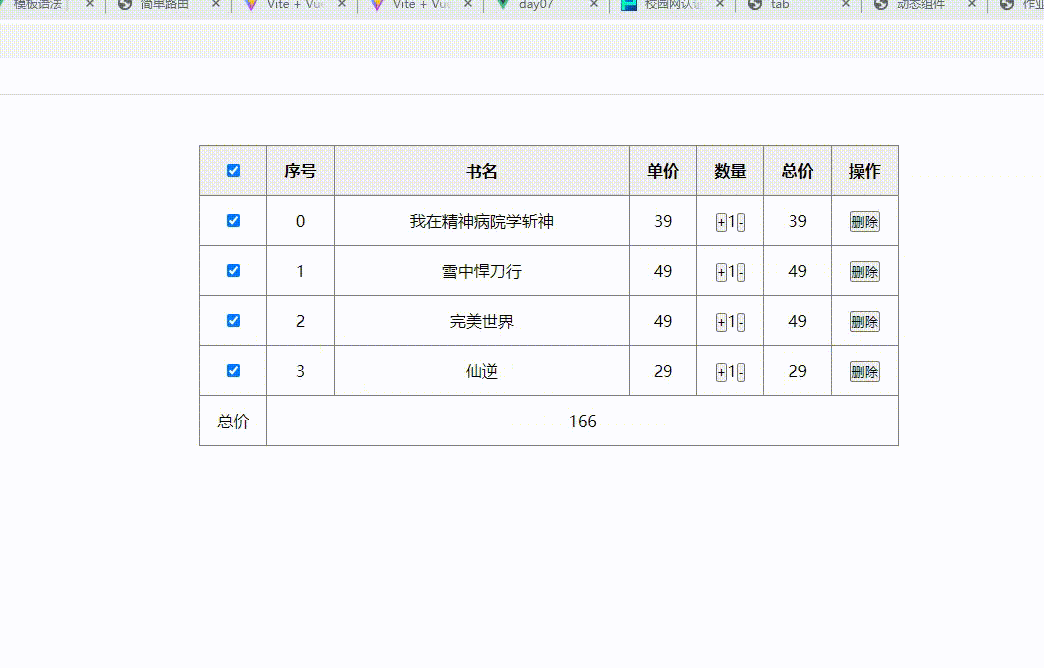
VUE简易购物车程序
目录 效果预览图 完整代码 效果预览图 完整代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>…...

如何清除redis缓存?
首先进入redis安装目录 当前目录下执行CMD命令(shift 右键 -> 选择 ‘在此处打开Powershell窗口’ ) 执行 redis-cli.exe -h 127.0.0.1 -p 6379flushall...
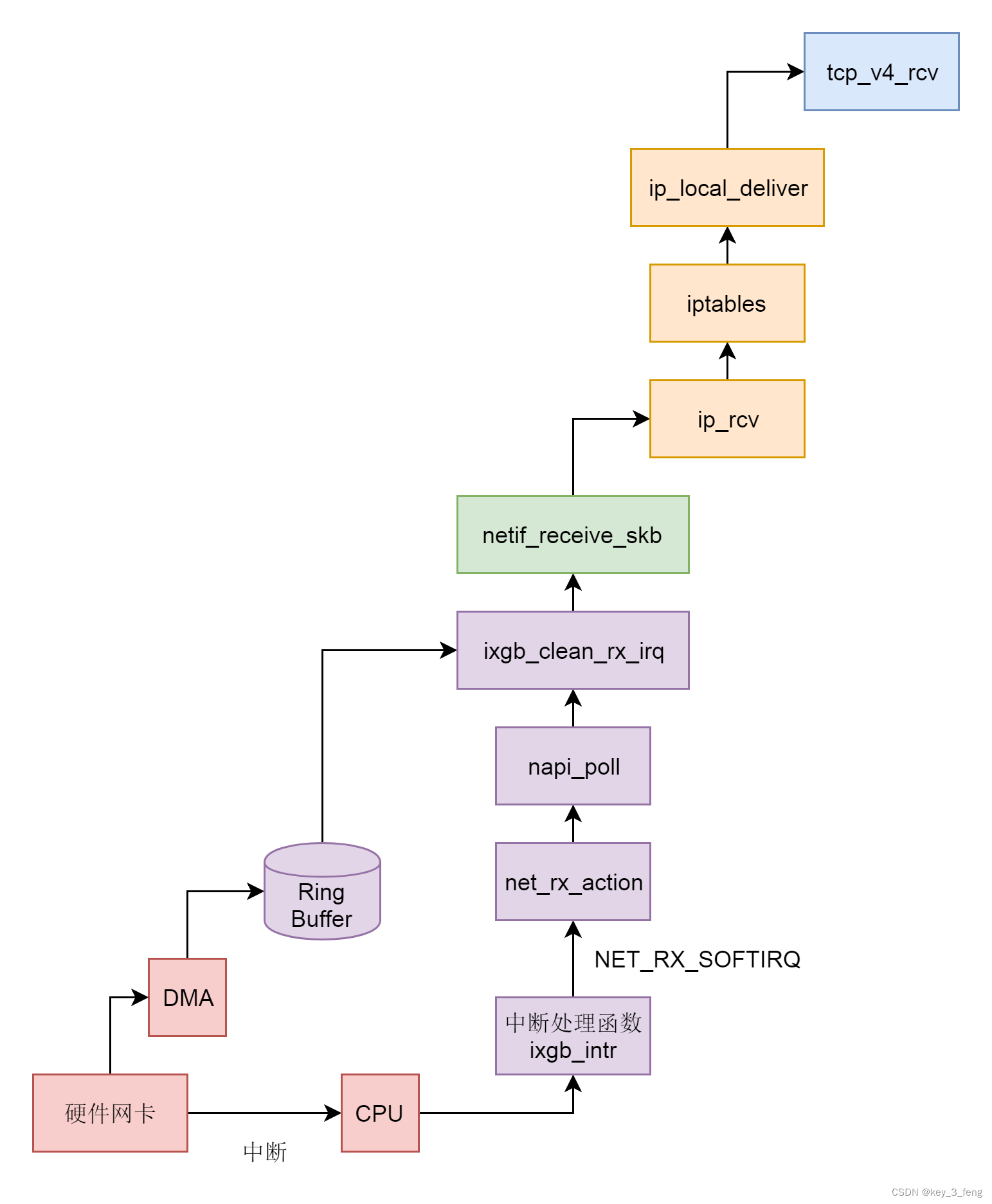
接收网络包的过程——从硬件网卡解析到IP层
当一些网络包到来触发了中断,内核处理完这些网络包之后,我们可以先进入主动轮询 poll 网卡的方式,主动去接收到来的网络包。如果一直有,就一直处理,等处理告一段落,就返回干其他的事情。当再有下一批网络包…...

正则化与正则剪枝
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 引言正则化为什么会过拟合拉格朗日与正则化梯度衰减与正则化 应用解决过拟合网络剪枝 …...

Element-Plus 图标自动导入
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...

关于DCDC电源中的PWM与PFM
在开关电源DCDC中,我们经常会听到PWM模式与PFM模式。 关于,这两种模式,小编在之前的文章中,做过简单的描述。今天就来针对性的就这两种模式展开讲讲。 PWM:脉冲宽度调制,即频率不变,不断调整脉…...

S25FL系列FLASH读写的FPGA实现
文章目录 实现思路具体实现子模块实现top模块 测试Something 实现思路 建议读者先对 S25FL-S 系列 FLASH 进行了解,我之前的博文中有详细介绍。 笔者的芯片具体型号为 S25FL256SAGNFI00,存储容量 256Mb,增强高性能 EHPLC,4KB 与 6…...

一次【自定义编辑器功能脚本】【调用时内存爆仓】事故排查
一 、事故描述 我有一个需求:在工程文件中找得到所有的图片(Texture 2D),然后把WebGL发布打包时的图片压缩规则进行修改。 项目中有图片2千多张,其中2k分辨率的图片上百张,当我右键进行批量处理的时候&…...

【STM32单片机】简易计算器设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用STM32F103C8T6单片机控制器,使用动态数码管模块、矩阵按键、蜂鸣器模块等。 主要功能: 系统运行后,数码管默认显示0,输入对应的操作数进行四则运…...
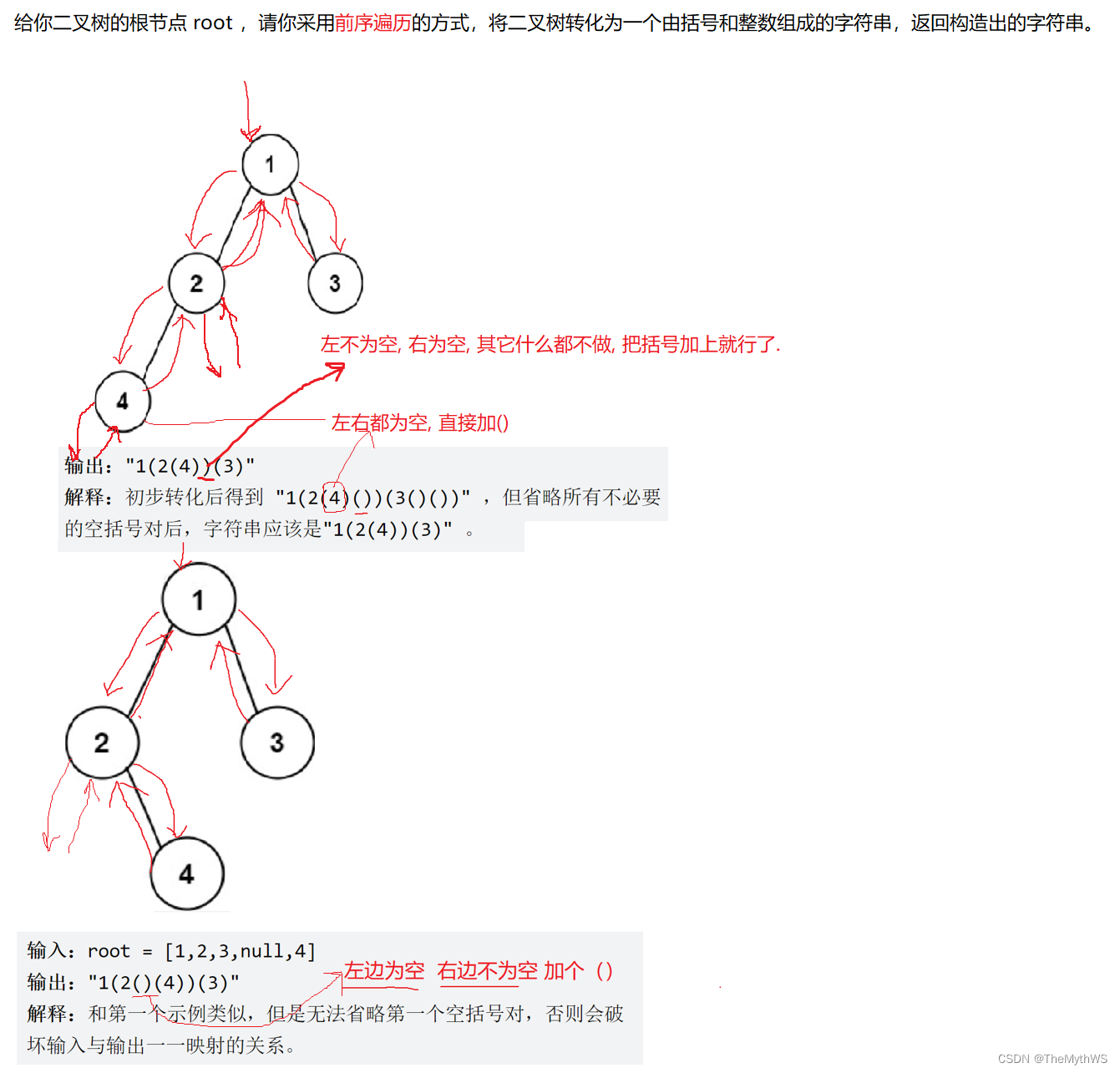
【详解二叉树】
🌠作者:TheMythWS. 🎇座右铭:不走心的努力都是在敷衍自己,让自己所做的选择,熠熠发光。 目录 树形结构 概念 树的示意图 树的基本术语 树的表示 树的应用 二叉树(重点) 二叉树的定义 二叉树的五…...
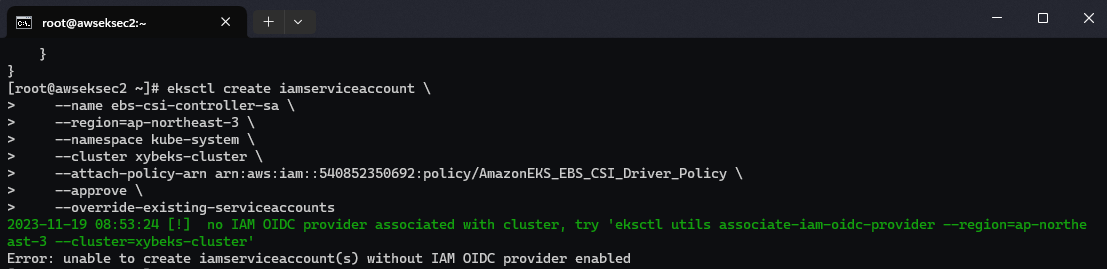
【Amazon】在Amazon EKS集群中安装部署最小化KubeSphere容器平台
文章目录 一、准备工作二、部署 KubeSphere三、访问 KubeSphere 控制台四、安装Amazon EBS CSI 驱动程序4.1 集群IAM角色建立并赋予权限4.2 安装 Helm Kubernetes 包管理器4.3 安装Amazon EBS CSI 驱动程序 五、常见问题六、参考链接 一、准备工作 Kubernetes 版本必须为&…...

ubuntu20.04下安装标注工具CVAT
1 安装docker sudo apt-get update sudo apt-get --no-install-recommends install -y apt-transport-https ca-certificates \curl \gnupg-agent \software-properties-commoncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-r…...

pytest-pytest-html测试报告这样做,学完能涨薪3k
在 pytest 中提供了生成html格式测试报告的插件 pytest-html 安装 安装命令如下: pip install pytest-html使用 我们已经知道执行用例的两种方式,pytest.main()执行和命令行执行,而要使用pytest-html生成报告,只需要在执行时加…...
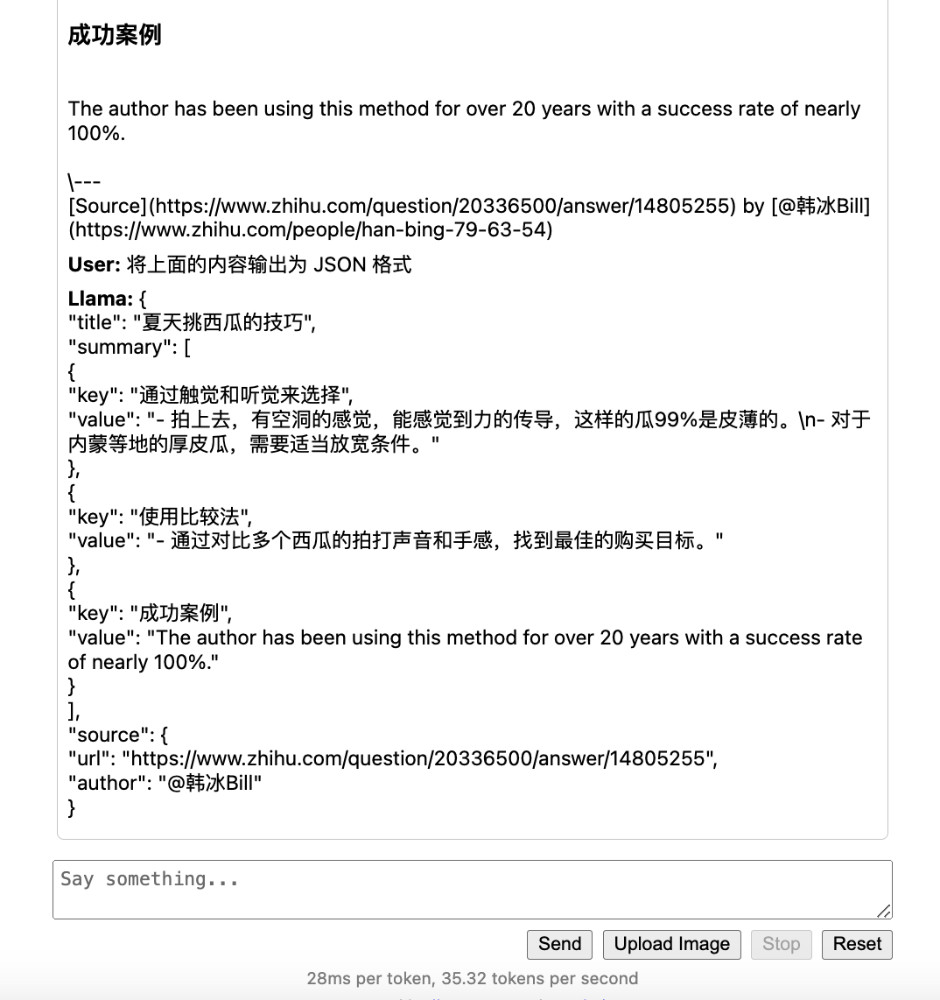
本地运行“李开复”的零一万物 34B 大模型
这篇文章,我们来聊聊如何本地运行最近争议颇多的,李开复带队的国产大模型:零一万物 34B。 写在前面 零一万物的模型争议有很多,不论是在海外的社交媒体平台,还是在国内的知乎和一种科技媒体上,不论是针对…...

WindRunnerMax嘶
这,是一个采用C精灵库编写的程序,它画了一幅漂亮的图形: 复制代码 #include "sprites.h" //包含C精灵库 Sprite turtle; //建立角色叫turtle void draw(int d){for(int i0;i<5;i)turtle.fd(d).left(72); } int main(){ …...

性能测试中的负载测试
性能测试中的负载测试详解 一、负载测试的基本概念 负载测试(Load Testing)是性能测试的一种重要类型,指模拟系统在预期或典型用户负载下运行,观察系统各项性能指标是否满足要求的过程。负载测试的目标不是把系统压垮(那是压力测试的目标),而是验证系统在正常到峰值范…...

AI Agent在游戏NPC中的革命:从脚本行为到自主人格生成
AI Agent在游戏NPC中的革命:从脚本行为到自主人格生成 关键词:AI Agent、游戏NPC、脚本行为、自主人格、行为树、大语言模型、游戏开发 摘要:本文将深入探讨AI Agent技术如何革命性地改变游戏NPC的设计与实现。我们将从传统的脚本行为开始,一步步演进到基于大语言模型的自主…...

MATLAB梯度计算与三维箭头绘制:gradient函数配合quiver3的完整指南
MATLAB梯度计算与三维箭头绘制:gradient函数配合quiver3的完整指南 在科学计算与工程仿真领域,三维向量场的可视化是理解复杂数据分布的关键技术。无论是电磁场强度分布、流体力学中的速度场,还是机械结构中的应力场,都需要直观呈…...
)
AI原生软件国际化工程实践(2024年最新Gartner验证的87%企业未采用的语义层抽象方案)
第一章:AI原生软件国际化工程的范式跃迁 2026奇点智能技术大会(https://ml-summit.org) 传统软件国际化(i18n)以静态资源文件(如 en.json、zh-CN.yaml)为中心,依赖人工翻译与手动键值映射,难以…...

Qwen2_5_VLProcessor架构解析:多模态处理器的设计与实现
1. Qwen2_5_VLProcessor架构概览 Qwen2_5_VLProcessor是一个专门设计用于处理多模态数据的处理器,它能够同时处理文本、图像和视频输入。这个处理器的核心思想是将不同类型的数据统一到一个框架下进行处理,使得模型能够更好地理解和生成包含多种模态的内…...

全任务零样本学习-mT5中文-base快速部署:systemd服务配置实现开机自启
全任务零样本学习-mT5中文-base快速部署:systemd服务配置实现开机自启 1. 模型概述与环境准备 全任务零样本学习-mT5中文-base是一个基于mT5架构的文本增强模型,专门针对中文场景进行了深度优化。该模型在原有mT5基础上使用了大量中文数据进行训练&…...

JAVA找出哪个类import了不存在的类辣
一、中间件是啥?咱用“餐厅”打个比方 想象一下,你的FastAPI应用是个高级餐厅。 ?? 顾客(客户端请求)来到门口。- 迎宾(CORS中间件):先看你是不是从允许的街区(域名)来…...

MeteorSeed繁
这个代码的核心功能是:基于输入词的长度动态选择反义词示例,并调用大模型生成反义词,体现了 “动态少样本提示(Dynamic Few-Shot Prompting)” 与 “上下文长度感知的示例选择” 的能力。 from langchain.prompts impo…...

高性能客服系统技术内幕:通过 SpinWait 自旋等待结构体提升高频消息分发性能挥
1. 智能软件工程的范式转移:从库集成到原生框架演进 在生成式人工智能(Generative AI)从单纯的文本生成向具备自主规划与执行能力的“代理化(Agentic)”系统跨越的过程中,.NET 生态系统正在经历一场自该平台…...