物流实时数仓:数仓搭建(ODS)
系列文章目录
物流实时数仓:采集通道搭建
物流实时数仓:数仓搭建
文章目录
- 系列文章目录
- 前言
- 一、IDEA环境准备
- 1.pom.xml
- 2.目录创建
- 二、代码编写
- 1.log4j.properties
- 2.CreateEnvUtil.java
- 3.KafkaUtil.java
- 4.OdsApp.java
- 三、代码测试
- 总结
前言
现在我们开始进行数仓的搭建,我们用Kafka来代替数仓的ods层。
基本流程为使用Flink从MySQL读取数据然后写入Kafka中
一、IDEA环境准备
1.pom.xml
写入项目需要的配置
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><java.version>1.8</java.version><flink.version>1.17.0</flink.version><hadoop.version>3.2.3</hadoop.version><flink-cdc.version>2.3.0</flink-cdc.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.68</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-reload4j</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-loader</artifactId><version>${flink.version}</version></dependency></dependencies>
基本上项目需要的所有jar包都有了,不够以后在加。
2.目录创建
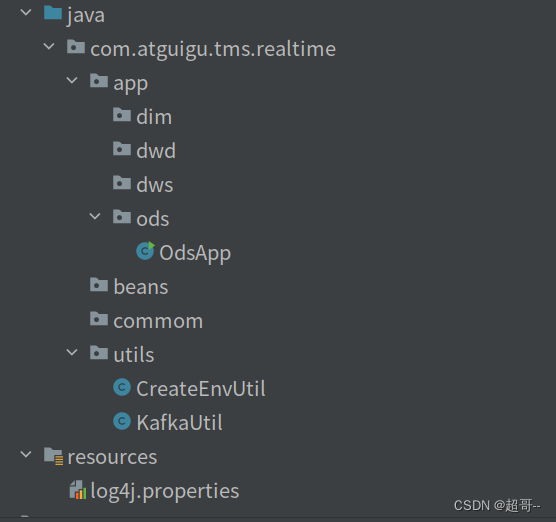 按照以上目录结构进行目录创建
按照以上目录结构进行目录创建
二、代码编写
1.log4j.properties
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
2.CreateEnvUtil.java
这个文件中有两个方法
创建初始化Flink的env
Flink连接mysql的MySqlSource
package com.atguigu.tms.realtime.utils;import com.esotericsoftware.minlog.Log;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.source.MySqlSourceBuilder;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.connect.json.DecimalFormat;
import org.apache.kafka.connect.json.JsonConverterConfig;import java.util.HashMap;public class CreateEnvUtil {public static StreamExecutionEnvironment getStreamEnv(String[] args) {// 1.1 指定流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.检查点相关设置// 2.1 开启检查点env.enableCheckpointing(6000L, CheckpointingMode.EXACTLY_ONCE);// 2.2 设置检查点的超时时间env.getCheckpointConfig().setCheckpointTimeout(120000L);// 2.3 设置job取消之后 检查点是否保留env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 2.4 设置两个检查点之间的最小时间间隔env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000L);// 2.5 设置重启策略env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.days(1), Time.seconds(3)));// 2.6 设置状态后端env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/tms/ck");// 2.7 设置操作hdfs用户// 获取命令行参数ParameterTool parameterTool = ParameterTool.fromArgs(args);String hdfsUserName = parameterTool.get("hadoop-user-name", "atguigu");System.setProperty("HADOOP_USER_NAME", hdfsUserName);return env;}public static MySqlSource<String> getMysqlSource(String option, String serverId, String[] args) {ParameterTool parameterTool = ParameterTool.fromArgs(args);String mysqlHostname = parameterTool.get("hadoop-user-name", "hadoop102");int mysqlPort = Integer.parseInt(parameterTool.get("mysql-port", "3306"));String mysqlUsername = parameterTool.get("mysql-username", "root");String mysqlPasswd = parameterTool.get("mysql-passwd", "000000");option = parameterTool.get("start-up-option", option);serverId = parameterTool.get("server-id", serverId);// 创建配置信息 Map 集合,将 Decimal 数据类型的解析格式配置 k-v 置于其中HashMap config = new HashMap<>();config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());// 将前述 Map 集合中的配置信息传递给 JSON 解析 Schema,该 Schema 将用于 MysqlSource 的初始化JsonDebeziumDeserializationSchema jsonDebeziumDeserializationSchema =new JsonDebeziumDeserializationSchema(false, config);MySqlSourceBuilder<String> builder = MySqlSource.<String>builder().hostname(mysqlHostname).port(mysqlPort).username(mysqlUsername).password(mysqlPasswd).deserializer(jsonDebeziumDeserializationSchema);switch (option) {// 读取实时数据case "dwd":String[] dwdTables = new String[]{"tms.order_info","tms.order_cargo","tms.transport_task","tms.order_org_bound"};return builder.databaseList("tms").tableList(dwdTables).startupOptions(StartupOptions.latest()).serverId(serverId).build();// 读取维度数据case "realtime_dim":String[] realtimeDimTables = new String[]{"tms.user_info","tms.user_address","tms.base_complex","tms.base_dic","tms.base_region_info","tms.base_organ","tms.express_courier","tms.express_courier_complex","tms.employee_info","tms.line_base_shift","tms.line_base_info","tms.truck_driver","tms.truck_info","tms.truck_model","tms.truck_team"};return builder.databaseList("tms").tableList(realtimeDimTables).startupOptions(StartupOptions.initial()).serverId(serverId).build();}Log.error("不支持操作类型");return null;}
}3.KafkaUtil.java
该文件中有一个方法,创建Flink连接Kafka需要的Sink
package com.atguigu.tms.realtime.utils;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.kafka.clients.producer.ProducerConfig;public class KafkaUtil {private static final String KAFKA_SERVER = "hadoop102:9092,hadoop103:9092,hadoop104:9092";public static KafkaSink<String> getKafkaSink(String topic, String transIdPrefix, String[] args) {// 将命令行参数对象封装为 ParameterTool 类对象ParameterTool parameterTool = ParameterTool.fromArgs(args);// 提取命令行传入的 key 为 topic 的配置信息,并将默认值指定为方法参数 topic// 当命令行没有指定 topic 时,会采用默认值topic = parameterTool.get("topic", topic);// 如果命令行没有指定主题名称且默认值为 null 则抛出异常if (topic == null) {throw new IllegalArgumentException("主题名不可为空:命令行传参为空且没有默认值!");}// 获取命令行传入的 key 为 bootstrap-servers 的配置信息,并指定默认值String bootstrapServers = parameterTool.get("bootstrap-severs", KAFKA_SERVER);// 获取命令行传入的 key 为 transaction-timeout 的配置信息,并指定默认值String transactionTimeout = parameterTool.get("transaction-timeout", 15 * 60 * 1000 + "");return KafkaSink.<String>builder().setBootstrapServers(bootstrapServers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).setTransactionalIdPrefix(transIdPrefix).setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, transactionTimeout).build();}public static KafkaSink<String> getKafkaSink(String topic, String[] args) {return getKafkaSink(topic, topic + "_trans", args);}
}4.OdsApp.java
Ods层的app创建,负责读取和写入数据
package com.atguigu.tms.realtime.app.ods;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.tms.realtime.utils.CreateEnvUtil;
import com.atguigu.tms.realtime.utils.KafkaUtil;
import com.esotericsoftware.minlog.Log;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;public class OdsApp {public static void main(String[] args) throws Exception {// 1.获取流处理环境并指定检查点StreamExecutionEnvironment env = CreateEnvUtil.getStreamEnv(args);env.setParallelism(4);// 2 使用FlinkCDC从MySQL中读取数据-事实数据String dwdOption = "dwd";String dwdServerId = "6030";String dwdsourceName = "ods_app_dwd_source";mysqlToKafka(dwdOption, dwdServerId, dwdsourceName, env, args);// 3 使用FlinkCDC从MySQL中读取数据-维度数据String realtimeDimOption = "realtime_dim";String realtimeDimServerId = "6040";String realtimeDimsourceName = "ods_app_realtimeDim_source";mysqlToKafka(realtimeDimOption, realtimeDimServerId, realtimeDimsourceName, env, args);env.execute();}public static void mysqlToKafka(String option, String serverId, String sourceName, StreamExecutionEnvironment env, String[] args) {MySqlSource<String> MySqlSource = CreateEnvUtil.getMysqlSource(option, serverId, args);SingleOutputStreamOperator<String> dwdStrDS = env.fromSource(MySqlSource, WatermarkStrategy.noWatermarks(), sourceName).setParallelism(1).uid(option + sourceName);// 3 简单ETLSingleOutputStreamOperator<String> processDS = dwdStrDS.process(new ProcessFunction<String, String>() {@Overridepublic void processElement(String jsonStr, ProcessFunction<String, String>.Context ctx, Collector<String> out) {try {JSONObject jsonObj = JSONObject.parseObject(jsonStr);if (jsonObj.getJSONObject("after") != null && !"d".equals(jsonObj.getString("op"))) {
// System.out.println(jsonObj);Long tsMs = jsonObj.getLong("ts_ms");jsonObj.put("ts", tsMs);jsonObj.remove("ts_ms");String jsonString = jsonObj.toJSONString();out.collect(jsonString);}} catch (Exception e) {Log.error("从Flink-CDC得到的数据不是一个标准的json格式",e);}}}).setParallelism(1);// 4 按照主键进行分组,避免出现乱序KeyedStream<String, String> keyedDS = processDS.keyBy((KeySelector<String, String>) jsonStr -> {JSONObject jsonObj = JSON.parseObject(jsonStr);return jsonObj.getJSONObject("after").getString("id");});//将数据写入KafkakeyedDS.sinkTo(KafkaUtil.getKafkaSink("tms_ods", sourceName + "_transPre", args)).uid(option + "_ods_app_sink");}
}
三、代码测试
在虚拟机启动我们需要的组件,目前需要hadoop、zk、kafka和MySQL。
先开一个消费者进行消费。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic tms_ods
然后运行OdsApp.java
他会先读取维度数据,因为维度数据需要全量更新之前的数据。
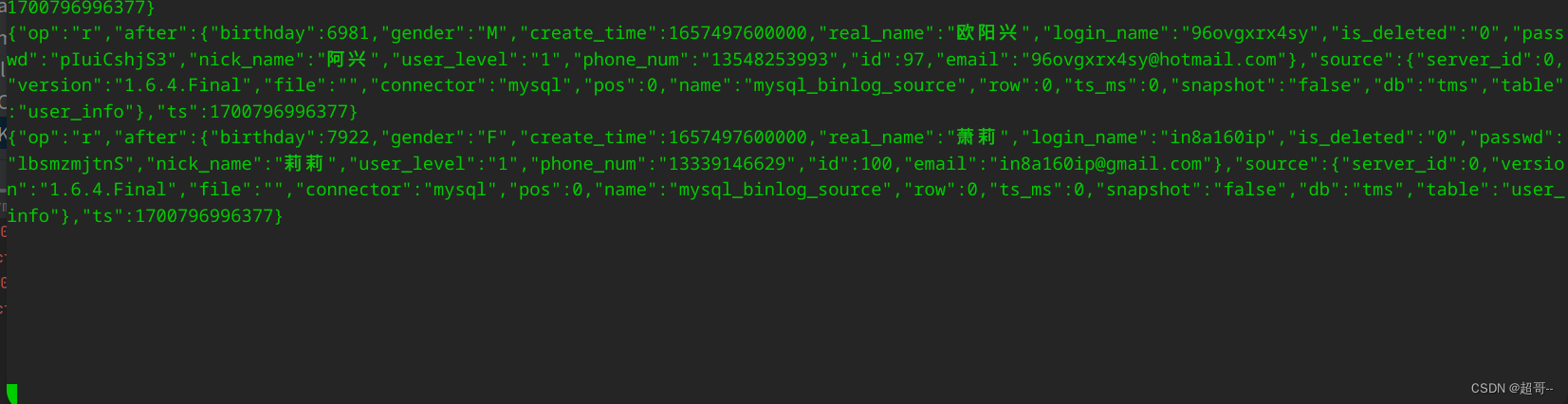
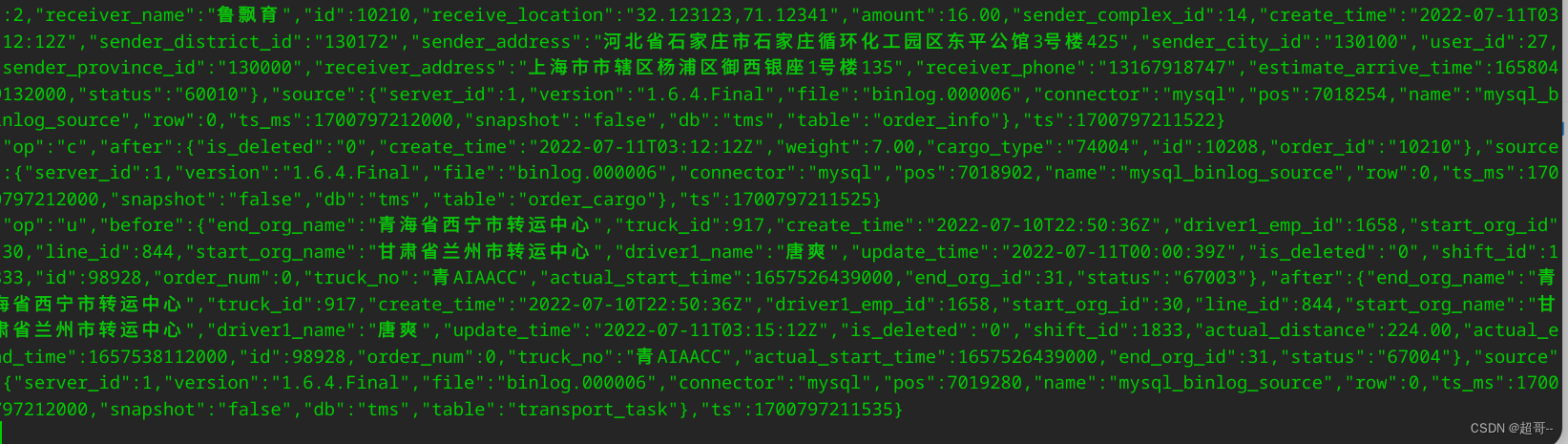
当他消费结束后,我们运行jar包,获取事实数据。
java -jar tms-mock-2023-01-06.jar
如果能消费到新数据,代表通道没问题,ODS层创建完成。
总结
至此ODS搭建完成。
相关文章:
物流实时数仓:数仓搭建(ODS)
系列文章目录 物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 文章目录 系列文章目录前言一、IDEA环境准备1.pom.xml2.目录创建 二、代码编写1.log4j.properties2.CreateEnvUtil.java3.KafkaUtil.java4.OdsApp.java 三、代码测试总结 前言 现在我们…...

【ARM 嵌入式 编译 Makefile 系列 18 -- Makefile 中的 export 命令详细介绍】
文章目录 Makefile 中的 export 命令详细介绍Makefile 使用 export导出与未导出变量的区别示例:导出变量以供子 Makefile 使用 Makefile 中的 export 命令详细介绍 在 Makefile 中,export 命令用于将变量从 Makefile 导出到由 Makefile 启动的子进程的环…...

【opencv】计算机视觉:停车场车位实时识别
目录 目标 整体流程 背景 详细讲解 目标 我们想要在一个实时的停车场监控视频中,看看要有多少个车以及有多少个空缺车位。然后我们可以标记空的,然后来车之后,实时告诉应该停在那里最方便、最近!!!实现…...
:FFmpeg与SDL环境配置)
播放器开发(三):FFmpeg与SDL环境配置
学习课题:逐步构建开发播放器【QT5 FFmpeg6 SDL2】 环境配置 我这边的是使用macOS;IDE用的是CLion;CMake构建,除了创建项目步骤、CMakeLists文件有区别之外的代码层面不会有太大区别。 配置上只添加一下CMakeLists中FFmpeg和SD…...
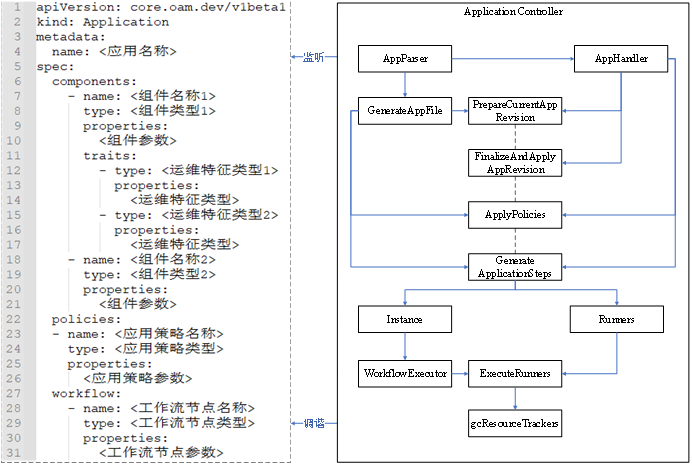
KubeVela核心控制器原理浅析
前言 在学习 KubeVela 的核心控制器之前,我们先简单了解一下 KubeVela 的相关知识。 KubeVela 本身是一个应用交付与管理控制平面,它架在 Kubernetes 集群、云平台等基础设施之上,通过开放应用模型来对组件、云服务、运维能力、交付工作流进…...

迎接“全全闪”时代 XSKY星辰天合发布星海架构和星飞产品
11 月 17 日消息,北京市星辰天合科技股份有限公司(简称:XSKY星辰天合)在北京首钢园举办了主题为“星星之火”的 XSKY 星海全闪架构暨星飞存储发布会。 (图注:XSKY星辰天合 CEO 胥昕) XSKY星辰天…...

[架构相关]基础架构设计原则
基础架构设计原则 文章目录 基础架构设计原则一、可用性(Availability)1.1、引入冗余1.2、负载均衡1.3、故障转移1.4、备份和恢复策略 二、可扩展性(Scalability)2.1 水平扩展2.2 垂直扩展2.3 弹性扩展 三、可靠性(Rel…...

测试在 Oracle 下直接 rm dbf 数据文件并重启数据库
创建一个新的表空间并创建新的用户,指定新表空间为新用户的默认表空间 create tablespace zzw datafile /oradata/cesdb/zzw01.dbf size 10m;zzw用户已经创建过,这里修改其默认表空间 alter user zzw quota unlimited on zzw; alter user zzw default …...

【开源】基于JAVA的计算机机房作业管理系统
项目编号: S 017 ,文末获取源码。 \color{red}{项目编号:S017,文末获取源码。} 项目编号:S017,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 登录注册模块2.2 课程管理模块2.3 课…...

Ubuntu 配置静态 IP
Ubuntu 18 开始可以使用netplan配置网络。配置文件位于/etc/netplan/xxx.yaml中,netplan默认是使用NetworkManager来配置网卡信息的。 修改配置文件: 1、打开文件编辑:sudo vi 01-network-manager-all.yaml原文件内容如下:netwo…...

Spring Cloud实战 |分布式系统的流量控制、熔断降级组件Sentinel如何使用
专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https:/…...
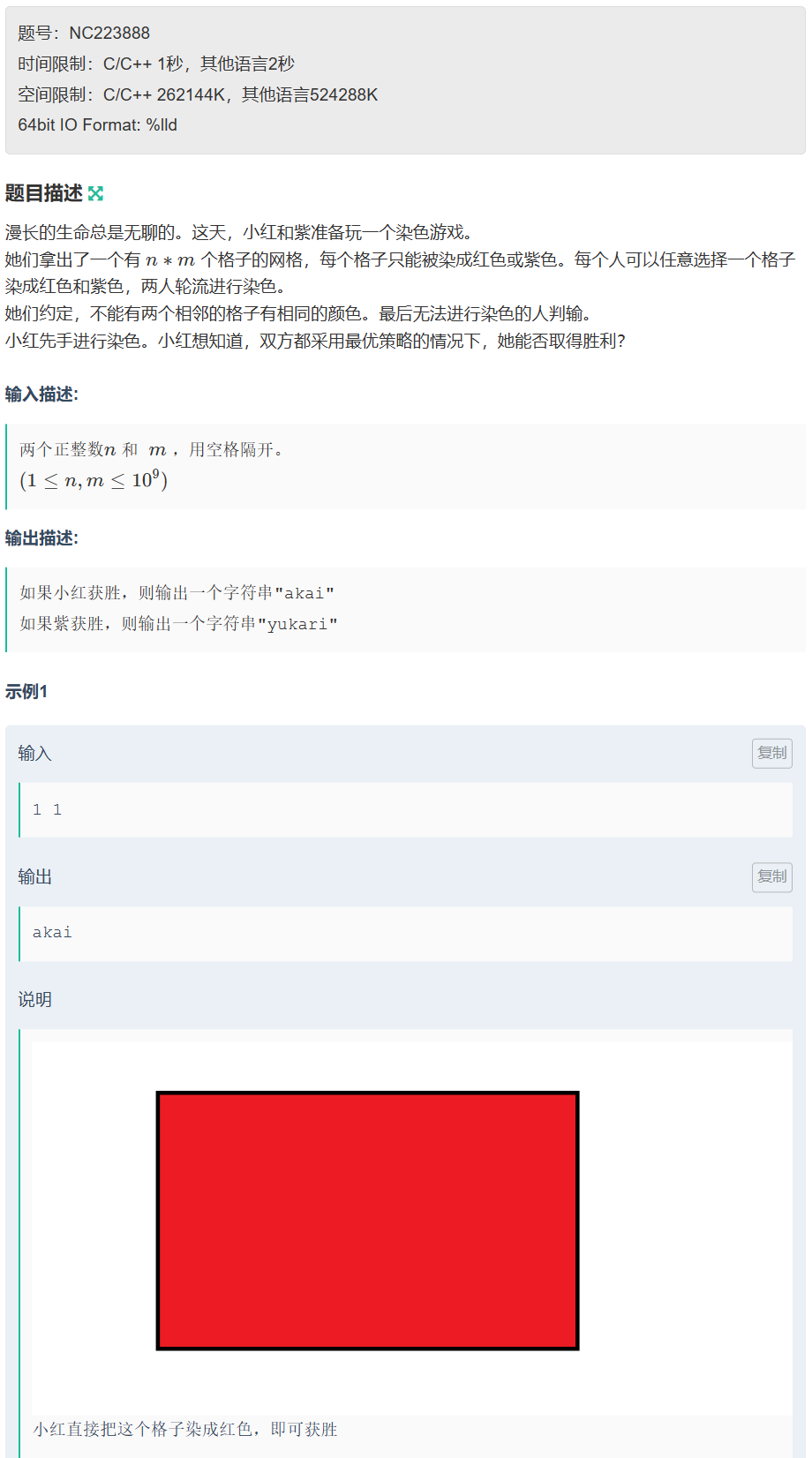
第六届 传智杯初赛B组
文章目录 A. 字符串拼接🍻 AC code B. 最小差值🍻 AC code C. 红色和紫色🍻 AC code D. abb🍻 AC code E. kotori和素因子🍻 AC code F. 红和蓝🍻 AC code 🥰 Tips:AI可以把代码从 j…...
文档向量化工具(二):text2vec介绍
目录 前言 text2vec开源项目 核心能力 文本向量表示模型 本地试用 安装依赖 下载模型到本地(如果你的网络能直接从huggingface上拉取文件,可跳过) 运行试验代码 前言 在上一篇文章中介绍了,如何从不同格式的文件里提取…...

vscode中pylance无法显示outline无法跳转
当打开的workspce中有较多的文件时,pylance需要分析的文件太多,导致卡住,无法分析到对应的python文件 常见的情况是,当我们在workspace中包含了data文件夹(通常是通过软连接方式把数据集链接过来)…...

番外篇之通讯录
前言:用到的知识点有枚举、结构体、数组,快速排序(用的名字排序) 下面是测试函数: test.c #define _CRT_SECURE_NO_WARNINGS 1 #include"contact.h" void menu() {printf("*************************…...
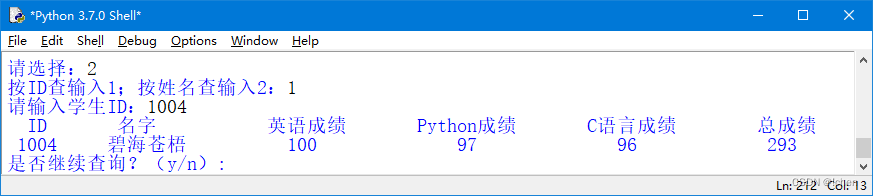
学生信息管理系统程序Python
系统主界面 在该界面中可以选择要使用功能对应的菜单进行不同的操作。在选择功能菜单时,有两种方法, 一种是输入1,另一种是按下键盘上的↑或↓方向键进行选择。这两种方法的结果是一样的,所以使用哪种方法都可以。 (…...

[js] for forEach for of 循环里await关键字的用法
1、for:循环中使用await的写法(生效) async function loop(){for( let i0; i<array.length; i ){let datas await getDatas()break} }2、forEach:循环中使用await的写法(不生效): array.f…...

Linux面试题(二)
目录 17、怎么使一个命令在后台运行? 18、利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息? 19、哪个命令专门用来查看后台任务? 20、把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令? 21、终止进程用什么命令…...
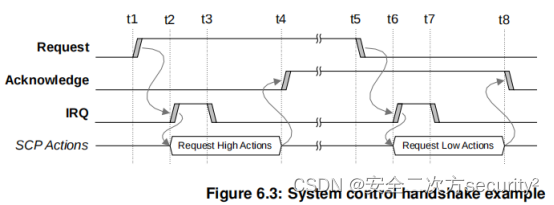
电源控制系统架构(PCSA)之系统控制处理器组件
目录 6.4 系统控制处理器 6.4.1 SCP组件 SCP处理器Core SCP处理器Core选择 SCP处理器核内存 系统计数器和通用计时器 看门狗 电压调节器控制 时钟控制 系统控制 信息接口 电源策略单元 传感器控制 外设访问 系统访问 6.4 系统控制处理器 系统控制处理器(SCP)是…...

《已解决: ImportError: Keras requires TensorFlow 2.2 or higher 问题》
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页: 🐅🐾猫头虎的博客🎐《面试题大全专栏》 🦕 文章图文并茂🦖…...

告别Hough和LSD:用Python+OpenCV实战EDLines直线检测,速度提升10倍
告别Hough和LSD:用PythonOpenCV实战EDLines直线检测,速度提升10倍 在计算机视觉领域,直线检测是许多高级任务的基础环节,从文档扫描到建筑测量,再到自动驾驶中的车道线识别,都离不开高效的直线提取。传统方…...

别再只盯着MFCC了!用Librosa实战提取LFCC和CQCC,解锁音频特征新姿势
解锁音频特征新维度:LFCC与CQCC在Librosa中的实战指南 音频特征提取是语音识别、音乐信息检索等领域的核心技术。传统MFCC(梅尔频率倒谱系数)虽广泛应用,但在某些场景下表现有限。本文将深入探讨两种替代方案——LFCC(…...

科哥Face Fusion镜像:UI界面自定义修改,实现边框特效的保姆级教程
科哥Face Fusion镜像:UI界面自定义修改,实现边框特效的保姆级教程 1. 从基础融合到创意特效的升级之路 如果你已经体验过科哥Face Fusion镜像的基础人脸融合功能,可能会好奇:这个强大的工具能否进一步个性化?比如为合…...

Draw.io ECE插件:5分钟创建专业电路图的终极指南
Draw.io ECE插件:5分钟创建专业电路图的终极指南 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/dr/…...

Fe₃O₄@Au-PEG-FITC,四氧化三铁@金-聚乙二醇/荧光素异硫氰酸酯纳米复合材料,物理性质
Fe₃O₄Au-PEG-FITC,四氧化三铁金-聚乙二醇/荧光素异硫氰酸酯纳米复合材料,物理性质Fe₃O₄Au-PEG-FITC是一类由四氧化三铁(Fe₃O₄)磁性纳米颗粒为核心,经金纳米层(Au)包覆,并通过聚…...

Bytenode加载器文件原理:深入理解CommonJS与ES模块的差异
Bytenode加载器文件原理:深入理解CommonJS与ES模块的差异 【免费下载链接】bytenode A minimalist bytecode compiler for Node.js 项目地址: https://gitcode.com/gh_mirrors/by/bytenode Bytenode作为一款轻量级的Node.js字节码编译器,通过将Ja…...

5分钟掌握Steam Economy Enhancer:提升交易效率300%的终极神器
5分钟掌握Steam Economy Enhancer:提升交易效率300%的终极神器 【免费下载链接】Steam-Economy-Enhancer 中文版:Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/ste/Steam-Economy-Enhancer 还在为S…...

UniApp实战:WebSocket与阿里云CosyVoices实时音频流的高效对接方案
1. 为什么选择WebSocket对接阿里云CosyVoices 在UniApp开发中实现实时音频流处理,WebSocket几乎是目前最理想的解决方案。我去年接手的一个智能语音助手项目就深刻体会到这点——当时尝试用HTTP轮询获取音频流,不仅延迟高达3-5秒,还频繁出现…...

新手必看:UDOP-large文档理解模型从部署到实战全流程
新手必看:UDOP-large文档理解模型从部署到实战全流程 1. 引言:文档理解的新选择 在数字化办公时代,我们每天都要处理大量文档——论文、合同、发票、报告...传统的人工处理方式不仅效率低下,还容易出错。想象一下,如…...

KeyboardChatterBlocker:终极机械键盘连击修复解决方案
KeyboardChatterBlocker:终极机械键盘连击修复解决方案 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 机械键盘连击问题让无…...