单细胞seurat入门—— 从原始数据到表达矩阵
根据所使用的建库方法,单细胞的RNA序列(也称为读取(reads)或标签(tags))将从转录本的3'端(或5'端)(10X Genomics,CEL-seq2,Drop-seq,inDrops)或全长转录本(Smart-seq)获得。

图片来源: Papalexi E and Satija R. Single-cell RNA sequencing to explore immune cell heterogeneity, Nature Reviews Immunology 2018 (https://doi.org/10.1038/nri.2017.76)
我们可以根据自己感兴趣的生物学问题而选择不同的方法。这些方法具有以下优点:
- 3'(或5')端测序:
- 通过独特的分子标记物(molecular identifiers)来更准确地定量鉴别生物复制品和扩增(PCR)复制品
- 可以给更多的细胞测序,更好地识别细胞类群
- 每个细胞的平均测序成本更低
- 最适用于10000个以上的细胞
- 全长(Full length)测序
- 可以检测到亚型水平上的表达差异
- 可以进行等位基因(allele-specific)表达差异的检测
- 可以给少量细胞进行更深度的测序
- 最适用于细胞量少的样本
全长测序和3'端测序需要进行许多相同的分析步骤,但3'端流程越来越受欢迎,在分析过程中包含了更多的步骤。因此,我们的教程将详细分析这些3'端流程的数据,重点是基于液滴的方法(inDrops,Drop seq,10X Genomics)。
3’端测序(包括所有基于液滴的方法)
对于单细胞RNA测序的数据分析来说,理解在每次读取中获得的信息,以及我们如何在分析过程中使用这些信息是非常有帮助的。
对于3'端测序的方法,来自同一转录本不同分子的读取只能来自转录本的3'端,因此具有相同序列的可能性很高。然而,在建库过程中的PCR步骤也可能产生读取重复。为了确定一次读取是生物重复还是技术重复,这些方法使用了唯一的分子标识符(UMIs)。
- 使用不同UMI映射到同一个转录本的读取来自不同的分子,是生物学上的复制-每个读取都应该被计数。
- 具有相同UMI的读取源于同一分子,是技术上的复制-这些UMI应该合并为一个读取的计数。
- 在下图中,ACTB的读取应合并计为单个读取,而ARL1的读取应分别计为单个读取。

图片来源: modified from Macosko EZ et al. Highly Parallel Genome-wide Expression Profiling of Individual Cells Using Nanoliter Droplets, Cell 2015 (https://doi.org/10.1016/j.cell.2015.05.002)
所以我们需要追踪UMI,除此之外,我们还需要什么信息来正确量化样本中每个细胞中每个基因的表达呢?无论使用何种基于液滴的方法,在细胞水平上进行正确的定量需要以下条件:
- 样本索引 (Sample index):确定读取来自于哪个样本。在建库期间添加——需要记录
- 细胞条形码 (Celluar barcode):确定读取来自于哪个细胞。每个建库方法都有一个供在建库期间使用的细胞条形码库存(stock)
- 唯一分子标识符 (UMI):确定读取来自哪个转录分子。UMI将被用于合并PCR复制物
- 测序读取1 (Sequencing read1):1号读取序列
- 测序读取2 (Sequencing read2):2号读取序列
例如,当使用inDrops v3建库方法时,以下内容显示如何在四次读取中获取所有信息:

图片来源:Sarah Boswell, Director of the Single Cell Sequencing Core at HMS
- R1 (61bp 读取1):读取的序列(顶部红色箭头)
- R2 (8bp 索引读取1(i7)):细胞条码 —— 判断读取来自于哪个细胞(顶部紫色箭头)
- R3 (8bp 索引读取2(i5)):样本/库索引 —— 判断读取来自哪个样本(底部红色箭头)
- R4 (14bp 读取2):读取2和剩下的细胞条形码和UMI —— 读取来自于哪个转录本(底部紫色箭头)
对于不同的基于液滴的单细胞RNA测序方法,分析流程是相似的,但是对UMI、细胞ID和样本索引的分析将有所不同。例如,下面是10X序列读取的示意图,其中索引、UMI和条码的位置不同:

图片来源: Sarah Boswell, Director of the Single Cell Sequencing Core at HMS
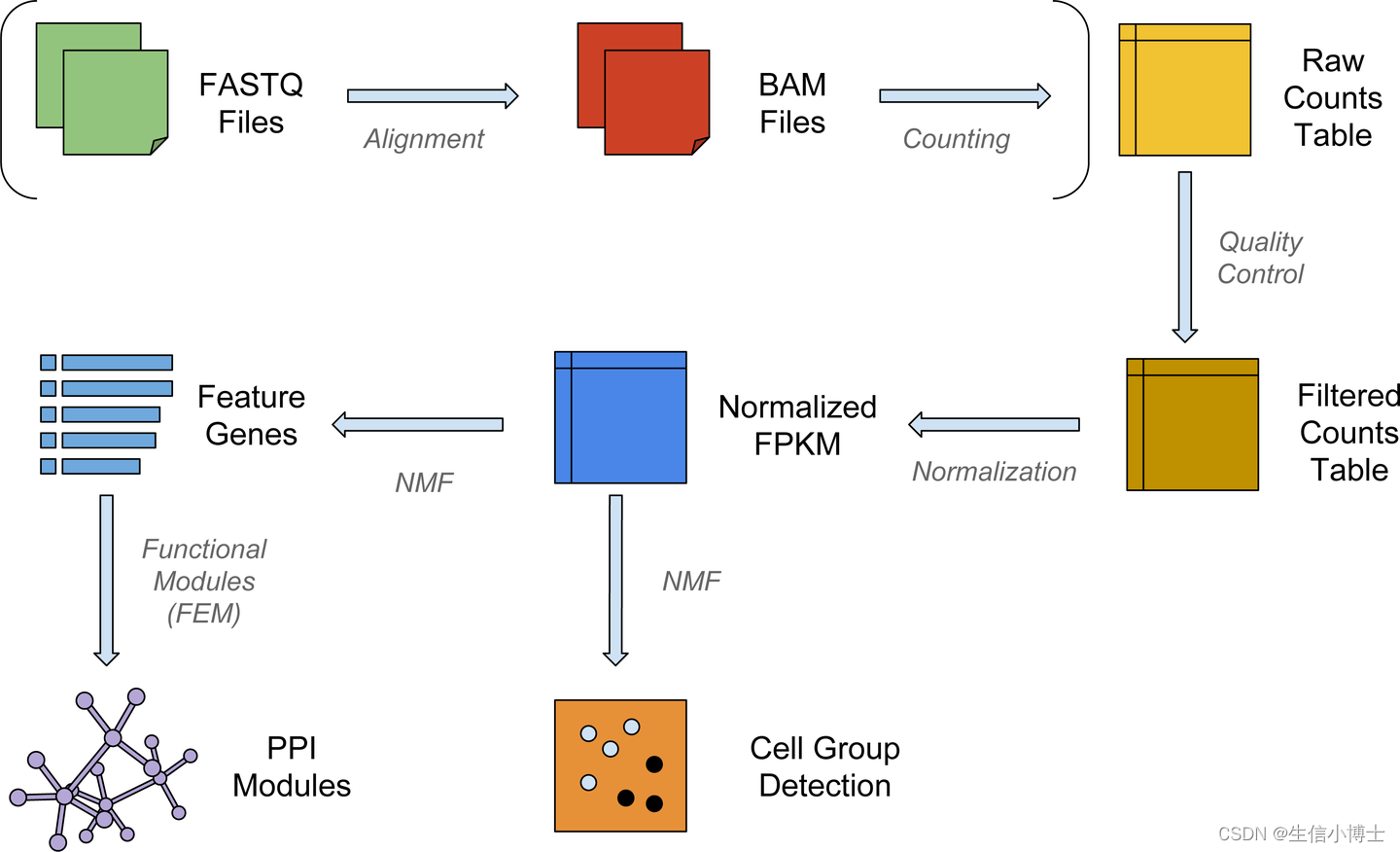
单细胞RNA测序的工作流程
单细胞RNA测序方法将确定如何从序列读取中解析条码和UMI。因此,尽管一些具体步骤略有不同,总体工作流程通常会遵循相同的步骤,而不考虑方法的差异。一般工作流程如下:

图片来源: Luecken, MD and Theis, FJ. Current best practices in single‐cell RNA‐seq analysis: a tutorial, Mol Syst Biol 2019 (doi: https://doi.org/10.15252/msb.20188746)
工作流程的步骤是:
- 生成计数矩阵 (Generation of the count matrix):格式化读取、分离样本、映射(mapping)和定量(quantification)
- 原始计数矩阵的质量控制 (Quality control of the raw counts):过滤掉质量差的细胞
- 过滤后计数的聚类 (Clustering of filtered counts):将转录活动相似的细胞归为一类(细胞类型=不同的聚类)
- 标记识别 (Marker identification):识别每个细胞群的基因标记(marker)
- 其他可选的下游步骤 (Optional downstream steps)
不管做什么样的分析,基于每种情况的单一样本而得出关于群体的结论都是不可信的。生物学重复仍然是非常必要的!也就是说,如果你想得出与总体相对应的结论,不应该局限于单一样本。
生成计数矩阵
我们将从讨论该工作流程的第一部分开始,该部分是从原始序列数据生成计数矩阵。我们将重点关注基于液滴的3'端测序,如inDrops、10X Genomics和Drop seq。

测序后,测序设备将原始测序数据输出为BCL或FASTQ格式,或生成计数矩阵 (count matrix)。如果读取的是BCL格式,那么我们需要转换为FASTQ格式。有一个名为bcl2fastq的命令行工具可以轻松地完成此转换。
注:在工作流程的这一步,我们不进行分离。您可能已经对6个样本进行了测序,但所有样本的读取可能都出现在同一个BCL或FASTQ文件中。
在许多单细胞RNA测序方法中,从原始数据生成计数矩阵将会经历很多类似的步骤。

umis 和 zUMIs 是用来估算3'端转录本测序数据表达量的命令行工具。两种工具都包含了UMIs的合并以校正扩增偏差(amplification bias)的功能。此过程中的步骤包括:
- 格式化读写并过滤低质量的细胞条码
- 分离样本
- 比对/伪映射到转录组
- 合并UMI并量化读写
如果使用10X Genomic建库方法, Cell Ranger 流程将会被用于以上所有的步骤。
1. 格式化读写并过滤低质量的细胞条码
FASTQ文件可被用于解析细胞条码、UMI和样本条码。对于基于液滴的方法,由于以下原因,许多细胞条码将会匹配到数量较少(< 1000)的读取,这是因为:
- 封装了来自于死/濒死细胞的游离RNA
- 混入了只表达少量基因的简单细胞(如红细胞等)
- 其他因素的影响
这些多余的条码需要在读取比对之前从测序数据中过滤掉。要进行此筛选,将提取并保存每个细胞的“细胞条码”和“分子条码”。例如,如果使用了umis工具,每次读取时都会将信息添加到标题行,格式如下:
@HWI-ST808:130:H0B8YADXX:1:1101:2088:2222:CELL_GGTCCA:UMI_CCCTAGGAAGATGGAGGAGAGAAGGCGGTGAAAGAGACCTGTAAAAAGCCACCGN+@@@DDBD>=AFCF+<CAFHDECII:DGGGHGIGGIIIEHGIIIGIIDHII#建库方法中使用的细胞条码应该是已知的,且未知的条码将会被丢弃,同时允许存在适量与已知细胞条码不匹配的现象。
2. 分离样本读取
如果测序不止一个样本,这个过程的下一步是对样本进行分离。这个步骤不是由umis工具完成,而是由zUMIs完成的。我们需要对读取的数据进行分析,以确定与每个细胞关联的样本条码。
3. 映射/伪映射至cDNA
为了确定读取源于哪个基因,可使用传统的(STAR)或轻量级方法(Kallisto/RapMap)对读取进行映射 (mapping)。
4. 合并UMI并完成对读取的定量
重复的UMI被合并,这样唯一的UMI可以使用Kallisto或featureCounts这样的工具定量。结果是一个细胞的基因计数矩阵:
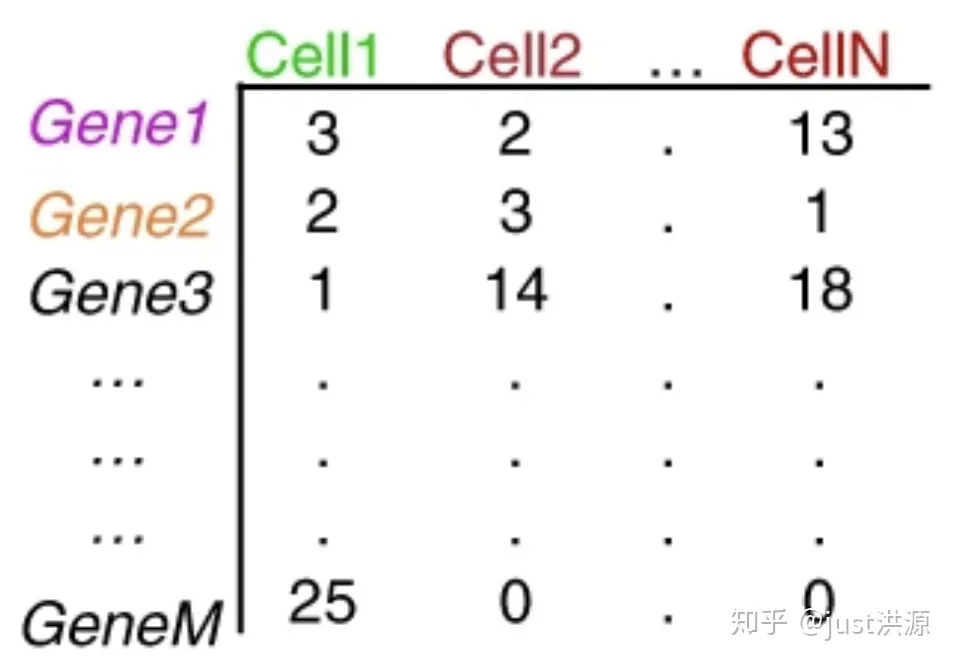
图片来源:extracted from Lafzi et al. Tutorial: guidelines for the experimental design of single-cell RNA sequencing studies, Nature Protocols 2018 (https://doi.org/10.1038/s41596-018-0073-y)
矩阵中的每个值表示一个细胞中相应基因的读取数。使用计数矩阵,我们可以探索和过滤数据,只保留较高质量的细胞。
相关文章:
单细胞seurat入门—— 从原始数据到表达矩阵
根据所使用的建库方法,单细胞的RNA序列(也称为读取(reads)或标签(tags))将从转录本的3端(或5端)(10X Genomics,CEL-seq2,Drop-seq&…...

Docker部署Nacos
此篇文章使用的nacos为2.2.1版本 拉取Nacos镜像 docker pull nacos/nacos-server:v2.2.1先将容器启动起来 docker run -d \ --name nacos \ -p 8848:8848 \ -p 9848:9848 \ -p 9849:9849 \ --privilegedtrue \ -e JVM_XMS256m \ -e JVM_XMX256m \ -e MODEstandalone \ -e NA…...

1005. K 次取反后最大化的数组和
原题链接:1005. K 次取反后最大化的数组和 思路: 先把数组排序好,然后直接从下标0(最小的负数)开始反转,那么接下来有两种情况: 1.负数反转完了,k还有剩余。此时因为nums内全部都是正数,所以我…...
【云原生】什么是 Kubernetes ?
什么是 Kubernetes ? Kubernetes 是一个开源容器编排平台,管理着一系列的 主机 或者 服务器,它们被称作是 节点(Node)。 每一个节点运行了若干个相互独立的 Pod。 Pod 是 Kubernetes 中可以部署的 最小执行单元&#x…...

自建CA实战之 《0x01 Nginx 配置 https单向认证》
自建私有化证书颁发机构(Certificate Authority,CA)实战之 《0x01 Nginx 配置 https单向认证》 上一篇文章我们介绍了如何自建私有化证书颁发机构(Certificate Authority,CA),本篇文章我们将介…...

《QT从基础到进阶·三十八》QWidget实现炫酷log日志打印界面
QWidget实现了log日志的打印功能,不仅可以在界面显示,还可以生成打印日志。先来看下效果,源码放在文章末尾: LogPlugin插件类管理log所有功能,它可以获取Log界面并能打印正常信息,警告信息和错误信息&…...
JVM的小知识总结
加载时jvm做了这三件事: 1)通过一个类的全限定名来获取该类的二进制字节流 什么是全限定类名? 就是类名全称,带包路径的用点隔开,例如: java.lang.String。 即全限定名 包名类型 非限定类名也叫短名,就…...
深入理解JVM虚拟机第二十六篇:详解JVM当中的虚方法和非虚方法,并从字节码指令的角度去分析虚方法和非虚方法
😉😉 学习交流群: ✅✅1:这是孙哥suns和树哥给大家的福利! ✨✨2:我们免费分享Netty、Dubbo、k8s、Spring...应用和源码级别的视频资料 🥭🥭3:QQ群:583783824 📚📚 微信:DashuDeveloper拉你进微信群,免费领取! 一:非虚方法和虚方法 方法…...

ElasticSearch的日志配置
ElasticSearch默认情况下使用Log4j2来记录日志,日志配置文件的路径为$ES_HOME/config/log4j2.properties,配置方法见Log4j2的官方文档。 参考path-settings,通过指定path.logs,可以指定日志文件的保存路径。 在日志配置文件$ES_…...

SQL Injection (Blind)`
SQL Injection (Blind) SQL Injection (Blind) SQL盲注,是一种特殊类型的SQL注入攻击,它的特点是无法直接从页面上看到注入语句的执行结果。在这种情况下,需要利用一些方法进行判断或者尝试,这个过程称之为盲注。 盲注的主要形式有…...

NX二次开发UF_CURVE_ask_trim 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CURVE_ask_trim Defined in: uf_curve.h int UF_CURVE_ask_trim(tag_t trim_feature, UF_CURVE_trim_p_t trim_info ) overview 概述 Retrieve the current parameters of an a…...
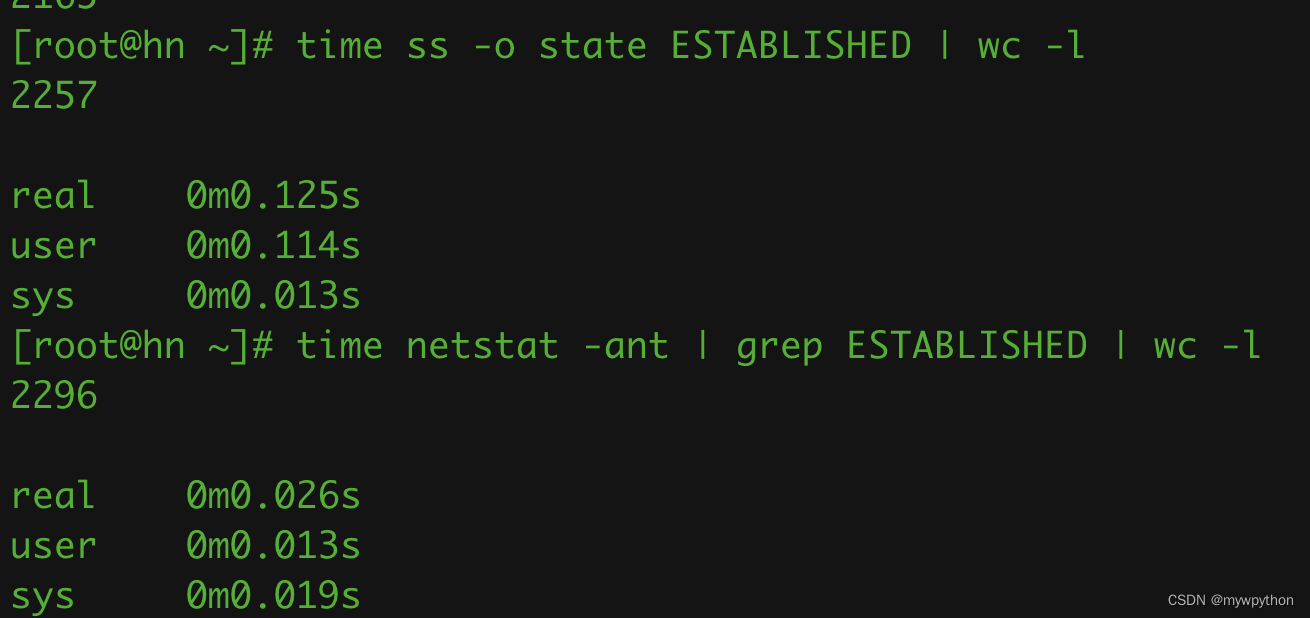
linux的netstat命令和ss命令
1. 网络状态 State状态LISTENING监听中,服务端需要打开一个socket进行监听,侦听来自远方TCP端口的连接请求ESTABLISHED已连接,代表一个打开的连接,双方可以进行或已经在数据交互了SYN_SENT客户端通过应用程序调用connect发送一个…...
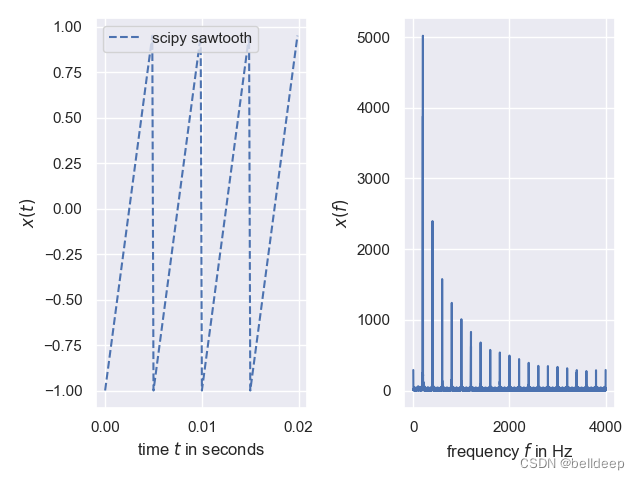
python:傅里叶分析,傅里叶变换 FFT
使用python进行傅里叶分析,傅里叶变换 FFT 的一些关键概念的引入: 1.1.离散傅里叶变换(DFT) 离散傅里叶变换(discrete Fourier transform) 傅里叶分析方法是信号分析的最基本方法,傅里叶变换是傅里叶分析的核心&…...

云原生系列Go语言篇-编写测试Part 2
基准测试 确定代码是快或慢非常复杂。我们不用自己计算,应使用Go测试框架内置的基准测试。下面来看第15章的GitHub代码库sample_code/bench目录下的函数: func FileLen(f string, bufsize int) (int, error) {file, err : os.Open(f)if err ! …...

CMake Error:No targets specified and no makefile found
在适用cmake构建项目的时候,突然遇到了这个报错 Make Error at CMakeLists.txt:1 (project): VERSION not allowed unless CMP0048 is set to NEW – Configuring incomplete, errors occurred! make: *** No targets specified and no makefile found. Stop. CMake…...

常见树种(贵州省):019滇白珠、杜茎山、苍山越桔、黄背越桔、贵州毛柃、半齿柃、钝叶柃、细枝柃、细齿叶柃木、土蜜树、山矾、胡颓子、檵木
摘要:本专栏树种介绍图片来源于PPBC中国植物图像库(下附网址),本文整理仅做交流学习使用,同时便于查找,如有侵权请联系删除。 图片网址:PPBC中国植物图像库——最大的植物分类图片库 一、滇白珠…...

java - 定时器
一、什么是定时器 定时器是指可以通过 Java 中的 Timer 类和 TimerTask 类所提供的功能来实现定期执行某些任务的工具。 标准库中提供了一个 Timer 类 . Timer 类的核心方法为 schedule . schedule 包含两个参数 . 第一个参数指定即将要执行的任务代码 , 第二个参数指定多…...

jQuery【菜单功能、淡入淡出轮播图(上)、淡入淡出轮播图(下)、折叠面板】(五)-全面详解(学习总结---从入门到深化)
目录 菜单功能 淡入淡出轮播图(上) 淡入淡出轮播图(下) 折叠面板 菜单功能 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><…...

攻防非对称问题| 当前企业面临的网络攻防非对称问题及其解决途径
随着信息技术的不断发展,网络已经成为我们日常生活和商业活动中不可或缺的一部分。然而,随之而来的是网络安全问题的不断升级。网络攻防非对称问题是当前亟待解决的一个复杂而严峻的挑战。其主要的表现是攻击成本远低于防御成本以及相同投入带来的攻击能…...

Java多线程二-线程安全
1、线程安全问题 多个线程,同时操作同一个共享资源的时候,可能会出现业务安全问题。 2、实例:取钱的线程安全问题 2.1、场景 小明和小红是夫妻,他们有个共同账户,余额是十万元,如果两人同时取钱并且各自取…...

ORA-31215: DBMS_LDAP PL/SQL无效LDAP修改值,Oracle报错故障修复与远程处理方案,快速解决连接配置难题
针对ORA-31215错误,核心在于DBMS_LDAP包在执行PL/SQL程序时,尝试向LDAP目录服务提交了一个不符合规范(如类型不匹配、格式错误、或为NULL)的属性值修改请求,导致操作失败;解决方法主要围绕检查并修正代码中…...
)
Fish-Speech 1.5 多语言语音合成实战:如何用 API 快速生成中日语语音(附完整代码示例)
Fish-Speech 1.5 多语言语音合成实战:从API调用到音色定制的完整指南 在数字内容创作和智能交互领域,多语言语音合成技术正成为打破沟通壁垒的关键工具。Fish-Speech 1.5作为新一代开源语音合成引擎,以其出色的多语言支持能力和灵活的API接口…...
在系统架构设计中的应用)
从点外卖到银行转账:用生活案例理解数据流图(DFD)在系统架构设计中的应用
从点外卖到银行转账:用生活案例理解数据流图在系统设计中的应用 中午12点,你打开外卖APP选了一份黄焖鸡米饭,点击支付后,商家接单、骑手取餐、最终送达——这个看似简单的流程背后,隐藏着一个精密的数据流动网络。就像…...

终极Saasfly第三方服务集成指南:如何快速添加支付网关和认证提供商
终极Saasfly第三方服务集成指南:如何快速添加支付网关和认证提供商 【免费下载链接】saasfly Your Next SaaS Template or Boilerplate ! A magic trip start with bun create saasfly . The more stars, the more surprises 项目地址: https://gitcode.com/GitHu…...

Qwen3-Embedding-4B入门指南:向量归一化对余弦相似度计算的影响实验对比
Qwen3-Embedding-4B入门指南:向量归一化对余弦相似度计算的影响实验对比 1. 引言:从关键词匹配到语义理解 你有没有遇到过这样的烦恼?在文档里搜索“苹果”,结果既找到了水果,也找到了手机,甚至还有一堆无…...

黑苹果触摸板手势终极方案:从卡顿到流畅的完整配置指南
黑苹果触摸板手势终极方案:从卡顿到流畅的完整配置指南 【免费下载链接】Hackintosh Hackintosh long-term maintenance model EFI and installation tutorial 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintosh 还在为黑苹果触摸板的生硬操作而烦恼吗…...
彻底搞懂PowerBI表操作)
别再死记硬背DAX函数了!用这3个真实业务场景(销售分析/客户分层/动态排名)彻底搞懂PowerBI表操作
用真实业务场景解锁PowerBI表操作函数的实战价值 在数据分析领域,掌握DAX函数就像获得了一把瑞士军刀,但真正的高手不在于记住每个工具的名称,而在于知道何时使用以及如何组合它们解决实际问题。本文将带你跳出函数手册的死记硬背模式&#x…...

论文AI率标准2026年大变化:各高校各平台最新红线全整理
2026年各高校和检测平台的AI率红线确实有了新的变化,整体趋势是要求越来越严。把目前能收集到的信息整理在一起,供参考。 注意:各高校政策更新比较快,以下信息以2026年初的公开要求为准,具体以所在学校最新通知为准。…...
:音视频播放、录制)
鸿蒙 Media Kit(媒体服务):音视频播放、录制
本文同步发表于微信公众号,微信搜索 程语新视界 即可关注,每个工作日都有文章更新 Media Kit(媒体服务)是鸿蒙系统中用于开发音视频播放或录制功能的核心模块。无论是开发音乐播放器、视频播放器,还是实现音视频录制、…...

Qwen3-14B-Int4-AWQ效果深度评测:代码生成、推理与数学能力横向对比
Qwen3-14B-Int4-AWQ效果深度评测:代码生成、推理与数学能力横向对比 1. 评测背景与模型特点 Qwen3-14B-Int4-AWQ作为通义千问系列的最新量化版本,在保持原版14B参数规模的同时,通过AWQ(Activation-aware Weight Quantization&am…...