处理数据中的缺失值--删除缺少值的行
两个最主要的处理缺失值的方法是:
❏ 删除缺少值的行;
❏ 填充缺失值;
我们首先将serum_insulin的中的字段值0替换为None,可以看到缺失值的数量为374个;
print(pima['serum_insulin'].isnull().sum())
pima['serum_insulin'] = pima['serum_insulin'].map(lambda x:x if x != 0 else None)
print(pima['serum_insulin'].isnull().sum())
# 0
# 374
替换所有的缺失字段,可以看到不同字段缺失值的情况是不一样的;
columns = ['serum_insulin', 'bmi', 'plasma_glucose_concentration','diastolic_blood_pressure', 'triceps_thickness']
for c in columns:pima[c].replace([0], [None], inplace=True)print(pima.isnull().sum())
# times_pregnant 0
# plasma_glucose_concentration 5
# diastolic_blood_pressure 35
# triceps_thickness 227
# serum_insulin 374
# bmi 11
# pedigree_function 0
# age 0
# onset_diabetes 0
# dtype: int64
可以看到此时describe不会针对有缺失值的列进行计算
print(pima.describe())
# times_pregnant pedigree_function age onset_diabetes
# count 768.000000 768.000000 768.000000 768.000000
# mean 3.845052 0.471876 33.240885 0.348958
# std 3.369578 0.331329 11.760232 0.476951
# min 0.000000 0.078000 21.000000 0.000000
# 25% 1.000000 0.243750 24.000000 0.000000
# 50% 3.000000 0.372500 29.000000 0.000000
# 75% 6.000000 0.626250 41.000000 1.000000
# max 17.000000 2.420000 81.000000 1.000000
我们可以自己手动计算均值
# print(pima['plasma_glucose_concentration'].mean(), pima['plasma_glucose_concentration'].std())# 121.6867627785059 30.53564107280403
处理缺失数据最简单的方式就是丢弃数据行,我们使用dropna方法进行处理,可以看到将近丢弃一半的数据;从机器学习的角度考虑,尽管数据都有值、很干净,但是我们没有利用尽可能多的数据,忽略了一半以上的观察值。
pima_dropped = pima.dropna()
rows = pima.shape[0]
rows_dropped = pima_dropped.shape[0]
num_rows_lost = round(100*(rows-rows_dropped)/rows)
print('lost {}% rows'.format(num_rows_lost))
# lost 49% rows
通过以下我们可以看到糖尿病的患病概率影响并不是很大;
print(pima['onset_diabetes'].value_counts(normalize=True))
print(pima_dropped['onset_diabetes'].value_counts(normalize=True))
# onset_diabetes
# 0 0.651042
# 1 0.348958
# Name: proportion, dtype: float64
# onset_diabetes
# 0 0.668367
# 1 0.331633
# Name: proportion, dtype: float64
通过以下可以看到各个字段的均值处理前后的大小
pima_mean = pima.mean()
pima_dropped_mean = pima_dropped.mean()
print(pima_mean)
print(pima_dropped_mean)
# times_pregnant 3.845052
# plasma_glucose_concentration 121.686763
# diastolic_blood_pressure 72.405184
# triceps_thickness 29.15342
# serum_insulin 155.548223
# bmi 32.457464
# pedigree_function 0.471876
# age 33.240885
# onset_diabetes 0.348958
# dtype: object# times_pregnant 3.30102
# plasma_glucose_concentration 122.627551
# diastolic_blood_pressure 70.663265
# triceps_thickness 29.145408
# serum_insulin 156.056122
# bmi 33.086224
# pedigree_function 0.523046
# age 30.864796
# onset_diabetes 0.331633
# dtype: object
可以看到进行数据处理之后,每个字段的变化率
mean_percent = (pima_dropped_mean - pima_mean) / pima_mean
print(mean_percent)
# times_pregnant -0.141489
# plasma_glucose_concentration 0.007731
# diastolic_blood_pressure -0.024058
# triceps_thickness -0.000275
# serum_insulin 0.003265
# bmi 0.019372
# pedigree_function 0.108439
# age -0.071481
# onset_diabetes -0.04965
# dtype: object
通过饼图查看各个字段的百分比变化;
ax = mean_percent.plot(kind='bar', title='% change in average column values')
ax.set_ylabel('% change')
plt.show()
可以看到,times_pregnant(怀孕次数)的均值在删除缺失值后下降了14%,变化很大!pedigree_function(糖尿病血系功能)也上升了11%,也是个飞跃。可以看到,删除行(观察值)会严重影响数据的形状,所以应该保留尽可能多的数据。
使用处理过的数据训练scikit-learn的K最近邻(KNN,k-nearest neighbor)分类模型,可以看到最好的邻居数是7个,此时KNN模型的准确率是74.5%;
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVX_dropped = pima_dropped.drop('onset_diabetes', axis= 1)
print('learning from {} rows'.format(X_dropped.shape[0]))
y_dropped = pima_dropped['onset_diabetes']knn_para = {'n_neighbors':[1,2,3,4,5,6,7]}
knn = KNeighborsClassifier()
grid = GridSearchCV(knn, knn_para)
grid.fit(X_dropped, y_dropped)
print(grid.best_score_, grid.best_params_)# learning from 392 rows
# 0.7348263550795197 {'n_neighbors': 7}
相关文章:

处理数据中的缺失值--删除缺少值的行
两个最主要的处理缺失值的方法是: ❏ 删除缺少值的行; ❏ 填充缺失值; 我们首先将serum_insulin的中的字段值0替换为None,可以看到缺失值的数量为374个; print(pima[serum_insulin].isnull().sum()) pima[serum_insu…...
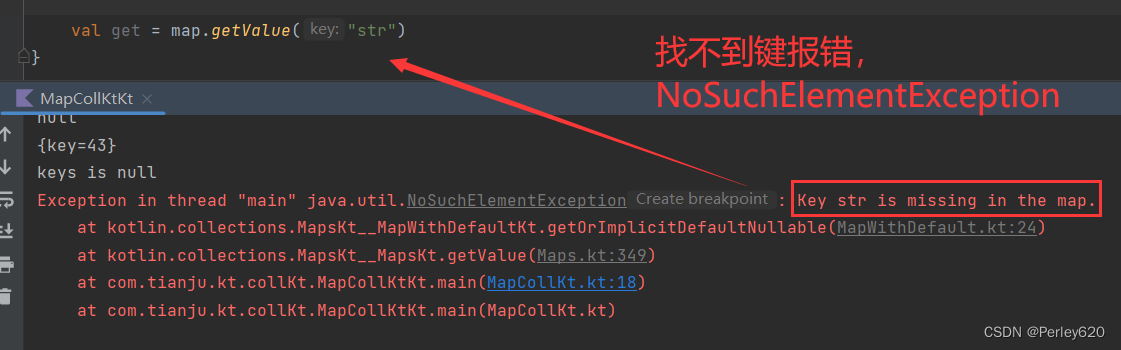
Kotlin学习——kt里的集合,Map的各种方法之String篇
Kotlin 是一门现代但已成熟的编程语言,旨在让开发人员更幸福快乐。 它简洁、安全、可与 Java 及其他语言互操作,并提供了多种方式在多个平台间复用代码,以实现高效编程。 https://play.kotlinlang.org/byExample/01_introduction/02_Functio…...

MIT 6.824 -- MapReduce Lab
MIT 6.824 -- MapReduce Lab 环境准备实验背景实验要求测试说明流程说明 实验实现GoLand 配置代码实现对象介绍协调器启动工作线程启动Map阶段分配任务执行任务 Reduce 阶段分配任务执行任务 终止阶段 崩溃恢复 注意事项并发安全文件转换golang 知识点 测试 环境准备 从官方gi…...

创新研报|顺应全球数字化,能源企业以“双碳”为目标的转型迫在眉睫
能源行业现状及痛点分析 挑战一:数字感知能力较弱 挑战二:与业务的融合度低 挑战三:决策响应速度滞后 挑战四:价值创造有待提升 挑战五:安全风险如影随形 能源数字化转型定义及架构 能源行业数字化转型体系大体…...
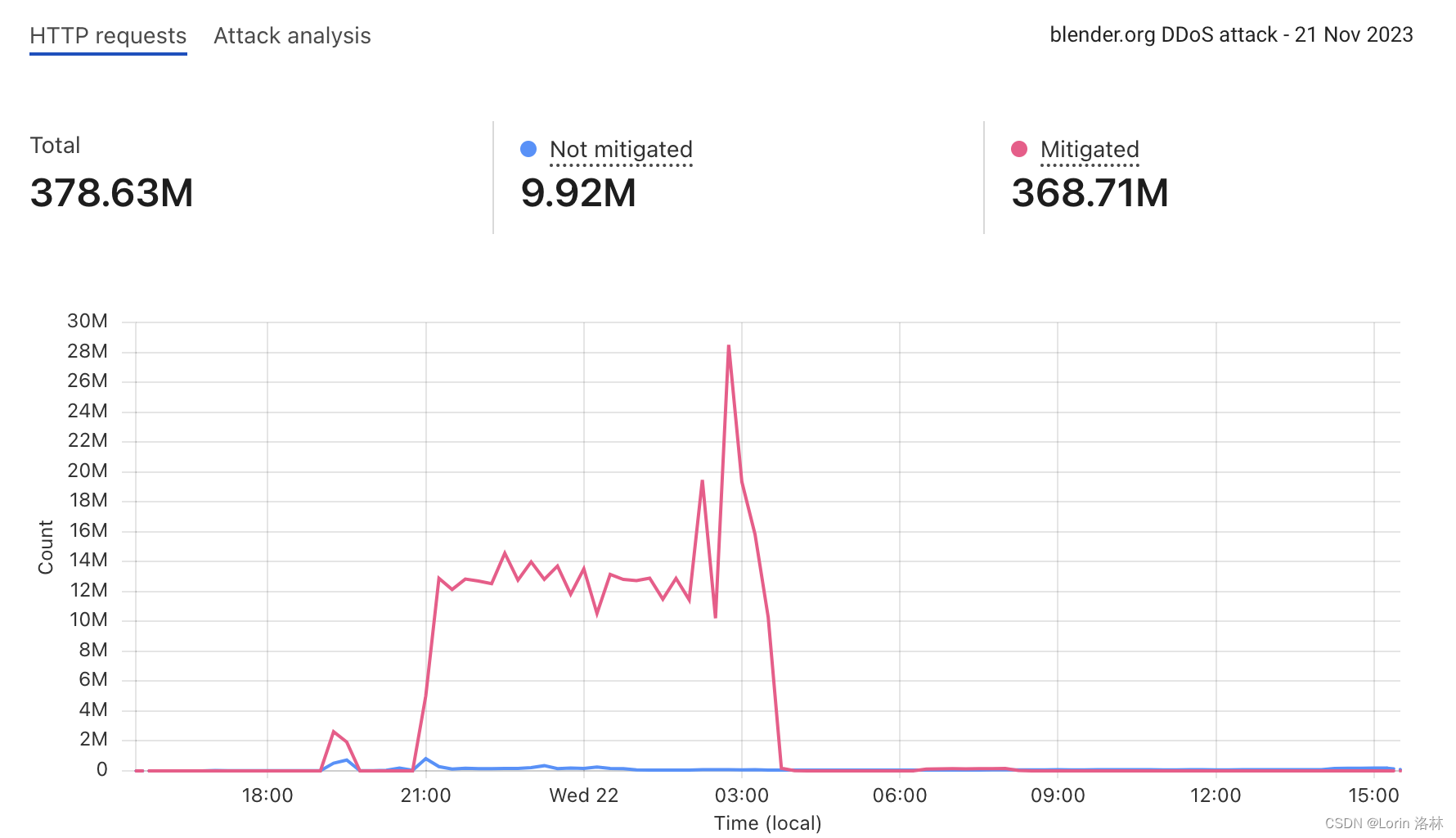
Blender 连续 5 天遭受大规模 DDoS 攻击
Blender 发布公告指出,在2023年11月18日至23日期间,blender.org 网站遭受了持续的分布式拒绝服务(DDoS)攻击,攻击者通过不断发送请求导致服务器超载,使网站运营严重中断。此次攻击涉及数百个 IP 地址的僵尸…...

Python 获取本地和广域网 IP
Python 获取本地IP ,使用第三方库,比如 netifaces import netifaces as nidef get_ip_address():try:# 获取默认网络接口(通常是 eth0 或 en0)default_interface ni.gateways()[default][ni.AF_INET][1]# 获取指定网络接口的IP地…...
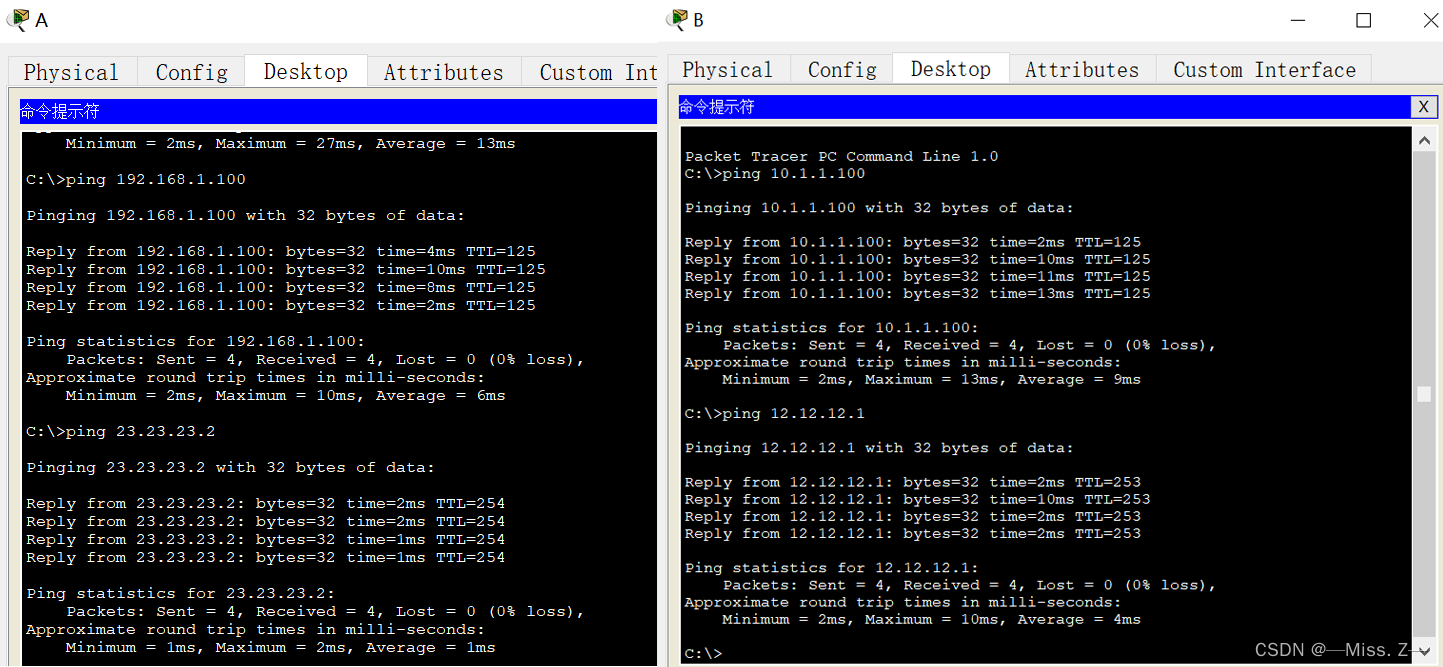
静态路由配置过程
静态路由 静态路由简介 路由器在转发数据时,要先在路由表(Routing Table)中在找相应的路由,才能知道数据包应该从哪个端口转发出去。路由器建立路由表基本上有以下三种途径。 (1)直连路由:路由…...
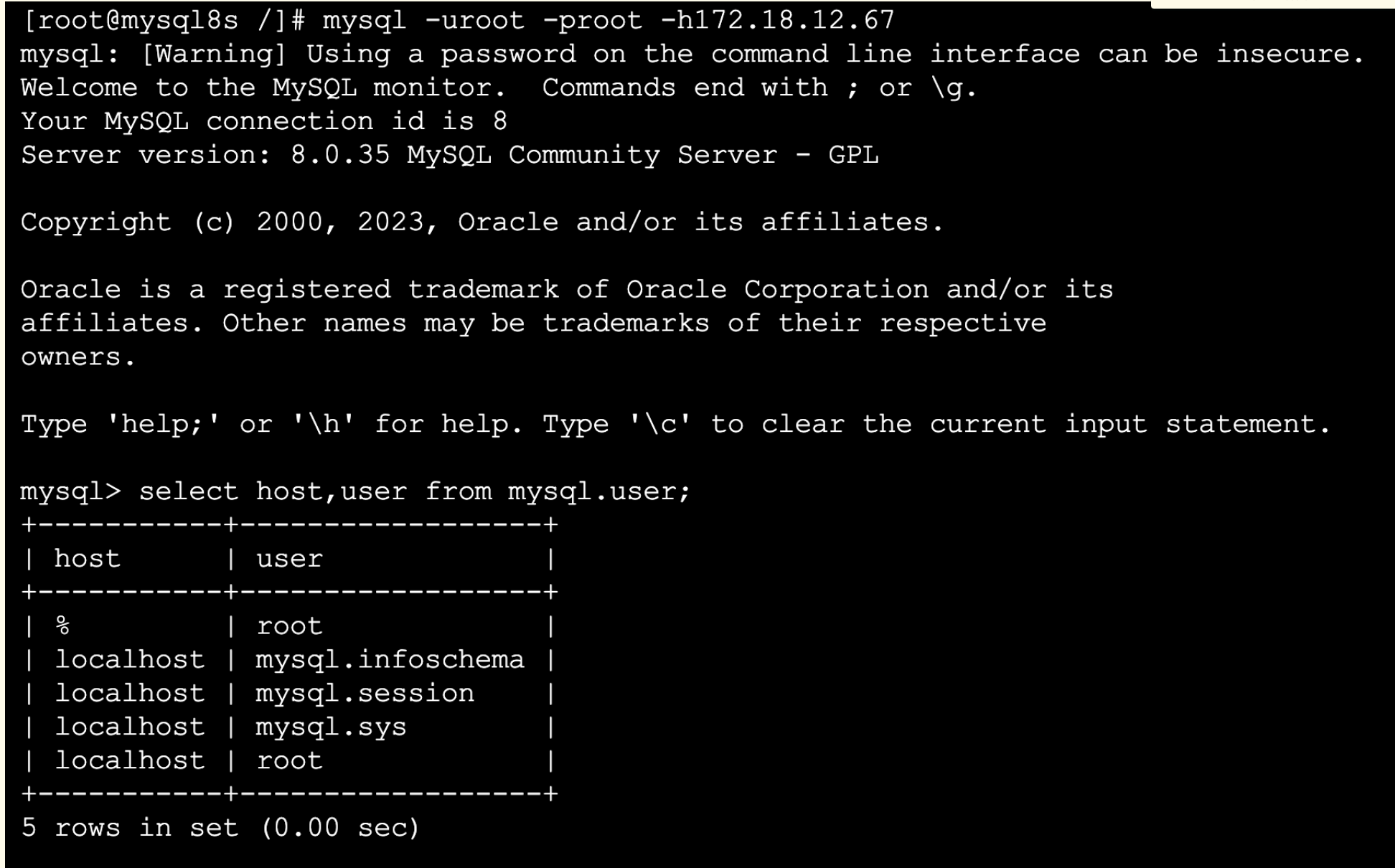
基于OGG实现MySQL实时同步
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

【计算机网络笔记】多路访问控制(MAC)协议——轮转访问MAC协议
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

什么是好的FPGA编码风格?(3)--尽量不要使用锁存器Latch
前言 在FPGA设计中,几乎没人会主动使用锁存器Latch,但有时候不知不觉中你的设计莫名其妙地就生成了一堆Latch,而这些Latch可能会给你带来巨大的麻烦。 什么是锁存器Latch? Latch,锁存器,一种可以存储电路…...

从0开始学习JavaScript--构建强大的JavaScript图片库
在现代Web开发中,图像是不可或缺的一部分,而构建一个强大的JavaScript图片库能够有效地管理、展示和操作图像,为用户提供更丰富的视觉体验。本文将深入探讨构建JavaScript图片库的实用技巧,并通过丰富的示例代码演示如何实现各种功…...

linux复习笔记05(小滴课堂)
hell脚本与crontab定时器的运用 查看状态: 关闭服务: 开启服务: 重启服务: crontab定时器的使用: 我们可以看到没有任何任务。 编辑: 我们可以看到这个任务了。 删除所有任务: 这代表着每分钟…...
springboot函数式web
1.通常是路由(请求路径)业务 2.函数式web:路由和业务分离 一个configure类 配置bean 路由等 实现业务逻辑 这样实现了业务和路由的分离...
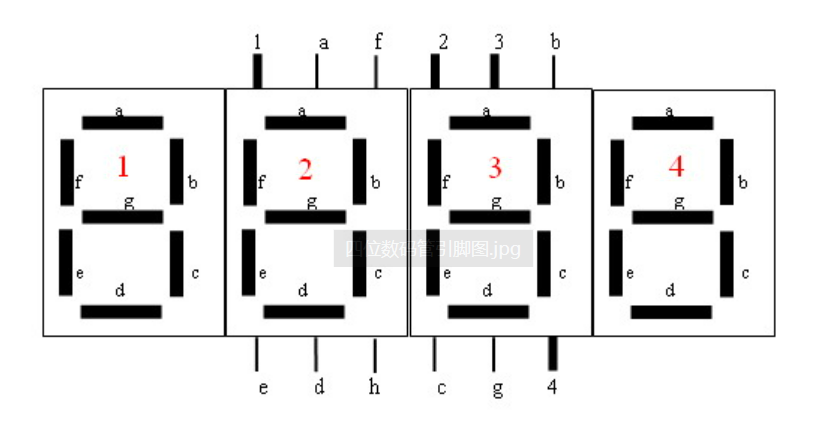
常见的1/2/3位数码管接线详解
今天玩数码管的时候接触到了数码管的接线,分享一下供刚开始接触的童鞋参考 首先了解什么是数码管 数码管是一种可以显示数字和其他信息的电子设备,是显示屏其中一类, 通过对其不同的管脚输入相对的电流,会使其发亮,从而…...

C++模板介绍
定义 C模板是一种编程技术,它允许程序员在编译时生成具有特定类型的函数或类,而无需在运行时进行类型检查。模板是一种泛型编程的方式,它使得程序员可以编写可适用于多种数据类型的代码,提高了代码的重用性和灵活性。 C模板可以…...

kafka kraft 集群搭建保姆级教学 包含几个踩坑点
一.为啥弃用zookeeper kafka 弃用 ZooKeeper 而采用 KRaft 的主要原因是为了改进 Kafka 集群的可靠性和可管理性。 在传统的 Kafka 架构中,ZooKeeper 用于存储和管理集群的元数据、配置信息和状态。然而,使用 ZooKeeper 作为协调服务存在一些限制和挑战…...

html实现360度产品预览(附源码)
文章目录 1.设计来源1.1 拖动汽车产品旋转1.2 汽车产品自动控制 2.效果和源码2.1 动态效果2.2 源代码 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/134613931 html实现360度产品预览(附源码&…...

11-23 SSM4
Ajax 同步请求 :全局刷新的方式 -> synchronous请求 客户端发一个请求,服务器响应之后你客户端才能继续后续操作,请求二响应完之后才能发送后续的请求,依次类推 有点:服务器负载较小,但是由于服务器相应…...
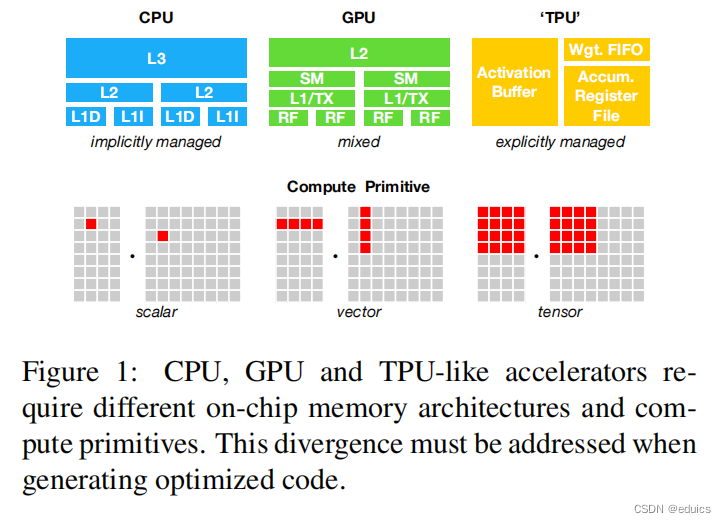
CPU、GPU、TPU内存子系统架构
文章目录 CPU、GPU、TPU内存子系统架构概要CPUGPUTPU共同点和差异: CPU、GPU、TPU内存子系统架构 概要 Memory Subsystem Architecture,图源自TVM CPU CPU(中央处理器)的内存子系统:隐式管理 主内存(…...

R数据分析:集成学习方法之随机生存森林的原理和做法,实例解析
很久很久以前给大家写过决策树,非常简单明了的算法。今天给大家写随机(生存)森林,随机森林是集成了很多个决策数的集成模型。像随机森林这样将很多个基本学习器集合起来形成一个更加强大的学习器的这么一种集成思想还是非常好的。…...

Claude Code 常用命令大全
Claude Code 的命令体系主要分为三类:在终端中执行的 CLI 命令、在交互界面内使用的 斜杠命令 和用于快速操作的 键盘快捷键。⌨️ CLI 命令这类命令在启动 Claude Code 的终端中直接执行,用于启动、配置和管理会话。claude:在当前目录启动一…...

化工园区智能一体化巡检平台
平台以数字孪生、AI智能研判、多模态感知为核心技术底座,整合全域数据,实现"一张屏管园区"的高效管控。数据可视化大屏:实时呈现园区设备状态、巡检轨迹、隐患告警等核心信息,支持3D园区模型缩放、旋转,精准…...

FreeRTOS任务优先级设置不当导致系统卡死的排查与修复
1. FreeRTOS任务优先级设置不当的典型表现 在STM32F1系列单片机开发中,使用FreeRTOS时如果任务优先级设置不当,系统往往会表现出一些典型症状。最常见的就是系统运行一段时间后突然卡死,所有任务停止响应,连最基本的LED闪烁或串口…...
)
别再只盯着配体-受体了!用MEBOCOST从你的scRNA-seq数据里挖出隐藏的代谢通讯网络(附完整Python代码)
解锁单细胞代谢通讯:MEBOCOST实战指南与创新洞见 单细胞RNA测序技术已经彻底改变了我们对细胞异质性和组织微环境的理解方式。然而,当我们沉浸在配体-受体相互作用的分析中时,一个更为丰富的代谢通讯世界正等待着被探索。代谢物作为细胞间信号…...

如何免费使用QQ截图独立版?3分钟快速上手终极指南
如何免费使用QQ截图独立版?3分钟快速上手终极指南 【免费下载链接】QQScreenShot 电脑QQ截图工具提取版,支持文字提取、图片识别、截长图、qq录屏。默认截图文件名为ScreenShot日期 项目地址: https://gitcode.com/gh_mirrors/qq/QQScreenShot 还在为截图工具…...

模拟IC设计进阶指南:MOS开关电路的非理想特性与优化策略
1. MOS开关电路的非理想特性揭秘 第一次用MOS管做开关电路时,我天真地以为它就是个完美的电子开关——导通时零电阻,关断时完全绝缘。直到在采样保持电路里看到信号波形出现诡异的台阶,才意识到教科书里的理想模型都是"卖家秀"。实…...

Dify 1.11.0升级后,我的企业知识库终于能看懂PPT截图了:多模态RAG实战踩坑记录
Dify 1.11.0升级实战:构建企业级多模态知识库的完整指南 当企业知识库开始"看懂"PPT截图和PDF图表时,RAG技术才真正触及生产力变革的核心。Dify 1.11.0的多模态升级,让我们终于能将堆积如山的培训PPT、产品手册和系统截图转化为可检…...

“听劝!”预算1k内吉他别瞎买:雅马哈/布洛克/费森横评,这款单板琴让我惊掉下巴!
准备买第一把吉他了,是不是既兴奋又有点慌?面对琳琅满目的品牌和从几百到几千的价格,心里直打鼓: 太便宜的是不是“烧火棍”?太贵了又怕自己坚持不下去浪费钱。 更怕的是,花了钱买回家,发现声音…...

s2-pro语音合成5分钟快速上手:零基础小白也能玩转AI配音
s2-pro语音合成5分钟快速上手:零基础小白也能玩转AI配音 1. s2-pro语音合成简介 s2-pro是Fish Audio开源的专业级语音合成模型镜像,它能让你的文字变成自然流畅的语音。想象一下,你只需要输入一段文字,就能得到一个真人般的声音…...

Ollama部署LFM2.5-1.2B-Thinking:轻量级但强思考的开发者首选模型
Ollama部署LFM2.5-1.2B-Thinking:轻量级但强思考的开发者首选模型 1. 为什么选择LFM2.5-1.2B-Thinking模型 如果你正在寻找一个既轻量又聪明的AI助手来帮你写代码、解决问题或者进行创意写作,LFM2.5-1.2B-Thinking模型绝对值得你关注。这个模型虽然只有…...