网络爬虫(Python:Requests、Beautiful Soup笔记)
网络爬虫(Python:Requests、Beautiful Soup笔记)
- 网络协议简要介绍
- 一。OSI参考模型
- 二、TCP/IP参考模型
- 对应关系
- TCP/IP各层实现的协议
- 应用层
- 传输层
- 网络层
- HTTP协议
- HTTP请求
- HTTP响应
- HTTP状态码
- Requests(Python)
- Requests模块支持的http方法
- GET
- HEAD
- POST
- PUT
- DELETE
- TRACE
- OPTIONS
- CONNECT
- 异常
- Requests库请求时需要注意的事项
- Python正则表达式(re模块)
- Beautiful Soup(bs4)
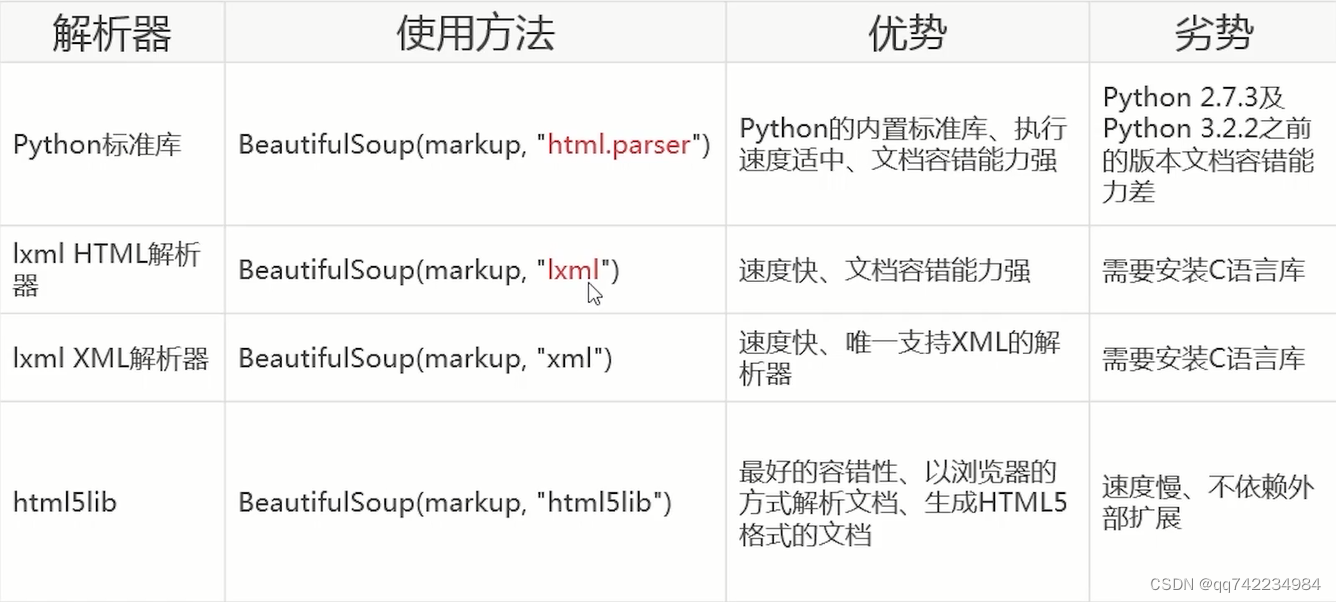
- Beautiful Soup支持的解析器
- 选择子节点、父节点和兄弟节点
- 方法选择器
- find_all方法
- find方法
- CSS选择器
- lxml(Python)
网络协议简要介绍
一。OSI参考模型

| 七层 | 功能 | |
|---|---|---|
| 应用层 | 7 | 提供应用程序间通信 |
| 表示层 | 6 | 处理数据格式、数据加密等 |
| 会话层 | 5 | 建立、维护和管理会话 |
| 传输层 | 4 | 建立主机端到端连接 |
| 网络层 | 3 | 寻址和路由选择 |
| 数据链路层 | 2 | 提供介质访问、链路管理等 |
| 物理层 | 1 | 比特流传输 |
二、TCP/IP参考模型
| TCP/IP协议栈 | |
|---|---|
| 应用层 | 提供应该程序网络接口 |
| 传输层 | 建立端到端连接 |
| 网络层 | 寻址和路由选择 |
| 数据链路层 | 物理介质访问 |
| 物理层 | 二进制数据流传输 |
对应关系
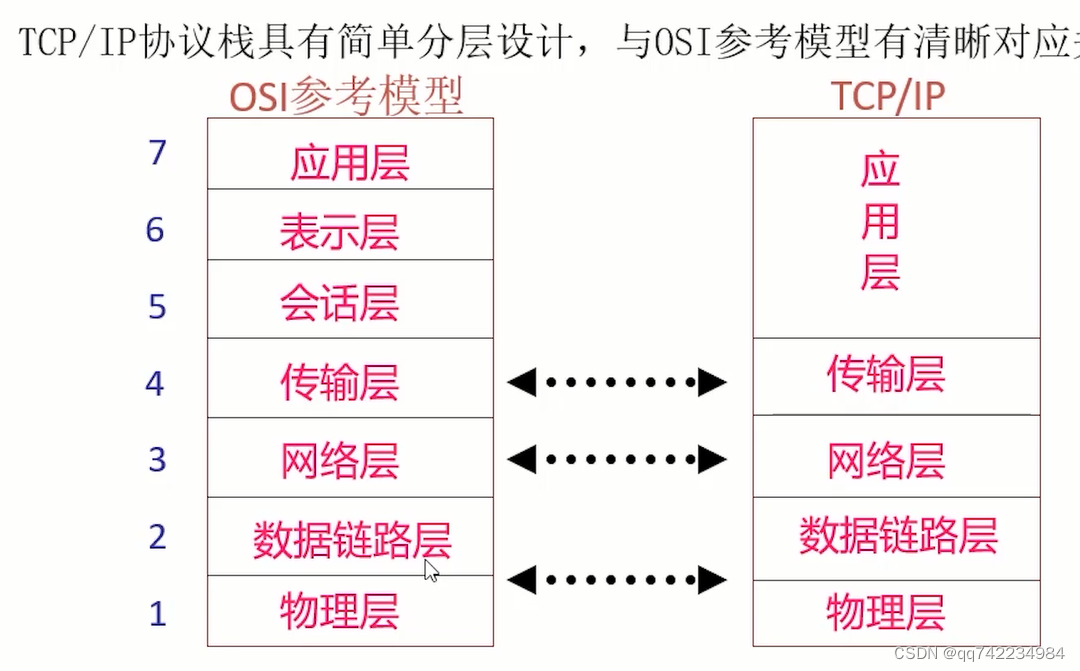
TCP/IP各层实现的协议
应用层
- HTTP:超文本传输协议,基于TCP,使用80号端口,是用于从www服务器传输超文本到本地浏览器的传输协议。
- SMTP:简单邮件传输协议,基于TCP,使用25号端口,是一组用于由源地址到目的地址传送邮件的规则,用来控制信件的发送、中转。
- FTP:文件传输协议,基于TCP,一般上传下载用FTP服务,数据端口是20号,控制端口是21号。
- TELNET:远程登录协议,基于TCP,使用23号端口,是Internet远程登陆服务的标准协议和主要方式。为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序连接到服务器。使用明码传送,保密性差、简单方便。
- SSH:安全外壳协议,基于TCP,使用22号端口,为建立在应用层和传输层基础上的安全协议。SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
传输层
- TCP:传输控制协议。一种面向连接的、可靠的、基于字节流的传输层通信协议。
- UDP:用户数据报协议。一种面向无连接的通讯协议,不可靠的、基于报文的传输层通信协议。
- SCTP:流量传输控制协议。一种面向连接的流传输协议。
- MPTCP:多路径传输控制协议。TCP的多路径版本。SCTP虽然在首发两端有多条路径,但实际只是使用一条路径传输,当该条路径出现故障时,不需要断开连接,而是转移到其他路径。MPTCP真正意义上实现了多路径并行传输,在连接建立阶段,建立多条路径,然后使用多条路径同时传输数据。
网络层
- lP:Internet 协议。通过路由选择将下一条IP封装后交给接口层。IP数据报是无连接服务。
- ICMP:Internet 控制报文协议。是网络层的补充。用于在P主机、路由器之间传递控制消息,检测网络通不通、主机是否可达、路由是否可用等网络本身的消息。
- ARP:地址解析协议。通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。
- RARP:反向地址解析协议。
HTTP协议
HTTP (HyperText Transfer Protocol,超文本传输协议)是互联网上应用最为广泛的一种网络协议,它是基于TCP的应用层协议
客户端和服务端进行通信的一种规则,它的模式非常简单,就是客户端发起请求,服务端响应请求
HTTP请求
- 请求行:包含请求方法、请求地址和HTTP协议版本
- 消息报头:包含一系列的键值对
- 请求正文(可选)︰注意和消息报头之间有一个空行
谷歌浏览器开发者工具 preserve log
在我们开发页面时,点击按钮触发了某个接口并跳转了页面,这时Network中的信息会刷新,不做保留,这个时候我们只需要勾选上谷歌开发者工具的preserve log,就可以保留上一个页面接口调用信息,从而方便我们查看。
GET 从服务器获取指定(请求地址)的资源的信息,它通常只用于读取数据,就像数据库查询一样,不会对资源进行修改。
POST 向指定资源提交数据(比如提交表单,上传文件),请求服务器进行处理。数据被包含在请求正文中,这个请求可能会创建新的资源或更新现有的资源。
PUT 通过指定资源的唯一标识(在服务器上的具体存放位置),请求服务器创建或更新资源。
DELETE 请求服务器删除指定资源。
HEAD 与GET方法类似,从服务器获取资源信息,和GET方法不同的是,HEAD不含有呈现数据,仅仅是HTTP头信息。HEAD 的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获得资源的元信息(或元数据)。
OPTIONS 该方法可使服务器传回资源所支持的所有HTTP请求方法。
HTTP响应
- 状态行:包含HTTP协议版本、状态码和状态描述,以空格分隔
- 响应头:即消息报头,包含一系列的键值对
- 响应正文:返回内容,注意和响应头之间有一个空行
HTTP状态码
1XX 消息–请求已被服务接收,继续处理
2XX 成功–请求已成功被服务器接收、理解、并接受
- 200 OK
- 202 Accepted接收
- 202 Accepted接收
- 203 Non-Authoritative lnformation非认证信息
- 204 No Content无内容
3XX 重定向–需要后续操作才能完成这一请求
- 301 Moved Permanently请求永久重定向
- 302 Moved Temporarily请求临时重定向
- 304 Not Modified文件未修改,可以直接使用缓存的文件
- 305 Use Proxy 使用代理
4XX 请求错误–请求含有词法错误或者无法被执行
- 400 Bad Request由于客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized请求未经授权。这个状态代码必须和WWW-Authenticate报头域一起使用
- 403 Forbidden服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因
- 404 Not Found请求的资源不存在,例如,输入了错误的URL
5XX 服务器错误–服务器在处理某个正确请求时发生错误
- 500 Internal Server Error服务器发生不可预期的错误,导致无法完成客户端的请求
- 503 Service Unavailable服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常
- 504 Gateway Time-out 网关超时
简述HTTP和HTTPS协议区别?
- HTTP协议是使用明文数据传输的网络协议。端口80
- HTTPS协议。HTTP协议的安全升级版,在HTTP的基础上增加了数据加密。端口443
列举请求头中常见的字段?
- User-Agent:客户端请求标识
- Accept:传输文件类型
- Referer:请求来源
- cookie:登录凭据
Requests(Python)
Requests模块支持的http方法
GET
当客户端向Web服务器请求一个资源的时候使用;它被用来访问静态资源,比如HTML文档和图片等
本机ip地址查询:http://httpbin.org/ip
通过requests.get(url, headers=None, params=None)方法可以发送GET请求,其中url为请求地址,headers为请求头部,params为请求参数。
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
response = requests.get('http://www.example.com', headers=headers)
print(response.text)
# content参数返回HTTP响应的二进制数据源,形式为bytes。
# status_code参数返回HTTP响应的状态码,形式为整数。
- 可以设置verify参数为False来跳过SSL证书验证。
- 可以设置timeout参数来设置请求超时时间,避免长时间等待无响应。
- 可以使用proxies参数来设置代理服务器。
import requests
#构造的URL的数据,一定要和Post请求做好区分
data = {'key1':'value1','key2':'value2'}
#使用的是GET请求的方法,params关键字一定要做好区分
response = requests.get('http://httpbin.org/get',params=data)
#查看了是哪个URL给我们返回的数据
print(response.url)
#查看返回头,注意,是headers不是header
print(response.headers)
#查看返回体
print(response.text)
cookies
import requests
url = 'https://www.baidu.com'
#定制请求头,使用了一个标准的浏览器的UA
header = {'user-agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36'}
response = requests.get(url=url,headers=header)
print(response.headers)
#cookie是一个对象RequestsCookieJar,行为和字典类似
print(response.cookies)
print(response.cookies['BIDUPSID'])
IP池和隧道代理的区别
- 动态IP池中获取的是大量的IP,需要爬虫自己切换代理IP,并发送请求。
- 只需要将请求发给隧道,由隧道自行选择可用代理并转发请求。
proxy = {# http://用户名:密码@代理的接口信息"http": "http://uesrname:password@代理地址:端口","https": "http://uesrname:password@代理地址:端口"
}
cookie和session的区别?
- cookie和session都是用来跟踪浏览器用户身份的会话方式
- cookie数据保存在客户端,session数据保存在服务器端。
- Cookie过期看生成时设置的值,session过期看服务器设定。
HEAD
当客户端向Web服务器请求一个资源的一些信息而不是资源的全部信息的时候使用;主要用于确认URL的有效性以及资源更新的日期时间等
POST
当客户端向服务端发送信息或者数据的时候使用;表单提交(向Web服务器发送大量的复杂的数据)
requests.post(url, data=None, json=None, headers=None, timeout=None)
- data:发送的数据,字典或者元组列表形式
- json:发送JSON格式的数据
- headers:请求头信息
- timeout:请求的最长等待时间
PUT
当客户端向Web服务端指定URL发送一个替换的文档或者上传一个新文档的时侯使用
DELETE
当客户端尝试从Web服务端删除一个由请求URL唯一标识的文档的时候使用
TRACE
当客户端要求可用的代理服务器或者中间服务更改请求来宣布自己的时候使用
OPTIONS
当客户端想要决定其他可用的方法来检索或者处理Web服务端的一个文档时使用
CONNECT
当客户端想要确定一个明确的连接到远程主机的时候使用,通常便于通过Http代理服务器进行SSL加密通信( Https )连接使用
session
import requests#在requests模块中有session方法# 为什么没有携带请求头
# 不需要提供定制化的请求头,直接使用python默认的请求头就可以# 需要提供请求的数据
login_data = {"email": "dazhuang_python@sina.com","password": "abcd1234"
}# 实例化session方法,用于自动化的记录session信息
session = requests.session()# 发送了一个POST请求,并且提供了login_data数据
# login_response = requests.post(url="http://yushu.talelin.com/login", data=login_data)
# 1.需要把原来的requests替换为实例化好的session
login_response = session.post(url="http://yushu.talelin.com/login", data=login_data)
# print(login_response.text)
# 登录之后,请求个人信息页的时候是失败的
# 可以在请求头中提供cookies就可以访问个人信息页面了
# personal_response = requests.get(url="http://yushu.talelin.com/personal")
# 自动化的带上session,个人的登录凭据信息
personal_response = session.get(url="http://yushu.talelin.com/personal")
print(personal_response.text)
异常
- 遇到网络问题(如:DNS查询失败、拒绝连接等)时,Requests会 抛出一个 ConnectionError 异常
- 如果HTTP请求返回了不成功的状态码,Response.raise_for_status()会抛出一个HTTPError异常
- 遇到网络问题(如:DNS查询失败、拒绝连接等)时,Requests会抛出一个ConnectionError 异常
- 如果HTTP请求返回了不成功的状态码,Response.raise_for_status()会抛出一个HTTPError异常
- 若请求超时,则抛出一个 Timeout异常
- 若请求超过了设定的最大重定向次数,则会抛出一个TooManyRedirects异常
所有Requests显式抛出的异常都继承自requests.exceptions.RequestException。
IP代理有哪些分类,区别是什么?
- 透明代理的意思是爬虫请求数据的时候会携带真实IP
- 普通匿名代理会改变请求信息
- 高匿代理隐藏真实IP
Requests库请求时需要注意的事项
当请求频率较高时,可能会出现请求失败响应码为429的情况。这是由于目标网站的反爬虫模块对请求频率进行了限制。常见的应对措施包括:
- 设置请求头信息。请求头中包括User-Agent、Referer等信息,用于欺骗反爬模块,尽量模拟浏览器的行为。
- 设置请求延时。请求之间加入一定的延时,避免请求频率过高。
- 使用代理。使用代理服务器进行请求,使反爬虫模块难以跟踪。
- 分布式爬虫。将爬虫程序部署到不同的服务器上。
- 遵循robots协议。robots协议是一种规范爬虫采集方式的协议,爬虫必须遵循这个协议。
总的来说,爬虫程序要注意遵守网站的规定,遵守一定的爬虫道德准则,避免对网站造成过大的负担。此外,也要避免过度使用爬虫,以免被封禁或被针对。
参考:https://requests.readthedocs.io/en/latest/
Python正则表达式(re模块)
Python正则表达式(re模块)
import requests
import re# 请求图书列表页的链接
# 获取每一条图书信息
# 格式化每一条图书信息def handle_detail_re(content):"""处理列表页返回数据:param content: response.text:return: print"""# 图书条目正则表达式,re.S可以进行全文匹配item_search = re.compile('description-font">.*?</div>', re.S)# 获取每一页图书条目数据all_item = item_search.findall(content)# 图书的名称title_search = re.compile('title">(.*?)</span>')# 获取图书的作者,出版社,价格author_press_price_search = re.compile(r'<span>(.*?)</span>')# 图书的描述desc_search = re.compile(r'summary">(.*?)</span>')for item in all_item:# 获取到了作者,出版社,价格 的列表信息author_press_price = author_press_price_search.search(item).group(1).split('/')if len(author_press_price) == 3:print({"title": title_search.search(item).group(1),"author": author_press_price[0],"press": author_press_price[1],"price": author_press_price[2],"desc": desc_search.search(item).group(1)})def main():header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"}for i in range(1, 5):url = "http://*****.*******.com/book/search?q=python&page={}".format(i)response = requests.get(url=url, headers=header)handle_detail_re(response.text)if __name__ == '__main__':main()
Beautiful Soup(bs4)
Beautiful Soup 是 Python 用于解析 HTML 和 XML 文件的第三方库,可以从 HTML 和 XML 文件中提取数据。
Beautiful Soup支持的解析器
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,基本信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,p></p>的名字是‘p’,格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>…<>中字符串,格式:<tag>.string |
| Commeent | 标签内字符串的注释部分,一种特殊的 Comment类型 |
# 安装的是beautifulsoup4,但是导包的时候,是通过bs4来导入的,并且导入的是大写的BeautifulSoup
from bs4 import BeautifulSouphtml = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# lxml提前安装好,pip install lxml,第一个参数是html代码段,第二个参数是解析器
soup = BeautifulSoup(html, 'lxml')
# 查看经过bs4实例化,初始化的代码段
print(soup.prettify())
# 获取到的是数据结构,tag,tag有很多方法,如string
print(type(soup.title))
# 来查看文档中title的属性值
print(soup.title.string)
print(soup.head)
# 当有多个节点的时候,我们当前的这种选择模式,只能匹配到第一个节点,其他节点会被忽略
print(soup.p)
# 获取节点的名称
print(soup.title.name)
# attrs会返回标签的所有属性值,返回的是一个字典
print(soup.p.attrs)
print(soup.p.attrs['name'])
# 返回的节点属性,可能是列表,也可能是字符串,需要进行实际的判断
print(soup.p['name'])
print(soup.p['class'])
### 输出
<html><head><title>The Dormouse's story</title></head><body><p class="title" name="dromouse"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p></body>
</html>
<class 'bs4.element.Tag'>
The Dormouse's story
<head><title>The Dormouse's story</title></head>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
title
{'class': ['title'], 'name': 'dromouse'}
dromouse
dromouse
['title']
选择子节点、父节点和兄弟节点
- contents:获取直接子节点,该属性返回一个列表(list类的实例)
- children:获取直接子节点,该属性返回list_iterator类的实例,这个可迭代对象可以用for循环进行迭代
- descendants:获取所有的子孙节点,该属性返回一个产生器(generator),for循环迭代才可输出产生器的值
- parent:获取某个节点的直接父节点,返回当前节点的父节点的Tag对象
- parents:获取某个节点的所有父节点,返回当前节点所有父节点的可迭代对象,for循环迭代出所有父节点Tag对象
- next_sibling:获取当前节点的下一个兄弟节点
- previous_sibling:获取当前节点的上一个兄弟节点
- next_siblings:获取当前节点后面的所有兄弟节点,返回一个可迭代对象
- previous_siblings:获取当前节点前面的所有兄弟节点,返回一个可迭代对象
(注:节点之间的换行符或其他文本会被当成文本节点处理,是bs4.element.NavigableString类的实例,而普通节点是bs4.element.Tag类的实例)
方法选择器
find_all方法
根据节点名、属性、文本内容等选择所有符合要求的节点,该方法属于Tag对象,又由于BeautifulSoup是Tag的子类,所以find_all方法在BeautifulSoup对象上也可以调用(find_all方法以当前Tag对象对应的节点作为根开始继续选取节点,嵌套查询)。
def find_all(self, name=None, attrs= {}, recursive= True, text= None, limit= None, **kwargs):
- name参数:用于指定节点名,会选取所有节点名与name参数相同的节点,返回一个bs4.element.ResultSet对象,该对象是可迭代的,通过迭代获取每一个符合条件的节点(Tag对象)
- attrs参数:通过节点的属性查找,attrs参数是一个字典类型,key是节点属性名,value是节点属性值
- text参数:搜索匹配的文本节点,传入的参数可以是字符串也可以是正则表达式对象
find方法
用于查询满足条件的第一个节点,返回的是bs4.element.Tag对象
#通过属性来进行查询
#通过text文本来获取匹配的文本import re
from bs4 import BeautifulSouphtml='''
<div class="panel"><div class="panel-heading"><h4>Hello</h4></div><div class="panel-body"><ul class="list" id="list-1" name="elements"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul><ul class="list" id="list-1"><li class="element">Foo2</li><li class="element">Bar2</li><li class="element">Jay2</li></ul><ul class="list list-small" id="list-2"><li class="element">Foo</li><li class="element">Bar</li></ul></div>
</div>
'''soup = BeautifulSoup(html,'lxml')
#attrs,传入的是属性参数,类型是字典,attrs={"id":"list-1"}
# print(soup.find_all(attrs={"id":"list-1"}))
# print(soup.find_all(attrs={"name":"elements"}))
#也可以直接传入ID这个参数
# print(soup.find_all(id="list-1"))
#class在Python中是一个关键字,find_all方法里面要用class的时候,后面加上一个下划线
# print(soup.find_all(class_="list"))#可以通过text参数来获取文本的值,可以传递正则表达式,返回是一个列表
# print(soup.find_all(text=re.compile("Foo\d")))#find方法,返回的是一个单个的元素,第一个匹配的元素,而find_all返回的是所有值的列表
# print(soup.find(name="ul"))"""
find_parents 和 find_parent:前者返回所有祖先节点,后者返回直接父节点。
find_next_siblings 和 find_next_sibling:前者返回后面所有的兄弟节点,后者返回后面第一个兄弟节点。
find_previous_siblings 和 find_previous_sibling:前者返回前面所有的兄弟节点,后者返回前面第一个兄弟节点。
find_all_next 和 find_next:前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点。
find_all_previous 和 find_previous:前者返回节点前所有符合条件的节点,后者返回第一个符合条件的节点。
"""
CSS选择器
使用CSS选择器需要使用Tag对象的select方法,该方法接收一个字符串类型的CSS选择器,选择器如:
- .classname:选取样式名为classname的节点,也就是class属性值是classname的节点
- nodename:选取节点名为nodename的节点
- #idname:选取id属性值为idname的节点
嵌套选择节点:可以将节点选择器、方法选择器和CSS选择器混合使用
获取属性值与文本:select方法返回Tag对象的集合,可以用Tag对象的方式获取节点属性值和文本内容,获取属性值可以使用attrs,也可以直接使用[…]方式引用节点的属性,获取节点的文本内容可以使用get_text方法,也可以使用string属性。
#使用css选择器,只需要呢,调用select方法,传入css选择器即可from bs4 import BeautifulSouphtml='''
<div class="panel"><div class="panel-heading"><h4>Hello</h4></div><div class="panel-body"><ul class="list" id="list-1"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul><ul class="list list-small" id="list-2"><li class="element">Foo</li><li class="element">Bar</li></ul></div>
</div>
'''soup = BeautifulSoup(html,'lxml')
#需要调用select方法,传入css选择器
# print(soup.select(".panel .panel-heading"))#获取ul标签下所有Li标签
# print(soup.select("ul li"))#获取id为list-2,class为element两个Li标签
# print(type(soup.select("#list-2 .element")[0]))#支持嵌套选择
#先获取到ul标签,tag类型,for 调用select方法在次传入css选择器
for ul in soup.select("ul"):for li in ul.select("li"):#调用tag类型里面的方法,string方法来获取文本内容# print(li.string)print(li['class'])#支持使用属性获取元素
# for ul in soup.select("ul"):
# print(ul['id'])#建议大家使用find find_all查询匹配单个结果或多个结果
#css选择器非常的熟悉,那么就可以使用css选择器
参考:https://beautifulsoup.cn/
lxml(Python)
Python读写xml(xml,lxml)
#导入lxml库,etree
from lxml import etree#准备的html数据,不完整,html,body,li不完整
html_data = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul>
</div>
'''
#使用etree.HTML
html = etree.HTML(html_data)
#etree.tostring,decode()
# <html><body><div>
# <ul>
# <li class="item-0"><a href="link1.html">first item</a></li>
# <li class="item-1"><a href="link2.html">second item</a></li>
# <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
# <li class="item-1"><a href="link4.html">fourth item</a></li>
# <li class="item-0"><a href="link5.html">fifth item</a>
# </li></ul>
# </div>
# </body></html>
# print(etree.tostring(html).decode())
#返回_Element,就是整个xml树的根节点
# print(type(html))
#使用的是双斜杠,返回是一个列表,每一个元素都是element类型,列表里面的每一个element类型的元素就
#代表我们获取到的标签元素
# result = html.xpath("//li/a/text()")
#获取li标签下面所有的class属性值
# result = html.xpath("//li/@class")
#获取的li标签href值为link1.html这个a标签,使用了单引号,如果外面使用的是
#双引号,内部一定要使用单引号,大家一定要注意
# result = html.xpath("//li/a[@href='link1.html']/text()")
#我们需要获取span标签,一定要注意span他是a标签的子元素,而不是li标签的子元素,使用双斜杠
# result = html.xpath("//li//span")
#我们使用了last()函数,最后一个标签,-1代表倒数第二个标签
result = html.xpath("//li[last()]/a/@href")
print(result)
批量下载图片
import os
import requests
from bs4 import BeautifulSoupdef download_images(url, headers):""":param url::param headers::return:"""# 发送HTTP请求并获取网页内容response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')# 图片保存路径for title in soup.find_all('title'):title = title.contents[0].split(')')[0]save_folder = os.path.join(".\images", title)if not os.path.exists(save_folder):os.makedirs(save_folder)# 获取所有图片的标签img_tags = soup.find_all('img')# 遍历图片标签并下载图片for img_tag in img_tags:try:img_url = img_tag['src']# 如果图片URL是相对路径,则拼接完整URL# if img_url.startswith('/'):# img_url = url + img_url# 发送HTTP请求并保存图片img_response = requests.get(img_url)img_data = img_response.content# 提取图片文件名img_filename = img_url.split('/')[-1]# 拼接保存路径save_path = os.path.join(save_folder, img_filename)# 保存图片with open(save_path, 'wb') as img_file:img_file.write(img_data)print(f"已保存图片: {save_path}")except Exception as error:print(error)continueheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/69.0.3497.100 Safari/537.36'}
for i in range(1843443, 1843445, 1):# 替换为目标网站的URLurl = 'https://dxs.moe.gov.cn/zx/a/hd_sxjm_sxjmlw_2022qgdxssxjmjslwzs_2022ctlw/230613/{}.shtml?source=hd_sxjm_sxjmlw_2022qgdxssxjmjslwzs'.format(i)# 调用函数进行图片下载download_images(url, headers)for i in range(1820271, 1820297, 2):# 替换为目标网站的URLurl = 'https://dxs.moe.gov.cn/zx/a/hd_sxjm_sxjmlw_2022qgdxssxjmjslwzs/221106/{}.shtml?source=hd_sxjm_sxjmlw_2022qgdxssxjmjslwzs'.format(i)# 调用函数进行图片下载download_images(url, headers)相关文章:
网络爬虫(Python:Requests、Beautiful Soup笔记)
网络爬虫(Python:Requests、Beautiful Soup笔记) 网络协议简要介绍一。OSI参考模型二、TCP/IP参考模型对应关系TCP/IP各层实现的协议应用层传输层网络层 HTTP协议HTTP请求HTTP响应HTTP状态码 Requests(Python)Requests…...

【Kotlin】内联函数
文章目录 内联函数noinline: 避免参数被内联非局部返回使用标签实现Lambda非局部返回为什么要设计noinline crossinline具体化参数类型 Kotlin中的内联函数之所以被设计出来,主要是为了优化Kotlin支持Lambda表达式之后所带来的开销。然而,在Java中我们似…...
Unity技美35——再URP管线环境下,配置post后期效果插件(post processing)
前两年在我的unity文章第10篇写过,后效滤镜的使用,那时候大部分项目用的还是unity的基础管线,stander管线。 但是现在随着unity的发展,大部分项目都用了URO管线,甚至很多PC端用的都是高效果的HDRP管线,这就…...
Redis:持久化RDB和AOF
目录 概述RDB持久化流程指定备份文件的名称指定备份文件存放的目录触发RDB备份redis.conf 其他一些配置rdb的备份和恢复优缺点停止RDB AOF持久化流程AOF启动/修复/恢复AOF同步频率设置rewrite压缩原理触发机制重写流程no-appendfsync-on-rewrite 优缺点 如何选择 概述 Redis是…...
基于python协同过滤推荐算法的音乐推荐与管理系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 基于Python的协同过滤推荐算法的音乐推荐与管理系统是一个集成了音乐推荐和管理的系统,它使用协同过滤算…...

【极客技术】真假GPT-4?微调 Llama 2 以替代 GPT-3.5/4 已然可行!
近日小编在使用最新版GPT-4-Turbo模型(主要特点是支持128k输入和知识库截止日期是2023年4月)时,发现不同商家提供的模型回复出现不一致的情况,尤其是模型均承认自己知识库达到2023年4月,但当我们细问时,Fak…...
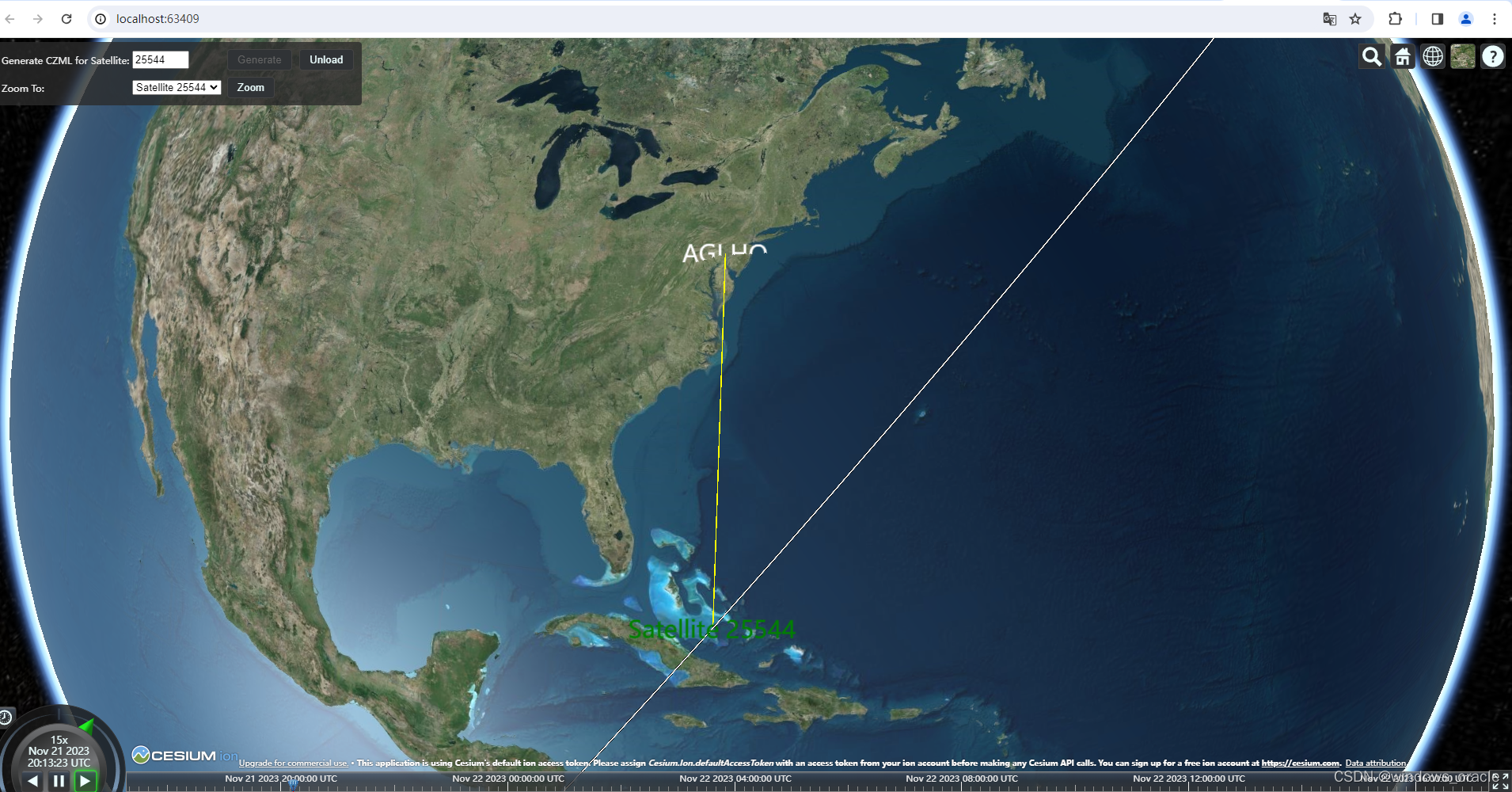
STK Components 二次开发-创建地面站
1.地面站只需要知道地面站的经纬高。 // Define the location of the facility using cartographic coordinates.var location new Cartographic(Trig.DegreesToRadians(-75.596766667), Trig.DegreesToRadians(40.0388333333), 0.0); 2.创建地面站 创建方式和卫星一样生成对…...

数据结构与算法(三)贪心算法(Java)
目录 一、简介1.1 定义1.2 基本步骤1.3 优缺点 二、经典示例2.1 选择排序2.2 背包问题 三、经典反例:找零钱3.1 题目3.2 解答3.3 记忆化搜索实现3.4 动态规划实现 一、简介 1.1 定义 贪心算法(Greedy Algorithm),又名贪婪法&…...

057-第三代软件开发-文件监视器
第三代软件开发-文件监视器 文章目录 第三代软件开发-文件监视器项目介绍文件监视器实现原理关于 QFileSystemWatcher实现代码 关键字: Qt、 Qml、 关键字3、 关键字4、 关键字5 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML&…...
二十七、微服务案例
目录 一、实现输入搜索功能 1、下载代码,在idea上打开 2、新建RequestParams类,用于接收解析请求 3、在启动类中加入客户端地址Bean,以便实现服务 4、编写搜索方法 5、新建返回分页结果类 6、实现搜索方法 7、编写控制类,…...

(C++)string类的模拟实现
愿所有美好如期而遇 前言 我们模拟实现string类不是为了去实现他,而是为了了解他内部成员函数的一些运行原理和时间复杂度,在将来我们使用时能够合理地去使用他们。 为了避免我们模拟实现的string类与全局上的string类冲突(string类也在std命名空间中)&…...

处理数据中的缺失值--删除缺少值的行
两个最主要的处理缺失值的方法是: ❏ 删除缺少值的行; ❏ 填充缺失值; 我们首先将serum_insulin的中的字段值0替换为None,可以看到缺失值的数量为374个; print(pima[serum_insulin].isnull().sum()) pima[serum_insu…...
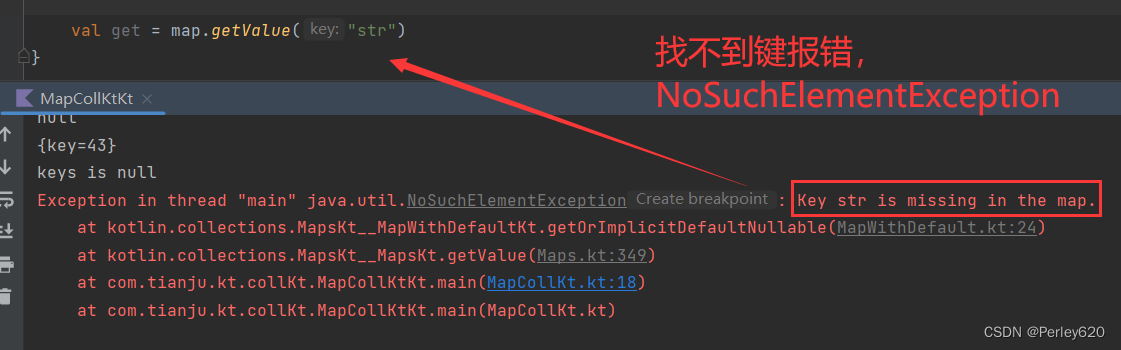
Kotlin学习——kt里的集合,Map的各种方法之String篇
Kotlin 是一门现代但已成熟的编程语言,旨在让开发人员更幸福快乐。 它简洁、安全、可与 Java 及其他语言互操作,并提供了多种方式在多个平台间复用代码,以实现高效编程。 https://play.kotlinlang.org/byExample/01_introduction/02_Functio…...

MIT 6.824 -- MapReduce Lab
MIT 6.824 -- MapReduce Lab 环境准备实验背景实验要求测试说明流程说明 实验实现GoLand 配置代码实现对象介绍协调器启动工作线程启动Map阶段分配任务执行任务 Reduce 阶段分配任务执行任务 终止阶段 崩溃恢复 注意事项并发安全文件转换golang 知识点 测试 环境准备 从官方gi…...

创新研报|顺应全球数字化,能源企业以“双碳”为目标的转型迫在眉睫
能源行业现状及痛点分析 挑战一:数字感知能力较弱 挑战二:与业务的融合度低 挑战三:决策响应速度滞后 挑战四:价值创造有待提升 挑战五:安全风险如影随形 能源数字化转型定义及架构 能源行业数字化转型体系大体…...
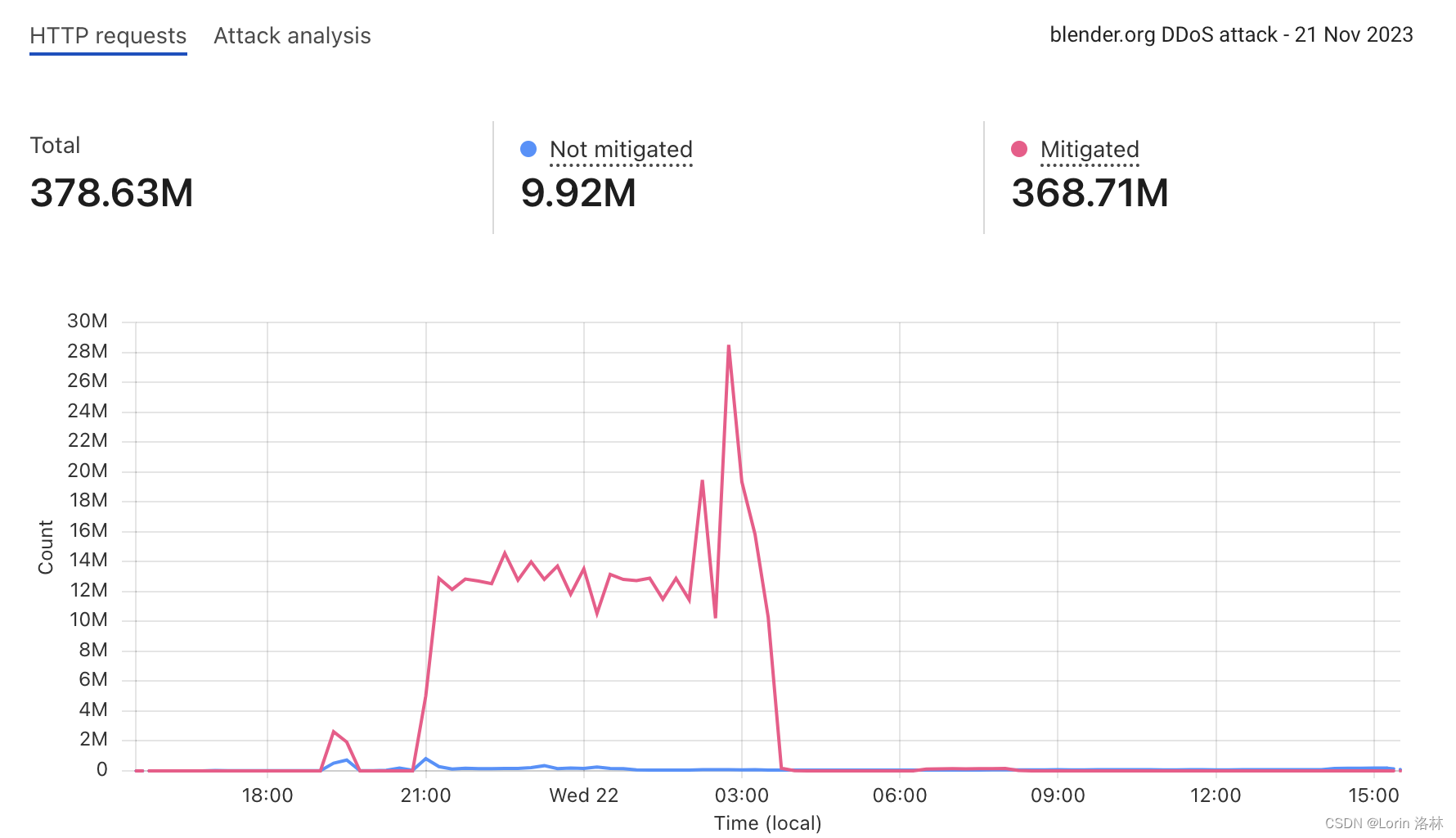
Blender 连续 5 天遭受大规模 DDoS 攻击
Blender 发布公告指出,在2023年11月18日至23日期间,blender.org 网站遭受了持续的分布式拒绝服务(DDoS)攻击,攻击者通过不断发送请求导致服务器超载,使网站运营严重中断。此次攻击涉及数百个 IP 地址的僵尸…...

Python 获取本地和广域网 IP
Python 获取本地IP ,使用第三方库,比如 netifaces import netifaces as nidef get_ip_address():try:# 获取默认网络接口(通常是 eth0 或 en0)default_interface ni.gateways()[default][ni.AF_INET][1]# 获取指定网络接口的IP地…...
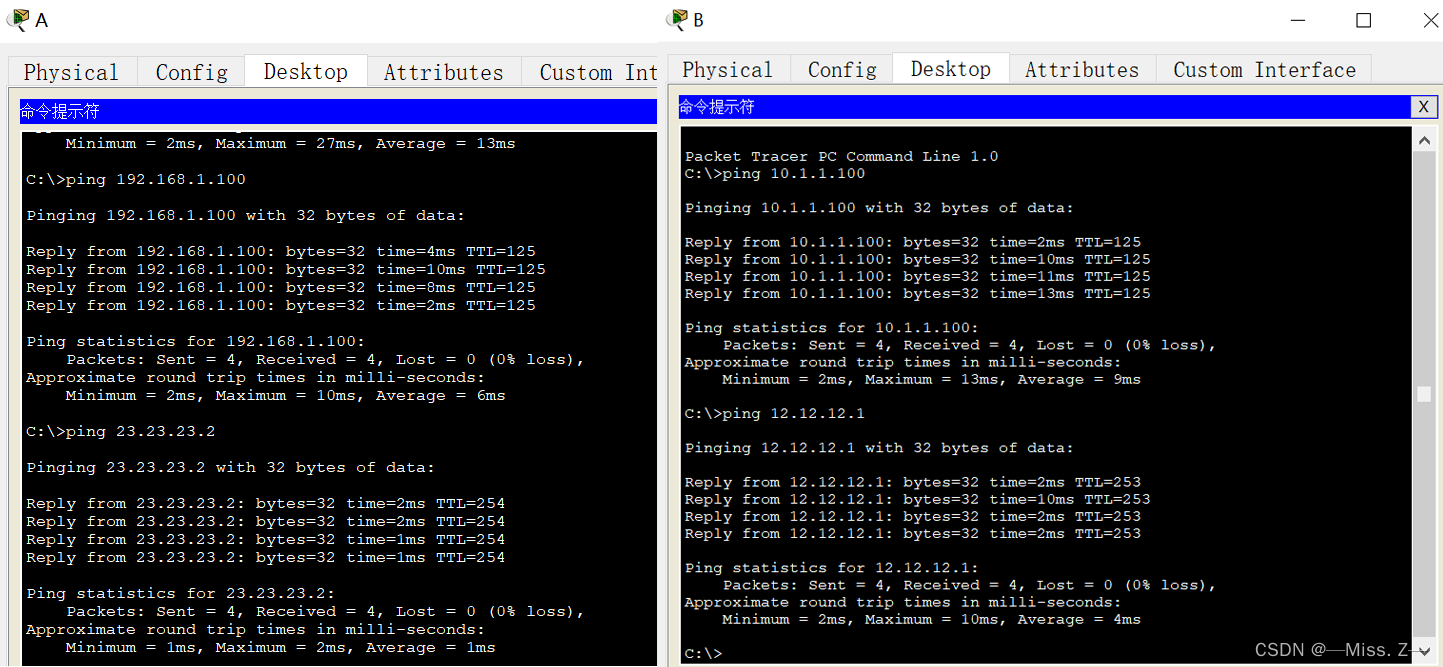
静态路由配置过程
静态路由 静态路由简介 路由器在转发数据时,要先在路由表(Routing Table)中在找相应的路由,才能知道数据包应该从哪个端口转发出去。路由器建立路由表基本上有以下三种途径。 (1)直连路由:路由…...
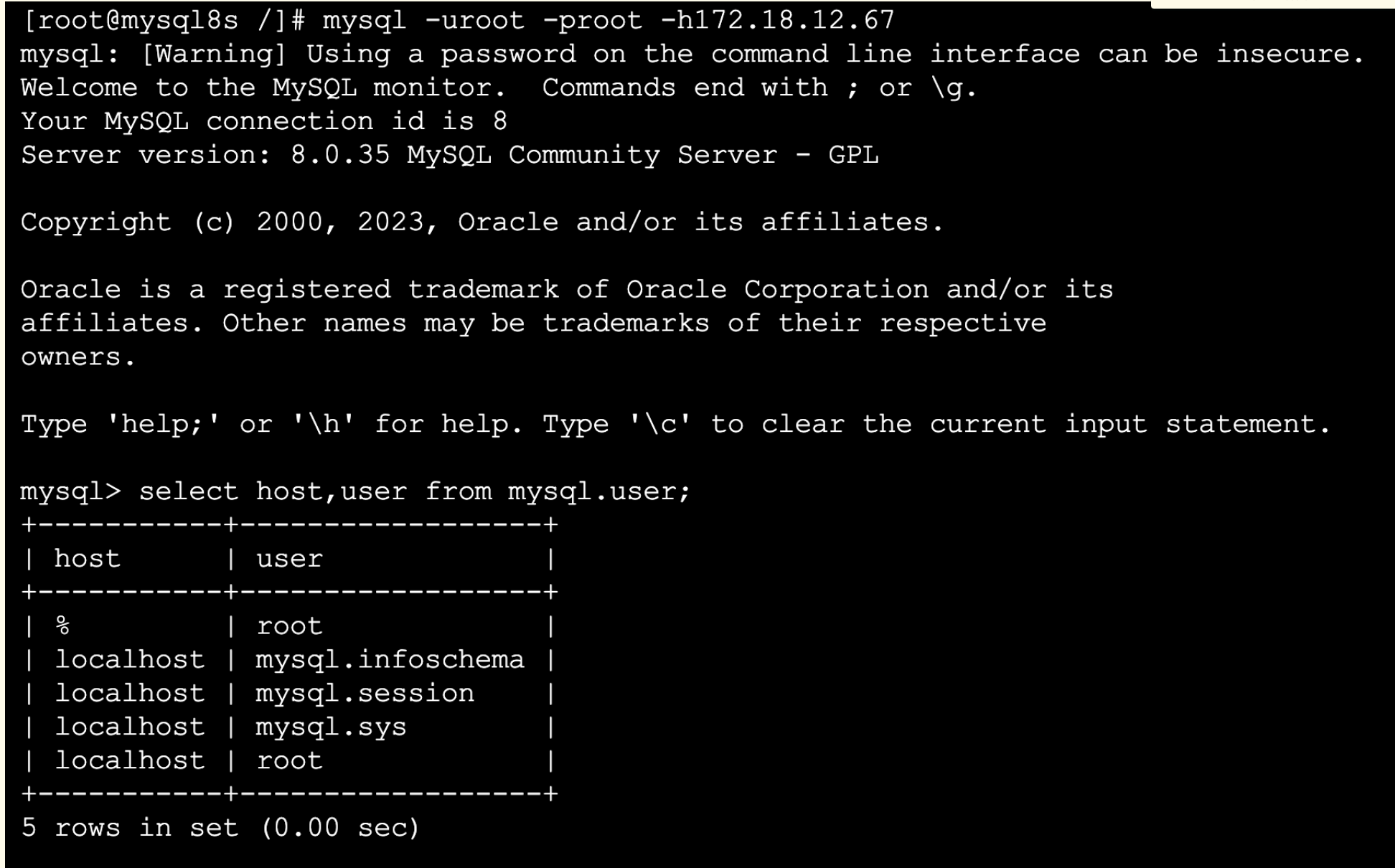
基于OGG实现MySQL实时同步
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

【计算机网络笔记】多路访问控制(MAC)协议——轮转访问MAC协议
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...
)
保姆级教程:手把手教你用PyTorch复现ICASSP 2023的EMA注意力模块(附完整代码)
从零实现ICASSP 2023多尺度注意力:EMA模块的工程实践指南 在计算机视觉领域,注意力机制已经成为提升模型性能的关键组件。ICASSP 2023提出的EMA(Efficient Multi-Scale Attention)模块通过创新的跨空间学习方式,在保持…...

MySQL优化全攻略:索引、SQL与分库分表的最佳实践第
一、各自优势和对比 这是检索出来的数据,据说是根据第三方评测与企业数据,三款产品在代码生成质量上各有侧重: 产品 语言优势 场景亮点 核心差异 百度 Comate C核心代码质量第一;Python首生成率达92.3% SQL生成准确率提升35%&…...

深入解析rewriteBatchedStatements:如何通过SQL重写提升MySQL批处理性能
1. 揭开rewriteBatchedStatements的神秘面纱 第一次听说rewriteBatchedStatements这个参数时,我正被一个批量导入数据的性能问题折磨得焦头烂额。当时我们的系统需要每小时处理数十万条用户行为数据,但MySQL的插入速度始终上不去。直到某天深夜调试时&am…...

西门子S7-1500PLC大型程序实战:FB块PTO控制多轴运动,S7-1200PLC智能IO...
西门子S7-1500PLC大型程序,各种FB块PTO控制20多个轴,5台S7-1200PLC智能IO通讯,ModbusRTU通讯轮询,完整威纶通触摸屏程序,是学习西门子PLC通信、伺服好帮手 程序结构分明,注释详细,有机械结构图&…...

3分钟快速优化Windows性能:Mem Reduct系统优化工具终极指南
3分钟快速优化Windows性能:Mem Reduct系统优化工具终极指南 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct …...

Windows 11 LTSC 微软商店一键恢复工具:3分钟让精简版系统重获完整应用生态
Windows 11 LTSC 微软商店一键恢复工具:3分钟让精简版系统重获完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 24…...

10个Python数据分析实战技巧:从入门到精通的完整指南
10个Python数据分析实战技巧:从入门到精通的完整指南 【免费下载链接】Bioinformatics-with-Python-Cookbook-Second-Edition 项目地址: https://gitcode.com/gh_mirrors/bi/Bioinformatics-with-Python-Cookbook-Second-Edition 想要快速掌握Python数据分析…...

5大核心价值实现信息自由:面向研究者的信息获取工具全攻略
5大核心价值实现信息自由:面向研究者的信息获取工具全攻略 在信息获取成本日益增加的今天,优质内容被各种付费墙→限制内容访问的付费机制层层封锁。信息获取工具作为突破这一限制的关键解决方案,正成为研究者、教育工作者和内容创作者的必备…...

iOS 26.4越狱深度解析:从技术原理到实战应用的全面指南
iOS 26.4越狱深度解析:从技术原理到实战应用的全面指南 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址…...

AD域环境管理实操手册
第一章 域用户账户管理 1.1 域用户账户基础 域用户账户是AD域环境中身份验证的核心载体,主要有两个核心作用: 验证用户的身份合法性 授权或拒绝用户对域资源的访问 注意:域用户在客户机登录后,默认仅属于本地Users组,无管理员权限,如需提升权限可将域用户加入本地Power…...