大语言模型损失函数详解
我们可以把语言模型分为两类:
- 自动回归式语言模型:自动回归式语言模型在本质上是单向的,也就是说,它只沿着一个方向阅读句子。正向(从左到右)预测;反向(从右到左)预测。
- 自动编码式语言模型:自动编码式语言模型同时利用了正向预测和反向预测的优势。在进行预测时,它会同时从两个方向阅读句子,所以自动编码式语言模型是双向的。
本文将结合具体模型和论文,探讨这两种模型的损失函数。
一、自动编码式语言模型
提到自动编码式语言模型,那最经典的非BERT莫属了。
1.1 BERT
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的自然语言处理模型。它由Google于2018年提出,以解决语境相关性和双向理解的问题。BERT采用双向训练方式,能够同时考虑文本左右两侧的上下文信息,有效捕获语境含义。
BERT的损失函数由两部分组成,第一部分是来自 Mask-LM 的单词级别分类任务,另一部分是句子级别的分类任务。通过这两个任务的联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句子级别的语义信息。
在第一部分的损失函数中,如果被 mask 的词集合为 M(即计算BERT的MLM loss时会忽略没被mask的token),因为它是一个词典大小 |V| 上的多分类问题,那么具体说来有:
在句子预测任务中,也是一个分类问题的损失函数:
这两个损失函数也很容易理解:
- 多分类问题,类别的数量等于词表的大小,第
个词被正确预测的概率越大,相应的损失越小
- 二分类问题,第
个句子的类别被正确预测的概率越大,相应的损失越小
因此,两个任务联合学习的损失函数是:
二、自动回归式语言模型
BERT一度引领了NLP领域。但是随着OpenAI-GPT系列模型的爆火,自回归式模型被更为广泛的采用。本章详细解析GLM大模型、LoRA微调方法、Prefix tuning这三篇论文中的损失函数。以期找到这些损失函数的共性。
2.1 GLM系列大模型
清华大学提出的GLM大模型预训练框架采用了自回归的空白填充方法,在自然语言理解、无条件生成、有条件生成等NLP任务上取得了显著成果。其中,GLM-130B是最大的模型,拥有1300亿参数,支持中英文双语,旨在训练出开源开放的高精度千亿中英双语语言模型。该模型采用了量化技术,可在4块3090(24G)或8块2080Ti(11G)上推理。
输入向量为,抽样出文本段
,每个文本段
都代表了一系列连续的token吗,可以写做
,每个文本段
都用[MASK]代表,从而形成了
。
表示抽样文本段的数量,
表示每个抽样文本段的长度。预训练目标可以用下式表示:
需要对所有的抽样文本段进行随机打乱, 是
被打乱后,所有可能性的集合,
又可以写作
。在预测缺失的文本段
时(每个
都包含多个单词,所以需要用集合S表示,
作为下标),模型可以访问到被破坏的文本
,以及
前面所有的抽样文本段。
那每个中token的预测概率应该如何表示呢?如下:
很简单,把所有token的概率乘起来就可以了。
需要注意的是,这边要弄清楚和
的区别:
代表第
- 由于
有很多种打乱方式,
表示其中某一个打乱方式的第
2.2 LoRA
以上是针对GLM这系列特殊的模型。那么对于一般的自回归式模型,有没有更普遍的一种表达方式呢?我们以LoRA这篇文章为例。
每一个下游任务都能用 内容-目标对来表示:,
和
都是token序列。例如在自然语言->sql语句任务中,
是自然语言查询,
是其相应的SQL命令。对于概括任务而言,
是文章的内容,
是其相应的概述内容。预训练的自回归语言模型可以用
来表示。那么微调就是要找到一组参数
,使得下式最大:
即用前的所有样本来预测第
个样本。
三、参考文献
[1] Devlin J , Chang M W , Lee K ,et al.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[2] Du Z , Qian Y , Liu X ,et al.GLM: General Language Model Pretraining with Autoregressive Blank Infilling[J]. 2021.DOI:10.48550/arXiv.2103.10360.
[3] Zeng, Aohan, et al. "Glm-130b: An open bilingual pre-trained model." arXiv preprint arXiv:2210.02414 (2022).
[4] Hu E J , Shen Y , Wallis P ,et al.LoRA: Low-Rank Adaptation of Large Language Models[J]. 2021.DOI:10.48550/arXiv.2106.09685.
相关文章:
大语言模型损失函数详解
我们可以把语言模型分为两类: 自动回归式语言模型:自动回归式语言模型在本质上是单向的,也就是说,它只沿着一个方向阅读句子。正向(从左到右)预测;反向(从右到左)预测。…...

Spring Boot 3 集成 Knife4j
基础环境 SpringBoot : 3.0.6 Java: jdk-17.0.5 Maven: 3.6.1依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xs…...

BetaFlight模块设计之三十六:SoftSerial
BetaFlight模块设计之三十六:SoftSerial 1. 源由2. API接口2.1 openSoftSerial2.2 onSerialRxPinChange2.3 onSerialTimerOverflow2.4 processTxState2.5 processRxState 3. 辅助函数3.1 applyChangedBits3.2 extractAndStoreRxByte3.3 prepareForNextRxByte 4. 总结…...

PC访问华为昇腾开发板的摸索过程
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> 最近要折腾华为昇腾开发板(官方名称叫:Atlas 200I DK)。先是按照官方教程折腾:Atlas200DK环境部署。我发现…...
C++学习之路(六)C++ 实现简单的工具箱系统命令行应用 - 示例代码拆分讲解
简单的工具箱系统示例介绍: 这个示例展示了一个简单的工具箱框架,它涉及了几个关键概念和知识点: 面向对象编程 (OOP):使用了类和继承的概念。Tool 是一个纯虚类,CalculatorTool 和 FileReaderTool 是其派生类。 多态࿱…...
redis运维(十四) hash缓存案例
一 缓存案例 ① 需求 ② 个人理解 策略:不更新缓存,而是删除缓存大部分观点认为:1、做缓存不应该是去更新缓存,而是应该删除缓存2、然后由下个请求去缓存,发现不存在后再读取数据库,写入redis缓存 高并发场景下,到底先更新缓存还是先更…...

Rust UI开发(三):iced如何打开图片(对话框)并在窗口显示图片?
注:此文适合于对rust有一些了解的朋友 iced是一个跨平台的GUI库,用于为rust语言程序构建UI界面。 这是一个系列博文,本文是第三篇,前两篇的链接: 1、Rust UI开发(一):使用iced构建…...
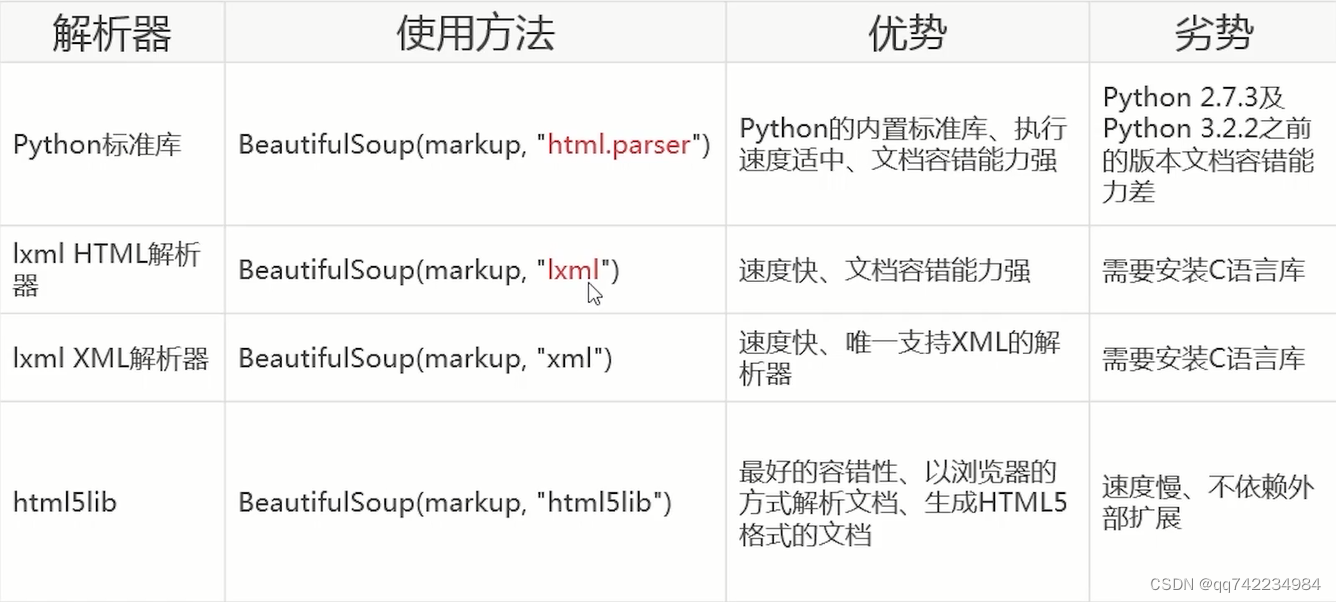
网络爬虫(Python:Requests、Beautiful Soup笔记)
网络爬虫(Python:Requests、Beautiful Soup笔记) 网络协议简要介绍一。OSI参考模型二、TCP/IP参考模型对应关系TCP/IP各层实现的协议应用层传输层网络层 HTTP协议HTTP请求HTTP响应HTTP状态码 Requests(Python)Requests…...

【Kotlin】内联函数
文章目录 内联函数noinline: 避免参数被内联非局部返回使用标签实现Lambda非局部返回为什么要设计noinline crossinline具体化参数类型 Kotlin中的内联函数之所以被设计出来,主要是为了优化Kotlin支持Lambda表达式之后所带来的开销。然而,在Java中我们似…...
Unity技美35——再URP管线环境下,配置post后期效果插件(post processing)
前两年在我的unity文章第10篇写过,后效滤镜的使用,那时候大部分项目用的还是unity的基础管线,stander管线。 但是现在随着unity的发展,大部分项目都用了URO管线,甚至很多PC端用的都是高效果的HDRP管线,这就…...
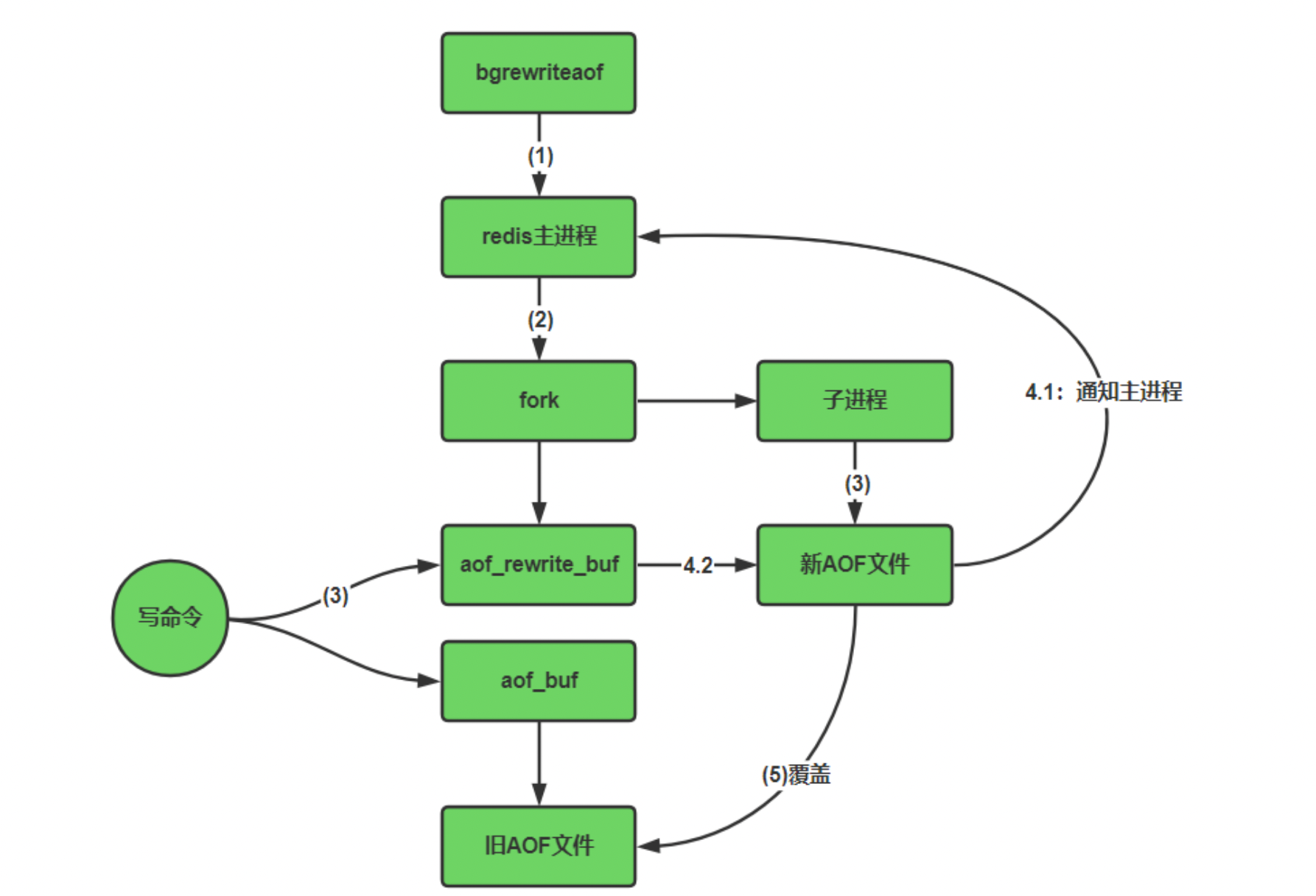
Redis:持久化RDB和AOF
目录 概述RDB持久化流程指定备份文件的名称指定备份文件存放的目录触发RDB备份redis.conf 其他一些配置rdb的备份和恢复优缺点停止RDB AOF持久化流程AOF启动/修复/恢复AOF同步频率设置rewrite压缩原理触发机制重写流程no-appendfsync-on-rewrite 优缺点 如何选择 概述 Redis是…...
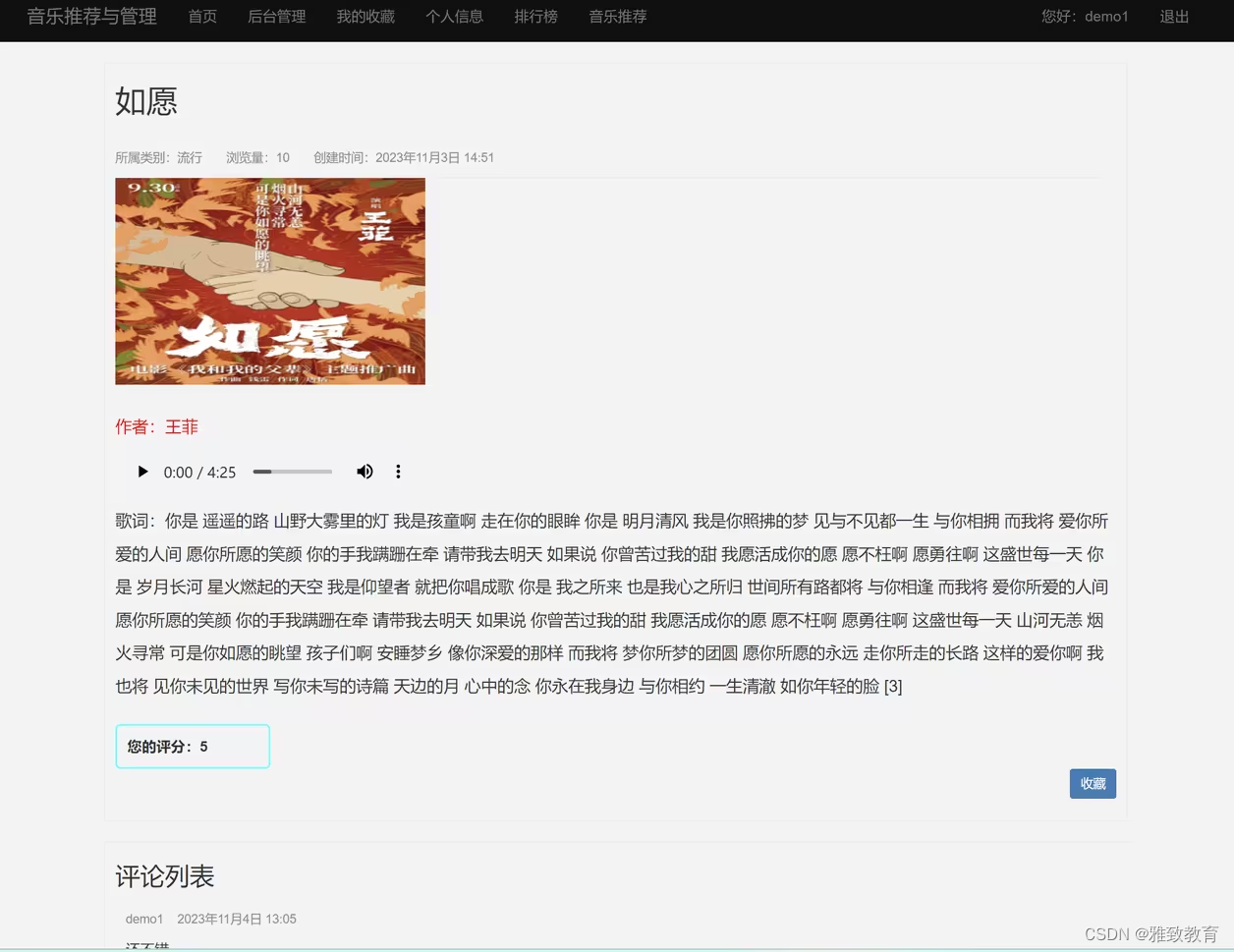
基于python协同过滤推荐算法的音乐推荐与管理系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 基于Python的协同过滤推荐算法的音乐推荐与管理系统是一个集成了音乐推荐和管理的系统,它使用协同过滤算…...

【极客技术】真假GPT-4?微调 Llama 2 以替代 GPT-3.5/4 已然可行!
近日小编在使用最新版GPT-4-Turbo模型(主要特点是支持128k输入和知识库截止日期是2023年4月)时,发现不同商家提供的模型回复出现不一致的情况,尤其是模型均承认自己知识库达到2023年4月,但当我们细问时,Fak…...
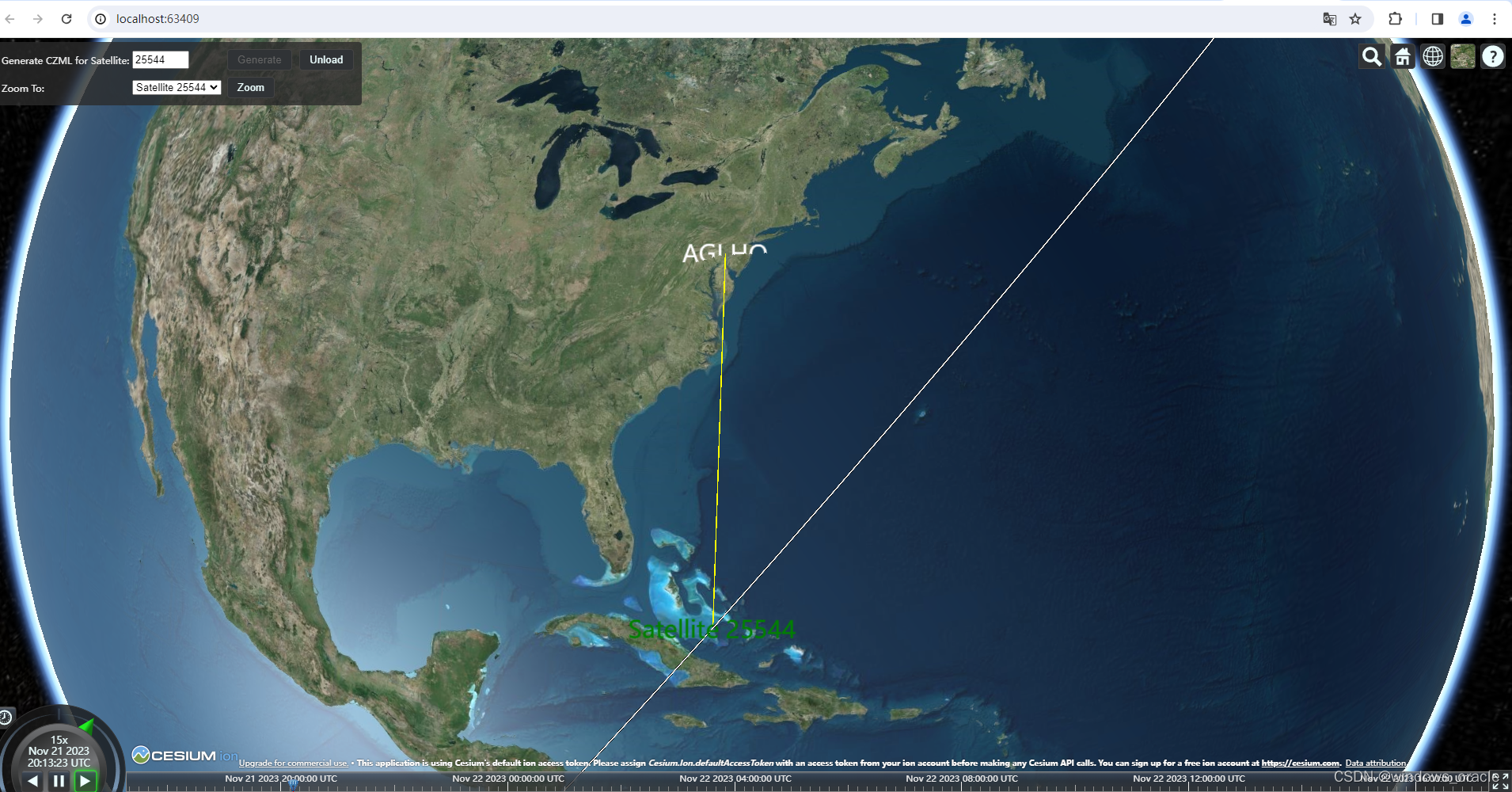
STK Components 二次开发-创建地面站
1.地面站只需要知道地面站的经纬高。 // Define the location of the facility using cartographic coordinates.var location new Cartographic(Trig.DegreesToRadians(-75.596766667), Trig.DegreesToRadians(40.0388333333), 0.0); 2.创建地面站 创建方式和卫星一样生成对…...

数据结构与算法(三)贪心算法(Java)
目录 一、简介1.1 定义1.2 基本步骤1.3 优缺点 二、经典示例2.1 选择排序2.2 背包问题 三、经典反例:找零钱3.1 题目3.2 解答3.3 记忆化搜索实现3.4 动态规划实现 一、简介 1.1 定义 贪心算法(Greedy Algorithm),又名贪婪法&…...

057-第三代软件开发-文件监视器
第三代软件开发-文件监视器 文章目录 第三代软件开发-文件监视器项目介绍文件监视器实现原理关于 QFileSystemWatcher实现代码 关键字: Qt、 Qml、 关键字3、 关键字4、 关键字5 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML&…...
二十七、微服务案例
目录 一、实现输入搜索功能 1、下载代码,在idea上打开 2、新建RequestParams类,用于接收解析请求 3、在启动类中加入客户端地址Bean,以便实现服务 4、编写搜索方法 5、新建返回分页结果类 6、实现搜索方法 7、编写控制类,…...

(C++)string类的模拟实现
愿所有美好如期而遇 前言 我们模拟实现string类不是为了去实现他,而是为了了解他内部成员函数的一些运行原理和时间复杂度,在将来我们使用时能够合理地去使用他们。 为了避免我们模拟实现的string类与全局上的string类冲突(string类也在std命名空间中)&…...

处理数据中的缺失值--删除缺少值的行
两个最主要的处理缺失值的方法是: ❏ 删除缺少值的行; ❏ 填充缺失值; 我们首先将serum_insulin的中的字段值0替换为None,可以看到缺失值的数量为374个; print(pima[serum_insulin].isnull().sum()) pima[serum_insu…...
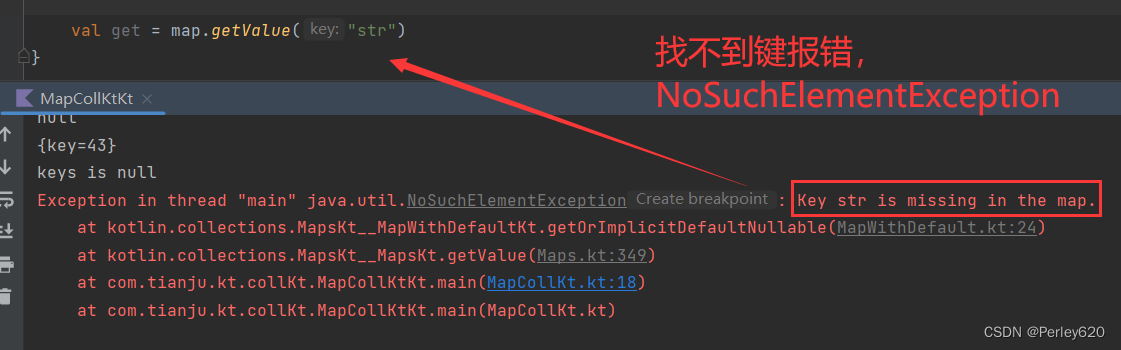
Kotlin学习——kt里的集合,Map的各种方法之String篇
Kotlin 是一门现代但已成熟的编程语言,旨在让开发人员更幸福快乐。 它简洁、安全、可与 Java 及其他语言互操作,并提供了多种方式在多个平台间复用代码,以实现高效编程。 https://play.kotlinlang.org/byExample/01_introduction/02_Functio…...

化工园区智能一体化巡检平台
平台以数字孪生、AI智能研判、多模态感知为核心技术底座,整合全域数据,实现"一张屏管园区"的高效管控。数据可视化大屏:实时呈现园区设备状态、巡检轨迹、隐患告警等核心信息,支持3D园区模型缩放、旋转,精准…...

intv_ai_mk11行业落地案例:教育内容总结、电商文案生成、开发需求转代码
intv_ai_mk11行业落地案例:教育内容总结、电商文案生成、开发需求转代码 1. 教育内容总结应用实践 1.1 教育场景痛点分析 教育工作者经常面临海量教学资料的整理和提炼工作。传统人工总结方式存在效率低下、主观性强、格式不统一等问题。以某在线教育平台为例&am…...

3分钟搞定Jellyfin中文元数据:MetaShark插件全攻略
3分钟搞定Jellyfin中文元数据:MetaShark插件全攻略 【免费下载链接】jellyfin-plugin-metashark jellyfin电影元数据插件 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metashark 还在为Jellyfin媒体库中那些没有中文信息的电影和剧集发愁吗…...

CSS如何控制全屏显示的元素样式
全屏元素应设display: block或flex、position: fixed并绑定top/left/width/height,:fullscreen中显式声明box-sizing: border-box,移动端优先用webkit-playsinline模拟全屏。全屏元素的display和position怎么设才不“飘”全屏显示的元素(比如…...

如何在5分钟内为Unity游戏实现实时翻译:XUnity.AutoTranslator完整实战指南
如何在5分钟内为Unity游戏实现实时翻译:XUnity.AutoTranslator完整实战指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一款功能强大的Unity游戏实时翻译插件&…...

如何通过SMUDebugTool精细调校AMD Ryzen处理器性能
如何通过SMUDebugTool精细调校AMD Ryzen处理器性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.com/gh_m…...

氙灯VS LED太阳光模拟器:对比与选型
在材料科学、光催化研究与环境模拟等领域,太阳光模拟器已成为不可或缺的核心设备。然而,面对氙灯与LED两种主流技术路线,科研人员与设备采购者常常陷入选择困境。Luminbox紫创测控太阳光模拟器将从技术原理、性能参数、应用场景与成本效益多维…...

千问3.5-2B开源镜像部署教程:4.3GB权重免下载,24GB显存稳定运行
千问3.5-2B开源镜像部署教程:4.3GB权重免下载,24GB显存稳定运行 1. 平台介绍 千问3.5-2B是Qwen系列的小型视觉语言模型,它能够同时理解图片和生成文本。这个模型最特别的地方在于,你可以上传一张图片,然后用自然语言…...

Ostrakon-VL-8B入门必看:Python安装与环境变量配置避坑指南
Ostrakon-VL-8B入门必看:Python安装与环境变量配置避坑指南 想玩转Ostrakon-VL-8B这类强大的多模态模型,第一步就是把Python环境给搭好。很多新手朋友兴致勃勃地下载了代码,结果一运行就卡在第一步,屏幕上蹦出个“python不是内部…...

文脉定序系统Docker容器化部署与ComfyUI工作流集成
文脉定序系统Docker容器化部署与ComfyUI工作流集成 你是不是也遇到过这样的烦恼?手里有一堆文本素材,比如产品描述、用户评论或者文章草稿,想要把它们按照某种逻辑重新排列,让内容读起来更通顺、更有条理。手动整理吧,…...