Python基础教程:强大的Pandas数据分析库
Pandas是一个基于 NumPy 的非常强大的开源数据处理库,它提供了高效、灵活和丰富的数据结构和数据分析工具,当涉及到数据分析和处理时,使得数据清洗、转换、分析和可视化变得更加简单和高效。本文中,我们将学习如何使用Pandas来处理和分析数据。
首先,我们需要安装Pandas库。您可以使用以下命令来安装它:
pip install pandas
安装完成后,我们可以开始使用Pandas了。首先,让我们导入Pandas库:
import pandas as pd
 Pandas 的两个主要的数据结构是 Series 和 DataFrame。Series 是一维数组,可以存储任意类型的数据;DataFrame 是二维表格数据结构,可以看做是一系列 Series 对象的集合,每个 Series 对象代表一列数据。下面我们来学习下这两种数据结构。
Pandas 的两个主要的数据结构是 Series 和 DataFrame。Series 是一维数组,可以存储任意类型的数据;DataFrame 是二维表格数据结构,可以看做是一系列 Series 对象的集合,每个 Series 对象代表一列数据。下面我们来学习下这两种数据结构。
1.Series
Series是Pandas中的一维数据结构,类似于一维数组或列表。它可以存储任何数据类型,并且每个元素都有一个与之关联的标签,称为索引。 在创建一个 Series 时,我们可以通过指定索引来为每个元素进行命名,这样一来就可以通过索引来访问和操作这些元素。在访问 Series 中的元素时,我们同样需要使用索引来指定要访问的位置。
以下是创建Series的一个示例:
import pandas as pd
import numpy as npdata = pd.Series([1, 3, 5, np.nan, 6, 8])
# 自建索引
data = pd.Series([1, 3, 5, np.nan, 6, 8], index)
# 通过字典直接创建带索引的数据
data = pd.Series({0: 1, 1: 3, 2: 5, 3: np.nan, 4: 6, 5: 8 })
print(data)
输出结果:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
在上面的示例中,我们创建了一个包含整数和NaN值的Series。可以看到,每个元素都有一个索引。与传统的数组和列表不同,Pandas 的索引可以是任意数据类型,包括整数、字符串、日期等。索引有助于对数据进行标记和命名,使得数据的访问更加方便和直观。
在 Pandas 的 DataFrame 中,索引的作用更加重要。除了可以为每一行和每一列指定索引外,DataFrame 还支持多级索引,也就是可以为行和列同时指定多个索引。这为多维数据的处理提供了更多的灵活性和功能性。通过索引,我们可以轻松地从 DataFrame 中选择特定的行数和列数,我们可以通过指定行索引和列索引来选择任意子集的数据,也可以通过使用条件表达式来筛选满足特定条件的数据。
2.DataFrame
DataFrame是Pandas中的二维数据结构,类似于Excel表格或SQL表。它由行和列组成,并且可以存储不同类型的数据。在Pandas中,我们可以使用pd.DataFrame()函数来创建DataFrame。在这个函数中,我们可以通过参数columns来指定DataFrame的列索引,也就是字段名或列名。通过这个参数,我们可以定义每一列的名称,方便后续对数据框中的数据进行索引和操作。
如果我们想要自定义索引值,可以在pd.DataFrame()函数中使用参数index来实现。通过指定index参数,我们可以为每一行指定一个唯一的标识符,可以是字符串、整数或其他数据类型。这样一来,就可以更灵活地根据指定的索引值来获取和操作数据框中的数据。通过这种方式,我们可以根据具体的需求来定义数据框的索引,并且能够更好地满足我们对数据的处理和分析的需求。
以下是创建DataFrame的一个示例:
import pandas as pddata = {'name': ['John', 'Emma', 'Mike', 'Lisa'],'age': [28, 24, 32, 35],'city': ['New York', 'London', 'Paris', 'Tokyo']}
df = pd.DataFrame(data)
print(df)
# 通过columns指定DataFrame的列索引
data = [[1,'Bob', 24, 'American'],[2, 'Nancy', 23, 'Australia'],[3, 'Lili', 22, 'China'],[4, 'Leo', 27, 'M78'],[5, 'David', 24, 'moon']]
df = pd.DataFrame(data, columns=['serial', 'name', 'age', 'from',])
# 自定义索引
df = pd.DataFrame(data, columns=['serial', 'name', 'age', 'from'], index=['a','b','c','d','e'])print(df)
输出结果:
name age city
0 John 28 New York
1 Emma 24 London
2 Mike 32 Paris
3 Lisa 35 Tokyoserial name age from
a 1 Bob 24 American
b 2 Nancy 23 Australia
c 3 Lili 22 China
d 4 Leo 27 M78
e 5 David 24 moon
在上面的示例中,我们使用一个字典来创建DataFrame。字典的键是列名,而字典的值是该列的数据。同样地,我们也使用了列表来创建data,这个嵌套列表中每一个子列表为 DataFrame 的一行,是不是和我们创建上面Series有点异曲同工?实际上, DataFrame 的每一行或者每一列都可以看作一个 Series。 接下来,让我们看一些常用的数据操作和分析技巧。
3. 数据操作
3.1 选择和过滤
Pandas提供了多种方法来选择和过滤数据。以下是一些常用的方法:
#选择列:可以使用列名或列索引来选择列。
df['name']
#选择行:可以使用行索引来选择行。
df.loc['a']
#过滤行:可以使用条件表达式来过滤行。
df[df['age'] > 30]
# 切片方式访问
print(df.iloc[1:3]) # 访问第二行到第三行数据
输出的结果如下:
a Bob
b Nancy
c Lili
d Leo
e David
Name: name, dtype: objectserial 1
name Bob
age 24
from American
Name: a, dtype: objectserial name age from
a 1 Bob 24 American
d 4 Leo 27 M78
e 5 David 24 moonserial name age from
b 2 Nancy 23 Australia
c 3 Lili 22 China
3.2 数据排序
Pandas提供了排序数据的功能。以下是一个示例:
df = df.sort_values(by='age', ascending=False)
print(df)
在上面的示例中,我们按照年龄列对数据进行降序排序。输出结果如下:
serial name age from
d 4 Leo 27 M78
a 1 Bob 24 American
e 5 David 24 moon
b 2 Nancy 23 Australia
c 3 Lili 22 China
3.3 数据聚合
Pandas提供了聚合数据的功能。假设我们上述的示例中增加一个为年级(grade),
data = [[1,'Bob', 24, 'American', 'high-school'],[2, 'Nancy', 23, 'Australia', 'college'],[3, 'Lili', 22, 'China', 'college'],[4, 'Leo', 27, 'M78', 'university'],[5, 'David', 24, 'moon', 'high-school']]df = pd.DataFrame(data, columns=['serial', 'name', 'age', 'from', 'grade'], index=['a','b','c','d','e'])
# 聚合,按grade分组,并计算分组后的平均年龄
xdf = df.groupby('grade')['age'].mean()
print(xdf)
输出结果如下:
grade
college 22.5
high-school 24.0
university 27.0
Name: age, dtype: float64
在上面的示例中,我们按照年级列对数据进行分组,并计算每个年级的平均年龄。
3.4 数据可视化
Pandas还提供了数据可视化的功能。以下是一个示例:
# 此处需引入matplotlib
import matplotlib.pyplot as plotdf.plot(kind='bar', x='name', y='age')
plot.show() # 显示图像
在上面的示例中,我们使用柱状图来可视化姓名和年龄数据。这只是Pandas的一小部分功能。它还提供了许多其他功能,如数据清洗、缺失值处理、数据合并、数据透视表等。

4.一些高级用法
4.1 多级索引
Pandas的多级索引功能非常强大,它允许我们在一个DataFrame中创建复杂的层次结构索引,从而更灵活地组织和分析数据。一个常见的应用场景是使用多级索引来表示时间序列数据,比如将年份和季度作为索引的两个层级。
通过创建多级索引,我们可以将数据按照不同的层级进行划分和聚合。例如,我们可以根据年份来对数据进行分组,然后在每个年份内再按照季度进行分组。这样,我们可以更方便地进行各种统计分析,比如计算每个季度的平均值、总和等。
import pandas as pd# 创建多级索引
index = pd.MultiIndex.from_tuples([('2019', 'Q1'), ('2019', 'Q2'), ('2020', 'Q1'), ('2020', 'Q2')])
data = pd.DataFrame({'Sales': [100, 200, 150, 250]}, index=index)
# 查询特定季度的销售数据
print(data.loc[('2020', 'Q1')])
# 查询特定年份的销售数据
print(data.loc['2020'])
输出结果如下:
Sales 150
Name: (2020, Q1), dtype: int64Sales
Q1 150
Q2 250
在创建多级索引时,我们可以使用Pandas的MultiIndex类来指定索引的层级和标签。通过指定层级的名称和对应的标签值,我们可以轻松地创建一个具有多级索引的DataFrame。
使用多级索引可以带来很多好处,比如提高数据的查询效率、简化数据的操作和分析等。但同时,也需要注意在使用多级索引时,要避免索引混淆和数据结构复杂度过高的问题。因此,在使用多级索引时,需要根据具体的需求和数据特点来灵活应用。
4.2 透视表
透视表是一种根据数据中的一个或多个列创建汇总表格的方法。Pandas提供了pivot_table函数,可以方便地对数据进行聚合和分析。 通过pivot_table函数,我们可以指定一个或多个列作为行索引,另一个或多个列作为列索引,然后根据指定的聚合函数对数据进行汇总。这样,我们就可以快速计算出各个行和列对应的统计量,比如平均值、总和、计数等。
import pandas as pd# 创建一个包含销售数据的DataFrame
data = pd.DataFrame({'Year': ['2019', '2019', '2020', '2020'],'Quarter': ['Q1', 'Q2', 'Q1', 'Q2'],'Product': ['A', 'B', 'A', 'B'],'Sales': [100, 200, 150, 250]})
# 创建透视表
pivot_table = data.pivot_table(index='Year', columns='Quarter', values='Sales', aggfunc='sum')
# 打印透视表
print(pivot_table)
输出如下:
Quarter Q1 Q2
Year
2019 100 200
2020 150 250
Pandas的透视表功能为我们提供了一种方便、灵活的数据聚合和分析方法,可以帮助我们更好地理解和利用数据。透视表的好处在于它提供了一种直观、简洁的方式来查看和分析数据。通过透视表,我们可以轻松地对数据进行切片、切块和筛选,从而更深入地了解数据的特征和关系。
使用透视表时,我们可以根据具体的需求选择合适的聚合函数、行列索引和筛选条件,以获取我们想要的分析结果。透视表不仅适用于单个DataFrame,还可以用于多个DataFrame的合并和分析。
4.3 时间序列分析
在处理时间序列数据方面,Pandas提供了灵活且高效的功能。它的日期和时间处理功能包括日期范围生成、日期索引、日期加减运算、日期格式化等。你可以轻松地创建日期范围,并使用这些日期作为数据的索引,便于对时间序列数据进行操作和分析。
Pandas还支持重采样操作,可以将时间序列数据从一个频率转换为另一个频率。例如,你可以将按天采样的数据转换为按月采样的数据,或者将按小时采样的数据转换为按分钟采样的数据。重采样功能允许你根据需要灵活地调整数据的粒度和频率。
import pandas as pd# 创建一个包含时间序列数据的DataFramedata = pd.DataFrame({'Date': pd.date_range(start='2020-01-01', periods=10),'Sales': [100, 200, 150, 250, 180, 120, 300, 350, 400, 250]})# 将日期列设置为索引data.set_index('Date', inplace=True)
# 计算每周销售总额weekly_sales = data.resample('W').sum()
# 打印每周销售总额print(weekly_sales)
输出结果如下:
Sales
Date
2020-01-05 880
2020-01-12 1420
此外,Pandas提供了滑动窗口操作,可以在时间序列数据上执行滑动窗口统计计算。你可以定义窗口的大小和滑动的步长,并针对窗口内的数据进行汇总、聚合或其他计算操作。这对于处理时间序列数据中的移动平均值、滚动求和等任务非常有用。
5. Pandas处理Excel文件
当使用Pandas处理Excel文件时,你可以使用read_excel()函数来读取Excel数据,并将其加载到一个DataFrame中。下面是一个简单的示例:
import pandas as pd# 读取Excel文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 显示DataFrame的前几行数据
print(df.head())
在这个例子中,我们假设存在一个名为"data.xlsx"的Excel文件,其中包含一个名为"Sheet1"的工作表。通过调用read_excel()函数,我们将这个Excel文件读取并加载到名为df的DataFrame中。然后,我们使用head()方法显示DataFrame的前几行数据。
接下来,我们可以对读取的数据进行各种操作和处理。下面是一些常见的操作示例:
python
复制代码
# 筛选特定列数据
selected_columns = ['Name', 'Age']
filtered_data = df[selected_columns]# 按条件筛选数据
condition = df['Age'] > 25
filtered_data = df[condition]# 数据排序
sorted_data = df.sort_values(by='Age', ascending=False)# 添加新列
df['Gender'] = ['Male', 'Female', 'Male', 'Female', 'Male']# 写入到新的Excel文件
df.to_excel('new_data.xlsx', index=False)
在上述示例中,我们展示了一些常见的操作。例如,我们筛选了特定列的数据、根据条件筛选数据、对数据进行排序,并在DataFrame中添加了新的列。最后,我们使用to_excel()方法将处理后的数据写入到一个名为"new_data.xlsx"的新Excel文件中。
这只是Pandas处理Excel文件的一小部分功能示例。Pandas提供了更多强大且灵活的功能,可以帮助你根据具体需求对Excel数据进行处理、清洗和分析。
5. 总结
本文这些示例只是Pandas应用的一小部分,只是为了使我们在学习中对Pandas有初步的了解。Pandas还提供了许多其他强大的功能,使数据分析和处理更加便捷。下面是一些扩展的Pandas功能:
- 合并数据:Pandas提供了多种方法来合并不同的数据集,例如使用
merge()函数按照指定的列将多个DataFrame进行合并,使用concat()函数沿着指定轴将多个DataFrame堆叠在一起,以及使用join()函数根据索引或列的值进行连接。 - 拆分数据:你可以使用
split()函数将包含多个值的单个列拆分成多个列,从而使数据更加规整和易于处理。 - 过滤数据:Pandas提供了各种方法来筛选和过滤数据,如使用布尔条件进行行过滤,使用
filter()函数根据列名进行列过滤,以及使用query()函数根据指定条件查询数据。 - 处理缺失值:在现实数据中,经常会出现缺失值问题。Pandas提供了灵活的方法来处理缺失值,如使用
isnull()和notnull()函数检测缺失值,使用dropna()函数删除包含缺失值的行或列,以及使用fillna()函数填充缺失值。 - 处理字符串:如果你需要对文本数据进行处理,Pandas提供了一系列处理字符串的方法,如使用
str.contains()函数检测包含特定子串的值,使用str.replace()函数替换字符串,以及使用str.extract()函数提取符合指定模式的字符串。
上一篇教程:Python基础教程:Matplotlib图形绘制
除了上述功能,Pandas还支持数据透视表、时间序列分析、数据可视化等高级功能。如果你想深入学习和掌握这些功能,可以查阅[Pandas官方文档](pandas - Python Data Analysis Library (pydata.org)),也可以参考一些专门针对Pandas的书籍和在线教程:如Pandas中文网。后续教程中,也会深入讲解Pandas的使用。
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
Python全套学习资料

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


5️⃣Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。

上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓

相关文章:
Python基础教程:强大的Pandas数据分析库
Pandas是一个基于 NumPy 的非常强大的开源数据处理库,它提供了高效、灵活和丰富的数据结构和数据分析工具,当涉及到数据分析和处理时,使得数据清洗、转换、分析和可视化变得更加简单和高效。本文中,我们将学习如何使用Pandas来处理…...

【深入剖析K8s】容器技术基础(一):从进程开始说起
容器其实是一种特殊的进程而已。 可执行镜像 为了能够让这些代码正常运行’我们往往还要给它提供数据’比如我们这个加法程序所需要的输人文件这些数据加上代码本身的二进制文件放在磁盘上’就是我们平常所说的一个程序,也叫代码的可执行镜像(executablejmage&…...
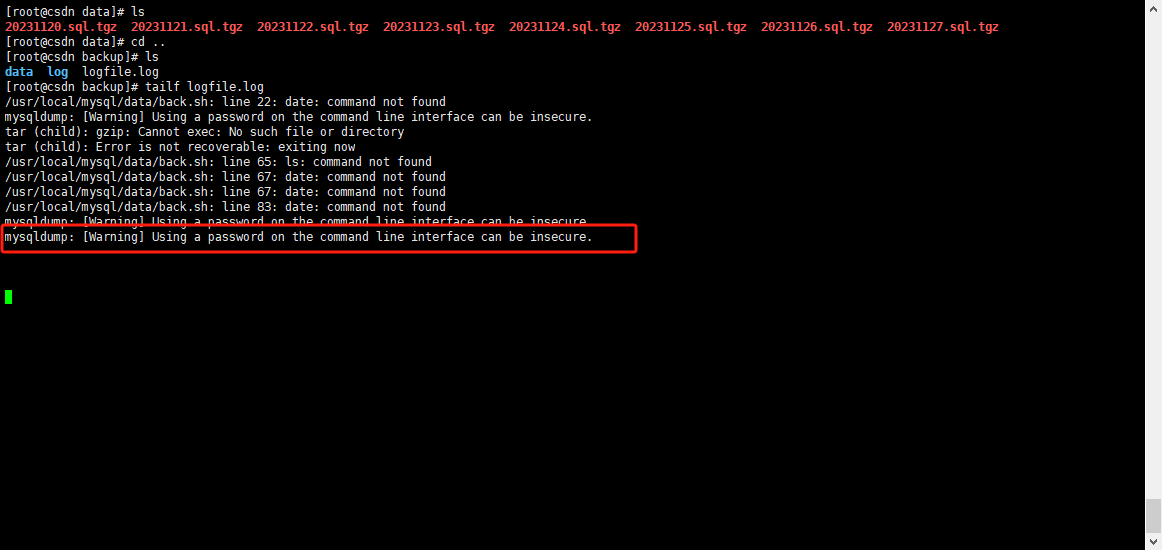
Mysql使用周期性计划任务定时备份,发现备份的文件都是空的?为什么?如何解决?
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...
)
算法leetcode|90. 子集 II(rust重拳出击)
文章目录 90. 子集 II:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 90. 子集 II: 给你一个整数数组 nums ,其…...

git 泄露
得到flag有两种方法: 1、版本比对:git diff 用法:git diff <分支名1> <分支名2> 2、版本回退:git reset 用法:git reset --hard <分支名> python2 GitHack.py http://www.example.com/.git/ g…...
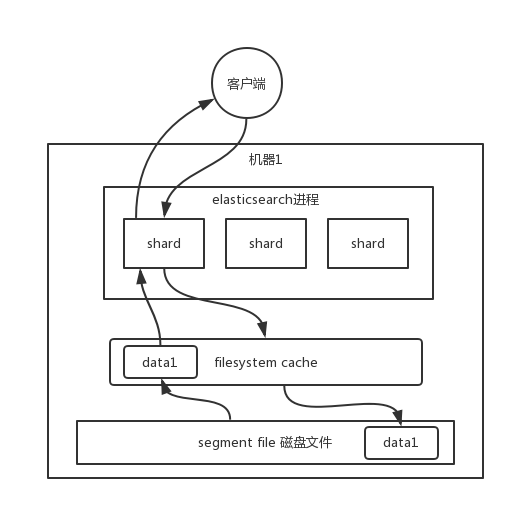
Elasticsearch知识
目录 Elasticsearch逻辑设计和物理设计 逻辑设计物理设计Elasticsearch原理 倒排索引文档的分析过程保存文档搜索文档写数据的底层原理 数据刷新(fresh)事务日志的写入ES在大数据量下的性能优化 文件系统缓存优化数据预热文档(Document&…...

极智芯 | 解读国产AI算力天数智芯产品矩阵
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文分享一下 解读国产AI算力天数智芯产品矩阵。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 天数智芯属于国产 GPGPU 阵…...

使用 OpenCV 发现圆角矩形的轮廓
OpenCV - 如何找到圆角矩形的矩形轮廓? 问题: 在图像中,我试图找到矩形对象的圆角轮廓。然而,我对两者的尝试 HoughLinesP 并 findContours 没有产生预期的结果。 我的目标是找到一个类似于以下形状的矩形: 。 代码: import cv2 import matplotlib.pyplot as plt…...
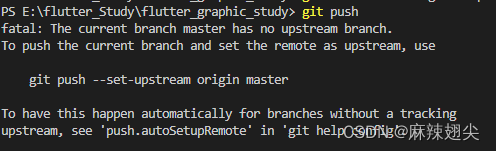
vscode项目推送到git
1、打开项目文件 打开文件后点击vs code左侧工具栏中第三个源代码管理图标,点击初始化仓库,此时会创建一个本地仓库会检查该项目中的文件变更 2、创建远程仓库 点击克隆/下载,复制HTTPS地址 3、添加远程地址 1)图形化操作 2…...

COMP2121 Discrete Mathematics
COMP2121 Discrete Mathematics 需要可WeChat: zh6-86...

【随笔记录】VMware搭建python开发环境
Vmware虚拟机总是连接不到网络。 环境为:笔记本WLAN 解决方法。 1.直接使用VMware 编辑->虚拟网络编辑器->恢复默认设置。 2.取消网卡的IP的dhcp获取,改为static。网关为提供IP的主机的网络IP(NAT模式) 3.windows打开共享网…...

基于C++实现水仙花数
1、水仙花数的连营 1.1、水仙花数 在学习程序设计课程时,大多数读者一定采用循环结构编写过求解水仙花数的程序。 【实例 1-1】水仙花数 一个三位整数(100~999),若各位数的立方和等于该数自身,则称其为“…...

关于一个类中引用两外一个类中的变量和方法,一个技巧可以提高开发效率
import static com.xx.xx.util.ext.xx.toJson; import static com.xx.xx.util.ext.smf.Cert.certMgrClient; 第一个引用一个方法,第二个引用一个变量, 引用后就可以直接通过变量名或者方法名就行使用,很方便,不要通过class.方式调…...
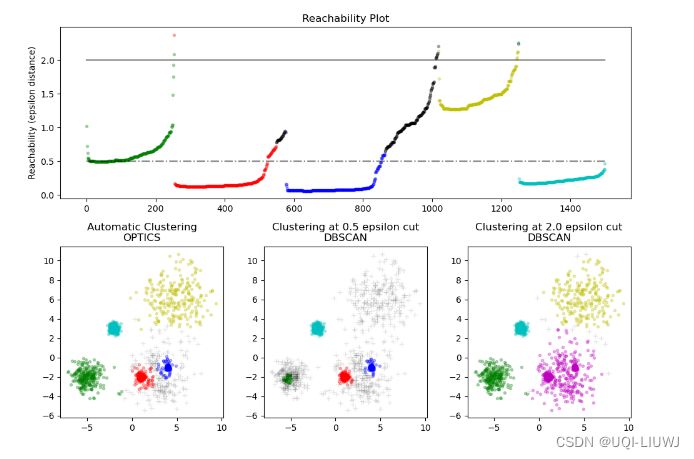
算法笔记:OPTICS 聚类
1 基本介绍 OPTICS(Ordering points to identify the clustering structure)是一基于密度的聚类算法 OPTICS算法是DBSCAN的改进版本 在DBCSAN算法中需要输入两个参数: ϵ 和 MinPts ,选择不同的参数会导致最终聚类的结果千差万别,因此DBCSAN…...
SSRF漏洞防御:黑白名单的编写
文章目录 SSRF漏洞防御:黑白名单的编写黑名单的制作白名单的制作 SSRF漏洞防御:黑白名单的编写 以pikachu靶场中SSRF(crul)为例我们可以看到未做任何防御 我们查看源代码 黑名单的制作 思路: 什么内容不能访问 构造代码 $xyarray("file" > "",&q…...

想要对网站进行安全监测,安全SCDN效果怎么样?
随着互联网的迅速成长,各种网站出现的越来越多,个人网站、企业网站等,同时网站竞争也越来越强。随着用户对网站需求增多,对网站的安全也愈发受到人们的重视。那么我们日常网站运营中,有需要对网站进行安全监控…...

操作符extends的作用是什么?
在TypeScript中,extends关键字用于创建类之间的继承关系。它允许一个类(子类)继承另一个类(父类)的属性和方法,并可以在子类中添加新的属性和方法或者修改继承自父类的属性和方法。 extends的作用是实现类…...
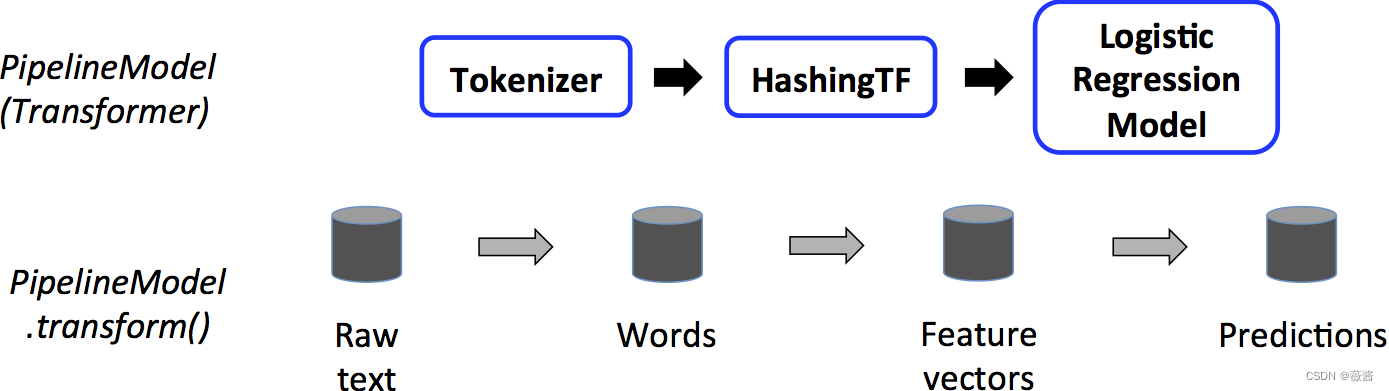
跟着chatgpt一起学|1.spark入门之MLLib
chatgpt在这一章表现的不好,所以我主要用它来帮我翻译文章提炼信息 1.前言 首先找到spark官网里关于MLLib的链接 spark内一共有2种支持机器学习的包, 一种是spark.ml,基于DataFrame的,也是目前主流的 另一种则是spark.mllib,是基于RDD的…...

JAVA后端开发技术报告
JAVA后端开发技术报告 一、引言 随着互联网技术的不断发展,JAVA作为一门成熟的后端开发语言,应用范围广泛。本报告旨在介绍JAVA后端开发的相关技术,包括JAVA语言基础、Spring框架、数据库技术以及性能优化等方面,帮助开发者更好…...

销售心理学 如何了解客户的购买心理激发客户购买兴趣
销售心理学 如何了解客户的购买心理激发客户购买兴趣 在销售的世界里,掌握客户的购买心理,如同一把神奇的钥匙,能够解锁客户内心的需求和兴趣。如何巧妙地运用销售心理学,激发客户的购买欲望呢?以下是一些建议&#x…...

AI论文写作软件哪个好?实测8款AI论文生成工具,轻松完成论文创作!
论文写作是不是让你头疼?文献查找难、框架搭建慢、内容原创性低、格式不规范…别担心!其实有捷径可走——AI论文写作工具能帮你系统解决这些痛点。本文实测8款热门AI论文写作工具,帮你找到最适合的学术助手。 本文将围绕不同学习阶段…...

GCViewer扩展开发终极指南:自定义数据读取器与导出格式的完整教程
GCViewer扩展开发终极指南:自定义数据读取器与导出格式的完整教程 【免费下载链接】GCViewer Fork of tagtraum industries GCViewer. Tagtraum stopped development in 2008, I aim to improve support for Suns / Oracles java 1.6 garbage collector logs (inclu…...

Packr 跨平台打包最佳实践:Windows、Linux、macOS 全攻略
Packr 跨平台打包最佳实践:Windows、Linux、macOS 全攻略 【免费下载链接】packr Packages your JAR, assets and a JVM for distribution on Windows, Linux and Mac OS X 项目地址: https://gitcode.com/gh_mirrors/pac/packr Packr 是一款强大的跨平台打包…...
)
Shell变量与环境变量(自定义配置,灵活复用)
在Linux/Unix Shell编程与日常运维中,变量是贯穿始终的核心工具——它就像一个可自定义的“数据容器”,能存储文本、数字、路径等各类信息,通过灵活配置实现代码复用、环境统一,大幅提升操作效率与脚本可维护性。很多新手容易混淆…...

一文搞懂 Cookie、Session 和 Token 的区别
背景 在 Web 应用中,HTTP 是无状态协议,服务器无法自动识别用户身份。为了实现用户登录状态的保持与身份认证,需要引入 Cookie、Session 和 Token 等机制来在多次请求之间维持用户状态 Cookie Cookie 是存储在客户端(浏览器&#…...

别再手动切换主从了!用Patroni+etcd给PostgreSQL 15上个自动故障转移的保险
告别手动切换时代:用Patronietcd构建PostgreSQL 15全自动高可用架构 凌晨三点,数据库告警短信惊醒梦中人——主库响应超时。你揉着惺忪睡眼打开终端,却发现从库早已自动接管业务流量,应用连接池平稳如常。这不是科幻场景ÿ…...

PHP支付配置安全加固指南:从SSL证书到PCI DSS合规,7步实现生产环境零漏洞上线
第一章:PHP支付配置安全加固的核心原则与风险全景在现代Web应用中,PHP支付模块常因配置疏忽成为攻击者突破口。密钥硬编码、环境变量泄露、未校验回调签名、调试模式残留等隐患,极易导致资金盗刷、订单篡改或敏感信息外泄。安全加固并非仅依赖…...

3步彻底清除Windows系统OneDrive残留:专业卸载方案深度解析
3步彻底清除Windows系统OneDrive残留:专业卸载方案深度解析 【免费下载链接】OneDrive-Uninstaller Batch script to completely uninstall OneDrive in Windows 10 项目地址: https://gitcode.com/gh_mirrors/on/OneDrive-Uninstaller 你是否发现OneDrive在…...

7脚 LED数码屏的刷新显示,乱码请指正
我是新手近段时间的工作是点亮7脚LED数码屏,刷新时遇到了困惑请大家帮助指正,在此表示非常感谢。 下面是7脚LED数码屏结构图。 用了7个 case下面是刷新代码switch(ScanPinNum){// ---------------- CASE1: PIN1------------------------case 1: …...
