FLASK博客系列7——我要插入数据库
我们来继续上次的内容,实现将数据插入数据库。
我们先更改下models.py,由于上次笔误,把外键关联写错了。在这里给大家说声抱歉。不过竟然没有小伙伴发现。
models.py
from app import dbclass User(db.Model): # 表名将会是 user(自动生成,小写处理)id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 主键name = db.Column(db.String(20)) # 用户名# 给这个article模型添加一个author属性(关系表),User为要连接的表,backref为定义反向引用# lazy表示禁止自动查询,后面可以直接操作这个对象。只可以用在一对多和多对多关系中,不可以用在一对一和多对一中articles = db.relationship('Article', backref=db.backref('user'), lazy='dynamic')class Article(db.Model):# 也可以自定义表名__tablename__ = 'article'# id 主键 自增id = db.Column(db.Integer, primary_key=True, autoincrement=True)# 文章标题 非空title = db.Column(db.String(100), nullable=False)# 文章正文 非空content = db.Column(db.Text, nullable=False)# 关联表,这里要与相关联的表的类型一致, user.id 表示关联到user表下的id字段author_id = db.Column(db.Integer, db.ForeignKey('user.id'))
接着我们在根目录下创建一个scripts文件夹,用来存放我们一些脚本文件。在scripts文件夹下新建一个insert_sql.py,用来插入测试数据。
insert_sql.py
from app import db
from models import User, Articledef insert_data():username = "clannadhh"articles =[{"title": "石正丽新研究:需持续监控蝙蝠", "detail": "石正丽新研究:需持续监控蝙蝠"},{"title": "建议增设火车青年票", "detail": "建议增设火车青年票"},{"title": "审议现场人大代表张伯礼哭了", "detail": "审议现场人大代表张伯礼哭了"},{"title": "31省区市首次确诊病例0新增", "detail": "31省区市首次确诊病例0新增"},{"title": "世界首个新冠疫苗人体临床数据", "detail": "世界首个新冠疫苗人体临床数据"},]# 新建一个用户user = User(name=username)db.session.add(user)# 提交db.session.commit()# 从测试数据中添加文章。for article in articles:article_post = Article(author_id=user.id, title=article['title'], content=article['detail'], )db.session.add(article_post)# 提交db.session.commit()if __name__ == '__main__':insert_data()
然后我们运行 python insert_sql.py ,测试数据来源于我们上节课的内容。
我们查看下article表,可以看到数据已经插入了。
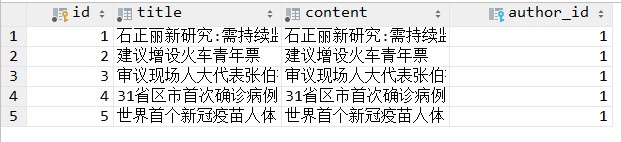
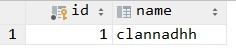
我们接着看下user表。可以看到新增了一个用户clannadhh。
我们再更改下app.py
import osfrom flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy # 导入扩展类import modelsbasedir = os.path.abspath(os.path.dirname(__file__))app = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'blog.db')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = Falsedb = SQLAlchemy(app) # 初始化扩展,传入程序实例 app@app.route('/')
def index():user = models.User.query.first() # 查询第一个用户,因为我们只有一个用户articles = models.Article.query.filter_by(author_id=user.id) # 根据用户ID查询文章return render_template("article/list.html",username=user.name,articles=articles)if __name__ == '__main__':app.run()
记得修改list.html。将 {{ article.detail}} 改为 {{ article.content }}。
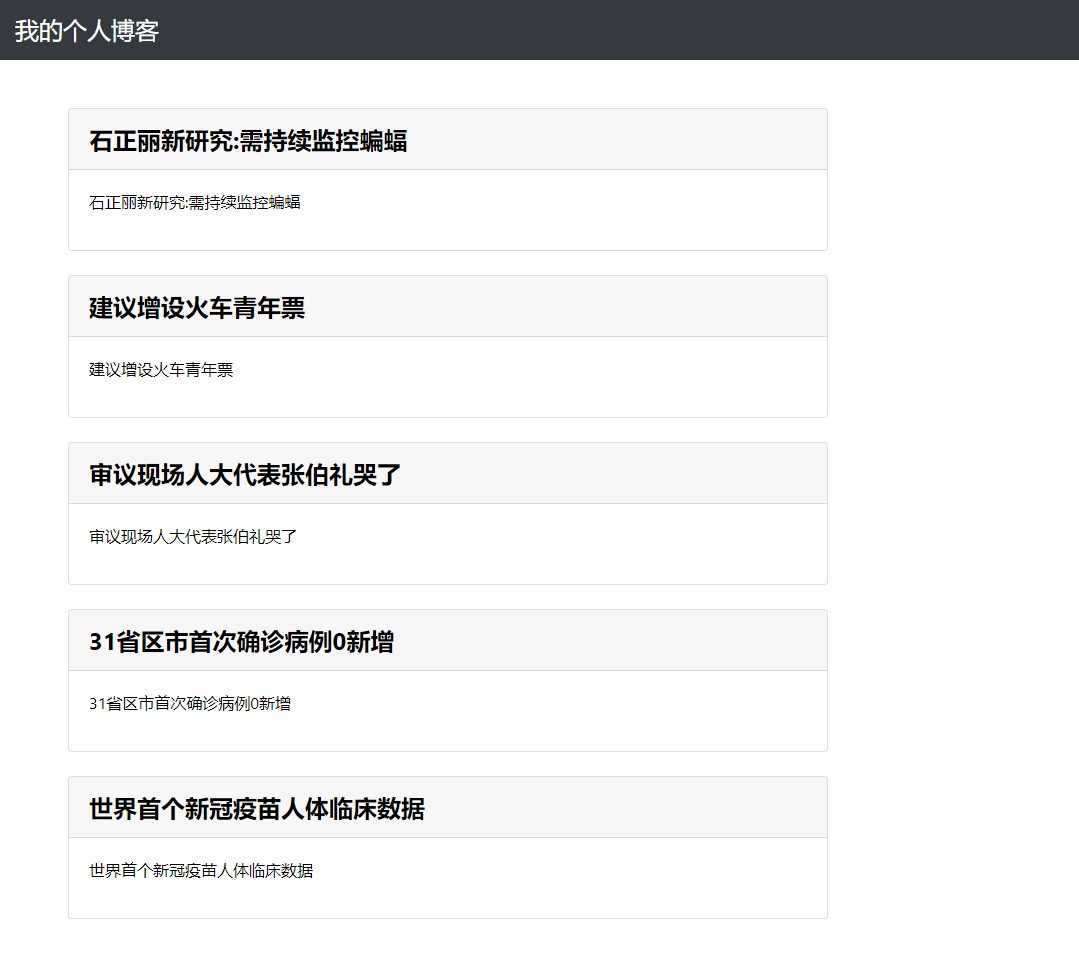
接着打开链接 http://127.0.0.1:5000。可以看到文章渲染出来了。
上面我们简单对数据库进行了操作,下面给大家送上一些基本操作的总结。
读取
>>>from models import User, Article # 导入模型类
>>>article = Article.query.first() # 获取Article模型的第一条记录
>>>article.user # 获取该文章的作者
<User 1>
>>>article.user.name # 获取该文章的作者的名字
'clannadhh'
>>>article.title # 获取文章标题
'石正丽新研究:需持续监控蝙蝠'
>>>article.content # 获取文章内容
'石正丽新研究:需持续监控蝙蝠'
>>>Article.query.all() # 查询所有的文章
[<Article 1>, <Article 2>, <Article 3>, <Article 4>, <Article 5>]
>>>Article.query.count() # 统计文章的数量
5
>>>Article.query.get(1) # 获取id为1的文章
<Article 1>
>>>Article.query.filter_by(author_id=1) # 查询用户id为1的文章
<flask_sqlalchemy.BaseQuery object at 0x000002889475BCC0>
>>>Article.query.filter_by(author_id=1).first() # 查询用户id为1的文章的第一条记录
<Article 1>
>>>Article.query.filter(Article.author_id==1).first() # 查询用户id为1的文章的第一条记录
<Article 1>下面是一些常用的过滤方法:
| 过滤方法 | 说明 |
| filter() | 使用指定的规则过滤记录,返回新产生的查询对象 |
| filter_by() | 使用指定规则过滤记录(以关键字表达式的形式),返回新产生的查询对象 |
| order_by() | 根据指定条件对记录进行排序,返回新产生的查询对象 |
| group_by() | 根据指定条件对记录进行分组,返回新产生的查询对象 |
下面是一些常用的查询方法:
| 查询方法 | 说明 |
| all() | 返回包含所有查询记录的列表 |
| first() | 返回查询的第一条记录,如果未找到,则返回None |
| get(id) | 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回None |
| count() | 返回查询结果的数量 |
| first_or_404() | 返回查询的第一条记录,如果未找到,则返回404错误响应 |
| get_or_404(id) | 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回404错误响应 |
| paginate() | 返回一个Pagination对象,可以对记录进行分页处理 |
今天的内容就到这里,想了解什么,记得给我留言。
相关文章:
FLASK博客系列7——我要插入数据库
我们来继续上次的内容,实现将数据插入数据库。 我们先更改下models.py,由于上次笔误,把外键关联写错了。在这里给大家说声抱歉。不过竟然没有小伙伴发现。 models.py from app import dbclass User(db.Model): # 表名将会是 user࿰…...
)
HarmonyOS应用开发者高级认证(题库)
判断题 每一个自定义组件都有自己的生命周期 正确Worker线程不支持UI操作 正确首选项preferences是以key-value形式存储数据,其中key是可以重复的。 错误HarmonyOS应用可以兼容OpenHarmony生态 正确使用端云一体化开发,无需自己搭建服务器 正确只要…...

软件建模与文档:架构师怎样绘制系统架构蓝图?
Java全能学习面试指南:https://javaxiaobear 首先,请你设想这样一个场景:如果公司安排你做架构师,要你在项目开发前期进行软件架构设计,你该如何开展你的工作?如何输出你的工作成果?如何确定你的…...
ChatGLM2-6B微调过程说明文档
参考文档: ChatGLM2-6B 微调(初体验) - 知乎 环境配置 下载anaconda,版本是Anaconda3-2023.03-0-Linux-x86_64.sh,其对应的python版本是3.10,试过3.7和3.11版本的在运行时都报错。 执行下面的命令安装anaconda sh Anaconda3-202…...

Django之中间件
引入 1、Django自带7个中间件,每个中间件都有各自的功能 2、django能够自定义中间件 3、使用场景: 1. 全局身份校验 2. 全局用户权限校验 3. 全局访问频率的校验 ...... 【1】什么是中间件 Django中间件是一个轻量级、可重用的组件,用于处理…...
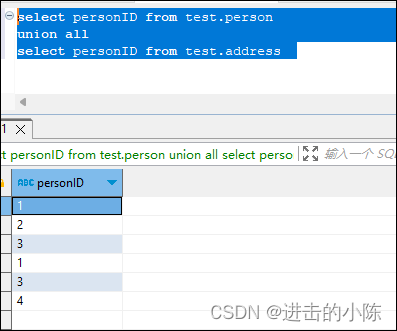
sql中的left join, right join 和inner join,union 与union all的用法
left join, right join 和inner join:这些都是SQL中用来连接两个或多个表的操作。 union,union all:用于合并两个或多个 SELECT 语句的结果。 但是有时候,对于Select出来的结果集不是很清楚。 假设我们有两张表。pers…...

Linux:strace 简介
文章目录 1. 前言2. 什么是 strace ?3. 使用 strace3.1 追踪指定进程3.1.1 通过程序名追踪进程3.1.2 通过 进程 ID (PID) 追踪程序3.1.3 追踪 子进程 或 线程 3.2 系统调用情况统计3.3 追踪过滤3.3.1 追踪指定的系统调用集合3.3.2 追踪对指定文件句柄集合操作的系统调用3.3.3 …...

【深度学习】神经网络训练过程中不收敛或者训练失败的原因
在面对模型不收敛的时候,首先要保证训练的次数够多。在训练过程中,loss并不是一直在下降,准确率一直在提升的,会有一些震荡存在。只要总体趋势是在收敛就行。若训练次数够多(一般上千次,上万次,…...

el-table修改表格每行的高度包含表头
需求: 需要修改el-table表格每行的高度为54px,并且包含表头。 .el-table {tr {height: 54px;td {padding: 0;}th {padding: 0;}} }如果样式没有生效,可能.el-table需要加上样式穿透...

常用数据存储格式介绍:Excel、CSV、JSON、XML
在现代数字时代,数据经过提炼后可以推动创新、简化运营并支持决策流程。然而,在提取数据之后,并将其加载到数据库或数据仓库之前,需要将数据转化为可用的数据存储格式。本文将介绍开发者常用的4种数据存储格式,包括 Ex…...
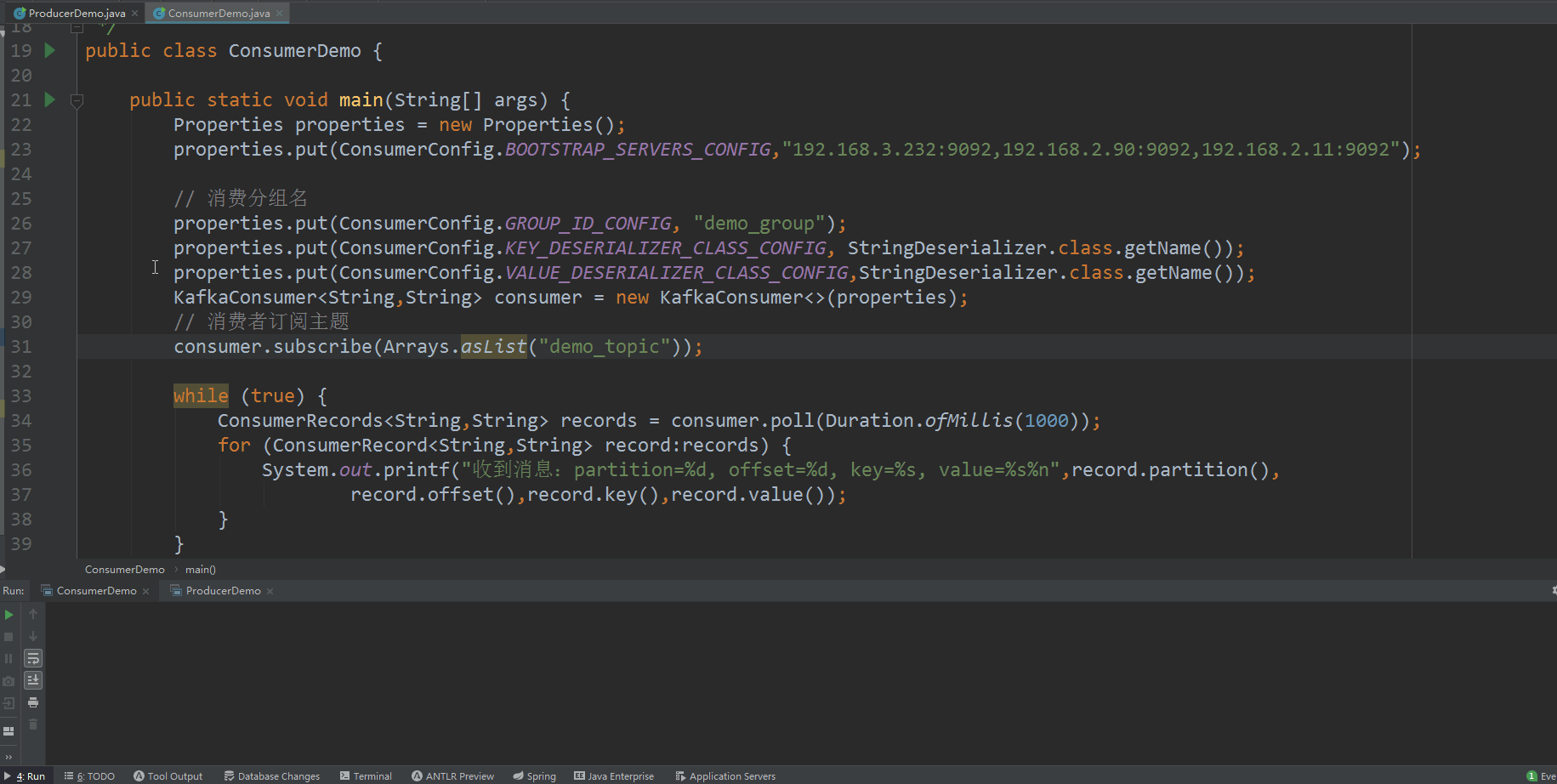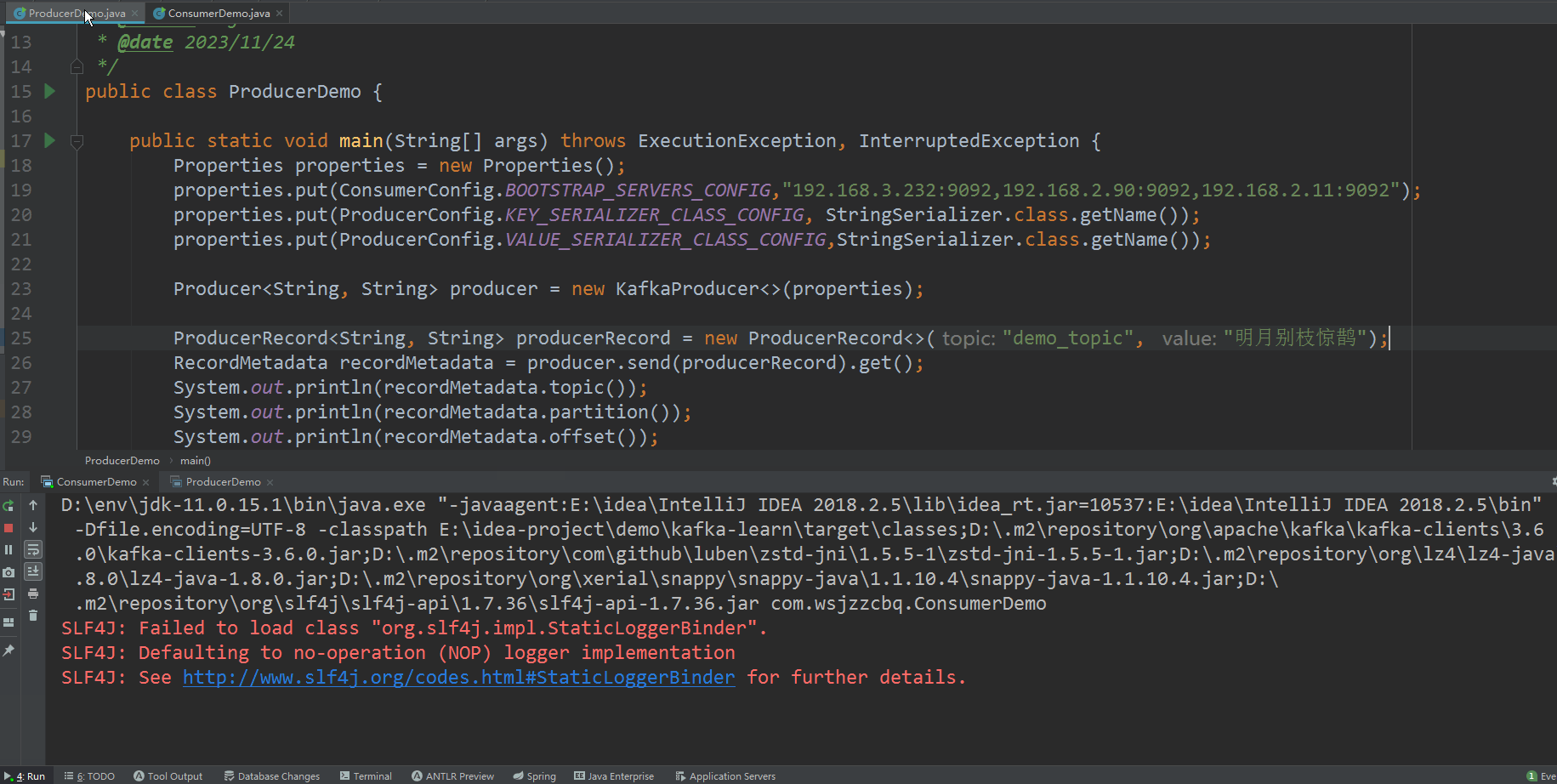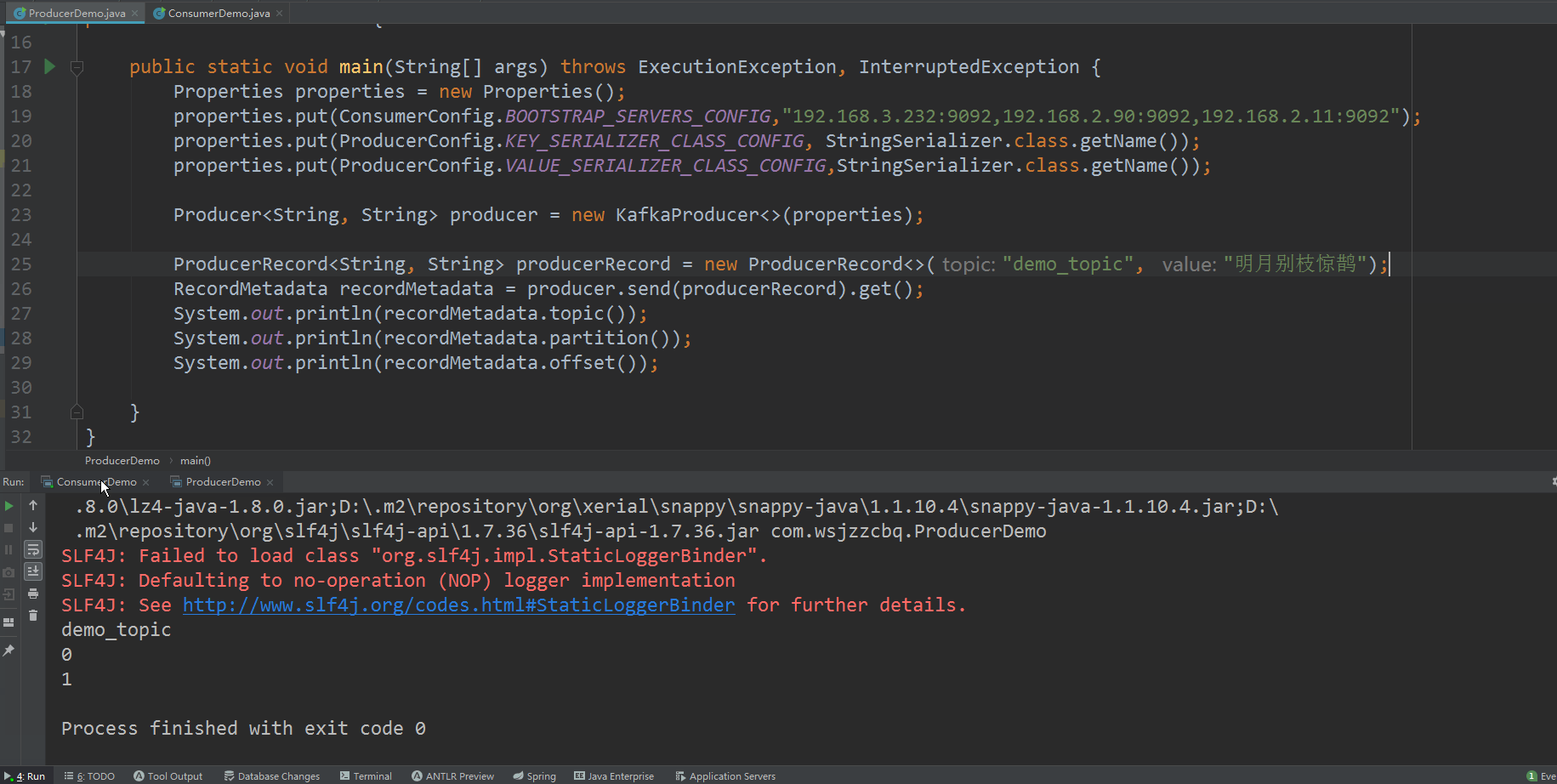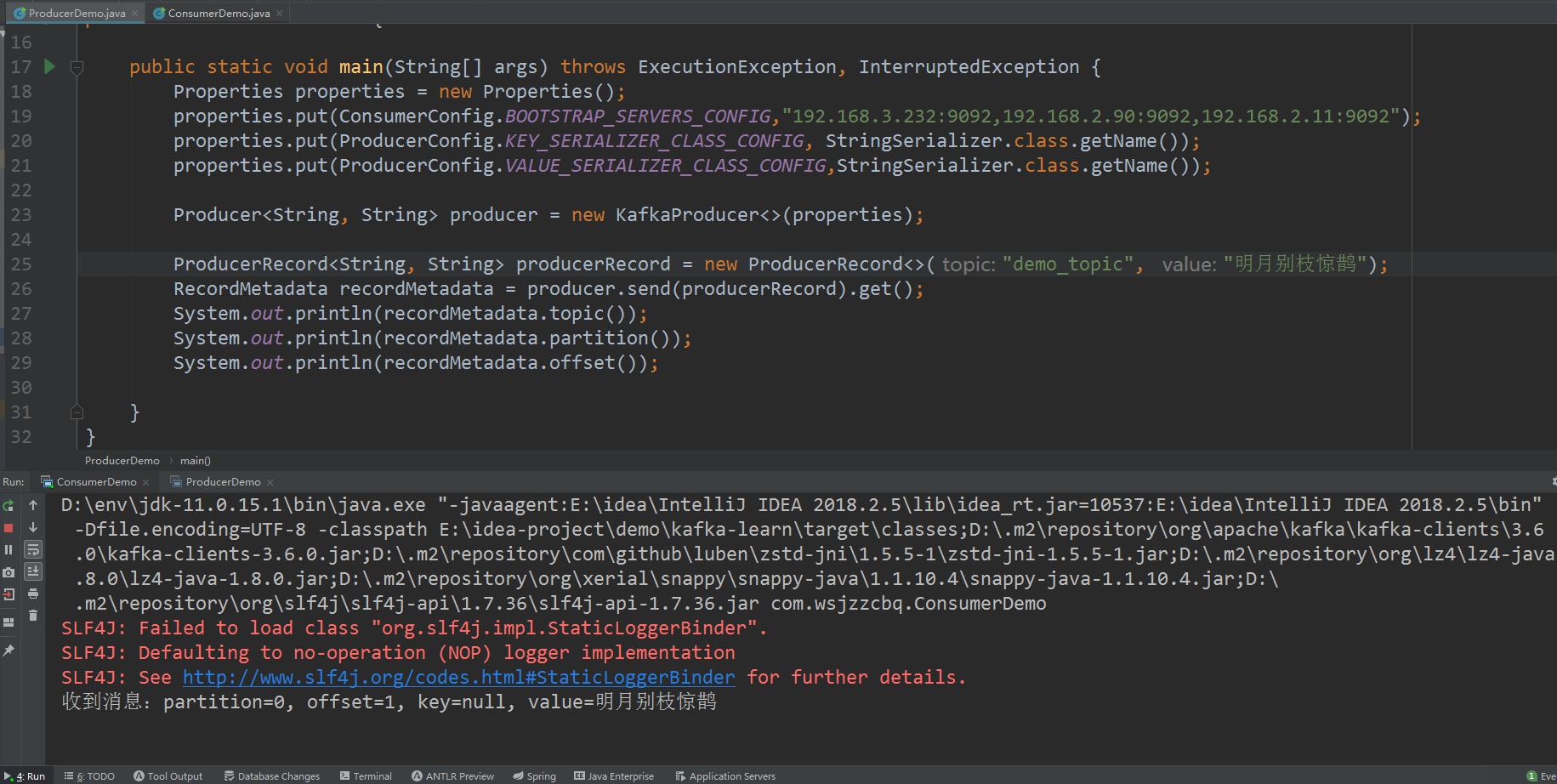
kafka 集群 KRaft 模式搭建
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序 Kafka 官网:https://kafka.apache.org/ Kafka 在2.8版本之后,移除了对Zookeeper的依赖,将依赖于ZooKeeper的控制器…...

如何进行有效的移动应用测试?
1、识别关键功能: 对于移动应用测试,首先要了解应用的需求和功能规格,确定哪些功能是最关键的。 关键功能通常是用户最常用的功能,对应用的成功和用户体验至关重要。 2、设定测试目标和用例: 针对每个关键功能,设置具体的测试目…...

飞翔的鸟小游戏
第一步是创建项目 项目名自拟 第二步创建个包名 来规范class 再创建一个包 来存储照片 如下 package game; import java.awt.*; import javax.swing.*; import javax.imageio.ImageIO;public class Bird {Image image;int x,y;int width,height;int size;double g;double t;…...

吴恩达《机器学习》10-1-10-3:决定下一步做什么、评估一个假设、模型选择和交叉验证集
一、决定下一步做什么 在机器学习的学习过程中,我们已经接触了许多不同的学习算法,逐渐深入了解了先进的机器学习技术。然而,即使在了解了这些算法的情况下,仍然存在一些差距,有些人能够高效而有力地运用这些算法&…...
)
大数据-之LibrA数据库系统告警处理(ALM-37000 MPPDBServer数据目录或Redo目录缺失)
告警解释 当出现如下情况时,产生该告警: 数据实例数据目录被删除。数据实例Redo目录(pg_xlog)被删除。 告警属性 告警ID 告警级别 可自动清除 37000 严重 是 告警参数 参数名称 参数含义 ServiceName 产生告警的服务…...
)
华为eNSP使用教程(Enterprise Network Simulation Platform,企业网络仿真平台)
文章目录 华为eNSP使用教程详解引言eNSP界面快速入门启动与初始设置主界面组成创建和管理项目 构建网络拓扑添加和连接设备配置设备参数示例:配置设备接口IP 保存配置 仿真网络功能启动与测试示例:测试网络连通性 使用调试工具 疑难技术点解析路由协议配…...

19.Spring如何处理线程并发问题?
Spring如何处理线程并发问题? 在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域,因为Spring对一些Bean中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。 ThreadLocal和线程同步机制都是为了解决多…...

Python办公神器:教你如何快速分拆、删页、合并PDF文件
哈喽大家好,我是了不起,今天教你如何用Python快速分拆、删页、合并PDF文件 介绍 有时我们可能需要对PDF文件进行一些处理,例如分拆、删页、合并等。这些操作在一些专业的PDF软件中可能比较容易实现,但是如果我们想要用Python来自…...
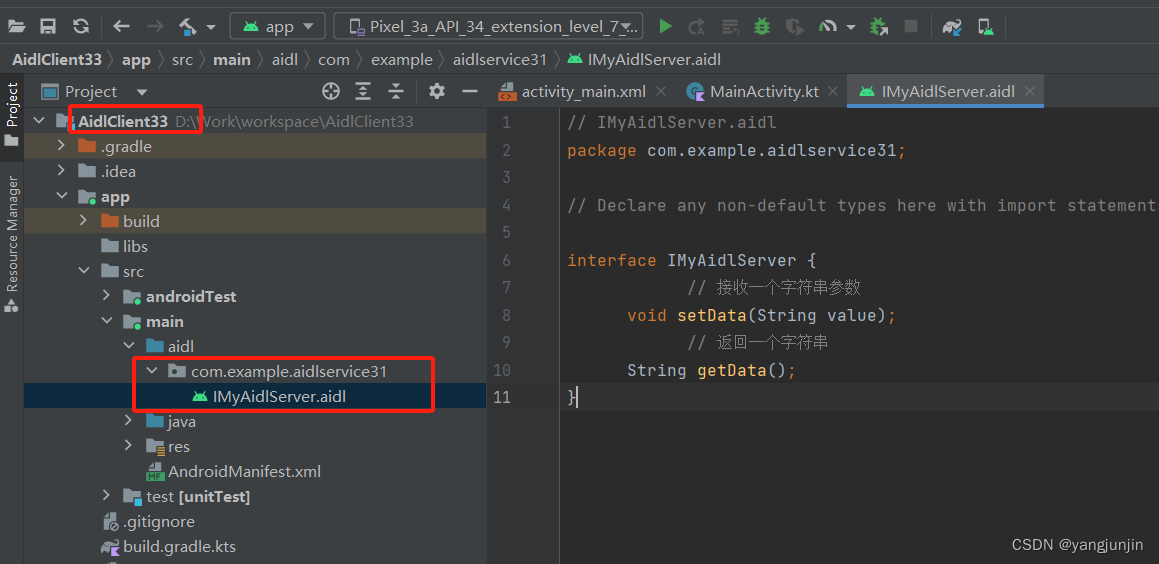
Android aidl的简单使用
一.服务端 1.创建aidl文件,然后记得build下生成java文件 package com.example.aidlservice31;// Declare any non-default types here with import statementsinterface IMyAidlServer {// 接收一个字符串参数void setData(String value);// 返回一个字符串String …...
双十一备战与复盘
如何组织备战 重要节点 从大促启动会开始后我就开始计划我们本次备战的整体节奏。 挑战在哪 以上内容介绍了CDP平台有多么重要,那么画像系统备战的核心挑战在“如何保障在大流量高并发情况下系统稳定提供高性能服务”,主要表现在:稳定性、…...

AMD Ryzen底层硬件调试:如何通过SMU Debug Tool实现处理器性能的精确控制与优化
AMD Ryzen底层硬件调试:如何通过SMU Debug Tool实现处理器性能的精确控制与优化 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table…...
)
别再只用DoHeatmap了!用pheatmap给单细胞marker基因热图加亿点细节(附完整R代码)
解锁单细胞热图高级定制:从DoHeatmap到pheatmap的工业级可视化方案 在单细胞转录组分析中,热图是展示marker基因表达模式的黄金标准工具。虽然Seurat的DoHeatmap函数提供了快速可视化的解决方案,但当我们需要发表级图表或更精细的表达模式展示…...

NCM格式解密与转换完全指南:5大核心技巧释放音频文件价值
NCM格式解密与转换完全指南:5大核心技巧释放音频文件价值 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字化音乐收藏日益普及的今天,网易云音乐的NCM加密格式成为许多音乐爱好者的困扰。ncmdump作为一款…...

HunyuanVideo-Foley 入门:Node.js环境配置与音效生成API服务封装
HunyuanVideo-Foley 入门:Node.js环境配置与音效生成API服务封装 1. 引言 想象一下,你正在开发一个视频编辑应用,需要为视频片段自动添加合适的音效。手动操作不仅耗时,还很难保证音效与画面的完美匹配。这就是HunyuanVideo-Fol…...

通义千问1.5-1.8B-Chat-GPTQ-Int4一键部署效果展示:低显存占用下的流畅对话体验
通义千问1.5-1.8B-Chat-GPTQ-Int4一键部署效果展示:低显存占用下的流畅对话体验 最近在尝试各种轻量级大模型本地部署,一个绕不开的痛点就是显存。动不动就十几GB的显存需求,让很多只有一张普通消费级显卡的朋友望而却步。正好,我…...

PLC立体车库智能仿真系统:博途V15 3×2车库模型,西门子PLC控制,触摸屏操作,自动出入...
PLC立体车库智能仿真 博途V15 32立体车库 西门子1200PLC 触摸屏仿真 不需要实物 自带人机界面 小车上下行有电梯效果 每一个程序段都有注释 FC块标准化编写 自带变频器输出也可以仿真 现在拥有自动出入仓库的功能 IO表已列出最近在搞的32立体车库仿真项目挺有意思,用…...

浏览器神器Tampermonkey:手把手教你安装和使用4款必备油猴脚本
Tampermonkey进阶指南:解锁浏览器潜能的4个实战脚本方案 每次遇到网页限制复制、强制登录、内容折叠这些烦人的设计时,我都习惯性地点开浏览器右上角那个猴子图标。作为从业十年的前端开发者,我可以负责任地说:Tampermonkey是浏览…...

论文阅读:arxiv 2026 From Assistant to Double Agent: Formalizing and Benchmarking Attacks on OpenClaw for
总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894 From Assistant to Double Agent: Formalizing and Benchmarking Attacks on OpenClaw for Personalized Local AI Agent https://arxiv.org/abs/2602.08412 该…...

Dism++终极指南:如何用这款免费工具彻底优化Windows系统
Dism终极指南:如何用这款免费工具彻底优化Windows系统 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language Dism是一款强大的Windows系统维护工具&#x…...

STM32 RTC掉电也能走时?手把手教你用VBAT和LSE晶振搭建硬件时钟电路
STM32 RTC掉电也能走时?手把手教你用VBAT和LSE晶振搭建硬件时钟电路 嵌入式系统中实时时钟(RTC)的重要性不言而喻,它不仅是记录时间的工具,更是许多关键功能的基石。想象一下,当你的智能门锁因为断电而无法…...