python小数据分析小结及算法实践集锦
在缺乏大量历史数据的新兴技术和产业中,商业分析可能会面临一些挑战。然而,有一些技术和方法可以帮助分析者在数据不充分的情况下进行科学化商业分析,并为决策提供支持。
1. 当面对缺乏大量历史数据的新兴技术和产业时所采常用的技术和方法
我们用较为熟悉的加油站为例,假如加油站是新兴商业,对新建加油站做商业分析,系统的、综合的使用科学化数据化决策技术和方法。
1.1. 小数据分析
尽管没有大量数据,但仍可以利用少量数据进行深入分析。小数据分析强调对有限数据的深入理解,可以通过精细的采样和深入的定性分析来获取有价值的见解。
- 方法: 针对少数现有加油站,收集其用户的行为数据、支付方式、用户满意度等。
- 目的: 通过深度分析小范围数据,了解用户需求、燃油消耗模式和服务体验。
1.2. 实地调研和专家意见
在新兴技术和产业中,实地调研和专家意见可能是获得信息的重要途径。通过与领域专家合作、参与行业活动以及实地考察,可以获得实时和实地的见解。
- 方法: 与城市规划者、交通专家、环保专家、汽车产业专家进行合作,以了解城市交通规划、环保政策和汽车市场发展趋势。
- 目的: 利用专业意见为新兴加油站提供更深层次的背景信息。
1.3. 原型和试错方法
采用敏捷开发和试错方法,通过快速构建原型并在实践中进行调整,以逐步完善商业模型。这种方法有助于在实践中不断学习和改进。
- 方法: 在小规模范围内建设新型加油站原型,并进行试运营。收集用户反馈,改进服务和设施。
- 目的: 通过实际运营情况验证商业模型,迅速调整并提高商业模型的可行性。
1.4. 市场调查和趋势分析
利用市场调查和趋势分析,了解相关行业的动态和发展趋势。这可以通过消费者调查、行业报告、竞争对手分析等方式实现。
- 方法: 进行市场调查,了解当地车辆数量、驾驶习惯、竞争对手情况,并分析汽车行业的发展趋势。
- 目的: 了解市场需求和趋势,为新建加油站提供市场定位和战略方向。
1.5. 模拟和建模
利用数学模型和模拟方法,尽可能还原新兴技术和产业的运作机制。这可以帮助分析者理解潜在的影响因素和变数,为决策提供参考。
- 方法: 利用数学模型模拟新型加油站的运营情况,包括车流量、销售量、收益等。
- 目的: 通过建模分析,理解加油站运营的关键因素,为经济效益提供参考。
1.6. 机器学习和预测分析:
尽管可能没有大量历史数据,但可以利用机器学习算法进行趋势分析和模型预测。这需要使用现有的有限数据,但随着时间的推移,模型可以逐步优化。
- 方法: 利用机器学习算法,分析过去加油站销售数据,预测未来的销售趋势。
- 目的: 尽管是新兴商业,但通过现有数据进行趋势预测,为制定销售策略提供参考。
1.7. 数据挖掘和开放数据:
利用开放数据、社交媒体数据等来源,进行数据挖掘,寻找与新兴技术和产业相关的信息。这可以提供额外的信息来源。
- 方法: 利用开放数据分析城市交通流量、环保指标等数据,了解城市需求。
- 目的: 通过挖掘开放数据,获取关于城市交通和环保方面的信息,为新兴加油站的服务规划提供数据支持。
1.8. 决策支持系统:
部署决策支持系统,整合分析结果和不同数据来源,为决策者提供可视化和交互式工具,帮助他们更好地理解情况并做出决策。
- 方法: 建立决策支持系统,整合实时市场数据、用户反馈、专家建议等信息。提供可视化工具帮助决策者制定战略。
- 目的: 为决策者提供一个综合平台,帮助他们更好地理解市场动态,做出基于数据的决策。
通过以上综合的商业分析方法,可以为新兴加油站的选址、建设和运营提供全面的、科学化的决策支持。这种方法能够在缺乏大量历史数据的情况下,通过不同角度的综合分析,为企业制定合理的商业战略提供科学依据。
在这个过程中,关键是采用综合性的方法,结合不同数据来源和分析手段,以获取尽可能多的信息。同时,需要在实践中不断验证和调整商业模型,以适应新兴技术和产业的不断变化。
2. 常用技术和方法的实践
2.1. 数据化决策
2.1.1. 信息量化
如何估计池塘里鱼的数目,周边有多少车辆?
发布博客 2023.11.2
如果我们想知道我们生活的区域周边有多少车辆,可否使用这样方案:我们在纵向的街道上,通过随机录像、拍照记录1000辆车牌号,下周大致相同时间,再随机记录1000辆车牌号;同样方法在横向街道,再进行一次,这样估算反映了什么呢?反映出这个街道上,周边能到此街道的车辆规模,是这样吗?
科学化决策数据分析,先从量化开始
发布博客 2023.10.30
虽然大数据说一切皆可量化,从某种意义上说,人类的偏好是量化的唯一来源。如果意味着量化是主观的,只能说明这种量化的性质就是主观的。它不是物体的物理特性,而是人对事物的权衡和看法。我们唯一要关注的问题就是:该如何量化人们的选择。
2.1.2. 商业分析常用模型
PEST、波特五力、波士顿矩阵、SWOT、价值链等战略分析方法整理学习笔记
发布博客 2020.04.17
在做信息化规划、产品设计、需求分析、商业计划书、组织机构优化管理咨询等业务活动过程中,信息收集与分析是非常重要的环节,是建立领域模型的基础。如何做好信息收集及分析工作,对于有一定经验的人员来说,可以采用自顶向下方法,参照战略分析工具指引,探索业务机理,快速建立领域管理模型。战略分析工具:PEST分析模型、波特五力模型、价值链分析、雷达图、因果关系、利益相关者分析、竞争者分析。战略选择工具:SWOT分析、波士顿矩阵、通用矩阵、V矩阵、EVA管理、定向政策矩阵、战略地位和行动评估矩阵。
2.2. 相关分析
2.2.1. 关联分析
python关联分析实践学习笔记
发布博客 2023.10.12
曾经有个沃尔玛超市,它将啤酒与尿布这样两个奇怪的东西放在一起进行销售,并且最终让啤酒与尿布这两个看起来没有关联的东西的销量双双增加。
我们关注的是在这样的场景下,如何找出物品之间的关联规则。接下来就来介绍下如何使用Apriori算法,来找到物品之间的关联规则。
2.2.2. 灰色关联分析
借助与ChatGPT对话进行灰色关联分析算法的应用分析
发布博客 2023.02.15
虽然文章内容比较长,但是,我们可以从与ChatGPT沟通过程中感觉到未来压力,是我们的良师益友,也可能是我们的竞争对手。也欢迎专业人士对ChatGPT回答予以评价。
灰色关联分析法详解及python实践
发布博客 2023.02.13
灰色关联分析主要有两个作用,一是进行系统发展影响因素分析,诊断影响系统发展的重要因素。第二个作用就是用于综合评价问题,给出研究对象或者方案的优劣排名,可用于经营管理咨询工作。由于企业经营数据偏少,大数据方法不适用,因此,我们把企业好比一个灰色系统,挖掘有限数据的价值,对可识别的指标进行分析。本文详解灰色关联分析方法,以及基于python应用实践。
2.3. 指标赋权
2.3.1. 熵值法
客观赋权熵值法多指标综合评价方法原理及python实践
发布博客 2023.09.14
熵值法是一种常用的多指标综合评价方法,它可以将多个指标的数据进行综合分析,得出一个综合评价结果。熵值法的作用非常广泛,可以应用于各种领域,如企业管理、环境评价、投资决策等。
熵值法与层次分析法(AHP)对比,是属于客观评价,而层次分析法是主观评价。除了熵值法,还可以使用主成分分析法、因子分析法等统计方法来确定权重。需要注意的是,无论使用哪种方法确定权重,都应结合实际情况和指标性质进行综合考虑,并进行敏感性分析,以确定所选择的权重是否合理可靠。
2.3.2. 模糊综合评价法
模糊层次综合分析法Python实践及相关优缺点分析
发布博客 2020.09.08 ·
模糊综合评价法(FCE)是一种根据模糊数学隶属度理论把定性评价转化为定量评价的方法,它具有结果清晰,系统性强的特点,能较好地解决模糊的、难以量化的问题,适合各种非确定性问题的解决。我们先看模糊综合评价数据表,这是专家(或其他统计方式)对评价打分表投票表决结果统计数据,简单的说就是对需要评价的因素(指标)给出主管或客观的“优、良、一般、较差、非常差”评价。这样,我们能给企业什么样的评价呢?
2.3.3. 层次分析法
AHP(层次分析法)学习笔记及多层权重Python实践
发布博客 2020.09.07
层次分析法(The analytic hierarchy process)简称AHP,它是将与决策有关的因素分解成目标、准则、方案等层次,在此基础之上进行定性和定量分析的决策方法。本文为简明AHP学习笔记,并通过Python实践构建多层权重。
2.4. 预测
卡尔曼滤波预测应用python实践
发布博客 2023.07.04
使用python,以运动位置与速度,预测短期用电量为例实践卡尔曼滤波预测应用,ChatGPT在这次实践中发挥了助手的作用,通过理解用户问题并提供相关知识和指导,帮助解释卡尔曼滤波算法的原理和步骤,给出代码实现的建议和提示,提高工作效率和准确性。
机器学习回归任务指标评价及Sklearn神经网络模型评价实践
发布博客 2023.05.12
机器学习回归模型评价是指对回归模型的性能进行评估,以便选择最佳的回归模型。其中,MAE、MSE、RMSE 用于衡量模型预测值与真实值之间的误差大小,R² 用于衡量模型对数据的拟合程度。在实际应用中,我们可以使用这些指标来评估回归模型的性能,并对模型进行优化。例如,在工业领域,回归算法可以通过对历史数据的回归分析,预测用电负荷、发电量等生产指标。
随机森林算法及贝叶斯优化调参Python实践
发布博客 2022.07.03
使用随机森林算法实验验证贝叶斯优化调参优于人工调参,代码使用Python实践。
参数优化基本思想是基于数据使用贝叶斯定理估计目标函数的后验分布,然后再根据分布选择下一个采样的超参数组合。它充分利用了前一个采样点的信息,其优化的工作方式是通过对目标函数形状的学习,并找到使结果向全局最大提升的参数。
蒙特卡罗方法(Monte Carlo method)
发布博客 2014.03.27
蒙特卡罗方法又称统计模拟法、随机抽样技术,是一种随机模拟方法,以概率和统计理论方法为基础的一种计算方法,是使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。将所求解的问题同一定的概率模型相联系,用电子计算机实现统计模拟或抽样,以获得问题的近似解。为象征性地表明这一方法的概率统计特征,故借用赌城蒙特卡罗命名。
2.5. 时序预测
Prophet算法框架趋势模型、季节模型原理详解与应用实践
发布博客 2023.06.30 ·
本文是在ChatGPT协助下,分析了Prophet算法框架趋势模型、季节模型原理,并展开了应用实践。
Prophet算法框架预测输出及使用方法
发布博客 2023.06.27 ·
本文介绍并分析prophet预测输出数据内容。
Prophet 时间序列预测框架入门实践笔记
发布博客 2023.06.26
Prophet是Facebook开源的一种时间序列预测框架,旨在使时间序列分析更加容易和快速。Prophet可以处理具有多个季节性和突发事件的时间序列数据,并且在数据缺失或异常情况下仍然能够进行良好的预测。
时间序列分析ARMA模型原理及Python statsmodels实践(下)
发布博客 2022.10.11
本文是系统整理基于ARMA模型预测销量实践过程,归纳时间序列及相关基本概念、ARMA模型及其建模过程,本篇是模型原理及相关基础概念的后续内容,重点是代码实现及分析。
·
时间序列分析ARMA模型原理及Python statsmodels实践(上)
发布博客 2022.10.05
本文是系统整理基于ARMA模型预测销量实践过程,归纳时间序列及相关基本概念、ARMA模型及其建模过程,本篇重点是模型原理及相关基础概念,代码实现及分析详见下篇。
2.6. 因果分析
【精选】Ylearn因果推断入门实践——Kaggle银行客户流失
发布博客 2022.11.05 ·
增加因果推断研究客户流失,这是我使用开源YLearn的因果推断入门第一个实践,按开源给的案例学习研究,代码简单内涵丰富,思维也要由相关关系转换到因果关系。
大数据因果推理与学习入门综合概述
发布博客 2022.10.29
从大数据相关关系趋势预测思维,增强加入大数据因果推理思维的入门学习内容分享,认清因果关系和因果效应估计,初步了解因果推理过程,最终提高大数据决策能力。
2.7. 聚合分析
无监督学习——聚类(clustering)算法应用初探
发布博客 2019.04.15
我们在实际工作中,使用当前信息化资产——历史生产数据进行大数据人工智能研发工作,通过深度学习,虽然取得很好的结果,不过还有专家对此有疑虑,例如数据准确性问题,物联网采集的数据“异常”情况、人工分类失误为数据打上错误的标签等等,对于这些问题,我引入了聚类算法,用以区分正常数据、不正常数据。本文通过实践,重点描述DBSCAN算法的应用,以及效果,对比Birch和K-Means算法。
2.8. 其他
统计工作随笔—同比与环比(同期为负值)、百分点
发布博客 2016.08.24
关于同比与环比,如果同期数为负数,或为0,如何计算同比增长?以及百分点pp的概念。
Pandas常用累计、同比、环比等统计方法实践案例
发布博客 2022.02.18
统计表中常常以本年累计、上年同期(累计)、当期(例如当月)完成、上月完成为统计数据,并进行同比、环比分析。如下月报统计表所示样例,本文将使用Python Pandas工具进行统计。
原创
从幂律分布到特征数据概率分布——12个常用概率分布
发布博客 2021.08.02
分析提取及衍生特征数据概率分布,出现较为突出的幂律分布情况,为此整理出12个常用概率分布比较学习。高斯法则和幂律法则的典型代表是分别身高和财富,把姚明放到100个人中,并不会显著改变平均身高,但把比尔·盖茨放到100个人中,就会极大改变平均财富。
3. 总结
在缺乏大量历史数据的新兴技术和产业中,商业分析的关键在于科学的数据化决策技术和方法的运用,而专家经验仍然是不可或缺的要素。以下是在这一前提下的总结:
-
专家经验的价值
- 综合评价: 专家经验具有独特的综合评价能力,可以从多个角度综合考虑新兴技术和产业的各种因素,为商业分析提供全面的视角。
- 判断力: 专家能够基于自身的行业知识和实践经验,作出有针对性的判断,填补数据不足的空缺,为决策提供更加可靠的依据。
- 创新建模: 在面对新兴技术时,专家经验有助于创新建模,通过独到的见解和对未来趋势的把握,为商业分析提供更灵活、适应性强的模型。
-
科学方法的作用
- 解放专家: 科学方法通过数据化和自动化的手段,能够解放专家从繁琐的数据处理工作中,使其更专注于深度分析和决策制定。
- 降低不确定性: 科学方法可以通过模型和算法降低不确定性,提高决策的可信度,特别在缺乏大量历史数据的情况下,能够更好地进行趋势预测和规划。
- 优化决策流程: 科学方法通过建立决策支持系统、模型和算法,优化整个商业分析的决策流程,提高效率和准确性。
-
综合利用专家和科学方法
- 平衡权衡: 专家和科学方法相辅相成,商业分析不应是专家和数据之间的二选一,而是在两者之间寻找平衡,使专家经验能够与科学方法相互补充,形成更为全面的决策基础。
- 实践验证: 专家经验提供了对模型和算法的实际验证和修正的可能性,使科学方法更符合实际场景,避免过于理论化。
-
创新和适应性
- 灵活应变: 专家经验在面对新兴技术时,能够提供灵活应变的能力,帮助企业更好地适应技术和市场的变化。
- 创新视角: 科学方法通过大数据分析等手段提供丰富的信息,而专家则能够为数据提供创新的解读和视角,推动企业在新兴技术领域的创新发展。
-
知识的传承
- 知识的积累(知识库): 利用知识库和知识图谱的技术手段,将专家经验以结构化的形式存储和管理。这有助于实现知识的传承,使得企业能够更好地利用历史经验来指导未来的商业分析和决策。
- 算法可解释性: 在采用科学方法时,算法的可解释性是至关重要的。可解释性使专家能够理解模型背后的推理过程,对模型的输出进行解释,并结合自身经验进行验证。
- 建设知识传承平台: 在企业内部建设知识传承平台,通过培训、文档、在线资源等手段,促使新一代专业人才更好地吸收和应用老一辈专家的经验和知识。
知识的传承通过知识库、知识图谱、算法可解释性等手段,使得专家的经验不仅仅停留在个体层面,而能够被科学化、系统化地传递和应用。这种科学化的知识传承提升了商业分析的连续性和稳定性,使得企业更具适应性和竞争力。
综合而言,专家经验与科学方法相结合,构成了在新兴技术和产业中科学化商业分析的有机整体。这一综合方法能够在不断变化的环境中为企业提供有力的支持,促使决策更为科学、全面和灵活。
相关文章:

python小数据分析小结及算法实践集锦
在缺乏大量历史数据的新兴技术和产业中,商业分析可能会面临一些挑战。然而,有一些技术和方法可以帮助分析者在数据不充分的情况下进行科学化商业分析,并为决策提供支持。 1. 当面对缺乏大量历史数据的新兴技术和产业时所采常用的技术和方法 …...

【docker系列】docker高阶篇
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
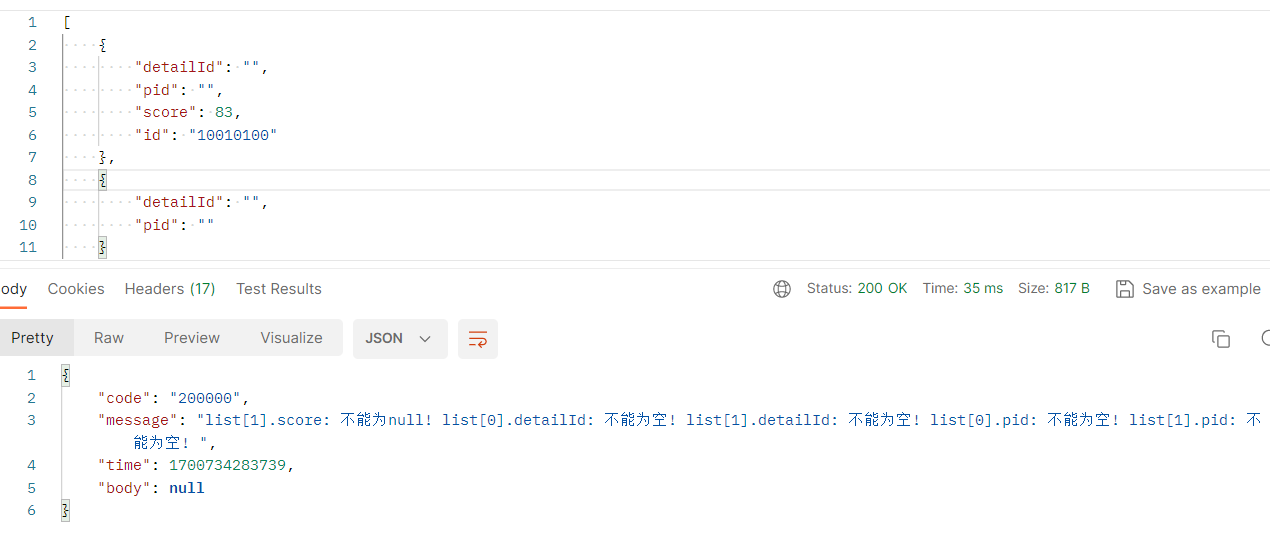
SpringBoot校验List失效解决方法
文章目录 SpringBoot校验List失效解决方法附:校验基本数据类型和String类型的方法参数时也需要在类上加Validated SpringBoot校验List失效解决方法 失效场景示例代码: RestController RequestMapping("/v1/jx/flowSummary") Slf4j public cl…...
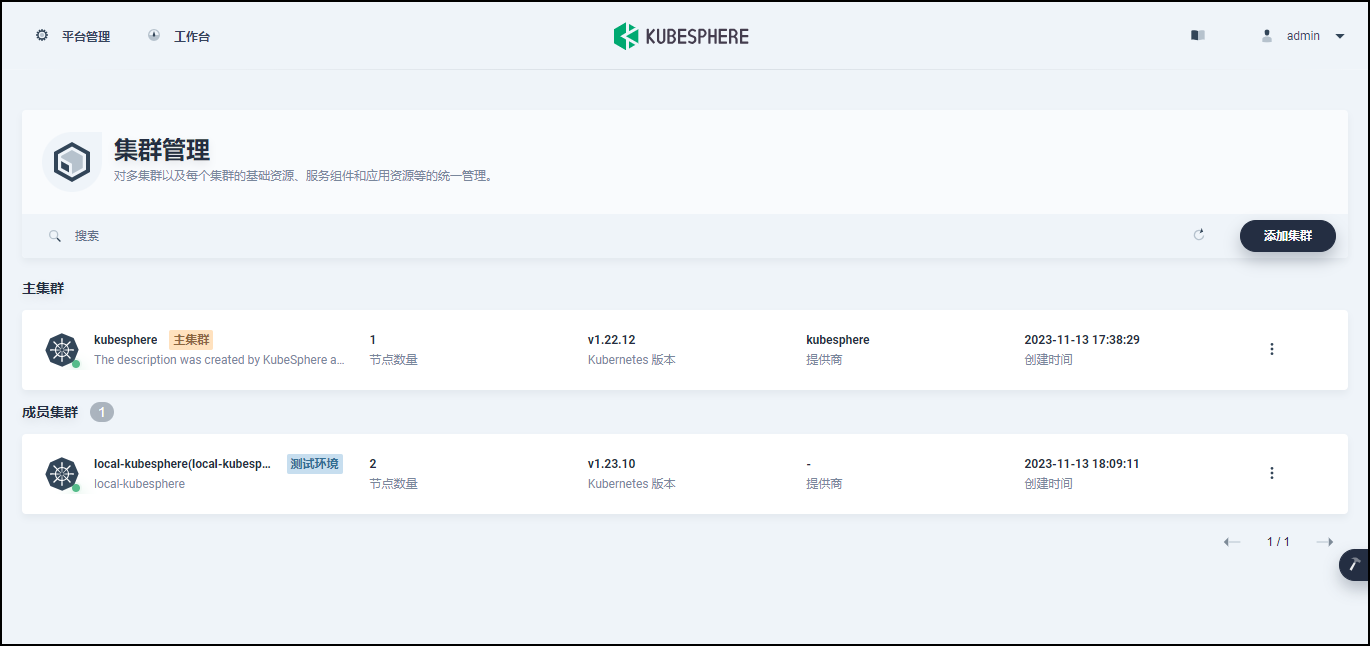
【KubeSphere】基于AWS在 Linux 上以 All-in-One 模式安装 KubeSphere
文章目录 一、实验配置说明二、实验准备工作1.确认系统版本2. 修改网络DNS3. 关闭SELINUX4. 关闭防火墙 三、实验依赖项安装四、下载 KubeKey五、一键化安装部署六、验证安装结果七、登录KubeSphere管理控制台八、参考链接 一、实验配置说明 本实验基于AWS启动一台新实例&…...
数)
3.一维数组——输入十个数,输出其中最大(小)数
文章目录 前言一、题目描述 二、题目分析 三、解题 程序运行代码 前言 本系列为一维数组编程题,点滴成长,一起逆袭。 一、题目描述 输入十个数,输出其中最大(小)数 二、题目分析 打擂台法:maxa[0]; 最大…...
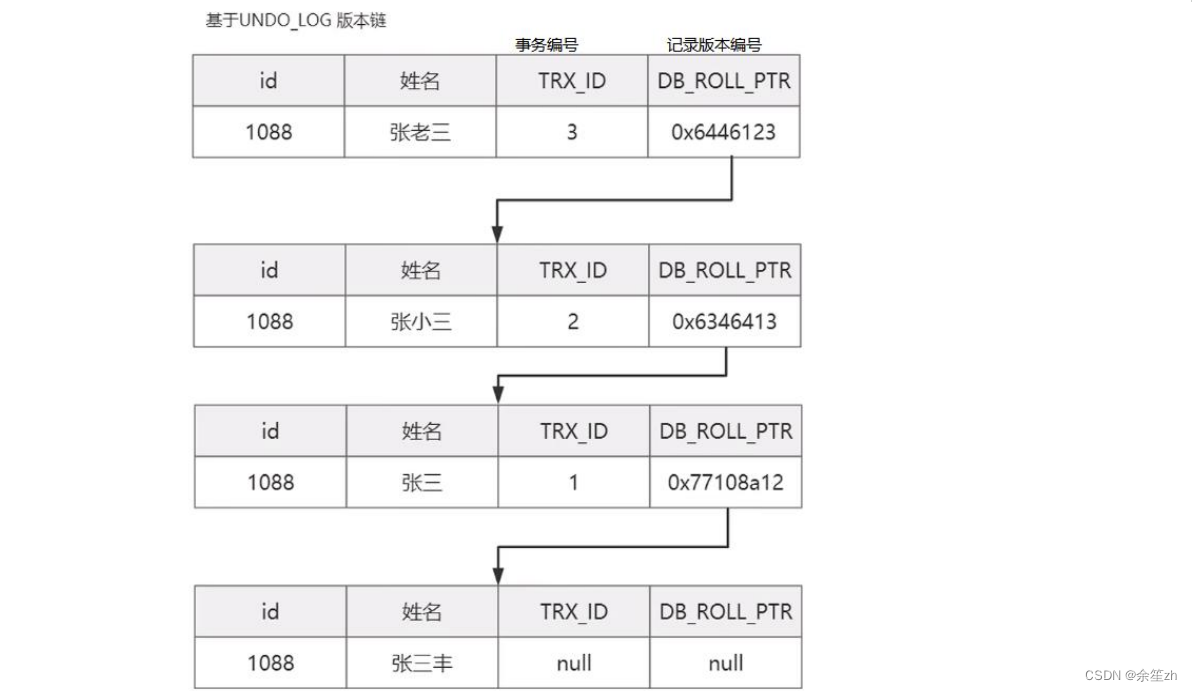
mysql高级知识点
一、mysql架构 连接层:负责接收客户端的连接请求,可以进行授权、认证(验证账号密码)。服务层:负责调用sql接口,对sql语法进行解析,对查询进行优化,缓存。引擎层:是真正进行执行sql的地方&#x…...
python pdf转txt文本、pdf转json
文章目录 一、前言二、实现方法1. 目录结构2. 代码 一、前言 此方法只能转文本格式的pdf,如果是图片格式的pdf需要用到ocr包,以后如果有这方面需求再加这个方法 二、实现方法 1. 目录结构 2. 代码 pdf2txt.py 代码如下 #!/usr/bin/env python # -*- …...

LabVIEW中如何达到NI SMU最大采样率
LabVIEW中如何达到NI SMU最大采样率 NISMU的数字化仪功能对于捕获SMU详细的瞬态响应特性或表征待测设备(DUT)响应(例如线性调整率和负载调整率)至关重要。没有此功能,将需要一个外部示波器。 例如,假设在…...

redis运维(二十)redis 的扩展应用 lua(二)
一 redis 的扩展应用 lua redis lua脚本语法 ① 什么是脚本缓存 redis 缓存lua脚本 说明: 重启redis,脚本缓存会丢失 下面讲解 SCRIPT ... 系列 SCRIPT ② LOAD 语法:SCRIPT LOAD lua代码 -->载入一个脚本,只是预加载,不执行思考1࿱…...

Docker ps命令
docker ps:列出容器。 语法: docker ps [OPTIONS]OPTIONS说明: -a:显示所有的容器,包括未运行的。 -f:根据条件过滤显示的内容。 --format:指定返回值的模板文件。 -l:显示最近…...

前端实现留言板
留言板的主要使用场景是为用户提供一个在网站或应用上留言的平台,这样他们可以分享自己的想法、意见或建议。这些留言可以帮助开发者收集用户反馈,从而改进产品或服务。 使用HTML、CSS和JavaScript实现的留言板:这种方法的优点是简单易实现&a…...
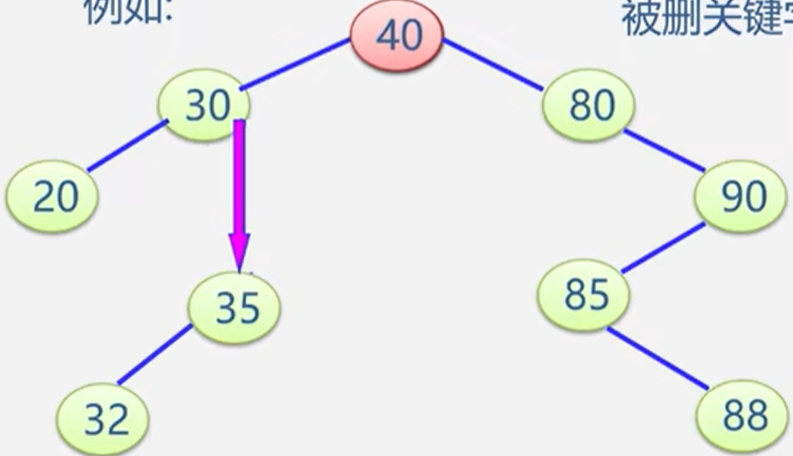
【二叉排序树(Binary Sort Tree)又称为二叉搜索树,二叉查找树,)二叉排序树的操作----插入生成删除】
文章目录 二叉排序树(Binary Sort Tree)又称为二叉搜索树,二叉查找树,)二叉树的查找分析二叉排序树的操作----插入二叉排序树的操作----生成二叉排序树的操作----删除 二叉排序树(Binary Sort Tree…...

Verilog基础:时序调度中的竞争(二)
相关阅读 Verilog基础https://blog.csdn.net/weixin_45791458/category_12263729.html?spm1001.2014.3001.5482 作为一个硬件描述语言,Verilog HDL常常需要使用语句描述并行执行的电路,但其实在仿真器的底层,这些并行执行的语句是有先后顺序…...

云原生周刊:Kubernetes 1.29 中的删除、弃用和主要更改 | 2023.11.27
开源项目推荐 Orphaned ConfigMaps 该版本库包含一个脚本,用于识别 Kubernetes 命名空间中的孤立的配置映射。孤立的配置映射是指那些未被命名空间中的任何活动 Pod 或容器引用的配置映射。 Kubernetes Multi Cooker 该项目包含一个小型 Kubernetes 控制器&…...

深入理解计算机中的程序
目录 程序的存储 程序的编译过程 各位宝宝好,我们这次从计算机底层来讲一下程序是如何存储,编译的 程序的存储 我们拿一个最简单的程序来举个例子: #include<stdio.h> int main() {printf("hello world");return 0; } …...

uniapp视频倍速播放插件,uniapp视频试看插件——sunny-video使用文档
sunny-video视频倍速播放器 组件名:sunny-video 效果图 img1img2img3img4 平台差异说明 目前已应用到APP(安卓、iOS)、微信(小程序、H5)其它平台未测试 安装方式 本组件符合easycom规范,HBuilderX 2.5…...

【微软技术栈】与其他异步模式和类型互操作
本文内容 任务和异步编程模型 (APM)任务和基于事件的异步模式 (EAP)任务和等待句柄 .NET 中异步模式的简短历史记录: .NET Framework 1.0 引进了 IAsyncResult 模式,也称为异步编程模型 (APM) 或 Begin/End 模式。.NET Framework 2.0 增加了基于事件的…...
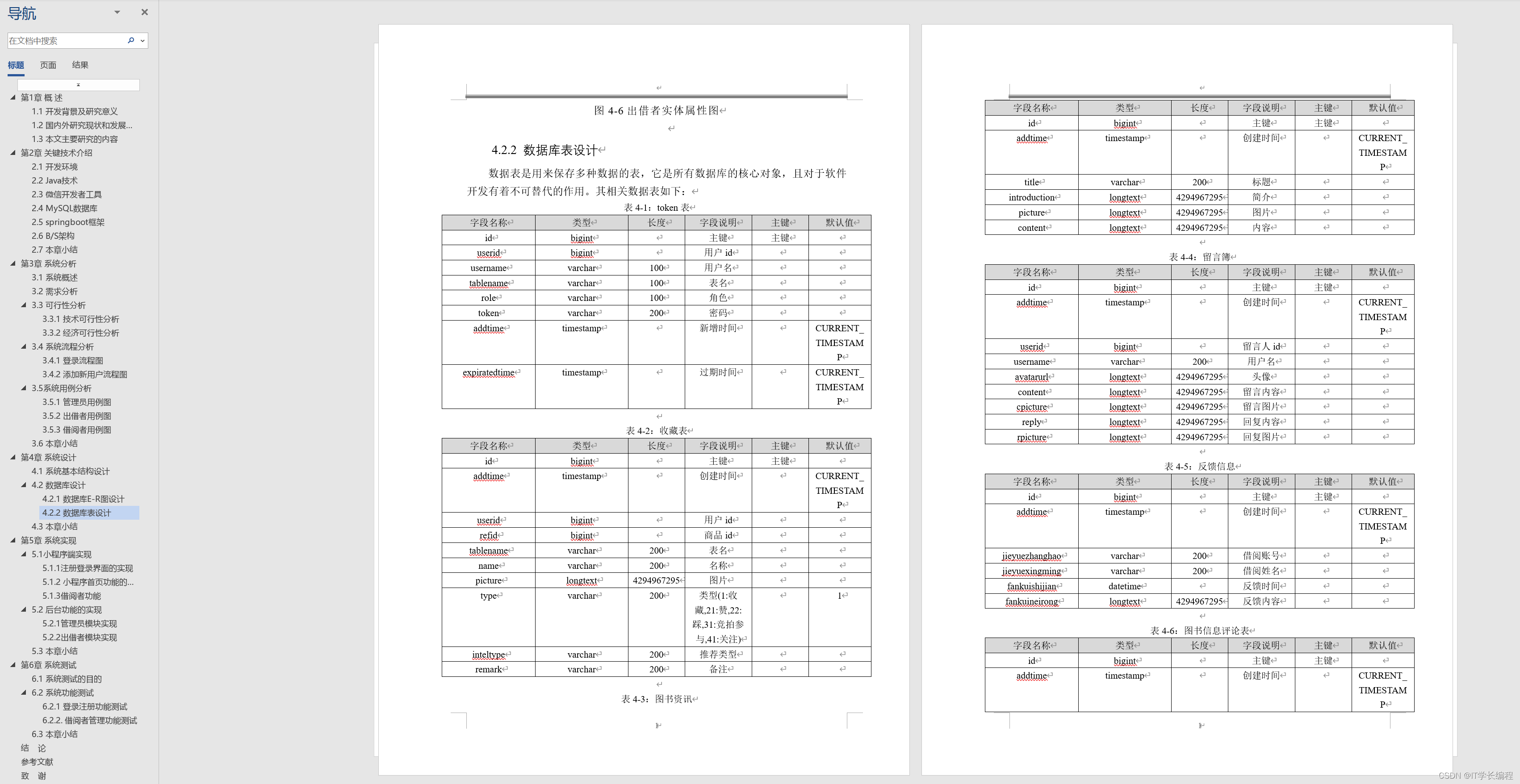
计算机毕业设计 基于微信小程序的“共享书角”图书借还管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

腾讯云CVM标准型SA5云服务器AMD EPYC Bergamo处理器
腾讯云服务器标准型SA5实例是最新一代的标准型实例,CPU采用AMD EPYC™ Bergamo全新处理器,采用最新DDR5内存,默认网络优化,最高内网收发能力达4500万pps。腾讯云百科txybk.com分享腾讯云标准型SA5云服务器CPU、内存、网络、性能、…...

网站要怎么进行维护和防御攻击
随着数字经济的不断发展,互联网各业都在稳步发展,但是很多站长搭建网站程序后也不知道怎么去维护网站的稳定和是否有漏洞后门等,为此德迅云安全专门为各大站长研发了网站监测产品 知道网站表现:网站监测可以帮助您了解您的网站的…...
)
别再手动P图了!用Python+Flask 5分钟搭建一个车牌图片生成API(支持蓝黄绿白黑牌)
5分钟构建车牌生成API:用PythonFlask打造高定制化图像服务 在自动化测试和图像处理领域,生成逼真的车牌图像是一个常见但容易被低估的需求。无论是用于车牌识别算法的训练数据增强,还是作为开发测试的模拟数据源,一个灵活的车牌生…...

STM32无硬件RNG时,如何利用ADC噪声与DMA高效生成真随机数
1. 为什么STM32需要真随机数? 在嵌入式开发中,随机数的应用场景远比我们想象的广泛。比如智能家居设备的配对码生成、工业控制中的防碰撞算法、物联网设备的密钥协商等场景,都需要高质量的随机数。我遇到过最典型的案例是一个智能门锁项目&am…...

UEFI固件分析实战:从入门到精通的逆向工程指南
UEFI固件分析实战:从入门到精通的逆向工程指南 【免费下载链接】UEFITOOL28 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITOOL28 在现代计算机系统中,UEFI固件扮演着连接硬件与操作系统的关键角色,其安全性与功能性直接影响整个…...

m4s-converter:让B站缓存视频真正为你所用的本地化工具
m4s-converter:让B站缓存视频真正为你所用的本地化工具 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 一、问题象限:B站…...

注册获取阿里云qwen大模型api key
1.进入阿里云官网,然后注册登录并完善个人信息https://cn.aliyun.com/2.搜索框搜索api key 或点击模型,最下边的api key-->创建...

2026届必备的五大AI辅助论文神器推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 依托自然语言处理跟知识图谱技术,AI开题报告工具能够针对研究领域文献开展自动解…...

Blue-Topaz主题新手入门指南:打造你的个性化Obsidian笔记环境
Blue-Topaz主题新手入门指南:打造你的个性化Obsidian笔记环境 【免费下载链接】Blue-Topaz_Obsidian-css A blue theme for Obsidian. 项目地址: https://gitcode.com/gh_mirrors/bl/Blue-Topaz_Obsidian-css 还在为Obsidian默认界面单调而烦恼?…...

通义千问2.5-7B从下载到对话:完整部署流程与代码示例
通义千问2.5-7B从下载到对话:完整部署流程与代码示例 1. 引言 1.1 为什么选择通义千问2.5-7B 通义千问2.5-7B-Instruct是阿里云2024年9月发布的中等规模开源大模型,具有以下突出优势: 性能强劲:在7B参数级别中英文综合能力领先…...
PyVideoTrans:开源视频翻译与AI配音的完整解决方案
PyVideoTrans:开源视频翻译与AI配音的完整解决方案 【免费下载链接】pyvideotrans Translate the video from one language to another and embed dubbing & subtitles. 项目地址: https://gitcode.com/gh_mirrors/py/pyvideotrans PyVideoTrans是一款功…...

4步攻克Windows与Office激活难题:从新手到专家的智能解决方案
4步攻克Windows与Office激活难题:从新手到专家的智能解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 在数字化办公环境中,软件激活问题常常成为影响工作效率的隐…...