Scrapy爬虫异步框架之持久化存储(一篇文章齐全)
1、Scrapy框架初识(点击前往查阅)
2、Scrapy框架持久化存储
3、Scrapy框架内置管道(点击前往查阅)
4、Scrapy框架中间件(点击前往查阅)

Scrapy 是一个开源的、基于Python的爬虫框架,它提供了强大而灵活的工具,用于快速、高效地提取信息。Scrapy包含了自动处理请求、处理Cookies、自动跟踪链接、下载中间件等功能
Scrapy框架的架构图(先学会再来看,就能看懂了!)
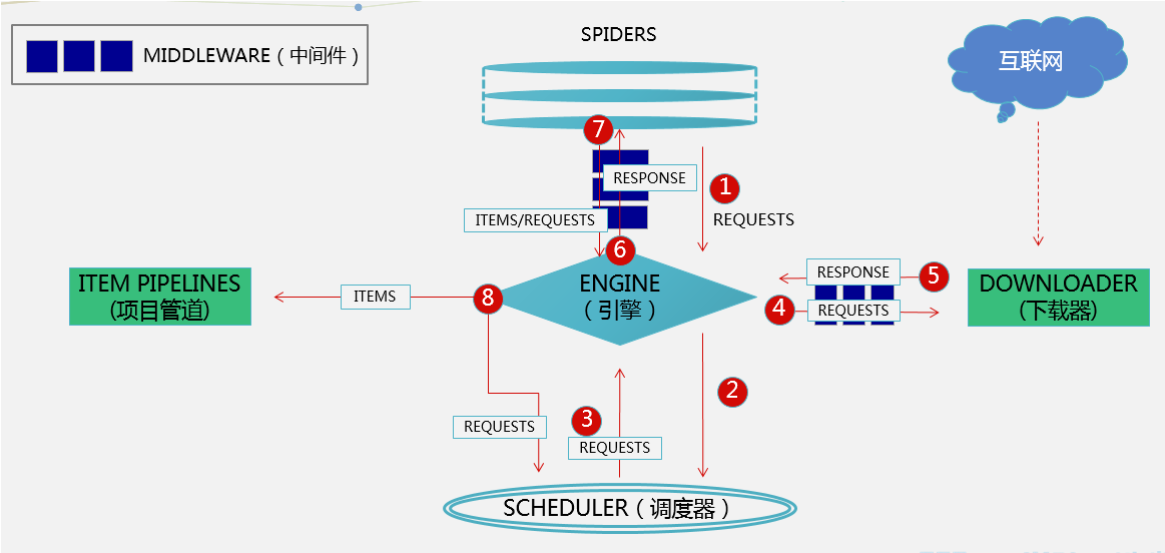
一、持久化存储(文本)
1:基于终端指令的存储
基于终端指令:简单,但是局限性较大。
scrapy crawl myspider -o project_name.后缀名
命令讲解: (例:scrapy crawl baidu -o baidudata.json)
- myspider:执行的爬虫文件名
- project_name.后缀名:想要保存的文件名和格式(具体格式参考下面)
终端指令的方法只可以将parse方法的返回值存储到指定后缀的文本文件中。且格式只能是如下展示的。

1.1:执行代码
import scrapyclass BaiduSpider(scrapy.Spider):# 爬虫文件的唯一标识(就是你创建的爬虫文件夹名字)name = "baidu"# 允许的域名,这个代表你只能访问这个网址的子域名,其他的都会禁止(这个我们会注释掉,不会打开)# allowed_domains = ["www.xxx.com"]# 起始的url列表,网址可以随便放,可以放多个,列表中的url都会被框架进行异步请求发送。start_urls = ["https://www.xiachufang.com/category/40076/"]# 数据解析:parse调用的次数取决于start_urls列表元素的个数def parse(self, response): # response参数就表示响应对象# 创建一个空列表用于存储all_data = []# 利用xpath解析:(scrapy内置xpath,无需另外导入)li_list = response.xpath('//div[@class="pure-u-3-4 category-recipe-list"]//ul/li')for li in li_list:# 1、scrapy中的xpath会返回Selector对象,我们需要的数据在该对象data属性中(extract可以实现该功能,)# 2、extract_first()就是取第一个,因为文本两边有空格,所以.strip() 可以去除两侧的空格title = li.xpath('.//p[1]/a/text()').extract_first().strip()author = li.xpath('.//p[4]/a/text()').extract_first().strip()# 将每次获取到的标题和作者添加到字典中dic = {'title': title,'author': author}# 将字典添加到列表中all_data.append(dic)# 爬取到的数据被作为parse方法的返回值return all_data1.1:执行结果分析
此代码在这个Scrapy框架初识(点击前往查阅)代码上就加了前4步(如下图)。
- 第5步:执行代码
- 第6步:最后生成的文件Scrapy框架初识(点击前往查阅)
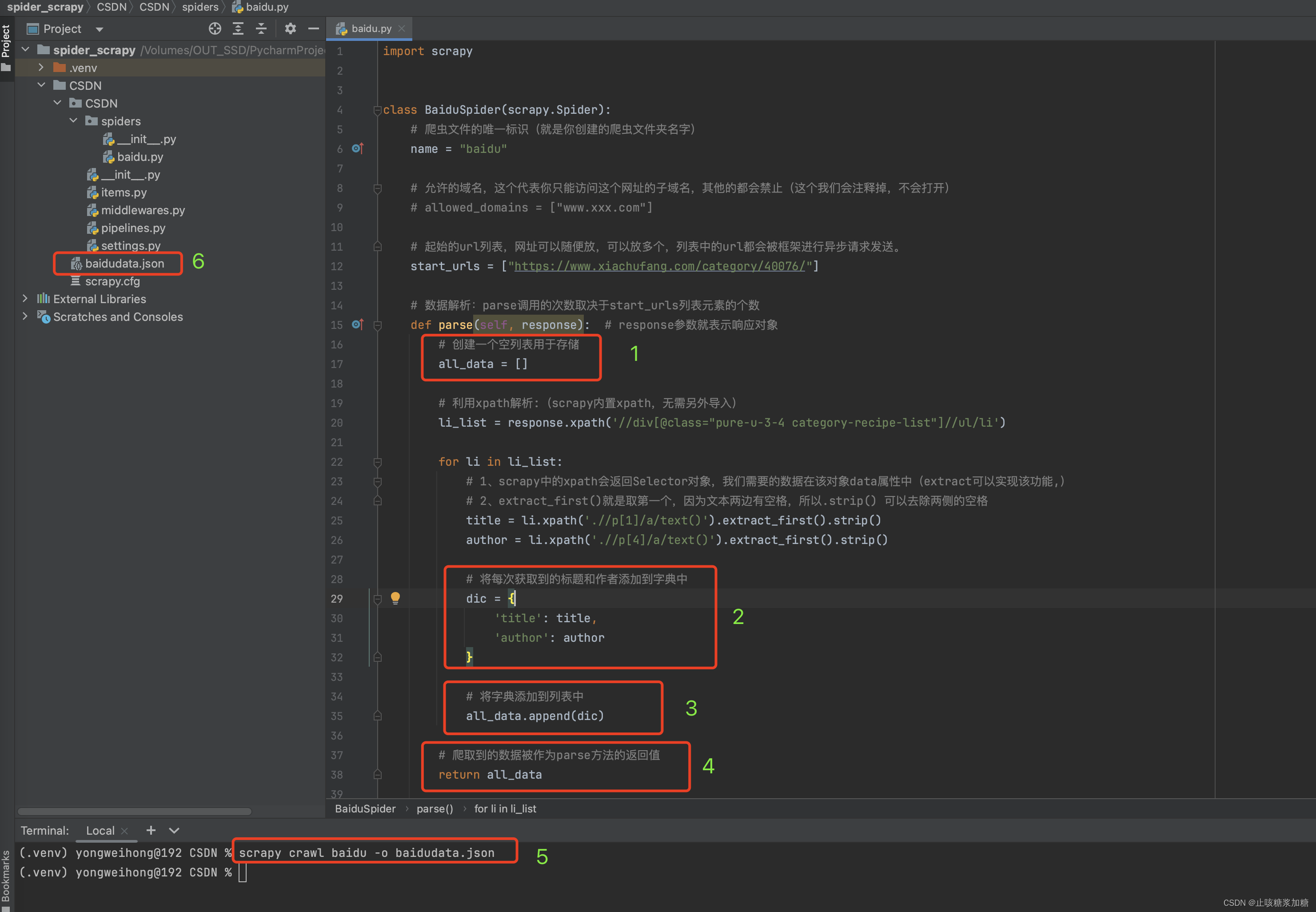
基于终端指令存储就是这样的,虽然简单,但是局限性很大。
2:基于管道的存储(存入本地文件)
基于管道的形式:相比较终端复杂,但是灵活性很大。
管道存储so easy 只需5步
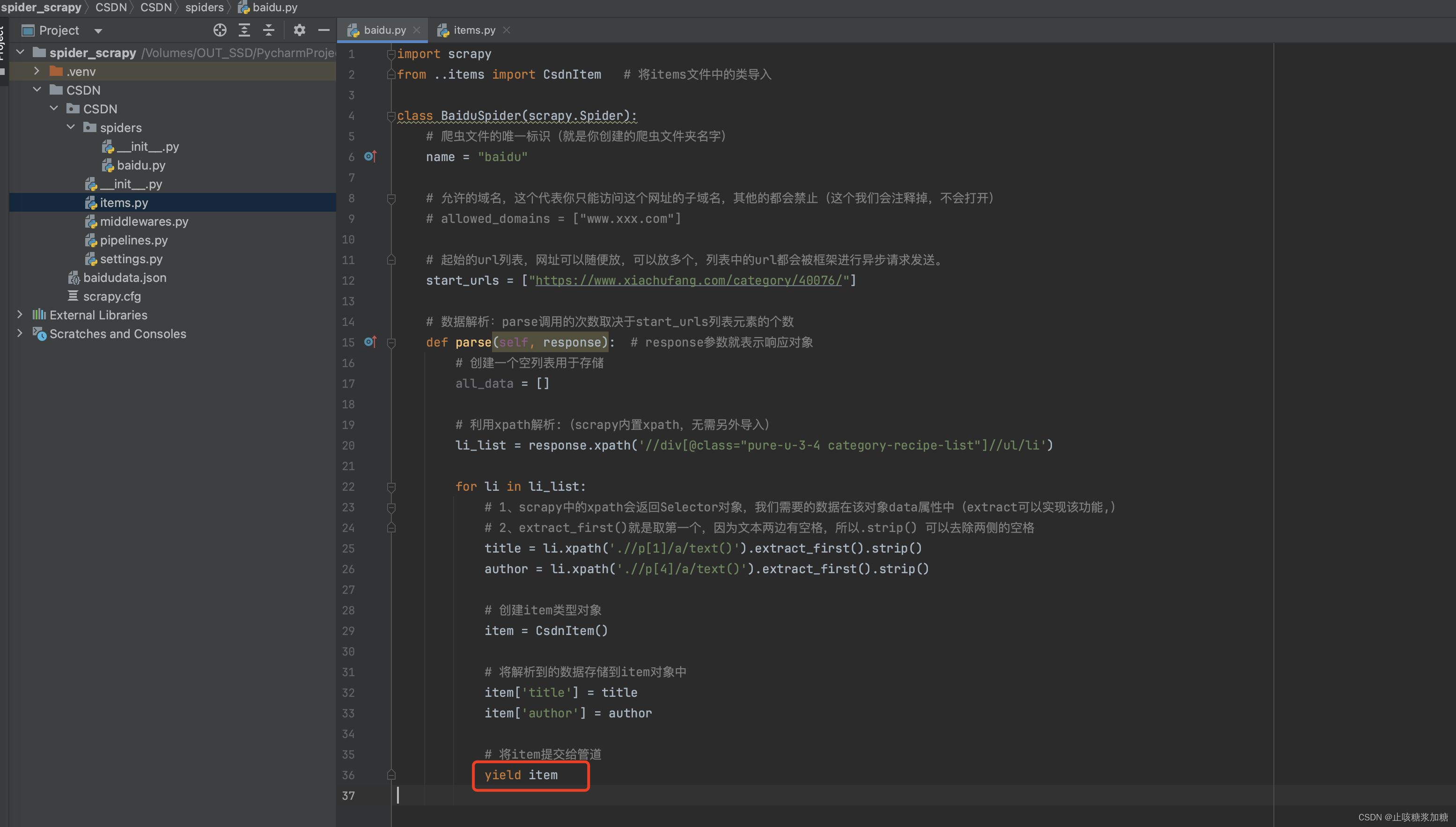
2.1:在爬虫文件中进行数据解析操作。
解析代码如下⬇️
import scrapyclass BaiduSpider(scrapy.Spider):# 爬虫文件的唯一标识(就是你创建的爬虫文件夹名字)name = "baidu"# 允许的域名,这个代表你只能访问这个网址的子域名,其他的都会禁止(这个我们会注释掉,不会打开)# allowed_domains = ["www.xxx.com"]# 起始的url列表,网址可以随便放,可以放多个,列表中的url都会被框架进行异步请求发送。start_urls = ["https://www.xiachufang.com/category/40076/"]# 数据解析:parse调用的次数取决于start_urls列表元素的个数def parse(self, response): # response参数就表示响应对象# 创建一个空列表用于存储all_data = []# 利用xpath解析:(scrapy内置xpath,无需另外导入)li_list = response.xpath('//div[@class="pure-u-3-4 category-recipe-list"]//ul/li')for li in li_list:# 1、scrapy中的xpath会返回Selector对象,我们需要的数据在该对象data属性中(extract可以实现该功能,)# 2、extract_first()就是取第一个,因为文本两边有空格,所以.strip() 可以去除两侧的空格title = li.xpath('.//p[1]/a/text()').extract_first().strip()author = li.xpath('.//p[4]/a/text()').extract_first().strip()
2.2:创建一个item类型的对象。
创建的item对象,需要封装自己需要的变量。例如:我需要title、author两个变量(框架中有封装好item类型文件)
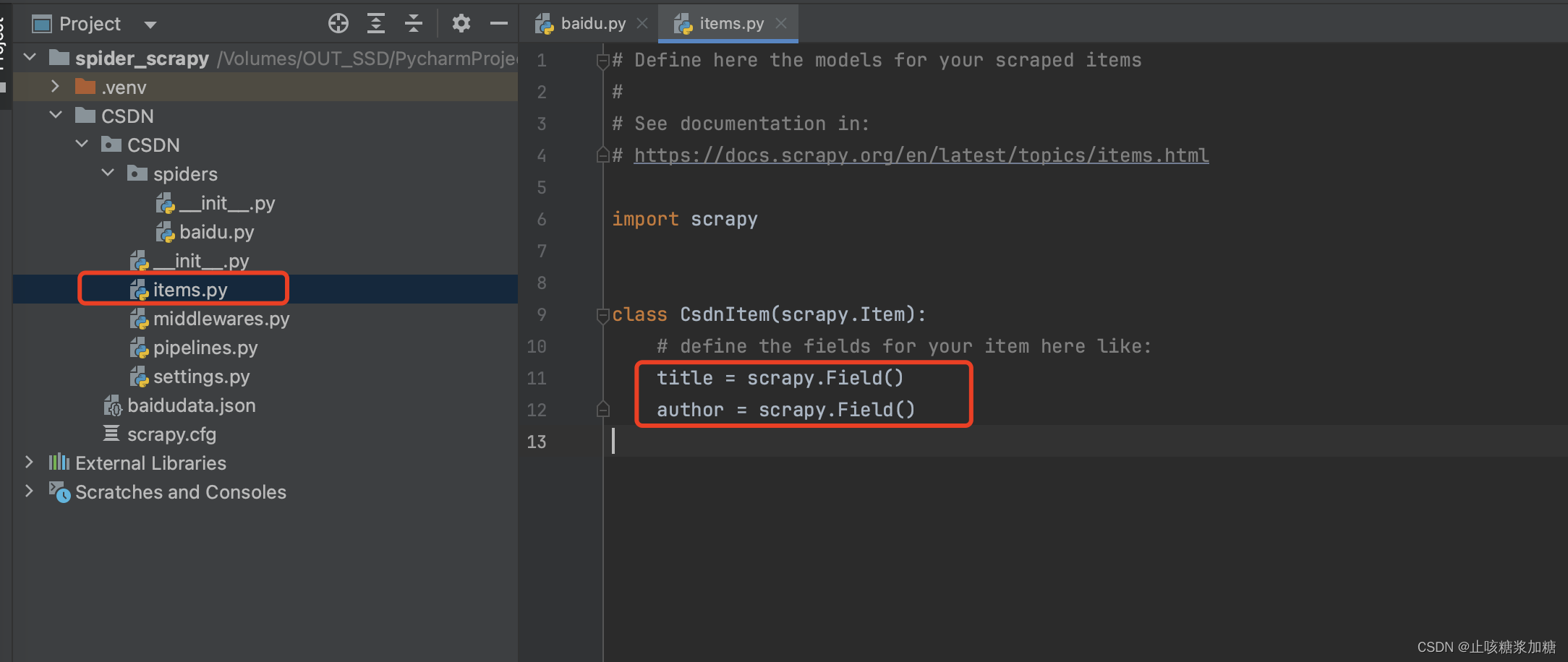
2.2.1:将解析到的数据存储到该对象中。
如何将解析好的数据存储到item对象中呢?各位看官接着往下看~
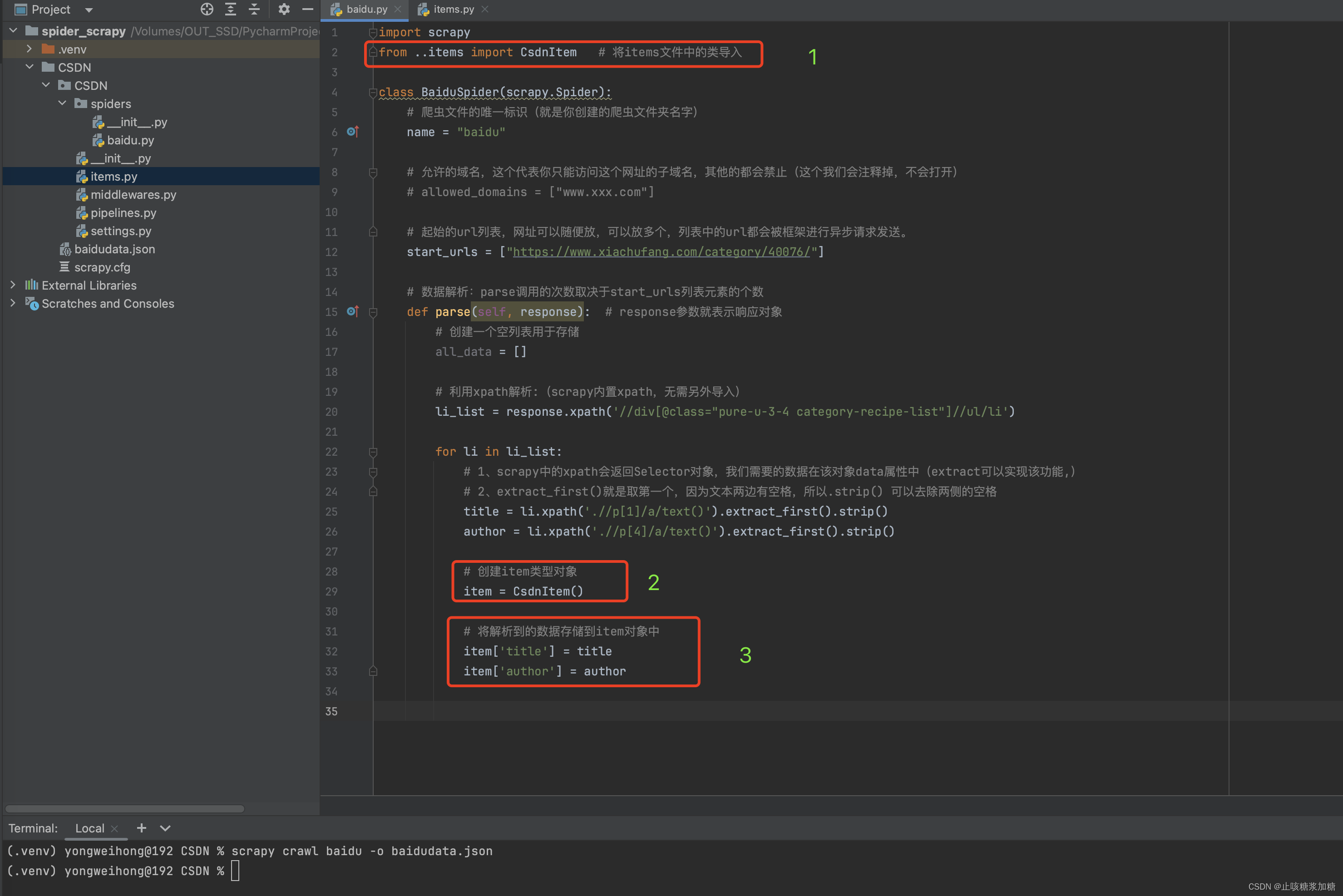
2.3:将item对象提交给管道。
什么是管道呢?管道在框架中在哪呢?就在这~
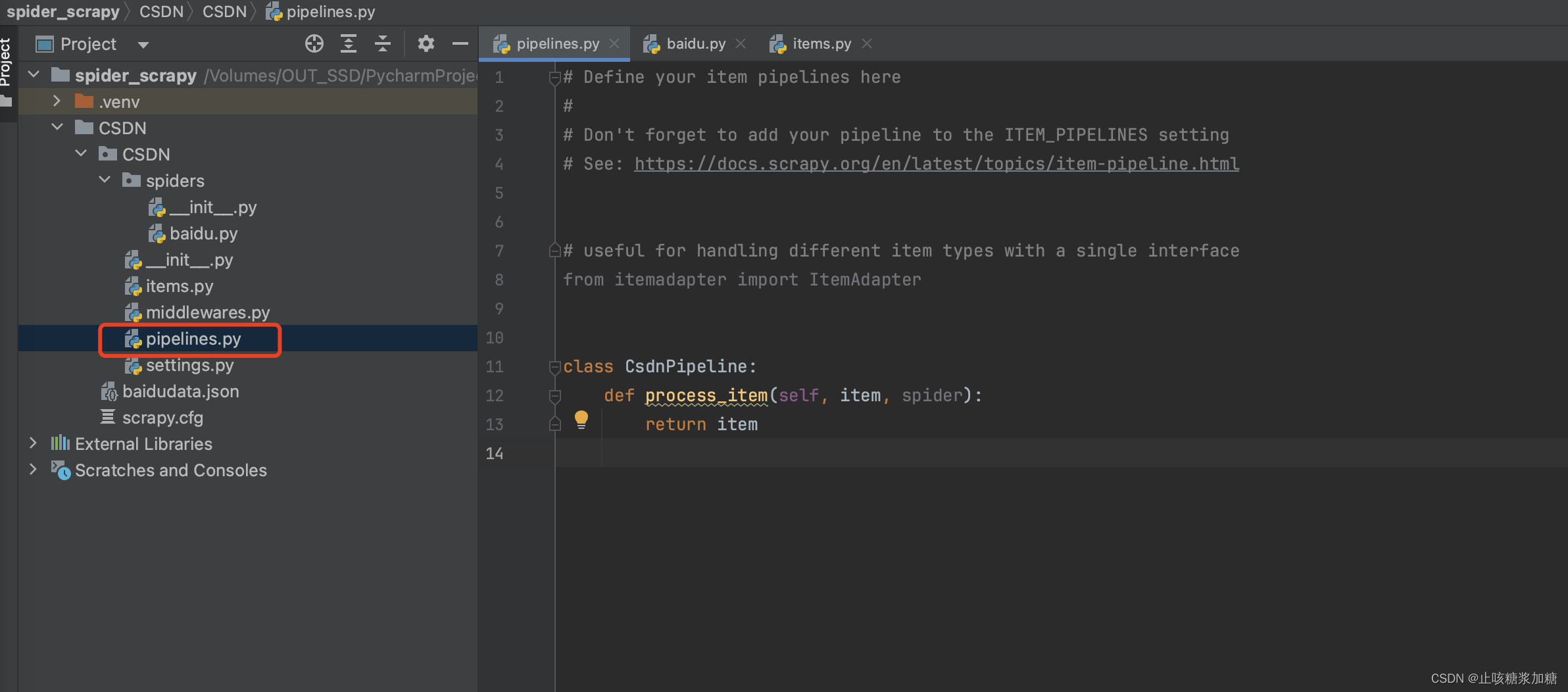
如何将item对象提交给管道呢?只需要 yield 关键字就可以了!
2.4:在管道中实现process_item的函数,实现对item对象的接收,对其进行指定的持久化存储。
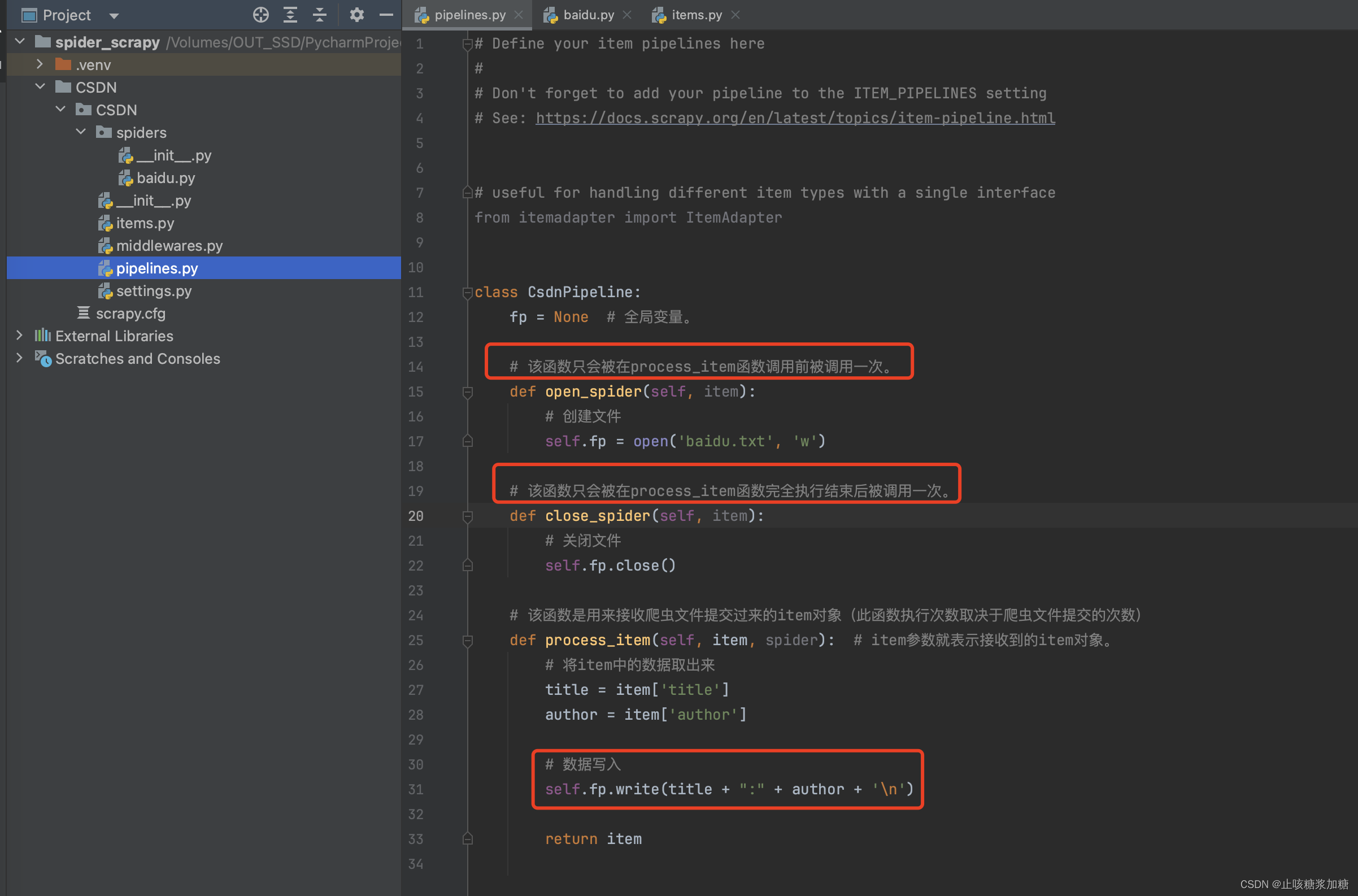
代码讲解:(return是有多个管道把数据传递给下一个,后面会讲解)
- open_spider函数:这个函数只会在process_item函数之前之前执行一次,所以这就操作的空间了,我们可以先定义一个全局变量,然后在这个函数中创建一个文件句柄。
- process_item函数:self调用写入数据就行了。
- close_spider函数:该函数会在process_item函数完全执行结束之后调用一次,这个里边就关闭文件就行了。
错误演示:❌❌❌
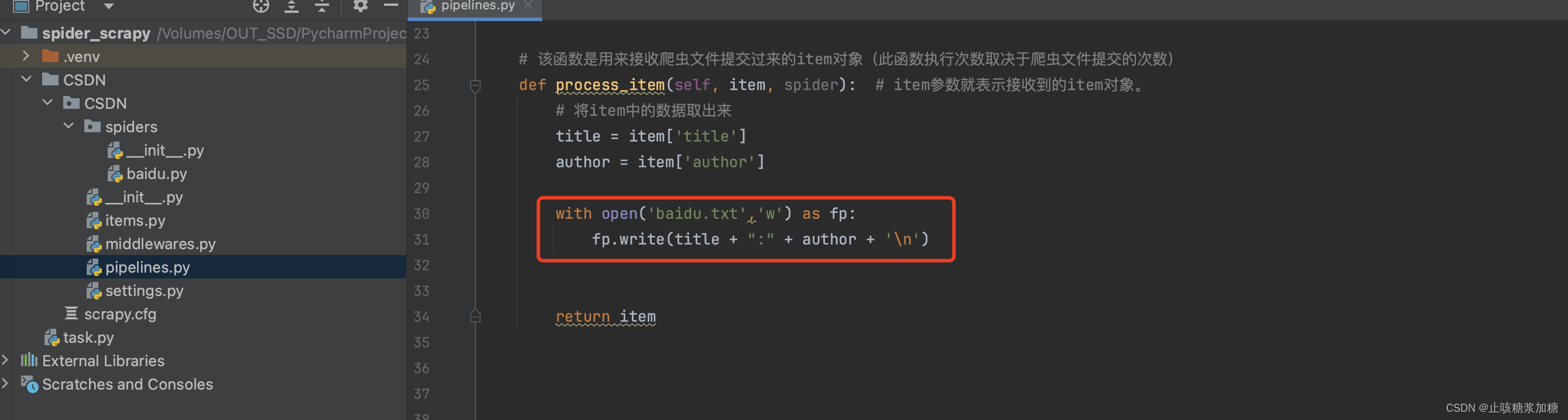
可能会有同学会想到用这个方法来储存,这就要想到一个问题了,process_item函数会被执行很多次(执行的次数取决于爬虫文件提交的次数)所以这个方法肯定是不行的。
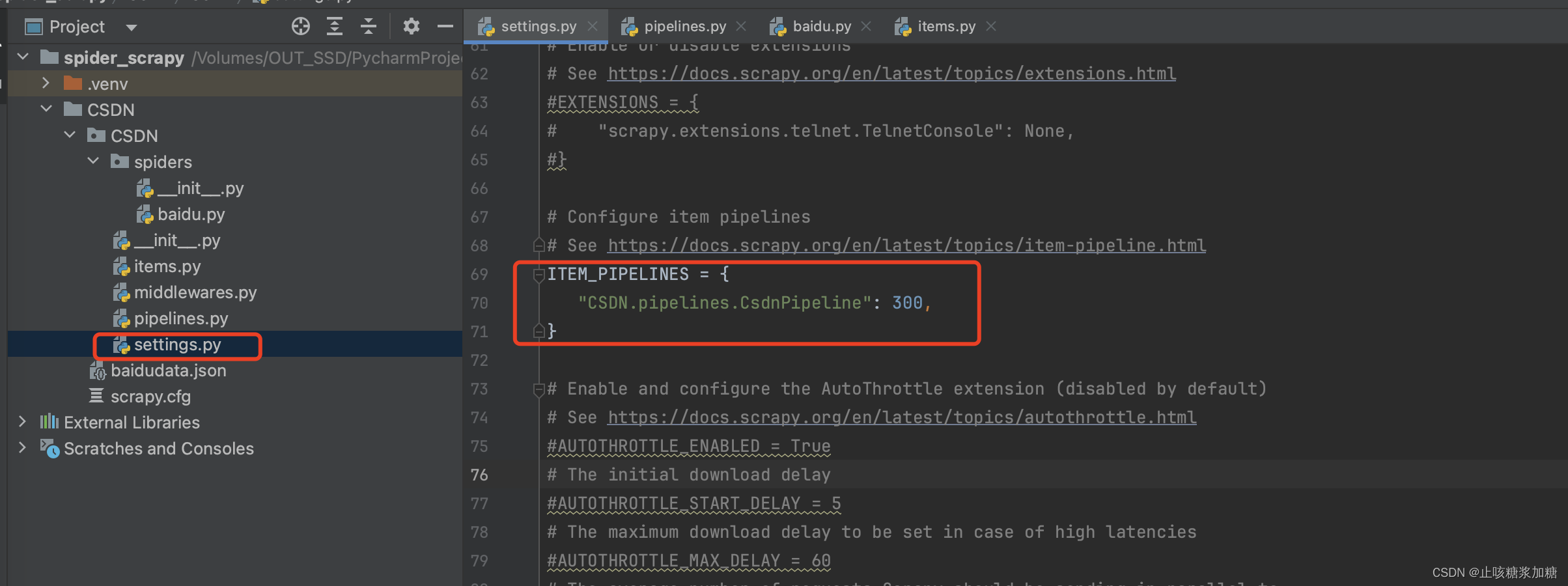
2.5:在配置文件中开启管道功能。
注释去掉就是开启了,后面的300是优先级的,如果有多个管道会用到,数字越小优先级越高,下面会讲~(另外UA或者Cookie一些反爬根据网站需求决定是否开启)
2.6:执行结果
执行指令:my_spider就是你的爬虫文件名字
scrapy crawl my_spider执行代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass CsdnPipeline:fp = None # 全局变量。# 该函数只会被在process_item函数调用前被调用一次。def open_spider(self, item):# 创建文件self.fp = open('baidu.txt', 'w')# 该函数只会被在process_item函数完全执行结束后被调用一次。def close_spider(self, item):# 关闭文件self.fp.close()# 该函数是用来接收爬虫文件提交过来的item对象(此函数执行次数取决于爬虫文件提交的次数)def process_item(self, item, spider): # item参数就表示接收到的item对象。# 将item中的数据取出来title = item['title']author = item['author']# 数据写入self.fp.write(title + ":" + author + '\n')return item
以我们设置的文件格式,文件名字储存好了。 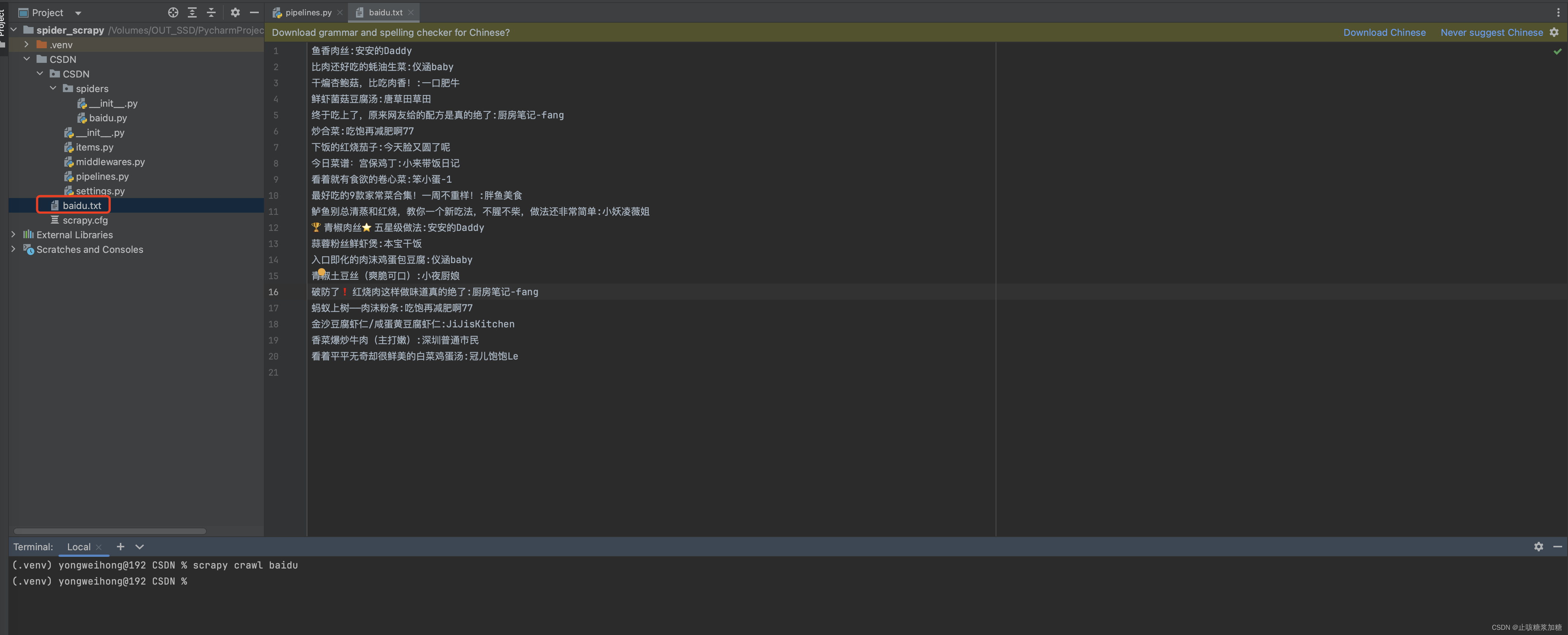
二、基于管道的存储(存入数据库)
首先肯定要先安装MySQL数据库的,没有安装可以参考最新版MySQL安装 & 配置 & 启动
还需要安装模块用于操作MySQL数据库
pip install pymsql存到数据库步骤:(数据库要提前开启哦)
和存入本地文件唯一不同的地方就在第四步管道函数的编写,下面我们就把这方面重点分析一下~
1:settings中配置
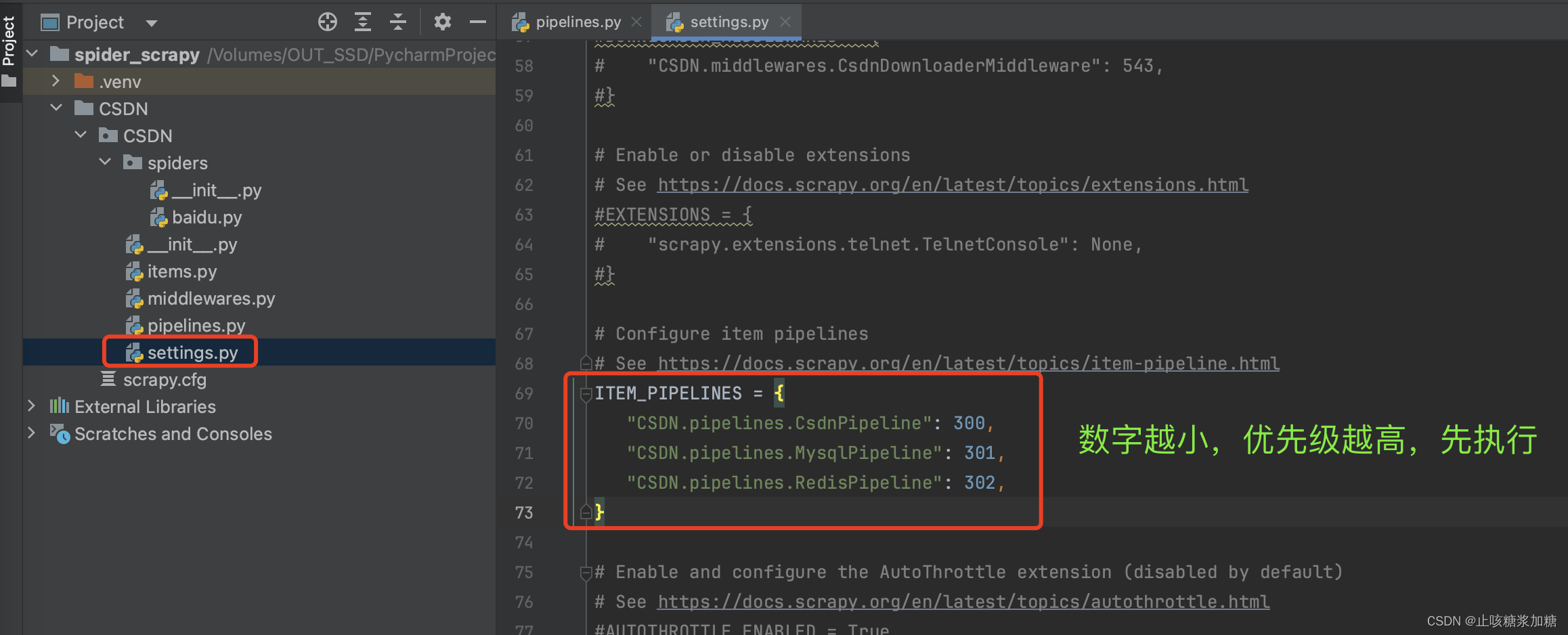
前面还提到了 yield 的关键字,是提交给管道的,他优先提交给数字小的,也就是优先级高的。
2:管道原理剖析

还记得前面的 return吗?现在来填坑了!!!
如果 你需要一个管道就OK了下面不需要了,那OK不需要return也是可以的,但是,你下面还有管道,那必须要return的,不然你数据无法传递下去,并且还会报错。
3:代码编写
首先要学会Python操作MySQL方法,不会的可以参考这Python操作中MySQL数据方法
此代码指针对MySQL数据库的,完整的需要包含上面 class CsdnPipeline 中的代码
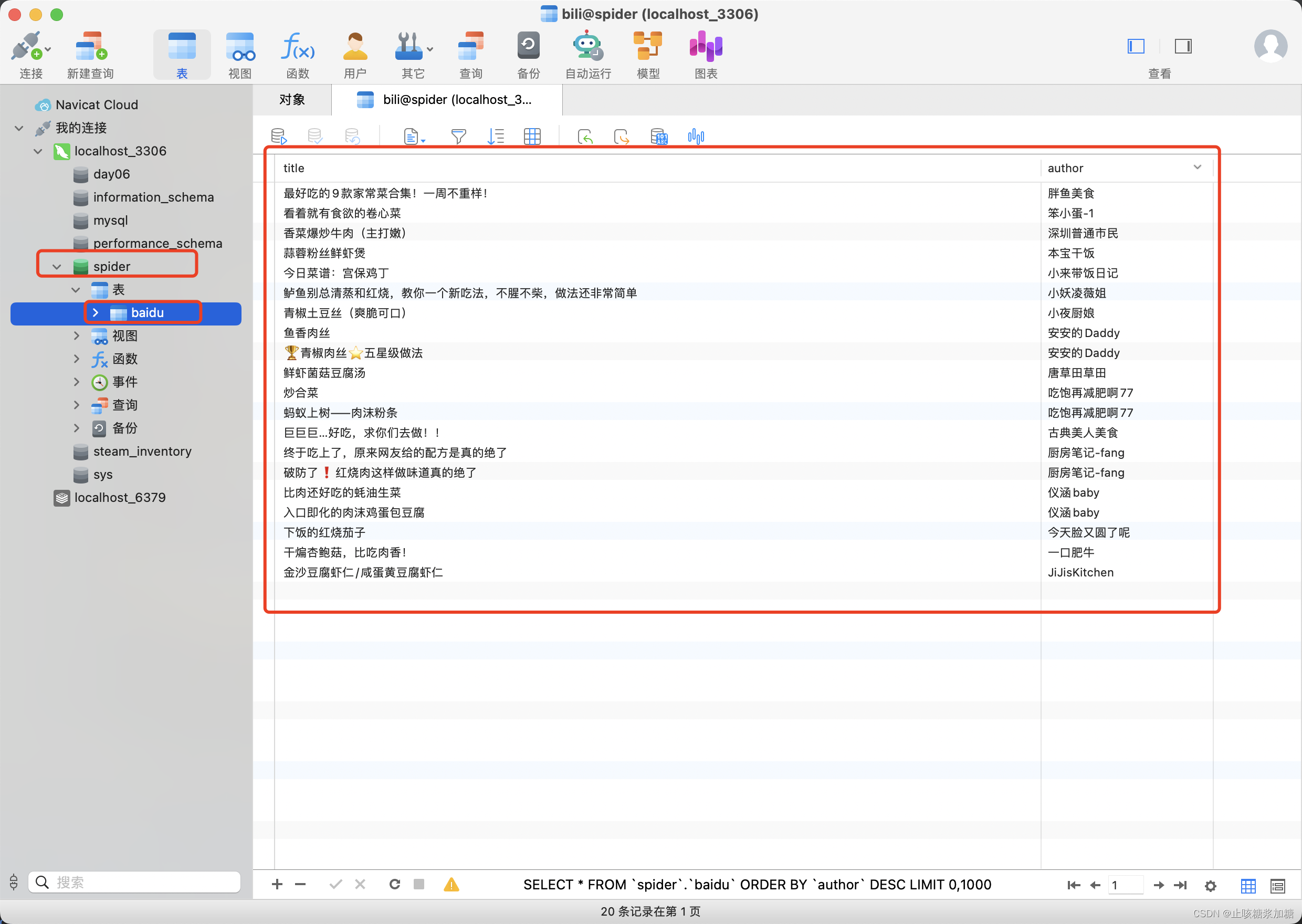
import pymysql # 导入操作数据库模块class MysqlPipeline:# 1、创建一个链接对象conn = pymysql.connect(host='127.0.0.1', # mysql服务器的ip地址port=3306, # mysql默认端口号user='root', # mysql用户名password='root1234', # mysql密码db='spider', # mysql指定的数据库)# 2、创建一个游标对象:用来执行sql语句cursor = conn.cursor()def process_item(self, item, spider):# 利用上面传入的item,我们先获取到数据title = item['title']author = item['author']# 将2个字段存储到mysql数据表中sql = 'insert into bili(title,author) values ("{}","{}")'.format(title, author)# 使用游标对象执行sql语句self.cursor.execute(sql)# 提交事物,最后才会将数据存入数据库中self.conn.commit()return itemdef close_spider(self, spider):# 关闭游标和链接对象self.cursor.close()self.conn.close()代码分析:

其中主要就是数据库的链接,要提前创建好表和对应的字段,然后会简单的SQL语句。
4:执行结果
三、基于管道的存储(存入Redis缓存中)
首先肯定要先安装Redis的,没有安装可以参考手把手安装部署Redis
还需要安装模块用于操作Redis,这个安装个低版本的,高的有些数据格式不支持,例如字典就不行的。
pip install redis==2.10.6存到Redis步骤:(Redis要提前开启哦)
和上面一样的唯一不同的地方就在第四步管道函数的编写,下面我们就把这方面重点分析一下~
1:settings中配置

2:代码编写
此代码指针对Redis缓存的,完整的需要包含上面 class CsdnPipeline 和 class MysqlPipeline 中的代码。
from redis import Redis # 导入模块class RedisPipeline:# 创建链接对象conn = Redis(host='127.0.0.1', port=6379)def process_item(self, item, spider):# 将item这个字典存储到redis中self.conn.lpush('bili', item) # lpush(参数1,参数2):参数1新建列表的名称,参数2是向列表中存储的数据return item代码分析:

Redis的比较简单,主要就是连接,按照这个写就行了,没有啥理解的,固定语法。
3:执行结果
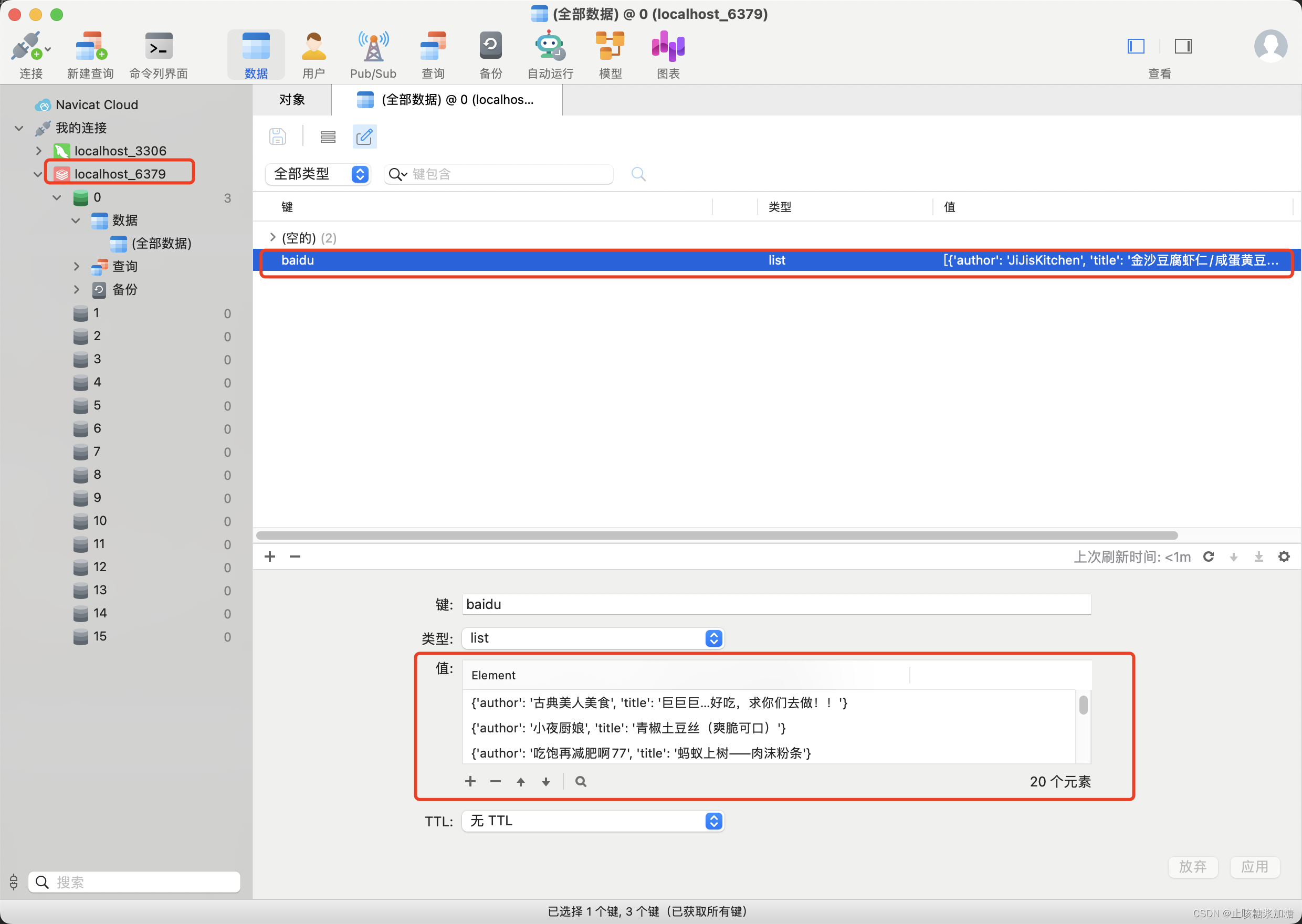
自此Scrapy框架持久化存储的2种方法就这些了,另外还有就是图片和视频的持久存储,在内置管道中讲解。
相关文章:
Scrapy爬虫异步框架之持久化存储(一篇文章齐全)
1、Scrapy框架初识(点击前往查阅) 2、Scrapy框架持久化存储 3、Scrapy框架内置管道(点击前往查阅) 4、Scrapy框架中间件(点击前往查阅) Scrapy 是一个开源的、基于Python的爬虫框架,它提供了…...
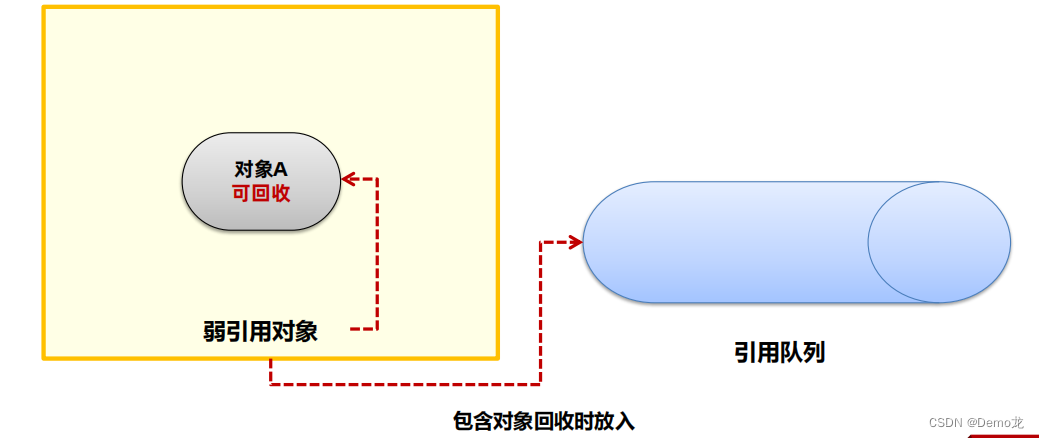
JVM——几种常见的对象引用
目录 1. 软引用软引用的使用场景-缓存 2.弱引用3.虚引用和终结器引用 可达性算法中描述的对象引用,一般指的是强引用,即是GCRoot对象对普通对象有引用关系,只要这层关系存在, 普通对象就不会被回收。除了强引用之外,Ja…...

C++期末考试选择题题库100道C++期末判断题的易错知识点复习
今天备考C,看到了一些好的复习资料,整合一起给大家分享一下 选择题 对于常数据成员,下面描述正确的是 【 B 】 A. 常数据成员必须被初始化,并且不能被修改 B. 常数据成员可以不初始化,并且不能被修改 C. 常数据成…...

使用qemu调试arm内核
参考书籍《奔跑吧Linux内核》–笨叔 下载Linux-5.0源码 https://benshushu.coding.net/public/runninglinuxkernel_5.0/runninglinuxkernel_5.0/git/files或者直接git源码 git clone https://e.coding.net/benshushu/runninglinuxkernel_5.0/runninglinuxkernel_5.0.git安装必…...

Pytorch深度学习实战2-1:详细推导Xavier参数初始化(附Python实现)
目录 1 参数初始化2 Xavier参数初始化原理2.1 前向传播阶段2.2 反向传播阶段2.3 可视化思考 3 Python实现 1 参数初始化 参数初始化在深度学习中起着重要的作用。在神经网络中,参数初始化是指为模型中的权重和偏置项设置初始值的过程。合适的参数初始化可以帮助模型…...

Java的threadd常用方法
常用API 给当前线程命名 主线程 package com.itheima.d2;public class ThreadTest1 {public static void main(String[] args) {Thread t1 new MyThread("子线程1");//t1.setName("子线程1");t1.start();System.out.println(t1.getName());//获得子线程…...
一键修复0xc000007b错误代码,科普关于0xc000007b错误的原因
最近很多用户都有遇到过0xc000007b错误的问题,出现这样的问题想必大家都会手足无措吧,其实解决这样的问题也有很简单的解决方法,这篇文章就来教大家如何一键修复0xc000007b,同时给大家科普一下关于0xc000007b错误的原因࿰…...
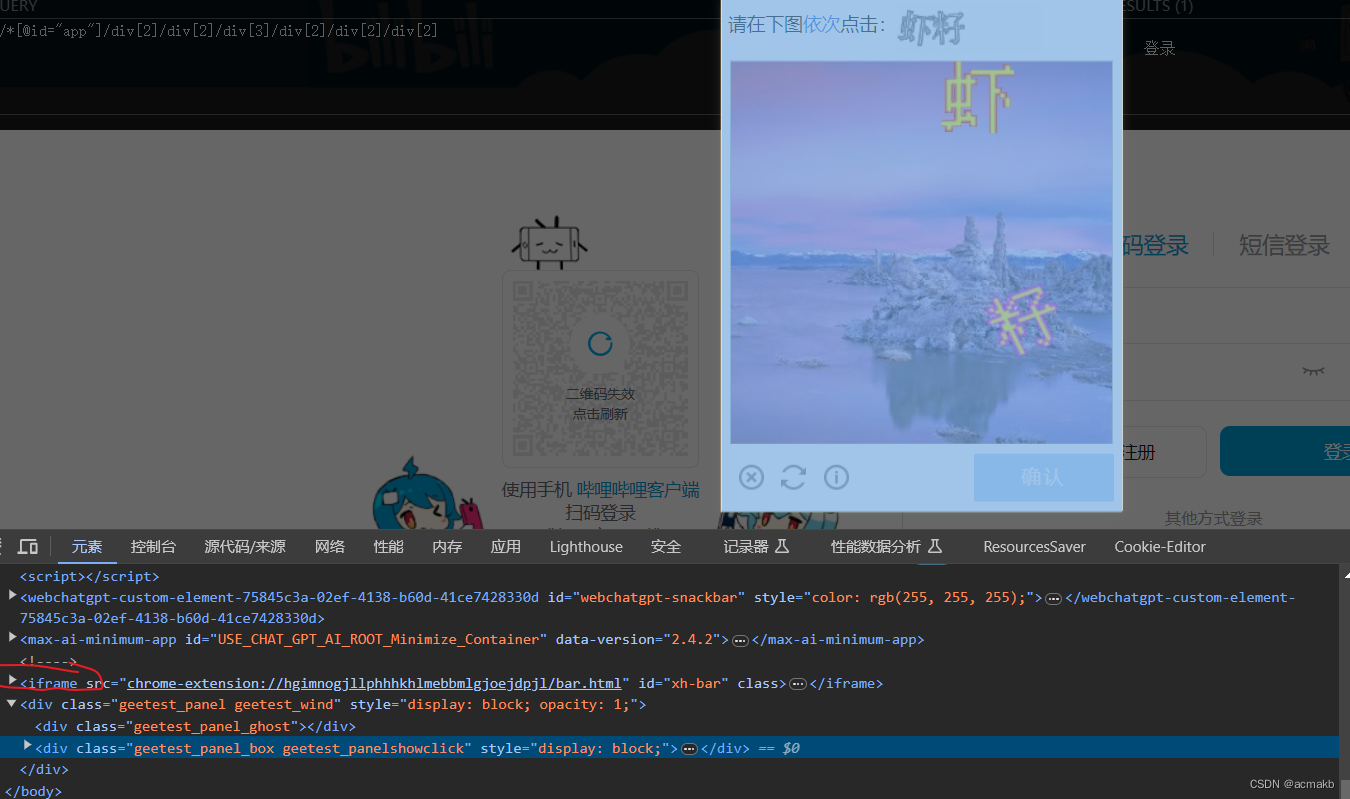
使用Selenium、Python和图鉴打码平台实现B站登录
selenium实战之模拟登录b站 基础知识铺垫: 利用selenium进行截图: driver.save_screenshot() 注意图片文件名要用png结尾. 关于移动: ActionChains(bro).move_to_element_with_offset()# 对于某个图像ActionChains(bro).move_by_offset(…...

嵌入式设备视频编码比较:H.264、H.265、MPEG-2和MJPG
在嵌入式设备领域,视频编码是一项关键技术,它能够将高清视频压缩为更小的数据量,以实现高效的存储和传输。本文将对四种常见的视频编码标准进行详细比较,包括H.264(AVC)、H.265(HEVC)…...

创意二维码案例:意大利艺术家的最新二维码艺术展!
意大利艺术家——米开朗基罗皮斯特莱托(Michelangelo Pistoletto)的个人艺术展“二维码‘说’”(QR CODE POSSESSION)正在北京798艺术区的常青艺术画廊展出,这是一次别出心裁的创意艺术展! 主要体现在3个方…...
XML映射文件
<?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace"org.mybatis.example.BlogMapper&q…...
AlDente Pro v1.22.2(mac电池最大充电限制工具)
AlDente Pro是一款适用于Mac操作系统的小工具,可以帮助您限制电池充电量以延长电池寿命。通常情况下,电池在充满的状态下会继续接受电源充电,这可能会导致电池寿命缩短。使用AlDente Pro,您可以设置电池只充到特定的充电水平&…...
原生小程序图表
原生小程序使用图表 话不多说直接进入正题 官方文档: https://www.ucharts.cn/v2/#/ 下载文件 首先去gitee上把文件下载到自己的项目中 https://gitee.com/uCharts/uCharts 找到微信小程序和里面的组件 把里面src下的文件全部下载下来放入自己项目中 项目文件 新建文件…...

UniPro集成华为云WeLink 为企业客户构建互为联接的协作平台
华为云WeLink是华为开启数字化办公体验、帮助企业实现数字化转型的实践,类似钉钉。UniPro的客户企业中,有使用WeLink作为协作工具的,基于客户的实际业务需求,UniPro实现了与WeLink集成的能力,以帮助客户企业丰富和扩展…...

【论文解读】基于生成式面部先验的真实世界盲脸修复
论文地址:https://arxiv.org/pdf/2101.04061.pdf 代码地址:https://github.com/TencentARC/GFPGAN 图片解释: 与最先进的面部修复方法的比较:HiFaceGAN [67]、DFDNet [44]、Wan 等人。[61] 和 PULSE [52] 在真实世界的低质量图像…...
蓝桥杯第四场双周赛(1~6)
1、水题 2、模拟题,写个函数即可 #define pb push_back #define x first #define y second #define int long long #define endl \n const LL maxn 4e057; const LL N 5e0510; const LL mod 1e097; const int inf 0x3f3f; const LL llinf 5e18;typedef pair…...

【Web】CmsEasy 漏洞复现
访问主页 到处点一点没啥发现 扫目录 访问/admin 账号密码都是admin admin(弱口令) 登录成功 看到左边列表有模板,心里大概有数了哈 进行一波历史漏洞的查 CmsEasy_v5.7 漏洞测试 payload1: 1111111111";}<?php phpinfo()?> payload2: 11";…...
Spring 中存储 Bean 的相关注解
Bean的存 IoC控制反转,就是将对象的控制权交给Spring的IOC容器,由IOC容器创建及管理对象。 也就是bean的存储 类注解:五大注解 Controller(控制器存储) Service(服务存储) Component(组件存储…...

Proteus下仿真AT89C51单片机串行口的问题
在Proteus下仿真AT89C51单片机的串行口的时候,Proteu不同版本下差别较大。 同样的程序,在7.8的老版本(7.8版本的原理图仿真软件名称是ISIS 7 Professional)下仿真串行口,收发均正常。但是,在8.13版…...

java学习part17
110-面向对象(高级)-关键字final的使用及真题_哔哩哔哩_bilibili 1.概念 tips:java里有const关键字,但是用于保留字,不会使用,目前没有意义。 final变量没有默认赋值,只能在以下三个地方赋值,且只能赋值一…...

GaussDB /openGauss 与 MySQL、Oracle、PostgreSQL 核心对比表
GaussDB /openGauss 与 MySQL、Oracle、PostgreSQL 核心对比表(偏选型实用版,重点看业务适配、迁移成本、国产化、性能)一、整体定位对比表格数据库定位适用场景国产化属性GaussDB企业级分布式关系库,软硬协同金融核心、政务、高并…...

Amber插件系统开发指南:如何扩展框架功能的完整教程
Amber插件系统开发指南:如何扩展框架功能的完整教程 【免费下载链接】amber A Crystal web framework that makes building applications fast, simple, and enjoyable. Get started with quick prototyping, less bugs, and blazing fast performance. 项目地址:…...
)
收藏!大模型岗位真相:看似暴涨,实则与多数程序员无关(小白必看)
一、虚假的岗位增长:AI岗位全在上游,小白根本够不到 很多程序员(尤其是刚入门的小白)都在焦虑:明明全网都在说AI风口、大模型岗位暴涨,为什么自己投简历却石沉大海?其实真相很扎心——AI岗位不是…...

DownKyi视频管理进阶指南:从新手到专家的实践路径
DownKyi视频管理进阶指南:从新手到专家的实践路径 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等࿰…...

LCD12864带字库开发实战:从引脚配置到中文显示
1. LCD12864带字库模块基础认知 第一次拿到这种带字库的液晶屏时,我盯着那20个引脚发呆了半小时。后来才发现,真正需要关注的只有7-8个关键引脚。这种128x64点阵的液晶模块最吸引人的地方在于它内置了GB2312字库,这意味着我们不需要自己造轮子…...

零基础玩转EVA-01:手把手教你用机甲AI分析图片,效果惊艳
零基础玩转EVA-01:手把手教你用机甲AI分析图片,效果惊艳 1. 初识EVA-01:你的机甲视觉助手 想象一下,你面前有一张复杂的机械设计图,或者一张充满细节的风景照片。传统的AI图片分析工具可能只会给你一段干巴巴的文字描…...

2026地学最新调剂信息:北京师范大学、合肥工业大学、兰州大学、广州大学、宁波大学等
北京师范大学文理学院(珠海):原网址:https://fas.bnu.edu.cn/zsjy/yjszs/72ce767035ea4a4cbd8ba5607569af1f.htm合肥工业大学资源与环境工程学院调剂信息:原网址:https://geoscience.hfut.edu.cn/info/1042…...

Simulink电气仿真避坑指南:为什么我的可变RLC模型总报错?可能是你源选错了
Simulink电气仿真避坑指南:可变RLC模型报错的根源与解决方案 在电力电子和电机控制仿真领域,Simulink无疑是工程师们的首选工具。但许多用户在尝试搭建可变RLC元件时,总会遇到各种莫名其妙的报错和收敛问题。这往往不是因为你的电路设计有问…...

Fish-Speech 1.5问题解决:常见错误排查,让你的TTS服务稳定运行
Fish-Speech 1.5问题解决:常见错误排查,让你的TTS服务稳定运行 1. 为什么你的Fish-Speech服务总在关键时刻掉链子? 上周我帮一个朋友排查他的语音合成服务故障,他的Fish-Speech 1.5在演示前突然罢工——WebUI能打开,…...

Nunchaku FLUX.1-dev使用手册:ComfyUI中启动、加载工作流与生成图片
Nunchaku FLUX.1-dev使用手册:ComfyUI中启动、加载工作流与生成图片 1. 环境准备与安装部署 1.1 硬件与软件要求 在开始使用Nunchaku FLUX.1-dev模型前,请确保您的系统满足以下基础要求: 硬件配置: 显卡:支持CUDA的…...