R语言——taxize(第五部分)
taxize(第五部分)
- 3. taxize 文档中译
- 3.71. nbn_synonyms(从 NBN 返回具有给定 id 的分类群名称的所有同义词)
- 3.72. ncbi_children(在 NCBI 中搜索类群的子类群)
- 3.73. ncbi_downstream(检索 NCBI 层次结构下游的所有类群名称)
- 3.74. ncbi_get_taxon_summary(从 uids 获取 NCBI 分类群信息)
- 3.75. ping(查看Taxize 中使用的 API是否正常工作)
- 3.76. plantGenusNames(ThePlantList 中的植物属名向量)
- 3.77. plantminer(从 Plantminer.com 搜索分类数据)
- 3.78. plantNames(来自 ThePlantList 的植物物种(属-种加词)名称向量)
- 3.79. pow_lookup(在邱园的《世界植物志》中查找分类群)
- 3.80. pow_search(搜索邱园的《世界植物志》)
- 3.81. pow_synonyms(在邱园《世界植物》中查找同义词)
- 3.82. rankagg(按给定的分类等级汇总数据)
- 3.83. rank_ref(分类等级 ID 查询表)
- 3.84. rank_ref_zoo(分类等级 ID 查找表(WoRMS))
- 3.85. resolve(解析来自不同数据源的名称)
- 3.86. sci2comm(根据学名获取俗名)
- 3.87. scrapenames(使用 "全球名称识别和发现 "功能解析名称)
- 3.88. species_plantarum_binomials(来自《植物物种》的物种名称)
- 3.89. status_codes(获取 HTTP 状态代码)
- 3.90. synonyms(根据输入的分类名称或标识符,从各种来源检索同义词)
- 3.91. taxize-authentication(taxize许可认证)
- 3.92. taxize-defunct(taxize 中已失效的功能)
- 3.93. taxize-params(taxize 中的参数)
- 3.94. taxize_capwords(将字符串的第一个字母大写)
- 3.95. taxize_cite(获取 taxize 中使用的数据源的引文和许可证)
- 3.96. taxize_options(taxize 中的可选项)
- 3.97. taxon-state(来自 get_* 函数调用的最后一个分类群状态对象)
- 3.98. tax_agg(按照给定的分类等级汇总物种数据)
- 3.99. tax_name(获取给定等级的分类学名称)
- 3.100. tax_rank(获取给定分类名称的等级)
- 3.101. theplantlist(ThePlantList 的科、属、种名称查询表)
- 3.102. tol_resolve(使用开放生命树 (OTL) 解析器解析名称)
- 3.103. tpl_families(获取植物名单的科名)
- 3.104. tpl_get(获取植物清单的 csv 文件)
- 3.105. tpl_search(taxonstand fxn 的轻量级封装,用于调用 Theplantlist.org 数据库)
- 3.106. tp_accnames(返回带有给定 id 的分类群名称的所有已接受名称)
- 3.107. tp_dist(返回具有给定 id 的分类群名称的所有分布记录)
- 3.108. tp_refs(返回具有给定 id 的分类群名称的所有参考记录)
- 3.109. tp_search(按学名、俗名或Tropicos ID 搜索Tropicos)
- 3.110. tp_summary(返回带有给定 id 的分类群名称的摘要数据)
- 3.111. tp_summary(返回具有给定 id 的分类群名称的所有同义词)
- 3.112. ubio_ping
- 3.113. upstream(检索给定分类群名称或 ID 的上游分类群)
- 3.114. vascan_search(搜索 CANADENSYS Vascan API)
- 3.115. worms_downstream(检索 WORMS 系统下游的所有分类群名称)
- 3.116. worrms_ranks
3. taxize 文档中译
3.71. nbn_synonyms(从 NBN 返回具有给定 id 的分类群名称的所有同义词)
用法:nbn_synonyms(id, ...)
参数:
- id:分类标识代码。
- …:传递给 crul::verb-GET 的其他参数。
返回值:数据框。
示例:nbn_synonyms(id = 'NHMSYS0001501147')
3.72. ncbi_children(在 NCBI 中搜索类群的子类群)
描述:在 NCBI 分类学数据库中搜索分类群子类的 uids。分类群可以通过名称或 uid 进行引用。在少数情况下,不同的分类群具有相同的名称(如 Satyrium)。如果搜索其中一个分类群,则会同时返回这两个分类群的子分类群。使用 uid 代替名称或指定一个祖先可以避免这种情况。如果提供了祖先,则只会返回分类群及其祖先的子代。只有在两个分类群具有相同名称和相同指定祖先的情况下,此操作才会失败。
用法:ncbi_children( name = NULL, id = NULL, start = 0, max_return = 1000, ancestor = NULL, out_type = c("summary", "uid"), ambiguous = FALSE, key = NULL, ... )
参数:
- name:要搜索的字符串。只返回与所给名称完全匹配的结果。与 id 不兼容。
- id:要搜索的 uid。与name不兼容。
- start:要返回的第一条记录。如果省略,则从第一条记录开始返回结果(start=0)。
- max_return:返回子类群的最大数量。
- ancestor:所搜索分类群的祖先。如果同名的分类群可能不止一个,这将非常有用。如果使用 id 则无效。
- out_type:目前为 "summary "或 “uid”:
- summary:输出结果是一个 data.frame 列表,其中包含子类群 uid、name 和
rank。 - uid:子类群 uids 字符向量列表。
- summary:输出结果是一个 data.frame 列表,其中包含子类群 uid、name 和
- ambiguous:如果为 FALSE,则会从输出中删除带有 “未分类”、“未知”、"未培养 "或 "sp. "等字样的子类群。注意:该选项仅适用于 out_type= "summary "时。
- key:NCBI Entrez API 密钥。
- …:传递给 crul::HttpClient 的 Curl 选项。
返回值:输出类型取决于 out_type 参数的值。找不到分类群的结果是 NA,没有子类的结果是空数据结构。
HTTP版本:我们硬编码 http_version = 2L,以便在向 Entrez API 发送 HTTP 请求时使用 HTTP/1.1。参见 curl::curl_symbols(‘CURL_HTTP_VERSION’)。
请求速率限制:如果因超出速率限制而出错,请参阅 taxize_options(),您可以在其中设置 ncbi_sleep。
示例:ncbi_children(name="Satyrium")
3.73. ncbi_downstream(检索 NCBI 层次结构下游的所有类群名称)
用法:ncbi_downstream(id, downto, intermediate = FALSE, ...)
参数:
- id:一个 NCBI 分类标识符。
- downto:您希望深入到的分类级别。分类级别区分大小写,必须拼写正确。拼写请参见 data(rank_ref)。
- intermediate:如果为 “true”,则返回包含目标分类群等级名称的长度为 2 的列表,以及中间分类群的附加 data.frame 列表。默认值: FALSE。
- …:传递给 ncbi_children()的其他参数。
返回值:从目、类等科向下分类的分类信息数据框,或者,如果中间名=TRUE,长度为 2 的列表,包含目标分类群等级名称和中间名。
示例:ncbi_downstream(id = 7459, downto="species")
3.74. ncbi_get_taxon_summary(从 uids 获取 NCBI 分类群信息)
描述:使用 eutils esummary 从 NCBI 分类数据库下载一组分类 UID 的分类群摘要信息。
用法:ncbi_get_taxon_summary(id, key = NULL, ...)
参数:
- id:NCBI的分类uids,以检索相关信息。
- key:NCBI Entrez API 密钥。
- …:传递给 crul::verb-GET 的其他参数。
说明:如果输入向量或 NCBI ID 列表长度超过约 2500 个字符(使用 nchar(paste(ids, collapse = “+”)) ),请将列表分割成若干块,因为大约达到这个字符数时,就会出现 HTTP 414 错误 “Request-URI Too Long”。
返回值:一个包含以下列的 data.frame:
- uid:查询到的 uid。
- name:分类群名称;如果分类群属于物种,则为二项式名称。
- rank:分类等级(如 “属”)。
HTTP版本:我们硬编码 http_version = 2L,以便在向 Entrez API 发送 HTTP 请求时使用 HTTP/1.1。参见 curl::curl_symbols(‘CURL_HTTP_VERSION’)。
示例:ncbi_get_taxon_summary(c(1430660, 4751))
3.75. ping(查看Taxize 中使用的 API是否正常工作)
用法:
col_ping(what = "status", ...)eol_ping(what = "status", ...)itis_ping(what = "status", ...)ncbi_ping(what = "status", key = NULL, ...)tropicos_ping(what = "status", ...)nbn_ping(what = "status", ...)gbif_ping(what = "status", ...)bold_ping(what = "status", ...)ipni_ping(what = "status", ...)vascan_ping(what = "status", ...)fg_ping(what = "status", ...)
参数:
- what:status(默认)、content或 HTTP 状态代码之一。如果是 status、
我们只检查 HTTP 状态代码是否为 200,或类似表示服务已启动的代码。如果是content,我们会进行简单快速的检查,以确定返回的内容是否符合预期。如果是 HTTP 状态代码,则必须与适当的代码相匹配。请参见 status_codes()。 - …:传递给 crul::verb-GET 的其他参数。
- key:NCBI Entrez API 密钥。
返回值:TRUE or FALSE。
HTTP版本:我们硬编码 http_version = 2L,以便在向 Entrez API 发送 HTTP 请求时使用 HTTP/1.1。参见 curl::curl_symbols(‘CURL_HTTP_VERSION’)。
示例:col_ping("content")
3.76. plantGenusNames(ThePlantList 中的植物属名向量)
描述:这些名称来自 http://www.theplantlist.org,是随机选择的属名子集,目的是为本软件包中的示例提供一些名称。
格式:长度为793的向量。
3.77. plantminer(从 Plantminer.com 搜索分类数据)
用法:plantminer(plants, from = "tpl", messages = TRUE, ...)
参数:
- plants:植物物种名称矢量。必填。
- from:tpl(用于 theplantlist.com 数据)或 flora(用于巴西植物清单)之一。必须使用。默认值:tpl。
- message:是否提供了信息。默认为TRUE。
- …:传递给 crul::HttpClient 的 Curl 选项。
返回值:结果的数据框。
示例:plantminer("Ocotea pulchella")
3.78. plantNames(来自 ThePlantList 的植物物种(属-种加词)名称向量)
描述:这些名称来自 http://www.theplantlist.org,是随机选择的属/种加词形式的名称子集,目的是为本软件包中的示例提供一些名称。
格式:长度为 1182 的向量。
3.79. pow_lookup(在邱园的《世界植物志》中查找分类群)
用法:pow_lookup(id, include = NULL, ...)
参数:
- id:需要分类群 ID。
- include:要包含在结果中的附加字段的向量。选项包括 "distribution"和 “descriptioins”。
- …:传递给 crul::HttpClient 的 其他参数。
示例:pow_lookup(id = 'urn:lsid:ipni.org:names:320035-2')
3.80. pow_search(搜索邱园的《世界植物志》)
用法:pow_search(sci_com, limit = 100, cursor = "*", sort = NULL, q = NULL, ...)
参数:
- sci_com:查询词、学名或俗名。
- limit:要返回的记录数。默认值:100。
- cursor:字符串光标。
- sort:要排序的字段和排序顺序,以下划线隔开,例如,sort=“name_desc”。
- q:已弃用,请使用sci_com。
- …:传递给 crul::HttpClient 的 其他参数。
返回值:一个列表,其中的元数据 (meta) 插槽包含响应属性列表,数据 (data) 插槽包含结果的 data.frame。
示例:pow_search(sci_com = "sunflower", limit = 2)
3.81. pow_synonyms(在邱园《世界植物》中查找同义词)
用法:pow_synonyms(id, ...)
用法:
- id:需要分类群 ID。
- …:传递给 pow_lookup()的其他参数。
示例:pow_synonyms(id = 'urn:lsid:ipni.org:names:320035-2')
3.82. rankagg(按给定的分类等级汇总数据)
用法:rankagg(data = NULL, datacol = NULL, rank = NULL, fxn = "sum")
参数:
- data:一个 data.frame。列标题必须大写(如属、族等)。
- datacol:数据列。
- rank:按分类等级汇总。
- fxn:算法函数或向量或函数。
示例:rankagg(data=dat, datacol="abundance", rank="Genus")
3.83. rank_ref(分类等级 ID 查询表)
描述:数据框共 46 行,2 列:
- rankid:一个连续的数字等级标识。
- ranks:以逗号分隔的矢量,这些名称在行内被认为彼此相等。
说明:
- 我们使用这个 data.frame 根据等级排序进行数据排序/筛选。
- 如果其中一个数据源 taxize 中出现了 rank_ref 数据集中没有的 rank,请告知我们。
- 如果您对等级排序有异议,请告诉我们。
- 请注意,rankid 280 本质上是 “遗传变异”;放在 "未指定 "之上,表示它们并非没有等级,但也不是真正的分类等级。据我所知,这些 "遗传变异 "类型是无法区分的。
3.84. rank_ref_zoo(分类等级 ID 查找表(WoRMS))
描述:与 rank_ref 相同,但特别适用于 WoRMS,在 WoRMS 中,组/亚组的等级被放在科/目之间,而不是放在种/属之间。
3.85. resolve(解析来自不同数据源的名称)
描述:通过 iPlant 的名称解析器和全球名称解析器 (GNR) 解析名称。
用法:resolve(sci, db = "gnr", query = NULL, ...)
参数:
- sci:一个或多个分类名称的向量(不支持俗名)。
- db:检查名称的来源。默认值:gnr。 请注意,每个分类数据源都有自己的标识符,因此如果您为标识符提供了错误的 db 值,您可能会得到一个结果,但很可能是错误的(不是您所期望的)。
- query:已弃用,请使用sci。
- …:传递给 crul::verb-GET 或 crul::verb-POST 的 Curl 选项。此外,每个函数都会传递更多命名参数。
返回值:长度等于 db 参数长度(请求的数据源数量)的列表,每个元素都是包含该数据源结果的 data.frame 或列表。
示例:resolve(sci=c("Helianthus annuus", "Homo sapiens"))
3.86. sci2comm(根据学名获取俗名)
用法:
sci2comm(...)## Default S3 method:
sci2comm(sci, db = "ncbi", simplify = TRUE, scinames = NULL, ...)## S3 method for class 'uid'
sci2comm(id, ...)## S3 method for class 'tsn'
sci2comm(id, simplify = TRUE, ...)## S3 method for class 'wormsid'
sci2comm(id, simplify = TRUE, ...)## S3 method for class 'iucn'
sci2comm(id, simplify = TRUE, ...)
参数:
- …:传递给函数 get_uid()、get_tsn() 的其他参数。
- sci:一个或多个学名或部分名称。
- db:数据源,“ncbi”(默认)、“itis”、“eol”、"worms "或 "iucn "之一。请注意,每个分类数据源都有自己的标识符,因此如果您为标识符提供了错误的 db 值,您可能会得到一个结果,但很可能是错误的(不是您所期望的)。如果使用 ncbi 或 iucn,我们建议您获取一个 API 密钥;请参阅 taxize-authentication。
- simplify:如果为 TRUE,则将输出简化为名称向量。如果为 FALSE,则返回不同来源的变量格式,通常是 data.frame。仅适用于 eol 和 itis。指定 FALSE 时,将在 eol 和 itis 的输出中获取每种方言的语言。
- scinames:已弃用,请使用sci。
- id:由 get_tsn()、get_uid()返回的标识符。
返回值:按输入分类群名称或分类群 ID 命名的字符向量列表。 character(0) 表示不匹配。
NCBI请求的HTTP版本:本方法硬编码了http_version=2L以便让HTTP请求使用HTTP/1.1访问Entrez API。详见curl::curl_symbols(“CURL_HTTP_VERSION”)。
示例:sci2comm(sci='Helianthus annuus')
3.87. scrapenames(使用 "全球名称识别和发现 "功能解析名称)
描述:使用全球名称识别和发现服务,请参见 http://gnrd.globalnames.org/ 注意:该函数有时会返回数据,有时不会。该函数的应用程序接口存在严重缺陷。
用法:scrapenames( url = NULL, file = NULL, text = NULL, engine = NULL, unique = NULL, verbatim = NULL, detect_language = NULL, all_data_sources = NULL, data_source_ids = NULL, return_content = FALSE, ... )
参数:
- url:网页、PDF、Microsoft Office 文档或图像文件的编码 URL。
- file:当使用 multipart/form-data 作为内容类型时,可能会发送一个文件。这应该是您机器上文件的路径。
- text:文本内容;最好与 POST 请求一起使用。
- engine:默认值:0。1 表示 TaxonFinder,2 表示 NetiNeti,或 0 表示两者。如果没有,则两个引擎都使用。
- unique:如果为 TRUE(默认值),则响应具有不带偏移的唯一名称。
- verbatim:如果为 TRUE(默认为 FALSE),响应将排除verbatim字符串。
- detect_language:TRUE 时(默认),如果输入文本的语言被确定为非英语,则不会使用 NetiNeti。当 FALSE 时,如有要求,将使用 NetiNeti。
- all_data_sources:根据所有可用数据源解析找到的名称。
- data_source_ids:用管道分隔的数据源 id 列表,用于解析找到的名称。请参见数据源列表 http://resolver.globalnames.org/data_sources。
- return_content:返回经 OCR 处理的文本。返回 x m e t a meta metacontent 插槽中的文本字符串。默认值: FALSE。
- …:传递给 crul::verb-GET 的其他参数。
说明:必须指定 url、文件或文本中的一个,且只能指定其中一个。
返回值:长度为 2 的列表,第一个是元数据,第二个是作为 data.frame 的数据。
示例:scrapenames('https://en.wikipedia.org/wiki/Spider')
3.88. species_plantarum_binomials(来自《植物物种》的物种名称)
描述:这些名称是根据卡尔-林奈(Carl Linnaeus)最初于 1753 年出版的《植物志》(Species Plantarum)汇编而成的。这是第一部统一使用双名的著作,也是植物命名的起点。该书列出了当时已知的所有植物物种,并按属进行了分类。该数据集提供了一个有用的参考点,可用于了解分类学名称自诞生以来的变化情况。这些名称由 Robert W. Kiger 抄录。
格式:一个包含 5940 行和 3 个变量的数据框:
- genus:属中每个物种的双名物种名的第一部分。
- epithet:每个物种的种加词或双名物种名称的第二部分。
- page_number:页码字段有时会使用以下缩写。
- add.:指出现在第二卷索引最后一页无编号的增编。
- err.:指第二卷索引之后的无编号勘误页。
- canc.:在页码之后,表示该二项式出现在该页的注销版上,而不出现在其替代版上(如 1957-1959 年传真版)。
3.89. status_codes(获取 HTTP 状态代码)
用法:status_codes()
示例:status_codes()
3.90. synonyms(根据输入的分类名称或标识符,从各种来源检索同义词)
用法:
synonyms(...)## Default S3 method:
synonyms(sci_id, db = NULL, rows = NA, x = NULL, ...)## S3 method for class 'tsn'
synonyms(id, ...)## S3 method for class 'tpsid'
synonyms(id, ...)## S3 method for class 'nbnid'
synonyms(id, ...)## S3 method for class 'wormsid'
synonyms(id, ...)## S3 method for class 'iucn'
synonyms(id, ...)## S3 method for class 'pow'
synonyms(id, ...)## S3 method for class 'ids'
synonyms(id, ...)synonyms_df(x)
参数:
- …:传递给内部函数 get_*() 和收集同义词函数的其他参数。
- sci_id:分类群名称(字符)或 ID(字符或数字)向量。
- db:要查询的数据库。可以是 itis、tropicos、nbn、worms 或 pow。请注意,每个分类数据源都有自己的标识符,因此如果您提供了错误的标识符 db 值,您可能会得到一个结果,但很可能是错误的(不是您所期望的)。如果使用 tropicos,建议获取一个 API 密钥;请参阅 taxize-authentication。
- rows:从 1 到无穷大的任意数字。如果默认为 NA,则所有行都会被考虑。请注意,如果您输入的分类标识符属于以下任何可接受的类别:tsn、tpsid、nbnid、ids,则该参数将被忽略。
- x:对于 synonyms():已弃用,参见 sci_id。对于 synonyms_df(),synonyms()的输出结果。
- id:标识符,由 get_tsn()、get_tpsid()、get_nbnid()、get_wormsid()、get_pow() 返回。
说明:如果直接提供 ID(而不是通过 get_*()函数),则必须指定 ID 的类型。对于 db = “itis”,您可以通过参数 accepted 来切换是否只使用 accepted = TRUE 或全部使用 accepted = FALSE。默认为 accepted = FALSE 注意 IUCN 需要一个 API 密钥。请参阅 rredlist::rredlist-package,了解如何使用 IUCN Redlist 自动识别。
返回值:一个已命名的结果列表,每个槽中有三种类型的输出:
- 如果未找到该名称: NA_character_。
- 如果找到了名称但没有找到同义词,则显示空 data.frame(0 行)。
- 如果找到了名称,并且找到了同义词,则会生成包含同义词的 data.frames(列名称因数据源而异)。
示例:synonyms(183327, db="itis")
3.91. taxize-authentication(taxize许可认证)
什么是API:API 是应用程序编程接口。API "一词可用于多种情况,但在本例中我们讨论的是网络 API 或网络资源的 API(接口)。taxize 通过网络 API 与远程数据库交互。你不需要关心所有工作原理的细节,只需知道其中有些需要身份验证,有些则不需要。
什么是API 密钥:对于那些需要身份验证的 API,通常是通过 API 密钥来完成身份验证的:长度可变的字母数字字符串,在请求 API 时提供。taxize 不会为你获取这些密钥;相反,你必须为每个服务获取一个密钥,但我们确实提供了如何获取这些密钥的信息。请参阅 key_helpers(),了解如何获取此软件包的密钥。
使用API 密钥:你可以将 API 密钥作为 R 选项存储在 .Rprofile 文件中,或者作为环境变量存储在 .Renviron 文件或 .bash_profile 文件、o.zshrc 文件(如果使用 oh-my-zsh)或类似文件中。。用以下名称保存 API 密钥:
- Tropicos:R 选项或环境变量为 “TROPICOS_KEY”。
- IUCN:R 选项或环境变量为 “IUCN_REDLIST_KEY”。
- ENTREZ:R 选项或环境变量为 “ENTREZ_KEY”。
如果保存为 .Renviron,看起来就像这样: ENTREZ_KEY=somekey。
如果保存在 .bash_profile、.zshrc 或类似文件中,它看起来像: export ENTREZ_KEY=somekey。
如果保存在 .Rprofile 中,它看起来像: options(ENTREZ_KEY = “somekey”)。
记住重新启动 R 会话(如果使用 shell,则启动新的 shell 窗口/标签页),以利用新的 R 选项或环境变量。
我们强烈建议使用环境变量 (https://en.wikipedia.org/wiki/Environment_variable) 而不是 R 选项,因为环境变量广泛应用于各种编程语言、操作系统和计算环境;而 R 选项则是 R 的专用选项。
请注意,NCBI Entrez 并不要求您使用 API 密钥,但使用密钥可获得更高的速率限制(每段时间内的请求次数更多),从每秒 3 次到 10 次不等,因此请务必获得一个。
3.92. taxize-defunct(taxize 中已失效的功能)
描述:以下功能现已停用(不再可用):
- 所有 COL 函数均已失效:as.colid、col_children、col_classification、col_downstream、col_search、get_colid、get_colid_、as.data.frame.colid、children.colid、classification.colid、downstream.colid、id2name.colid、lastest_common.colid、synonyms.colid、upstream.colid。
- col_classification():参考classification()。
- tp_classification():参考classification()。
- eol_hierarchy():参考classification()。
- eol_invasive():参见 originr 软件包中的 eol。
- use_eol():EOL 不再需要 API 密钥。
- tpl_search():直接使用Taxonstand 的TPL或TPLck。
- get_seqs():此函数更名为 toncbi_getbyname()。
- get_genes():此函数更名为 toncbi_getbyid()。
- get_genes_avail():此函数更名为 toncbi_search()。
- ncbi_getbyname():参见 traits 软件包中的 ncbi_byname。
- ncbi_getbyid():参见 traits 软件包中的 ncbi_byid。
- ncbi_search():参见 traits 软件包中的 ncbi_searcher。
- gisd_isinvasive():参见 originr 软件包中的 gisd。
- ubio_classification():uBio 网络服务曾中断过一段时间,现在(截至 2016-05-09)已恢复正常,但我们不相信它能一直保持正常可用。
- ubio_classification_search():uBio 网络服务曾中断过一段时间,现在(截至 2016-05-09)已恢复正常,但我们不相信它能一直保持正常可用。
- ubio_id():uBio 网络服务曾中断过一段时间,现在(截至 2016-05-09)已恢复正常,但我们不相信它能一直保持正常可用。
- ubio_ping():uBio 网络服务曾中断过一段时间,现在(截至 2016-05-09)已恢复正常,但我们不相信它能一直保持正常可用。
- ubio_search():uBio 网络服务曾中断过一段时间,现在(截至 2016-05-09)已恢复正常,但我们不相信它能一直保持正常可用。
- ubio_synonyms():uBio 网络服务曾中断过一段时间,现在(截至 2016-05-09)已恢复正常,但我们不相信它能一直保持正常可用。
- get_ubioid():uBio 网络服务显然已无限期关闭。
- phylomatic_tree():该函数已失效。参见软件包 brranching 中的 phylomatic。
- phylomatic_format():该函数已失效。参见软件包 brranching 中的 phylomatic_names。
- iucn_summary_id():此函数已失效。使用 iucn_summary()。
- eubon():该函数已失效。使用 eubon_search()。
- tnrs():该功能已失效。太不可靠。
- tnrs_sources():该功能已失效。太不可靠。
3.93. taxize-params(taxize 中的参数)
描述:关于整个包的标准化参数信息。
标准化参数:
- sci:科学名(scientific)。
- com:俗名(common)。
- id:名称标识符。
- sci_com:科学名或俗名。
- sci_id:科学名或标识符。
我们本打算为参数接受学名、俗名或名称标识符这三种选项中的任何一种的情况统一参数名称。但是,在这种情况下,我们无法使用明确的参数名称,因此我们保留了两种情况下(get_ids() 和 vascan_search())的参数名称。
3.94. taxize_capwords(将字符串的第一个字母大写)
用法:taxize_capwords(s, strict = FALSE, onlyfirst = FALSE)
参数:
- s:字符串。
- strict:算法是否应严格控制大写字母的大小写。默认为 FALSE。
- onlyfirst:第一个字大写,其他字小写。适用于分类名称。
示例:taxize_capwords(c("using AIC for model selection"))
3.95. taxize_cite(获取 taxize 中使用的数据源的引文和许可证)
用法:taxize_cite(fxn = "itis", what = "citation")
参数:
- fxn:功能进行搜索。一个特例是软件包名称 “taxize”,它会给出软件包的引用。
- what:citation(默认)、license或两者之一。
示例:taxize_cite(fxn='eol_search')
3.96. taxize_options(taxize 中的可选项)
用法:taxize_options(taxon_state_messages = NULL, ncbi_sleep = NULL, quiet = FALSE)
参数:
- taxon_state_messages:抑制信息?NULL(与设置 FALSE 相同)。设置为 TRUE 表示抑制信息,设置为 FALSE 表示不抑制信息。
- ncbi_sleep:NCBI ENTREZ http 请求之间的休眠秒数。适用于以下函数:classification()、comm2sci()、genbank2uid()、get_uid() 和 ncbi_children()。默认值: 0.334(不含 API 密钥)或 0.101(含 API 密钥)。最小值不能小于 0.101。
- quiet:该函数的静音信息输出: TRUE。
示例:taxize_options()
3.97. taxon-state(来自 get_* 函数调用的最后一个分类群状态对象)
用法:
taxon_last()
taxon_clear()
说明:
- taxon_last():获取最后一个正在使用的taxon_state对象。
- taxon_clear():清除最后一个taxon_state对象中的所有数据。
taxon_state 对象是一个 R6 对象,用于保存数据和方法,以跟踪 get_* 函数中收集的结果。您不应该自行创建 taxon_state R6 对象。
需要注意的行为:
- 如果没有传递 taxon_state 对象,就不必担心先前运行的 get_* 函数会干扰另一个 get_* 函数的调用 - 要使用 taxon_state,必须明确传递 taxon_state 对象。
- 传入的 taxon_state 对象的 $class 必须与调用 get_* 函数的 $class 匹配。例如,只能向 get_gbifid()传递 $class 为 gbifid 的 taxon_state,以此类推。
- 如果在 get* 函数运行时运行 taxon_clear(),可能会丢失该软件包在清除前的任何已知状态。
有关如何控制 get* 函数中的信息,请参阅内部方法 progressor。
返回值:taxon_last() 返回最后使用的 taxon_state 类对象,否则返回 NULL(如果没有找到)。
taxon_clear() 清除保存的状态。
3.98. tax_agg(按照给定的分类等级汇总物种数据)
用法:
tax_agg(x, rank, db = "ncbi", messages = FALSE, ...)## S3 method for class 'tax_agg'
print(x, ...)
参数:
- x:群落数据矩阵。分类群在列,样本在行。
- rank:按分类等级汇总。
- db:要使用的分类 API,“ncbi”、"itis "或两者,请参阅 tax_name()。请注意,每个分类数据源都有自己的标识符,因此如果您为标识符提供了错误的 db 值,您可能会得到一个结果,但很可能是错误的(不是您所期望的)。如果使用 ncbi,我们建议您获取一个 API 密钥;请参阅 taxize-authentication。
- messages:如果为 FALSE(默认),则抑制信息。
- …:传递给 get_tsn() 或 get_uid() 的其他参数。
说明:tax_agg 将分类群聚合(求和)到特定的分类级别。如果在数据库(ITIS 或 NCBI)中找不到某个分类群,或者所提供的分类群属于更高的分类学级别,则不会汇总该分类群。
返回值: tax_agg 类的列表,包含以下项目:
- x:汇总数据的群落数据矩阵。
- by:显示分类群汇总情况的查找表。
- n_pre:汇总前的分类群数量。
- rank:分类群汇总的等级。
3.99. tax_name(获取给定等级的分类学名称)
用法:tax_name( sci, get, db = "itis", pref = "ncbi", messages = TRUE, query = NULL, ... )
参数:
- sci:要查询的分类名称向量。
- get:要获取的分类名称的等级,参见 rank_ref。
- db:要搜索的数据库:“Itis”、"NCBI "或 “两者”。如果是 “两者”,将同时查询 NCBI 和 ITIS。结果将是两者的结合。如果使用 ncbi,建议获取一个 API 密钥;请参阅 taxize-authentication。
- pref:如果 db =“both”,则设置联合的首选项。可以是 “ncbi”(默认)或 “itis”。目前尚未实现。
- messages:如果为 “true”,则在控制台中打印实际查询的分类群。
- query:已弃用,参见 sci。
- …:传递给 get_tsn() 或 get_uid() 的其他参数。
返回值:一个 data.frame,除了 db 和查询词列外,每个查询等级都有一列。
注意:tax_rank() 返回分类群的实际等级,而 tax_name() 则搜索并返回分类群中任何指定的更高等级。
示例:tax_name(sci = "Helianthus annuus", get = "family", db = "itis")
3.100. tax_rank(获取给定分类名称的等级)
用法:tax_rank(sci_id, db = NULL, rows = NA, x = NULL, ...)
参数:
- sci_id:要查询的一个或多个分类群名称(字符)或 ID(字符或数字)的向量。或从 get_*()函数(如 get_tsn())返回的对象。
- db:要查询的数据库:ncbi、itis、eol、tropicos、gbif、nbn、worms、natserv、bold。请注意,每个分类数据源都有自己的标识符,因此如果您为标识符提供了错误的数据库值,您可能会得到一个结果,但很可能是错误的(不是您所期望的)。如果使用 ncbi,我们建议您获取一个 API 密钥;请参阅 taxize-authentication。
- rows:从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。
- x:已弃用,参见 sci_id。
- …:classification()的其他参数。
返回值:带等级的字符向量命名列表(全部小写)。
注意:tax_name() 返回指定等级的名称,而 tax_rank() 则返回分类群的实际等级。
示例:tax_rank("Helianthus annuus", db = "itis")
3.101. theplantlist(ThePlantList 的科、属、种名称查询表)
描述:这些名称来自 http://www.theplantlist.org,是 1.1 版的数据。函数 names_list() 使用了这些数据。这是从 Theplantlist 中约 35 万个已被接受的物种名称中随机选择的一个子集。
格式:一个包含 10,000 行和 3 个变量的数据框:
- family:科名。
- genus:属名。
- species:种加词。
3.102. tol_resolve(使用开放生命树 (OTL) 解析器解析名称)
用法:tol_resolve( names = NULL, context_name = NULL, do_approximate_matching = TRUE, ids = NULL, include_suppressed = FALSE, ... )
参数:
- names:要查询的分类群名称。
- context_name:要搜索的分类上下文的名称(长度为一个字符的向量)。必须与 rotl::tnrs_contexts() 返回的值之一相匹配(区分大小写)。
- do_approximate_matching:表示是否执行近似字符串(又称 “模糊”)匹配的逻辑值。使用 FALSE 会大大提高匹配速度。默认值:TRUE。
- ids:用于识别名称的 OTL id 数组。这些 ID 将分配给 names 数组中的每个名称。如果提供了 ids,则 ids 和名称的长度必须相同。
- include_suppressed:通常情况下,TNRS 结果会忽略一些拟类群,如现行标准桶和其他非 OTU。如果该参数为 true,则允许这些拟类群作为可能的 TNRS 结果。默认值: FALSE。
- …:在 rotl::tnrs_match_names()中传递给 httr::POST 的 Curl 选项。
返回值:汇总查询结果的数据框。原始查询输出作为属性附加到返回对象中(可使用 attr(object, “original_response”)获取)。
示例:tol_resolve(c("Hyla", "Salmo", "Diadema", "Nautilus"))
3.103. tpl_families(获取植物名单的科名)
用法:tpl_families(...)
参数:…:传递给 crul::verb-GET 的 Curl 选项。
说明:需要互联网连接,才能连接到 <www.theplantlist.org>。
返回值:返回一个 data.frame,其中包括《植物名录》索引的所有科的名称及其所属的主要类群(即Angiosperms, Gymnosperms, Bryophytes and Pteridophytes)。
示例:head(tpl_families())
3.104. tpl_get(获取植物清单的 csv 文件)
用法:tpl_get(x, family = NULL, ...)
参数:
- x:csv 文件的写入目录。
- family:如果您只想要一个或大于 1 个科,而不是全部,请将它们列在一个向量中。
- …:传递给 crul::verb-GET 的 Curl 选项。
说明:如果您已经有一个与所提供目录相同的目录,则会抛出警告,但仍可正常工作。写入你的主目录,根据需要更改 x。
返回值:除了信息和进度条外,不会向控制台返回任何信息。将 csv 文件写入 x。
3.105. tpl_search(taxonstand fxn 的轻量级封装,用于调用 Theplantlist.org 数据库)
用法:tpl_search()
3.106. tp_accnames(返回带有给定 id 的分类群名称的所有已接受名称)
用法:tp_accnames(id, key = NULL, ...)
参数:
- id:分类标识代码。
- key:您的 Tropicos API 密钥;有关验证的帮助,请参见 taxize-authentication。
- …:传递给 crul::verb-GET 的 Curl 选项。
示例:tp_accnames(id = 25503923)
3.107. tp_dist(返回具有给定 id 的分类群名称的所有分布记录)
用法:tp_dist(id, key = NULL, ...)
参数:
- id:分类标识代码。
- key:您的 Tropicos API 密钥;有关验证的帮助,请参见 taxize-authentication。
- …:传递给 crul::verb-GET 的 Curl 选项。
返回值:两个 data.frame 的列表,一个名为 “location”,另一个名为 “reference”。
3.108. tp_refs(返回具有给定 id 的分类群名称的所有参考记录)
用法:tp_refs(id, key = NULL, ...)
参数:
- id:分类标识代码。
- key:您的 Tropicos API 密钥;有关验证的帮助,请参见 taxize-authentication。
- …:传递给 crul::verb-GET 的 Curl 选项。
返回值:列表或数据框。
3.109. tp_search(按学名、俗名或Tropicos ID 搜索Tropicos)
用法:tp_search( sci = NULL, com = NULL, nameid = NULL, orderby = NULL, sortorder = NULL, pagesize = NULL, startrow = NULL, type = NULL, key = NULL, name = NULL, commonname = NULL, ... )
参数:
- sci:学名。
- com:俗名。
- nameid:搜索字符串。
- orderby:搜索字符串。
- sortorder:搜索字符串。
- pagesize:搜索字符串。
- startrow:搜索字符串。
- type:搜索类型,“wildcard”(默认)将在搜索字符串末尾添加一个通配符。"exact"将精确使用搜索字符串。
- key:您的 Tropicos API 密钥;有关验证的帮助,请参见 taxize-authentication。
- name:已弃用,请使用sci。
- commonname:已弃用,请使用com。
- …:传递给 crul::HttpClient 的其他参数。
返回值:列表或数据框。
3.110. tp_summary(返回带有给定 id 的分类群名称的摘要数据)
用法:tp_summary(id, key = NULL, ...)
参数:
- id:分类标识代码。
- key:您的 Tropicos API 密钥;有关验证的帮助,请参见 taxize-authentication。
- …:传递给 crul::verb-GET 的 Curl 选项。
返回值:数据框。
示例:tp_summary(id = 25509881)
3.111. tp_summary(返回具有给定 id 的分类群名称的所有同义词)
用法:tp_synonyms(id, key = NULL, ...)
参数:
- id:分类标识代码。
- key:您的 Tropicos API 密钥;有关验证的帮助,请参见 taxize-authentication。
- …:传递给 crul::verb-GET 的 Curl 选项。
返回值:列表或数据框。
示例:tp_synonyms(id = 25509881)
3.112. ubio_ping
用法:ubio_ping()
3.113. upstream(检索给定分类群名称或 ID 的上游分类群)
描述:该函数使用 while 循环不断收集分类群,直至您在 upto 参数中指定的分类等级。目前只能从 ITIS (itis) 获取数据。itis 没有公开用于获取特定分类等级的分类群的方法,因此我们要在函数内自行完成。
用法:
upstream(...)## Default S3 method:
upstream(sci_id, db = NULL, upto = NULL, rows = NA, x = NULL, ...)## S3 method for class 'tsn'
upstream(sci_id, db = NULL, upto = NULL, ...)## S3 method for class 'ids'
upstream(sci_id, db = NULL, upto = NULL, ...)
参数:
- …:传递给 itis_downstream()的其他参数。
- sci_id:要查询的分类群名称(字符)或 ID(字符或数字)向量。
- db:要查询的数据库。一个或两个都是itis。请注意,每个分类数据源都有自己的标识符,因此如果您为标识符提供了错误的数据库值,您可能会得到一个结果,但很可能是错误的(不是您所期望的)。
- upto:在分类学中属于什么级别。One of: ’superkingdom’, ’kingdom’, ’subkingdom’,’infrakingdom’,’phylum’,’division’,’subphylum’, ’subdivision’,’infradivision’, ’superclass’,’class’,’subclass’,’infraclass’, ’superorder’,’order’,’suborder’,’infraorder’,’superfamily’,’family’, ’subfamily’,’tribe’,’subtribe’,’genus’,’subgenus’, ’section’,’subsection’, ’species’,’subspecies’,’variety’,’form’,’subvariety’,’race’, ’stirp’, ’morph’,’aberration’,’subform’, or ’unspecified’。
- rows:从 1 到无穷大的任意数字。如果默认值为 NA,则所有行都会被考虑。请注意,如果您输入的分类id属于以下任何可接受的类别,该参数将被忽略:tsn。
- x:已弃用,请输入sci_id。
返回值:包含所提供分类群上游名称的 data.frames 命名列表。如果数据库中没有匹配项,则会得到一个 NA。
示例:upstream('Pinus contorta', db = 'itis', upto = 'genus')
3.114. vascan_search(搜索 CANADENSYS Vascan API)
用法:vascan_search(q, format = "json", raw = FALSE, ...)
参数:
- q:可以是学名、俗名或 VASCAN 分类群标识符。
- format:json(默认)或 xml 之一。
- raw:若为 TRUE,则返回原始 json 或 xml 数据;若为 FALSE,则返回解析后的数据。
- …:传递给 crul::verb-GET 的 Curl 选项。
返回值:json、xml 或列表。
示例:vascan_search(q = "Helianthus annuus")
3.115. worms_downstream(检索 WORMS 系统下游的所有分类群名称)
用法:worms_downstream(id, downto, intermediate = FALSE, start = 1, ...)
参数:
- id:一个或多个 AphiaID。
- downto:您希望深入到的分类级别。分类级别区分大小写,必须拼写正确。拼写请参见 rank_ref_zoo。
- intermediate:如果为 “true”,则返回包含目标分类群等级名称的长度为 2 的列表,以及中间分类群的附加 data.frame 列表。默认值: FALSE。
- start:起始记录编号。
- …:传递给 worrms::wm_children() 的 crul 选项,包括 marine_only 和 offset 参数,详情参见 ?worrms::wm_children 。
返回值:从目、纲等下游到科的分类信息的 data.frame,或者,如果 intermediated=TRUE,长度为 2 的列表,包含目标分类群等级名称和中间名称。
示例:worms_downstream(id = 125732, downto="species")
3.116. worrms_ranks
描述:使用 worrms::wm_ranks_id(-1) 创建于 2020-02-11。
格式:一个包含 216 行和 2 个变量的数据框:
- id:等级id。
- rank:等级名称。
说明:如果 WORMS 不返回等级名称,则在 taxize 中出现 - 只要返回等级 id,我们就可以使用该数据集填写等级信息。
相关文章:
)
R语言——taxize(第五部分)
taxize(第五部分) 3. taxize 文档中译3.71. nbn_synonyms(从 NBN 返回具有给定 id 的分类群名称的所有同义词)3.72. ncbi_children(在 NCBI 中搜索类群的子类群)3.73. ncbi_downstream(检索 NCB…...

负载均衡lvs
简介 ipvsadm 是 Linux 内核中的 IP 虚拟服务器(IPVS)管理工具。IPVS是 Linux 内核提供的一种负载均衡解决方案,它允许将入站的网络流量分发到多个后端服务器,以实现负载均衡和高可用性。IPVS通过在内核中维护一个虚拟服务器表&a…...

【腾讯云云上实验室】探索向量数据库背后的安全监控机制
当今数字化时代,数据安全成为了企业和个人最为关注的重要议题之一。随着数据规模的不断增长和数据应用的广泛普及,如何保护数据的安全性和隐私性成为了迫切的需求。 今天,我将带领大家一起探索腾讯云云上实验室所推出的向量数据库,…...
阅读笔记——《Removing RLHF Protections in GPT-4 via Fine-Tuning》
【参考文献】Zhan Q, Fang R, Bindu R, et al. Removing RLHF Protections in GPT-4 via Fine-Tuning[J]. arXiv preprint arXiv:2311.05553, 2023.【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。 目录 摘要 一、介绍 二、背景 三、方法…...

electron实现截图的功能
Electron是一种跨平台的桌面应用程序开发框架,可以使用HTML、CSS和JavaScript等Web技术构建桌面应用程序。下面是一种使用Electron实现截图的简单方法: 安装Electron和截图库 首先,需要安装Electron和一个截图库,例如electron-sc…...

11、动态数码管显示
数码管驱动方式 1、单片机直接扫描:硬件设备简单,但会消耗大量的单片机CPU时间 2、专用驱动芯片:内部自带显存、扫描电路,单片机只需告诉他显示什么即可 #include <REGX52.H> //数组代表显示亮灯的内容0、1、2、3、4、5、…...

Linux的基本指令(三)
目录 前言 echo指令(简述) Linux的设计理念 输出重定向操作符 > 追加输出重定向操作符 >> 输入重定向操作符 < 补充知识 学前补充 more指令 less指令 head指令 tail指令 查看文件中间的内容 利用输出重定向实现 利用管道“ |…...

使用python 实现华为设备的SFTP文件传输
实验目的: 公司有一台CE12800的设备,管理地址位172.16.1.2,现在需要编写自动化脚本,通过SFTP实现简单的上传下载操作。 实验拓扑: 实验步骤: 步骤1:将本地电脑和ensp的设备进行桥接ÿ…...

高防cdn防护原理是什么,是否可以防护服务器吗
随着互联网业务的迅速发展,网络安全问题日益凸显。在这样的背景下,高防CDN作为一种有效的网络安全解决方案,受到了越来越多的关注。那么高防CDN的防护原理是什么呢?接下来就跟小德一起深入了解下吧! 1. 高防CDN的基本概念 我们要明确什么是…...
)
SELinux零知识学习三十五、SELinux策略语言之角色和用户(6)
接前一篇文章:SELinux零知识学习三十四、SELinux策略语言之角色和用户(5) 三、SELinux策略语言之角色和用户 SELinux提供了一种依赖于类型强制(类型增强,TE)的基于角色的访问控制(Role-Based Access Control),角色用于组域类型和限制域类型与用户之间的关系,SELinux…...

初学Flink 学后总结
最近开始学习Flink,一边学习一边记录,以下是基于【尚硅谷】Flink1.13实战教程总结的笔记,方便后面温习 目录 初始 Flink 一:基础概念 1.Flink是什么 2.Flink主要应用场景...

CSS新手入门笔记整理:CSS基本介绍
CSS,指的是“Cascading Style Sheet(层叠样式表)”,用于控制网页外观。 CSS引入方式 外部样式表 独立建立一个.CSS文件,在HTML中使用 link标签 来引用CSS文件。link标签放置在head标签内部。 语法 <link rel&qu…...

【华为OD】B\C卷真题 100%通过:需要打开多少监控器 C/C++实现
【华为OD】B\C卷真题 100%通过:需要打开多少监控器 C/C实现 目录 题目描述: 示例1 代码实现: 题目描述: 某长方形停车场,每个车位上方都有对应监控器,当且仅当在当前车位或者前后左右四个方向任意一个…...

HarmonyOS开发(七):构建丰富页面
1、组件状态管理 1.1、概述 在应用中,界面一般都是动态的。界面会根据不同状态展示不一样的效果。 ArkUI作为一种声明式UI,具有状态驱动UI更新的特点,当用户进行界面交互或有外部事件引起状态改变时,状态的变会会触发组件的自动…...
--rsa - RSA加密解密)
LuatOS-SOC接口文档(air780E)--rsa - RSA加密解密
示例 -- 请在电脑上生成私钥和公钥, 当前最高支持4096bit, 一般来说2048bit就够用了 -- openssl genrsa -out privkey.pem 2048 -- openssl rsa -in privkey.pem -pubout -out public.pem -- privkey.pem 是私钥, public.pem 是公钥 -- 私钥用于 加密 和 签名, 通常保密, 放在…...
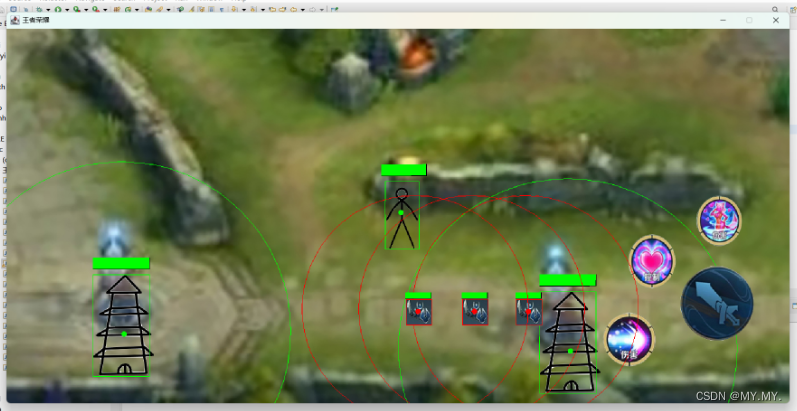
简易版王者荣耀
所有包和类 GameFrame类 package newKingOfHonor;import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.KeyAdapter; import java.awt.event.KeyEvent; import java.io.File; import java.util.ArrayList;im…...

功能测试进阶建议,学习思路讲解
1. 深入了解测试理论: 了解测试的原理、方法和最佳实践,包括黑盒测试、白盒测试、灰盒测试等。可以阅读相关的书籍或参加在线课程。 2. 学习相关测试工具: 掌握常用的测试工具,如缺陷发现工具、性能测试工具、安全测试工具等。可以…...

AI数字人与虚拟人:区别与应用场景
随着人工智能和虚拟技术的不断发展,AI数字人和虚拟人成为了数字世界中的两个重要概念。本文将介绍AI数字人和虚拟人的区别,并探讨它们在不同领域的应用场景。 一、AI数字人与虚拟人的区别 定义和概念: AI数字人:是利用人工智能技术…...
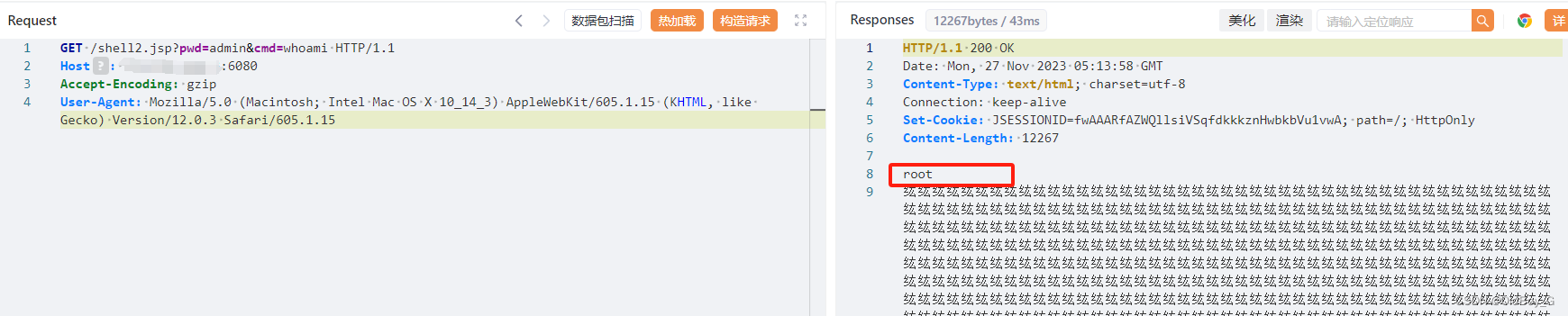
金蝶Apusic应用服务器 任意文件上传漏洞复现
0x01 产品简介 金蝶Apusic应用服务器(Apusic Application Server,AAS)是一款标准、安全、高效、集成并具丰富功能的企业级应用服务器软件,全面支持JakartaEE8/9的技术规范,提供满足该规范的Web容器、EJB容器以及WebSer…...
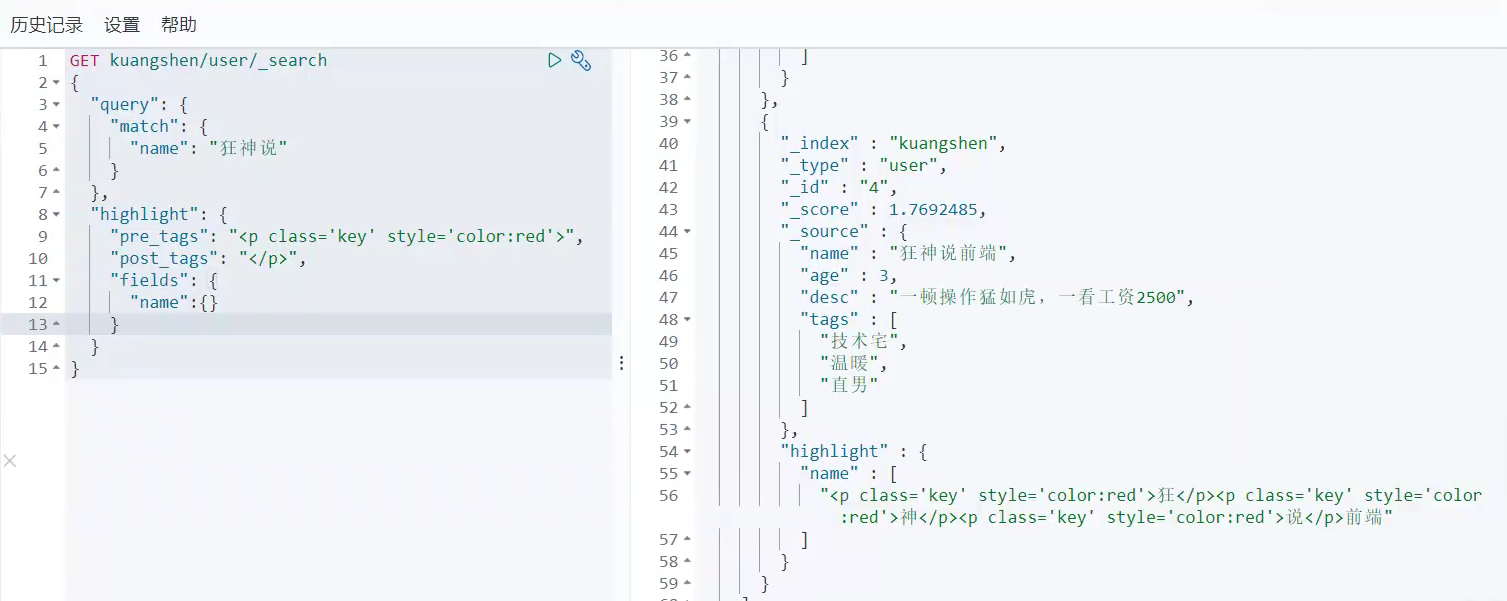
ElasticSearch学习笔记(狂神说)
ElasticSearch学习笔记(狂神说) 视频地址:https://www.bilibili.com/video/BV17a4y1x7zq 在学习ElasticSearch之前,先简单了解一下Lucene: Doug Cutting开发是apache软件基金会 jakarta项目组的一个子项目是一个开放…...
)
告别SBC音质焦虑!实测LC3编解码在TWS耳机上的音质与延迟表现(附对比数据)
告别SBC音质焦虑!实测LC3编解码在TWS耳机上的音质与延迟表现(附对比数据) 作为一名长期被蓝牙音频压缩算法折磨的发烧友,第一次听到LC3编码的测试样机时,那种震撼感至今难忘——人声突然从蒙着纱布的状态变得触手可及&…...

科技企业如何借助智能工具加快技术研发与市场推广?
观点作者:科易网-国家科技成果转化(厦门)示范基地现状概述:科技成果转化与市场推广的双重困境 在数智时代,技术转移与成果转化正经历深刻变革。一方面,海量数据成为创新的核心要素,但传统科技企…...

【GIS操作指南】ArcMap界面坐标单位一键切换:从平面到经纬度的实战设置
1. 为什么需要切换坐标单位? 刚接触ArcMap的朋友可能会发现,软件右下角默认显示的坐标单位往往是米或千米这类平面单位。但在处理带有地理坐标的数据时,比如气象数据、GPS轨迹或者行政区划边界,我们更习惯使用经纬度来定位。这就好…...

AI大模型风口已至!4大高薪就业方向,助你精准转型少走弯路!
当下,AI大模型正从“技术爆发期”迈入“全面应用期”。对于IT从业者而言,这并非一道“要不要转”的选择题,而是一道“往哪转”的战略题。 很多人想抓住这波红利,却卡在“不知道从哪下手”“不清楚自己适合哪个赛道”的困境中。 …...

Planify Nextcloud集成:私有云环境下的安全任务同步终极指南
Planify Nextcloud集成:私有云环境下的安全任务同步终极指南 【免费下载链接】planify Task manager with Todoist, Nextcloud & CalDAV support designed for GNOME 项目地址: https://gitcode.com/gh_mirrors/pl/planify Planify是一款专为GNOME设计的…...

multiagent-particle-envs与PettingZoo对比:迁移指南与最佳实践
multiagent-particle-envs与PettingZoo对比:迁移指南与最佳实践 【免费下载链接】multiagent-particle-envs Code for a multi-agent particle environment used in the paper "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments"…...

ThinkBook 16 2024款装Ubuntu 22.04,无线网卡和蓝牙驱动修复保姆级教程
ThinkBook 16 2024款Ubuntu 22.04无线与蓝牙驱动终极解决方案 刚拿到新款ThinkBook 16 2024的开发者们,在享受其强悍性能的同时,可能都会遇到一个共同的烦恼——安装Ubuntu 22.04后无线网卡和蓝牙无法正常工作。这并非硬件故障,而是由于Intel…...
)
Windows远程桌面防爆破实战:用PowerShell自动封禁恶意IP(附完整脚本)
Windows远程桌面安全加固:基于PowerShell的智能IP封禁系统 远程桌面服务(RDP)作为企业IT基础设施的核心组件,其安全性直接关系到整个系统的稳定运行。根据2023年全球网络安全报告显示,针对3389端口的暴力破解尝试占所有…...

终极指南:如何构建轻量级Arduino设备与Home Assistant的无缝MQTT集成
终极指南:如何构建轻量级Arduino设备与Home Assistant的无缝MQTT集成 【免费下载链接】arduino-home-assistant ArduinoHA allows to integrate an Arduino/ESP based device with Home Assistant using MQTT. 项目地址: https://gitcode.com/gh_mirrors/ar/ardui…...

利用快马平台为dhnvr416h-hd设备快速构建交互式原型模拟器
最近在做一个智能硬件项目,需要为dhnvr416h-hd设备开发一个快速原型模拟器。这个模拟器主要用于验证设备接口和功能逻辑,避免直接操作真实设备带来的风险。经过一番摸索,我发现用InsCode(快马)平台可以非常高效地完成这个任务,下面…...