ElasticSearch学习笔记(狂神说)
ElasticSearch学习笔记(狂神说)
视频地址:https://www.bilibili.com/video/BV17a4y1x7zq
在学习ElasticSearch之前,先简单了解一下Lucene:
- Doug Cutting开发
- 是apache软件基金会 jakarta项目组的一个子项目
- 是一个开放源代码的全文检索引擎工具包
- 不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)
- 当前以及最近几年最受欢迎的免费Java信息检索程序库。
Lucene和ElasticSearch的关系:
- ElasticSearch是基于Lucene 做了一下封装和增强
1、ElasticSearch概述
官网:https://www.elastic.co/cn/downloads/elasticsearch
Elaticsearch,简称为es,es是一个开源的==高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据==;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为==排名第一的搜索引擎类应用==。
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便lava程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
谁在使用
1、维基百科,类似百度百科,全文检索,高亮,搜索推荐/2(权重!)
2、The Guardian (国外新闻网站) ,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论) +社交网络数据(对某某新闻的相关看法) ,数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
3、Stack Overflow (国外的程序异常讨论论坛) , IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
4、GitHub (开源代码管理),搜索 上千亿行代码
5、电商网站,检索商品
6、日志数据分析, logstash采集日志, ES进行复杂的数据分析, ELK技术, elasticsearch+logstash+kibana
7、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
8、BI系统,商业智能, Business Intelligence。比如说有个大型商场集团,BI ,分析一下某某区域最近3年的用户消费 金额的趋势以及用户群体的组成构成,产出相关的数张报表, **区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘, Kibana进行数据可视化
9、国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一一个使用场景)
2、ES和Sola
2.1、ElasticSearch简介
- Elasticsearch是一个实时分布式搜索和分析引擎。 它让你以前所未有的速度处理大数据成为可能。
- 它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
- 维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。
- 英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
- StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
- Github使用Elasticsearch检索1300亿行的代码。
- 但是Elasticsearch不仅用于大型企业,它还让像DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。
- Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
- Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域, Lucene可被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 但是, Lucene只是一个库。 想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是, Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
- Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2.2、Sola简介
- Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
- Solr可以独立运行在letty. Tomcat等这些Selrvlet容器中 , Solr 索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档, Solr根据xml文档添加、删除、更新索引。Solr 搜索只需要发送HTTP GET请求,然后对Solr返回xml、json等格式的查询结果进行解析,组织页面布局。
- Solr不提供构建UI的功能, Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
- Solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene.
- Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交-定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
2.3、ElasticSearch与Solr比较
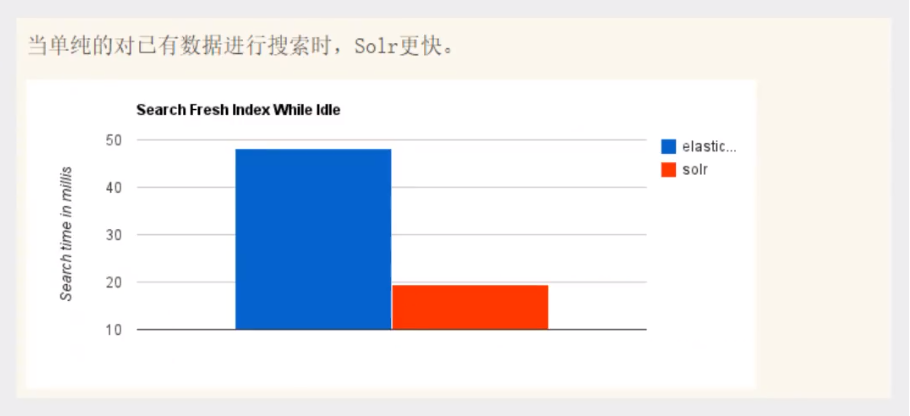
- 当单纯的对已有数据进行搜索时,Solr更快
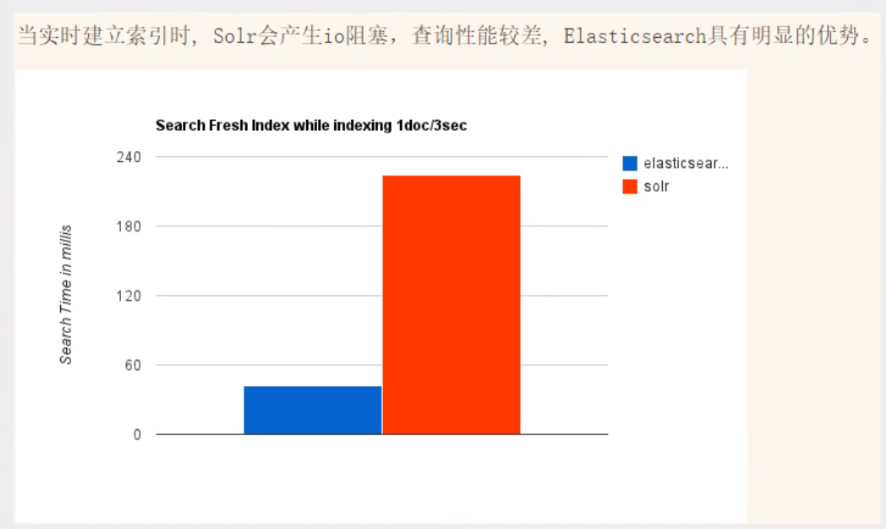
- 当实时建立索引时,Solr会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势
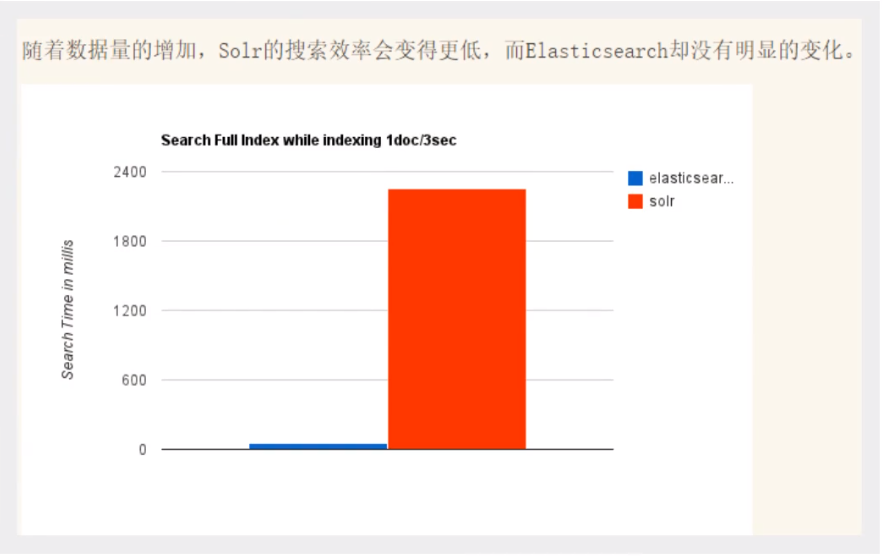
- 随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化
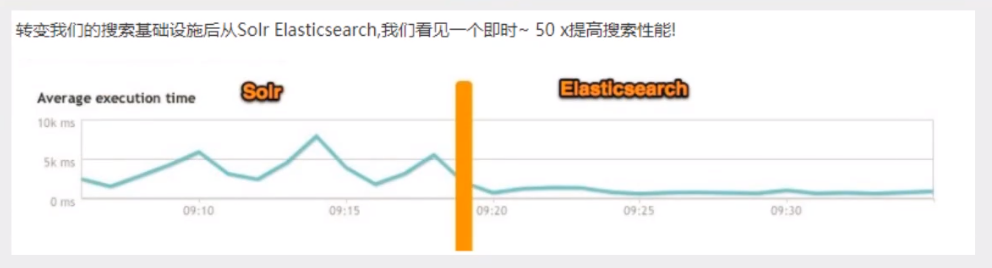
- 转变我们的搜索基础设施后从Solr ElasticSearch,我们看见一个即时~ 50x提高搜索性能!
总结
1、es基本是开箱即用(解压就可以用!) ,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、 CSV ,而Elasticsearch仅支持json文件格式。
4、Solr 官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑。
5、Solr 查询快,但更新索引时慢(即插入删除慢) ,用于电商等查询多的应用;
- ES建立索引快(即查询慢) ,即==实时性查询快==,用于facebook新浪等搜索。
- Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
3、ElasticSearch安装
jdk8 最低要求
使用Java开发,必须保证ElasticSearch的版本与Java的核心jar包版本对应!(Java环境保证没错)
3.1、安装
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
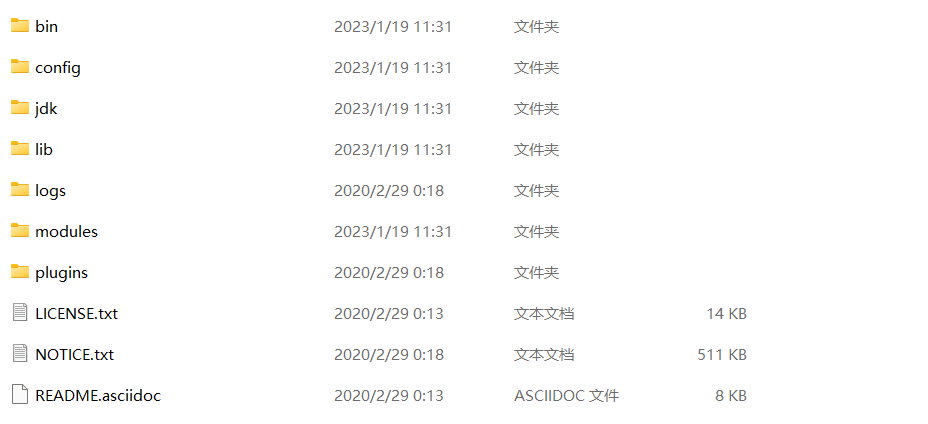
bin 启动文件目录
config 配置文件目录1og4j2 日志配置文件jvm.options java 虚拟机相关的配置(默认启动占1g内存,内容不够需要自己调整)elasticsearch.ym1 elasticsearch 的配置文件! 默认9200端口!跨域!
1ib 相关jar包
modules 功能模块目录
plugins 插件目录ik分词器
启动测试

3.2、安装可视化界面
elasticsearch-head
使用前提:需要安装nodejs
下载的版本需要与ElasticSearch版本对应
1、下载地址
https://github.com/mobz/elasticsearch-head
2、安装
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
3、启动
cd elasticsearch-head
# 安装依赖
npm install # 如果安装了淘宝镜像可以用 cnpm install
# 启动
npm run start
# 访问
http://localhost:9100/
安装依赖

启动

访问
由于ES在9200端口,而可视化界面在9100端口,故出现跨域问题无法访问
什么是跨域:https://blog.csdn.net/qq_38128179/article/details/84956552
解决跨域
开启跨域(在elasticsearch解压目录config下elasticsearch.yml中添加)
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"
重启elasticsearch
重新访问

如何理解上图:
- 如果你是初学者
- 索引 可以看做 “数据库”
- 类型 可以看做 “表”
- 文档 可以看做 “库中的数据(表中的行)”
这个head,我们只是把它当做可视化数据展示工具,之后所有的查询都在kibana中进行,因为不支持json格式化,不方便
3.3、安装Kibana
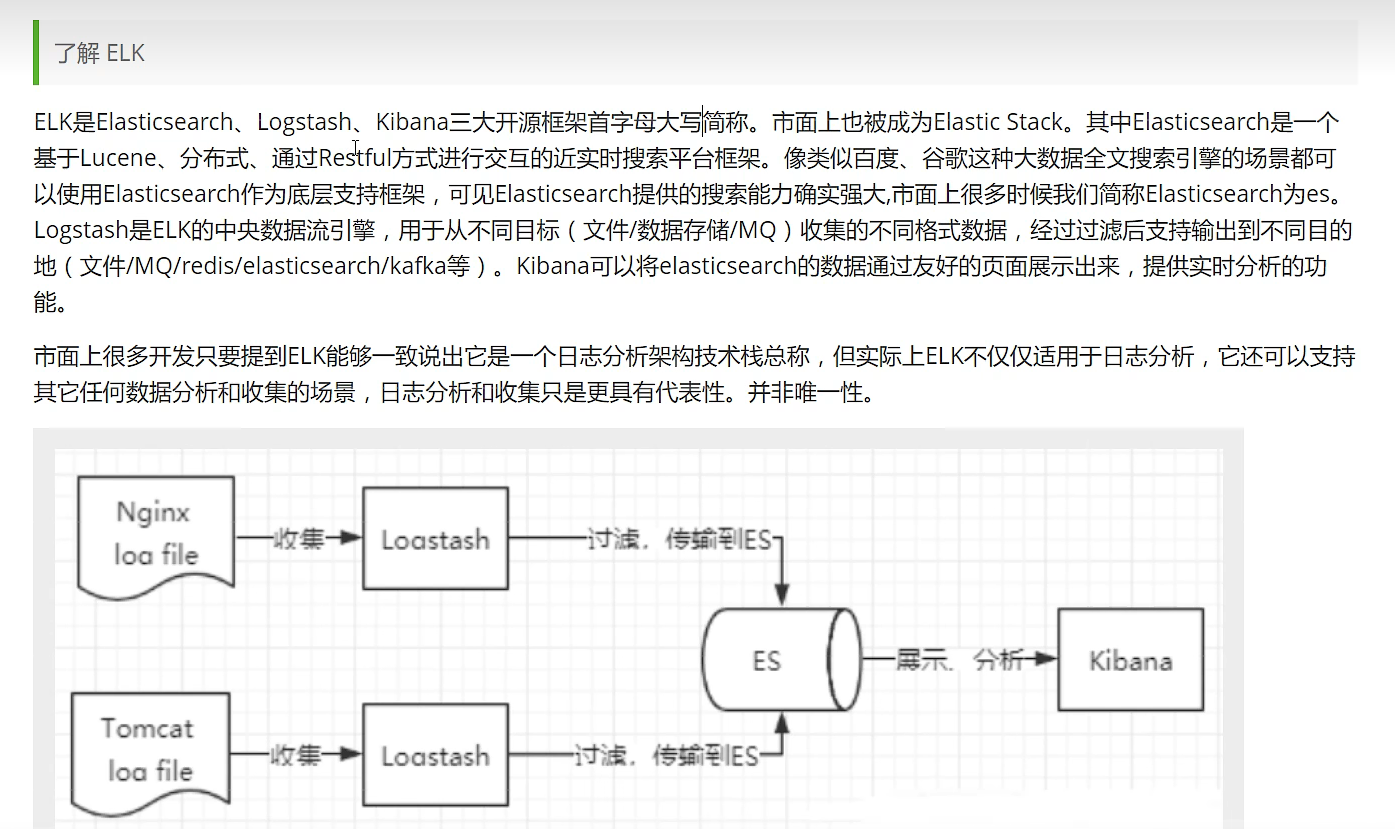
了解ELK
下载地址
https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
下载的版本需要与ElasticSearch版本对应
安装
解压即可
启动

访问
怎么测试
我们之后的所有操作都在这里编写!
汉化
很多人对英文不太熟悉,可以进行汉化
编辑器打开kibana解压目录/config/kibana.yml,添加
i18n.locale: "zh-CN"
保存完毕重启即可
4、ElasticSearch核心概念
概述
1、索引(ElasticSearch)
- 包含多个分片
2、字段类型(映射)
- 字段类型映射(字段是整型,还是字符型…)
3、文档
4、分片(Lucene索引,倒排索引)
ElasticSearch是面向文档,关系行数据库和ElasticSearch客观对比!一切都是JSON!
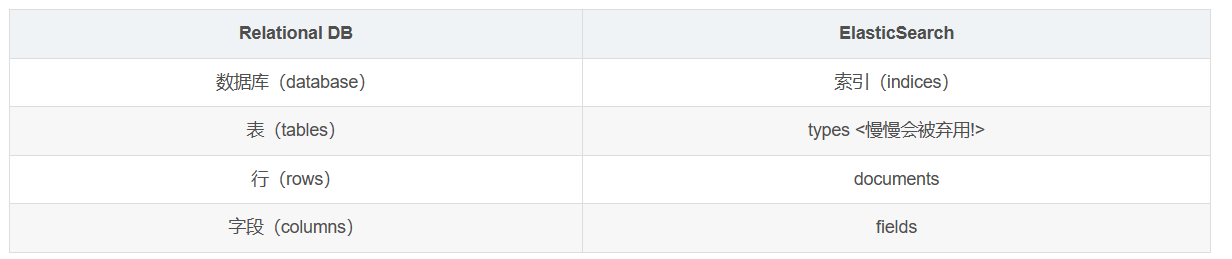
elasticsearch(集群)中可以包含多个索引(数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行) ,每个文档中又包含多个字段(列)。
物理设计
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
一个人就是一个集群! ,即启动的ElasticSearch服务,默认就是一个集群,且默认集群名为elasticsearch
逻辑设计
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的顺序找到它:索引 => 类型 => 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
文档(”行“)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
-
自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value !
-
可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象 ! fastjson进行自动转换 !}
-
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型(“表”)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
- elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引(“库”)
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片 如何工作
创建新索引
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片(primary shard ,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
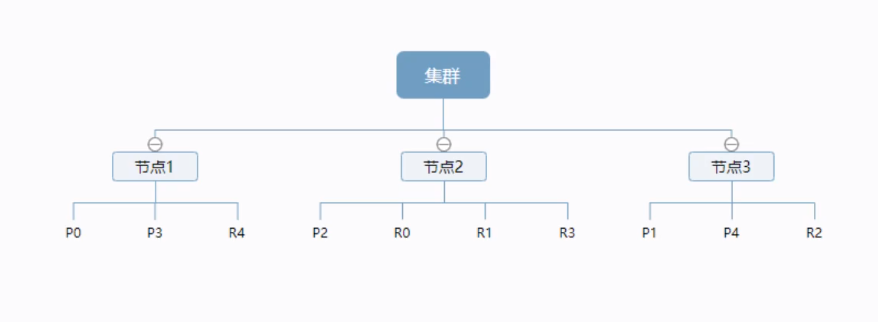
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于失。实际上,一个分片是一个Lucene索引(一个ElasticSearch索引包含多个Lucene索引) ,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引(Lucene索引底层)
简单说就是 按(文章关键字,对应的文档<0个或多个>)形式建立索引,根据关键字就可直接查询对应的文档(含关键字的),无需查询每一个文档
https://blog.csdn.net/qq_43403025/article/details/114779166
5、IK分词器(elasticsearch插件)
IK分词器:中文分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一一个匹配操作,默认的中文分词是将每个字看成一个词(不使用用IK分词器的情况下),比如“我爱狂神”会被分为”我”,”爱”,”狂”,”神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
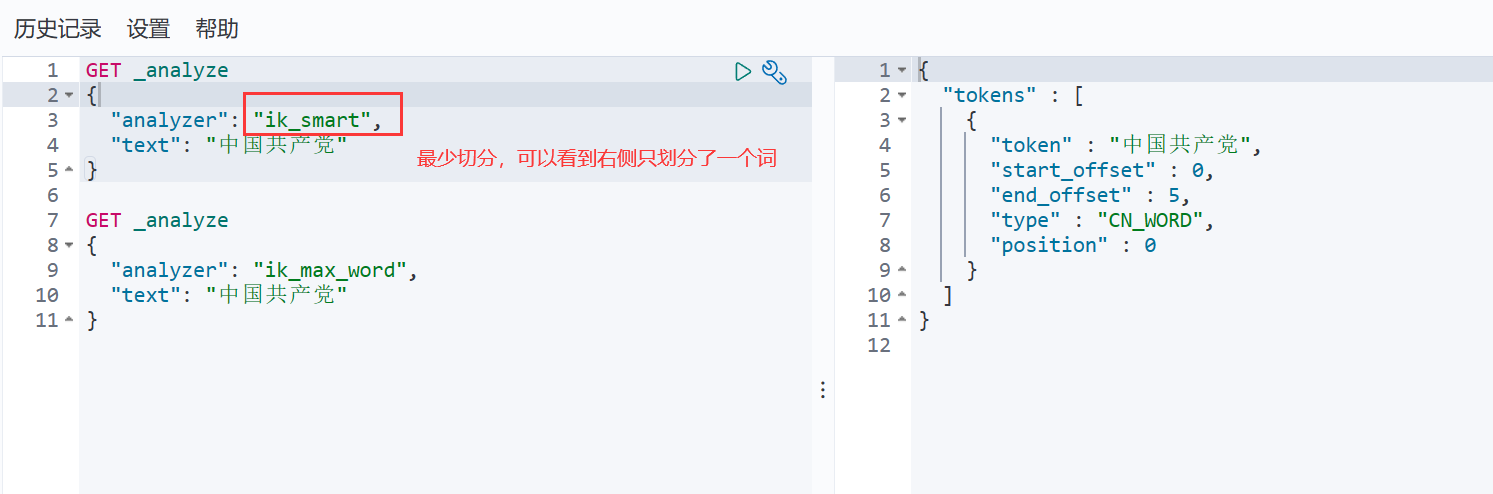
IK提供了两个分词算法: ik_smart和ik_max_word ,其中ik_smart为最少切分, ik_max_word为最细粒度划分!
下载地址(注意与ES版本一致)
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
安装
在ElasticSearch的plugins目录下新建一个ik目录,把下载的zip解压放入ik目录
重启ES

发现我们的IK分词器已经被成功加载!
查看所有插件
在ES的bin目录下输入
elasticsearch-plugin list

测试
ik_smart
ik_max_word
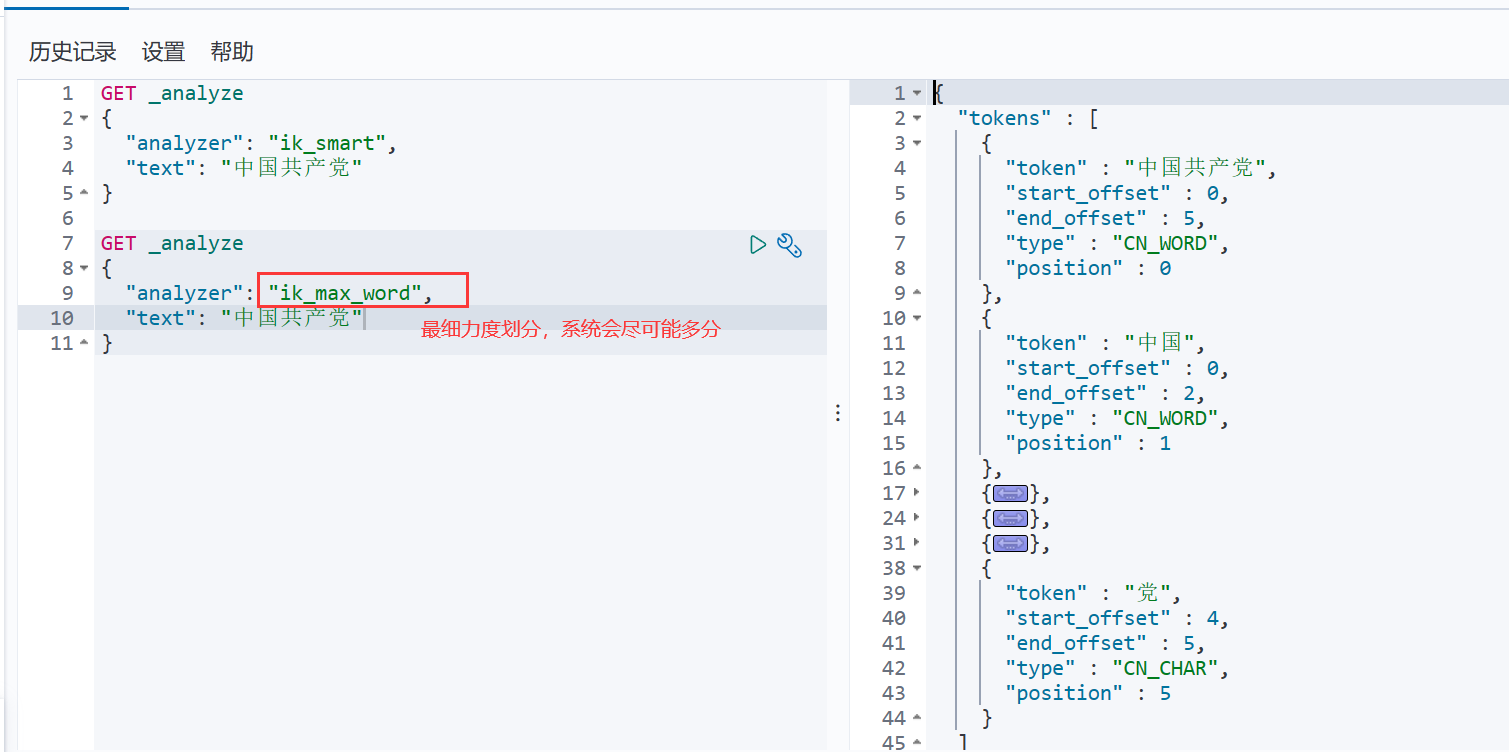
从上面看,感觉分词都比较正常,但是大多数,分词都满足不了我们的想法,如下例
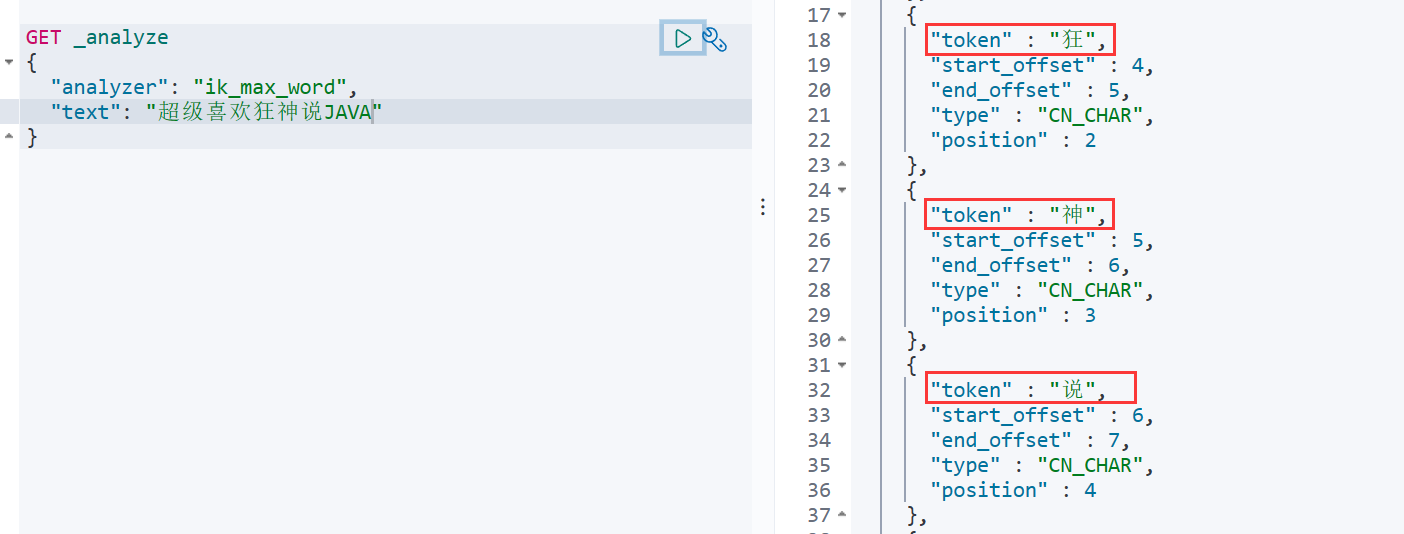
如果我们某个词并不希望它被拆分,那么,我们需要手动将该词添加到分词器的词典当中
手动添加字典
...\elasticsearch-7.6.1\plugins\ik\config
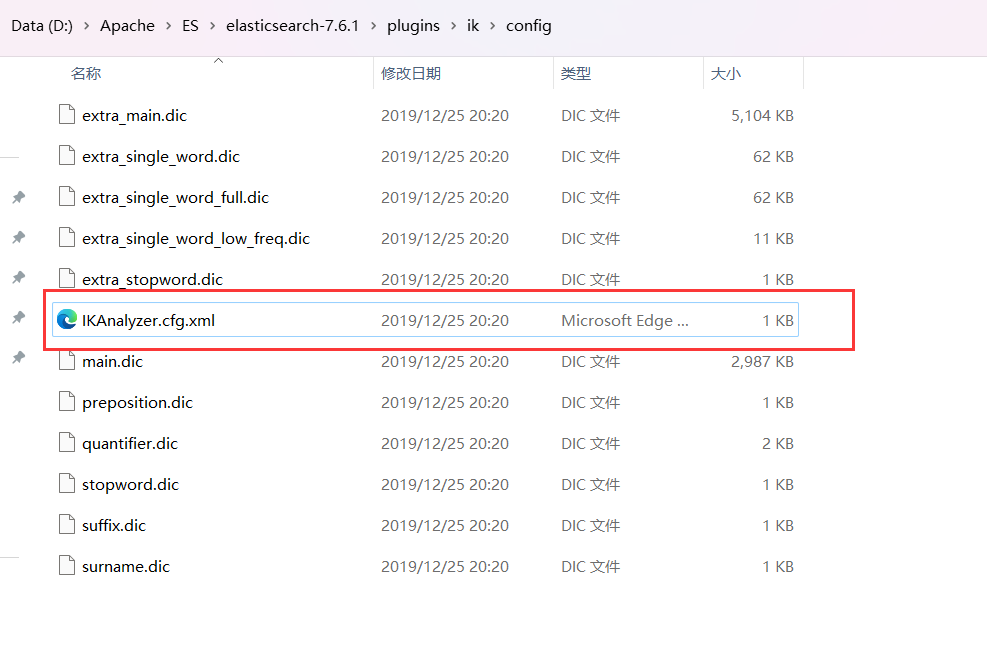
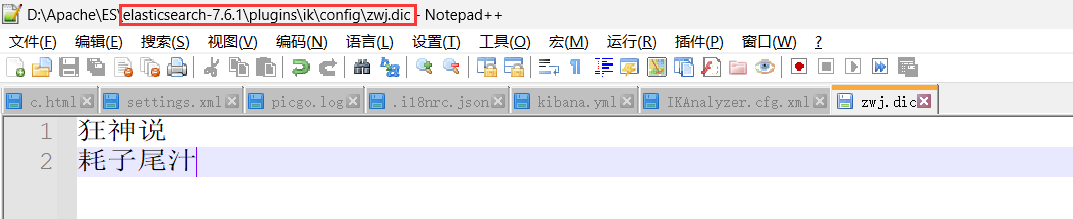
在此目录新建my.dic文件用来放我们自己的字典
把我们的dic文件配置到xml中
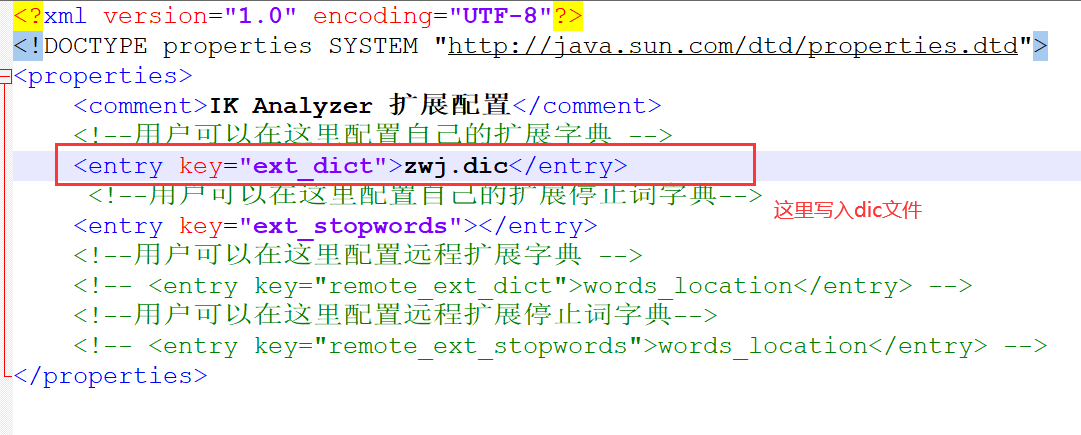
重启ES
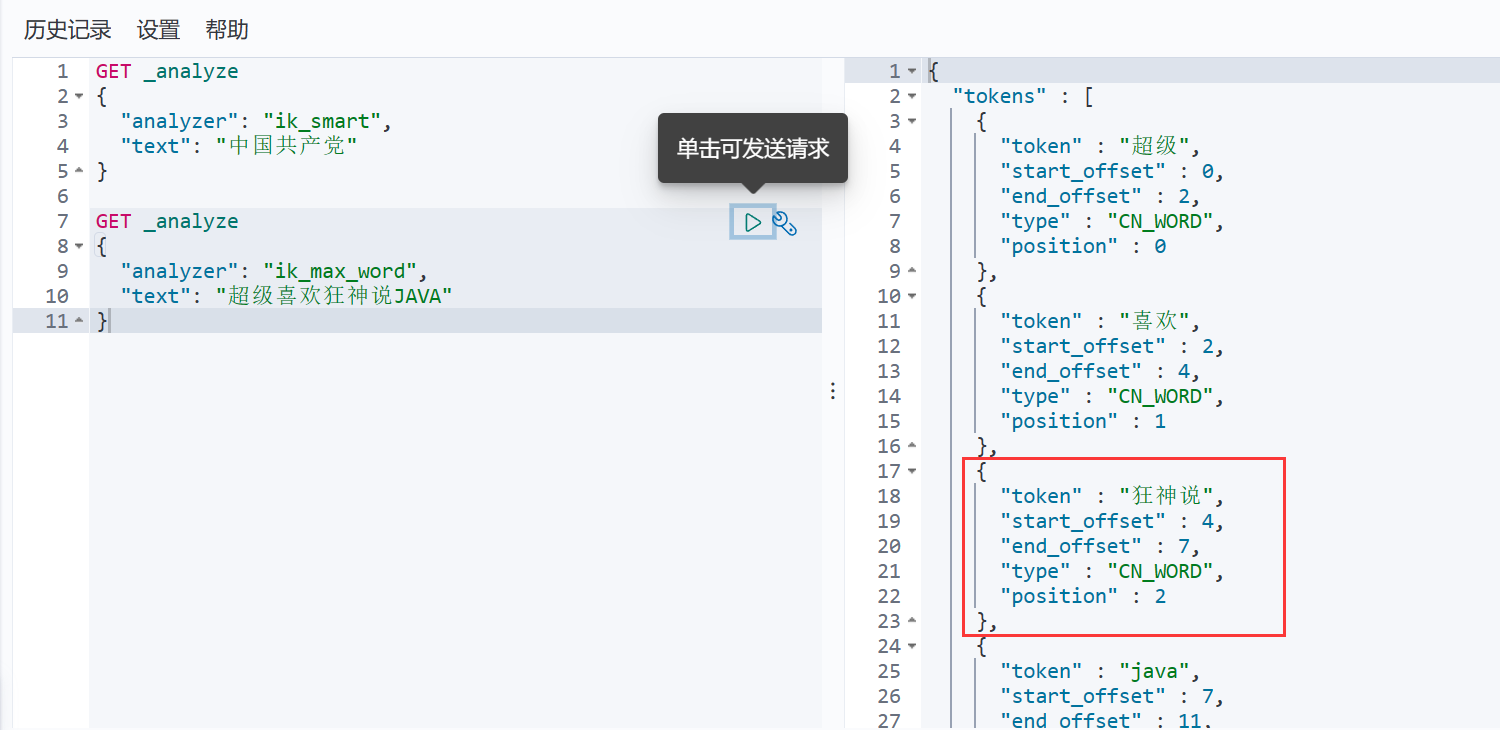
发现狂神说已经不会被拆分了!
6、Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
数据类型说明
-
字符串类型
- text、keyword
- text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
- text、keyword
-
数值型
- long、Integer、short、byte、double、float、half float、scaled float
-
日期类型
- date
-
布尔类型
- boolean
-
二进制类型
- binary
索引测试
1、创建一个索引
# 格式
PUT /索引名/~类型名~/文档id
{请求体
}
PUT /test1/type1/1
{"name": "狂神说","age" : 3
}
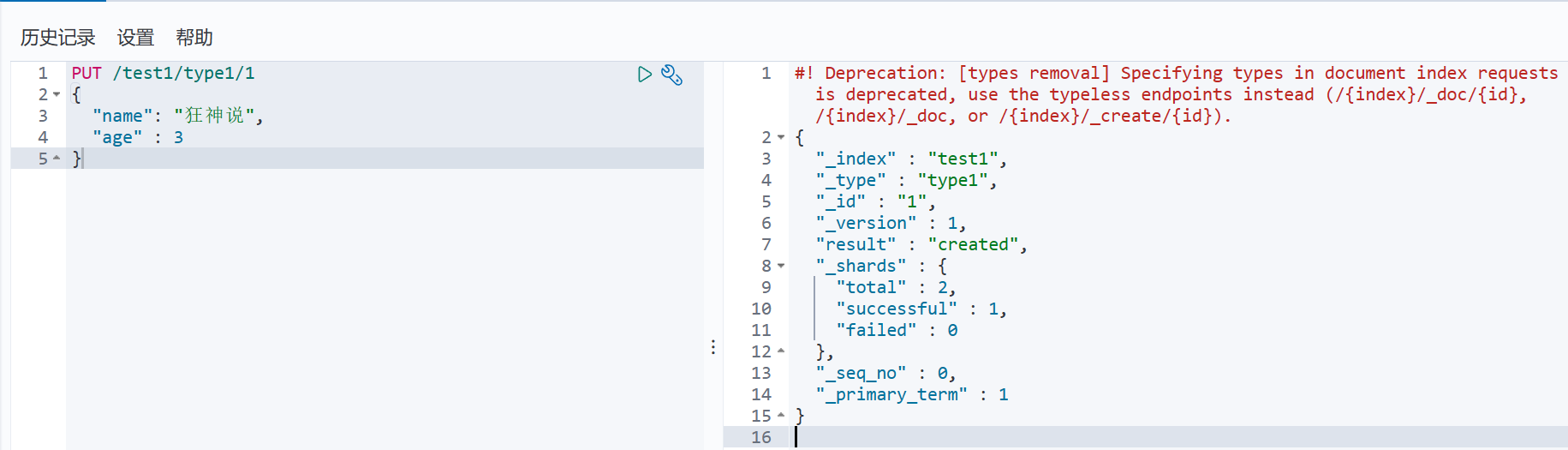
索引创建成功
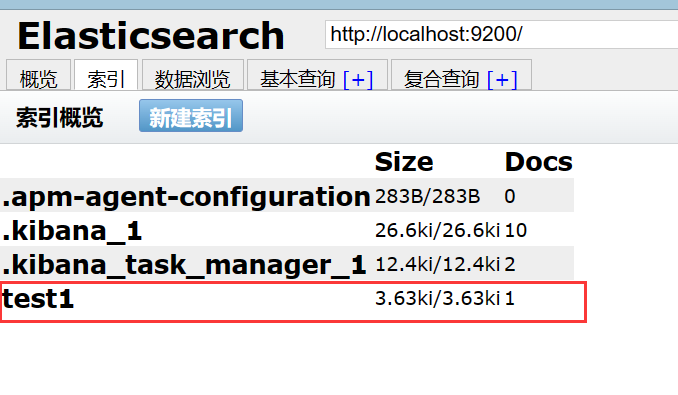
数据也增加成功
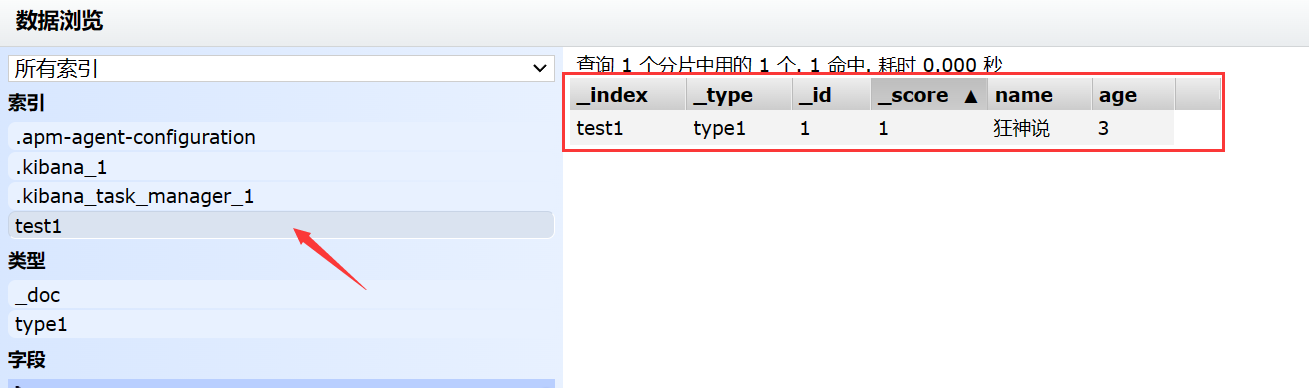
2、指定索引字段规则
创建索引test2并限制内部规则
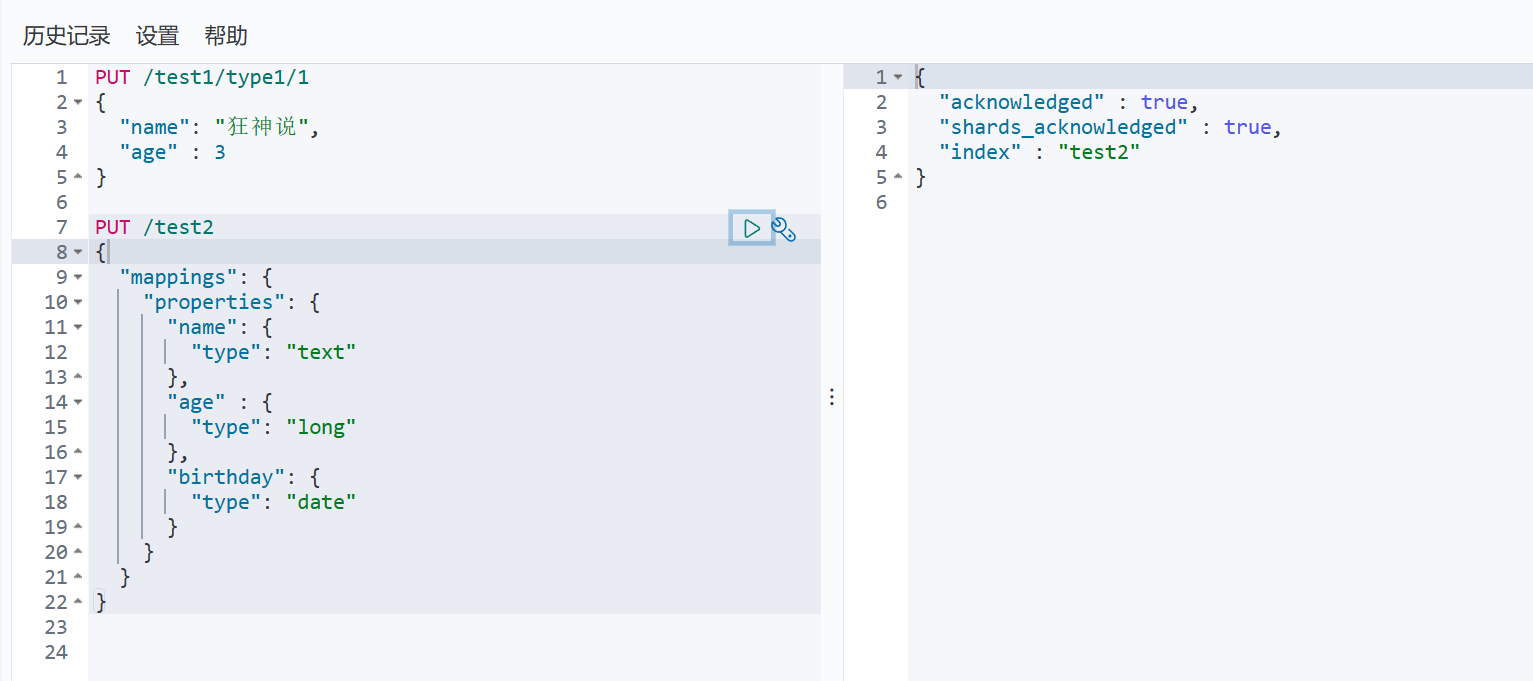
3、获取规则
GET /test2
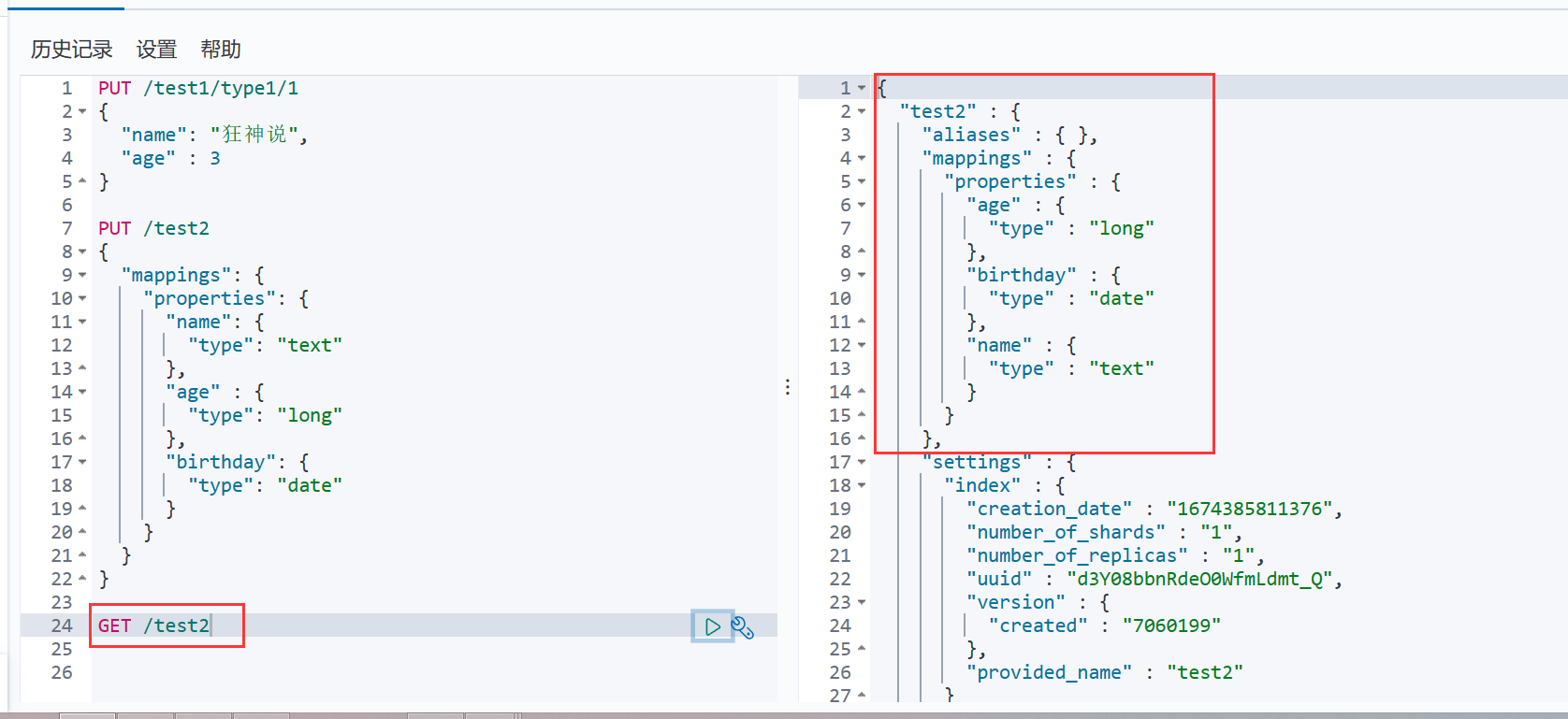
4、查看默认信息
GET /test3
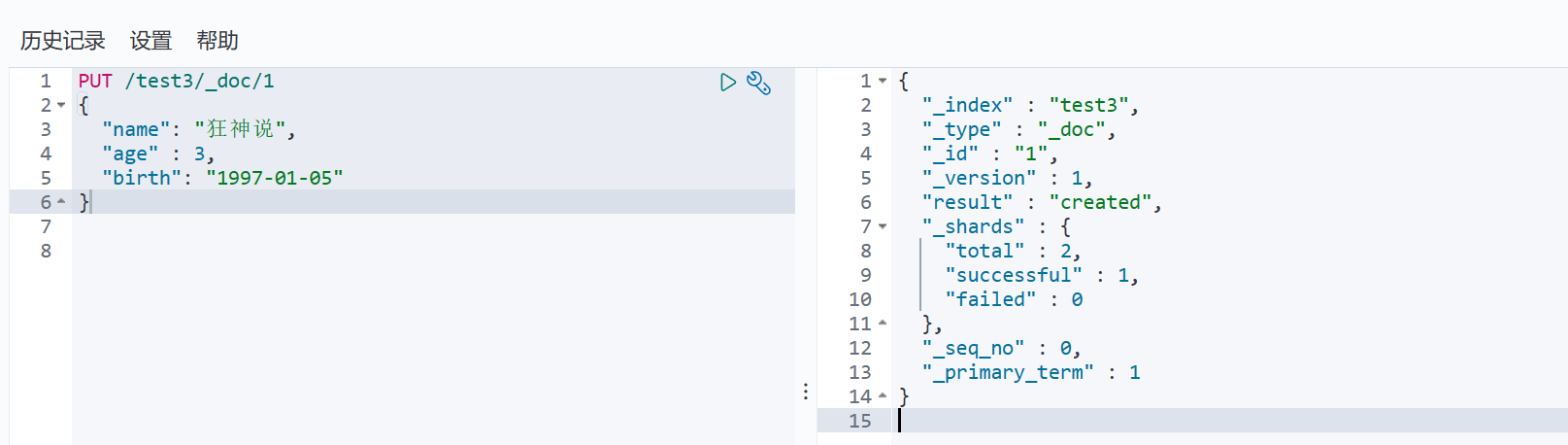
如果自己的文档没有指定类型,那么es会给我们默认配置字段类型
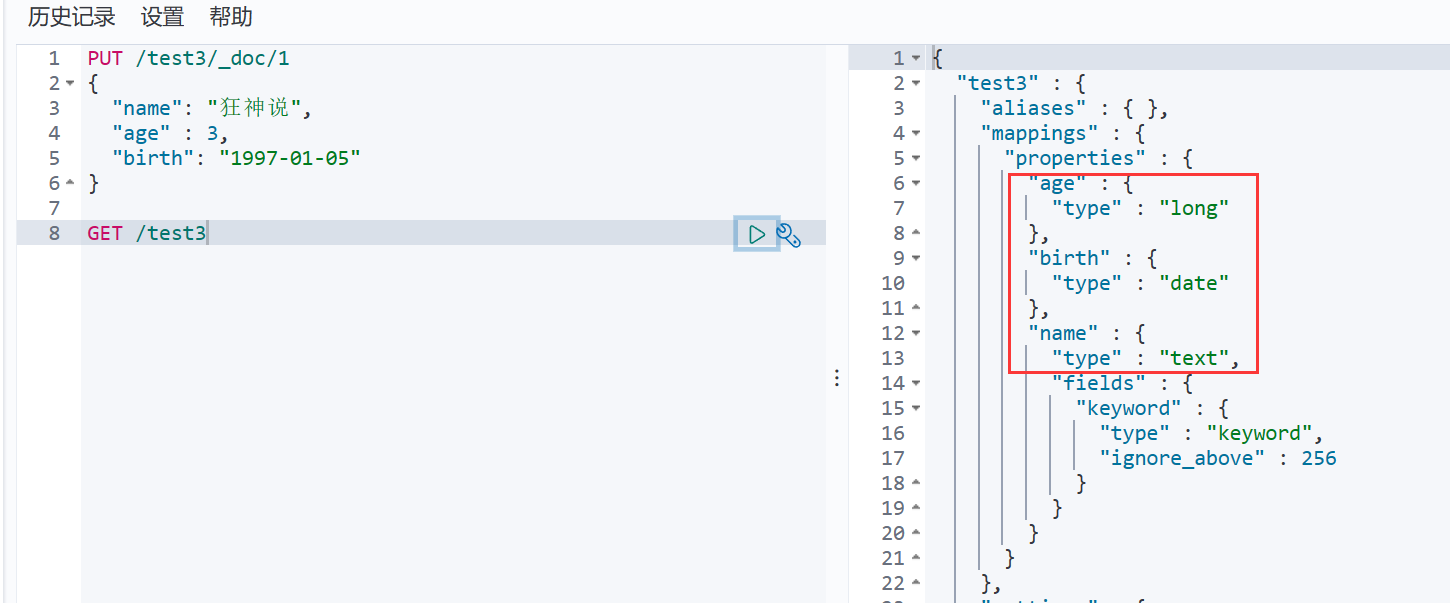
扩展:通过get _cat/ 可以获取ElasticSearch的当前的很多信息!
GET _cat/indices
GET _cat/aliases
GET _cat/allocation
GET _cat/count
GET _cat/fielddata
GET _cat/health
GET _cat/indices
GET _cat/master
GET _cat/nodeattrs
GET _cat/nodes
GET _cat/pending_tasks
GET _cat/plugins
GET _cat/recovery
GET _cat/repositories
GET _cat/segments
GET _cat/shards
GET _cat/snapshots
GET _cat/tasks
GET _cat/templates
GET _cat/thread_pool
5、修改
①旧的(使用put覆盖原来的值)
- 版本+1(_version)
- 但是如果漏掉某个字段没有写,那么更新时没有写的字段 ,会消失
PUT test1/type1/1
{"name": "狂神说JAVA","age": 13
}
②新的(使用post的update)
- version不会改变
- 需要注意doc
- 不会丢失字段
POST /test3/_doc/1/_update
{"doc":{"name" : "post修改,version不会加一","age" : 2}
}
6、删除
DELETE test1/type1/1
DELETE test1
文档查询
Get zwj/user/_search
{"query": { // 查询参数"match": {"name": "狂神"}},"_source": ["name","age"], // 查询指定字段"sort": [{ // 按某个字段排序"age": {"order": "asc"}}],"from": 0, // 从第几个数据开始分页!!!不是页码"size": 2 // pageSize 每页 数据
}
初始数据: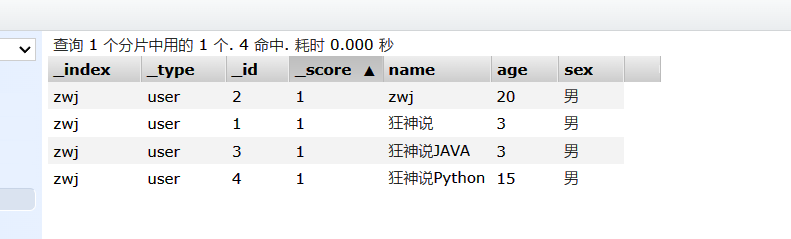
PUT /zwj/user/4
{"name": "狂神说Python","age" : 15,"sex": "男"
}
1、模糊查询name包含狂神的
Get zwj/user/_search
{"query": {"match": {"name": "狂神"}}
}
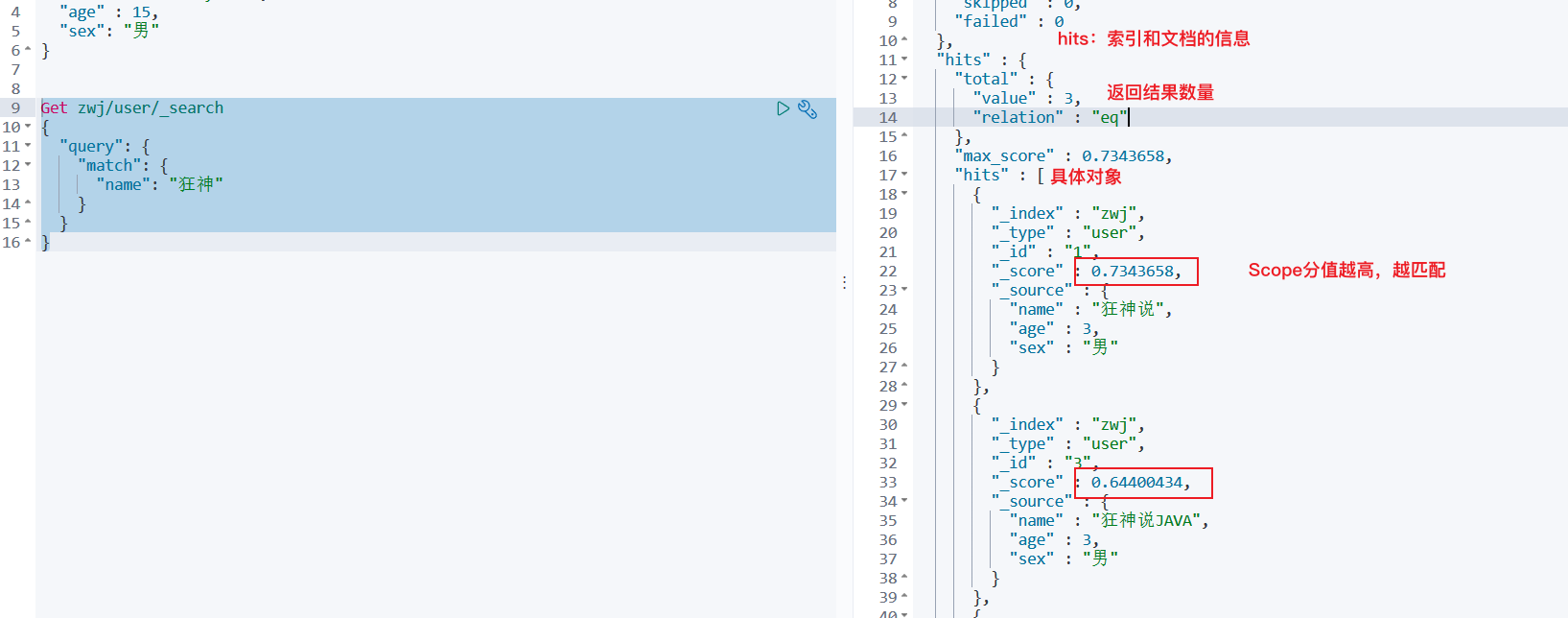
2、查询指定字段+limit
Get zwj/user/_search
{"query": {"match": {"name": "狂神"}},"_source": ["name","age"],"sort": [{"age": {"order": "desc"}}],"from": 0,"size": 2
}
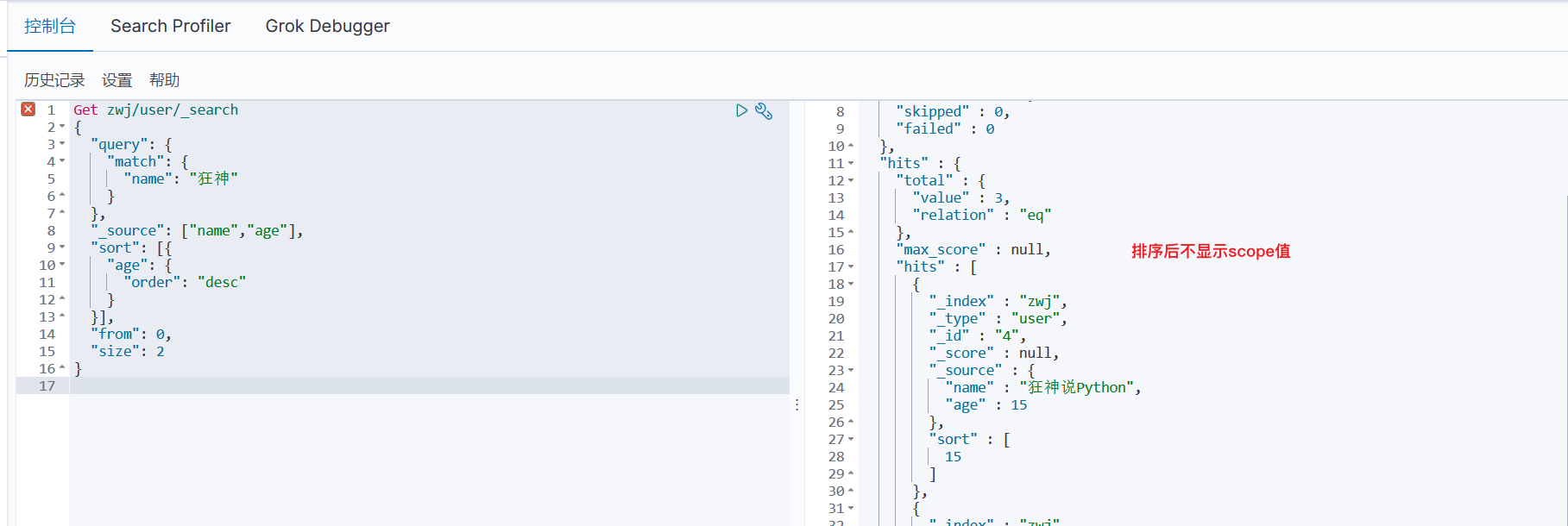
3、布尔值查询
must(where A and B):所有的条件都要符合
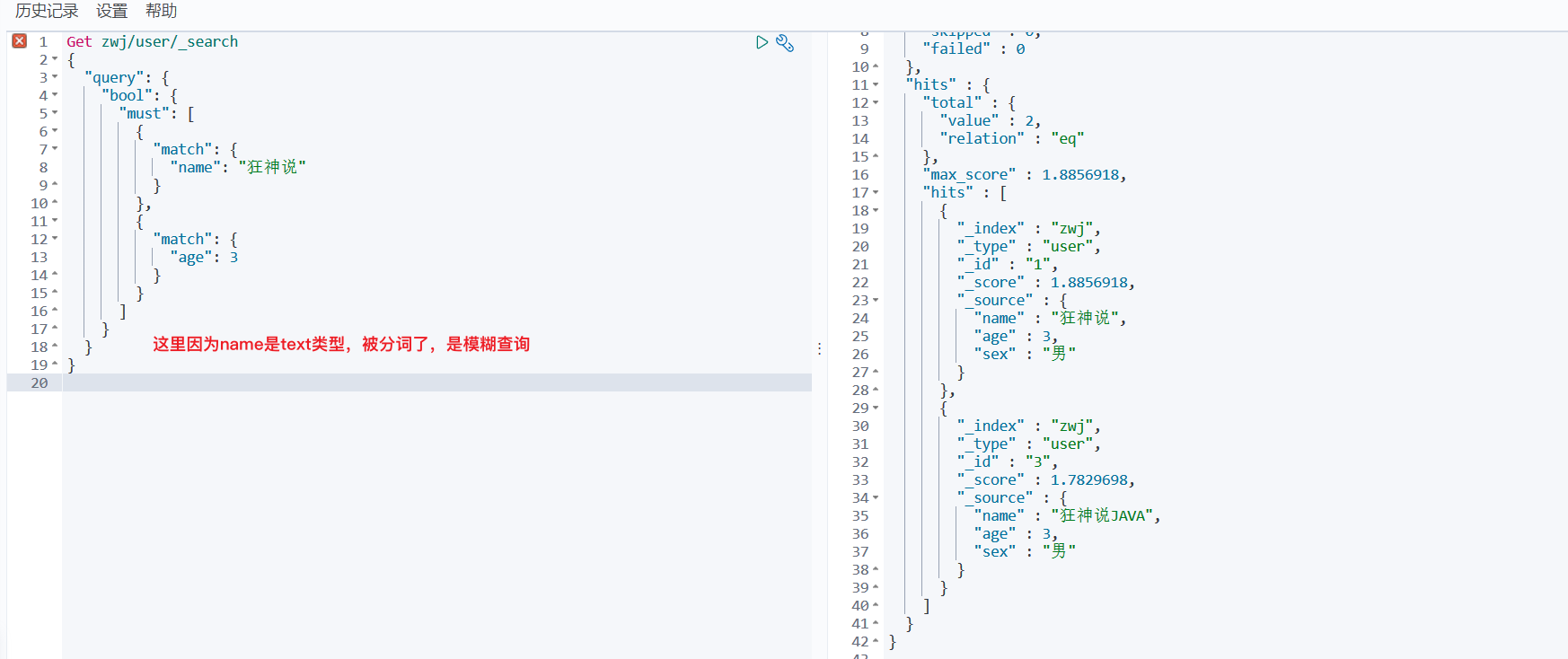
should(where A or B): 任一条件符合即可
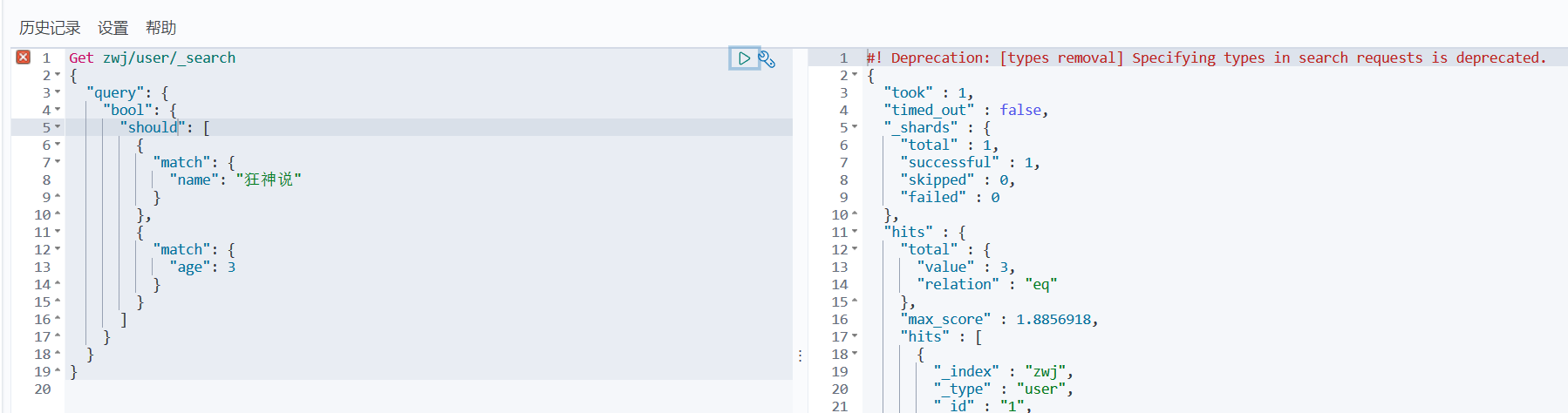
must_not: !=
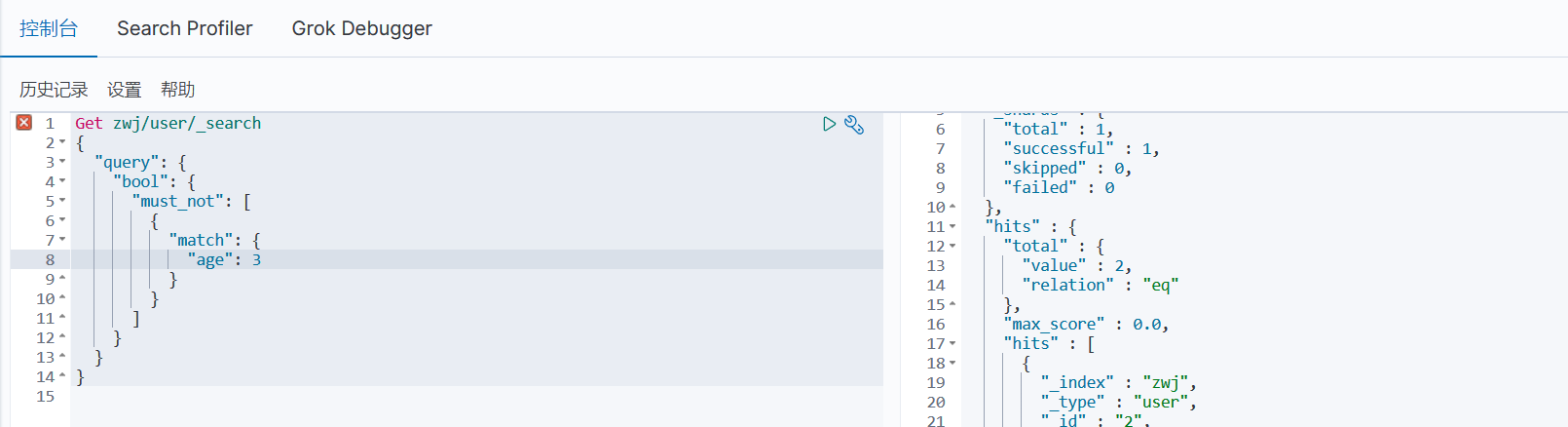
4、筛选
filter:
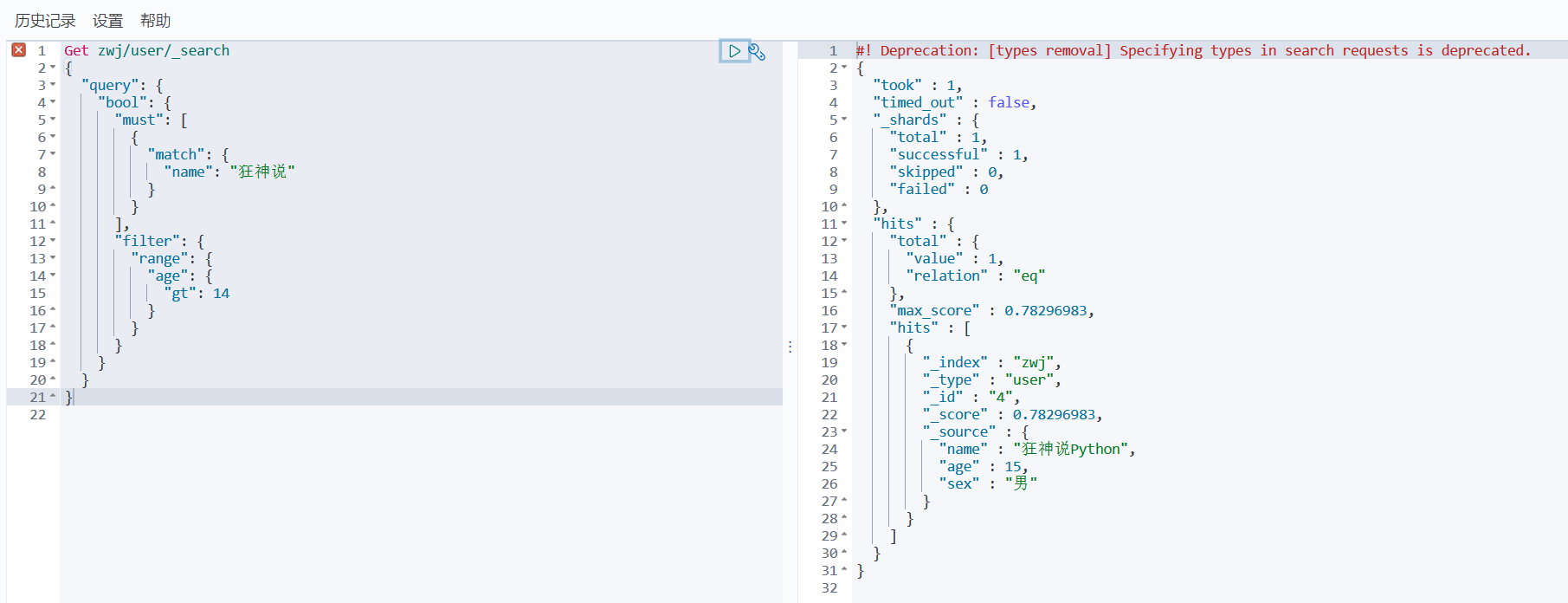
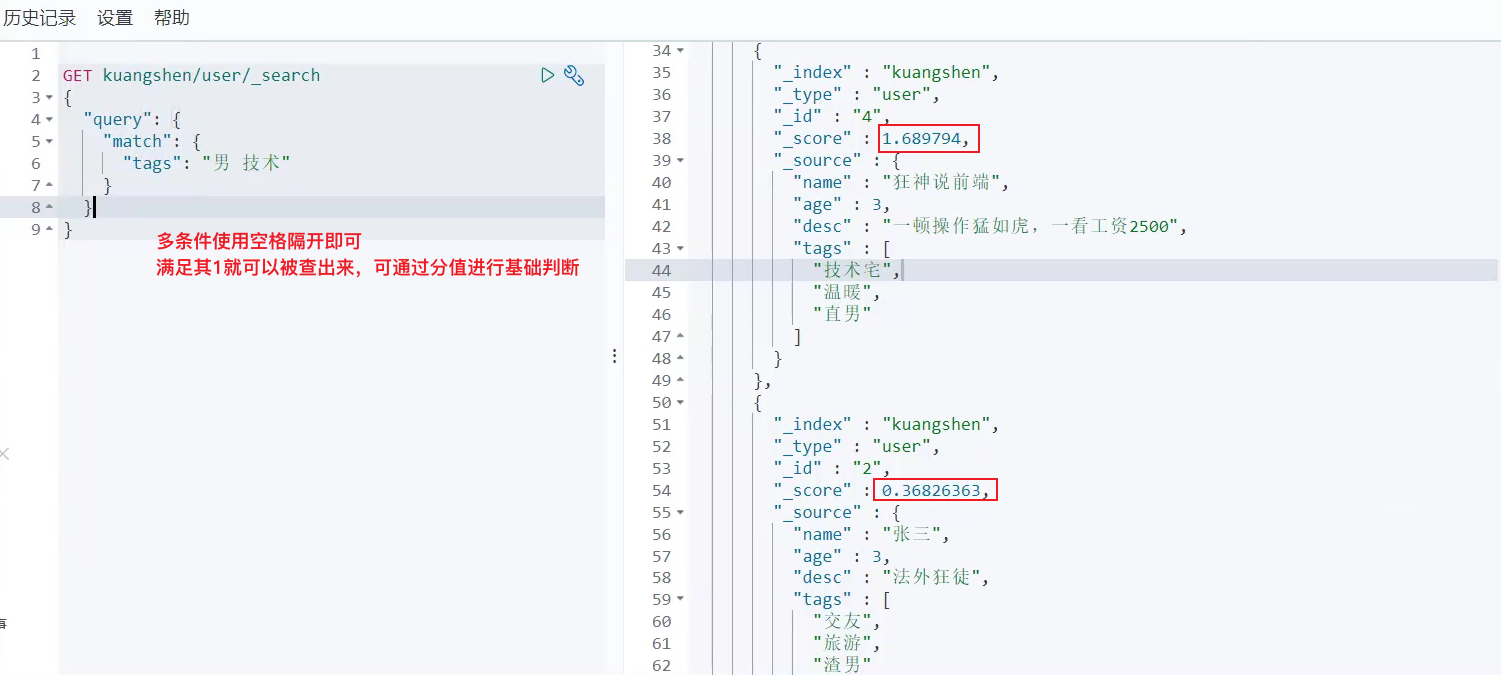
5、多条件查询
6、精确查询
term查询 是直接通过倒排索引指定的词条进行精确查询的~
关于分词:
- term,直接精确查询
- match,会使用分词器解析(上述查男把直男、渣男都查出来了)
两个类型
- text:可以被分词器解析
- kerwork: 不可以被分词器解析
新建testdb库:
put testdb
{"mappings": {"properties": {"name": {"type": "text"},"desc": {"type": "keyword"}}}
}
插入数据:
put testdb/_doc/1
{"name": "狂神说Java","desc": "狂神说Java desc"
}put testdb/_doc/2
{"name": "狂神说Java","desc": "狂神说Java desc2"
}
查询数据
- keyword: (简单字符串,不会被分析)
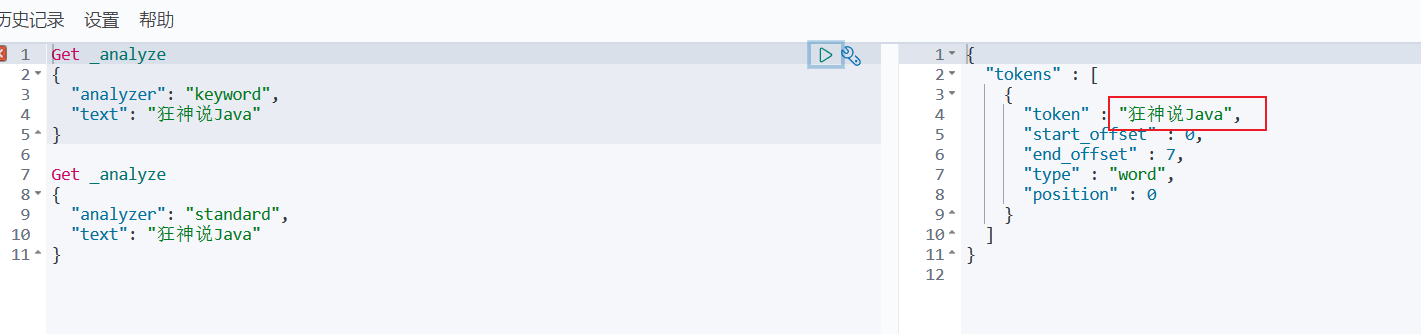
- standard:
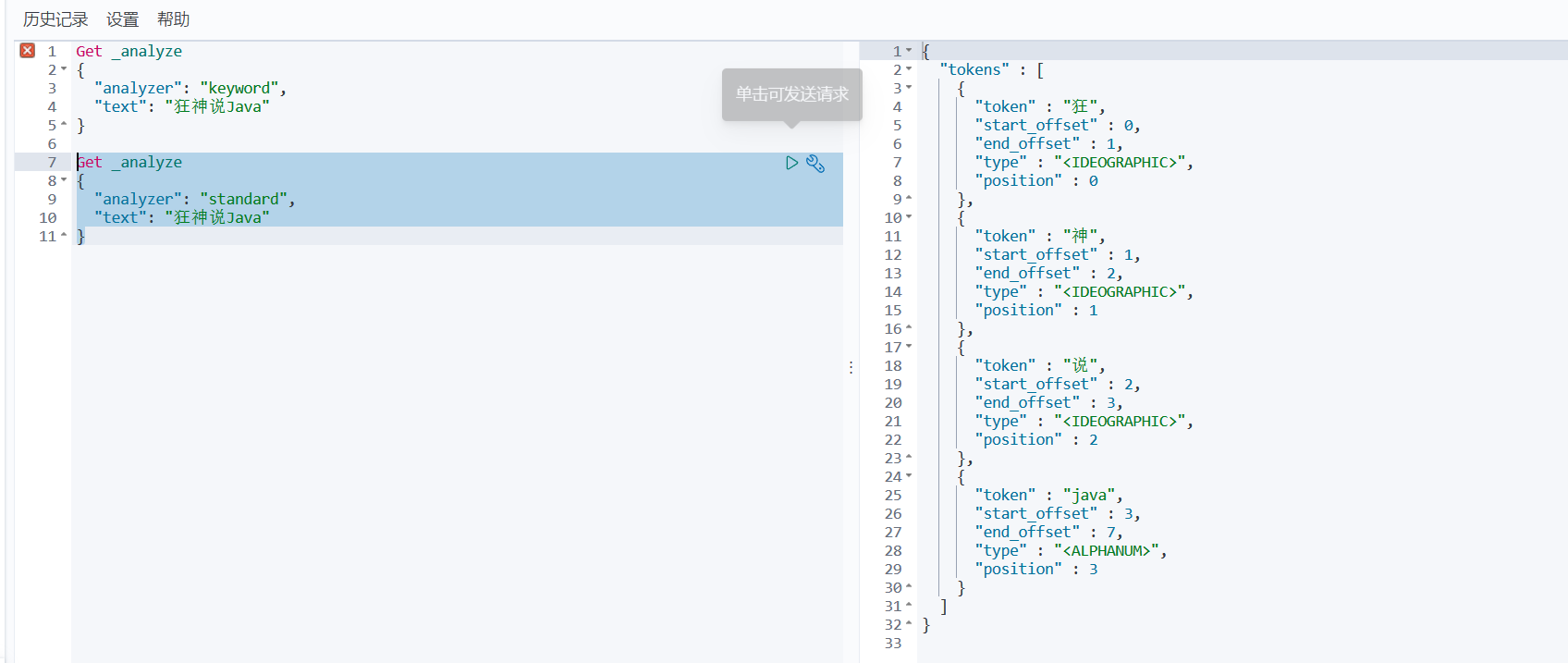
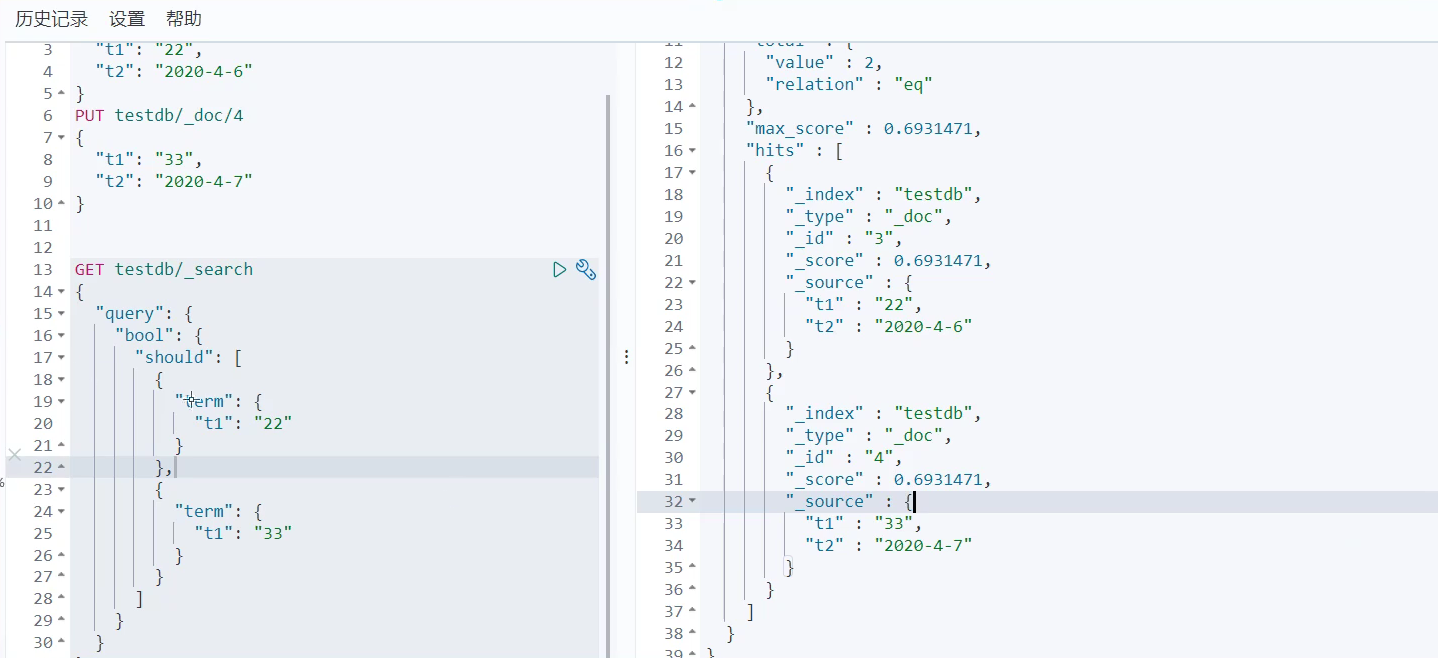
精确查询多个值:
put testdb/_doc/3
{"t1": "22","t2": "2020-4-6"
}put testdb/_doc/4
{"t1": "33","t2": "2020-4-7"
}
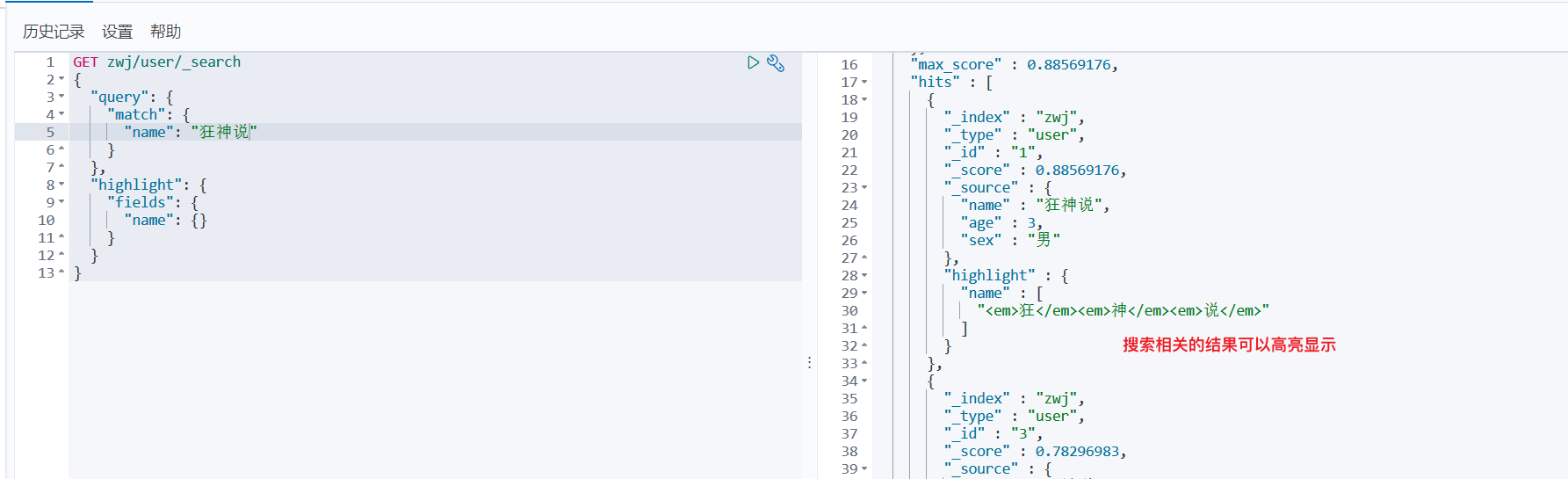
高亮查询:
GET zwj/user/_search
{"query": {"match": {"name": "狂神说"}},"highlight": {"fields": {"name": {}}}
}
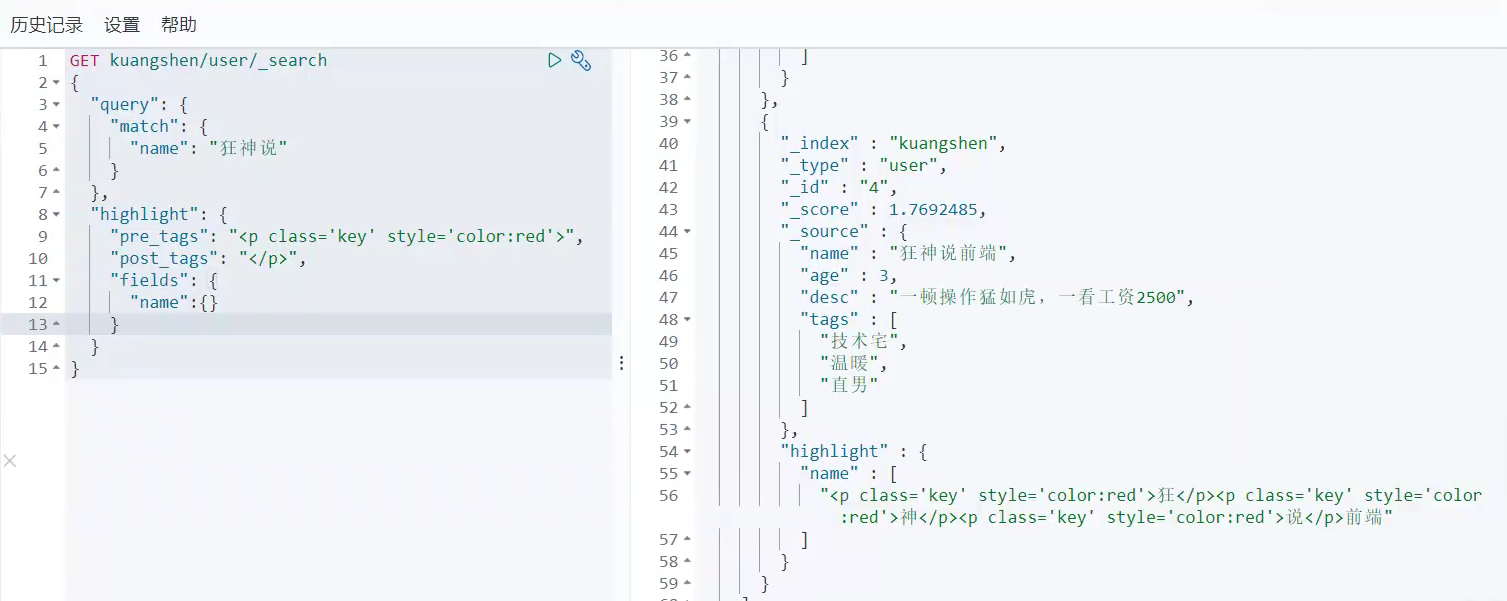
支持自定义搜索高亮:
GET zwj/user/_search
{"highlight": {"pre_tags": {},"post_tags": {}, "fields": {"name": {}}}
}
7、集成SpringBoot
实际上集成做的事情很简单
1、新建SpringBoot项目(目前默认的大版本是3,与2有很大改动,推荐用2)
2、导入相关依赖(我习惯用mybatis和mysql,所以一起导入了)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.10</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.zwj</groupId><artifactId>SpringBootES</artifactId><version>0.0.1-SNAPSHOT</version><name>SpringBootES</name><description>SpringBootES</description><properties><java.version>8</java.version></properties><dependencies><!--elasticsearch 相关--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter-test</artifactId><version>3.0.3</version><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
3、注册bean
package com.zwj.config;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class ESClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){return new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200,"http")));}}
由于一些原因后续的实战我没有跟,公司这个用的不多,一些东西用到的时候还是要去查文档~~
相关文章:
ElasticSearch学习笔记(狂神说)
ElasticSearch学习笔记(狂神说) 视频地址:https://www.bilibili.com/video/BV17a4y1x7zq 在学习ElasticSearch之前,先简单了解一下Lucene: Doug Cutting开发是apache软件基金会 jakarta项目组的一个子项目是一个开放…...
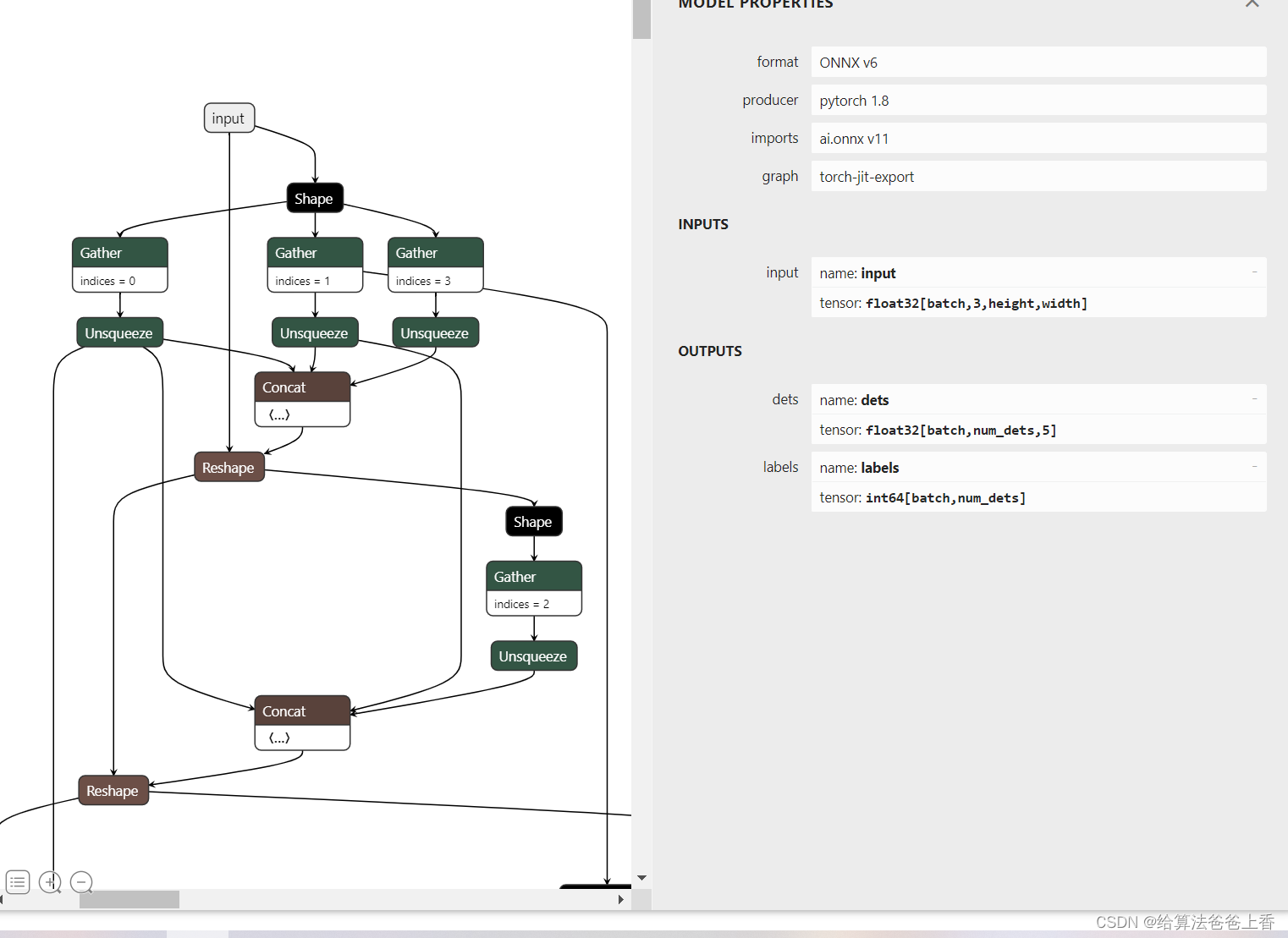
OpenMMlab导出yolox模型并用onnxruntime和tensorrt推理
导出onnx文件 直接使用脚本 import torch from mmdet.apis import init_detector, inference_detectorconfig_file ./configs/yolox/yolox_tiny_8xb8-300e_coco.py checkpoint_file yolox_tiny_8x8_300e_coco_20211124_171234-b4047906.pth model init_detector(config_fi…...

CMake语法解读 | Qt6需要用到
CMake 入门CMakeLists.txtmain.cpp编译示例cmake常用参数入门 Hello CMake CMake 是一个用于配置跨平台源代码项目应该如何配置的工具建立在给定的平台上。 ├── CMakeLists.txt # 希望运行的 CMake命令 ├── main.cpp # 带有main 的源文件 ├── include # 头文件目录 …...

jenkins 参数构建
整体思路 依赖环境及工具 GitCentos7及以上GitlabJenkinsshellansible 创建一个jenkins项目 应用保存,测试构建 在gitlab创建新项目,编写index.html [rootjenkins-node1 .ssh]# ssh-keygen Generating public/private rsa key pair. Enter file in …...
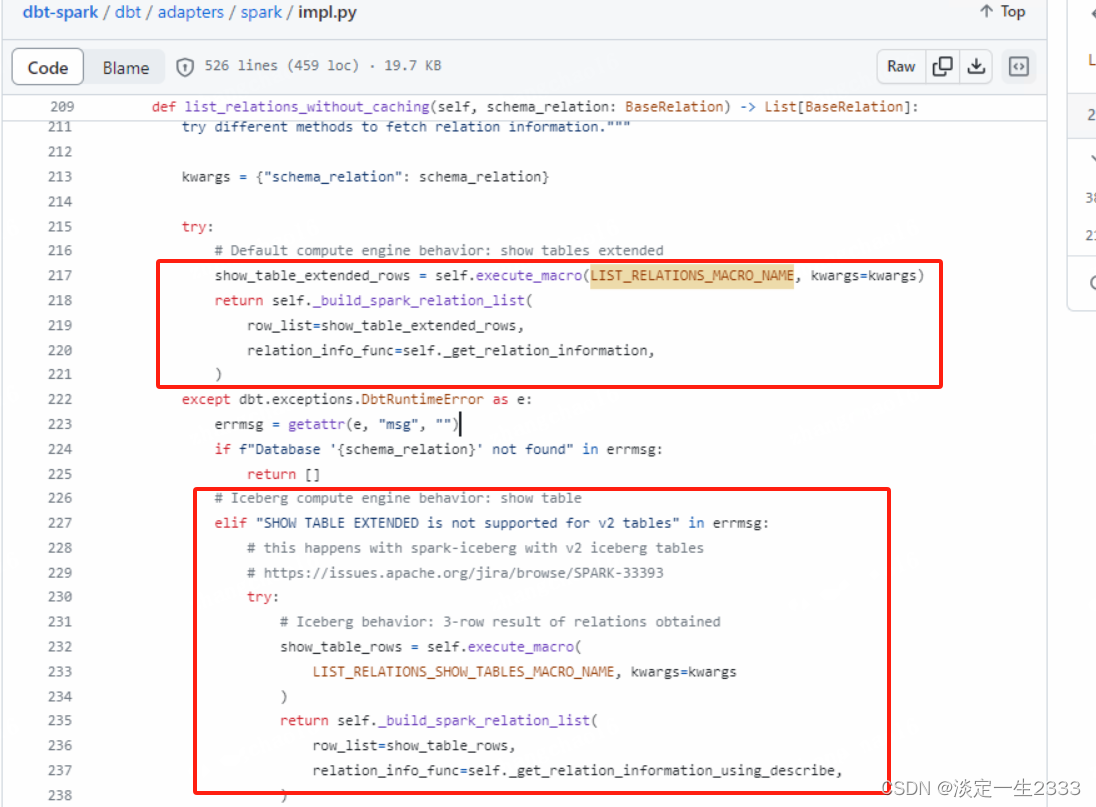
DBT踩坑第二弹
总结下dbt-spark踩到的坑,连接方式采用的是thrift连接 Kerberos认证。考虑到开源组件Kyuubi也是基于Hiveserver2,使用的thrift协议,所以采用Kyuubi执行SparkSQL。 官方文档给出的Thrift方式连接示例真的是简单,但是真是用起来真是…...

elasticsearch Connection reset by peer如何处理
如何处理: 代码的心跳代码删除,服务linux内核参数修改 客户端时间要小于服务端时间#异常代码 public RestHighLevelClient elasticsearchClient() {// 初始化 RestClient, hostName 和 port 填写集群的内网 IP 地址与端口 // String[] hosts nod…...

IO和NIO的区别 BIO,NIO,AIO 有什么区别? Files的常用方法都有哪些?
文章目录 IO和NIO的区别BIO,NIO,AIO 有什么区别?Files的常用方法都有哪些? 今天来对java中的io, nio, bio, aio进行了解,有何区别。 IO和NIO的区别 NIO与IO区别 IO是面向流的,NIO是面向缓冲区的Java IO面向流意味着每次从流中读一个或多个字…...
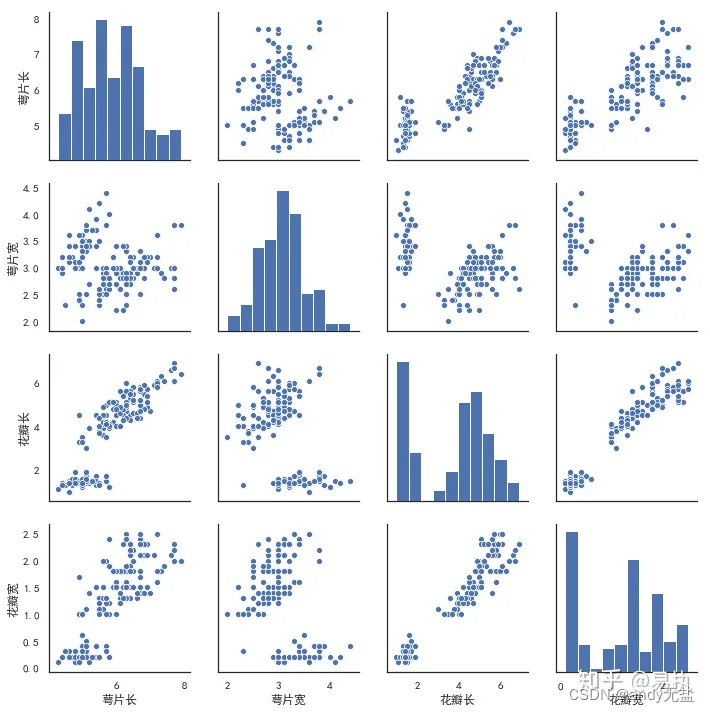
pairplot
Python可视化 | Seaborn5分钟入门(七)——pairplot - 知乎 (zhihu.com) Seaborn是基于matplotlib的Python可视化库。它提供了一个高级界面来绘制有吸引力的统计图形。Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需…...

pytest系列——pytest_collection_modifyitems钩子函数修改测试用例执行顺序
前言 pytest默认执行用例是根据项目下的文件名称按ascii码去收集运行的;文件中的用例是从上往下按顺序执行的。 pytest_collection_modifyitems 这个函数顾名思义就是收集测试用例、改变用例的执行顺序的。 【严格意义上来说,我们在用例设计原则上用例…...
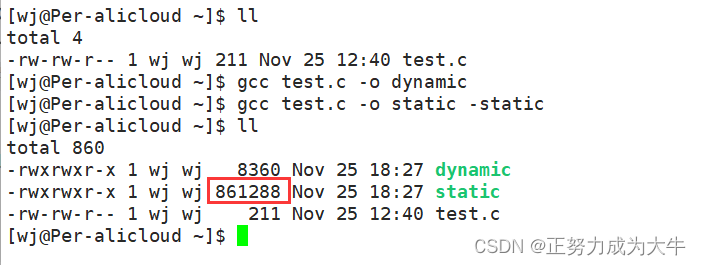
【Linux】gcc和g++
👦个人主页:Weraphael ✍🏻作者简介:目前正在学习c和Linux还有算法 ✈️专栏:Linux 🐋 希望大家多多支持,咱一起进步!😁 如果文章有啥瑕疵,希望大佬指点一二 …...
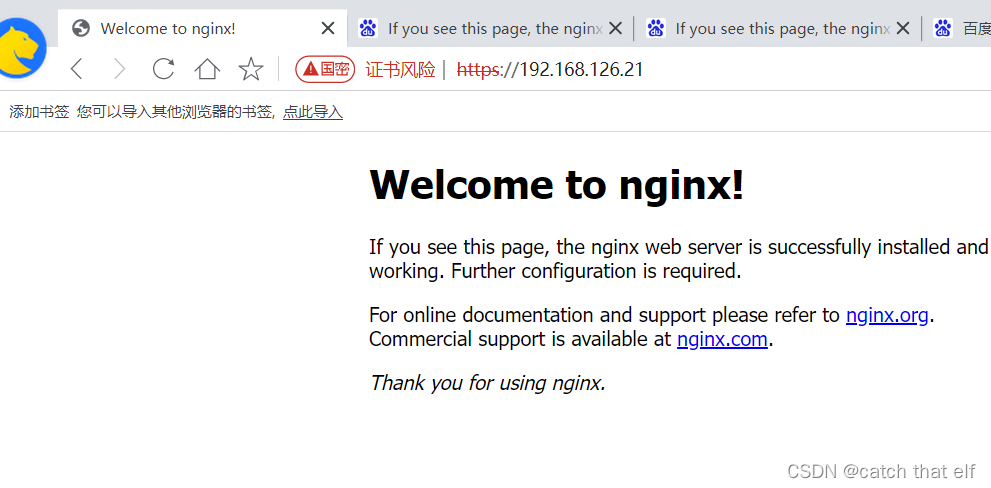
nginx国密ssl测试
文章目录 文件准备编译部署nginx申请国密数字证书配置证书并测试 文件准备 下载文件并上传到服务器,这里使用centos 7.8 本文涉及的程序文件已打包可以直接下载。 点击下载 下载国密版openssl https://www.gmssl.cn/gmssl/index.jsp 下载稳定版nginx http://n…...

H5 清除浮动
1、为什么要清除浮动? 为了解决块级元素浮动后父元素塌陷问题。 2、为什么会产生 父元素塌陷? 首先父元素没有设置高度,父元素的高度是由子元素中最高的控件决定,撑开 简单可以这样理解,原本是在和父元素在同一层级上…...
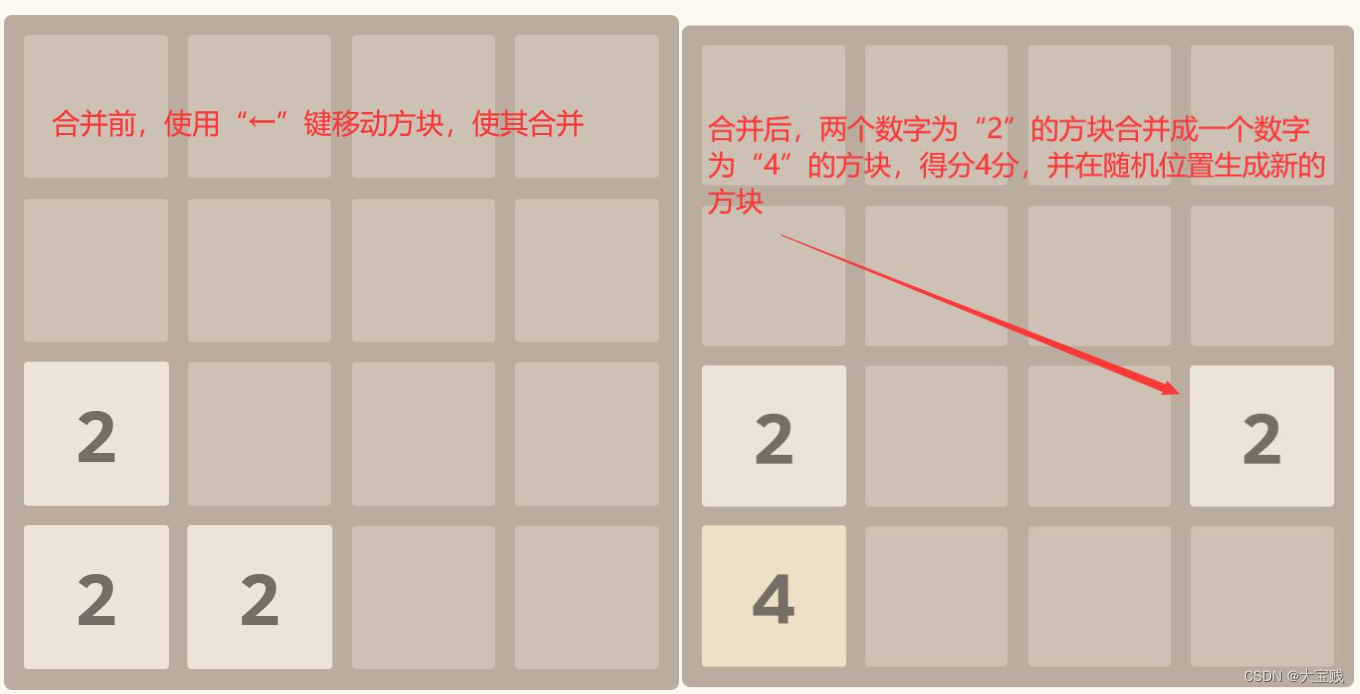
h5小游戏--2048
2048 经典2048小游戏,基于JS、Html5改写版 效果预览 点我下载源代码 下载代码解压后,双击index.html即可开始本游戏。 Game Rule 游戏规则 以下为游戏默认规则,若需要修改规则请修改代码。 移动箭头键来移动方块,当两个相同数…...

随手写了个博客多平台发布脚本:Python自动发布文章到Wordpress
引言 作为一名技术博主,提高博客发布效率是我们始终追求的目标。在这篇文章中,我将分享一个基于Python的脚本,能够实现博客多平台发布,具体来说,是自动发布文章到WordPress。通过这个简单而高效的脚本,…...

通义灵码,你的智能编码助手,免费公测啦!
目录 编辑 1、介绍 2、安装 3、功能介绍 行/函数级实时续写 自然语言生成代码 单元测试生成 代码注释生成 代码解释 研发智能问答 多编程语言、多编辑器全方位支持 4、视频 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家…...
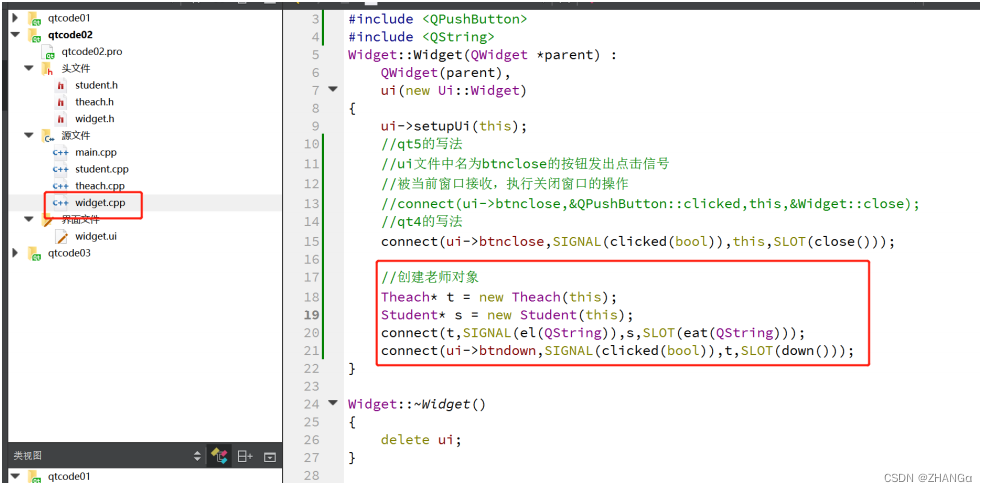
QT Day01 qt概述,创建项目,窗口属性,按钮,信号与槽
1.qt概述 1.什么是qt Qt 是一个跨平台的 C 图形用户界面应用程序框架。它为应用程序开发者提供建立艺 术级图形界面所需的所有功能。它是完全面向对象的,很容易扩展,并且允许真正的组 件编程。 2.支持的平台 Windows – XP 、 Vista 、 Win7 、 Win8…...
在WSL单机搭建Kafka伪集群)
Kafka(一)在WSL单机搭建Kafka伪集群
目录 1 运行Kafka单实例1.1 Windws1.1.1 安装包下载1.1.2 修改环境变量1.1.3 修改配置文件1.1.4 启动Kafka单机版 1.2 Linux1.2.1 安装包下载1.2.2 创建目录1.2.3 添加环境变量1.2.4 修改配置文件1.2.5 运行Kafka1.2.6 停止Kafka 2 搭建Kafka集群2.1 搭建Zookeeper集群2.2 搭建…...
centos7 keepalived 探测哪个是当前节点
前提 nginx 默认页面内容中需要加上各节点的ip nginx web页面修改 nginx配置文件路径:/etc/nginx/nginx.conf,该配置文件引用了/etc/nginx/conf.d/default.conf 打开/etc/nginx/conf.d/default.conf配置文件可以看到html页面的路径 /usr/share/nginx…...

【iOS】数据持久化(二)之归档和解档(iOS 13以后)
在之前介绍的数据存储方法中,不管是NSUserDefaults还是plist文件都不能对自定义对象进行存储,OC提供的解归档恰好解决了这个问题 本片文章对 iOS13 以后的版本 归档和解档 进行介绍。老版本的解归档见这篇文章:【iOS】文件(对象数…...
OpenHarmony模块化编译
一、环境配置 OpenHarmony版本:OpenHarmony 4.0 Release 编译环境:WSL2 Ubuntu 18.04 平台设备:RK3568 二、配置hb OpenHarmony 代码构建有build.sh和hb两种方式: #方式一、build.sh ./build.sh --product-name rk3568 --ccache#方式二、…...
研究)
石油干线管道关键参数稳定自动控制系统(CAP)研究
石油干线管道关键参数稳定自动控制系统(CAP)研究 摘要 石油干线管道是国家能源输送的重要基础设施,其运行过程中的压力、流量等关键参数的稳定控制直接关系到管道的安全性与经济性。本文针对石油干线管道参数控制的非线性、大滞后、强耦合等特点,设计并实现了一套关键参数…...

零门槛掌握《经济研究》LaTeX模板:从排版小白到学术专家的蜕变指南
零门槛掌握《经济研究》LaTeX模板:从排版小白到学术专家的蜕变指南 【免费下载链接】Chinese-ERJ 《经济研究》杂志 LaTeX 论文模板 - LaTeX Template for Economic Research Journal 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-ERJ 在学术写作的…...

ai赋能开发:让快马平台智能生成带数据分析的dht11温湿度监测应用
最近在做一个智能家居相关的项目,需要用到DHT11温湿度传感器。本来以为就是简单读取数据显示一下,但突然想到能不能加点智能分析功能,让数据更有价值。正好发现了InsCode(快马)平台,它的AI辅助开发功能帮我省去了大量编码时间&…...

Agent可观测性工程:监控、追踪与告警的最佳实践
Agent可观测性工程:监控、追踪与告警的最佳实践 一、 引言 (Introduction) (一)钩子 (The Hook) 你是否有过这种令人抓狂的经历?凌晨三点,手机突然弹出刺耳的告警提示音,内容是“你的金融风控Agent集群延迟飙升至27秒,核心交易拒单率突破5‰阈值!”。你从床上弹起来,…...

如何用klein.php构建RESTful API:10个实用技巧与最佳实践
如何用klein.php构建RESTful API:10个实用技巧与最佳实践 【免费下载链接】klein.php A fast & flexible router 项目地址: https://gitcode.com/gh_mirrors/kl/klein.php klein.php是一款轻量级且高性能的PHP路由库,专为构建快速灵活的Web应…...

ICDM 2024论文精读:MetaSTC如何用‘聚类+元学习’四两拨千斤,大幅提升预测效率?
MetaSTC技术解析:如何用聚类与元学习重构时空预测范式 清晨的城市交通如同人体血管,数据在其中奔流不息。预测这些流动的规律,是智能交通系统的核心挑战。传统深度学习模型往往陷入"算力黑洞"——为了1%的精度提升,需要…...
- 星盾安全体系与 TEE 可信执行环境交互原理)
16 华夏之光永存:华为破局(架构师级)- 星盾安全体系与 TEE 可信执行环境交互原理
原创:华为破局(架构师级)- 星盾安全体系与TEE可信执行环境交互原理 摘要 本文聚焦鸿蒙星盾安全体系与TEE可信执行环境,拆解全域安全架构、TEE核心特性、二者全流程交互原理,揭示鸿蒙硬件级可信全域防护的底层逻辑&…...
)
避坑指南:Electron 31.2.0 开发中常见的5个安全与配置陷阱(含解决方案)
Electron 31.2.0 开发实战:5个高频安全陷阱与工程化解决方案 当你第一次用Electron构建跨平台桌面应用时,控制台突然弹出的安全警告是否让你措手不及?本文将揭示Electron 31.2.0版本中最危险的5个配置陷阱,并提供经过生产验证的解…...

【自动驾驶C++算法优化实战手册】:20年资深专家亲授5大内存泄漏避坑法则与实时性提升300%的关键路径
第一章:自动驾驶C算法优化的底层逻辑与实时性本质自动驾驶系统对C算法的要求远超通用软件:毫秒级延迟、确定性执行路径、零容忍的不可预测抖动。其底层逻辑根植于硬件资源约束与任务语义耦合——感知、规划、控制模块必须在严格的时间预算内完成计算&…...

思源宋体CN:零成本打造专业中文排版的7个实用技巧
思源宋体CN:零成本打造专业中文排版的7个实用技巧 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业字体授权费发愁吗?想找一款既专业又免费的中文字体…...