卷积神经网络(Inception-ResNet-v2)交通标志识别
文章目录
- 一、前言
- 二、前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 2. 导入数据
- 3. 查看数据
- 二、构建一个tf.data.Dataset
- 1.加载数据
- 2. 配置数据集
- 三、构建Inception-ResNet-v2网络
- 1.自己搭建
- 2.官方模型
- 五、设置动态学习率
- 六、训练模型
- 七、模型评估
- 八、模型的保存与加载
- 九、预测
一、前言
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
往期精彩内容:
- 卷积神经网络(CNN)实现mnist手写数字识别
- 卷积神经网络(CNN)多种图片分类的实现
- 卷积神经网络(CNN)衣服图像分类的实现
- 卷积神经网络(CNN)鲜花识别
- 卷积神经网络(CNN)天气识别
- 卷积神经网络(VGG-16)识别海贼王草帽一伙
- 卷积神经网络(ResNet-50)鸟类识别
- 卷积神经网络(AlexNet)鸟类识别
- 卷积神经网络(CNN)识别验证码
来自专栏:机器学习与深度学习算法推荐
二、前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")
2. 导入数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL,pathlib# 设置随机种子尽可能使结果可以重现
import pandas as pd
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)from tensorflow import keras
from tensorflow.keras import layers,models
# 导入图片数据
pictures_dir = "images"
pictures_dir = pathlib.Path("pictures_dir")# 导入训练数据的图片路径名及标签
train = pd.read_csv("annotations.csv")
3. 查看数据
image_count = len(list(pictures_dir.glob('*.png')))
print("图片总数为:",image_count)
图片总数为: 5998
train.head()
| file_name | category | |
|---|---|---|
| 0 | 000_0001.png | 0 |
| 1 | 000_0002.png | 0 |
| 2 | 000_0003.png | 0 |
| 3 | 000_0010.png | 0 |
| 4 | 000_0011.png | 0 |
二、构建一个tf.data.Dataset
1.加载数据
数据集中已经划分好了测试集与训练集,这次只需要进行分别加载就好了。
def preprocess_image(image):image = tf.image.decode_jpeg(image, channels=3) # 编码解码处理image = tf.image.resize(image, [299,299]) # 图片调整return image/255.0 # 归一化处理def load_and_preprocess_image(path):image = tf.io.read_file(path)return preprocess_image(image)
AUTOTUNE = tf.data.experimental.AUTOTUNE
common_paths = "images/"# 训练数据的标签
train_image_label = [i for i in train["category"]]
train_label_ds = tf.data.Dataset.from_tensor_slices(train_image_label)# 训练数据的路径
train_image_paths = [ common_paths+i for i in train["file_name"]]
# 加载图片路径
train_path_ds = tf.data.Dataset.from_tensor_slices(train_image_paths)
# 加载图片数据
train_image_ds = train_path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
# 将图片与标签进行对应打包
image_label_ds = tf.data.Dataset.zip((train_image_ds, train_label_ds))
image_label_ds
plt.figure(figsize=(20,4))for i in range(20):plt.subplot(2,10,i+1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片images = plt.imread(train_image_paths[i])plt.imshow(images)# 显示标签plt.xlabel(train_image_label[i])plt.show()

2. 配置数据集
BATCH_SIZE = 6# 将训练数据集拆分成训练集与验证集
train_ds = image_label_ds.take(5000).shuffle(1000) # 前1500个batch
val_ds = image_label_ds.skip(5000).shuffle(1000) # 跳过前1500,选取后面的train_ds = train_ds.batch(BATCH_SIZE)
train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)val_ds = val_ds.batch(BATCH_SIZE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)
val_ds
# 查看数据 shape 进行检查
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(6, 299, 299, 3)
(6,)
# 再次查看数据,确认是否被打乱
plt.figure(figsize=(8,8))for images, labels in train_ds.take(1):for i in range(6):ax = plt.subplot(4, 3, i + 1) plt.imshow(images[i])plt.title(labels[i].numpy()) #使用.numpy()将张量转换为 NumPy 数组plt.axis("off")

三、构建Inception-ResNet-v2网络
1.自己搭建
下面是本文的重点 InceptionResNetV2 网络模型的构建,可以试着按照上面的图自己构建一下 InceptionResNetV2,这部分我主要是参考官网的构建过程,将其单独拎了出来。
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, Dense, Flatten, Dropout,BatchNormalization,Activation
from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D, Concatenate, Lambda,GlobalAveragePooling2D
from tensorflow.keras import backend as Kdef conv2d_bn(x,filters,kernel_size,strides=1,padding='same',activation='relu',use_bias=False,name=None):x = Conv2D(filters,kernel_size,strides=strides,padding=padding,use_bias=use_bias,name=name)(x)if not use_bias:bn_axis = 1 if K.image_data_format() == 'channels_first' else 3bn_name = None if name is None else name + '_bn'x = BatchNormalization(axis=bn_axis, scale=False, name=bn_name)(x)if activation is not None:ac_name = None if name is None else name + '_ac'x = Activation(activation, name=ac_name)(x)return xdef inception_resnet_block(x, scale, block_type, block_idx, activation='relu'):if block_type == 'block35':branch_0 = conv2d_bn(x, 32, 1)branch_1 = conv2d_bn(x, 32, 1)branch_1 = conv2d_bn(branch_1, 32, 3)branch_2 = conv2d_bn(x, 32, 1)branch_2 = conv2d_bn(branch_2, 48, 3)branch_2 = conv2d_bn(branch_2, 64, 3)branches = [branch_0, branch_1, branch_2]elif block_type == 'block17':branch_0 = conv2d_bn(x, 192, 1)branch_1 = conv2d_bn(x, 128, 1)branch_1 = conv2d_bn(branch_1, 160, [1, 7])branch_1 = conv2d_bn(branch_1, 192, [7, 1])branches = [branch_0, branch_1]elif block_type == 'block8':branch_0 = conv2d_bn(x, 192, 1)branch_1 = conv2d_bn(x, 192, 1)branch_1 = conv2d_bn(branch_1, 224, [1, 3])branch_1 = conv2d_bn(branch_1, 256, [3, 1])branches = [branch_0, branch_1]else:raise ValueError('Unknown Inception-ResNet block type. ''Expects "block35", "block17" or "block8", ''but got: ' + str(block_type))block_name = block_type + '_' + str(block_idx)mixed = Concatenate(name=block_name + '_mixed')(branches)up = conv2d_bn(mixed,K.int_shape(x)[3],1,activation=None,use_bias=True,name=block_name + '_conv')x = Lambda(lambda inputs, scale: inputs[0] + inputs[1] * scale,output_shape=K.int_shape(x)[1:],arguments={'scale': scale},name=block_name)([x, up])if activation is not None:x = Activation(activation, name=block_name + '_ac')(x)return xdef InceptionResNetV2(input_shape=[299,299,3],classes=1000):inputs = Input(shape=input_shape)# Stem blockx = conv2d_bn(inputs, 32, 3, strides=2, padding='valid')x = conv2d_bn(x, 32, 3, padding='valid')x = conv2d_bn(x, 64, 3)x = MaxPooling2D(3, strides=2)(x)x = conv2d_bn(x, 80, 1, padding='valid')x = conv2d_bn(x, 192, 3, padding='valid')x = MaxPooling2D(3, strides=2)(x)# Mixed 5b (Inception-A block)branch_0 = conv2d_bn(x, 96, 1)branch_1 = conv2d_bn(x, 48, 1)branch_1 = conv2d_bn(branch_1, 64, 5)branch_2 = conv2d_bn(x, 64, 1)branch_2 = conv2d_bn(branch_2, 96, 3)branch_2 = conv2d_bn(branch_2, 96, 3)branch_pool = AveragePooling2D(3, strides=1, padding='same')(x)branch_pool = conv2d_bn(branch_pool, 64, 1)branches = [branch_0, branch_1, branch_2, branch_pool]x = Concatenate(name='mixed_5b')(branches)# 10次 Inception-ResNet-A blockfor block_idx in range(1, 11):x = inception_resnet_block(x, scale=0.17, block_type='block35', block_idx=block_idx)# Reduction-A blockbranch_0 = conv2d_bn(x, 384, 3, strides=2, padding='valid')branch_1 = conv2d_bn(x, 256, 1)branch_1 = conv2d_bn(branch_1, 256, 3)branch_1 = conv2d_bn(branch_1, 384, 3, strides=2, padding='valid')branch_pool = MaxPooling2D(3, strides=2, padding='valid')(x)branches = [branch_0, branch_1, branch_pool]x = Concatenate(name='mixed_6a')(branches)# 20次 Inception-ResNet-B blockfor block_idx in range(1, 21):x = inception_resnet_block(x, scale=0.1, block_type='block17', block_idx=block_idx)# Reduction-B blockbranch_0 = conv2d_bn(x, 256, 1)branch_0 = conv2d_bn(branch_0, 384, 3, strides=2, padding='valid')branch_1 = conv2d_bn(x, 256, 1)branch_1 = conv2d_bn(branch_1, 288, 3, strides=2, padding='valid')branch_2 = conv2d_bn(x, 256, 1)branch_2 = conv2d_bn(branch_2, 288, 3)branch_2 = conv2d_bn(branch_2, 320, 3, strides=2, padding='valid')branch_pool = MaxPooling2D(3, strides=2, padding='valid')(x)branches = [branch_0, branch_1, branch_2, branch_pool]x = Concatenate(name='mixed_7a')(branches)# 10次 Inception-ResNet-C blockfor block_idx in range(1, 10):x = inception_resnet_block(x, scale=0.2, block_type='block8', block_idx=block_idx)x = inception_resnet_block(x, scale=1., activation=None, block_type='block8', block_idx=10)x = conv2d_bn(x, 1536, 1, name='conv_7b')x = GlobalAveragePooling2D(name='avg_pool')(x)x = Dense(classes, activation='softmax', name='predictions')(x)# 创建模型model = Model(inputs, x, name='inception_resnet_v2')return modelmodel = InceptionResNetV2([299,299,3],58)
model.summary()
2.官方模型
# import tensorflow as tf
# # 如果使用官方模型需要将图片shape调整为 [299,299,3],目前图片的shape是 [150,150,3]
# model = tf.keras.applications.inception_resnet_v2.InceptionResNetV2()
# model.summary()
五、设置动态学习率
这里先罗列一下学习率大与学习率小的优缺点。
- 学习率大
- 优点: 1、加快学习速率。 2、有助于跳出局部最优值。
- 缺点: 1、导致模型训练不收敛。 2、单单使用大学习率容易导致模型不精确。
- 学习率小
- 优点: 1、有助于模型收敛、模型细化。 2、提高模型精度。
- 缺点: 1、很难跳出局部最优值。 2、收敛缓慢。
注意:这里设置的动态学习率为:指数衰减型(ExponentialDecay)。在每一个epoch开始前,学习率(learning_rate)都将会重置为初始学习率(initial_learning_rate),然后再重新开始衰减。计算公式如下:
learning_rate = initial_learning_rate * decay_rate ^ (step / decay_steps)
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])
六、训练模型
Inception-ResNet-v2 模型相对之前的模型较为复杂,故而运行耗时也更长,我这边每一个epoch运行时间是130s左右。我的GPU配置是 NVIDIA GeForce RTX 3080。建议大家先将 epochs 调整为1跑通程序。
epochs = 10history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
Epoch 1/10
834/834 [==============================] - 154s 163ms/step - loss: 2.5214 - accuracy: 0.3563 - val_loss: 1.3834 - val_accuracy: 0.6168
Epoch 2/10
834/834 [==============================] - 133s 159ms/step - loss: 0.9230 - accuracy: 0.7522 - val_loss: 0.5457 - val_accuracy: 0.8531
Epoch 3/10
834/834 [==============================] - 133s 159ms/step - loss: 0.3952 - accuracy: 0.9105 - val_loss: 0.3391 - val_accuracy: 0.9064
Epoch 4/10
834/834 [==============================] - 134s 160ms/step - loss: 0.1876 - accuracy: 0.9655 - val_loss: 0.2481 - val_accuracy: 0.9296
Epoch 5/10
834/834 [==============================] - 131s 156ms/step - loss: 0.1071 - accuracy: 0.9862 - val_loss: 0.1265 - val_accuracy: 0.9716
Epoch 6/10
834/834 [==============================] - 128s 153ms/step - loss: 0.0587 - accuracy: 0.9954 - val_loss: 0.0911 - val_accuracy: 0.9794
Epoch 7/10
834/834 [==============================] - 132s 158ms/step - loss: 0.0429 - accuracy: 0.9976 - val_loss: 0.0941 - val_accuracy: 0.9777
Epoch 8/10
834/834 [==============================] - 132s 158ms/step - loss: 0.0306 - accuracy: 0.9980 - val_loss: 0.0955 - val_accuracy: 0.9777
Epoch 9/10
834/834 [==============================] - 133s 158ms/step - loss: 0.0248 - accuracy: 0.9997 - val_loss: 0.0864 - val_accuracy: 0.9794
Epoch 10/10
834/834 [==============================] - 132s 158ms/step - loss: 0.0216 - accuracy: 0.9988 - val_loss: 0.0750 - val_accuracy: 0.9794
七、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
八、模型的保存与加载
# 保存模型
model.save('model/14_model.h5')
# 加载模型
new_model = keras.models.load_model('model/14_model.h5')
九、预测
# 采用加载的模型(new_model)来看预测结果plt.figure(figsize=(10, 5)) # 图形的宽为10高为5for images, labels in val_ds.take(1):for i in range(6):ax = plt.subplot(2, 3, i + 1) # 显示图片plt.imshow(images[i])# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0) # 使用模型预测路标predictions = new_model.predict(img_array)plt.title(np.argmax(predictions))plt.axis("off")

相关文章:
卷积神经网络(Inception-ResNet-v2)交通标志识别
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、构建一个tf.data.Dataset1.加载数据2. 配置数据集 三、构建Inception-ResNet-v2网络1.自己搭建2.官方模型 五、设置动态学习率六、训练模型七、模型评…...

网易云音频数据如何爬取?
在当今数字化时代,音频数据的获取和处理变得越来越重要。本文将详细介绍如何使用Objective-C语言构建音频爬虫程序,以爬取网易云音乐为案例。我们将从Objective-C的基础知识开始,逐步深入到爬取思路分析、构建爬虫框架、完整爬取代码等方面&a…...

97、Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
简介 论文地址 使用扩散模型来推断文本相关图像作为内容先验,并使用单目深度估计方法来提供几何先验,并引入了一种渐进的场景绘制和更新策略,保证不同视图之间纹理和几何的一致性 实现流程 简单而言: 文本-图片扩散模型生成一…...
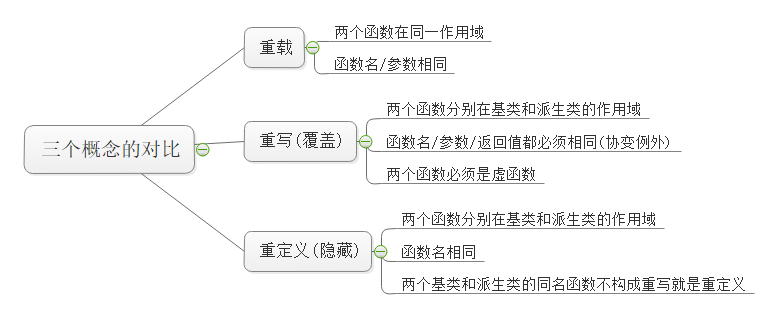
【C++】多态(上) 多态 | 虚函数 | 重写 | final、override | 接口继承与实现继承 | 抽象类
一、多态 概念 多态,就是多种状态,即不同的对象去完成同一个行为时会产生出不同的状态。比如:买票时,成人要原价买,学生和老人就可以享受优惠价便宜一点儿。同样是买票这个行为,不同的对象来做就有不同的…...

国内怎么投资黄金,炒黄金有哪些好方法?
随着我国综合实力的不断强大,投资市场的发展也日臻完善,现已成为了国际黄金市场的重要组成部分,人们想要精准判断金市走向,就离不开对我国经济等信息的仔细分析。而想要有效提升盈利概率,人们还需要掌握国内黄金投资的…...
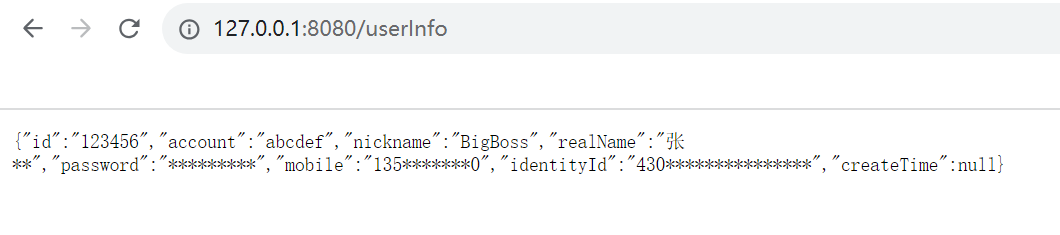
springboot实现数据脱敏
springboot实现数据脱敏 怎么说呢,写着写着发觉 ”这写的什么玩意“ 。 总的来说就是,这篇文章并不能解决数据脱敏问题,但以下链接可以。 SpringBoot中利用自定义注解优雅地实现隐私数据脱敏 然后回到本文,本来是想基于AOP代理&am…...
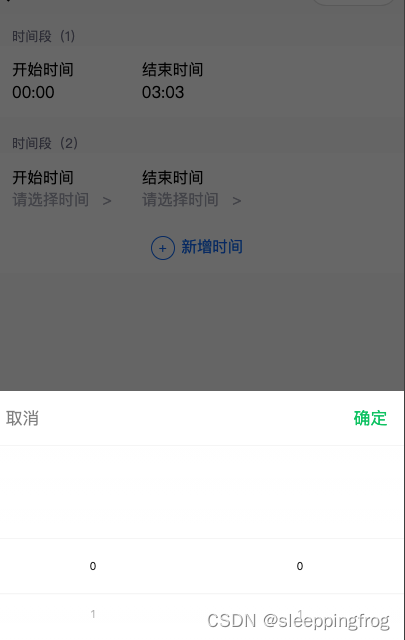
uniapp实现多时间段设置
功能说明: 1 点击新增时间,出现一个默认时间段模板,不能提交 2 点击“新增时间文本”,弹出弹窗,选择时间,不允许开始时间和结束时间同时为00:00, <view class"item_cont"> …...

uni-app - 去除隐藏页面右侧垂直滚动条
全局配置 "globalStyle": { //全局配置 "scrollIndicator":"none", // 不显示滚动条 "app-plus":{ "scrollIndicator":"none" // 在APP平台都不显示滚动条 } }局部配置 "path": "pages/ind…...
)
一次简单的 Http 请求异常处理 (请求的 url 太长, Nginx 直接返回 400, 导致请求服务异常)
1 结论 按照惯例直接说结论。 后台服务 A 有一个 Http 接口, 代码如下: RequestMapping(value "/user", method RequestMethod.GET) public List<UserInfoVo> getUserInfoByUserIds(RequestParam(value "userIds") List<String> userIds…...
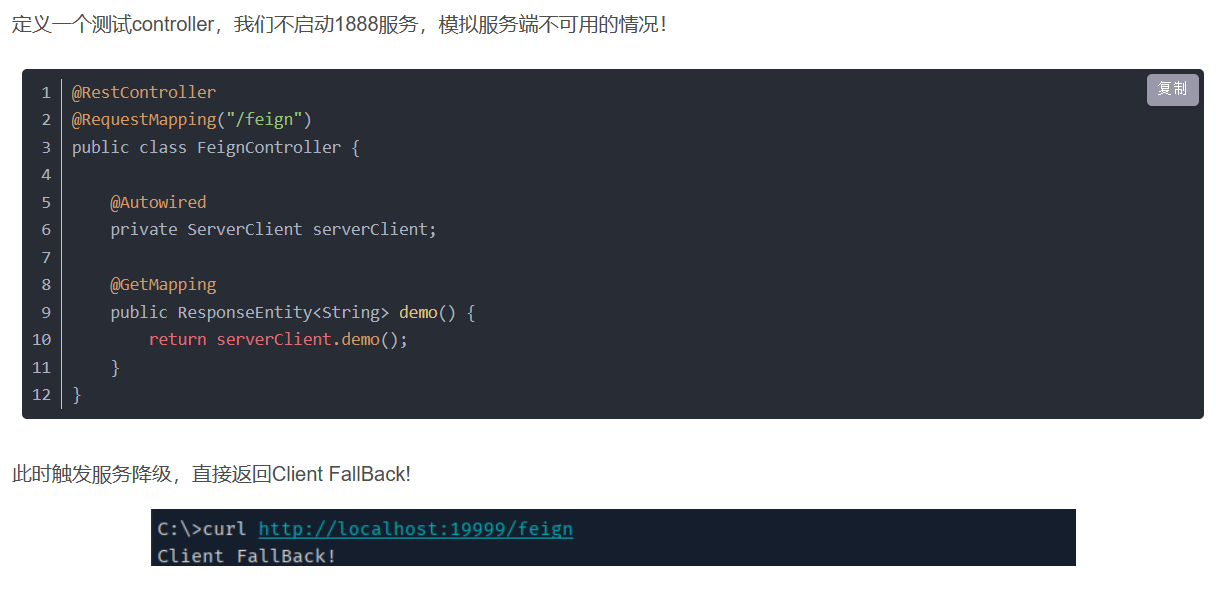
spring Cloud在代码中如何应用,erueka 客户端配置 和 服务端配置,Feign 和 Hystrix做高可用配置
文章目录 Eureka一、erueka 客户端配置二、eureka 服务端配置 三、高可用配置FeignHystrix 通过这篇文章来看看spring Cloud在代码中的具体应用,以及配置和注解; Eureka 一、erueka 客户端配置 1、Eureka 启禁用 eureka.client.enabledtrue 2、Eurek…...

C#8.0中新语法“is {}“的介绍及使用
一、C#7.0及之前is的使用 is操作符检查表达式的结果是否与给定类型兼容,或者(从c# 7.0开始)根据模式测试表达式。有关类型测试is操作符的信息,请参阅类型测试和类型转换操作符文章的is操作符部分。 1、is 模式匹配 从C࿰…...

编译器设计01-入门概述
编译器作用概述 源代码 → 编译器 目标代码 源代码\xrightarrow{\ \ \ 编译器\ \ \ }目标代码 源代码 编译器 目标代码 编译阶段概述 编译处理包括两个阶段:前端处理和后端处理,中间过程生成语法树。 编译处理:源代码 → 语法树 …...

SpringBoot封装Elasticsearch搜索引擎实现全文检索
一、前言 注:本文实现了Java对Elasticseach的分页检索/不分页检索的封装 ES就不用过多介绍了,直接上代码: 二、实现步骤: 创建Store类(与ES字段对应,用于接收ES数据) import com.alibaba.f…...
一些题4)
(C)一些题4
1. 以下叙述中正确的是( )。 A.C程序中的注释只能出现在程序的开始位置和语句的后面 B.C程序书写格式严格,要求行内只能写一个语句 C,C程序书写格式自由,一个语句可以写在多行上 D.用C语言编写的程序只能放在一个程序文件中 2.设有如下程序段 char …...
ChatGPT初体验:注册、API Key获取与ChatAPI调用详解
自从2022年10月,ChatGPT诞生以后,实际上已经改变了很多!其火爆程度简直超乎想象,一周的时间用户过百万,两个月的时间用户过亿。 目前ChatGPT4已经把2023年4月以前的人类的知识都学习到了,在软件工程里面&am…...

TCP/IP协议、三次握手、四次挥手
TCP/IP TCP/IP协议分层TCP头部三次握手TCP四次挥手常见问题1、什么是TCP网络分层2、TCP为什么是三次握手,不是两次或者四次?3、TCP为什么是四次挥手,为什么不能是三次挥手将第二次挥手和第三次挥手合并?4、四次挥手时为什么TIME_W…...

Android U 匹配不到APN,无法发起数据建立的问题分析
问题 打开数据开关后,没有data PDN请求发起,因此无法上网。 根据日志确定是没有找到合适的data profile,原因一般有: 1、APN 没有配置 2、APN 类型/网络能力不满足——APN type或bearer 3、APN 配置了但被disable了——APN p…...

如何打造“面向体验”的音视频能力——对话火山引擎王悦
编者按:随着全行业视频化的演进,我们置身于一个充满创新与变革的时代。在这个数字化的浪潮中,视频已经不再只是传递信息的媒介,更是重塑了我们的交互方式和体验感知。作为字节跳动的“能力溢出”,火山引擎正在飞速奔跑…...

什么是NoOps
过去几年,自动化一直在推动整个 IT 行业向前发展。通过自动化某些任务,开发团队可以提高其能力,而无需感受到雇用新团队成员的预算压力。自动化还保证了更高的效率,特别是在操作和维护方面。 传统的软件开发工作流程涉及开发团队…...

Unity - Graphic解析
Gpahic 的作用 Graphic 是 Unity最基础的图形基类。主要负责UGUI的显示部分。 由上图可以看你出我们经常使用的Image,Text,都是继承自Graphic。 Graphic的渲染流程 在Graphic的源码中有以下属性 [NonSerialized] private CanvasRenderer m_CanvasRend…...

ovn 配置逻辑路由器实现三层转发
本文使用ovn搭建一个三层转发的环境,拓扑图如下 image.png 两个虚拟交换机ls1和ls2,端口ip网段分别为 10.10.10.0/24和 10.10.20.0/24。 虚拟交换机上分别连接两个vm(使用namespace模拟),使用dhclient动态获取ip。 一个虚拟路由器lr1,连接两个虚拟交换机ls1和ls2,实现跨网…...

Mel滤波器在语音识别中的关键作用与实现细节
1. 为什么语音识别需要Mel滤波器? 第一次接触语音识别时,我对着频谱图发愁——那些密密麻麻的频率分量看起来毫无规律。直到发现Mel滤波器这个"翻译官",才明白它能把机器看不懂的频谱,转换成人耳熟悉的"语言"…...

B站视频下载高效解决方案:bilibili-downloader完全指南
B站视频下载高效解决方案:bilibili-downloader完全指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 你是否遇到过这些困…...

Qwen3-TTS开源大模型实操:批量处理CSV文本并生成多语种MP3音频的Python脚本
Qwen3-TTS开源大模型实操:批量处理CSV文本并生成多语种MP3音频的Python脚本 1. 为什么你需要这个脚本:从手动点选到全自动批量合成 你有没有试过用Qwen3-TTS WebUI生成几十条产品介绍语音?每次打开页面、粘贴文本、选语言、点生成、等加载、…...

抠图怎么让边缘自然?别自己拿大剪刀,让工具替你“绣花”
还在大刀阔斧自己“操刀”抠图吗?边缘不是模糊发虚就是抠不干净,留着一圈难看的毛边,修来修去还是假得明显,纯属浪费时间。其实抠图怎么让边缘自然,找对合适工具就能让它替你“绣花”般精细抠图,比自己拿“…...

从零到一:Keil5环境搭建与STM32项目实战避坑指南
1. Keil5安装与基础配置 第一次接触Keil MDK的开发者,八成会在安装环节就踩坑。我当年用STM32F103C8T6做毕业设计时,光是解决xerces-c_3_0.dll缺失问题就折腾了一整天。这个经典错误其实有更稳妥的解决方案:除了将dll文件复制到System32目录…...
Pixel Language Portal效果实测:Hunyuan-MT-7B在游戏对话文本中的语气保留与文化适配能力
Pixel Language Portal效果实测:Hunyuan-MT-7B在游戏对话文本中的语气保留与文化适配能力 1. 引言:当翻译遇见像素冒险 在游戏本地化领域,传统翻译工具往往难以捕捉角色对话中的独特语气和文化内涵。Pixel Language Portal(像素…...
)
紧急预警:C++27 std::filesystem::copy_options::recursive_nowait 已被证实引发静默截断!附官方补丁+3行兼容封装方案(2025 Q2前必读)
第一章:C27 文件系统库扩展应用C27 标准对 <filesystem> 库进行了实质性增强,新增了异步路径遍历、符号链接元数据深度解析、跨设备硬链接原子创建以及基于策略的路径规范化接口。这些特性显著提升了在复杂存储拓扑(如容器挂载点、分布…...

3个实用技巧轻松解决ComfyUI-Custom-Scripts新手难题
3个实用技巧轻松解决ComfyUI-Custom-Scripts新手难题 【免费下载链接】ComfyUI-Custom-Scripts Enhancements & experiments for ComfyUI, mostly focusing on UI features 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Custom-Scripts ComfyUI-Custom-Scr…...

WeChatMsg:数据自主权回归的创新方法
WeChatMsg:数据自主权回归的创新方法 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg 副标题…...