Python 使用SQLAlchemy数据库模块
SQLAlchemy 是用Python编程语言开发的一个开源项目,它提供了SQL工具包和ORM对象关系映射工具,使用MIT许可证发行,SQLAlchemy 提供高效和高性能的数据库访问,实现了完整的企业级持久模型。
ORM(对象关系映射)是一种编程模式,用于将对象与关系型数据库中的表和记录进行映射,从而实现通过面向对象的方式进行数据库操作。ORM 的目标是在编程语言中使用类似于面向对象编程的语法,而不是使用传统的 SQL 查询语言,来操作数据库。
主要思想是将数据库表的结构映射到程序中的对象,通过对对象的操作来实现对数据库的操作,而不是直接编写 SQL 查询。ORM 工具负责将数据库记录转换为程序中的对象,反之亦然。
ORM 的核心概念包括:
- 实体(Entity): 在 ORM 中,实体是指映射到数据库表的对象。每个实体对应数据库中的一条记录。
- 属性(Attribute): 实体中的属性对应数据库表中的列。每个属性表示一个字段。
- 关系(Relationship): ORM 允许定义实体之间的关系,例如一对多、多对一、多对多等。这种关系会映射到数据库表之间的关系。
- 映射(Mapping): ORM 负责将实体的属性和方法映射到数据库表的列和操作。
- 会话(Session): ORM 提供了会话来管理对象的生命周期,包括对象的创建、更新和删除。
- 查询语言: ORM 通常提供一种查询语言,允许开发者使用面向对象的方式编写查询,而不是直接使用 SQL。
对象映射ROM模型可连接任何关系数据库,连接方法大同小异,以下总结了如何连接常用的几种数据库方式。
# sqlite 创建数据库连接
engine = create_engine('sqlite:///database.db', echo=False)# sqlite 创建内存数据库
engine = create_engine('sqlite://')
engine = create_engine('sqlite:///:memory:', echo=True)# PostgreSQL 创建数据库连接
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase') # default
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase') # psycopg2
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase') # pg8000# MySQL 创建数据库连接
engine = create_engine('mysql://scott:tiger@localhost/foo') # default
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo') # mysql-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo') # MySQL-connector-python
engine = create_engine('mysql+oursql://scott:tiger@localhost/foo') # OurSQL# Oracle 创建数据库连接
engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')# MSSQL 创建数据库连接
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn') # pyodbc
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname') # pymssql
数据表创建
简单的创建一个User映射类,映射到UserDB库上,分别增加几个常用的数据库字段,并插入一些测试数据。
import sqlite3,datetime,time
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Float, DateTime, Date, Time, Boolean, DECIMAL, Enum, Text# 建立基本映射类
Base = declarative_base()# 创建SQLITE数据库
engine = create_engine('sqlite:///:memory:', echo=False)# 创建映射类User
class User(Base):__tablename__ = 'UserDB'# 主键 primary_key | 自动增长 autoincrement | 不为空 nullable | 唯一性约束 uniqueid = Column(Integer, primary_key=True, autoincrement=True, nullable=True, unique=True)# 字符串类型username = Column(String(32), nullable=True, default="none")password = Column(String(32), nullable=True, default="none")# 姓名字段默认值是0age = Column(Integer,nullable=False, default=0)# 增加创建日期 [日期:时间]create_time = Column(DateTime, default=datetime.datetime.now)# onupdate=datetime.now 每次更新数据的时候都要更新该字段值update_time = Column(DateTime, onupdate=datetime.datetime.now, default=datetime.datetime.now)# 增加用户分数user_value = Column(Float, default=0.0)# 枚举类型定义# tag = Column(Enum("python",'flask','django'))# __repr__方法用于输出该类的对象被print()时输出的字符串,如果不想写可以不写def __repr__(self):return "<UserDB(username='%s',password='%s')>" % (self.username,self.password)if __name__ == "__main__":print("当前表名: {}".format(User.__table__))# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表Base.metadata.create_all(engine, checkfirst=True)# 逐条增加新记录insert_user = User(username='lyshark', password='123456', age=24, user_value=12.5)session.add(insert_user)insert_user = User(username='sqlalchemy', password='123', age=34, user_value=45.8)session.add(insert_user)# 插入多条记录session.add_all([User(username="admin", password="123123", age=54, user_value=66.9),User(username="root", password="3456576", age=67, user_value=98.4)])# 提交事务session.commit()
数据库查询
演示了通过ORM关系映射实现对单表的简单查询与筛选过滤功能。
import sqlite3,time,datetime
from sqlalchemy import func
from sqlalchemy import or_
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Float,DateTime# 建立基本映射类
Base = declarative_base()# 创建SQLITE数据库
engine = create_engine('sqlite:///:memory:', echo=False)# 创建映射类User
class User(Base):__tablename__ = 'UserDB'id = Column(Integer, primary_key=True, autoincrement=True, nullable=True, unique=True)username = Column(String(32), nullable=True, default="none")password = Column(String(32), nullable=True, default="none")age = Column(Integer,nullable=False, default=0)create_time = Column(DateTime, default=datetime.datetime.now)update_time = Column(DateTime, onupdate=datetime.datetime.now, default=datetime.datetime.now)user_value = Column(Float, default=0.0)# __repr__方法用于输出该类的对象被print()时输出的字符串,如果不想写可以不写def __repr__(self):return "<UserDB(username='%s',password='%s')>" % (self.username,self.password)if __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# 查询所有字段all_value = session.query(User).all()for item in all_value:print("ID: {} --> 用户: {}".format(item.id, item.username))# 查询指定字段key_value = session.query(User.username,User.password).all()print(key_value)# 查询第一条first_value = session.query(User).first()print("第一条记录: {} {}".format(first_value.username, first_value.password))# 使用过滤器 [ 过滤出age>20的用户,输出其(id,username)字段 ]filter_value = session.query(User.id,User.username).filter(User.age > 20).all()print("过滤结果: {}".format(filter_value))# 排序输出 [ 正序/倒序 ]sort_value = session.query(User.username,User.age).order_by(User.age).all()print("正序排列: {}".format(sort_value))sort_value = session.query(User.username,User.age).order_by(User.age.desc()).all()print("倒序排列: {}".format(sort_value))# 查询计数count_value = session.query(User).count()print("记录条数: {}".format(count_value))# and/or 条件过滤 默认为and 在filter()中用,分隔多个条件表示,如果是or则需增加or_连接多个条件and_value = session.query(User.username,User.age).filter(User.age >= 20, User.age <= 40).all()print("与查询: {}".format(and_value))or_value = session.query(User.username,User.age).filter(or_(User.age >= 20, User.age <= 40)).all()print("或查询: {}".format(or_value))# 等于查询equal_value = session.query(User.username,User.password).filter(User.age == 67).all()print("等于查询: {}".format(equal_value))not_equal_value = session.query(User.username,User.password).filter(User.age != 67).all()print("不等于查询: {}".format(not_equal_value))# like模糊匹配like_value = session.query(User.username,User.create_time).filter(User.username.like("%ly%")).all()print("模糊匹配: {}".format(like_value))# in查询范围in_value = session.query(User.username,User.password).filter(User.age.in_([24,34])).all()print("查询两者: {}".format(in_value))not_in_value = session.query(User.username,User.password).filter(User.age.notin_([24,34])).all()print("查询非两者: {}".format(not_in_value))# op正则匹配查询op_value = session.query(User.username).filter(User.username.op("regexp")("^a")).all()print("正则匹配: {}".format(op_value))# 调用数据库内置函数func_value = session.query(func.count(User.age)).one()print("调用函数: {}".format(func_value))# 数据切片cat_value = session.query(User.username).all()[:2]print("输出前两条: {}".format(cat_value))cat_value = session.query(User.username).offset(5).limit(3).all()print("第6行开始显示前3个: {}".format(cat_value))cat_value = session.query(User.username).order_by(User.id.desc())[0:10]print("输出最后10个: {}".format(cat_value))# 非空查询isnot_value = session.query(User).filter(User.username.isnot(None)).all()print("非空显示: {}".format(isnot_value))null_value = session.query(User).filter(User.username.is_(None)).all()print("为空显示: {}".format(null_value))# 分组测试group_by = session.query(User.username,func.count(User.id)).group_by(User.age).all()print("根据年龄分组: {}".format(group_by))# 进一步过滤查询having_by = session.query(User.username,User.age).group_by(User.age).having(User.age > 30).all()print("以age分组,并查询age大于30的记录: {}".format(having_by))
数据库修改
演示了修改数据库参数以及对数据库指定记录的删除功能。
import sqlite3,time,datetime
from sqlalchemy import func
from sqlalchemy import or_
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Float,DateTime# 建立基本映射类
Base = declarative_base()# 创建SQLITE数据库
engine = create_engine('sqlite:///:memory:', echo=False)# 创建映射类User
class User(Base):__tablename__ = 'UserDB'id = Column(Integer, primary_key=True, autoincrement=True, nullable=True, unique=True)username = Column(String(32), nullable=True, default="none")password = Column(String(32), nullable=True, default="none")age = Column(Integer,nullable=False, default=0)create_time = Column(DateTime, default=datetime.datetime.now)update_time = Column(DateTime, onupdate=datetime.datetime.now, default=datetime.datetime.now)user_value = Column(Float, default=0.0)# __repr__方法用于输出该类的对象被print()时输出的字符串,如果不想写可以不写def __repr__(self):return "<UserDB(username='%s',password='%s')>" % (self.username,self.password)if __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# 修改数据: 先查询在修改select_update = session.query(User).filter_by(username="lyshark").first()select_update.password = "test1234"session.commit()# 修改数据: 直接修改session.query(User).filter_by(username="lyshark").update({User.password: 'abcd'})session.commit()session.query(User).filter_by(username="lyshark").update({"password": '123456'})session.commit()# 删除数据: 先查询在删除del_ptr = session.query(User).filter_by(username="lyshark").first()session.delete(del_ptr)session.commit()# 删除数据: 直接删除session.query(User).filter(User.username=="sqlalchemy").delete()session.commit()
数据库查询转字典
将从数据库中过滤查询指定的记录,并将该记录转换为字典或JSON格式,利于解析。
import sqlite3,time,datetime,json
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Float,DateTime# 建立基本映射类
Base = declarative_base()# 创建SQLITE数据库
engine = create_engine('sqlite:///:memory:', echo=False)# 创建映射类User
class User(Base):__tablename__ = 'UserDB'id = Column(Integer, primary_key=True, autoincrement=True, nullable=True, unique=True)username = Column(String(32), nullable=True, default="none")password = Column(String(32), nullable=True, default="none")age = Column(Integer,nullable=False, default=0)create_time = Column(DateTime, default=datetime.datetime.now)update_time = Column(DateTime, onupdate=datetime.datetime.now, default=datetime.datetime.now)user_value = Column(Float, default=0.0)# 查询结果转字典 (保留数据类型)def single_to_dict(self):return {c.name: getattr(self, c.name) for c in self.__table__.columns}# 查询结果转字典 (全转为字符串)def dobule_to_dict(self):result = {}for key in self.__mapper__.c.keys():if getattr(self, key) is not None:result[key] = str(getattr(self, key))else:result[key] = getattr(self, key)return result# 将查询结果转为JSON
def to_json(all_vendors):v = [ ven.dobule_to_dict() for ven in all_vendors ]return vif __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# 查询结果转为字典(保持数据库格式)key_value = session.query(User).first()data = key_value.single_to_dict()print("转为字典: {}".format(data))# 查询结果转为字典(字符串格式)key_value = session.query(User).first()data = key_value.dobule_to_dict()print("转为字符串字典: {}".format(data))# 查询结果转为JSON格式key_value = session.query(User)data = to_json(key_value)print("转为JSON格式: {}".format(data))
数据库类内函数调用
用户在使用ORM模型定义类时,可以同时在该映射类中定义各种针对类模型的处理函数,实现对数据的动态处理
from werkzeug.security import generate_password_hash,check_password_hash
import sqlite3,datetime,time
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Float, DateTime, Date, Time, Boolean, DECIMAL, Enum, Text# 创建SQLITE数据库
engine = create_engine("sqlite:///:memory:", encoding='utf-8')
Base = declarative_base() # 生成orm基类# 创建会话
Session_class = sessionmaker(bind=engine) # 创建与数据库的会话session
session = Session_class() # 生成session实例# 创建映射类User
class User(Base):__tablename__ = 'UserDB'id = Column(Integer, primary_key=True, autoincrement=True, nullable=True, unique=True)username = Column(String(64))_password_hash_ = Column(String(256)) # 加下划线作为私有函数,无法被外部访问email = Column(String(64))# 设置一个password字段用来设置密码@propertydef password(self):raise Exception("密码不能被读取")# 赋值password字段时,则自动加密存储@password.setterdef password(self, value):self._password_hash_ = generate_password_hash(value)# 使用 check_password,进行密码校验 返回True False。def check_password(self, pasword):return check_password_hash(self._password_hash_, pasword)# 设置输出函数def print_function(self):# 密码不可读调用 self.password 会报错# print("用户: {} 密码: {}".format(self.username,self.password))print("用户: {} email: {}".format(self.username, self.email))return Trueif __name__ == "__main__":print("当前表名: {}".format(User.__table__))# 创建数据表Base.metadata.create_all(engine, checkfirst=True)# 插入测试数据insert = User(username="lyshark",password="123123",email="lyshark@163.com")session.add(insert)insert = User(username="admin",password="556677",email="lyshark@163.com")session.add(insert)session.commit()# 查询测试tag = session.query(User).filter_by(username="lyshark").first()print("测试密码是否正确: {}".format(tag.check_password("123123")))# 调用函数验证当前用户tag = session.query(User).filter_by(username="admin").first()func = tag.print_function()print("输出测试: {}".format(func))
数据库聚合函数
通过func库调用数据库内的聚合函数,实现统计最大最小平均数等数据。
import sqlite3,datetime,time
from sqlalchemy import func
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Float, DateTime, Date, Time, Boolean, DECIMAL, Enum, Text# 建立基本映射类
Base = declarative_base()# 创建SQLITE数据库
engine = create_engine('sqlite:///:memory:', echo=False)# 创建映射类User
class User(Base):__tablename__ = 'UserDB'# 主键 primary_key | 自动增长 autoincrement | 不为空 nullable | 唯一性约束 uniqueid = Column(Integer, primary_key=True, autoincrement=True, nullable=True, unique=True)# 字符串类型username = Column(String(32), nullable=True, default="none")password = Column(String(32), nullable=True, default="none")# 姓名字段默认值是0age = Column(Integer,nullable=False, default=0)# 增加创建日期 [日期:时间]create_time = Column(DateTime, default=datetime.datetime.now)# onupdate=datetime.now 每次更新数据的时候都要更新该字段值update_time = Column(DateTime, onupdate=datetime.datetime.now, default=datetime.datetime.now)# 增加用户分数user_value = Column(Float, default=0.0)# 枚举类型定义# tag = Column(Enum("python",'flask','django'))# __repr__方法用于输出该类的对象被print()时输出的字符串,如果不想写可以不写def __repr__(self):return "<UserDB(username='%s',password='%s')>" % (self.username,self.password)if __name__ == "__main__":print("当前表名: {}".format(User.__table__))# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表Base.metadata.create_all(engine, checkfirst=True)# 统计总数count = session.query(func.count(User.id)).first()print("总记录: {}".format(count))# age 字段平均值age_avg = session.query(func.avg(User.age)).first()print("平均值: {}".format(age_avg))# age 字段最大值age_max = session.query(func.max(User.age)).first()print("最大值: {}".format(age_max))# age 最小值age_min = session.query(func.min(User.age)).one()print("最小值: {}".format(age_min))# age 求和 只求前三个的和age_sum = session.query(func.sum(User.age)).one()print("求总数: {}".format(age_sum))# 提交事务session.commit()
ORM定义一对多关系
SQLAlchemy提供了一个relationship,这个类可以定义属性,以后在访问相关联的表的时候就直接可以通过属性访问的方式就可以访问得到。
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer, String, Text, func, ForeignKey# 打开数据库
Base = declarative_base()
engine = create_engine('sqlite:///:memory:', echo=False)# 主表
class Author(Base):__tablename__ = 'author'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)# 定义外键关联到Book模型上面,主表是authorbooks = relationship('Book', backref='author')def __repr__(self):return '<Author:(id={}, name={})>'.format(self.id, self.name)# 从表
class Book(Base):__tablename__ = 'book'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(20), nullable=False)# 外键关联到主表author的id字段上author_id = Column(Integer, ForeignKey('author.id',ondelete="RESTRICT"))def __repr__(self):return '<Book:(id={}, name={}, author_id={})>'.format(self.id, self.name, self.author_id)if __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# ------------------------------------------------------# 创建数据并插入author1 = Author(id=1, name="张三")author2 = Author(id=2, name="李四")book1 = Book(name="<Python 开发>", author_id=1)book2 = Book(name="<C++ 开发教程>", author_id=1)book3 = Book(name="<C# 从入门到精通>", author_id=1)book4 = Book(name="<渗透测试指南>", author_id=2)book5 = Book(name="<nmap 扫描工具指南>", author_id=2)session.add_all([author1,book1,book2,book3])session.add_all([author2,book4,book5])session.commit()# ------------------------------------------------------# 关联插入模式author1 = Author(id=3, name="王五")book1 = Book(name="<Python 开发>", author_id=1)book2 = Book(name="<C++ 开发教程>", author_id=1)book3 = Book(name="<C# 从入门到精通>", author_id=1)author1.books.append(book1)author1.books.append(book2)author1.books.append(book3)session.add(author1)session.commit()# ------------------------------------------------------# 一对多查询测试book = session.query(Book).get(1)print("书籍作者: {}".format(book.author.name))author = session.query(Author).get(1)print("书籍数量: {}".format(len(author.books)))for book_name in author.books:print("书籍: {}".format(book_name.name))
ORM定义一对一关系
如果想要将两个模型映射成一对一的关系,那么应该在父模型中,指定引用的时候,要传递一个uselist=False参数进去。就是告诉父模型,以后引用这个从模型的时候,不再是一个列表了,而是一个对象了。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker,relationship,backref
from sqlalchemy import create_engine, Column, Integer, String, Text, func, ForeignKey# 打开数据库
Base = declarative_base()
engine = create_engine('sqlite:///:memory:', echo=False)# 主表
class User(Base):__tablename__ = 'user'id = Column(Integer, primary_key=True, autoincrement=True)username = Column(String(50), nullable=False)def __repr__(self):return 'User(username:%s)' % self.username# 从表
class UserExtend(Base):__tablename__ = 'user_extend'id = Column(Integer,primary_key=True,autoincrement=True)school = Column(String(50))age = Column(String(32))sex = Column(String(32))uid = Column(Integer,ForeignKey('user.id'))user = relationship('User',backref=backref('extend', uselist=False))#uselist=False 告诉父模型 以后引用时不再是列表 而是对象def __repr__(self):return 'extend(school:%s)'%self.schoolif __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# ------------------------------------------------------# 插入测试数据user = User(username="lyshark")extend = UserExtend(school="<家里蹲大学>", age="22", sex="M")extend.user = usersession.add(extend)session.commit()# ------------------------------------------------------# 一对一关系测试user_ptr = session.query(User).first()print("用户名: {} --> 学校: {}".format(user_ptr.username,user_ptr.extend.school))extend_ptr = session.query(UserExtend).first()print("用户名: {} --> 学校: {} --> 年龄: {} --> 性别: {}".format(extend_ptr.user.username,extend_ptr.school,extend_ptr.age,extend_ptr.sex))
ORM定义多对多关系
多对多与上面的一对多,一对一不同,创建多对对必须使用中间表Table来解决查询问题。
- 多对多的关系需要通过一张中间表来绑定他们之间的关系。
- 先把两个需要做多对多的模型定义出来
- 使用Table定义一个中间表,中间表一般就是包含两个模型的外键字段就可以了,并且让他们两个来作为一个“复合主键”。
- 在两个需要做多对多的模型中随便选择一个模型,定义一个relationship属性,来绑定三者之间的关系,在使用relationship的时候,需要传入一个secondary=中间表。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker,relationship,backref
from sqlalchemy import create_engine, Column, Integer, String, Text, func, ForeignKey, Table
from sqlalchemy import Column,INT,VARCHAR,ForeignKey
from sqlalchemy.orm import relationship# 打开数据库
Base = declarative_base()
engine = create_engine('sqlite:///:memory:', echo=False)# 女孩表
class Girls(Base):__tablename__ = "girl"id = Column(Integer,primary_key=True, autoincrement=True)name = Column(String(32))# 建立多对多关系g2b = relationship("Boys",backref="b2g",secondary="hotel")# 男孩表
class Boys(Base):__tablename__ = "boy"id = Column(Integer,primary_key=True, autoincrement=True)name = Column(String(32))# 映射关系表
class Table(Base):__tablename__ = "hotel"id = Column(Integer, primary_key=True, autoincrement=True)boy_id = Column(Integer,ForeignKey("boy.id"))girl_id = Column(Integer,ForeignKey("girl.id"))if __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# ------------------------------------------------------# 增加数据 - relationship 正向girl_obj = Girls(name="女孩主")girl_obj.g2b = [Boys(name="男孩从1"),Boys(name="男孩从2")]session.add(girl_obj)session.commit()# 增加数据 - relationship 反向boy_obj = Boys(name="男孩主")boy_obj.b2g = [Girls(name="女孩从1"),Girls(name="女孩从2")]session.add(boy_obj)session.commit()# ------------------------------------------------------# 正向查询girl_obj_list = session.query(Girls).all()for girl_obj in girl_obj_list:for boy in girl_obj.g2b:print(girl_obj.name,boy.name)# 反向查询boy_obj_list = session.query(Boys).all()for boy in boy_obj_list:for girl in boy.b2g:print(girl.name,boy.name)
连接查询与子查询
连接查询通过JOIN语句实现,子查询则通过subquery实现,首先需要创建一对多关系然后才可使用子查询。
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer, String, Text, func, ForeignKey# 打开数据库
Base = declarative_base()
engine = create_engine('sqlite:///:memory:', echo=False)# 主表
class Author(Base):__tablename__ = 'author'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(10), nullable=False)# 定义外键关联到Book模型上面,主表是authorbooks = relationship('Book', backref='author')def __repr__(self):return '<Author:(id={}, name={})>'.format(self.id, self.name)# 从表
class Book(Base):__tablename__ = 'book'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(20), nullable=False)# 外键关联到主表author的id字段上author_id = Column(Integer, ForeignKey('author.id',ondelete="RESTRICT"))def __repr__(self):return '<Book:(id={}, name={}, author_id={})>'.format(self.id, self.name, self.author_id)if __name__ == "__main__":# 创建会话Session = sessionmaker(bind=engine)session = Session()# 创建数据表(存在则跳过)Base.metadata.create_all(engine, checkfirst=True)# ------------------------------------------------------# 创建数据并插入author1 = Author(id=1, name="张三")author2 = Author(id=2, name="李四")book1 = Book(name="<Python 开发>", author_id=1)book2 = Book(name="<C++ 开发教程>", author_id=1)book3 = Book(name="<C# 从入门到精通>", author_id=1)book4 = Book(name="<渗透测试指南>", author_id=2)book5 = Book(name="<nmap 扫描工具指南>", author_id=2)session.add_all([author1,book1,book2,book3])session.add_all([author2,book4,book5])session.commit()# ------------------------------------------------------# 连表查询no_join_select = session.query(Author).filter(Author.id == Book.id).filter(Author.name == "王五").all()print("查询主键==从键 并且 Author.name == 王五的记录: {}".format(no_join_select))# JOIN 连接查询join = session.query(Author).join(Book).filter(Book.name=="<nmap 扫描工具指南>").first().nameprint("查询主表Author中的Book书名的作者是: {}".format(join))join = session.query(Book).join(Author).filter(Author.name=="李四").all()for book in join:print("查询从表Book中的Author作者有哪些书: {}".format(book.name))# subquery 子查询sbq = session.query(Book.author_id,func.count('*').label("book_count")).group_by(Book.author_id).subquery()print("查询出书籍编号计数(子语句): {}".format(sbq))sub_join = session.query(Author.name,sbq.c.book_count).outerjoin(sbq,Author.id == sbq.c.author_id).all()print("查询用户有几本书(主语句): {}".format(sub_join))
相关文章:

Python 使用SQLAlchemy数据库模块
SQLAlchemy 是用Python编程语言开发的一个开源项目,它提供了SQL工具包和ORM对象关系映射工具,使用MIT许可证发行,SQLAlchemy 提供高效和高性能的数据库访问,实现了完整的企业级持久模型。 ORM(对象关系映射࿰…...
)
【nlp】4.3 nlp中常用的预训练模型(BERT及其变体)
nlp中常用的预训练模型 1 当下NLP中流行的预训练模型1.1 BERT及其变体1.2 GPT1.3 GPT-2及其变体1.4 Transformer-XL1.5 XLNet及其变体1.6 XLM1.7 RoBERTa及其变体1.8 DistilBERT及其变体1.9 ALBERT1.10 T5及其变体1.11 XLM-RoBERTa及其变体2 预训练模型说明3 预训练模型的分类1…...
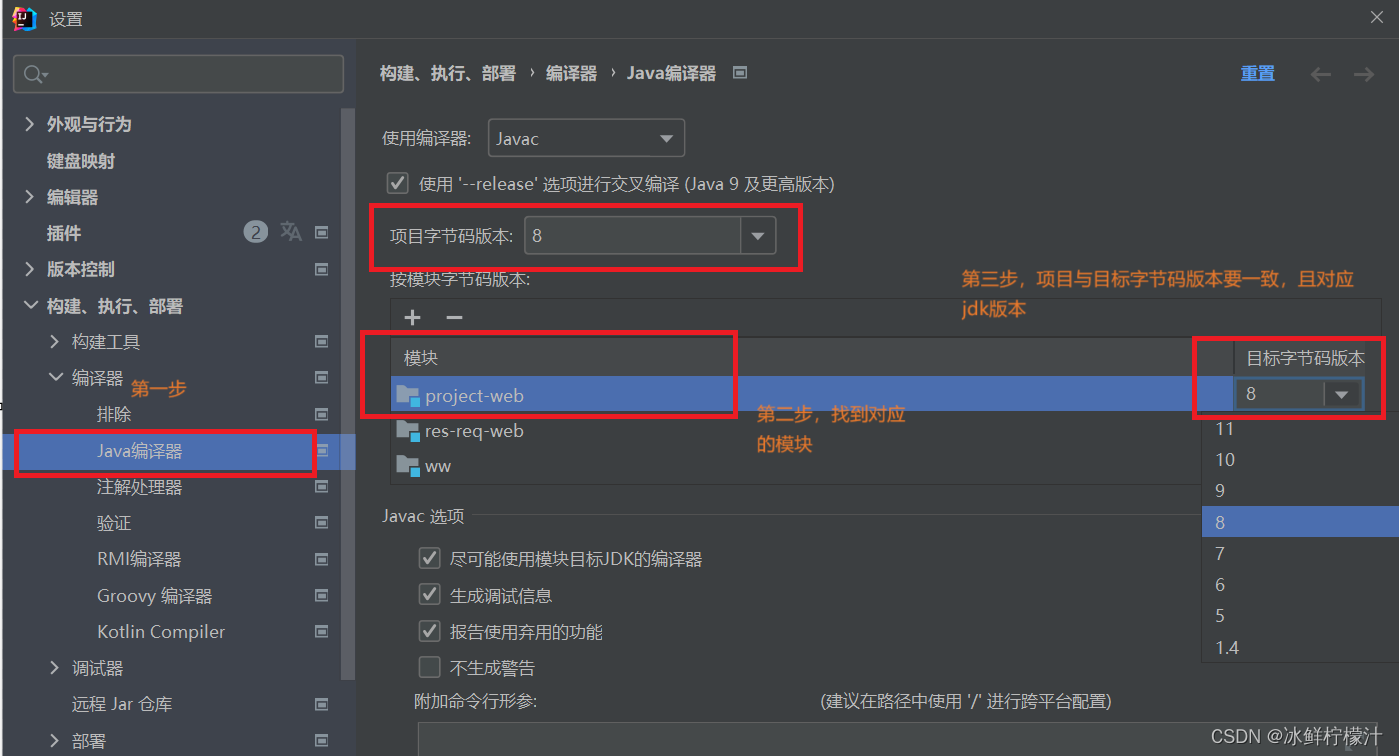
IDEA中 java: 警告: 源发行版 11 需要目标发行版 11 如何解决
步骤1找到项目结构,下面有两种方式 步骤2找到 模块中对应的项目,修改对应的源的语言级别和依赖的模块SDK(M) 步骤3,启动一下,看有无问题, 步骤4,去文件-->设置-->构建、执行、部署-->编译器-->…...

APP测试的测试内容有哪些,常见的Bug分类介绍!
对于产品的手机项目(应用软件),主要是进行系统测试。而针对手机应用软件APP的系统测试,我们通常从如下几个角度开展:功能模块测试、兼容性测试、安装和卸载测试、软件更新测试、性能测试、用户体验性测试、交叉事件测试…...
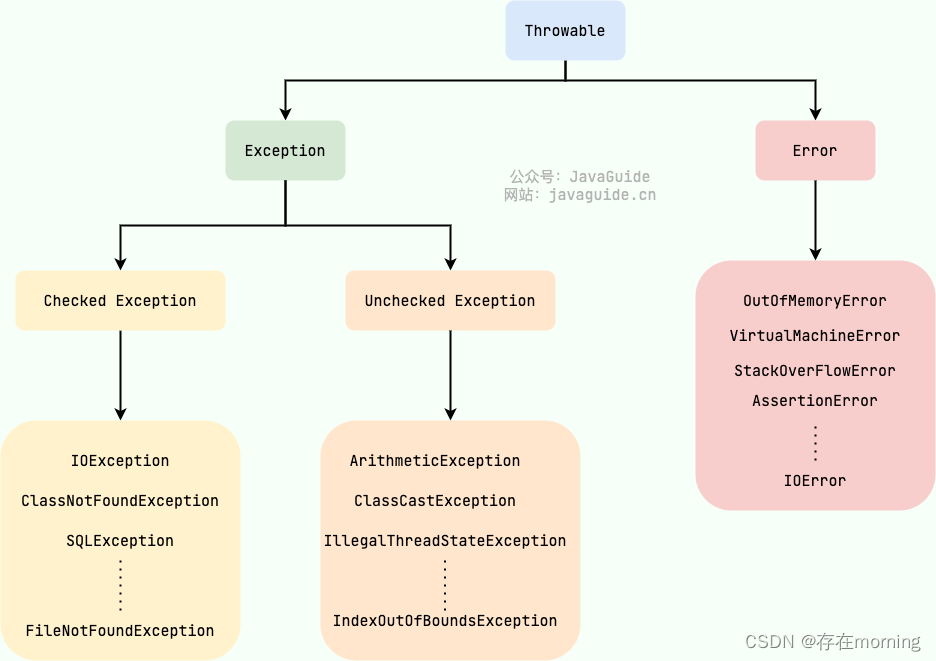
【Java程序员面试专栏 专业技能篇】Java SE核心面试指引(三):核心机制策略
关于Java SE部分的核心知识进行一网打尽,包括四部分:基础知识考察、面向对象思想、核心机制策略、Java新特性,通过一篇文章串联面试重点,并且帮助加强日常基础知识的理解,全局思维导图如下所示 本篇Blog为第三部分:核心机制策略,子节点表示追问或同级提问 异常处理 …...
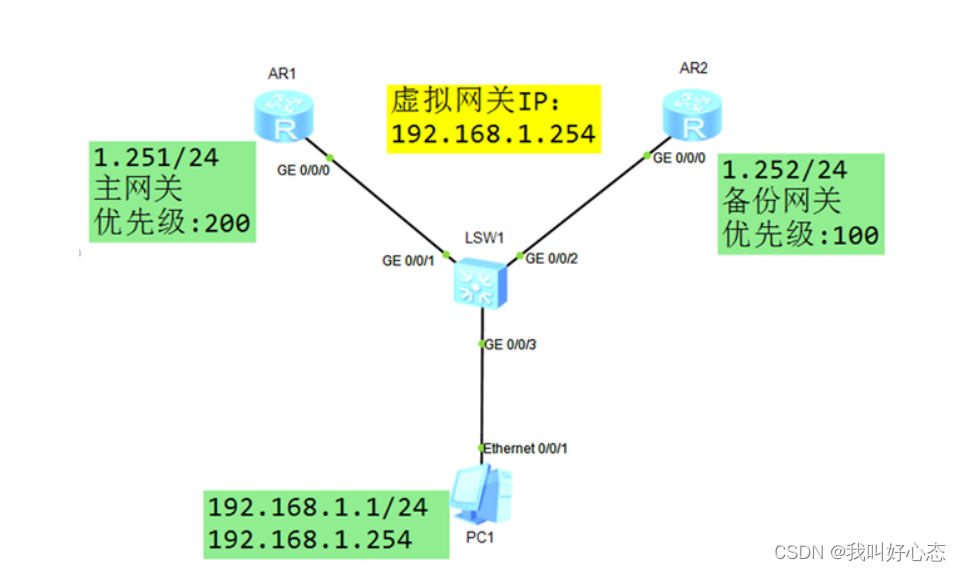
网络运维与网络安全 学习笔记2023.11.22
网络运维与网络安全 学习笔记 第二十三天 今日目标 VLAN间通信之交换机、VLAN间通信综合案例、浮动路由 VRRP原理与配置、VRRP链路跟踪、VRRP安全认证 VLAN间通信之交换机 单臂路由的缺陷 在内网的VLAN数量增多时,单臂链路容易成为网络瓶颈 三层交换机 具备…...

Android虚拟化
一、开源项目 开源的项目有一些,比如完全虚拟化的: twoyi 两仪由两部分组成:两仪 App,它实际上是一个 UI 渲染引擎,两仪内部运行的 ROM。 但是看telegram和github,这个app没有完整开源,并且最近…...

Nginx如何配置负载均衡
nginx的负载均衡有4种模式: 1)、轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。 2)、weight 指定轮询几率,weight和访问比率成正比,用于后端服务…...

Python虚拟环境
Python虚拟环境 介绍 虚拟环境(virtual environment),它是一个虚拟化,从电脑独立开辟出来的环境。通俗的来讲,虚拟环境就是借助虚拟机来把一部分内容独立出来,我们把这部分独立出来的东西称作“容器”&am…...
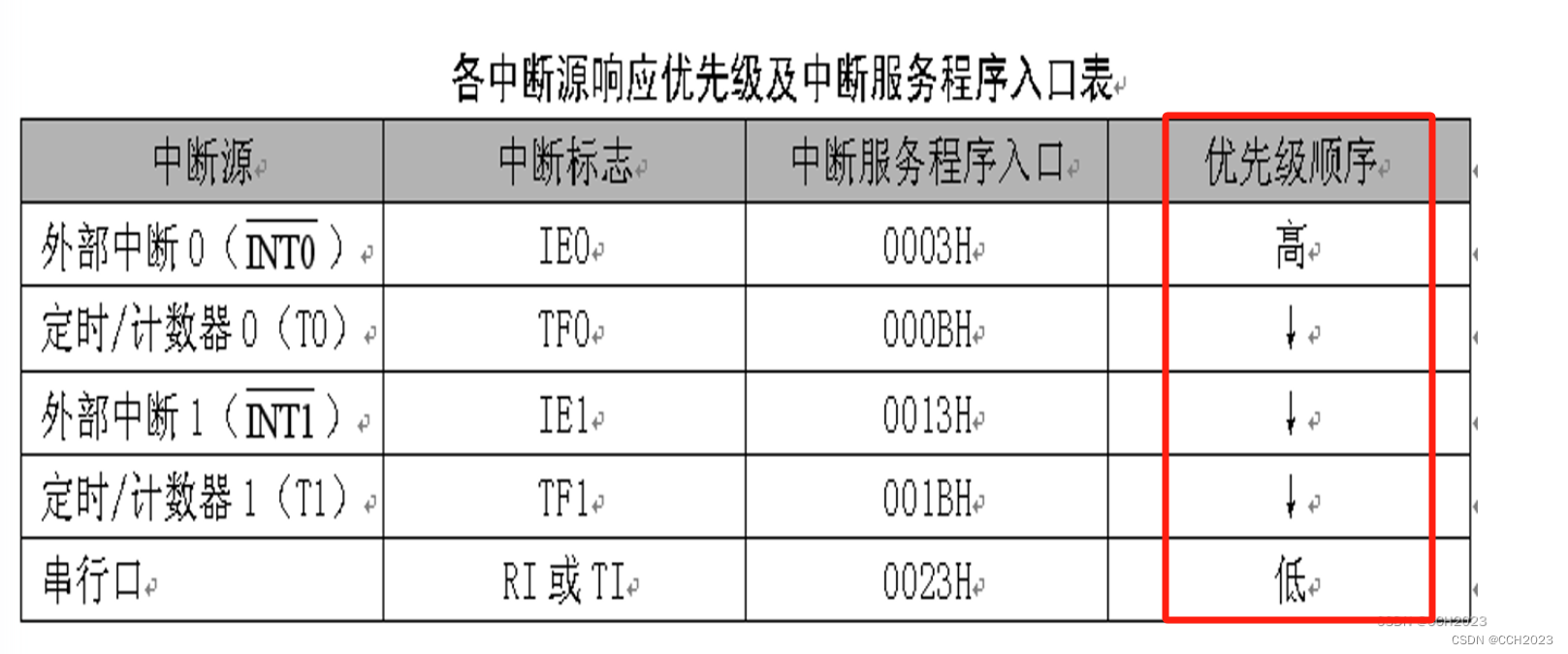
单片机学习4——中断的概念
中断的概念: CPU在处理A事件的时候,发生了B事件,请求CPU迅速去处理。(中断产生) CPU暂时中断当前的工作,转去处理B事件。(中断响应和中断服务) 待CPU将B事件处理完毕后࿰…...

Go语言网络爬虫工程经验分享:pholcus库演示抓取头条新闻的实例
网络爬虫是一种自动从互联网上获取数据的程序,它可以用于各种目的,如数据分析、信息检索、竞争情报等。网络爬虫的实现方式有很多,不同的编程语言和框架都有各自的优势和特点。在本文中,我将介绍一种使用Go语言和pholcus库的网络爬…...

Git安装
简单粗暴,跟着步骤一步一步来 右键就会有了...

以太网通讯协议小结--持续更新中
一、以太网介绍 以太网是一种产生较早,使用相当广泛的局域网技术,局域网就是一个区域的网络互联,可以使办公室也可以是学校等等,大小规模不一。 目前以太网根据速度等级分类大概分为:标准以太网(10Mbit/s…...

Excel换不了行怎么解决?
方法一: 使用Alt Enter键 在Excel中,输入文字时按下回车键,光标将会移到下一个单元格,如果想要换行,可以尝试使用Alt Enter键。具体操作如下: 1.在单元格中输入文字; 2.想要换行时,在需要换行的位置按下Alt Enter键; 3…...

Flink CDC -Sqlserver to Sqlserver java 模版编写
1.基本环境 <flink.version>1.17.0</flink.version> 2. 类文件 package com.flink.tablesql;import org.apache.commons.io.FileUtils; import org.apache.commons.lang3.StringUtils; import org.apache.flink.streaming.api.environment.StreamExecutionEnviro…...
4.前端--HTML标签-表格列表表单【2023.11.25】
1.表格 1.1表格的作用 表格的作用:表格主要用于显示、展示数据 1.2表格的基本格式 <table><tr><td>单元格内的文字</td><td>单元格内的文字</td>...</tr>... </table><table> </table> 是用于定义表…...
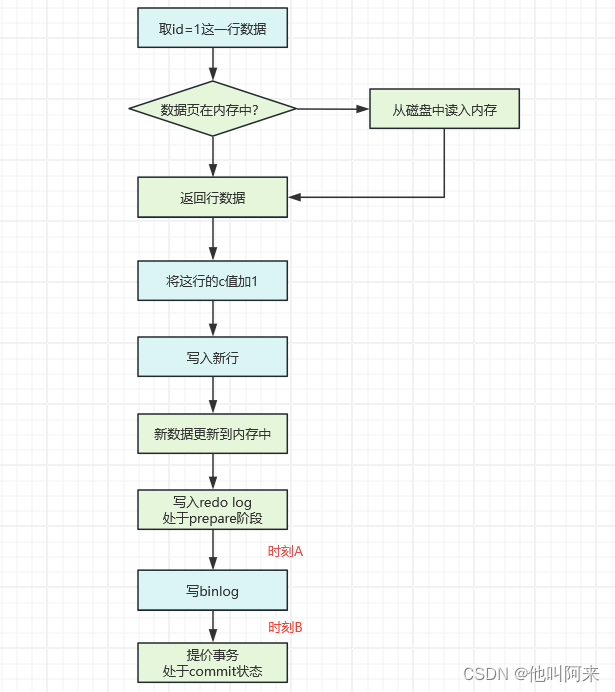
MySQL的Redo Log跟Binlog
文章目录 概要Redo Log日志Redo Log的作用Redo Log的写入机制 Binlog日志Binlog的作用Binlog写入机制 两段提交 概要 Redo Log和Binlog是MySQL日志系统中非常重要的两种机制,也有很多相似之处,本文主要介绍两者细节和区别。 Redo Log日志 Redo Log的作…...
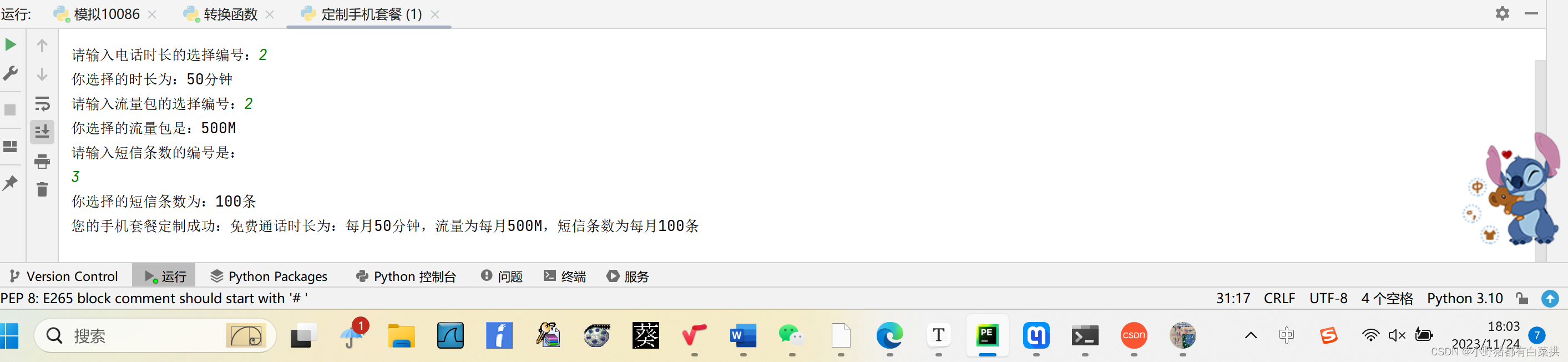
定制手机套餐---python序列
if __name__ __main__:print("定制手机套餐")print("")#定义电话时长:字典callTimeOptions{1:0分钟,2:50分钟,3:100分钟,4:300分钟,5:不限量}callTimeInputinput("请输入电话时长的选择编号:")callTimeResultcallTimeOpt…...
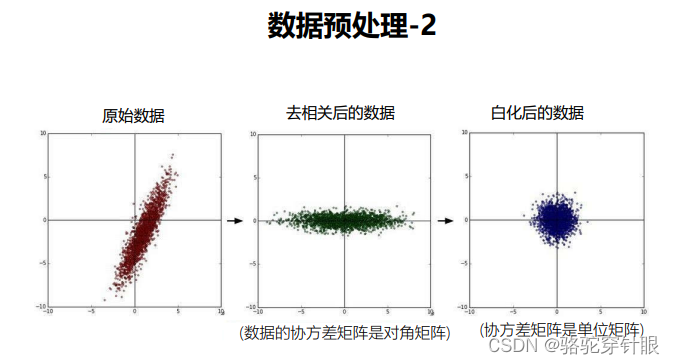
线性分类器--数据处理
数据集划分 通常按照 70%,20% ,10% 来分数据集 数据处理 斯坦福的线性分类器体验 http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/...

一些可能被忽视的 Vue3 API 附带案例
Vue3 是 Vue.js 的最新版本,它引入了许多新的 API 和改进。以下是一些可能被忽视的 Vue3 API: reactive:这是 Vue3 中用于创建响应式对象的函数。与 Vue2 中的 data 不同,reactive 返回的对象是响应式的,这意味着当对…...

seedlabs缓冲区溢出实验报告
分享学习经验,存在问题希望大佬答疑指正 如果图片看不了可以点这个链接看链接中的版本https://share.note.sx/zfs2vh0i#8oq951VpgKoRLwOys2sgP/5PKZY2YXjrvZ/2FYCzF8 1.概述 缓冲区溢出漏洞原理: 程序向固定大小的缓冲区中写入超过其容量的数据,导致相…...

终极指南:如何为Conform.nvim贡献代码并成为开源英雄
终极指南:如何为Conform.nvim贡献代码并成为开源英雄 【免费下载链接】conform.nvim Lightweight yet powerful formatter plugin for Neovim 项目地址: https://gitcode.com/gh_mirrors/co/conform.nvim Conform.nvim是一款轻量级但功能强大的Neovim格式化插…...
系统调用详解)
Linux文件偏移量与lseek()系统调用详解
1. 文件读写位置基础概念在Linux系统中,每次打开一个文件时,内核都会维护一个称为"文件偏移量"的指针。这个指针决定了下一个read()或write()操作将从文件的哪个位置开始执行。理解这个机制对于进行精确的文件操作至关重要。文件偏移量从0开始…...

RAGFlow Agent 搞定火电复杂图表
在当前的 LLM 应用层,有一个共识正在逐渐变得 painful:通用大模型在处理垂直领域的“存量知识”时,几乎是无能的。 这种无能尤其体现在工业领域。当我们把目光从“写周报、画海报”的互联网场景移开,投向真正硬核的“火电行业”时…...

OpenClaw跨平台控制方案:千问3.5-9B同步操作多台设备
OpenClaw跨平台控制方案:千问3.5-9B同步操作多台设备 1. 为什么需要跨设备自动化 去年团队扩容后,我遇到了一个典型的技术债问题:每次新同事入职,都需要手动配置5台不同操作系统的开发机(Ubuntu/macOS/Windows&#…...

C++的std--ranges等价
C的std::ranges等价:现代算法的新范式 C20引入的std::ranges库彻底改变了传统算法的编写方式,其中“等价”(equivalence)概念是理解范围操作的核心之一。与传统的“相等”(equality)不同,等价关…...
环境标准化指南,建议收藏)
告别环境冲突|Anaconda实战:AI开发全流程(数据→训练→部署)环境标准化指南,建议收藏
摘要:告别环境冲突、依赖地狱、复现失败!本文以 Anaconda 为核心,打造一套可复制、可迁移、可团队协作的 AI 全流程标准化方案,覆盖环境初始化→数据预处理→模型训练→打包部署,一套流程通吃个人实验与工程落地。前言…...

2025 ICPC武汉邀请赛 G [根号分治 容斥原理+DP]
Problem - G - Codeforces 观察题目,我们可以用贡献法, 计算每个格子的贡献,然后累加起来,对于重复的部分我们要减去 1.路径数量 首先,计算两个位置间有多少种路径互通,我们可以利用组合数进行计算&#x…...

DSP28377控制下三相并网系统的双二阶锁相环DSOGI-PLL程序优化及应用
基于DSP28377的三相并网双二阶锁相环DSOGI-PLL程序。系统概述 本文分析的代码实现了一个基于TI DSP28377D处理器的三相并网逆变器控制系统。该系统采用先进的双向功率控制架构,集成了三相锁相环(DSOGI-PLL)、空间矢量脉宽调制(SVPWM)和多种保护机制,适用…...

植物大战僵尸革新辅助工具:PVZ Toolkit全方位功能解析与使用指南
植物大战僵尸革新辅助工具:PVZ Toolkit全方位功能解析与使用指南 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 植物大战僵尸作为经典塔防游戏,多年来一直拥有庞大的玩家群…...