MySQL的Redo Log跟Binlog
文章目录
- 概要
- Redo Log日志
- Redo Log的作用
- Redo Log的写入机制
- Binlog日志
- Binlog的作用
- Binlog写入机制
- 两段提交
概要
Redo Log和Binlog是MySQL日志系统中非常重要的两种机制,也有很多相似之处,本文主要介绍两者细节和区别。
Redo Log日志
Redo Log的作用
准备一张测试表
create table test_redo(id int primary key, c int);
假设现在要执行这样一条sql
update test_redo set c = c + 1 where id = 1;
修改一条数据,首先是修改了Buffer Pool中该条数据所在的数据页。假如说我们刚提交了事务,发生了某个故障,内存中的数据都失效了,就会导致所做的修改跟着丢失了。这是不能接受的。
如何避免这样的情况发生?
一个简单粗暴的做法是:在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘
这样做有以下两个问题:
- 刷新一个完整的数据也太浪费
比如上面只修改了一个字段,就要刷新整个页(16KB),InnoDB是以页为单位进行IO的,很浪费 - 随机IO速度很慢
涉及到多个页时,页与页之间在磁盘上可能是不连续的,随机IO要比顺序IO慢很多。
为了达到系统崩溃后,服务重启也能恢复原来提交的事务修改的目的,同时避免出现上面提到的问题,Redo Log就是一种解决方案。
Redo Log,重做日志,其本质是记录⼀下事务对数据库做了哪些修改:
将第0号表空间的100号页面的偏移量为1处的值更新为2
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 Redo Log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面。
这就是 MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘。
通过事务执行过程中产生的redo日志刷新到磁盘的方式,跟前面提到的简单粗暴的方式比较,有如下好处:
- redo日志占用的空间非常少
- redo日志是顺序写入磁盘的
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
Redo Log的写入机制
日志文件
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示
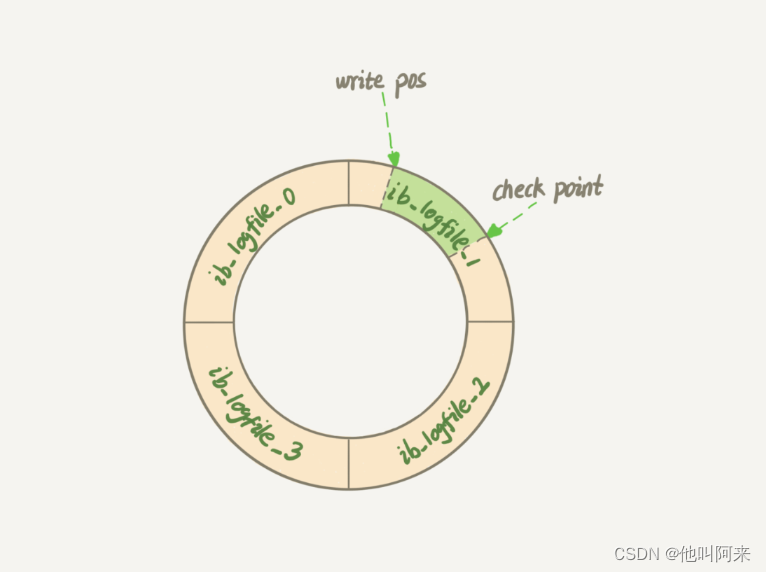
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示写满,这时候不能再执行新的更新,把 checkpoint 推进一下。
可通过以下查询redo log文件的数量跟大小
show variables like '%innodb_log_file%';
在服务器端可看到对应的文件

redo log buffer
假如执行如下sql
begin;
insert into t1 ...
insert into t2 ...
commit;
这个事务要往两个表中插入记录,插入数据的过程中,还没有执行 commit 的时候,不能直接写到 redo log 文件里的。这时候会先记录在redo log buffer
redo log buffer 就是一块内存,用来先存 redo 日志。也就是说,在执行第一个 insert 的时候,数据的确发生了修改,redo log buffer 也写入了日志。但是,真正把日志写到 redo log 文件(文件名是 ib_logfile+ 数字),是在执行 commit 语句的时候做的。
单独执行一个更新语句的时候,InnoDB 会自己启动一个事务,在语句执行完成的时候提交。过程跟上面是一样的。
redo log buffer是什么时候持久化到Redo Log中的呢?有如下3种策略,可通过innodb_flush_log_at_trx_commit进行配置。它有3种取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,由后台线程每隔1s执行一次刷盘操作 ;
- 设置为 1 的时候(默认值),表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 OS cache,然后由后台Master线程再每隔1秒执行OS
cache -> flush cache to disk 的操作。
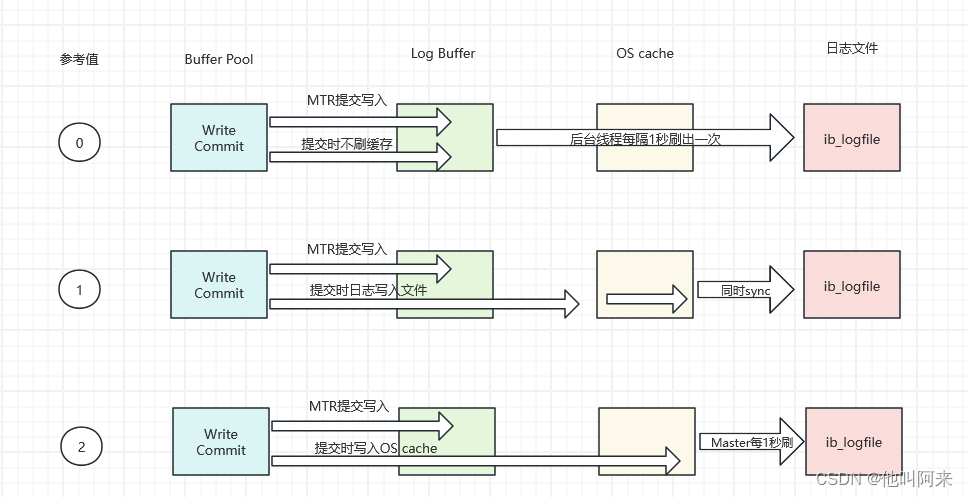
一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数据。设置为1时最为安全,但是性能也是最差。
Binlog日志
Binlog的作用
Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server层也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。
最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
Binlog日志有以下两个最重要的应用场景:
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过mysqlbinlog工具来恢复数据
Binlog日志文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
-
ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。 -
STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
优点:日志量小,减少磁盘IO,提升存储和恢复速度
缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。 -
MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
可通过以下sql查看Binlog信息
show variables like '%log_bin%';
show variables like '%binlog%';
格式查看
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.00 sec)Biglog文件格式
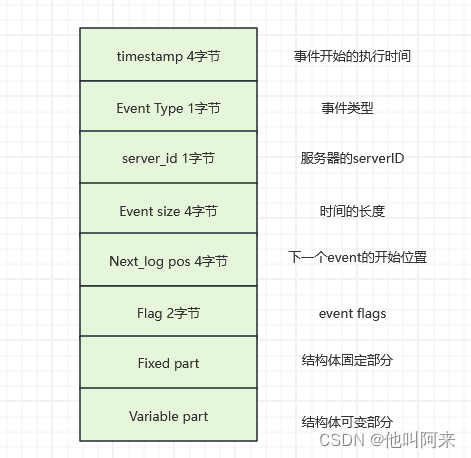
MySQL的binlog文件中记录的是对数据库的各种修改操作,用来表示修改操作的数据结构是Log event。不同的修改操作对应的不同的log event。比较常用的log event有:Query event、Row event、Xid event等。binlog文件的内容就是各种Log event的集合。
Binlog文件中Log event结构如下图所示:
查看当前的二进制日志文件列表及大小。指令如下:
mysql> SHOW BINARY LOGS;
+---------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+---------------+-----------+-----------+
| binlog.000004 | 712684 | No |
| binlog.000005 | 179 | No |
| binlog.000006 | 179 | No |
| binlog.000007 | 3412930 | No |
+---------------+-----------+-----------+
4 rows in set (0.00 sec)查看具体的文件
语法:show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
-- 文件内容太多了 这里限制了从 pos 156开始查看 限制5条
mysql> show binlog events in 'binlog.000004' from 156 limit 5 \G;
*************************** 1. row ***************************Log_name: binlog.000004Pos: 156Event_type: Anonymous_GtidServer_id: 1
End_log_pos: 235Info: SET @@SESSION.GTID_NEXT= 'ANONYMOUS'
*************************** 2. row ***************************Log_name: binlog.000004Pos: 235Event_type: QueryServer_id: 1
End_log_pos: 317Info: BEGIN
*************************** 3. row ***************************Log_name: binlog.000004Pos: 317Event_type: Table_mapServer_id: 1
End_log_pos: 402Info: table_id: 92 (small_admin.QRTZ_CRON_TRIGGERS)
*************************** 4. row ***************************Log_name: binlog.000004Pos: 402Event_type: Delete_rowsServer_id: 1
End_log_pos: 502Info: table_id: 92 flags: STMT_END_F
*************************** 5. row ***************************Log_name: binlog.000004Pos: 502Event_type: XidServer_id: 1
End_log_pos: 533Info: COMMIT /* xid=392 */
5 rows in set (0.00 sec)
binlog是二进制文件,无法直接查看,借助mysqlbinlog命令工具了,可以查看其中的内容
# mysqlbinlog使用语法
[root@node1 data]# mysqlbinlog --no-defaults --help
查看文件
mysqlbinlog --no-defaults --base64-output=decode-rows -vv binlog.000004 |tail -100
Binlog写入机制
事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。这就涉及到了 binlog cache 的保存问题。
系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。
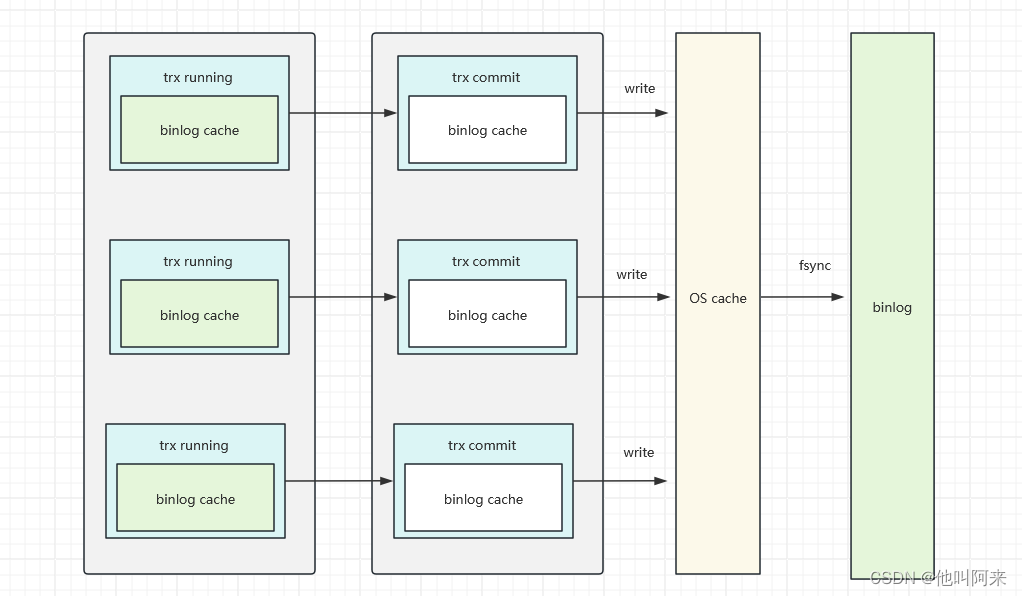
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。
但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
两段提交
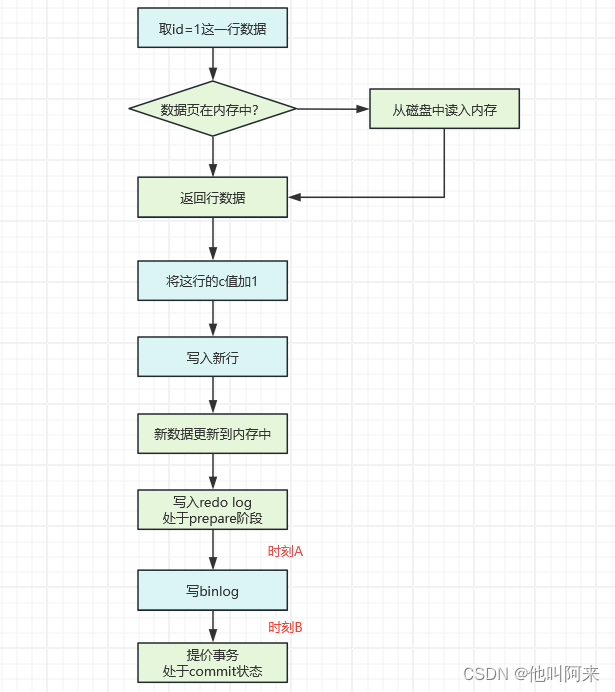
结合redo log 跟bin log ,执行update test_redo set c = c + 1 where id = 1 这条语句的大致过程如下:
- 执行器先找引擎取 id=1 这一行。id 是主键,引擎直接用树搜索找到这一行。如果 id=1 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把c的值加 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
Q:为什么需要两段提交?
A:用上面的更新语句作为例子
如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者是先写binlog再写redo log,下面对这两种情况讨论
- 先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完时MySQL 进程异常重启。由于redo log 写完后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。 但是由于 binlog 没写完, binlog 里面就没有记录这条语句。因此,之后备份日志的时候用这个 binlog 来恢复临时库的话,就会与原库的值有差异。
- 先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。在之后用 binlog 来恢复的时候就会与原库有差异。
Q:上图中,如果在时刻A,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了奔溃呢?
A:由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库
Q:如果在B时刻,也就是 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理?
A:崩溃恢复时的判断如下
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整: a. 如果是,则提交事务; b. 否则,回滚事务。
Q:redo log 和 binlog 是怎么关联起来的?
A:它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
相关文章:
MySQL的Redo Log跟Binlog
文章目录 概要Redo Log日志Redo Log的作用Redo Log的写入机制 Binlog日志Binlog的作用Binlog写入机制 两段提交 概要 Redo Log和Binlog是MySQL日志系统中非常重要的两种机制,也有很多相似之处,本文主要介绍两者细节和区别。 Redo Log日志 Redo Log的作…...
定制手机套餐---python序列
if __name__ __main__:print("定制手机套餐")print("")#定义电话时长:字典callTimeOptions{1:0分钟,2:50分钟,3:100分钟,4:300分钟,5:不限量}callTimeInputinput("请输入电话时长的选择编号:")callTimeResultcallTimeOpt…...
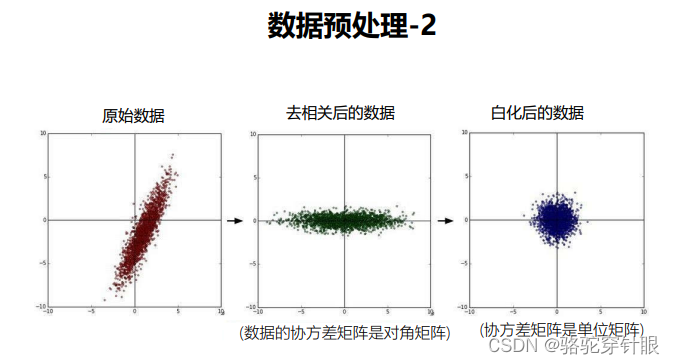
线性分类器--数据处理
数据集划分 通常按照 70%,20% ,10% 来分数据集 数据处理 斯坦福的线性分类器体验 http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/...

一些可能被忽视的 Vue3 API 附带案例
Vue3 是 Vue.js 的最新版本,它引入了许多新的 API 和改进。以下是一些可能被忽视的 Vue3 API: reactive:这是 Vue3 中用于创建响应式对象的函数。与 Vue2 中的 data 不同,reactive 返回的对象是响应式的,这意味着当对…...
Linux git
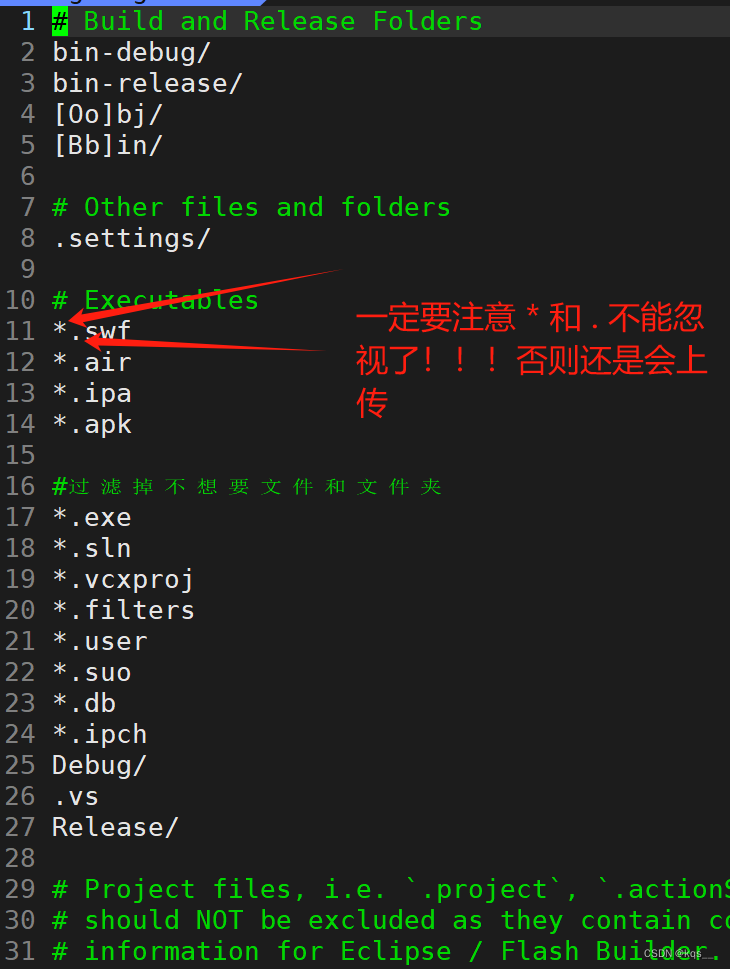
1.Git 初识 不知道你⼯作或学习时,有没有遇到这样的情况:我们在编写各种⽂档时,为了防止文档丢失,更改失误,失误后能恢复到原来的版本,不得不复制出⼀个副本,⽐如: “报告-v1”? …...
136. 只出现一次的数字
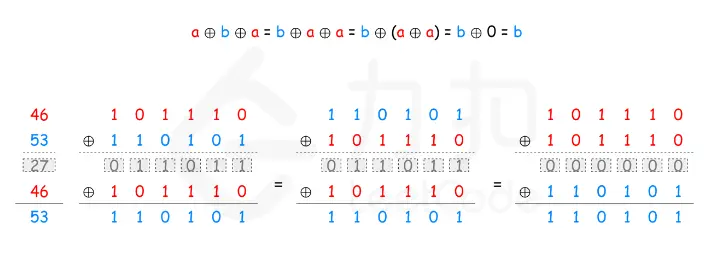
136. 只出现一次的数字 题目: 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空…...
redis的性能管理及集群架构(主从复制、哨兵模式)
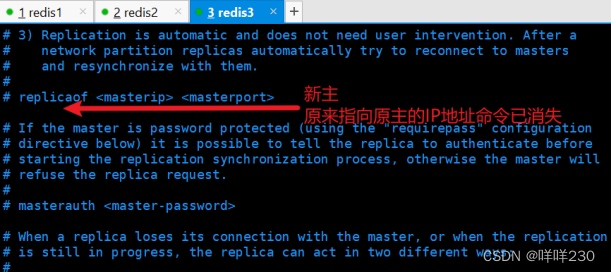
一、redis的性能管理 1、内存指标info memory 内存指标(重要) used_memory:853736 数据占用的内存 used_memory_rss:10551296 redis向操作系统申请的内存 used_memory_peak:853736 redis使用内存的峰值 注:单位:字节 系…...
,反向最大匹配算法(BMM)和双向最大匹配算法(BM)原理及实现)
【自然语言处理】正向最大匹配算法(FMM),反向最大匹配算法(BMM)和双向最大匹配算法(BM)原理及实现
目录 一,正向最大匹配算法(FMM) 二,反向最大匹配算法(RMM) 一,正向最大匹配算法(FMM) 正向最大匹配分词(Forward maximum matching segmentation)通常简称为…...
数据结构 | 堆排序
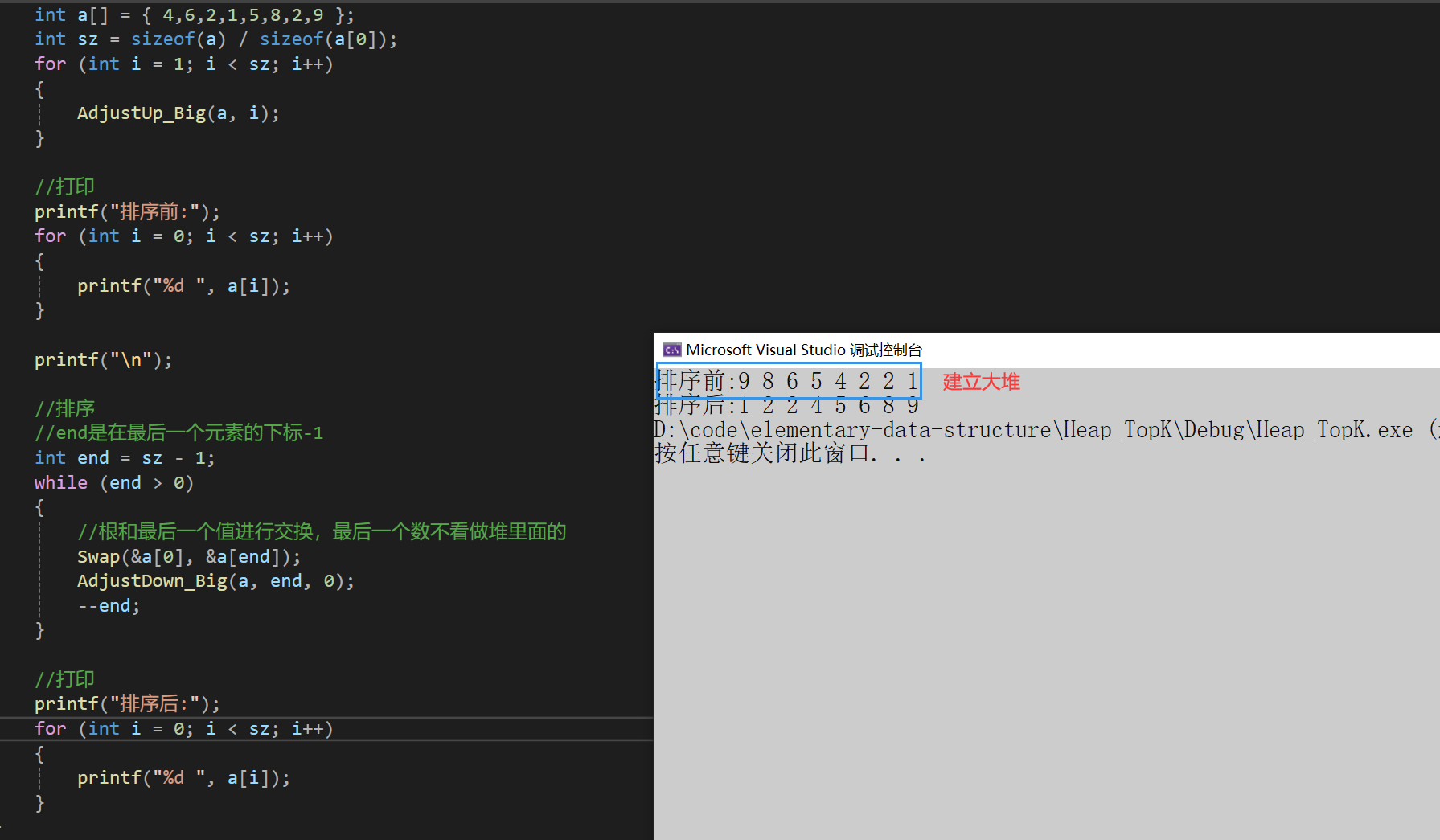
数据结构 | 堆排序 文章目录 数据结构 | 堆排序建立大堆排序结果以及全部代码 如果没有看过堆的实现的话可以先看前面的一章堆的实现,然后再来看这个堆排序,都是比较简单的~~ 这里堆排序首先建堆,建堆是要建小堆还是大堆呢? 在堆排…...

编程语言发展史:Go语言的设计和特点
一、前言 Go语言是一种由Google开发的编程语言,于2007年开始设计,2009年首次发布。Go语言是一种面向对象、静态类型、编译型的语言,具有高效、简单、安全等特点,可用于开发各种类型的应用程序。Go语言的设计和特点使其成为越来越…...

FinGPT:金融垂类大模型架构
Overview 动机 架构 底座模型: Llama2Chatglm2 Lora训练 技术路径 自动收集数据并整理 指令微调 舆情分析 搜新闻然后相似搜索 检索增强架构 智能投顾 Hugging face 地址 学术成果及未来方向 参考资料...
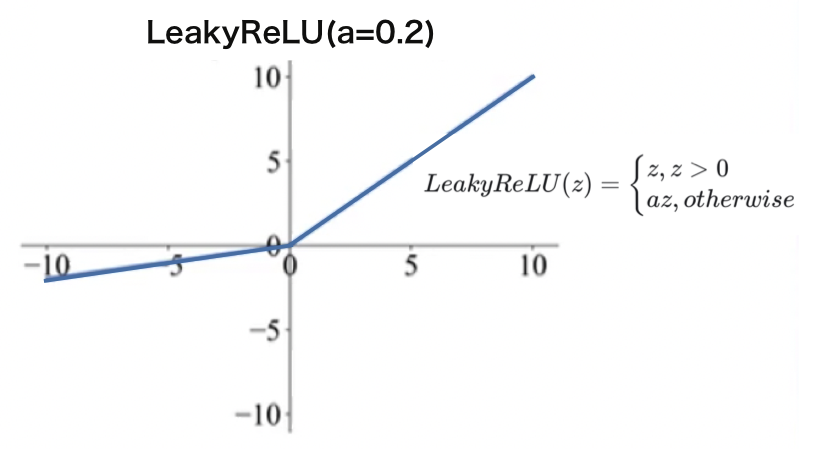
24. 深度学习进阶 - 矩阵运算的维度和激活函数
Hi,你好。我是茶桁。 咱们经过前一轮的学习,已经完成了一个小型的神经网络框架。但是这也只是个开始而已,在之后的课程中,针对深度学习我们需要进阶学习。 我们要学到超参数,优化器,卷积神经网络等等。看…...
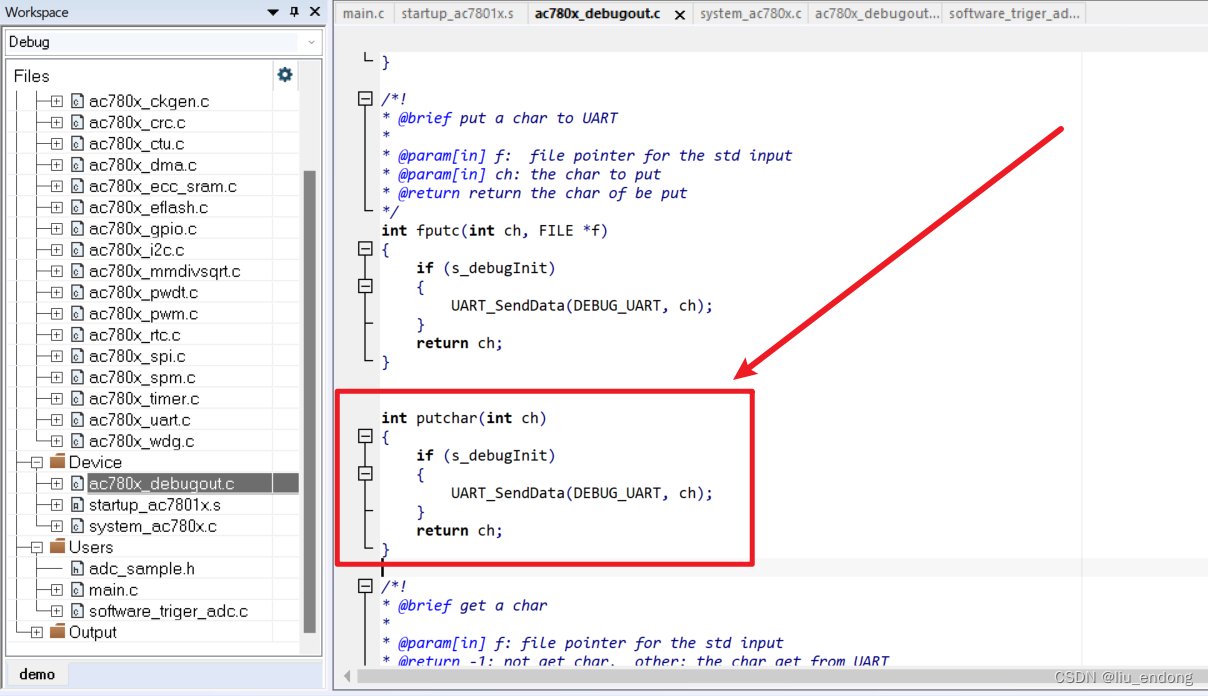
杰发科技AC7801——keil工程移植到IAR
0、简介 发现AC7801的代码只有keil工程的,IAR和Eclipse的代码只有一个例程,于是在从Keil移植到IAR时候遇到的问题记录下。 正常情况下,直接把keil的usr用户代码移植到iar的文件夹下面,删除原本的文件再添加新加进来的文件即可。…...
Word怎么看字数?简单教程分享!
“我在写文章时,总是想看看写了多少字。但是我发现我的Word无法看到字数。在Word中应该怎么查看字数呢?请帮帮我!” Word是一个广泛使用的文档编辑工具。在我们编辑文章时,如果想查看写了多少字,也是可以轻松完成的。 …...
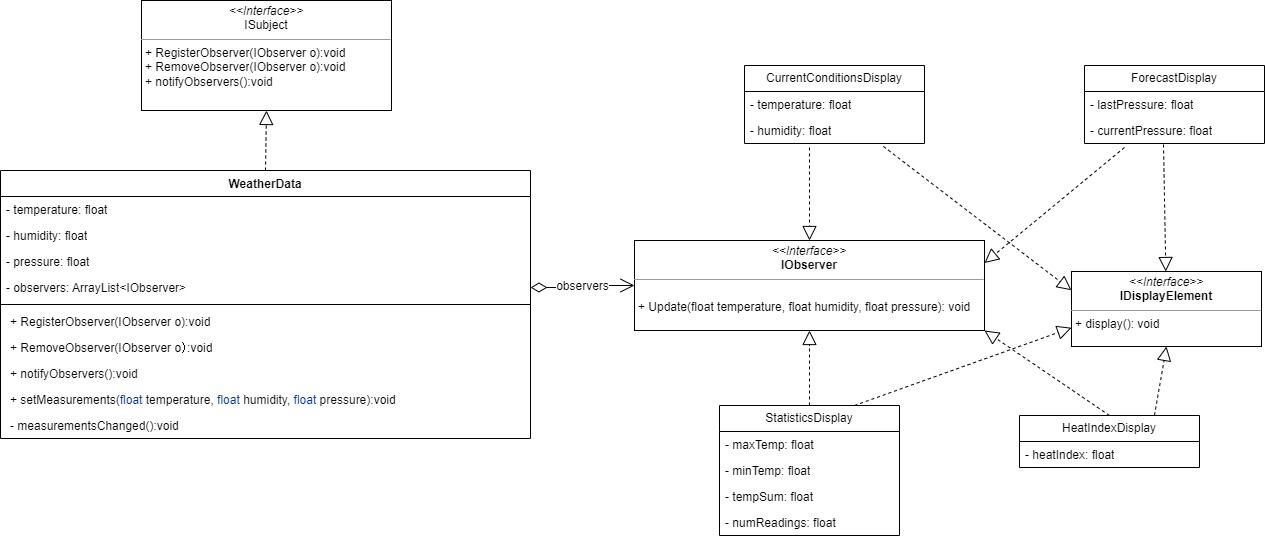
万字解析设计模式之观察者模式、中介者模式、访问者模式
一、观察者模式 1.1概述 观察者模式是一种行为型设计模式,它允许一个对象(称为主题或可观察者)在其状态发生改变时,通知它的所有依赖对象(称为观察者)并自动更新它们。这种模式提供了一种松耦合的方式&…...
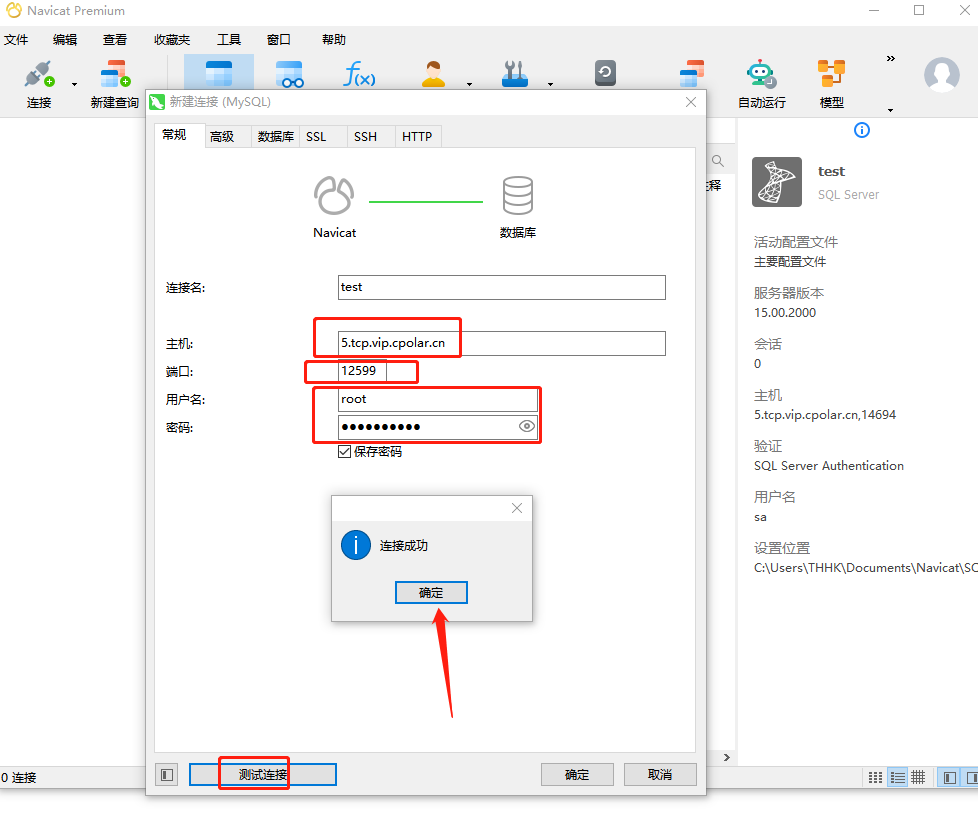
【MySQL | TCP】宝塔面板结合内网穿透实现公网远程访问
文章目录 前言1.Mysql服务安装2.创建数据库3.安装cpolar3.2 创建HTTP隧道4.远程连接5.固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 宝塔面板的简易操作性,使得运维难度降低,简化了Linux命令行进行繁琐的配置&#x…...

Python break用法详解
Python 语言没有提供 goto 语句来控制程序的跳转,这种做法虽然提高了程序流程控制的可读性,但降低了灵活性。为了弥补这种不足,Python 提供了 continue 和 break 来控制循环结构。本节先讲解 break 的用法。 某些时候,需要在某种…...
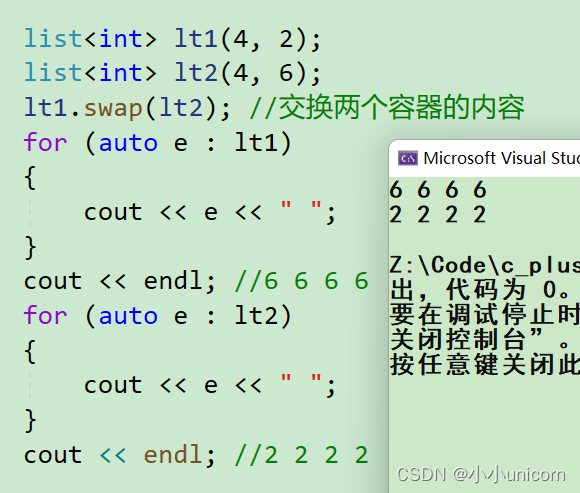
【C++初阶】STL详解(五)List的介绍与使用
本专栏内容为:C学习专栏,分为初阶和进阶两部分。 通过本专栏的深入学习,你可以了解并掌握C。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C 🚚代码仓库:小小unicorn的代码仓库&…...

MySQL特点和基本语句
MySQL MySQL是一种流行的关系型数据库管理系统,由瑞典MySQL AB公司开发,现属于甲骨文公司(Oracle)旗下产品。MySQL是基于C语言开发的,它具有高性能、可扩展性、易用性等特点,并且支持大量的用户访问。 My…...

Gin 学习笔记03-参数绑定
参数绑定 1、ShouldBindJSON2、ShouldBindQuery3、ShouldBindUri4、ShouldBind 1、ShouldBindJSON package mainimport ("github.com/gin-gonic/gin""net/http" )type User struct {Name string json:"name"Gender string json:"gender&…...

SecGPT-14B模型微调:OpenClaw自动化准备标注数据与训练脚本
SecGPT-14B模型微调:OpenClaw自动化准备标注数据与训练脚本 1. 为什么需要自动化微调流程 当我第一次尝试微调SecGPT-14B模型时,最让我头疼的不是模型本身,而是那些繁琐的前期准备工作。作为安全领域的从业者,我深知专业数据的价…...
)
Spring IOC 注解进阶:@Bean 管理第三方 Bean,@Import 拆分配置,@Value 注入资源(Spring系列5)
在日常Spring开发中,我们习惯用Component、Service、Repository这类注解标记自己编写的业务类,让Spring自动扫描并纳入IOC容器管理。但如果是第三方Jar包中的类(比如Druid数据源、第三方工具类),我们无法修改源码添加注…...

费马小定理,快速幂
今天显示延续了昨天的背包问题,先是写了一题背包问题,后面就写费马定理加快速幂。费马小定理证明如果一个数p是质数,并且a不是p的倍数,那么一定有a^(p-1)1(mod p);那么自然有a^(p-2)a^-1(mod p)…...

用Python可视化回溯算法:一步步动画演示八皇后问题的92种解法
用Python动画拆解八皇后问题:可视化回溯算法的92种解法 国际象棋盘上的八个皇后如何互不攻击?这个1848年提出的经典问题,曾让数学家高斯误算为76种解法。如今借助Python的可视化能力,我们可以将回溯算法的"试错-回退-重试&qu…...

模拟函数memmove
#include <stdio.h>//怎么实现是从前往后拷贝,还是从后往前拷贝 #include <assert.h>//拷贝函数,核心是可以处理内存重叠的情况 //定义 void *my_memmove(void *dest,const void *source,size_t n) {//准备工作 // assert(dest ! NULL); // …...

Vue.js核心原理之VNode如何映射真实DOM元素流程全解
VNode是Vue中描述DOM结构的轻量、可比较、不可变的JavaScript对象,包含tag、data、children等字段,不直接操作DOM,其真实DOM绑定和更新由patch过程完成。Vue.js 中的 VNode(虚拟节点)是实现响应式更新和高效 DOM 操作的…...
)
2026年4月,天府新区,成都装修公司哪家好,北京我爱我家装饰(成都旗舰店)
引言在快速发展的天府新区,装修选择成为了许多家庭和业主的首要问题。无论是新房装修、老房翻新还是局部改造,如何选择一家既专业又可靠的装修公司,确保从设计到施工的每个环节都令人满意,是大家最为关心的问题。本文将通过实际案…...

Stepper595:基于74HC595的轻量步进电机驱动库
1. Stepper595库概述:基于74HC595的轻量级步进电机驱动方案Stepper595是一个面向资源受限嵌入式平台的精简型步进电机控制库,其核心设计哲学是“用最少的硬件引脚、最简的时序逻辑、最低的代码开销实现可靠双电机协同控制”。该库不依赖传统GPIO逐位模拟…...

GraphViz+CANdelaStudio实战:如何可视化你的State Diagram状态转换图
GraphVizCANdelaStudio实战:如何可视化你的State Diagram状态转换图 在汽车电子开发领域,状态机的设计和验证是核心工作之一。当你在CANdelaStudio中精心设计了复杂的状态转换逻辑后,如何让这些抽象的状态关系变得直观可理解?这就…...
)
【数据结构与算法】第30篇:哈希表(Hash Table)
一、什么是哈希表1.1 基本思想哈希表通过哈希函数将关键字映射到数组的某个位置,实现快速访问。textkey → 哈希函数 → 数组下标 → 访问/存储示例:hash(key) key % 10key25 → 25%105 → 存入下标5key37 → 37%107 → 存入下标71.2 哈希冲突不同的key…...