【深度学习】如何找到最优学习率
经过了大量炼丹的同学都知道,超参数是一个非常玄乎的东西,比如batch size,学习率等,这些东西的设定并没有什么规律和原因,论文中设定的超参数一般都是靠经验决定的。但是超参数往往又特别重要,比如学习率,如果设置了一个太大的学习率,那么loss就爆了,设置的学习率太小,需要等待的时间就特别长,那么我们是否有一个科学的办法来决定我们的初始学习率呢?
在这篇文章中,我会讲一种非常简单却有效的方法来确定合理的初始学习率。
学习率的重要性
目前深度学习使用的都是非常简单的一阶收敛算法,梯度下降法,不管有多少自适应的优化算法,本质上都是对梯度下降法的各种变形,所以初始学习率对深层网络的收敛起着决定性的作用,下面就是梯度下降法的公式
![]()
这里 α 就是学习率,如果学习率太小,会导致网络loss下降非常慢,如果学习率太大,那么参数更新的幅度就非常大,就会导致网络收敛到局部最优点,或者loss直接开始增加,如下图所示。
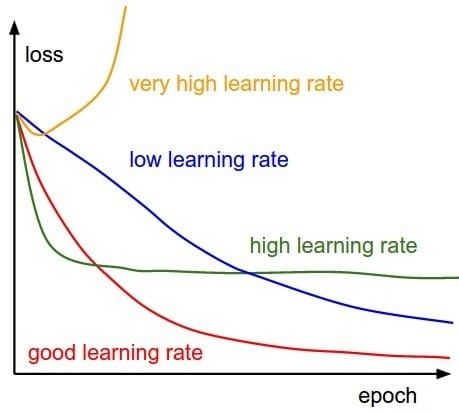
学习率的选择策略在网络的训练过程中是不断在变化的,在刚开始的时候,参数比较随机,所以我们应该选择相对较大的学习率,这样loss下降更快;当训练一段时间之后,参数的更新就应该有更小的幅度,所以学习率一般会做衰减,衰减的方式也非常多,比如到一定的步数将学习率乘上0.1,也有指数衰减等。
这里我们关心的一个问题是初始学习率如何确定,当然有很多办法,一个比较笨的方法就是从0.0001开始尝试,然后用0.001,每个量级的学习率都去跑一下网络,然后观察一下loss的情况,选择一个相对合理的学习率,但是这种方法太耗时间了,能不能有一个更简单有效的办法呢?
一个简单的办法
Leslie N. Smith 在2015年的一篇论文“Cyclical Learning Rates for Training Neural Networks”中的3.3节描述了一个非常棒的方法来找初始学习率,同时推荐大家去看看这篇论文,有一些非常启发性的学习率设置想法。
这个方法在论文中是用来估计网络允许的最小学习率和最大学习率,我们也可以用来找我们的最优初始学习率,方法非常简单。首先我们设置一个非常小的初始学习率,比如1e-5,然后在每个batch之后都更新网络,同时增加学习率,统计每个batch计算出的loss。最后我们可以描绘出学习的变化曲线和loss的变化曲线,从中就能够发现最好的学习率。
下面就是随着迭代次数的增加,学习率不断增加的曲线,以及不同的学习率对应的loss的曲线。

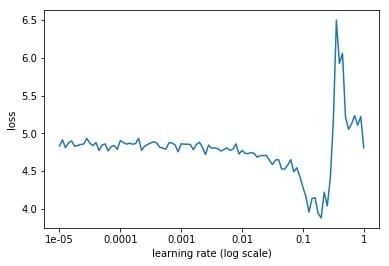
从上面的图片可以看到,随着学习率由小不断变大的过程,网络的loss也会从一个相对大的位置变到一个较小的位置,同时又会增大,这也就对应于我们说的学习率太小,loss下降太慢,学习率太大,loss有可能反而增大的情况。从上面的图中我们就能够找到一个相对合理的初始学习率,0.1。
之所以上面的方法可以work,因为小的学习率对参数更新的影响相对于大的学习率来讲是非常小的,比如第一次迭代的时候学习率是1e-5,参数进行了更新,然后进入第二次迭代,学习率变成了5e-5,参数又进行了更新,那么这一次参数的更新可以看作是在最原始的参数上进行的,而之后的学习率更大,参数的更新幅度相对于前面来讲会更大,所以都可以看作是在原始的参数上进行更新的。正是因为这个原因,学习率设置要从小变到大,而如果学习率设置反过来,从大变到小,那么loss曲线就完全没有意义了。
实现
上面已经说明了算法的思想,说白了其实是非常简单的,就是不断地迭代,每次迭代学习率都不同,同时记录下来所有的loss,绘制成曲线就可以了。下面就是使用PyTorch实现的代码,因为在网络的迭代过程中学习率会不断地变化,而PyTorch的optim里面并没有把learning rate的接口暴露出来,导致显示修改学习率非常麻烦,所以我重新写了一个更加高层的包mxtorch,借鉴了gluon的一些优点,在定义层的时候暴露初始化方法,支持tensorboard,同时增加了大量的model zoo,包括inceptionresnetv2,resnext等等,提供预训练权重,model zoo参考于Cadene的repo。目前这个repo刚刚开始,欢迎有兴趣的小伙伴加入我。
下面就是部分代码,近期会把找学习率的代码合并到mxtorch中。这里使用的数据集是kaggle上的dog breed,使用预训练的resnet50,ScheduledOptim的源码点这里。
- criterion = torch.nn.CrossEntropyLoss()
- net = model_zoo.resnet50(pretrained=True)
- net.fc = nn.Linear(2048, 120)
- with torch.cuda.device(0):
- net = net.cuda()
- basic_optim = torch.optim.SGD(net.parameters(), lr=1e-5)
- optimizer = ScheduledOptim(basic_optim)
- lr_mult = (1 / 1e-5) ** (1 / 100)
- lr = []
- losses = []
- best_loss = 1e9
- for data, label in train_data:
- with torch.cuda.device(0):
- data = Variable(data.cuda())
- label = Variable(label.cuda())
- # forward
- out = net(data)
- loss = criterion(out, label)
- # backward
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- lr.append(optimizer.learning_rate)
- losses.append(loss.data[0])
- optimizer.set_learning_rate(optimizer.learning_rate lr_mult)
- if loss.data[0] < best_loss:
- best_loss = loss.data[0]
- if loss.data[0] > 4 best_loss or optimizer.learning_rate > 1.:
- break
- plt.figure()
- plt.xticks(np.log([1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1]), (1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1))
- plt.xlabel(‘learning rate’)
- plt.ylabel(‘loss’)
- plt.plot(np.log(lr), losses)
- plt.show()
- plt.figure()
- plt.xlabel(‘num iterations’)
- plt.ylabel(‘learning rate’)
- plt.plot(lr)
one more thing
通过上面的例子我们能够有一个非常有效的方法寻找初始学习率,同时在我们的认知中,学习率的策略都是不断地做decay,而上面的论文别出心裁,提出了一种循环变化学习率的思想,能够更快的达到最优解,非常具有启发性,推荐大家去阅读阅读。
相关文章:
【深度学习】如何找到最优学习率
经过了大量炼丹的同学都知道,超参数是一个非常玄乎的东西,比如batch size,学习率等,这些东西的设定并没有什么规律和原因,论文中设定的超参数一般都是靠经验决定的。但是超参数往往又特别重要,比如学习率&a…...
详解—C++三大特性——多态
目录 一. 多态的概念 1.1 概念 二. 多态的定义及实现 2.1多态的构成条件 2.2 虚函数 2.3虚函数的重写 2.3.1虚函数重写的两个例外: 1. 协变(基类与派生类虚函数返回值类型不同) 2. 析构函数的重写(基类与派生类析构函数的名字不同) 2.4 C11 override 和 f…...

用idea搭建一个spring cloud微服务项目
以下是使用 IntelliJ IDEA 搭建 Spring Cloud 微服务项目的步骤: 创建一个新的 Maven 项目。 在 pom.xml 文件中添加以下依赖: <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-…...
SpringBoot——启动类的原理
优质博文:IT-BLOG-CN SpringBoot启动类上使用SpringBootApplication注解,该注解是一个组合注解,包含多个其它注解。和类定义SpringApplication.run要揭开SpringBoot的神秘面纱,我们要从这两位开始就可以了。 SpringBootApplicati…...
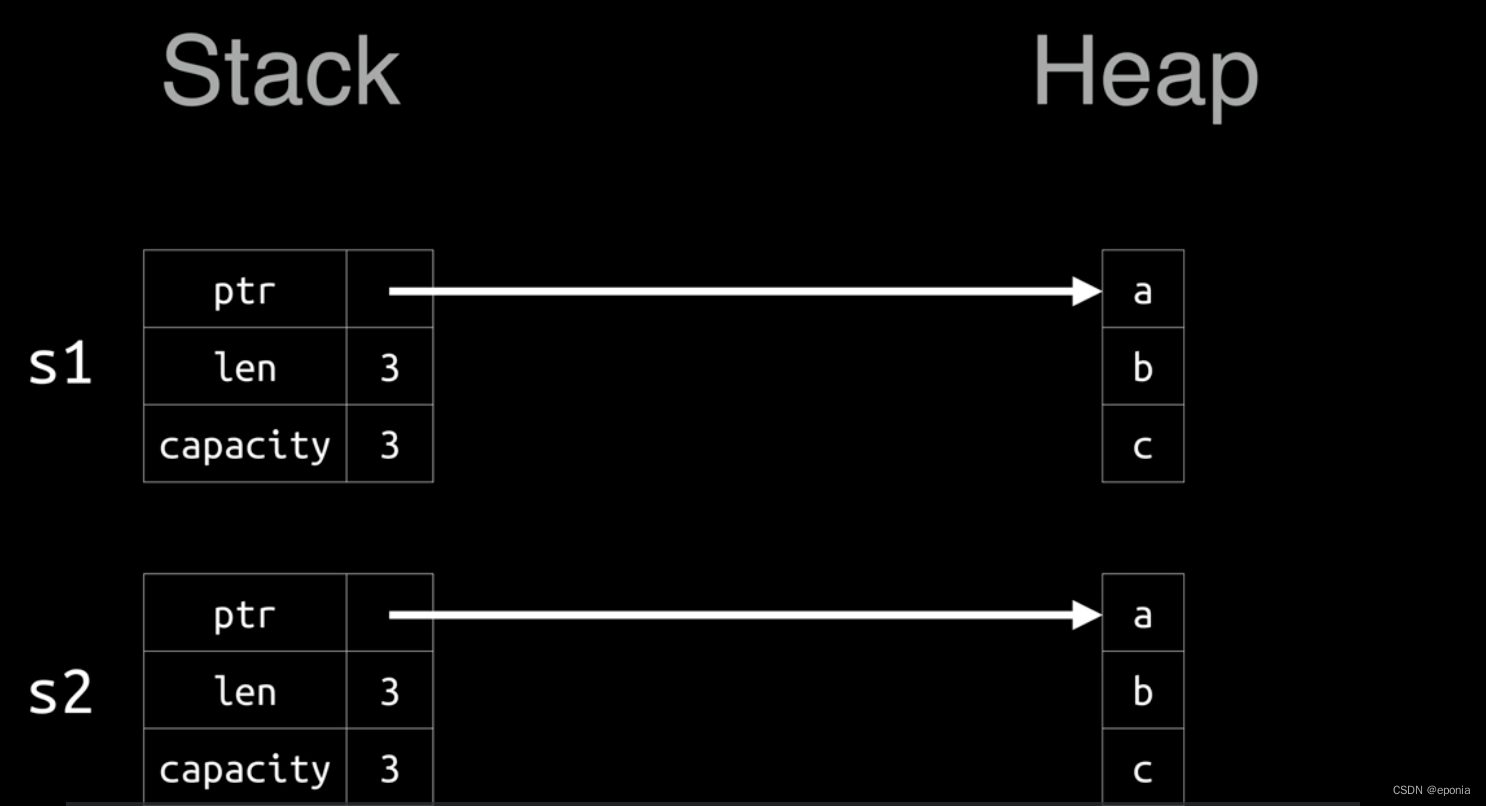
Rust语言入门教程(七) - 所有权系统
所有权系统是Rust敢于声称自己为一门内存安全语言的底气来源,也是让Rust成为一门与众不同的语言的所在之处。也正是因为这个特别的所有权系统,才使得编译器能够提前暴露代码中的错误,并给出我们必要且精准的错误提示。 所有权系统的三个规则…...
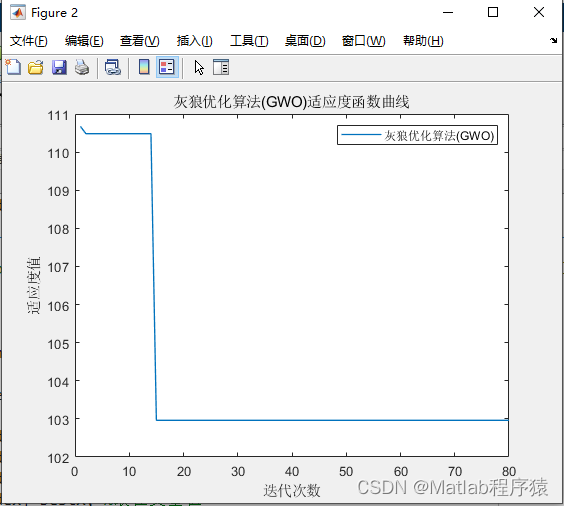
【MATLAB源码-第89期】基于matlab的灰狼优化算法(GWO)无人机三维路径规划,输出做短路径图和适应度曲线
操作环境: MATLAB 2022a 1、算法描述 灰狼优化算法(Grey Wolf Optimizer, GWO)是一种模仿灰狼捕食行为的优化算法。灰狼是群居动物,有着严格的社会等级结构。在灰狼群体中,通常有三个等级:首领ÿ…...

线程池的饱和策略有哪些?
线程池的饱和策略是指当线程池中的任务队列已满时,线程池如何处理新提交的任务。常见的饱和策略有以下几种: 阻塞策略 阻塞策略是指当线程池中的任务队列已满时,新提交的任务会等待队列中有空闲位置后再执行。这种策略可以避免过多的任务被…...

Git设置多个仓库同时推送
Git设置多个仓库同时推送 添加 在Git中,有时我们需要将同一份代码推送到不同的远程仓库,只是URL地址不同。 下面是一种优化的方法来设置多个仓库同时推送: # 添加一个新的远程仓库 git remote set-url --add origin2 新的仓库地址这样&am…...

前端入职环境安装
前端入职 后环境安装 ,内函 nodenvmgit微信开发者工具vscode 的安装包 一.node安装-js运行环境 1.node下载,下载地址Node.js 2.配置淘宝镜像 npm config set registry https://registry.npmmirror.com/ 3.查看配置 npm config list 二.nvm安装-切…...
《金融科技行业2023年专利分析白皮书》发布——科技变革金融,专利助力行业发展
金融是国民经济的血脉,是国家核心竞争力的重要组成部分,金融高质量发展成为2023年中央金融工作的重要议题。《中国金融科技调查报告》中指出,我国金融服务业在科技的助力下,从1.0时代的“信息科技金融”、2.0时代的“互联网金融”…...

Introducing the Arm architecture
快速链接: . 👉👉👉 个人博客笔记导读目录(全部) 👈👈👈 付费专栏-付费课程 【购买须知】:【精选】ARMv8/ARMv9架构入门到精通-[目录] 👈👈👈 — 适合小白入门【目录】ARMv8/ARMv9架构高级进阶-[目录]👈👈👈 — 高级进阶、小白勿买【加群】ARM/TEE…...

Python 使用SQLAlchemy数据库模块
SQLAlchemy 是用Python编程语言开发的一个开源项目,它提供了SQL工具包和ORM对象关系映射工具,使用MIT许可证发行,SQLAlchemy 提供高效和高性能的数据库访问,实现了完整的企业级持久模型。 ORM(对象关系映射࿰…...
)
【nlp】4.3 nlp中常用的预训练模型(BERT及其变体)
nlp中常用的预训练模型 1 当下NLP中流行的预训练模型1.1 BERT及其变体1.2 GPT1.3 GPT-2及其变体1.4 Transformer-XL1.5 XLNet及其变体1.6 XLM1.7 RoBERTa及其变体1.8 DistilBERT及其变体1.9 ALBERT1.10 T5及其变体1.11 XLM-RoBERTa及其变体2 预训练模型说明3 预训练模型的分类1…...
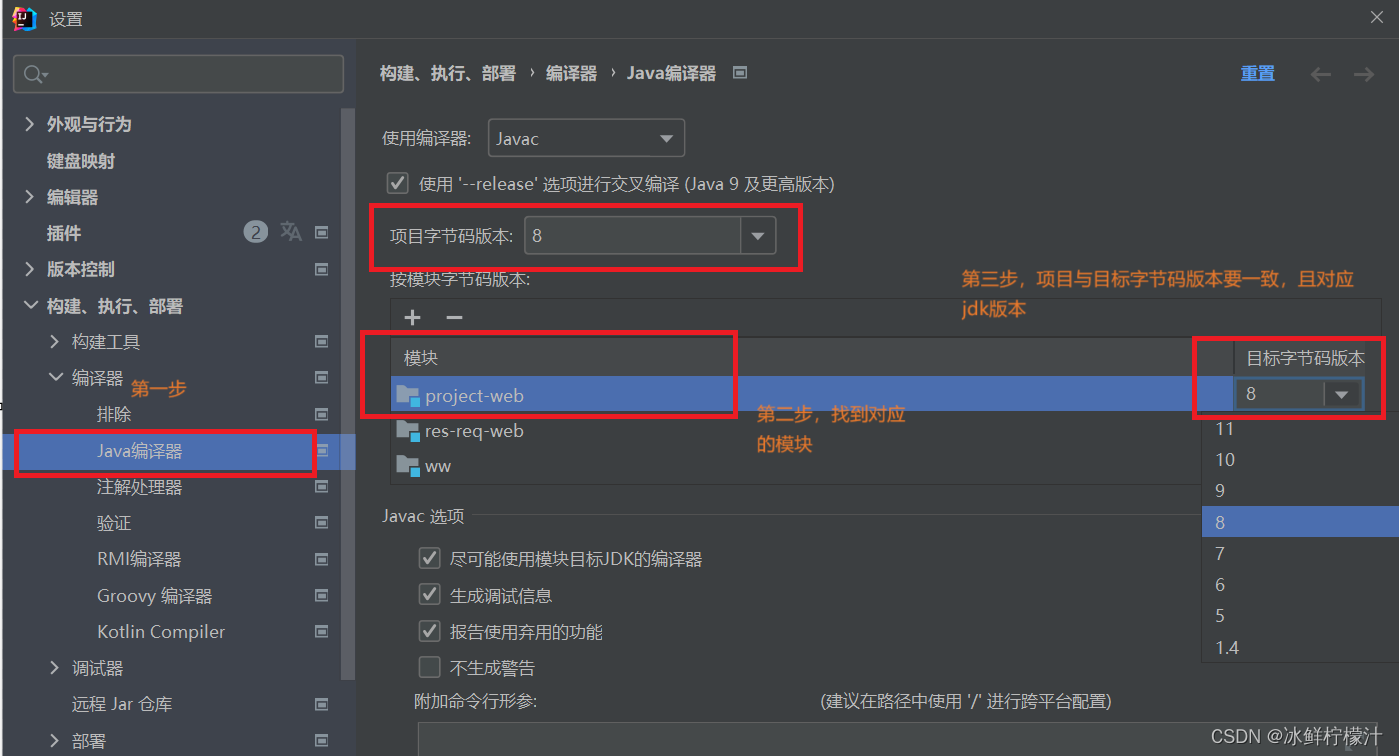
IDEA中 java: 警告: 源发行版 11 需要目标发行版 11 如何解决
步骤1找到项目结构,下面有两种方式 步骤2找到 模块中对应的项目,修改对应的源的语言级别和依赖的模块SDK(M) 步骤3,启动一下,看有无问题, 步骤4,去文件-->设置-->构建、执行、部署-->编译器-->…...

APP测试的测试内容有哪些,常见的Bug分类介绍!
对于产品的手机项目(应用软件),主要是进行系统测试。而针对手机应用软件APP的系统测试,我们通常从如下几个角度开展:功能模块测试、兼容性测试、安装和卸载测试、软件更新测试、性能测试、用户体验性测试、交叉事件测试…...
【Java程序员面试专栏 专业技能篇】Java SE核心面试指引(三):核心机制策略
关于Java SE部分的核心知识进行一网打尽,包括四部分:基础知识考察、面向对象思想、核心机制策略、Java新特性,通过一篇文章串联面试重点,并且帮助加强日常基础知识的理解,全局思维导图如下所示 本篇Blog为第三部分:核心机制策略,子节点表示追问或同级提问 异常处理 …...
网络运维与网络安全 学习笔记2023.11.22
网络运维与网络安全 学习笔记 第二十三天 今日目标 VLAN间通信之交换机、VLAN间通信综合案例、浮动路由 VRRP原理与配置、VRRP链路跟踪、VRRP安全认证 VLAN间通信之交换机 单臂路由的缺陷 在内网的VLAN数量增多时,单臂链路容易成为网络瓶颈 三层交换机 具备…...

Android虚拟化
一、开源项目 开源的项目有一些,比如完全虚拟化的: twoyi 两仪由两部分组成:两仪 App,它实际上是一个 UI 渲染引擎,两仪内部运行的 ROM。 但是看telegram和github,这个app没有完整开源,并且最近…...

Nginx如何配置负载均衡
nginx的负载均衡有4种模式: 1)、轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。 2)、weight 指定轮询几率,weight和访问比率成正比,用于后端服务…...

Python虚拟环境
Python虚拟环境 介绍 虚拟环境(virtual environment),它是一个虚拟化,从电脑独立开辟出来的环境。通俗的来讲,虚拟环境就是借助虚拟机来把一部分内容独立出来,我们把这部分独立出来的东西称作“容器”&am…...

C语言内存管理常见错误与防御性编程技巧
1. 指针未初始化引发的段错误1.1 结构体成员指针未初始化在C语言中,结构体内部的指针成员并不会自动分配内存。很多初学者会犯这样的错误:struct student {char *name;int score; }stu;int main() {strcpy(stu.name, "Jimy");stu.score 99;re…...

ICLR 2025 技术趋势解码:大模型优化与生成式AI的协同演进
1. 大模型优化的三大技术路线 过去一年我测试了超过20种大模型优化方案,发现当前技术演进主要集中在三个方向:参数压缩、训练加速和推理优化。先说最让我惊喜的轻量化技术,去年帮某电商客户把70B参数的客服模型压缩到3.8G大小,在移…...

活字格低代码:让业务流程设计从 “图纸” 到 “落地” 零 IT 转译
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

TOPMAX嵌入式Top-N最大值追踪库详解
1. TOPMAX库概述:嵌入式系统中的Top-N最大值追踪引擎TOPMAX是一个专为资源受限嵌入式平台设计的轻量级Arduino库,其核心功能是实时、高效地维护一个动态数据流中的前N个最大值。该库并非简单的排序容器,而是一种经过工程优化的“滑动窗口最大…...

电机速度计算
1. M法计算速度值详解:原理、公式与应用 概述 M法,也称为频率测量法,是一种通过在固定时间内统计脉冲数量来计算速度的常用方法。这种方法特别适用于中高速运动的测量场景,在电机控制、编码器测速等领域有着广泛的应用。 …...

绝地求生自动压枪解决方案:告别后坐力困扰,提升射击精准度
绝地求生自动压枪解决方案:告别后坐力困扰,提升射击精准度 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在激烈的绝地求…...

NTPAsyncClient:嵌入式异步时间同步轻量库解析
1. NTPAsyncClient 库深度解析:面向嵌入式实时系统的异步时间同步方案1.1 设计定位与工程价值NTPAsyncClient 是一个专为资源受限嵌入式平台设计的轻量级网络时间协议(NTP)客户端库,其核心目标并非替代标准 NTP daemon 的全功能实…...

Linux性能调优工具全景解析与实战指南
1. Linux性能调优工具全景图解析作为一名在Linux系统管理领域摸爬滚打多年的老手,我深知性能调优是系统管理员和开发者的必修课。今天我要分享的这组工具图谱,可以说是Linux性能分析的"九阳真经"。这些图表最初由Brendan Gregg等性能专家整理&…...

app手机监控功能
1 发现抖动的时候:发出大声警报 2 当处于监控状态的时候,手机无法打开任何app,只能停止在屏保界面。无法进行任何操作,无法关机 3 发现抖动的时候:拍照录视频 4 发现抖动的时候:打开GPS开关,发送…...

Globe.gl性能优化秘籍:如何高效处理大规模卫星数据可视化
Globe.gl性能优化秘籍:如何高效处理大规模卫星数据可视化 【免费下载链接】globe.gl UI component for Globe Data Visualization using ThreeJS/WebGL 项目地址: https://gitcode.com/gh_mirrors/gl/globe.gl Globe.gl是一个基于ThreeJS/WebGL的3D地球数据可…...