【论文阅读笔记】InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
【论文阅读笔记】StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation
- 论文阅读笔记
- 论文信息
- 引言
- 动机
- 挑战
- 方法
- 结果
- 关键发现
- 相关工作
- 1. 视觉语言基础模型
- 2. 视觉通用模型
- 方法/模型
- 视觉任务的统一说明
- 训练数据构建
- 网络结构
- 实验设计
- 关键点检测
- 分割
- 图像增强
- 图像编辑
- 复杂指令与简单指令
- 多任务学习
- 质量调整的重要性
- 未知任务的泛化
- 训练代价
- 总结
论文阅读笔记
- 用于将计算机视觉任务与人工指令相协调的统一通用框架
- 这篇工作希望单一模型整合计算机视觉领域的任务。和Emu Edit的出发点一样,都将多个视觉任务视为图像生成任务并同时处理,尤其是图像编辑。
- 和Emu一样使用质量调整作为提升模型性能的方法
- 数据制造过程使用了很多离线的图像编辑方案,如Paint by Example: Exemplar-based Image Editing with Diffusion Models制作目标替换数据,LAMA(Resolution-robust Large Mask Inpainting with Fourier Convolutions)制作目标删除和添加数据。此外还通过公开数据集扩充以及爬虫爬取真实数据
- LAION-Aesics-Predictor评估美学、LAION-600M图像上构建KNN-GIQAKNN-GIQA计算GIQA,这两个评估标准可作为现有图像生成质量的补充评价标准
- Emu Edit和Instruct Diffusion的异同
- 相同点:
- 视作多任务学习
- 不同点:
- 两者涵盖的任务不同,前者为不同任务使用不同的指令编码进行引导,训练标签遵循于不同任务的标签;后者手动设置了不同任务的编辑指令,不同格式的输出都整合到了三通道的图像作为标签;
- Emu Edit基于Emu更好的性能的diffusion;InstructDiffusion额外进行了质量调整
- 两者使用的数据集筛选标准不同;前者制作的数据集主要通过P2P生成,且更加精细化,后者使用了不少公开数据集
- 前者数据集大概1000万张;后者大概100万张
- 前者512分辨率,没有给出具体训练时间;后者分辨率256,200epoch,48个A100 GPU训练4天
- 相同点:
论文信息
- 论文标题:InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
- 作者:微软亚洲研究院
- 发表年份:2023
- 期刊/会议:暂无
- code:https://github.com/cientgu/InstructDiffusion
- 项目主页:https://gengzigang.github.io/instructdiffusion.github.io/

引言
动机
生成式预训练 Transformer (GPT) 通过为各种应用提供一个单一的、连贯的框架,成功地统一了多个 NLP 任务。
本文旨在计算机视觉领域实现类似的统一,即同时处理多个计算机视觉任务。
挑战
- 计算机视觉任务的多样性:
- 包含识别、检测、分割、生成等任务
- 不同任务的标签也不一样
- 方法和技巧的多样性:
- 视觉任务倾向于使用显著不同的方法和技巧处理不同任务,如GAN和DPM(概率扩散模型)
- 语言模型依靠Transformer可以解决大部分问题
- 连续输入和输出:
- 计算机视觉任务的输入和输出通常是连续的,如坐标或图像
- 图像可以被看作符合一定分布的,如果进行离散化会导致误差,不想文本数据可以被解释为离散Token的组合
方法
- 利用DDPM,提出了一种新的方法来解决这些挑战,将所有计算机视觉任务视为图像生成,特别是图像编辑任务【Visual Prompting via Image Inpainting和Images Speak in Images: A Generalist Painter for In-Context Visual Learning两篇文章是视作inpainting任务】
- 首先将不同的视觉任务通过文本描述为对应的图像编辑任务,如Figure1所示,分割可以解释为将对应的object像素转换为特定的颜色
- 随后把输出格式概括为3通道RGB图像、二进制掩码和关键点三种,并将mask和keypoint也编码到3通道RGB图像以适应DPM的输出
- 最后使用后处理模块来提取常用的输出格式进行评估
- 训练阶段使用一组不同的任务来统一训练单个模型,此外收集了一个新的图像编辑数据集
结果
- InstructDiffusion 可以处理各种视觉任务,包括理解任务(例如分割和关键点检测)和生成任务(例如编辑和增强)
- 它甚至展示了处理看不见的任务的能力,并在新的数据集上优于以前的方法。
关键发现
- 为每个任务训练单个模型相比,多个任务的联合训练可以提高泛化能力(同Emu Edit)
- 模型还在一定程度上展示了 AGI 的能力,因为它可以处理训练阶段看不到的任务,例如图像分类和分类
- 在训练期间没有看到的数据集上的表现优于以前的方法
相关工作
【构建一个能够解决任何任意任务的通用模型一直是人工智能研究的长期愿望】
1. 视觉语言基础模型
利用文本和图像大型数据对
- CLIP 和 ALIGN 使用对比损失进行训练
- 通过在跨模态共享嵌入空间中对齐图像和文本对,显示出对下游任务令人印象深刻的泛化能力
- 基于对比的方法缺乏生成语言的能力,限制了在开放任务中的使用,如Image caption、visual question answering
- 大型语言模型GPT、LLaMA、PaLM将视觉任务视作文本预测问题,将视觉任务映射为语言语义
2. 视觉通用模型
多任务学习,关键挑战在于任务输出的各种结构的多样性和复杂性
- 类语言的生成(量化离散)
- 从 NLP 领域的序列到序列模型中汲取灵感,并通过下一个标记预测对一系列离散标记进行建模
- Pix2Seq v2通过量化前三个任务的连续图像坐标来统一目标检测、实例分割、关键点检测和图像字幕
- Unified IO使用矢量VQ-VAE进一步统一密集结构输出,如图像、分割掩码和深度映射
- 图像组装生成
- Painter将密集预测任务表述为掩模图像修复问题,并在深度估计、语义分割、实例分割、关键点检测和图像恢复等视觉任务中展示了上下文能力
- PromptDiffusion利用上下文视觉学习与文本引导的扩散模型,并集成了六种不同任务的学习
本文方法通过更有力的指令对齐,显式的处理多种图像任务
方法/模型
通过利用去噪扩散概率模型 (DDPM),将所有计算机视觉任务视为具有灵活和交互式像素空间中的输出的人类直觉图像处理过程
视觉任务的统一说明
- 所有任务的统一建模界面称为指令图像编辑
- 训练集 x i : { c i , s i , t i } x^i:\{c^i,s^i,t^i\} xi:{ci,si,ti},分别编辑指令、原图像和目标图像,类似于Instruct pix2pix
- 关键点检测
- 精确定位图像中的关键对象组件
- 指令示例:“Please use red to encircle the left shoulder of the man.“
- 分割
- 识别输入图像中特定对象的区域
- 指令示例:“apply a blue semi-transparent mask to the rightmost dog while maintaining the remainder unaltered.“
- 图像增强和图像编辑
- 去模糊、去噪和水印去除等图像增强固有地产生输出图像,同样适用于图像编辑
- 指令示例:“Make the image much sharper” for 去模糊, “Please remoe the watermark on the image” for 去水印, and “add an apple in the woman’s hand” for 图像编辑
首先为每个任务手动编写 10 条指令。然后使用 GPT4 重写和扩展这些指令的多样性,从而模仿用户输入系统。。在训练过程中随机选择一个指令
训练数据构建
- 采用广泛使用的公开可用数据集,并根据指令模板构建地面实况目标图像
- InstructPix2Pix (IP2P)通过利用GPT3生成指令和Prompt2Prompt来创建输出图像,开创了使用合成训练数据集。然而,合成的源图像和目标图像表现出不同的质量和不可忽略的伪影,大多数指令都集中在全局样式修改而不是局部更改上【Emu Edit则是精心设计了合成数据集的制造流程和筛选流程】。
- MagicBrush 引入了一个包含超过 10,000 个手动注释的三元组的数据集,但与其他视觉任务相比,它的大小是有限的。
- 除了 IP2P [6]、GIER [63]、GQA [90] 和 MagicBrush [96] 等现有数据集外,还提出了一种新的数据集,称为野外图像编辑 (IEIW),其中包含 159,000 个图像编辑对,涵盖广泛的语义实体和不同级别的语义粒度
- 对象删除。参考分割数据集PhraseCut来构建对象删除数据。PhraseCut 为相应区域提供参考短语的图像。将这些区域设置为掩码并使用 LAMA 对其进行修复,将它们转换为教学修复数据集。交换输入和输出图像,并将“删除树顶部的蓝色鸟”等指令反转为“在树的顶部添加蓝色鸟”,以从添加组件的角度进一步补充数据
- 对象替换。首先构建了一个图库数据库,该数据库由基于这些语义感知区域的不同图像块组成。给定OpenImages或SA-1B的源图像,我们随机选择一个语义区域,作为查询补丁,从上述构建的图库中检索其最近的邻居数据库。检索到的相似补丁被视为源图像的参考图像,两者都被馈送到 PaintByExample 以生成目标图像。通过这种方式,我们获得了源图像和修改后的目标图像。为了生成指令,我们利用图像字幕工具,例如 BLIP2,以产生源字幕和目标字幕,然后通过大型语言模型生成可能的指令。例如,给定标题“正在运行的狗”和“带有黑白条纹的剪刀猫”,可能的指令是“请将跑步狗更改为带有黑白条纹的剪刀猫”。
- Web 爬虫。收集了真实的用户请求以及来自网站的经验丰富的 Photoshop 专业人士提供的相应结果。为了确保数据的准确性和相关性,我们利用关键字“Photoshop 请求”在 Google 中搜索,积累一个包含超过 23,000 个数据三元组的大量数据集,进一步改进对用户需求的理解,并减少训练和推理之间的域差距。
- 利用图像质量评估工具来消除标准数据
- LAION-Aesics-Predictor进行美学评分
- LAION-600M图像上构建KNN-GIQAKNN-GIQA模型来计算GIQA评分
- 排除质量分数较低的,以及源图像和目标图像质量分数差异过大的
网络结构
分为预训练适应、特定于任务的训练和指令调整三个阶段
-
预训练适应
- finetineSD1.5以适应编辑指令以及对应的图像
-
特定任务的训练
- 遵循Instruct pix2pix进行训练,但由于不同任务的数据量不同,使用不同的权重进行训练
L = E ( s i , c i , t i ) ∼ P ( x ) , ϵ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( z t , t , s i , t i ) ∥ 2 2 ] L=\mathbb{E}_{\left(s_i, c_i, t_i\right) \sim \mathcal{P}(x), \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_\theta\left(z_t, t, s_i, t_i\right)\right\|_2^2\right] L=E(si,ci,ti)∼P(x),ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t,si,ti)∥22]
- 遵循Instruct pix2pix进行训练,但由于不同任务的数据量不同,使用不同的权重进行训练
-
人工对齐
- 为提高编辑的质量,遵循大型语言模型的指令调优的思想,类似Emu Edit的质量调整过程
- 具体来说,生成一批数据,人工筛选其中最好的1000张队预训练模型微调
实验设计
训练数据
- 三元组{指令、源图像、目标图像},包含多种任务关键点检测、语义分割、参考分割、图像增强,包括去噪、去模糊和水印去除、图像编辑
- 关键点检测:COCO、CrowdPose、MPII、AIC四个数据集,训练过程中每个图像随机使用 1 到 5 个关键点,随机颜色。指令通过填充关键点类和特定颜色类的模板生成的
- 分割:COCO-Stuff作为语义分割训练,gRefCOCO和 RefCOCO 作为参考分割训练数据集。利用LLM收集提示模板作为文本指令。如“在对象上放置颜色掩码”。训练过程中,随机选择一个颜色进行“颜色”,并将“对象”替换为语义分割中的相应类别名称或引用分割。目标图像使用其对应的颜色放置透明度为 0.5 的掩码
- 图像增强:去模糊、去噪和水印去除。利用包含 2103 张图像和 REDS [50] 数据集的 GoPro,其中包含 24,000 张图像用于去模糊,SIDD 数据集由 320 张图像组成用于去噪,CLWD 数据集包含 60,000 张图像用于水印去除。
- 图像编辑:过滤的InstructPix2Pix、MagicBrush、GIER、GIER、GIER、生成的数据

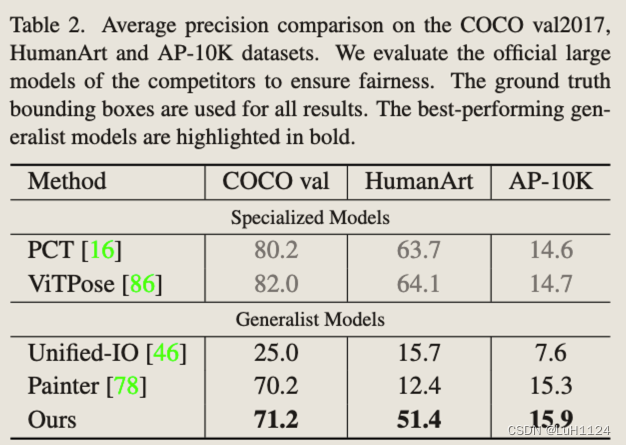
关键点检测
后处理:提取准确的姿势坐标信息,即精确的水平和垂直坐标,而不是简单地用不同的符号标记位置。采用了一个轻量级的 U-Net 结构,该结构对输出图像进行后处理以生成多通道heatmap
结果:没有打过专有模型,但高于其他通才模型,可能是由于数据量不够或者结合?但是可以泛化检测出训练集以外的关键点

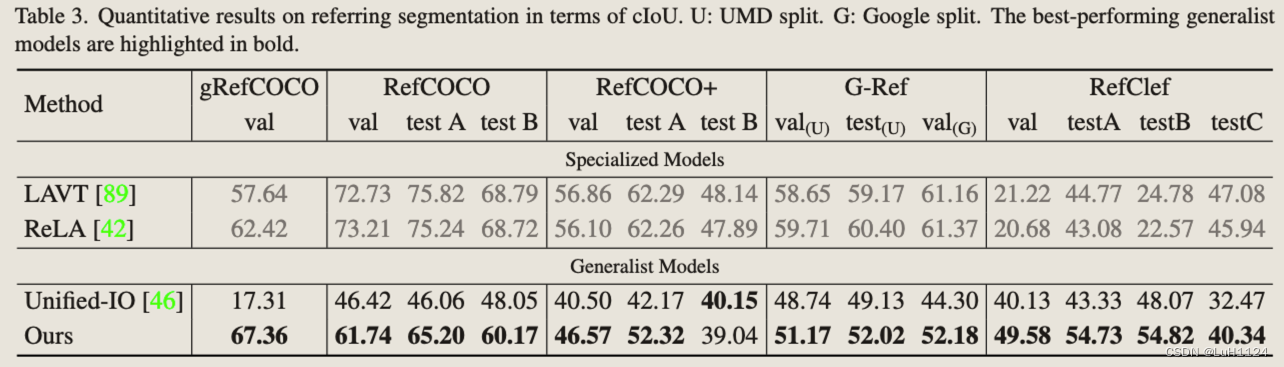
分割
后处理:与关键点检测类似,采用了一个轻量级的 U-Net 结构,该结构对输出图像进行后处理以提取每个单独对象的二进制掩码
结果:优于专有模型,通过文本指令建立与每个语义类别相对应的颜色,从而显着提高性能
图像增强
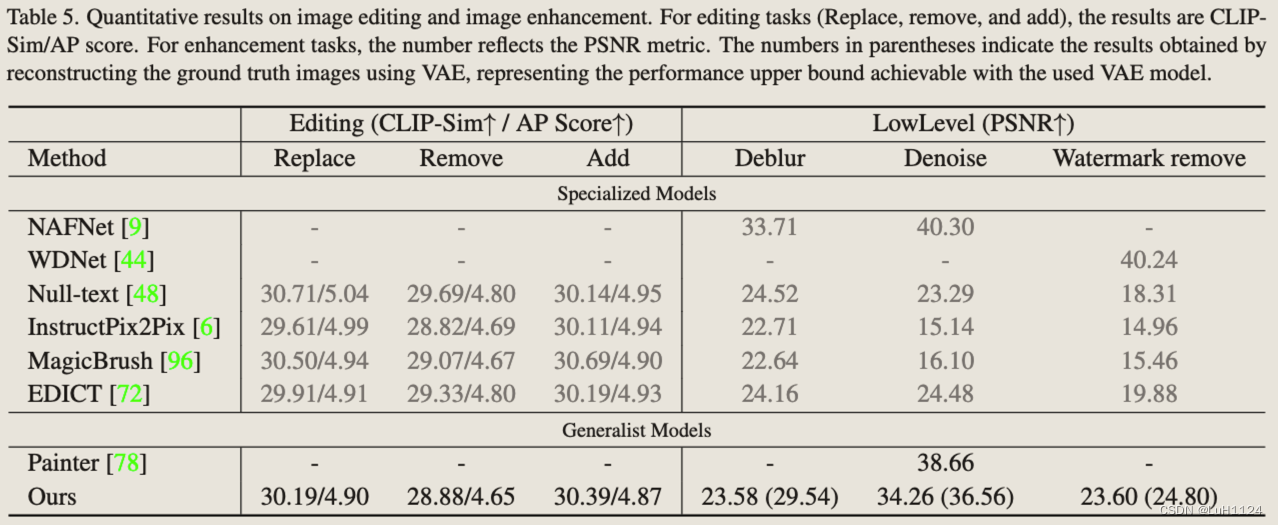
- 首先,针对图像编辑任务训练的专业模型在应用于图像增强任务时往往表现出较差的泛化能力
- 通才模型 Painter 在去噪任务中表现更好,但在通过上下文学习无缝集成图像编辑任务时遇到了挑战
- 模型在图像增强方面的性能受到 VAE 模型的限制,该模型引入了信息丢失。所以ground truth使用的是VAE重建的原始图像

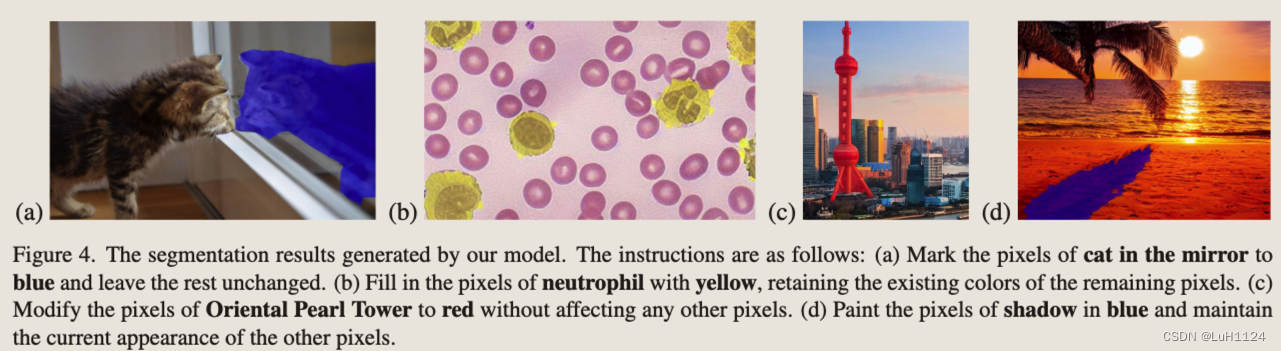
图像编辑
定量实验见Figure.5


复杂指令与简单指令
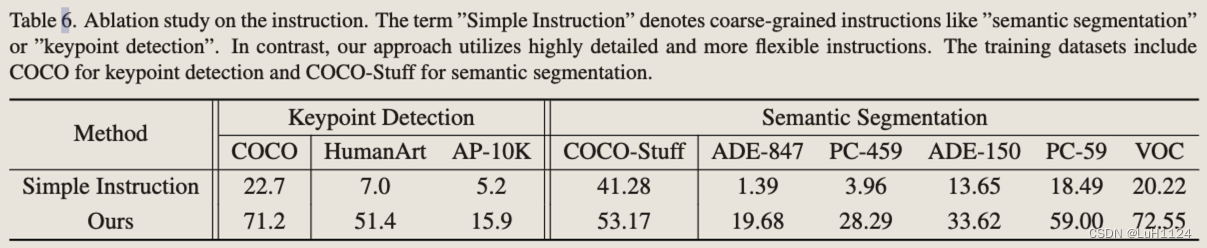
假设泛化能力是通过理解单个元素的特定含义而不是记忆整个指令来学习的技能。与之前简单地将自然语言视为任务指标的 Pix2seq 和 Unified-IO 等统一模型不同,该方法为每个任务使用详细描述作为指令。详细指令可以实现更好的性能
多任务学习
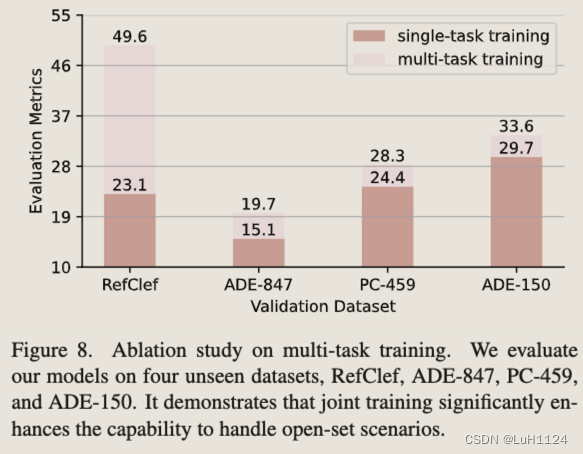
多任务学习下与专有模型分别在未见过的数据集上测试,泛化性能明显增强

多任务训练的编辑准确性高于单任务编辑
质量调整的重要性
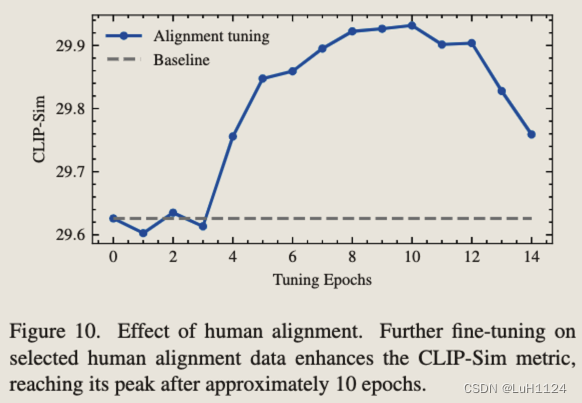
符合Emu的描述,不能训练太久,也不能训练太少,需要权衡。
未知任务的泛化

- 通过这种高度详细的指令跟随格式利用丰富的任务和不同的数据集来展示一定程度的人工智能 (AGI) 能力。
- 我们验证了它处理不属于其训练库的任务的能力,如人脸检测、分类甚至复杂的细粒度任务,如人脸对齐。
- 在检测和分类的背景下,采用了类似于参考分割的提示,通过识别标记区域的顶部、底部、左侧和右侧边界来导出边界框坐标。此外,使用一个通用的提示结构来验证类标签
- 发现能够泛化到动物的五点检测
训练代价
- SD] v1.5作为初始化来利用文本到图像的生成先验。将输入图像分辨率预处理为256 × 256,训练过程中学习率固定为1 × 10−4
- 采用 0.9999 的 EMA 率来稳定训练,使用 3072 的批量大小进行训练,总共 200 个 epoch,48 个 NVIDIA V100 GPU 上大约 4 天
- 在人工对齐阶段,使用 0.99 的 EMA 率来帮助模型快速适应指令调整数据集
总结
- InstructDiffusion 将所有计算机视觉任务视为图像生成,重点关注三种类型的输出格式:3 通道 RGB 图像、二进制掩码和关键点。我们证明了我们的方法在单个任务中取得了良好的性能,并且多个任务的联合训练增强了泛化能力。
- 未来工作
1)改进统一表示:我们旨在探索替代编码方案和技术,以更好地表示与各种计算机视觉任务相关的更多样化的输出范围。2)研究自监督学习和无监督学习的作用:为了增强 InstructDiffusion 的泛化能力,我们将探索使用自我监督和无监督学习技术来利用大规模未标记数据进行模型训练和适应。
相关文章:
【论文阅读笔记】InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
【论文阅读笔记】StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation 论文阅读笔记论文信息引言动机挑战 方法结果 关键发现相关工作1. 视觉语言基础模型2. 视觉通用模型 方法/模型视觉任务的统一说明训练数据构建网络结构 实验设…...

笔记62:注意力汇聚 --- Nadaraya_Watson 核回归
本地笔记地址:D:\work_file\(4)DeepLearning_Learning\03_个人笔记\3.循环神经网络\第10章:动手学深度学习~注意力机制 a a a a a a a a a a a a a a a a...

给定一个n×n的方阵,本题要求计算该矩阵除副对角线、最后一列和最后一行以外的所有元素之和。
7-5 矩阵运算 分数 20 全屏浏览题目 切换布局 作者 C课程组 单位 浙江大学 给定一个nn的方阵,本题要求计算该矩阵除副对角线、最后一列和最后一行以外的所有元素之和。副对角线为从矩阵的右上角至左下角的连线。 输入格式: 输入第一行给出正整数n(…...

Go语言的学习笔记3——Go语言项目布局
Go 1.11 版本开始引入 go.mod 和 go.sum 以支持Go Module构建机制,而这种机制成为官方的依赖包管理方式。 现在Go可执行程序项目的典型布局如下所示: exe-layout ├── cmd/ │ ├── app1/ │ │ └── main.go │ └── app2/ │ └…...

70-76-堆、贪心算法
LeetCode 热题 100 文章目录 LeetCode 热题 100堆70. 中等-数组中的第K个最大元素71. 中等-前K个高频元素72. 困难-数据流中的中位数 贪心算法73. 简单-买卖股票的最佳时机74. 中等-跳跃游戏75. 中等-跳跃游戏II76. 中等-划分字母区间 本文存储我刷题的笔记。 堆 70. 中等-数组…...

Qt Network
Qt Network Qt Network为使用TCP/IP的应用程序编程提供了一组API。各种C++类处理诸如请求、cookies和通过HTTP发送数据之类的操作。 标题使用模块 使用Qt模块需要直接或通过其他依赖项链接到模块库。一些构建工具对此有专门的支持,包括CMake和qmake. 标题使用CMake构建 使…...
Win10电脑用U盘重装系统的步骤
在Win10电脑中,用户遇到了无法解决的系统问题,用户这时候就可以考虑重装Win10系统,这样即可轻松解决问题,从而满足自己的操作需求。接下来小编给大家详细介绍关于Win10电脑中用U盘重装系统的教程步骤。 准备工作 1. 一台正常联网可…...

安防视频监控/磁盘阵列/集中云存储平台EasyCVR设备录像保活不生效原因是什么?该如何解决?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
【JDK21】详解虚拟线程
目录 1.概述 2.虚拟线程是为了解决哪些问题 2.1.线程切换的巨大代价 2.2.哪些情况会造成线程的切换 2.3.线程资源是有限的 3.虚拟线程 4.适用场景 1.概述 你发任你发,我用JAVA8?JDK21可能要对这句话say no了。 现在Oracle JDK是每4个版本&#x…...
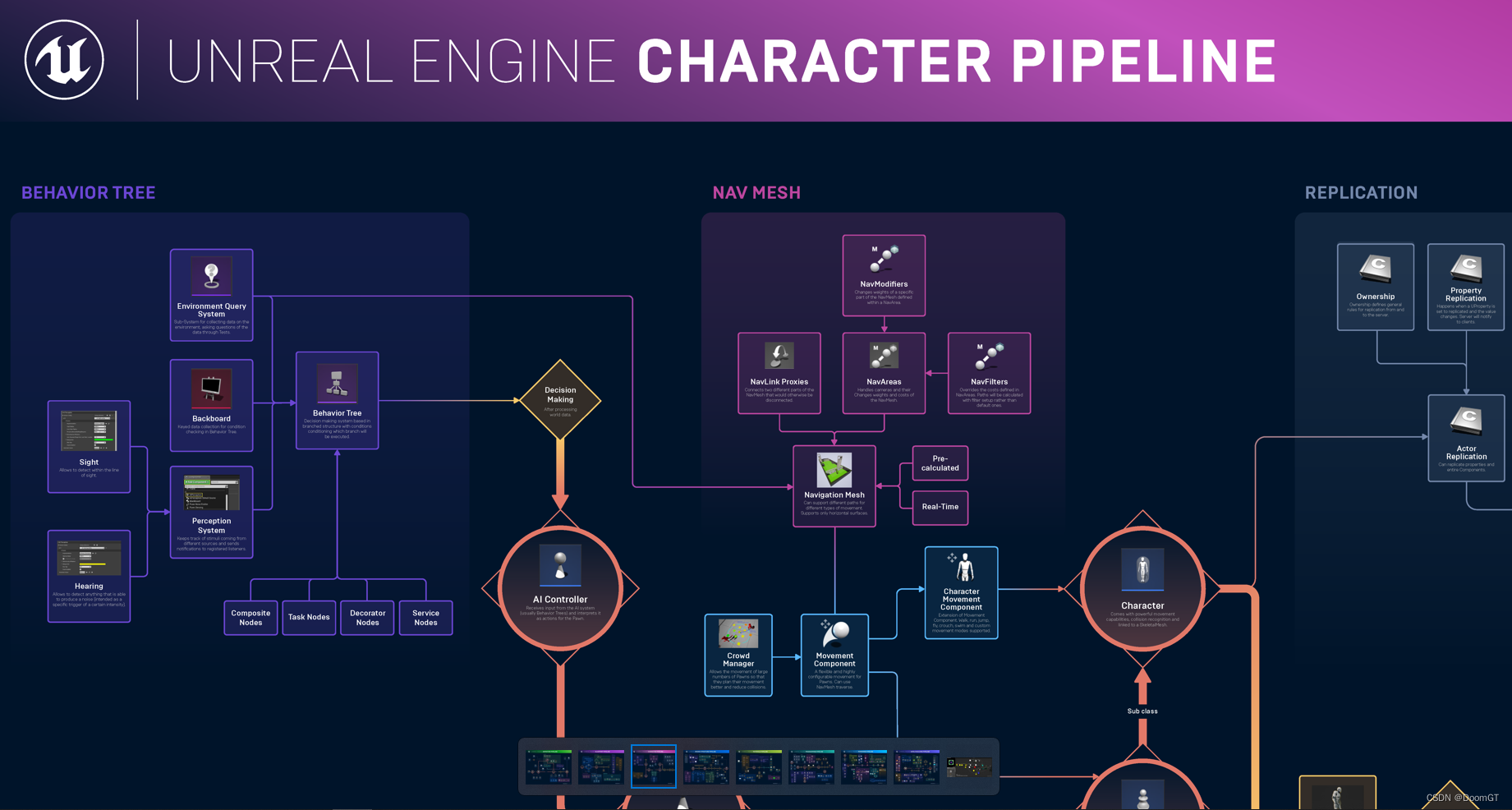
UE5 - 虚幻引擎各模块流程图
来自虚幻官方的一些资料,分享一下; 一些模块的流程图,比如动画模块: 或角色相关流程: 由于图片比较大,上传到了网络,可自取: 链接:https://pan.baidu.com/s/1BQ2KiuP08c…...
vue3实现element table缓存滚动条
背景 对于后台管理系统,数据的展示形式大多都是通过表格,常常会出现的一种场景,从表格跳到二级页面,再返回上一页时,需要缓存当前的页码和滚动条的位置,以为使用keep-alive就能实现这两种诉求,…...
)
flutter布局详解及代码示例(下)
布局 基本布局 GridView(二维滚动列表):比ListView多了一个方向的数据填充。ListBody(滚动列表):相比ListView,没有回收复用,简单易用。Table(表格布局)&am…...

SQL Server:流程控制语言详解
文章目录 一、批处理、脚本和变量局部变量和全局变量1、局部变量2、全局变量 二、顺序、分支和循环结构语句1、程序注释语句2、BEGIN┅END语句块3、IF┅ELSE语句4、CASE语句5、WHILE语句6、BREAK和CONTINUE语句BREAK语句CONTINUE语句 三、程序返回、屏幕显示等语句1、RETURN语句…...
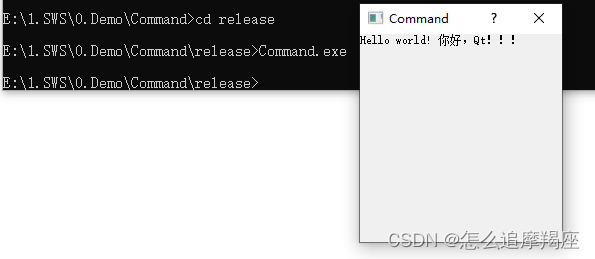
2、用命令行编译Qt程序生成可执行文件exe
一、创建源文件 1、新建一个文件夹,并创建一个txt文件 2、重命名为main.cpp 3、在main.cpp中添加如下代码 #include <QApplication> #include <QDialog> #include <QLabel> int main(int argc, char *argv[]) { QApplication a(argc, argv); QDi…...

【追求卓越08】算法--排序算法
引导 今天开始介绍我们在工作中经常遇到的算法--排序。排序算法有很多,我们主要介绍以下几种: 冒泡排序 插入排序 选择排序 归并排序 快速排序 计数排序 基数排序 桶排序 我们需要了解每一种算法的定义以及实现方式,并且掌握如何评…...
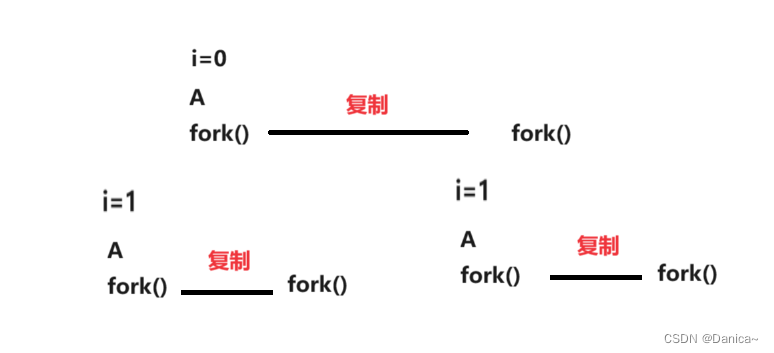
Linux fork笔试练习题
1.打印结果? #include <stdio.h> #include <unistd.h> #include <stdlib.h>int main() {int i0;for(;i<2;i){fork();printf("A\n");}exit(0); } 结果打印 A A A A A A 2.将上面的打印的\n去掉,结果如何? printf("…...

Jenkins 整合 Docker 自动化部署
Docker 安装 Jenkins 配置自动化部署 1. Docker 安装 Jenkins 1.1 拉取镜像文件 docker pull jenkins/jenkins1.2 创建挂载文件目录 mkdir -p $HOME/jenkins_home1.3 启动容器 docker run -d -p 8080:8080 -v $HOME/jenkins_home:/var/jenkins_home --name jenkins jenkin…...

竞赛选题 题目:基于大数据的用户画像分析系统 数据分析 开题
文章目录 1 前言2 用户画像分析概述2.1 用户画像构建的相关技术2.2 标签体系2.3 标签优先级 3 实站 - 百货商场用户画像描述与价值分析3.1 数据格式3.2 数据预处理3.3 会员年龄构成3.4 订单占比 消费画像3.5 季度偏好画像3.6 会员用户画像与特征3.6.1 构建会员用户业务特征标签…...

selenium已知一个元素定位同级别的另一个元素
1.需求与实际情况 看下图来举例 (1)需求 想点击test22(即序号-第9行)这一行中右边的“复制”这一按钮 (2)实际情况 只能通过id或者class定位到文件名这一列的元素,而操作这一列的元素是不…...

Kotlin中 for in 是有序的吗?forEach呢?
我们要遍历一个数组、一个列表,经常会用到kotlin的 for in 语法,但是 for in 是不是有序的呢?forEach是不是有序的呢?这就需要看一下它们的本质了。 数组的 for in // 调用: val arr arrayOf(1, 2, 3) for (ele in …...

FanControl:智能风扇控制的全方位解决方案
FanControl:智能风扇控制的全方位解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl…...

如何在Windows系统上高效安装和管理Android应用:APK Installer完整指南
如何在Windows系统上高效安装和管理Android应用:APK Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 对于需要在Windows电脑上运行Androi…...

Qwen3-VL-8B分步部署教程:vLLM服务+proxy_server+chat.html独立启动详解
Qwen3-VL-8B分步部署教程:vLLM服务proxy_serverchat.html独立启动详解 1. 项目概述 今天给大家分享一个完整的AI聊天系统部署方案,基于Qwen3-VL-8B大语言模型,包含前端界面、反向代理服务器和vLLM推理后端。这个系统采用模块化设计…...

喜马拉雅音频下载器:解决VIP内容离线保存的技术方案
喜马拉雅音频下载器:解决VIP内容离线保存的技术方案 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 你是否曾因网络波动…...

Laravel ResponseCache 快速入门:5个步骤实现全站缓存加速
Laravel ResponseCache 快速入门:5个步骤实现全站缓存加速 【免费下载链接】laravel-responsecache Speed up a Laravel app by caching the entire response 项目地址: https://gitcode.com/gh_mirrors/la/laravel-responsecache Laravel ResponseCache 是一…...

OpenClaw语音交互方案:Qwen3.5-9B对接Whisper实现语音指令控制
OpenClaw语音交互方案:Qwen3.5-9B对接Whisper实现语音指令控制 1. 为什么需要语音交互能力? 上周我在整理电脑文件时突然想到:既然OpenClaw能模拟人类操作电脑,为什么不给它加上耳朵呢?这个想法源于我经常双手沾满咖…...

如何用Untrunc开源工具拯救损坏的视频文件:从理论到实践的完整指南
如何用Untrunc开源工具拯救损坏的视频文件:从理论到实践的完整指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc …...

麒麟kylinV10系统yum源优化与rpm包管理实战
1. 麒麟kylinV10系统yum源优化实战 第一次用麒麟kylinV10系统时,最让我头疼的就是默认yum源速度慢得像蜗牛。记得有次安装个基础开发工具,等了半小时进度条才动了一点点。后来发现通过优化yum源配置,下载速度能提升10倍不止。下面就把我这几年…...

Unity3D RPG游戏开发:从零构建角色扮演游戏的核心系统
1. 环境准备与项目初始化 第一次打开Unity Hub时,新手常会被各种版本和选项搞得晕头转向。我建议直接安装最新的LTS版本(比如2022.3),这个版本就像游戏界的"稳定版安卓系统",既不会太老缺少功能,…...

SQL分组Group By
一、先搞懂:分组查询是干嘛的?分组查询 GROUP BY 就是把表中数据按照某个字段「分类」,然后对每一类做统计。比如你 emp 表有 gender(性别)字段,用分组就能:统计「男员工有多少人、女员工有多少…...