[RDMA-高级计算机网络report] Congestion Control for Large-Scale RDMA Departments

本文主要解决的问题是在RoCEv2体系中,基于优先级的拥塞控制PFC是一种粗粒度的机制。 它在端口(或端口加优先级)级别上运行,并且不区分流。PAUSE机制是基于每个端口(和优先级)的,而不是基于每个流的。 这将导致Unfairness和Victim flow等问题。为了解决这个问题,作者提出了DCQCN机制,DCQCN提供快速收敛以达到公平性,实现高链路利用率,确保低队列建立和低队列振荡。
背景
现实计算机网络中的通信场景中,主要是以发送小消息为主,因此处理延迟是提升性能的关键。
传统的 TCP/IP 网络通信,数据需要通过用户空间发送到远程机器的用户空间,在这个过程中需要经历若干次内存拷贝:
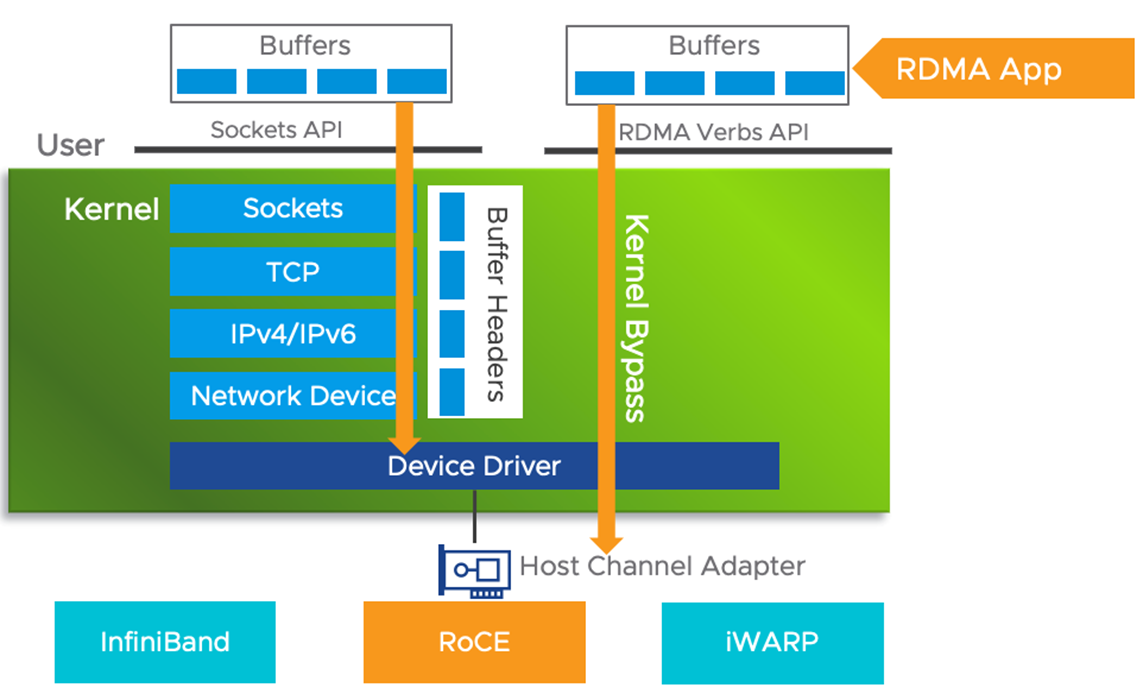
RDMA (Remote Direct Memroy Access )为了消除传统网络通信带给计算任务的瓶颈,我们希望更快和更轻量级的网络通信,由此提出了RDMA技术。RDMA利用 Kernel Bypass 和 Zero Copy技术提供了低延迟的特性,同时减少了CPU占用,减少了内存带宽瓶颈,提供了很高的带宽利用率。RDMA提供了给基于 IO 的通道,这种通道允许一个应用程序通过RDMA设备对远程的虚拟内存进行直接的读写。
RDMA 技术有以下几个特点:
-
CPU Offload:无需CPU干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充
-
Kernel Bypass:RDMA 提供一个专有的 Verbs interface 而不是传统的TCP/IP Socket interface。应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换
-
Zero Copy:每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
RoCE协议存在RoCEv1 (RoCE)和RoCEv2 (RRoCE)两个版本,主要区别RoCEv1是基于以太网链路层(L2)实现的RDMA协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),而RoCEv2是以太网TCP/IP协议中UDP层(L3)实现。
Queues | 队列
RDMA一共支持三种队列,发送队列(SQ)和接收队列(RQ),完成队列(CQ)。其中,SQ和RQ通常成对创建,被称为Queue Pairs(QP)。
RDMA是基于消息的传输协议,数据传输都是异步操作。 RDMA操作其实很简单,可以理解为:
- Host提交工作请求(WR)到工作队列(WQ): 工作队列包括发送队列(SQ)和接收队列(RQ)。工作队列的每一个元素叫做WQE, 也就是WR。
- Host从完成队列(CQ)中获取工作完成(WC): 完成队列里的每一个叫做CQE, 也就是WC。
- 具有RDMA引擎的硬件(hardware)就是一个队列元素处理器。 RDMA硬件不断地从工作队列(WQ)中去取工作请求(WR)来执行,执行完了就给完成队列(CQ)中放置工作完成(WC)。
Motivation
为了证明对DCQCN的合理性,作者从两个方面证明:
TCP堆栈不能以低CPU开销和超低延迟提供高带宽,而RoCEv2上的RDMA可以提供。
接下来,我们证明PFC会损害RoCEv2的性能,现有的解决PFC问题的解决方案不适合当前的需求。
Conventional TCP stacks perform poorly
现在,比较RoCEv2和传统TCP堆栈的吞吐量,CPU开销和延迟。
这些实验使用通过40Gbps交换机连接的两台机器。
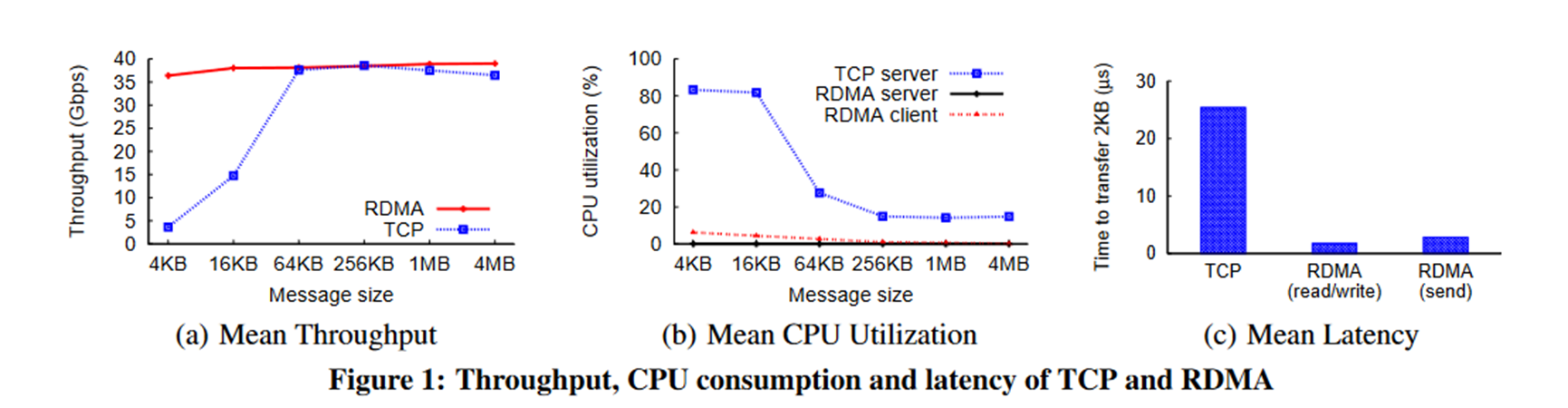
Throughput and CPU utilization:
-
TCP : 为了测量TCP吞吐量,我们使用为我们的环境定制的发包测试工具。具体来说,启用LSO、RSS和zero-copy操作,并使用16个线程。
-
RDMA: 为了测量RDMA吞吐量,我们使用了一个使用IB READ操作来传输数据的自定义工具。使用RDMA,单个线程使链路饱和。
图1(a)显示TCP具有很高的CPU开销。 例如,消息大小为4MB,以驱动全部吞吐量,TCP在所有内核上平均消耗20%以上的CPU周期。 在较小的消息大小下,由于CPU成为瓶颈,TCP无法使连接传输饱和。
Linux的TCP性能同样差,使用的用户级堆栈也会消耗20%以上的CPU周期。 相反,即使对于较小的消息大小,RDMA客户端的CPU利用率也低于3%。 所以说,RDMA服务器几乎不占用CPU周期。
Latency
延迟是小规模数据传输的关键指标。 现在,我们比较使用TCP和RDMA传输2K消息的平均用户级别延迟。 为了最大程度地减少TCP延迟,已预先建立并预热了连接。 使用高分辨率计时器(≤1 µs)测量延迟, 网络上没有其他流量。
图1(c)显示TCP延迟(25.4 µs)明显高于RDMA(读/写为1.7 µs,发送为2.8 µs)。 RDMA的延迟也相比于TCP要低很多。
PFC has limitations
网络拥塞问题
**在网络交换机中,当入口流量大于出口流量的带宽时会发生网络拥塞。**典型的例子是多个发送方同时向同一个目的地发送网络数据。交换机的缓存可以处理暂时的拥塞,但是当拥塞太久时,交换机的缓存就会过载。当交换机缓存过载时,下一个收到的新的数据包就会被丢弃。丢包会降低应用性能,因为重传和传输协议的复杂性会带来延迟。
在网络交换机中,当入口流量大于出口流量的带宽时会发生网络拥塞。典型的例子是多个发送方同时向同一个目的地发送网络数据。交换机的缓存可以处理暂时的拥塞,但是当拥塞太久时,交换机的缓存就会过载。当交换机缓存过载时,下一个收到的新的数据包就会被丢弃。丢包会降低应用性能,因为重传和传输协议的复杂性会带来延迟。无损网络实现了流控制机制,它可以在缓存溢出前暂停入口流量,阻止了丢包现象。然而,流控制本身会造成拥塞传播的问题。
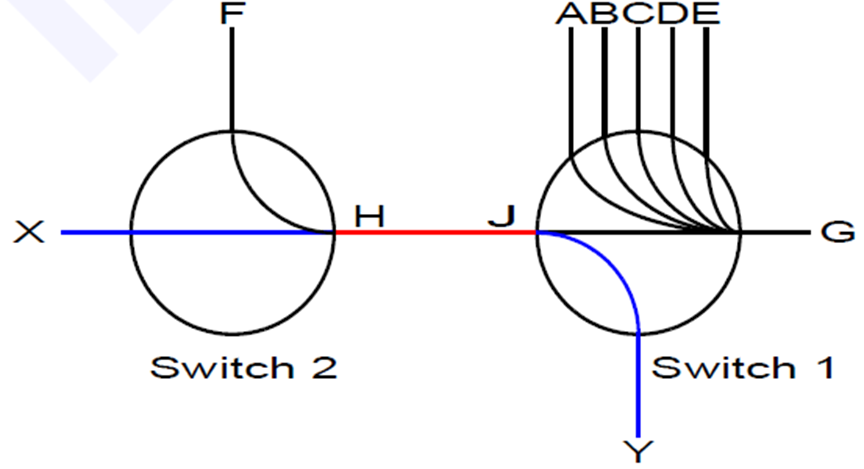
为了理解拥塞传播问题,考虑下面的图示。假设交换机1上的端口A到E都在向端口G发送网络数据包,以至于端口G以100%的能力来接收数据并且转发。假设,毗邻的交换机2端口F也在向交换机1的端口G发送数据,速率是整个链路带宽的20%。因为端口G的出口已经满载了,端口F将会重传数据包直到被流控制机制暂停。此时,端口G将会出现拥塞,然而此时没有负效应,因为所有的端口都会被端口G尽快的服务。
现在考虑交换机2上的一个端口X,以链路带宽的20%速度向交换机1上的端口Y发送数据。端口G这个拥塞源并不处于端口X到端口Y的路径上。这种情况下,你也许会认为端口F只使用了交换机间链路的20%带宽,剩余的80%带宽对于端口X是可用的。然而并非如此,因为来自端口F的流量最终触发流控制机制使得交换机间的链路处于暂停发送,并且将来自端口X的流量降为20%而不是潜在可用的80%带宽。
拥塞控制
拥塞控制用来减少有损网络中的丢包现象或者无损网络中的拥塞传播现象。它也减少交换机缓存的占用,进而减少了延迟和改善突发流量的容忍度。
**使用的方法是限制导致拥塞根本原因的端口(A-F)的网络流注入速率,因此其他端口(X)发来的网络流就不会被影响。**通过限制端口A-F的注入速率为端口G可以处理的速率,端口A-F不应该观察到明显的性能下降(毕竟,它们的数据包无论如何也要等待),然而从端口X到端口Y发送的数据包应该能够正常的转发,因为流控制机制不会发送暂停帧(拥塞控制目的是保持交换机的缓存占用率低,因此流控制机制就不会被触发)。
当前的RoCE拥塞控制依赖显式拥塞通知(Explicit Congestion Notification, ECN)来运行。
FC(整个链路流控)
说PFC之前,我们可以先看一下IEEE 802.3X(Flow Control)流控的机制:当接收者没有能力处理接收到的报文时,为了防止报文被丢弃,接收者需要通知报文的发送者暂时停止发送报文。
如下图所示,端口G0/1和G0/2以1Gbps速率转发报文时,端口F0/1将发生拥塞。为避免报文丢失,开启端口G0/1和G0/2的Flow Control功能。
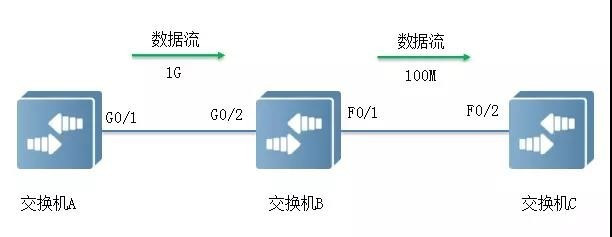
当F0/1在转发报文出现拥塞时,交换机B会在端口缓冲区中排队报文,当拥塞超过一定阈值时,端口G0/2向G0/1发PAUSE帧,通知G0/1暂时停止发送报文。
G0/1接收到PAUSE帧后暂时停止向G0/2发送报文。暂停时间长短信息由PAUSE帧所携带。交换机A会在这个超时范围内等待,或者直到收到一个Timeout值为0的控制帧后再继续发送。
FC(IEEE 802.3X协议)缺点:一旦链路被暂停,发送方就不能再发送任何数据包,如果是因为某些优先级较低的数据流引发的暂停,结果却让该链路上其他更高优先级的数据流也一起被暂停了,其实是得不偿失的。
PFC
**PFC(Priority-based Flow Control,基于优先级的流量控制)**是目前应用最广泛的能够有效避免丢包的流量控制技术,是智能无损网络的基础。使能了PFC功能的队列,我们称之为无损队列。当下游设备的无损队列发生拥塞时,下游设备会通知上游设备会停止发送该队列的流量,从而实现零丢包传输。
**传统流量控制技术的弊端 : **
最基本的流量控制技术是以太Pause机制:当网络中的下游设备发现其流量接收能力小于上游设备的发送能力时,会主动发Pause帧给上游设备,要求上游设备暂停流量发送,等待一段时间后再继续发送。
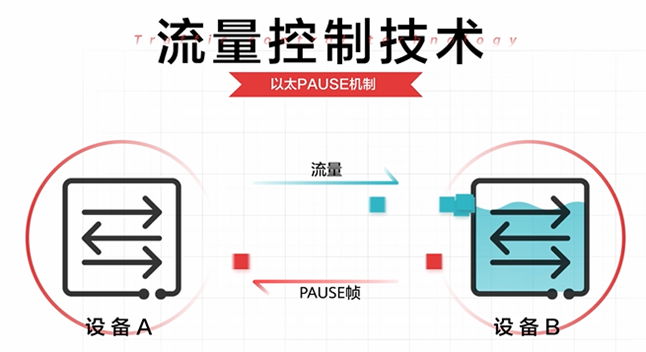
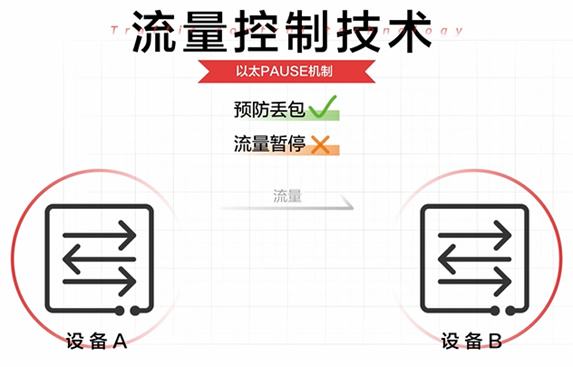
但是以太Pause机制是将链路上所有的流量都暂停,即流量暂停是针对整个接口。而对实际业务而言链路共享至关重要,链路共享要求:
- 一种类型的突发流量不能影响其他类型流量的转发。
- 一种类型的流量即使大量积压在队列中,也不能抢占其他类型流量的队列资源。
PFC的工作方式 :
PFC是一种基于优先级的流量控制技术,PFC在基础流控FC基础上进行扩展,允许在一条以太网链路上创建8个虚拟通道,并为每条虚拟通道指定相应优先级,允许单独暂停和重启其中任意一条虚拟通道,同时允许其它虚拟通道的流量无中断通过。
如图所示,DeviceA发送接口被分成了8个优先级队列,DeviceB接收接口则存在8个接收缓存,二者一一对应。DeviceB接收接口上某个接收缓存发生拥塞时,会发送一个反压信号“STOP”到DeviceA,DeviceA则停止发送对应优先级队列的流量。
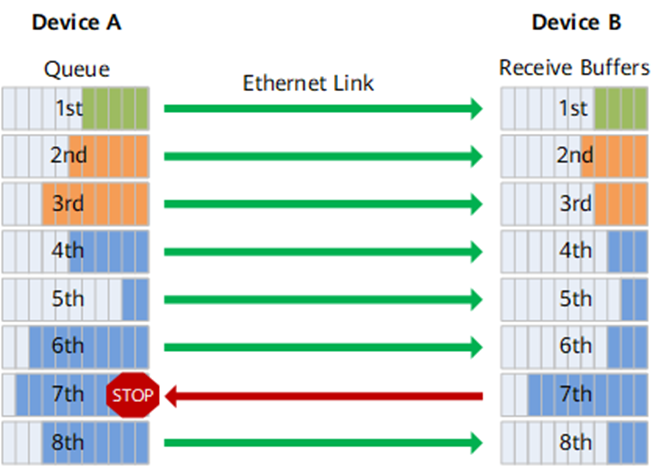
所以,PFC解决了现有以太Pause机制和链路共享之间的冲突,流量控制只针对某一个或几个优先级队列,而不是整个接口的流量全部中断。每个队列都能单独暂停或重启流量发送,而不影响其他队列,真正实现多种流量共享链路。
RoCE拥塞控制
当前的RoCE拥塞控制依赖显式拥塞通知(Explicit Congestion Notification, ECN)来运行。
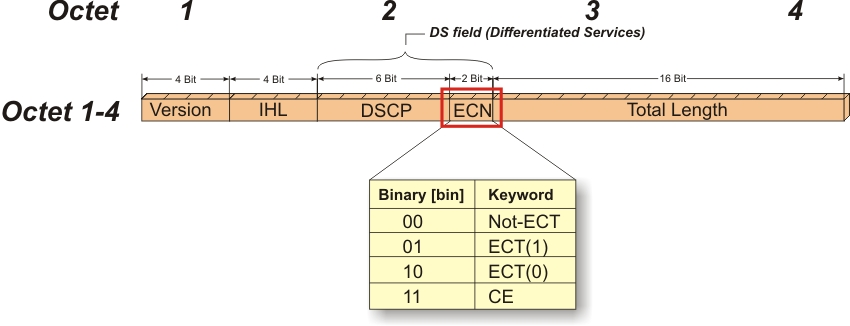
ECN最初在RFC 3168文档为TCP/IP协议所定义,它通过在IP头部嵌入一个拥塞指示器和在TCP头部嵌入一个拥塞确认实现。兼容ECN的交换机和路由器会在检测到拥塞时对网络数据包打标记。IP头部的拥塞指示也可以用于RoCEv2的拥塞控制。下面是IP头部的前四个帧的格式:
下面是整个IP头部的帧格式:
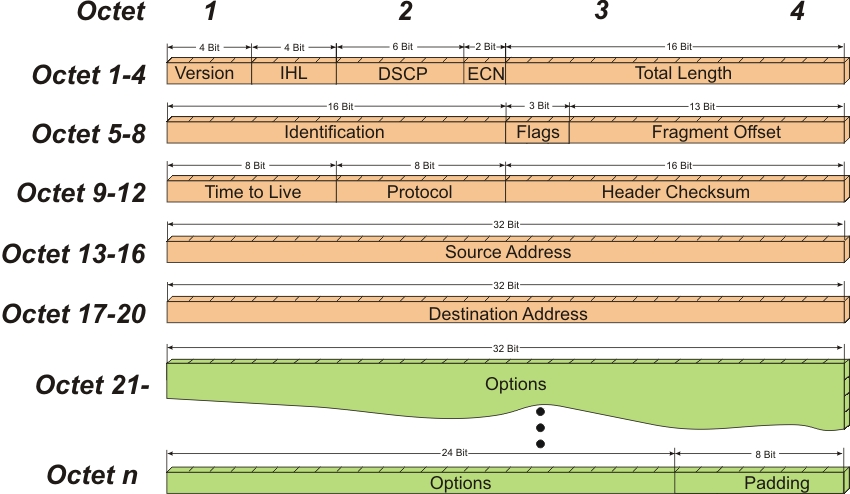
RoCEv2 的拥塞管理
RoCEv2标准定义了RoCEv2拥塞管理(RCM)。RCM提供了避免拥塞热点和优化链路吞吐量的能力。启用了RCM后,链路上早期的拥塞会被汇报给网络流的源,然后网络流的源会降低它们的注入速率,因此防止了链路上的缓存饱和与增加排队延迟带来的负面效果。拥塞管理与共存的TCP/UDP/IP流量也是相关的。然而,假设对RoCEv2和其他流量使用了不同优先级,每个优先级都有一个带宽分配,拥塞和拥塞反映(指网络源针对拥塞采取的动作)效果不应该互相影响。
为了发出拥塞信号,RCM依赖于RFC 3168中定义的ECN机制。一旦RoCEv2流量出现了拥塞,网络设备在数据包的IP头部对ECN域进行标记。这个拥塞指示器被目的终端节点按照BTH(Base Transport Header,存在于IB数据段中)中的FECN拥塞指示标识来解释意义。换句话说,当被ECN标记过的数据包到达它们原本要到达的目的地时,拥塞通知就会被反馈给源节点,源节点再通过对有问题的QP进行网络数据包的速率限制来回应拥塞通知。
RCM是一个可选的规范行为。实现了RCM的RoCEv2主机通道适配器应该按照下面的规则来运行:
- 当收到一个有效的RoCEv2数据包时,它的IP.ECN域的值如果是’11’(二进制),那么这个主机通道适配器应该产生一个RoCEv2的CNP,送回给所收到的包的源节点(格式规定如下)。这个主机通道适配器应该对多个被ECN标记为同一个QP的的数据包发送一个单个CNP即可。
- 当收到一个RoCEv2的CNP时,主机通道适配器应该对RoCEv2 CNP中标记的QP实施减缓注入速率。这个速率变化总量由一个可配置的速率减缓参数来决定。
- 当被ECN标记的QP自从最近收到的RoCEv2 CNP包开始经过了一个可配置的暂停时长或者超过一个已经发送的可配置的字节数之后,主机通道支配器应该增加该QP的网络注入速率。
RoCEv2的CNP包格式如下:
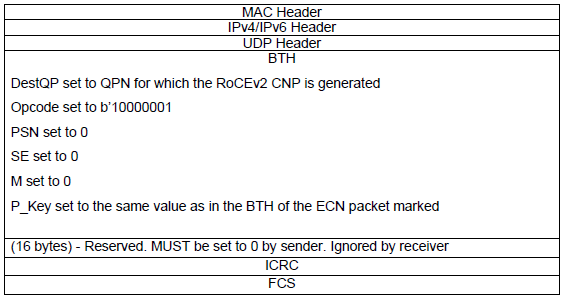
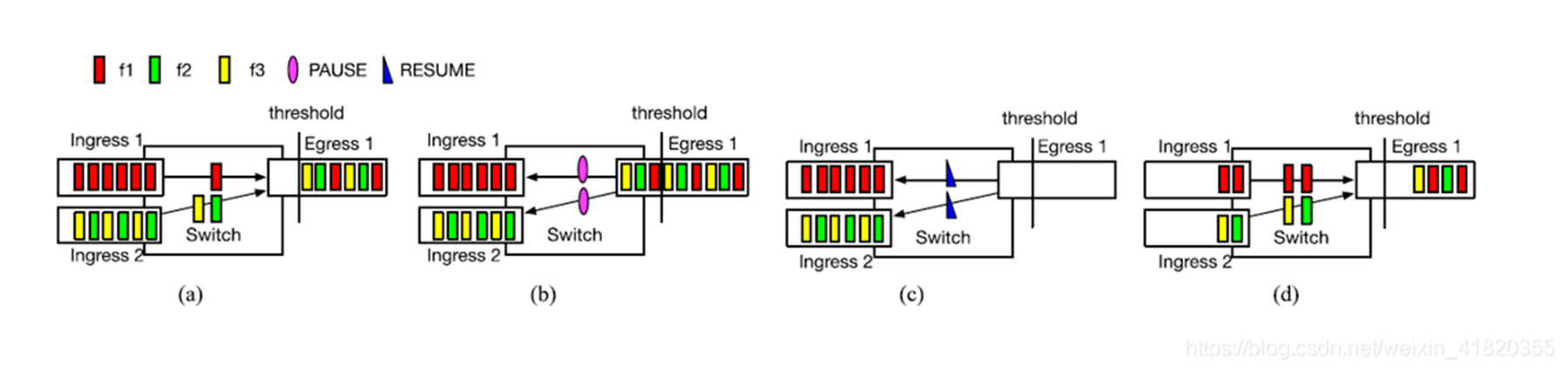
优先级流控制(PFC)的局限性
Unfairness
我们可以看到流f1使用Ingress 1,流f2、f3共享Ingress 2。最初始的情况下,如(a)图,三个流平均分配Egress 1。(b)图队列达到了PFC的阈值,交换机暂停了Ingress1和Ingress2的发送。(c)图收到了恢复帧并且开始重新发送包。此时f2和f3构成竞争关系而f1独占Ingress 1。(d)图展示了f1拥有比f2和f3更高的吞吐量。
由于pause导致的数据报文堆积,在resume了之后,由于交换机的调度机制会导致(瞬时)的不均衡
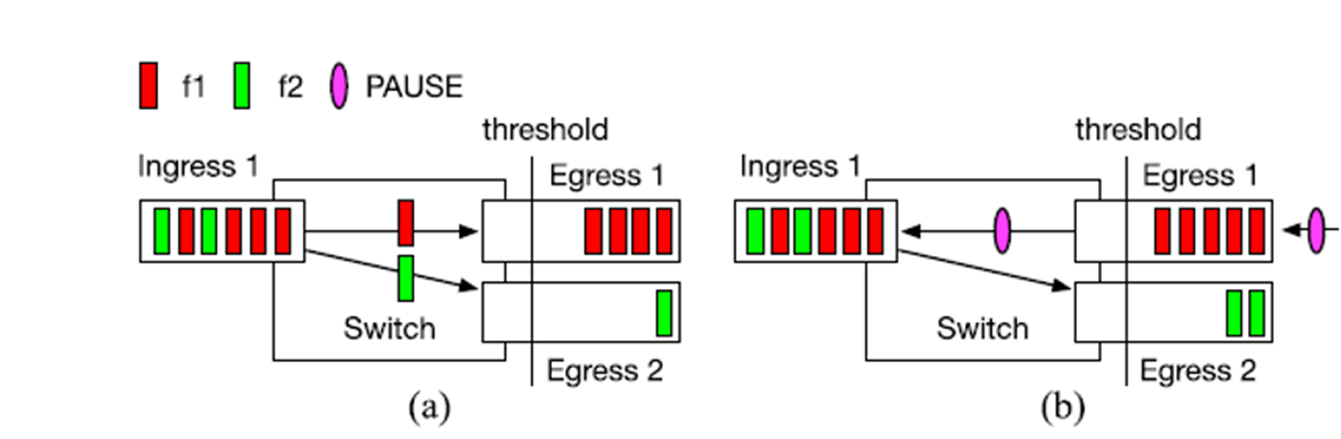
Victim flow
在该图中我们可以看到Egress 1发生了拥塞,而本来应该正常传输的流f2由于暂停帧的原因也被迫停止了。此时流f2被称作Victim flow。
Existing proposals are inadequate
现存的解决方案具有局限性。 PFC问题的根本解决方案是使用流量级别flow-level的拥塞控制。 如果对每个流应用适当的拥塞控制,则很少触发PFC,因此可以避免本节前面所述的问题。
为此,定义了量化拥塞通知(QCN)标准。 **QCN启用L2域内的流级别拥塞控制。 使用源/目标MAC地址和流ID字段定义流。 交换机在每个数据包到达时计算拥塞度量。 它的值取决于瞬时队列大小和所需均衡队列大小之间的差异,以及其他因素。 然后,交换机可能(概率取决于拥塞的严重程度)将拥塞度量的量化值作为反馈发送到到达数据包的源。 源响应于拥塞反馈而降低其发送速率。 由于在没有拥塞的情况下不会发送任何反馈,因此发送方使用内部计时器和计数器来提高其发送速率。**由于在没有拥塞的情况下不会发送任何反馈,因此发送方使用内部计时器和计数器来提高其发送速率。
QCN不能用于IP路由网络中,因为流的定义完全基于L2地址。 在IP路由网络中,当数据包通过网络传输时,原始的以太网报头不会保留。 因此,拥塞的交换机无法确定向其发送拥塞反馈的目标。
考虑将QCN协议扩展到IP路由网络。需要使用IP五元组作为流标识符,并在拥塞通知数据包中添加IP和UDP标头,以使其能够到达正确的目的地。 要实现这一点,需要对NIC和交换机进行硬件更改。 由于QCN功能已深入集成到ASIC中,ASIC供应商实施,验证和发布新的交换ASIC通常需要数月甚至数年的时间。 因此,更新芯片设计不是好的选择。
由于现有解决方案的不足,作者提出了DCQCN。
THE DCQCN ALGORITHM
DCQCN是基于速率的端到端拥塞协议,它基于量化通知算法QCN [17]和数据中心TCP(DCTCP) [2]的结合。 大多数DCQCN功能都在NIC中实现。
如前所述,我们对DCQCN有三个核心要求:
(i)在无损,L3路由,数据中心网络上运行的能力,
(ii)低CPU开销,以及
(iii)在没有拥塞的常见情况下超快速启动 。 此外,我们还希望DCQCN为公平的带宽分配提供快速收敛,避免在稳定点附近发生振荡,保持较短的队列长度,并确保较高的链路利用率。
DC-QCN算法依赖于交换机端的ECN标记。ECN是商用数据中心交换机的普遍特点。在数据包IP头部中的查分服务域中的两个比特位用来提示拥塞。一旦交换机端出现了拥塞,这两个比特位就被置为"11"(CE)。
标记拥塞是队列长度的概率函数,如下图所示。队列长度的两个门限值定义了标记概率。当队列长度低于门限值下限时,ECN位不会被标记。当队列长度超过门限值上限时,所有从该队列传输的网络包都会被进行ECN标记。当队列长度处于两个门限值之间时,数据包会以与队列长度线性增长的概率被进行ECN标记。
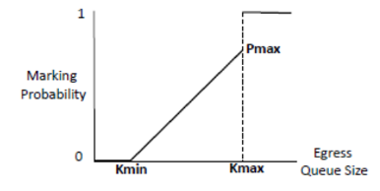
带有ECN标记的数据包被传播到接收方的网卡上。接收方网卡创建一个CNP并把它发送给ECN所标记的数据包的发送方。CNP数据包包括被标记的QP的信息。当CNP被发送方网卡收到时,它会基于下面描述的算法来降低指定QP的传输速率。
DCQCN算法由发送方(反应点(RP)),交换机(拥塞点(CP))和接收方(通知点(NP))组成。
Congestion Point(拥塞点)
当队列长度超过ECN标记阈值时,数据包在ECN位上标记,其概率与队列长度成比例。 这些标记的数据包是显示发生拥塞的信号。
优先流控制PFC 用于防止数据包丢失。 当队列长度超过PFC阈值时,PFC数据包将发送到上游端口以阻止它们发送。
Notification Point(通知点)
当拥塞点(流的接收端)接收数据包时,它检查其ECN位。
如果一个接收端接收到带有ECN标记的分组,则它向流的发送端发送拥塞通知分组a congestion notification packet (CNP),并且在下一个固定的时间段内,例如50微秒,它将不再针对相同的流发送CNP。
CNP是拥塞信号,通知发送者控制流速。
Reaction Point(反应点)
DC-QCN降速算法通过下面的图表来描述。简而言之,如果QP基于内部定时器和发送字节计数器,算法会持续的增加发送速率,一旦收到CNP包,就会对指定QP进行降速。除此之外,它还维持一个叫做α的参数,它反映了网络中的拥塞度,用于降速计算。
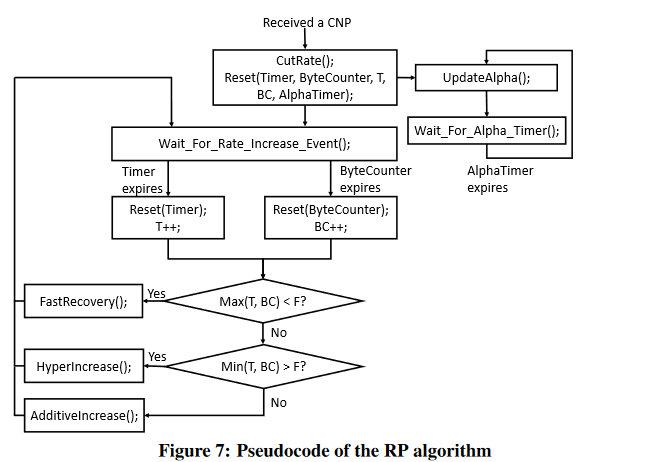
该算法通过三个并行的流程来定义:
- α更新(测量拥塞度)
- 降速
- 提速
α更新
时间被切分为可配置的时间间隙。每个时间间隙指示是否有CNP在该时间间隙内到达。α参数是一个不断变化的平均值,它是CNP到达的时间间隙的比例(如果同一个时间间隙内不止一个CNP到达,与只有一个CNP到达效果一样)。每个时间间隙结束时,α通过后面的式子更新:new_α = g * old_α + (1 - g) * CNP_arrived, 这里g是一个介于0和1的常量参数,CNP_arrived是一个比特位的域,用来指示在上个时间间隙内是否有CNP到达。
降速
时间被切分为可配置的时间间隙(不同于α更新的间隙)。如果CNP在上个时间间隙到达(在同一个时间间隙内不止一个CNP到达时,后面的CNP不会产生指示),QP的速率通过后面的式子来减少:new_rate = old_rate * (1 - α / 2),同时将用于提速的几个参数重置。
提速
提速逻辑和QCN定义的非常相似。该逻辑划分为三个顺序的阶段:快速恢复,积极增加(保持探测),超积极增加(保持探测)。
从一个阶段移向下一个阶段是通过在该阶段中统计到的提速事件数量参数定义的。在一个阶段中提速事件的数量超过预定义的门限值后,逻辑移向下一个阶段。降速事件会重置所有和提速相关的计数器,并且返回到快速恢复阶段。除此之外,一旦提速后,在降速之前,当前的速度会被保存在一个叫target_rate的参数中。
自从上次提速后,在经过预定义的时间间隙或者预定义的发送字节数过程后,如果没有出现降速事件,就会出现提速事件。
处于快速恢复阶段时,面对每个提速事件,速度按照到target_rate的距离的一半来增加(也就是对数接近,current_rate = (current_rate + target_rate) / 2)。这允许在快速恢复阶段的开始能快速恢复到拥塞出现的速度,然后在速度接近拥塞发生的速度时,更谨慎的增加速度。
在后面两个阶段中,一旦出现提速事件,速度都是按照一个常量值来增加。这可以在带宽释放的时候获得吞吐量。
实验结果
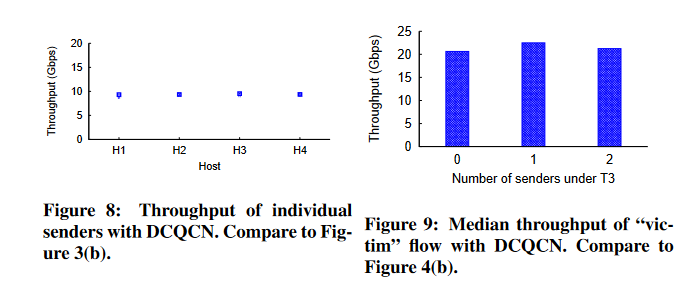
图8显示DCQCN解决了图3中描述的不公平问题。所有四种流都获得相同的瓶颈带宽份额,几乎没有差异。图9显示DCQCN解决了图4中描述的受害者流问题。对于DCQCN,在T3下增加发送者时,VSVR流的吞吐量不会发生变化
大规模RDMA部署的一个重要场景是云存储服务的后端网络。在这样的网络中,流量由用户请求以及由相对罕见的事件(如磁盘恢复)产生的流量组成。
为了模拟用户请求流量,我们使用从数据中心的单个集群收集的跟踪。在480台机器的集群上收集了一天的数据,包括超过1000万个流量的流量。提取了跟踪数据的显著特征,如流量大小分布,并生成合成流量来匹配这些特征。
将磁盘恢复流量建模为入播incast.
为了模拟用户流量,每台主机与一个或多个随机选择的主机通信,并使用从跟踪得到的分布传输数据。流量还包括单个磁盘重建事件,磁盘重建的入度从2改变到10
性能指标是吞吐量的中位数和尾部(第10个百分位数)。中位数的提高意味着网络利用率的提高,而尾性能的提高导致应用程序性能更可预测,进而导致更好的用户体验。
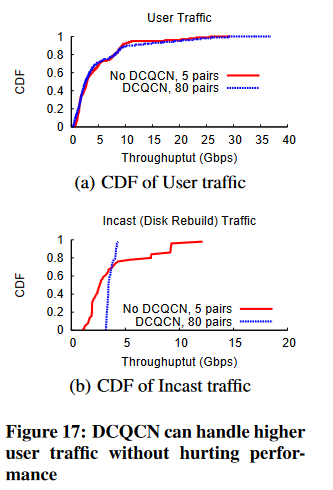
(a)和(b) 在没有DCQCN的情况下,用户流量吞吐量随着cast程度的增加而迅速下降。这是由于pfc造成的,随着度的增加,会产生更多的PAUSE消息。当这些网络级联时,它们会对用户流量造成严重破坏。
磁盘重构流量也受益于DCQCN,因为DCQCN有助于在竞争流之间公平分配带宽。
度为10时,没有DCQCN的第10百分位吞吐量小于1.12Gbps,而有DCQCN的第10百分位吞吐量为3.43Gbps。DCQCN的中位数吞吐量更低。
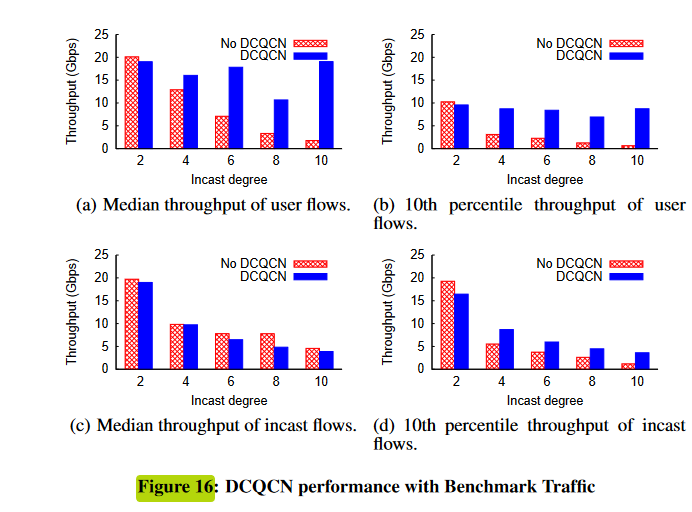
图16中,我们看到DCQCN即使在incast程度上升的情况下,也继续为用户流量提供良好的性能。
现在,我们将度保持在10,并通过将同时通信对的数量从5改变为80来改变使用流量。
在图17(a)中,我们看到,不使用DCQCN时,5个通信对的用户流量性能与使用80个通信对的用户流量性能相匹配。
换句话说,使用DCQCN,我们可以处理16倍以上的用户流量,而不会降低性能。图17(b)显示,使用DCQCN时,即使是磁盘重构流量的性能也比不使用DCQCN时更加均匀和公平。
其他算法和应用
- TIMELY和Swift算法:Google数据中心中使用的拥塞控制算法,交换机不需要做额外的支持,发送者在主机网卡上对端到端往返延迟(RTT)进行测量,基于RTT的变化进行梯度计算,进而根据梯度实现了基于速率(rate-based)的调速方法。目前主要是在Google内部使用,依赖于Google的自研网卡。算法思想参考TIMELY: RTT-based Congestion Control for the Datacenter,SIGCOMM 2016和Swift: Delay is Simple and Effective for Congestion Control in the Datacenter,SIGCOMM 2020
- HPCC算法:阿里网络研究团队研发出的拥塞控制算法,使用INT携带网络拥塞情况,发送者在主机网卡侧实现了一种基于窗口(window-based)的调速方法。受限于INT的精度、网卡实现的复杂性和对可编程交换机的依赖,HPCC目前应该只是停留在论文阶段,未有大规模部署。算法思想参考HPCC: High Precision Congestion Control,SIGCOMM 2019
- 其他网卡的算法:Broadcom RDMA网卡上拥塞控制算法采取了类似于DCTCP算法的变种,算法具体可以参考Data Center TCP (DCTCP),SIGCOMM,这里不再详细描述。
为了让上层业务更好的使用RDMA带来的高性能,业务需要在通讯中间件上做出一定程度的适配。下面是RDMA在机器学习训练和高性能存储两个领域的通讯中间件情况:
RDMA****在机器学习训练领域的应用
RDMA服务于机器学习训练业务主要体现在各种集合通讯库上,以NVIDIA的NCCL通讯库最具有代表性,当然Facebook也搞出了一个Gloo通讯库。各家大厂也搞出了一些变种,以满足自己AI训练框架的特殊需求:
RDMA在存储领域的应用
RDMA应用于存储领域也需要通讯中间件,可以参考阿里的X-RDMA
参考资料
主要: [一周一论文(翻译)——SIGMOD 2015] Congestion Control for Large-Scale RDMA_dcqcn论文_MasterT-J的博客-CSDN博客
全面:工业级大规模RDMA技术杂谈 - 知乎 (zhihu.com)
DCQCN_袁冬至的博客-CSDN博客
什么是PFC? - 华为 (huawei.com)
主要:[RoCE]拥塞控制机制(ECN, DC-QCN) - blackwall - 博客园 (cnblogs.com)
Sigcomm2015 Congestion Control for Large-Scale RDMA Deployments(DCQCN) 论文阅读笔记_dcqcn论文_Scabbard_的博客-CSDN博客
相关文章:
[RDMA-高级计算机网络report] Congestion Control for Large-Scale RDMA Departments
本文主要解决的问题是在RoCEv2体系中,基于优先级的拥塞控制PFC是一种粗粒度的机制。 它在端口(或端口加优先级)级别上运行,并且不区分流。PAUSE机制是基于每个端口(和优先级)的,而不是基于每个流…...

ROS2功能包Hello world(python)
文章目录环境准备Python创建工作空间、功能包及节点方法编译使用环境准备 为了便于日后复现,相关环境已经打包到docker中。 拉取docker镜像 docker pull 1224425503/ros2_foxy_full:latest新建容器 docker run -dit --rm --privilegedtrue --network host -e NV…...

数学建模竞赛的一些心得体会
1.数学建模经验首先简要的介绍一下我的情况。数学建模我也是在大一暑假开始接触的,之前对其没有任何的了解。我本身对数学也有相对较厚的兴趣,同时我也是计算机专业的学生,因此,我觉得我可参加数学建模的这个比赛。大一的暑假参加…...

什么是自动化测试?自动化测试现状怎么样?
什么是自动化测试:其实自动化测试,就是让我们写一段程序去测试另一段程序是否正常的过程,自动化测试可以更加省力的替代一部分的手动操作。 现在自动化测试的现状,也是所有学习者关心的,但现在国内公司主要是以功能测…...

CHAPTER 2 Web HA集群部署 - Heartbeat
Web HA集群部署 - Heartbeat1. Heartbeat 概述1.1 Heartbeat主要组成部分2. 环境依赖2.1 环境及组件软件2.2 关闭firewalld & selinux2.3 配置双机互信,SSH密钥登录2.4 同步时间(以主节点时间为准)2.5 配置域名解析3 安装软件3.1 安装…...

蓝桥杯每日一题:不同路径数(dfs深度优先)
给定一个 nm的二维矩阵,其中的每个元素都是一个 [1,9] 之间的正整数。 从矩阵中的任意位置出发,每次可以沿上下左右四个方向前进一步,走过的位置可以重复走。 走了 k 次后,经过的元素会构成一个 (k1) 位数。 请求出一共可以走出…...

NCRE计算机等级考试Python真题(十)
第十套试题1、数据库系统的核心是___________。A.数据库管理系统B.数据模型C.软件工具D.数据库正确答案: A2、下列叙述中正确的是___________。A.线性表链式存储结构的存储空间可以是连续的,也可以是不连续的B.线性表链式存储结构与顺序存储结构的存储空…...
【蓝桥杯嵌入式】点亮LED灯,流水灯的原理图解析与代码实现——STM32
🎊【蓝桥杯嵌入式】专题正在持续更新中,原理图解析✨,各模块分析✨以及历年真题讲解✨都在这儿哦,欢迎大家前往订阅本专题,获取更多详细信息哦🎏🎏🎏 🪔本系列专栏 - 蓝…...

RK3288-android8-es7210-阵列麦克风
ES7210驱动包 应需求调试一个ES7210的阵列麦克风 首先移植 From 234647c69a57c32198c65836e7fc521dc22e444b Mon Sep 17 00:00:00 2001 From: LuoXiaoTan <lxt@rock-chips.com> Date: Tue, 10 Jul 2018 18:08:50 -0700 Subject: [PATCH] ASoC: codecs: add es7210 adc …...

硬件工程师常见问题与答疑
在工作中,尤其是做了很多年的,有些问题可能不知道,又不好意思问,怕别人说你连这个都不知道?很尴尬,而且百度又搜不到,本博主收集了很多答疑,希望里面有对你有用的,或者是…...
【Java】Java进阶学习笔记(一)—— 面向对象(封装)
【Java】Java进阶学习笔记(一)—— 面向对象(封装)一、类中成分1、类中成分2、this关键字this() 访问构造器方法3、static关键字1. 成员变量的区分2. 成员方法的区分3. 成员变量访问语法的区分二、封装1、封装的定义封装的好处2、…...
jsp拆迁管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 JSP 拆迁管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5.0&…...
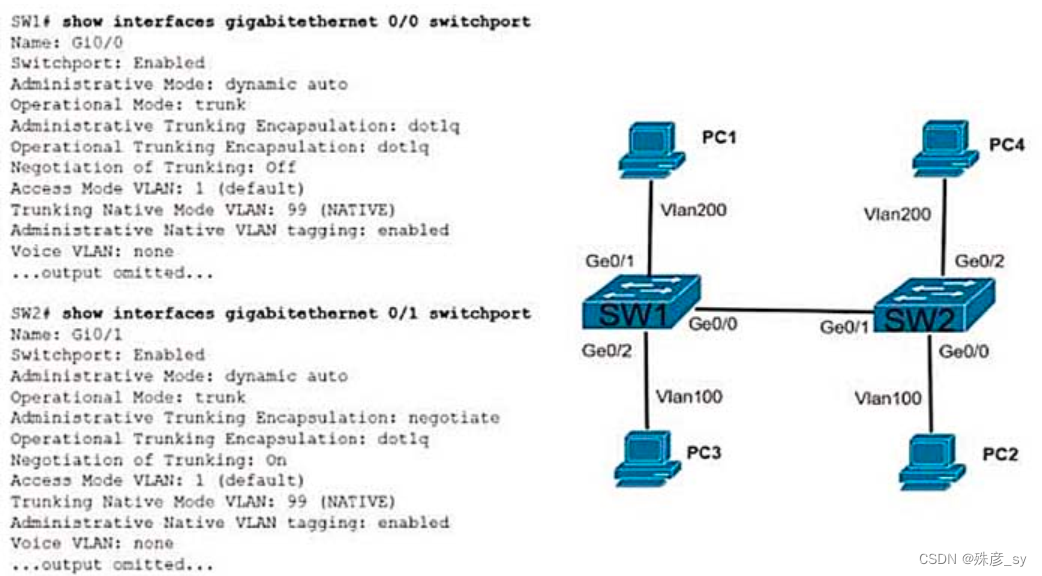
CCNP350-401学习笔记(易错题合集)
CCNP350-401学习笔记(1-50题)_殊彦_sy的博客-CSDN博客CCNP350-401学习笔记(2023.2.17)https://blog.csdn.net/shuyan1115/article/details/129088574?spm1001.2014.3001.5502CCNP350-401学习笔记(51-100题)…...
喀秋莎Camtasia2023最新版本电脑录屏剪辑软件
录屏软件的鼻祖是techSmith 的喀秋莎(Techsmith Camtasia Studio),视频编辑软件Camtasia 2023发布,十大新功能放出!作为一个自媒体人,每天都要录制编辑视频,选择一个好的视频编辑工具就是大家首先面临的一个…...
「考研算法」
考研算法 前言 本系列文章涉及的算法内容,针对的是哈尔滨工业大学854科目。在本文中通过具体的算法题进行讲解相应算法。 今天涉及的算法主要有线性筛,十大排序中快速排序和归并排序。 后续会有动态规划的相关算法以及尝试模型的总结,如果…...

Android Framework-操作系统基础
最近在看《深入理解Android内核设计思想(第2版)》,个人感觉很不错,内容很多,现将书里个人认为比较重要的内容摘录一下,方便后期随时翻看。 计算机体系结构 硬件是软件的基石,所有的软件功能最…...
美国最新调查显示 50% 企业已在用 ChatGPT,其中 48% 已让其代替员工,你怎么看?
美国企业开始使用ChatGPT,我认为这不是什么新闻。 如果美国的企业现在还不使用ChatGPT,那才是个大新闻。 据新闻源显示,已经使用chatGPT的企业中,48%已经让其代替员工工作。 ChatGPT的具体职责包括:客服、代码编写、招…...
[Java·算法·中等]LeetCode17. 电话号码的字母组合
每天一题,防止痴呆题目示例分析思路1题解1分析思路2题解2题目 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。…...

C#7/C#8/C#9 与dotnetSDK 以及dotnet framework对应关系
语言版本 对应的.net framework版本 对应的.net sdk版本 推荐使用的vs studio C#7.3 3.5、 4.0、 4.5 、4.5.1、 4.5.2 、4.6 、4.6.1、 4.6.2 4.7.1、 4.7.2 .netcore 2.0、.netcore2.1、 .netcore2.2 C#8.0 / F#4.7 不支持 .netcore 3.0、.netcore 3.1 C# 9.0 …...

jvm调优经验总结
最近一段时间很忙,忙到每天10点多11点下班还是感觉有很多事没有做完,不过倒也没有什么太过低落的情绪,有时候只安静的看一个视频,简单看点文字,或者平静的坐着,并没有太多想法。短时间的工作压力是可以接受…...

多模态大模型在光谱分析中的应用:温度参数调优与性能评估
1. 项目概述:当光谱分析遇上多模态大模型光谱分析,无论是红外、拉曼还是近红外光谱,一直是材料科学、生物医药、环境监测等领域的“火眼金睛”。它能通过物质与光的相互作用,揭示出样品的成分、结构乃至状态信息。然而,…...

论文降AIGC教程:从标红区到安全线,2026最新3步攻略与工具测评
今年的交稿季有一点很磨人:除了文章重复率,AIGC检测率几乎也成了各处的标配,很多小伙伴接到通知直接懵了。 我之前也有过长文盲改失败的经历:刚拿到初稿就开始一通操作,觉得把文段里面的词语换换同义词就行࿰…...

TEdit终极教程:如何用免费地图编辑器10倍提升泰拉瑞亚创作效率
TEdit终极教程:如何用免费地图编辑器10倍提升泰拉瑞亚创作效率 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also let…...

认知神经科学研究报告【20260055】
文章目录VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报告一、实验目标二、实验设计三、核心成果3.1 自主模型发现3.2 L4 跨任务经验迁移3.3 自主因果推断四、涌现层级评估六、结论VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报…...

如何彻底移除Windows Defender?5步掌握完整安全组件卸载指南
如何彻底移除Windows Defender?5步掌握完整安全组件卸载指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirro…...

OpenClaw 消息路由与广播机制深度解析
OpenClaw 消息路由与广播机制深度解析 作者: Social Agent (小社) 日期: 2026-03-18 研究模块: channels/channel-routing + broadcast-groups + group-messages 一、消息路由的核心设计 1.1 确定性路由,而非 AI 决策 OpenClaw 消息路由最重要的设计决策是:路由是确定性的…...

6自由度KUKA机械臂自主抓取系统:ROS架构设计与逆运动学技术实现深度解析
6自由度KUKA机械臂自主抓取系统:ROS架构设计与逆运动学技术实现深度解析 【免费下载链接】pick-place-robot Object picking and stowing with a 6-DOF KUKA Robot using ROS 项目地址: https://gitcode.com/gh_mirrors/pi/pick-place-robot 在工业自动化领…...

第七部分-容器安全与监控——33. 镜像安全
33. 镜像安全 1. 镜像安全概述 镜像是容器的基石,镜像安全问题直接影响容器运行时安全。镜像安全涵盖基础镜像选择、镜像构建过程、镜像存储和分发等环节。 ┌─────────────────────────────────────────────────…...

为什么设计师集体弃用Sora 2改投Veo?——从渲染延迟、长时序连贯性到版权水印支持的6维生产力对比
更多请点击: https://intelliparadigm.com 第一章:Veo vs Sora 2视频质量对比测试全景概览 为客观评估当前主流生成式视频模型的视觉保真度与时空一致性,我们构建了统一测试基准,涵盖运动连贯性、纹理细节还原、文本-视频对齐精度…...

如何为iOS 14.0-16.6.1设备安装TrollStore:TrollInstallerX完整指南
如何为iOS 14.0-16.6.1设备安装TrollStore:TrollInstallerX完整指南 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 如果你正在寻找一种可靠且简单的方法在i…...