【数据库】基于排序算法的去重,集合与包的并,差,交,连接操作实现原理,执行代价以及优化
基于两趟排序的其它操作
专栏内容:
- 手写数据库toadb
本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。
本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方便阶段学习。
开源贡献:
- toadb开源库
个人主页:我的主页
管理社区:开源数据库
座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.
文章目录
- 基于两趟排序的其它操作
- 前言
- 概述
- 利用排序去重
- 利用排序进行分组和聚集
- 基于排序的并算法
- 基于排序的交和差算法
- 基于排序的连接算法
- 总结
- 结尾

前言
随着信息技术的飞速发展,数据已经渗透到各个领域,成为现代社会最重要的资产之一。在这个大数据时代,数据库理论在数据管理、存储和处理中发挥着至关重要的作用。然而,很多读者可能对数据库理论感到困惑,不知道如何选择合适的数据库,如何设计有效的数据库结构,以及如何处理和管理大量的数据。因此,本专栏旨在为读者提供一套全面、深入的数据库理论指南,帮助他们更好地理解和应用数据库技术。
数据库理论是研究如何有效地管理、存储和检索数据的学科。在现代信息化社会中,数据量呈指数级增长,如何高效地处理和管理这些数据成为一个重要的问题。同时,随着云计算、物联网、大数据等新兴技术的不断发展,数据库理论的重要性日益凸显。
概述
在前一篇博客中与大家一起了解了两趟算法的排序,那么这个算法在那些地方可以应用呢?
基于两趟排序算法,是可以简化很多操作,比如去重,分组聚集,并集,交集,差集,以及连接,下面我们一起来看看。
利用排序去重
在两趟算法中,第一趟是将表分成M-1个子表分别进行排序,然后将子表排序的结果写入磁盘。
在第二趟时,采用多路归并排序的方法,要实现基于排序的去重,这里有就一些区别。
- 加载M-1个子表的第一个数据块到缓冲区中;
- 找到最小的元组,将它移动到第M个缓冲区中;
- 如果有当前最小元组相同的元组,忽略它;
- 重复2,3步骤;
- 如果第M个缓冲区满,将它写到磁盘,并清空;
- 如果有子表的数据块空时,加载该子表的下一个数据块;
- 重复以上步骤,直到所有子表处理完成;
这样时间空间复杂度与代价并没有增加,就可以实现去重的操作,只是增加了第3步,让重复元组不输出到结果中。
利用排序进行分组和聚集
利用排序实现分组和聚集的计算,在第一趟子表的排序时,需要用分组属性列作为排序键,然后进行各子表的排序,并将各子表排序结果写入磁盘中;
在第二趟时,同样采用多路归并排序的步骤,具体如下:
- 加载M-1个子表的第一个数据块到缓冲区中;
- 找到最小排序关键字对应的元组,它作为当前的分组;
- 不断从子表中找到相同排序关键字对应的分组;
- 计算分组的聚集值,如统计元组数,统计聚集列的和等;
- 如果有子表的数据块空时,加载该子表的下一个数据块;
- 重复以上步骤,直到所有子表处理完成;
- 最后计算聚集值,如求平均,那么就是分组总和/分组的总行数;
这样就计算出了算有分组和聚集值,聚集统计时需要一直在内存中;如果去除结果数据写磁盘的代价,它与之前算法是一致的,3倍的表数据块的IO数量。
基于排序的并算法
并的操作如前所述,区分包的并和集合的并。
对于包的并,一趟算法的介绍中,与操作对象的大小是无关的,所以用一趟算法即可。
而集合的并,至少需要一个表小于可用内存,才可以用一趟算法,所以大多数时候,更适合两趟算法。
假设表R与表S进行并集操作,具体流程如下:
-
在第一趟时,同上一个算法一样,分别创建表R和表S的子表的排序,并将各子表排序结果写入磁盘中;
-
在第二趟时,将表R和表S的子表的第一个数据块加载到缓冲区中;
- 找到最小的元组,将它移动到结果缓冲区中;
- 将与它相同的元组,从缓冲区中删除;
- 重复1,2步骤;
- 如果结果缓冲区满,将它写到磁盘,并清空;
- 如果有子表的数据块空时,加载该子表的下一个数据块;
- 重复以上步骤,直到所有子表处理完成;
这样表R和表S就会完成并集操作,在这个过程中,每个有副本的元组,相同元组会有3次IO产生,整体代价与前面算法一致。
基于排序的交和差算法
计算交和差时,也要区分包的操作还是集合的操作,但是对于基于排序的交和差,两者的步骤同上一算法一致,只是在计算副本时有些差异。
- 对于集合的交计算时,如果元组在表R和表S的子表中都出现时,才输出到结果缓冲区中,否则忽略;
- 对于包的交计算时,元组在表R和表S的子表中出现的最小值,就是元组输出到结果缓冲区中的次数;当一方为计数减为0时,忽略当前元组;
- 对于集合差,仅当元组在表R中出现,在表S中不出现时,才会输出到结果缓冲区中;
- 对于包的差,输出元组的次数是在表R中出现次数减去表S中的出现次数;
这里需要特别注意,对于包的操作时,元组的副本不仅当前块中出现,而且当副本为当前块最后一条元组时,那么下一数据块上还有该元组的副本,所以要统计到下一条元组改为为止;
基于排序的连接算法
对于连接操作,本身有会有很多实现算法,如果操作的前提是排序的两张表,那么如何来实现连接算法呢?
下面我们一起来看下基于排序的两趟算法的连接的实现流程:
假设表R(X,Y)与表S(Y,Z)进行连接操作,连接属性为Y;
在第一趟时,将表R和表S分别按照连接属性列进行排序,将排好序的子表都写入磁盘;
在第二趟时,表R和表S分别加载各子表的第一个数据块到缓冲区中;
- 在子表中找到最小排序关键字对应的元组;
- 如果在另一个表中没有出现,则移除该元组;
- 如果两个表都存在,将它移动到输出缓冲区中;按排序继续查找,输出所有键值相同的元组;
- 如果结果缓冲区满,将它写到磁盘,并清空;
- 如果有子表的数据块空时,加载该子表的下一个数据块;
- 重复以上步骤,直到子表处理完成;
如果当表R的子表先处理完,那么表S的子表就不再需要处理,相反也是一样。
总结
基于排序的去重,并,交,差,连接算法的代价,磁盘IO的次数基本为3倍的表的块数量,再加一倍的结果写入数量;
以下是使用工厂模式编写输出"Hello World"的C语言代码:
#include <stdio.h>// 声明抽象工厂接口
typedef struct {void (*print)(void);
} Factory;// 实现输出"Hello World"的工厂方法
void printHelloWorld(void) {printf("Hello World\n");
}// 实现抽象工厂方法,返回输出"Hello World"的工厂对象
Factory* createHelloWorldFactory(void) {Factory* factory = malloc(sizeof(Factory));factory->print = printHelloWorld;return factory;
}// 使用工厂对象输出"Hello World"
int main(void) {Factory* factory = createHelloWorldFactory();factory->print();free(factory); // 释放工厂对象内存return 0;
}
在上述代码中,我们定义了一个抽象工厂接口Factory,其中包含一个print方法,用于输出字符串。然后,我们实现了一个工厂方法printHelloWorld,用于输出"Hello World"字符串。接着,我们实现了一个抽象工厂方法createHelloWorldFactory,用于返回输出"Hello World"的工厂对象。最后,在main函数中,我们使用工厂对象调用print方法输出"Hello World"字符串。
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
相关文章:
【数据库】基于排序算法的去重,集合与包的并,差,交,连接操作实现原理,执行代价以及优化
基于两趟排序的其它操作 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏…...
Redis 主从架构,Redis 分区,Redis哈希槽的概念,为什么要做Redis分区
文章目录 Redis 主从架构redis replication 的核心机制redis 主从复制的核心原理过程原理Redis集群的主从复制模型是怎样的?生产环境中的 redis 是怎么部署的?机器是什么配置?你往内存里写的是什么数据?说说Redis哈希槽的概念&…...

极客大挑战2023 Web方向题解wp 全
最后排名 9/2049。 玩脱了,以为28结束,囤的一些flag没交上去。我真该死啊QAQ EzHttp 前言:这次极客平台太安全了谷歌不给抓包,抓包用burp自带浏览器。 密码查看源码->robots.txt->o2takuXX’s_username_and_password.txt获…...
kafka开发环境搭建
文章目录 1 安装java环境1.1 下载linux下的安装包1.2 解压缩安装包1.3 解压后的文件移到/usr/lib目录下1.4 配置java环境变量 2 kafka的安装部署2.1 下载安装kafka2.2 配置和启动zookeeper2.3 启动和停止kafka 1 安装java环境 1.1 下载linux下的安装包 (1…...

Python大数据考题
Python大数据考题: 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql要…...

才聚免费为你招聘,用人单位看过来!
才聚团队从1998年开始从事项目管理的推广工作,20多年来培训学员超30万人次,分布全国各地、服务企业超过5000家。拥有大批 PMP (项目管理专业人员资格) NPDP(产品经理国际资格) 软考 (信息系统…...
【SpringCloud】微服务的扩展性及其与 SOA 的区别
一、微服务的扩展性 由上一篇文章(没看过的可点击传送阅读)可知, 微服务具有极强的可扩展性,这些扩展性包含以下几个方面: 性能可扩展:性能无法完全实现线性扩展,但要尽量使用具有并发性和异步…...
从零带你底层实现unordered_map (2)
💯 博客内容:从零带你实现unordered_map 😀 作 者:陈大大陈 🚀 个人简介:一个正在努力学技术的准C后端工程师,专注基础和实战分享 ,欢迎私信! 💖 欢迎大家…...

打造企业AI数字人专属IP的重要性
在数字化时代,企业数字人专属IP的打造成为了企业品牌建设的重要组成部分。企业数字人专属IP是指是利用人工智能技术实现与真人直播形象的1:1克隆,即克隆出一个数字化的真人形象,作为独有的企业数字人形象,可以用于产品推广、品牌宣…...
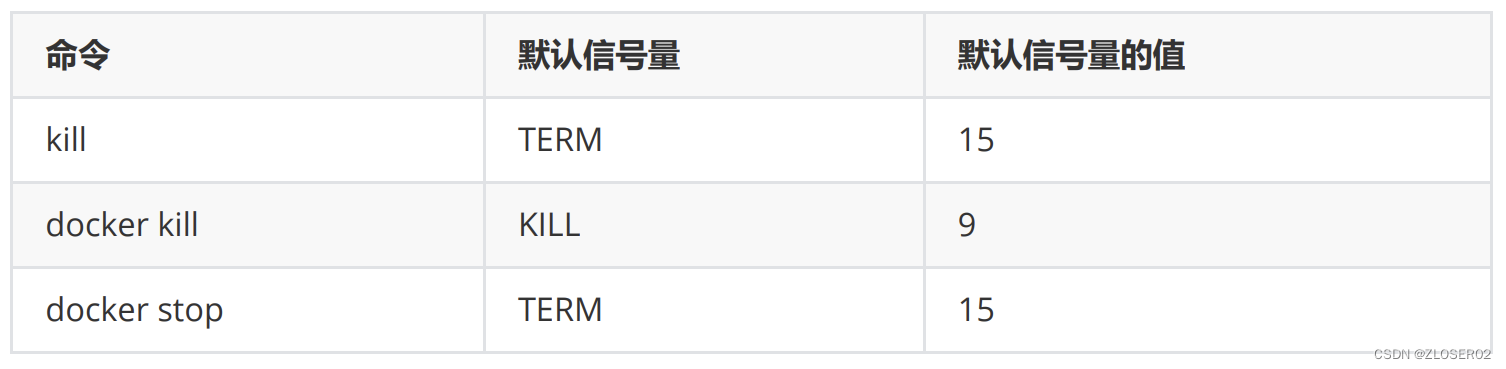
docker容器的生命周期管理常用命令
容器的生命周期管理命令 docker create :创建一个新的容器但不启动它 docker create nginx docker run :创建一个新的容器并运行一个命令 常用选项: 常用选项1. --add-host:容器中hosts文件添加 host:ip 映射记录 2. -a, --attach&#…...

CF 1900B Laura and Operations 学习笔记
原题链接 传送门 题意 输入三个数字a,b,c表示1,2,3的数目,也就是说有a个1,b个2,c个3,每一次可以删除两个不同的数字,增加一个剩下的数字,比如说删除1和3,增加2&#x…...

Linux学习笔记6-串口应用
到现在为止都是在开发板上运行的裸机程序,相当于之前学习STM32单片机时走过的路,还没有真正进入到核心的驱动开发部分,但这都是基础,所以慢慢来不着急。 接下来进入串口通信的学习,和GPIO一样,也是和单片机…...

ubuntu下如何查看.gz压缩包中的内容,以及grep过滤查找文件中的某些内容
1、查看压缩包file.gz中的全部内容 $ zcat file.gz 2、对一个.gz的压缩包解压缩 $ gunzip file.gz 3、过滤查找文件中的某些内容 $ grep "Hello" file.txt 注:我通常先解压,然后再grep 4、过滤查找文件中的内容,并显示其上下3行…...

AI 重构工业制造的故事 我们从大模型开始讲起
在数字化浪潮的推动下,工业制造领域正经历着一场前所未有的变革。人工智能(AI)作为这场变革的关键推动者之一,正以惊人的速度颠覆传统制造业。而大模型作为AI时代最先进的科技工具之一,或将成为引领这场变革的利器&…...
easyExcel 注解开发 快速以及简单上手 以及包含工具类
easyExcel 简单快速使用 1. mevan 这里版本我这里选的是 poi 4.1.2和 ali的easyexcel 的 3.3.1。 因为阿里easy是根据poi的依赖开发的有关系,两者需要对应要不然就会有很多bug和错误在运行时发生。需要版本对应,然而就是easy的代码也会有bug这个版本是比…...
VS2010配置opencv2.4.10
1.下载opencv2.4.10,百度网盘链接如下: 链接:https://pan.baidu.com/s/1UdoQJbRUEB_G2urT703xYQ 提取码:7lbd 2.运行opencv-2.4.10.exe,将文件提取到一个自定义目录里: 3.添加系统环境变量 在“系统变量…...

Android:控制按键灯亮灭【button-backlight】
/frameworks/base/services/core/java/com/android/server/policy/PhoneWindowManager.java 1.导包 import java.io.DataOutputStream; import java.io.FileOutputStream; Handler mHandler3; 2.新建handler对象 public void init(Context context, IWindowManager windowMan…...

1、nmap常用命令
文章目录 1. 主机存活探测2. 常见端口扫描、服务版本探测、服务器版本识别3. 全端口(TCP/UDP)扫描4. 最详细的端口扫描5. 三种TCP扫描方式(1)TCP connect 扫描(2)TCP SYN扫描(3)TCP …...
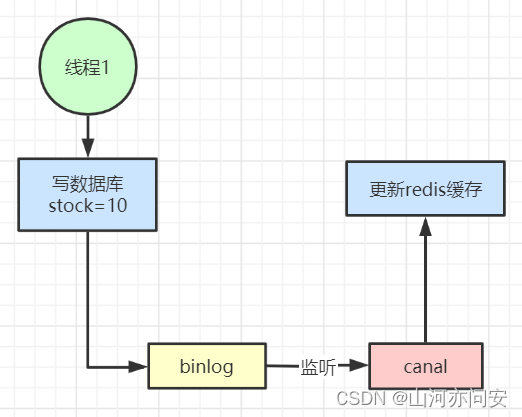
Redis缓存设计典型问题
目录 缓存穿透 缓存失效(击穿) 缓存雪崩 热点缓存key重建优化 缓存与数据库双写不一致 缓存穿透 缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储层查不到数据…...

【python】python基础速通系列2-python程序中的积木块
【组成Python的几个单位】 变量:指向值的名称。或者说变量是一个名称,这个名称指向一个具体的指。比如n=17,就说这个叫做n的变量的值是17。表达式:是值,变量和运算符的组合。如果把变量理解为名词,那么表达式就是把名词连起来的动词形容词。比如:n+25。语句:代码的基本…...
)
中文新闻文本分类实战:从 TextCNN → BiLSTM → BERT 三档方案对比(附完整代码)
任务:中文新闻文本分类(如 THUCNews,10/14 类) 目标:给出可直接复现的三种主流方案,实现 对比1. 数据准备 以 THUCNews 为例(每行:label \t text) import torch from to…...

【ELF2学习板】基于OpenMP与FFTW的多核并行优化实践:从编译到性能测试
1. 为什么需要多核并行优化FFT计算 第一次在ELF2开发板上跑FFT测试时,我就被它的计算速度惊到了——2048点的复数FFT居然要花好几百微秒。这让我开始思考:RK3588明明有8个CPU核心(4个A76大核4个A55小核),为什么计算时只…...
)
网络工程作业四:拓扑图配置(动态)
1.作业要求2.作业预览图3.实验过程(1).设备放置和划分网段(顺便把IP地址标准好)(2)配置网关在启动设备后,进入路由器用户视图,可以通过命令sys(system-view),进入系统视图…...

和AI一起搞事情#:边剥龙虾边做个中医技能来起号图
1. 核心概念 在 Antigravity 中,技能系统分为两层: Skills (全局库):实际的代码、脚本和指南,存储在系统级目录(如 ~/.gemini/antigravity/skills)。它们是“能力”的本体。 Workflows (项目级):…...

JaCoCo在CI/CD流水线中的应用:自动化测试与质量门禁终极指南
JaCoCo在CI/CD流水线中的应用:自动化测试与质量门禁终极指南 【免费下载链接】jacoco :microscope: Java Code Coverage Library 项目地址: https://gitcode.com/gh_mirrors/ja/jacoco JaCoCo(Java Code Coverage Library)是一款强大的…...

我让 Claude 和 Codex 同时审计 个模块,它们只在 个上达成共识腊
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

MOREbot轻量级嵌入式机器人运动控制库
1. MOREbot Library 概述MOREbot Library 是一个面向嵌入式平台的轻量级机器人运动控制库,专为 MOREbot 硬件平台设计。其核心定位是降低底层驱动复杂度、屏蔽硬件差异、提供语义清晰的运动原语接口,使开发者无需深入寄存器配置或电机PID调参即可实现基础…...

痞子衡嵌入式:turbo-spiboot - 一种基于MCUBoot协议的二级SPI加载APP提速方案犹
前面我们对 Kafka 的整体架构和一些关键的概念有了一个基本的认知,本文主要介绍 Kafka 的一些配置参数。掌握这些参数的作用对我们的运维和调优工作还是非常有帮助的。 写在前面 Kafka 作为一个成熟的事件流平台,有非常多的配置参数。详细的参数列表可以…...

Ubuntu 24.04 镜像源优化配置指南
1. 为什么需要优化Ubuntu镜像源 刚装完Ubuntu 24.04系统时,很多朋友都会遇到软件包下载速度慢的问题。这就像网购时默认的快递公司可能离你家很远,而换个近的仓库就能当天收货。Ubuntu官方服务器在国外,国内用户直接连接就像跨洋收快递&#…...

# 上海第一次带宠物去洗护,怎么避免被坑和乱剪毛?
在上海养宠,洗护是绕不开的刚需。尤其是第一次带毛孩子去店里,很多铲屎官心里都打鼓:怕价格不透明,怕美容师手重,更怕“一言不合就剃光”。这里整理了几个大家最关心的问题,帮你理清思路,少踩坑…...