大数据平台/大数据技术与原理-实验报告--部署全分布模式HBase集群和实战HBase
| 实验名称 | 部署全分布模式HBase集群和实战HBase | ||
| 实验性质 (必修、选修) | 必修 | 实验类型(验证、设计、创新、综合) | 综合 |
| 实验课时 | 2 | 实验日期 | 2023.11.07-2023.11.10 |
| 实验仪器设备以及实验软硬件要求 | 专业实验室(配有centos7.5系统的linux虚拟机三台) | ||
| 实验目的 | 1. 理解HBase数据模型。 2. 理解HBase体系架构。 3. 熟练掌握HBase集群的部署。 4. 了解HBase Web UI的使用。 5. 熟练掌握HBase Shell常用命令的使用。 6. 了解HBase Java API,能编写简单的HBase程序。 | ||
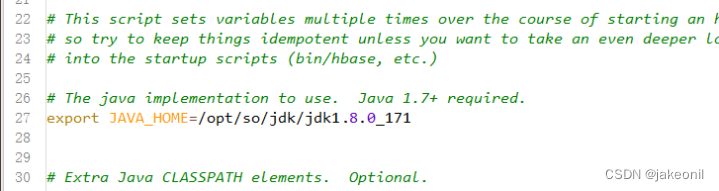
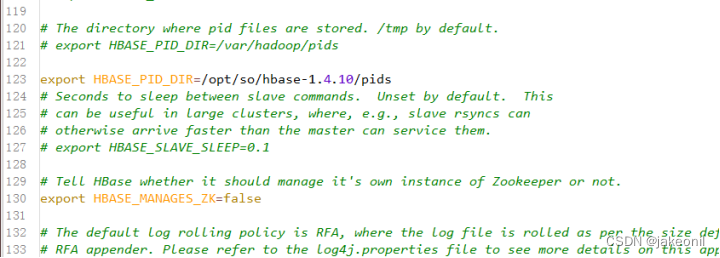
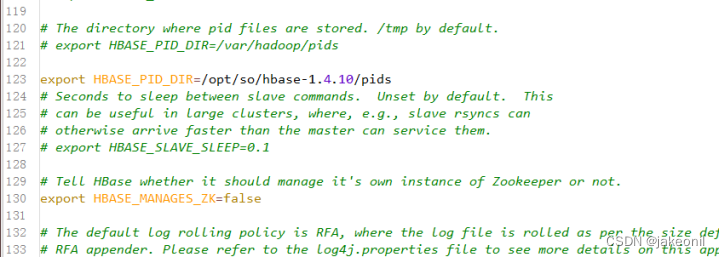
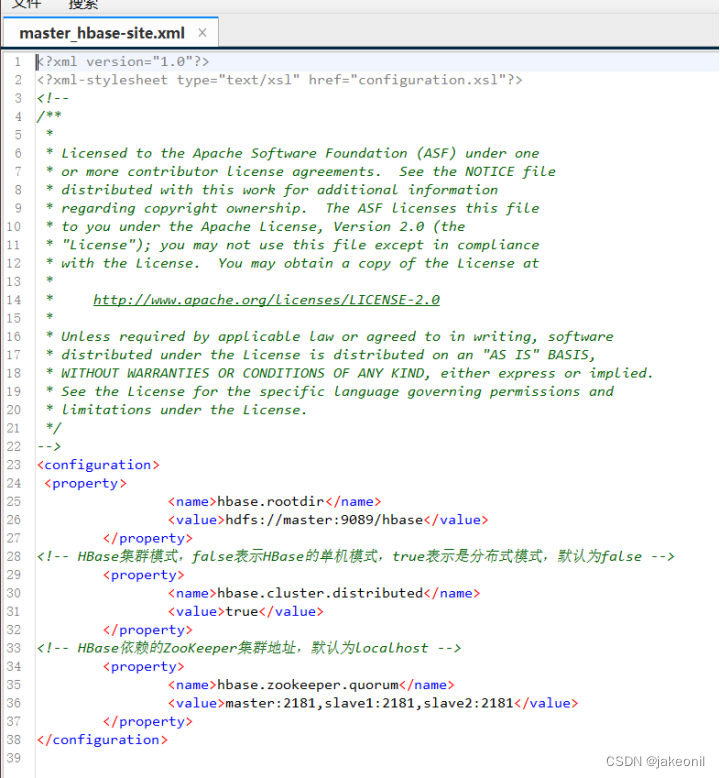
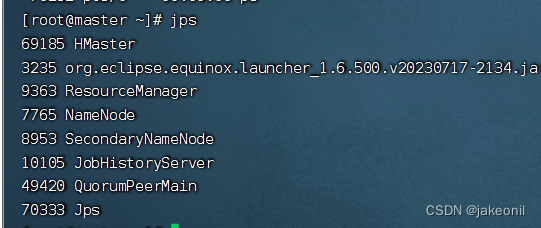
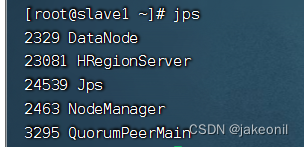
| 实验内容(实验原理、运用的理论知识、算法、程序、步骤和方法) 1.HBase集群的部署原理: Hadoop生态环境: HBase通常部署在Hadoop生态环境上,依赖HDFS(Hadoop Distributed File System)存储数据。 ZooKeeper: HBase集群通常依赖ZooKeeper进行协调和管理,确保集群中的各个节点之间的一致性和可用性。 Master-RegionServer架构: HBase集群包含一个或多个Master节点和多个RegionServer节点。Master负责集群管理和元数据操作,而RegionServer存储和处理实际的数据。 HBase根目录: HBase在HDFS上有一个根目录,用于存储表的元数据和实际数据。这个目录会分散在HDFS上的不同节点上,实现了数据的分布式存储。 2. HBase实战的实验原理: 创建和管理表: 使用HBase Shell或API创建表,定义列簇、列等结构,并观察表的分布情况。 数据写入和读取: 向HBase表中写入数据,并通过不同方式进行读取,观察数据的分布和读写性能。 HBase过滤器: 使用HBase过滤器来检索满足特定条件的数据,例如列值、时间戳等。 HBase Coprocessors: 实验使用HBase Coprocessors来进行数据处理,例如计数、聚合等,加强HBase的功能。 监控和性能调优: 使用HBase的监控工具(如HBase Web UI)来监测集群的状态,观察各节点的负载情况,进行性能调优。 故障模拟: 模拟节点故障,观察HBase的自动恢复机制,确保集群的可用性和容错性。 数据一致性: 观察HBase在数据写入和更新时的一致性保证,了解HBase的事务特性。 备份和恢复: 实验备份和恢复HBase表,确保在发生灾难性事件时能够迅速还原数据。 实验步骤: 1.规划全分布模式HBase集群。 采用的是HBase版本是1.4.10,3个节点的机器名分别为master、slave1、slave2,IP地址依次为192.168.18.100、192.168.18.101、192.168.18.102 2.部署全分布模式HBase集群。 1). 初始软硬件环境准备 (1)准备3台机器,安装操作系统,编者使用CentOS Linux 7.5。 (2)对集群内每一台机器,配置静态IP、修改机器名、添加集群级别域名映射、关闭防火墙。 (3)对集群内每一台机器,安装和配置Java,要求Java 1.7或更高版本,编者使用Oracle JDK 8u191。 (4)安装和配置Linux集群中主节点到从节点的SSH免密登录 2). 获取HBase HBase官方下载地址为https://hbase.apache.org/downloads.html,建议读者下载stable目录下的当前稳定版本。编者采用的HBase稳定版本是2019年6月10日发布的HBase 1.4.10,其安装包文件hbase-1.4.10-bin.tar.gz例如存放在master机器的/home/xuluhui/Downloads中。 3). 主节点上配置HBase HBase所有配置文件位于$HBASE_HOME/conf下,具体的配置文件如前文图5-9所示。本实验中编者仅修改hbase-env.sh、hbase-site.xml、regionservers三个配置文件。 假设当前目录为“/opt/so/hbase-1.4.10”,切换到普通用户如root下,在主节点master上配置HBase的具体过程如下所示。 (1)编辑配置文件hbase-env.sh hbase-env.sh用于设置Linux/Unix环境下运行HBase要用的环境变量,包括Java安装路径等,使用“vim conf/hbase-env.sh”对其进行如下修改。 设置JAVA_HOME,与master上之前安装的JDK位置、版本一致,将第27行的注释去掉,并修改为以下内容,修改后的效果如图所示。 export JAVA_HOME=/usr/java/jdk1.8.0_191/ 编辑配置文件hbase-env.sh中JAVA_HOME 将第46、47行的PermSize作为注释,因为JDK8中无需配置,修改后的效果如图所示。 编辑配置文件hbase-env.sh中PermSize JDK8下若PermSize配置不作为注释或删掉,则启动HBase集群时会出现以下“warning”警告信息 设置HBASE_PID_DIR,修改进程号文件的保存位置,该参数默认为“/tmp”,将第120行修改为以下内容,如图所示。其中pids目录由HBase集群启动后自动创建。 编辑配置文件hbase-env.sh中HBASE_PID_DIR 设置HBASE_MANAGES_ZK,将其值设置为false,即关闭HBase本身的ZooKeeper集群,将第128行修改为以下内容,如图所示。 编辑配置文件hbase-env.sh中HBASE_MANAGES_ZK (2)编辑配置文件hbase-site.xml hbase-site.xml是HBase核心配置文件,包括HBase数据存放位置、ZooKeeper集群地址等配置项。在master机器上修改配置文件hbase-site.xml,具体内容如下所示。 (3)编辑配置文件regionservers Regionservers用于设置运行HRegionServer从进程的机器列表,每行1个主机名。在master机器上修改配置文件regionservers,该文件原来内容为“localhost”,修改为以下内容。 slave1 slave2 3.启动全分布模式HBase集群。 (1. 启动HDFS集群 在主节点上使用命令“start-dfs.sh”启动HDFS集群,使用的命令及运行效果如图5-23所示,从图5-23中可以看出,HDFS主进程NameNode成功启动,slave1和slave2上的从进程DataNode此处未展示,读者应保证HDFS所有主从进程都启动成功。 (2. 启动ZooKeeper集群 由于本实验中HBase并未自动管理ZooKeeper,所以用户需要手工启动ZooKeeper集群。在ZooKeeper集群的所有节点上使用命令“zkServer.sh start”启动ZooKeeper集群,编者为了方便,在节点master上使用ssh远程连接slave1、slave2,完成了各个节点ZooKeeper的启动工作 (3. 启动HBase集群 在主节点上启动HBase集群
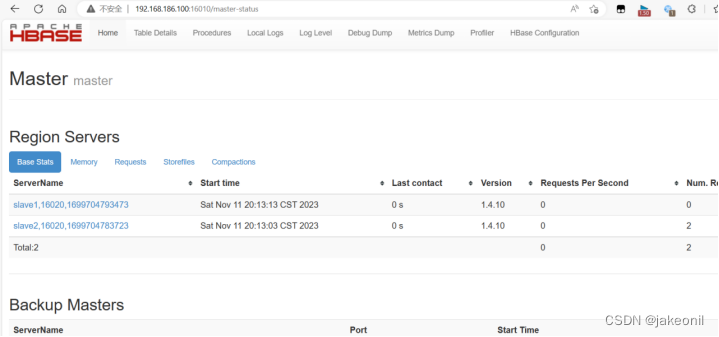
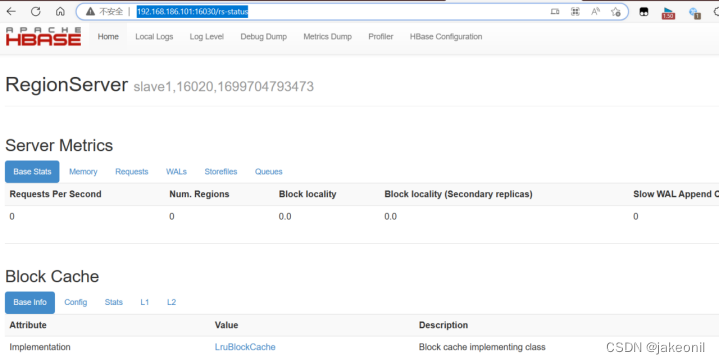
而在从节点上: 4.验证全分布模式HBase集群。 主节点上的webUI的界面是:
从节点的webUI的界面:
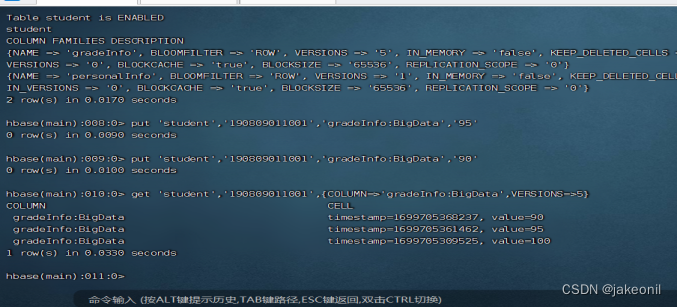
5.使用HBase Web UI。 (1)使用hbase shell
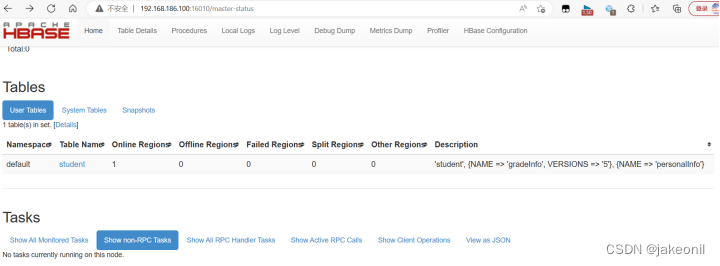
(2)打开HBase主节点的Web UI,可以看到已建立的student表,如图所示。
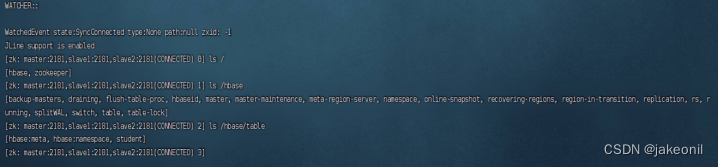
从HBase集群主节点的Web UI界面上查看student表 (3)使用命令“zkCli.sh -server master:2181,slave1:2181,slave2:2181”连接ZooKeeper客户端,从ZooKeeper的存储树中也可以查看到建立的student表,如图所示。
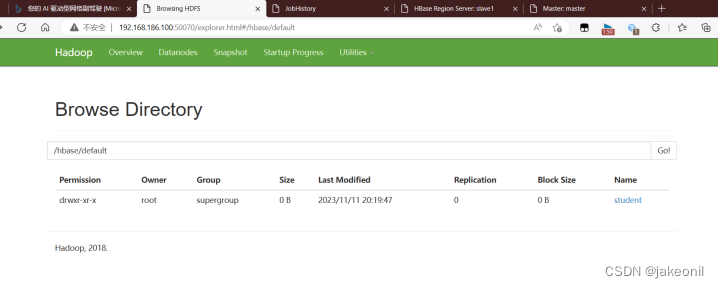
从ZooKeeper存储树中可查看到student表 (4)由于HBase底层存储采用HDFS,所以打开HDFS Web UI,也可以查看到建立的student表,如图所示。
6. 关闭全分布模式HBase集群。 使用命令“stop-hbase.sh” 关闭HBase集群照本实验设置,关闭HBase集群后HBase主节点master上的主进程HMaster、HBase从节点slave1、slave2上的从进程HRegionServer消失,同时HBase主从节点上所有与HBase相关的ZooKeeper节点文件*.znode和进程号文件*.pid也依次消失。 | |||


| 实验结果与分析 1.集群启动: 通过Web UI、HBase Shell以及其他工具,确认HBase集群启动正常。 2.表的创建和管理: 通过HBase Shell和Web UI,查看已建立的表(例如,student表)。 3.数据写入和读取: 使用HBase Shell或API向表中写入数据,并通过不同方式进行读取,观察性能。 4.过滤器和Coprocessors: 使用过滤器检索数据,尝试使用Coprocessors进行数据处理,验证功能。 5.监控和性能调优: 使用HBase Web UI监测集群状态,观察各节点负载情况,进行性能调优。 6.故障模拟: 模拟节点故障,验证HBase的自动恢复机制,确保集群容错性。数据一致性: 观察数据写入和更新时的一致性,了解HBase的事务特性。 7.备份和恢复: 实验备份和恢复HBase表,确认在灾难性事件时能够迅速还原数据。 |
相关文章:
大数据平台/大数据技术与原理-实验报告--部署全分布模式HBase集群和实战HBase
实验名称 部署全分布模式HBase集群和实战HBase 实验性质 (必修、选修) 必修 实验类型(验证、设计、创新、综合) 综合 实验课时 2 实验日期 2023.11.07-2023.11.10 实验仪器设备以及实验软硬件要求 专业实验室ÿ…...

手写字符识别神经网络项目总结
1.数据集 手写字符数据集 DIGITS,该数据集的全称为 Pen-Based Recognition of Handwritten Digits Data Set,来源于 UCI 开放数据集网站。 2.加载数据集 import numpy as np from sklearn import datasets digits datasets.load_digits() 3.分割数…...
八、Lua数组和迭代器
一、Lua数组 数组,就是相同数据类型的元素按一定顺序排列的集合,可以是一维数组和多维数组。 在 Lua 中,数组不是一种特定的数据类型,而是一种用来存储一组值的数据结构。 实际上,Lua 中并没有专门的数组类型…...
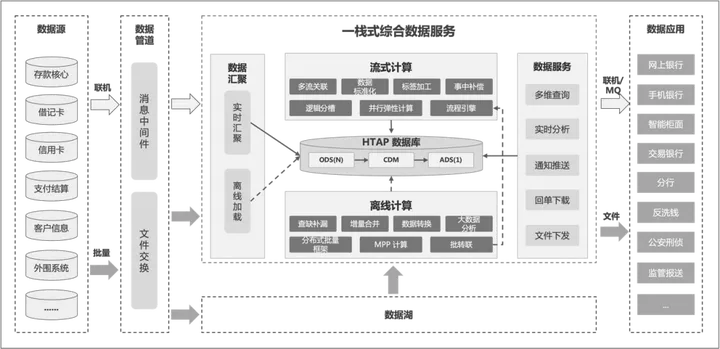
平凯星辰 TiDB 获评 “2023 中国金融科技守正创新扬帆计划” 十佳优秀实践奖
11 月 10 日,2023 金融街论坛年会同期举办了“第五届成方金融科技论坛——金融科技守正创新论坛”,北京金融产业联盟发布了“扬帆计划——分布式数据库金融应用研究与实践优秀成果”, 平凯星辰提报的实践报告——“国产 HTAP 数据库在金融规模…...

运算符展开、函数,对象,数组,字符串变化 集合
... 展开运算符 用于函数实参或者赋值号右边 console.log(...[1, 2, 3]) // 1,2,3console.log(Math.max(...[1, 2, 3]))//3 console.log(Math.max.apply(null, [1, 2, 3]))//3const o { a: 1, b: 2 }const obj { ...o, c: 3 }console.log(obj)//Object ... 剩余运算符 用于…...

NI自动化测试系统用电必备攻略,电源规划大揭秘
就像使用电脑之前需接通电源一样,自动化测试系统的电源选择也是首当其冲的问题,只不是这个问题更复杂。 比如,应考虑地理位置因素,因为不同国家或地区的公共电网所提供的线路功率有所不同。在电源布局和设备选型方面,有…...

ky10 server arm 在线编译安装openssl3.1.4
在线编译脚本 #!/bin/shOPENSSLVER3.1.4OPENSSL_Vopenssl versionecho "当前OpenSSL 版本 ${OPENSSL_V}" #------------------------------------------------ #wget https://www.openssl.org/source/openssl-3.1.4.tar.gzecho "安装OpenSSL${OPENSSLVER}...&q…...
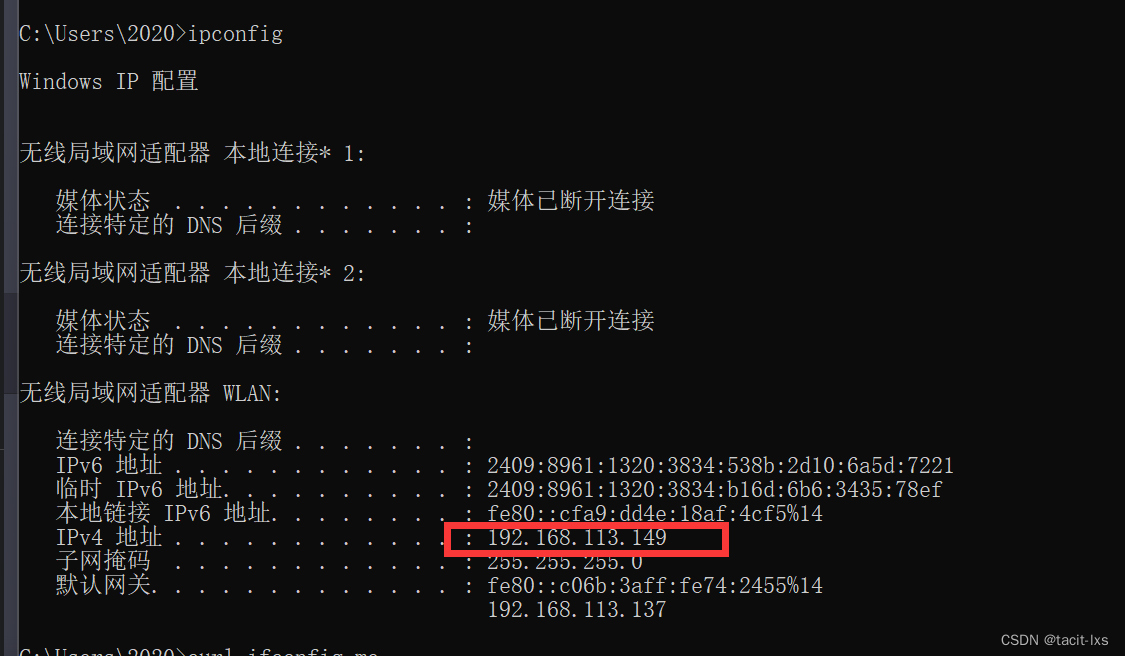
外网IP和内网IP的区别
首先得先知道什么是ip地址,它就是唯一标识连接网络的设备的,即IP地址充当了设备在网络中的“住址”,使得设备能够相互通信和交换数据。 我们常听开发人员说外网内网,那么它们有什么区别呢? 外网可以理解为互联网&…...

Jquery动画特效
1,Jquery提供的特效方法 2,实例代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><…...
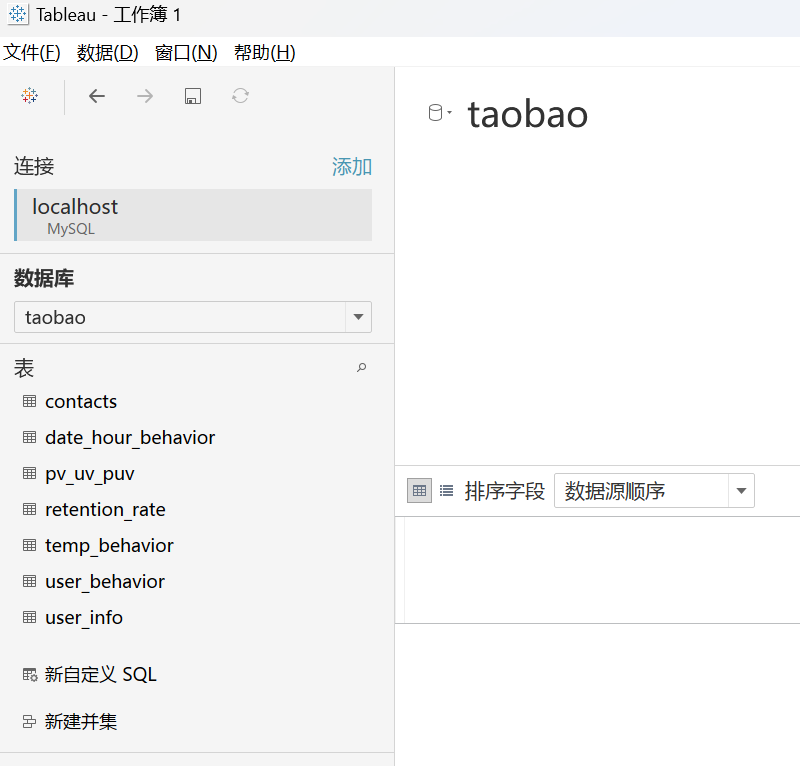
Tableau连接到mysql数据库,配置驱动
Tableau想要连接mysql数据库进行数据的可视化,但是没有ODBC驱动,看了几篇文章写的,不是很清楚,顺便写下自己的思路。 1、下载mysql对应的ODBC驱动 首先要知道自己mysql的版本,然后下载对应的ODBC驱动。 MySQL :: Dow…...

HuggingFace学习笔记--AutoModel的使用
1--AutoModel的使用 官方文档 AutoModel 用于加载模型; 1-1--简单Demo 测试代码: from transformers import AutoTokenizer, AutoModelif __name__ "__main__":checkpoint "distilbert-base-uncased-finetuned-sst-2-english"t…...

Kafka常见面试问题
1、Kafka分区设计及主副本如何同步 Apache Kafka是一种分布式流处理平台,它使用分布式复制协议来实现高可用性和容错性。在Kafka中,每个主题(topic)都有一个或多个分区(partition),每个分区都有…...
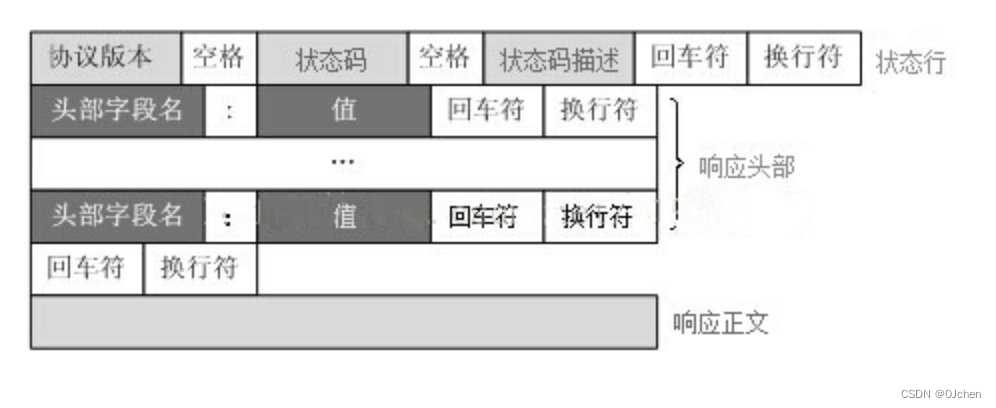
学习知识回顾随笔(远程连接MySQL|远程访问Django|HTTP协议|Web框架)
文章目录 如何远程连接MySQL数据库1.创建用户来运行,此用户从任何主机连接到mysql数据库2.使用IP地址来访问MySQL数据库 如何远程访问Django项目Web应用什么是Web应用应用程序的两种模式Web应用程序的优缺点 HTTP协议(超文本传输协议)简介HTT…...
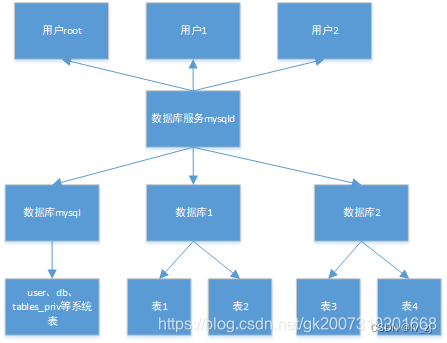
一、TIDB基础
官方文档:TiDB 产品文档 | PingCAP 文档中心 TIDB整个逻辑架构跟MYSQL类似,如下: TIDB集群:相当于MYSQL的数据库服务器,区别是MYSQL数据库服务器为单进程的,TIDB集群为分布式多进程的。 数据库ÿ…...

【微软技术栈】使用新的C#功能减少内存分配
本文内容 通过引用传递和返回引用安全上下文安全的上下文和 ref 结构统一内存类型通过参考安全提高性能 本节中介绍的技术可提高应用于代码中的热路径时的性能。热路径是代码库中在正常操作中经常重复执行的部分。将这些技术应用于不经常执行的代码将产生最小的影响。在进行任何…...

Linux shell编程学习笔记29:shell自带的 脚本调试 选项
Linux shell脚本的调试方法比较多,上次我们探讨和测试了shell内建命令set所提供的一些调试选项,其实 shell 本身也提供了一些调试选项。我们以bash为例来看看。 1 bash 的命令行帮助信息(bash --help) purleEndurer csdn ~ $ ba…...

分享几个可以免费使用GPT的网站
ChatGPT这个是国产的,里面可以使用3.5和4.0,免费用户每日都有各自的使用次数,反应迅速。文言一心国内百度的chart8新用户200次,但只能用3.5,响应速度有点慢 各有优缺点,大家看个人情况使用,个人…...

一. BEV感知算法介绍
目录 前言1. BEV感知算法的概念2. BEV感知算法数据形式3. BEV开源数据集介绍3.1 KITTI数据集3.2 nuScenes数据集 4. BEV感知方法分类4.1 纯点云方案4.2 纯视觉方案4.3 多模态方案 5. BEV感知算法的优劣6. BEV感知算法的应用介绍7. 课程框架介绍与配置总结下载链接参考 前言 自动…...

Scala如何写一个通用的游戏数据爬虫程序
以前想要获取一些网站数据的时候,都是通过人工手动复制粘贴,这样的效率及其低下。数据少无所谓,如果需要采集大量数据,手动就显得乏力了。半夜睡不着,爬起来写一段有关游戏商品数据的爬虫通用模板,希望能帮…...

前端命名规范总结
布局类:header, footer, container, main, content, aside, page, section 包裹类:wrap, inner 区块类:region, block, box 结构类:hd, bd, ft, top, bottom, left, right, middle, col, row, grid, span 列表类:list,…...

.NET 新特性概览与相关文章索引檀
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...

Threads库:裸机与RTOS下的轻量级函数多实例并发框架
1. Threads 库深度解析:在裸机与 RTOS 环境下实现函数的多实例并发执行1.1 项目定位与工程价值“Threads”并非一个独立的实时操作系统(RTOS),而是一个轻量级、可移植的函数级多实例并发抽象层。其核心设计目标是:在不…...
)
给STM32F429的RGB屏做个‘相册’:FATFS+软件解码JPG实战(避坑SD卡格式化)
STM32F429实战:构建安全高效的JPG图片浏览器 在嵌入式设备上实现图片浏览功能是许多项目的常见需求,尤其是当我们需要为产品添加图形界面或多媒体展示能力时。STM32F429凭借其强大的LTDC接口和DMA2D加速器,成为中高端嵌入式图形应用的理想选择…...

嵌入式FIFO缓冲区库:零堆分配、编译期确定的高效队列实现
1. FIFObuf 库概述FIFObuf 是一个专为 Arduino 和 ESP 系列微控制器平台设计的轻量级、模板化缓冲区管理库,提供 FIFO(先进先出)与 LIFO(后进先出)两种数据结构的高效实现。其核心设计哲学是“零运行时开销、最小内存占…...

专家 VS镜像视界:镜像视界算不算AI公司?
🎯 标准反杀答案如果按传统分类,我们当然使用AI技术;但如果从系统本质来看—— 我们不属于“AI公司”,而属于“空间智能基础设施公司”。AI只是我们系统中的一个模块, 而不是系统的核心。🧠 进阶拆解① 承认…...

MCP4728 vs AD569:四通道DAC芯片选型与Linux驱动开发对比
MCP4728与AD569四通道DAC芯片深度对比与Linux驱动实战指南 在嵌入式系统开发中,数字模拟转换器(DAC)的选择往往决定了整个信号链路的精度与稳定性。当项目需要同时控制多路模拟输出时,四通道DAC芯片如MCP4728和AD569便成为工程师的首选。这两款芯片虽然功…...

HDMI/DP/TypeC接口检测的硬件实现与设计考量
1. HDMI接口检测的硬件实现与设计要点 HDMI作为最普及的数字视频接口,其检测电路设计直接影响设备兼容性。实际工程中常见两种检测方案:5V电源检测和DDC地线检测。我经手过的显示器项目中,90%的兼容性问题都源于检测电路设计不当。 先说5V检测…...

WSL桥接网络配置:从临时到永久的IP固定方案
1. 为什么需要固定WSL的IP地址? 很多开发者在使用WSL(Windows Subsystem for Linux)进行嵌入式开发时都会遇到一个头疼的问题:每次重启WSL或者电脑后,IP地址都会变化。想象一下,你正在调试一个嵌入式设备&a…...

AI 时代:祛魅、适应与重新定义杂
指令替换 项目需求:将加法指令替换为减法 项目目录如下 /MyProject ├── CMakeLists.txt # CMake 配置文件 ├── build/ #构建目录 │ └── test.c #测试编译代码 └── mypass2.cpp # pass 项目代码 一,测试代码示例 test.c // test.c #includ…...

低空经济“充电网”:原理、场景与未来布局全解析
低空经济“充电网”:原理、场景与未来布局全解析 引言:为什么说“充电桩”是低空经济的“加油站”? [外链图片转存中…(img-5rpT3Icb-1775923220357)] 随着无人机与eVTOL(电动垂直起降飞行器)从“玩具”和“概念”走向…...