【深度学习实验】注意力机制(四):点积注意力与缩放点积注意力之比较
文章目录
- 一、实验介绍
- 二、实验环境
- 1. 配置虚拟环境
- 2. 库版本介绍
- 三、实验内容
- 0. 理论介绍
- a. 认知神经学中的注意力
- b. 注意力机制
- 1. 注意力权重矩阵可视化(矩阵热图)
- 2. 掩码Softmax 操作
- 3. 打分函数——加性注意力模型
- 3. 打分函数——点积注意力与缩放点积注意力
- a. 缩放点积注意力模型
- b. 点积注意力模型
- c. 模拟实验
- d. 模型比较与选择
- e. 代码整合
一、实验介绍
注意力机制作为一种模拟人脑信息处理的关键工具,在深度学习领域中得到了广泛应用。本系列实验旨在通过理论分析和代码演示,深入了解注意力机制的原理、类型及其在模型中的实际应用。
本文将介绍将介绍带有掩码的 softmax 操作
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7
conda activate DL
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib
conda install scikit-learn
2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
|---|---|---|
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 理论介绍
a. 认知神经学中的注意力
人脑每个时刻接收的外界输入信息非常多,包括来源于视
觉、听觉、触觉的各种各样的信息。单就视觉来说,眼睛每秒钟都会发送千万比特的信息给视觉神经系统。人脑通过注意力来解决信息超载问题,注意力分为两种主要类型:
- 聚焦式注意力(Focus Attention):
- 这是一种自上而下的有意识的注意力,通常与任务相关。
- 在这种情况下,个体有目的地选择关注某些信息,而忽略其他信息。
- 在深度学习中,注意力机制可以使模型有选择地聚焦于输入的特定部分,以便更有效地进行任务,例如机器翻译、文本摘要等。
- 基于显著性的注意力(Saliency-Based Attention)
- 这是一种自下而上的无意识的注意力,通常由外界刺激驱动而不需要主动干预。
- 在这种情况下,注意力被自动吸引到与周围环境不同的刺激信息上。
- 在深度学习中,这种注意力机制可以用于识别图像中的显著物体或文本中的重要关键词。
在深度学习领域,注意力机制已被广泛应用,尤其是在自然语言处理任务中,如机器翻译、文本摘要、问答系统等。通过引入注意力机制,模型可以更灵活地处理不同位置的信息,提高对长序列的处理能力,并在处理输入时动态调整关注的重点。
b. 注意力机制
-
注意力机制(Attention Mechanism):
- 作为资源分配方案,注意力机制允许有限的计算资源集中处理更重要的信息,以应对信息超载的问题。
- 在神经网络中,它可以被看作一种机制,通过选择性地聚焦于输入中的某些部分,提高了神经网络的效率。
-
基于显著性的注意力机制的近似: 在神经网络模型中,最大汇聚(Max Pooling)和门控(Gating)机制可以被近似地看作是自下而上的基于显著性的注意力机制,这些机制允许网络自动关注输入中与周围环境不同的信息。
-
聚焦式注意力的应用: 自上而下的聚焦式注意力是一种有效的信息选择方式。在任务中,只选择与任务相关的信息,而忽略不相关的部分。例如,在阅读理解任务中,只有与问题相关的文章片段被选择用于后续的处理,减轻了神经网络的计算负担。
-
注意力的计算过程:注意力机制的计算分为两步。首先,在所有输入信息上计算注意力分布,然后根据这个分布计算输入信息的加权平均。这个计算依赖于一个查询向量(Query Vector),通过一个打分函数来计算每个输入向量和查询向量之间的相关性。
-
注意力分布(Attention Distribution):注意力分布表示在给定查询向量和输入信息的情况下,选择每个输入向量的概率分布。Softmax 函数被用于将分数转化为概率分布,其中每个分数由一个打分函数计算得到。
-
打分函数(Scoring Function):打分函数衡量查询向量与输入向量之间的相关性。文中介绍了几种常用的打分函数,包括加性模型、点积模型、缩放点积模型和双线性模型。这些模型通过可学习的参数来调整注意力的计算。
-
加性模型: s ( x , q ) = v T tanh ( W x + U q ) \mathbf{s}(\mathbf{x}, \mathbf{q}) = \mathbf{v}^T \tanh(\mathbf{W}\mathbf{x} + \mathbf{U}\mathbf{q}) s(x,q)=vTtanh(Wx+Uq)
-
点积模型: s ( x , q ) = x T q \mathbf{s}(\mathbf{x}, \mathbf{q}) = \mathbf{x}^T \mathbf{q} s(x,q)=xTq
-
缩放点积模型: s ( x , q ) = x T q D \mathbf{s}(\mathbf{x}, \mathbf{q}) = \frac{\mathbf{x}^T \mathbf{q}}{\sqrt{D}} s(x,q)=DxTq (缩小方差,增大softmax梯度)
-
双线性模型: s ( x , q ) = x T W q \mathbf{s}(\mathbf{x}, \mathbf{q}) = \mathbf{x}^T \mathbf{W} \mathbf{q} s(x,q)=xTWq (非对称性)
-
-
-
软性注意力机制:
-
定义:软性注意力机制通过一个“软性”的信息选择机制对输入信息进行汇总,允许模型以概率形式对输入的不同部分进行关注,而不是强制性地选择一个部分。
-
加权平均:软性注意力机制中的加权平均表示在给定任务相关的查询向量时,每个输入向量受关注的程度,通过注意力分布实现。
-
Softmax 操作:注意力分布通常通过 Softmax 操作计算,确保它们成为一个概率分布。
-
1. 注意力权重矩阵可视化(矩阵热图)
【深度学习实验】注意力机制(一):注意力权重矩阵可视化(矩阵热图heatmap)
2. 掩码Softmax 操作
【深度学习实验】注意力机制(二):掩码Softmax 操作
3. 打分函数——加性注意力模型
- 加性模型: s ( x , q ) = v T tanh ( W x + U q ) \mathbf{s}(\mathbf{x}, \mathbf{q}) = \mathbf{v}^T \tanh(\mathbf{W}\mathbf{x} + \mathbf{U}\mathbf{q}) s(x,q)=vTtanh(Wx+Uq)
【深度学习实验】注意力机制(三):打分函数——加性注意力模型
3. 打分函数——点积注意力与缩放点积注意力
-
点积模型: s ( x , q ) = x T q \mathbf{s}(\mathbf{x}, \mathbf{q}) = \mathbf{x}^T \mathbf{q} s(x,q)=xTq
-
缩放点积模型: s ( x , q ) = x T q D \mathbf{s}(\mathbf{x}, \mathbf{q}) = \frac{\mathbf{x}^T \mathbf{q}}{\sqrt{D}} s(x,q)=DxTq (缩小方差,增大softmax梯度)
a. 缩放点积注意力模型
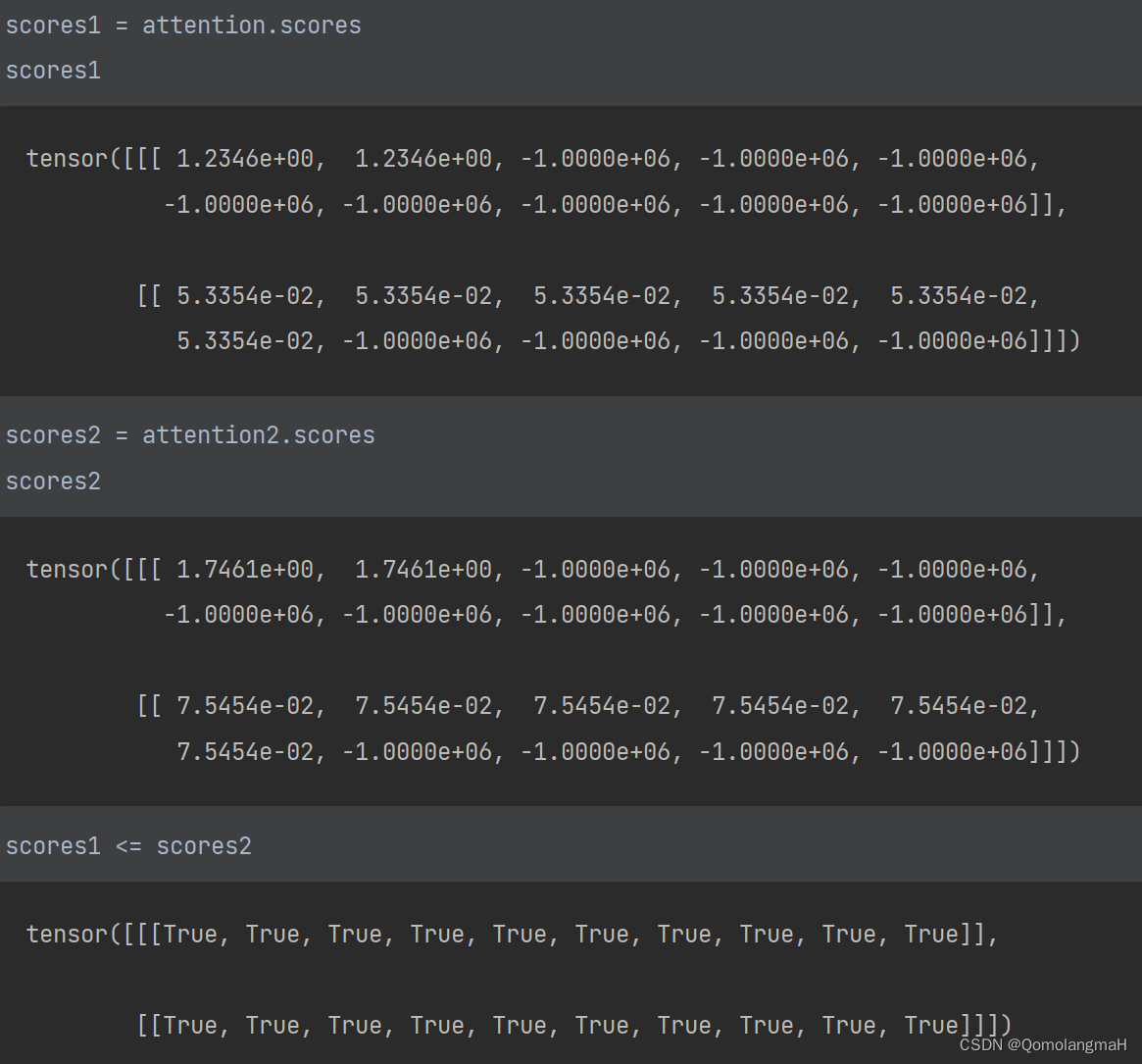
class DotProductAttention(nn.Module):"""缩放点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention, self).__init__(**kwargs)# 使用暂退法进行模型正则化self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens=None):d = queries.shape[-1]self.scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)self.attention_weights = masked_softmax(self.scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)-
初始化方法 (
__init__):- 参数:
dropout: Dropout 正则化的概率。
- 说明: 初始化方法定义了模型的组件,仅包含了一个 Dropout 正则化层。
- 参数:
-
前向传播方法 (
forward):- 参数:
queries: 查询张量,形状为(batch_size, num_queries, d)。keys: 键张量,形状为(batch_size, num_kv_pairs, d)。values: 值张量,形状为(batch_size, num_kv_pairs, value_size)。valid_lens: 有效长度张量,形状为(batch_size,)或(batch_size, num_queries)。
- 返回值: 加权平均后的值张量,形状为
(batch_size, num_queries, value_size)。
- 参数:
-
实现细节:
- 计算缩放点积得分:通过张量乘法计算
queries和keys的点积,然后除以 d \sqrt{d} d 进行缩放,其中 d d d 是查询或键的维度。 - 使用
masked_softmax函数计算注意力权重,根据有效长度对注意力进行掩码。 - 将注意力权重应用到值上,得到最终的加权平均结果。
- 使用 Dropout 对注意力权重进行正则化。
- 计算缩放点积得分:通过张量乘法计算
b. 点积注意力模型
class DotProductAttention2(nn.Module):"""点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention2, self).__init__(**kwargs)# 使用暂退法进行模型正则化self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens=None):# P195:(8.3),(8.4)# 在计算得分时不进行缩放操作(即不再除以sqrt(d))self.scores = torch.bmm(queries, keys.transpose(1, 2))self.attention_weights = masked_softmax(self.scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)- 区别:
- 计算点积得分:通过张量乘法计算
queries和keys的点积。
- 计算点积得分:通过张量乘法计算
c. 模拟实验
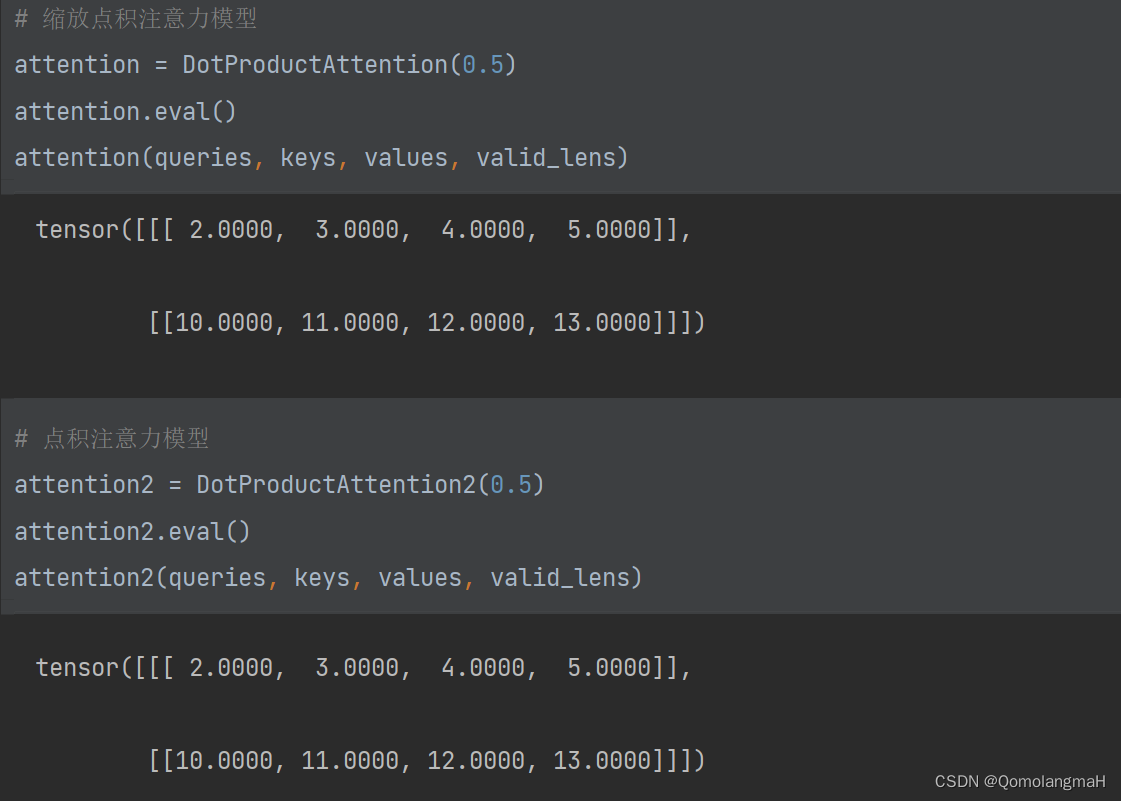
- 模型数据
queries, keys = torch.normal(0, 1, (2, 1, 2)), torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])
- 模型应用
# 创建缩放点积注意力模型
attention = DotProductAttention(0.5)
attention.eval()
# 使用模型进行前向传播
attention(queries, keys, values, valid_lens)# 创建点积注意力模型
attention2 = DotProductAttention2(0.5)
attention2.eval()
# 使用模型进行前向传播
attention2(queries, keys, values, valid_lens)
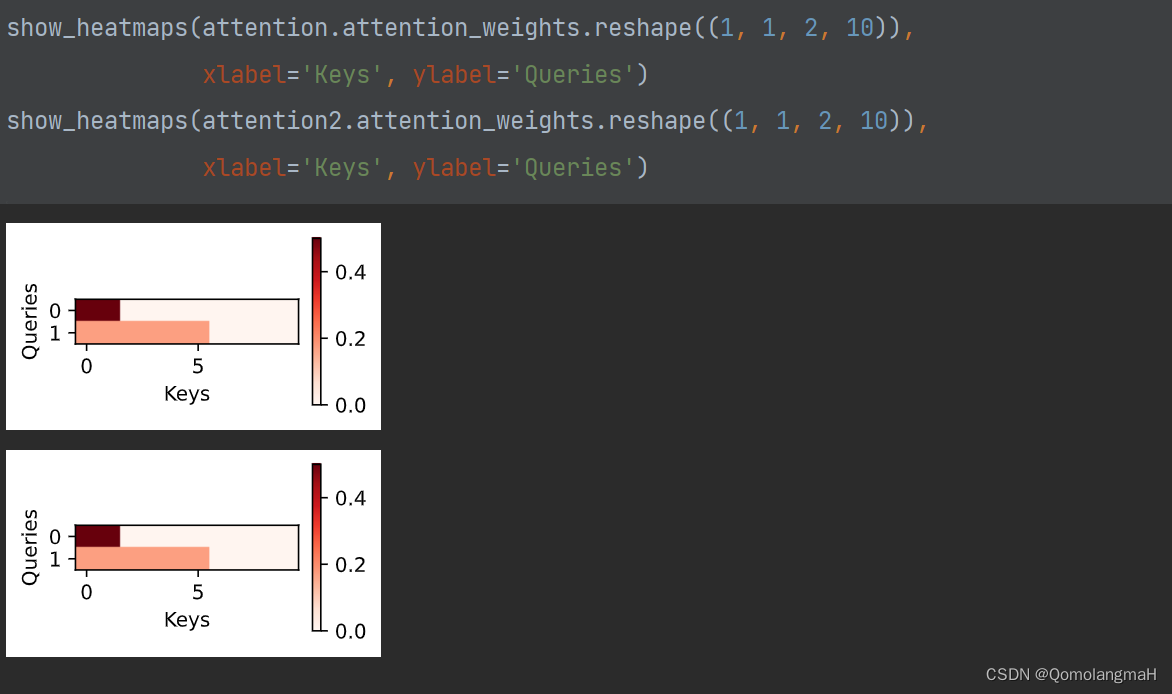
- 权重可视化
为了直观地展示模型在不同输入下的注意力分布,使用前文show_heatmaps函数,通过热图的形式展示注意力权重。
# 可视化缩放点积注意力权重
show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')# 可视化点积注意力权重
show_heatmaps(attention2.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')
d. 模型比较与选择
-
缩放点积注意力模型:
- 适用于处理高维度的查询和键。
- 通过缩放操作有助于防止点积得分的方差过大。
-
点积注意力模型:
- 适用于处理相对较低维度的查询和键。
- 更方便地利用矩阵乘积提高计算效率。
e. 代码整合
# 导入必要的库
import math
import torch
from torch import nn
import torch.nn.functional as F
from d2l import torch as d2l
from torch.utils import datadef masked_softmax(X, valid_lens):"""通过在最后一个轴上掩蔽元素来执行softmax操作"""# X:3D张量,valid_lens:1D或2D张量if valid_lens is None:return nn.functional.softmax(X, dim=-1)else:shape = X.shapeif valid_lens.dim() == 1:valid_lens = torch.repeat_interleave(valid_lens, shape[1])else:valid_lens = valid_lens.reshape(-1)# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6)return nn.functional.softmax(X.reshape(shape), dim=-1)def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5), cmap='Reds'):"""显示矩阵热图"""d2l.use_svg_display()num_rows, num_cols = matrices.shape[0], matrices.shape[1]fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,sharex=True, sharey=True, squeeze=False)for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)if i == num_rows - 1:ax.set_xlabel(xlabel)if j == 0:ax.set_ylabel(ylabel)if titles:ax.set_title(titles[j])fig.colorbar(pcm, ax=axes, shrink=0.6)class DotProductAttention(nn.Module):"""缩放点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention, self).__init__(**kwargs)# 使用暂退法进行模型正则化self.dropout = nn.Dropout(dropout)# queries的形状:(batch_size,查询的个数,d)# keys的形状:(batch_size,“键-值”对的个数,d)# values的形状:(batch_size,“键-值”对的个数,值的维度)# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)def forward(self, queries, keys, values, valid_lens=None):print(queries)d = queries.shape[-1]print(d)self.scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)print(self.scores)self.attention_weights = masked_softmax(self.scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)class DotProductAttention2(nn.Module):"""点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention2, self).__init__(**kwargs)# 使用暂退法进行模型正则化self.dropout = nn.Dropout(dropout)# queries的形状:(batch_size,查询的个数,d)# keys的形状:(batch_size,“键-值”对的个数,d)# values的形状:(batch_size,“键-值”对的个数,值的维度)# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)def forward(self, queries, keys, values, valid_lens=None):# P195:(8.3),(8.4)# 在计算得分时不进行缩放操作(即不再除以sqrt(d))self.scores = torch.bmm(queries, keys.transpose(1, 2))print(self.scores)self.attention_weights = masked_softmax(self.scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)queries, keys = torch.normal(0, 1, (2, 1, 2)), torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])# 缩放点积注意力模型
attention = DotProductAttention(0.5)
attention.eval()
attention(queries, keys, values, valid_lens)# 点积注意力模型
attention2 = DotProductAttention2(0.5)
attention2.eval()
attention2(queries, keys, values, valid_lens)
相关文章:
【深度学习实验】注意力机制(四):点积注意力与缩放点积注意力之比较
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 理论介绍a. 认知神经学中的注意力b. 注意力机制 1. 注意力权重矩阵可视化(矩阵热图)2. 掩码Softmax 操作3. 打分函数——加性注意力模型3. 打分函数——点积注意力与缩放…...

用于图像分类任务的经典神经网络综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…...

Linux如何查找某个路径下大于1G的文件
find 命令可以用于在 Linux 或 macOS 系统中查找文件和目录。如果你想查找大于1GB的文件,可以使用 -size 选项结合 参数。以下是一个示例: find /path/to/search -type f -size 1G这里的 /path/to/search 是你要搜索的目录的路径。这个命令将查找该目录…...
Java二级医院区域HIS信息管理系统源码(SaaS服务)
一个好的HIS系统,要具有开放性,便于扩展升级,增加新的功能模块,支撑好医院的业务的拓展,而且可以反过来给医院赋能,最终向更多的患者提供更好的服务。 系统采用前后端分离架构,前端由Angular、J…...
定义Token)
自制编程语言(第三弹)定义Token
终于到了激动人心的实现时候了。为了实现我们的自制语言,我们需要的步骤为: 词法分析语法分析语义分析(此处不设置)解释器 详细完整的代码可以点击这里查看github项目。 词法分析: 将代码片段识别为关键词、标识符、…...

linux下的工具---yum
一、什么是yum yum是Linux下的软件包管理器 二、什么是软件包管理器 1、在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序. 2、但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在…...
)
java全局异常处理(springboot)
介绍: 在日常项目开发中,异常是常见的,但是如何更高效的处理好异常信息,让我们能快速定位到BUG,是很重要的,不仅能够提高我们的开发效率,还能让你代码看上去更舒服,SpringBoot的项目…...
JAVA将PDF转图片
前言 当今时代,PDF 文件已经成为了常用的文档格式。然而,在某些情况下,我们可能需要将 PDF 文件转换为图片格式,以便更方便地分享和使用。这时,我们可以使用 Java 编程语言来实现这个功能。Java 提供了许多库和工具&a…...
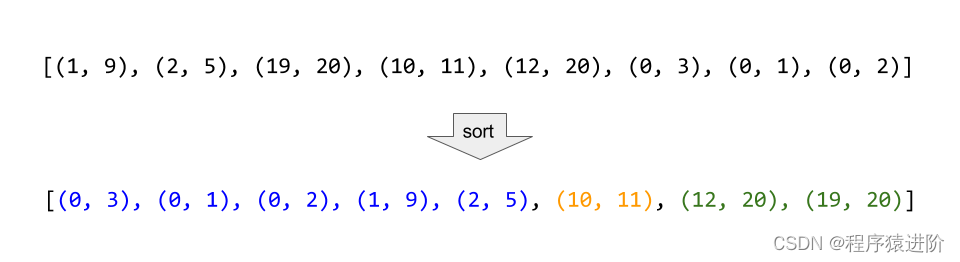
合并区间[中等]
一、题目 以数组intervals表示若干个区间的集合,其中单个区间为intervals[i] [starti, endi]。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。 示例 1: 输入:intervals […...

MYSQL基础知识之【LIKE子句的使用 ,NULL值的处理,空值的处理】
文章目录 前言MySQL LIKE 子句在PHP脚本中使用 LIKE 子句 MySQL NULL 值处理在命令提示符中使用 NULL 值使用PHP脚本处理 NULL 值 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:Mysql 🐱👓博主在前端领域还有…...

线索二叉树:C++实现
引言: 线索二叉树是一种特殊的二叉树,它可以通过线索(线索是指在二叉树中将空指针改为指向前驱或后继的指针)的方式将二叉树转化为一个线性结构,从而方便对二叉树进行遍历。本文将介绍如何使用C实现线索二叉树。 技术…...

C++——vector互换容器与预留空间
一.vector互换容器 功能描述:实现两个容器内元进行互换 函数原型: swap(vec); //将vec与本身的元素互换 实例: //1.基本使用 void test01() {vector<int>v1;for (int i 0; i < 10; i){v1.push_back(i);}cout << "交换前:" << e…...
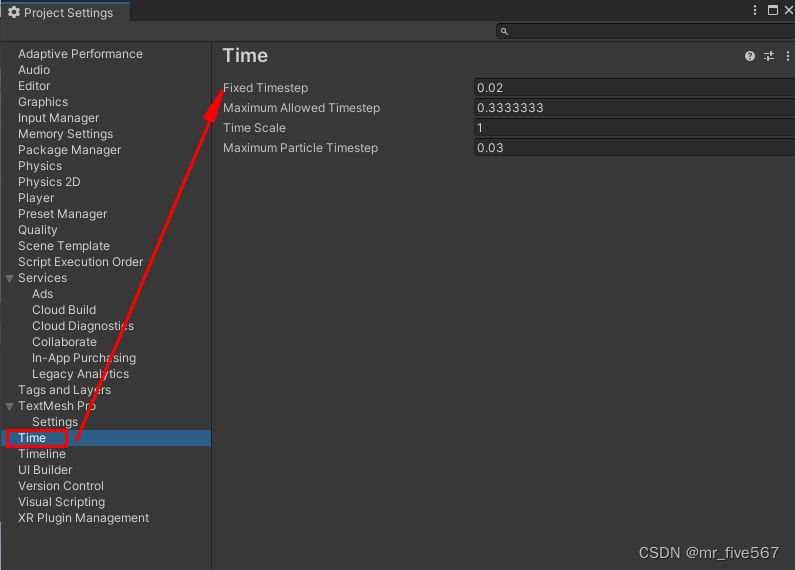
Unity 自带的一些可以操控时间的属性或方法。
今天来总结下Unity自带的一些可以操控时间的方法。 1、Time.time。比较常用计算运行时间而触发特定事件。 public class Controller : MonoBehaviour {public float eventTime 5f; // 触发事件的时间private float startTime; // 游戏开始的时间private void Start(){startT…...

vue 项目中使用 mqtt
1、在html 中用cdn方式引入 <script src"https://unpkg.com/mqtt/dist/mqtt.min.js"></script> 2、封装代码 mqtt_connect.js // import * as mqtt from mqtt/dist/mqtt.min // 不知道为什么 我用引入的方式不成,就在html 用的cdn方式接入了…...
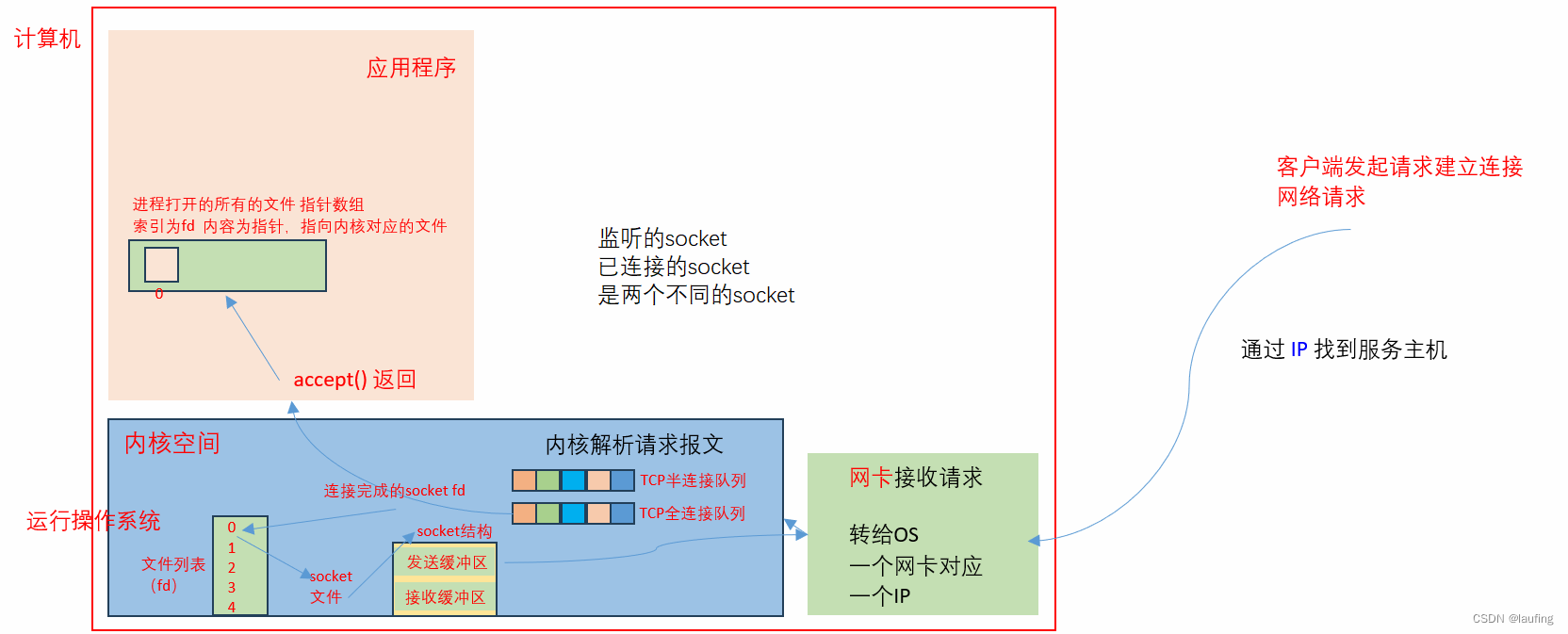
linux shell操作 - 05 进程 与 IO 模型
文章目录 计算机内存分配进程与子进程流IO模型非阻塞IOIO多路复用网络IO模型简单的socket并发的socket 计算机内存分配 一个32位,4G内存的计算机,内存使用分为两部分: 操作系统内核空间;应用程序的用户空间使用的操作系统不同&a…...

让SOME/IP运转起来——SOME/IP系统设计(下)之数据库开发
上一篇我们介绍了SOME/IP矩阵的设计流程,这一篇重点介绍如何把SOME/IP矩阵顺利的交给下游软件团队进行开发。 车载以太网通信矩阵开发完成后,下一步应该做什么? 当我们完成SOME/IP矩阵开发,下一步需要把开发完成的矩阵换成固定格…...

Mybatis反射工厂类DefaultReflectorFactory
DefaultReflectorFactory是反射工厂接口ReflectorFactory的默认实现,其主要是实现了对反射对象Reflector的创建和缓存。 有三个方法: // 判断是否开启缓存boolean isClassCacheEnabled();// 设置是否缓存void setClassCacheEnabled(boolean classCacheEn…...

antDesignPro a-table样式二次封装
antDesignPro是跟element-ui类似的一个样式框架,其本身就是一个完整的后台系统,风格样式都很统一。我使用的是antd pro vue,版本是1.7.8。公司要求使用这个框架,但是UI又有自己的一套设计。这就导致我需要对部分组件进行一定的个性…...
找免费4K高清图片素材,就上这6个网站
使用图片素材怕侵权?那就上这6个网站,免费下载,4K高清无水印,赶紧收藏起来~ 1、菜鸟图库 https://www.sucai999.com/pic.html?vNTYxMjky 一个很大的素材库,站内主要还是以设计素材为主,像图片素材就有上百…...
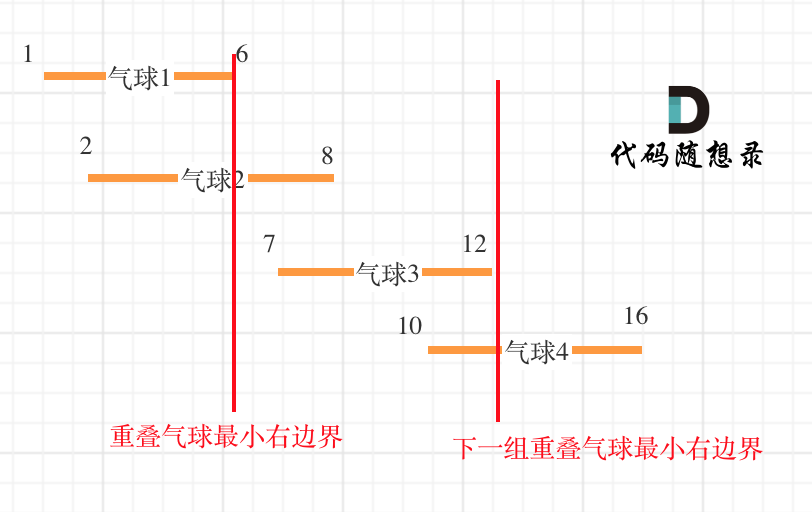
代码随想录算法训练营第35天| 860.柠檬水找零 406.根据身高重建队列 452. 用最少数量的箭引爆气球
JAVA代码编写 860.柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须…...

RK3566开发板Recovery分区实战:手把手教你扩展SD卡镜像并烧录recovery.img
RK3566开发板Recovery分区深度实践:从分区规划到系统部署全解析 1. 开发环境与硬件准备 在开始Recovery分区的实战操作前,我们需要确保开发环境配置正确。以下是基于Orange Pi 3B开发板的硬件规格和开发环境要求: 硬件配置清单: 主…...

3分钟快速上手:ESM蛋白质语言模型完全指南
3分钟快速上手:ESM蛋白质语言模型完全指南 【免费下载链接】esm Evolutionary Scale Modeling (esm): Pretrained language models for proteins 项目地址: https://gitcode.com/gh_mirrors/esm/esm ESM(Evolutionary Scale Modeling)…...
(Matlab代码实现))
基于matlab瞬态三角哈里斯鹰算法TTHHO多无人机协同集群避障路径规划(目标函数:最低成本:路径、高度、威胁、转角)(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

BIM设计师必备:Revit等高线地形建模的5个高效技巧与常见问题解决
BIM设计师必备:Revit等高线地形建模的5个高效技巧与常见问题解决 在BIM设计领域,地形建模往往被视为项目的基础性工作,却直接影响着后续设计的准确性和效率。对于经常处理复杂场地的景观设计师、城市规划师和土木工程师来说,Revi…...

造相Z-Image文生图模型v2避坑指南:显存优化与参数设置技巧
造相Z-Image文生图模型v2避坑指南:显存优化与参数设置技巧 1. 为什么需要关注显存优化 在本地部署造相Z-Image文生图模型v2时,显存管理是决定成败的关键因素。这个拥有20亿参数的模型虽然经过深度优化,但在实际使用中仍然可能遇到显存不足的…...

前端构建优化实战
前端构建优化实战:提升开发效率与性能 在当今快节奏的前端开发中,构建优化已成为提升开发效率和项目性能的关键环节。随着项目规模扩大,构建速度慢、打包体积过大等问题逐渐凸显,直接影响开发体验和用户体验。本文将分享几个前端…...

Phi-4-mini-reasoning模型部署与远程管理:MobaXterm高效连接与操作指南
Phi-4-mini-reasoning模型部署与远程管理:MobaXterm高效连接与操作指南 1. 引言 当你需要在远程服务器上部署和运行Phi-4-mini-reasoning这类AI模型时,一个高效的远程连接工具能让你事半功倍。MobaXterm作为一款集成了SSH、SFTP、X11服务器等多种功能的…...

软件测试面试宝典:Phi-4-mini-reasoning模拟面试官与测试用例设计
软件测试面试宝典:Phi-4-mini-reasoning模拟面试官与测试用例设计 1. 为什么需要AI模拟面试官 面试是每个软件测试工程师职业生涯中必须面对的挑战。传统准备方式往往面临几个痛点:找不到合适的练习伙伴、问题类型单一、无法获得即时反馈。而AI模拟面试…...

阿里开源OCR效果体验:万物识别在广告图识别中的实际表现
阿里开源OCR效果体验:万物识别在广告图识别中的实际表现 1. 引言 1.1 广告图识别的技术挑战 在数字营销领域,广告图是品牌传播的核心载体。一张优秀的广告图往往融合了创意文案、产品展示和视觉设计等多种元素。然而,这种图文混排的特性也…...

应届生面试:面试官最讨厌的5种回答
文章目录前言一、"我愿意学习" —— 最廉价的废话二、"这是组长分配的,我不知道为啥" —— 甩锅侠转世三、"我没什么特长,就是比较踏实" —— 凡尔赛式自卑四、答非所问,自说自话 —— 沉浸在自己的世界里五、…...