用于图像分类任务的经典神经网络综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net
📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️,如有错误敬请指正!
💕未来很长,值得我们全力奔赴更美好的生活!
前言
长期以来,计算机视觉一直是人工智能研究的关键领域之一。早期的图像处理方法通常基于手工设计的特征提取器,这在处理复杂任务时面临一些限制,随着深度学习的崛起,特别是深度神经网络的发展,计算机视觉领域发生了革命性的变化。深度学习的优势在于其能够学习从原始数据中提取有用特征的能力,而无需手动设计特征提取器,本文主要介绍在深度学习发展史中用于图像分类任务的经典神经网络。
文章目录
- 前言
- 一、图像分类任务介绍
- 二、基于卷积的网络
- 1. LeNet
- 2. AlexNet
- 3. VGG
- 4. GoogLeNet
- 5. ResNet
- 6. DenseNet
- 7. RepVGG
- 三、基于Transformer的网络
- 1. Vision Transformer
- 2. Swin Transformer
- 四、基于轻量化的网络
- 1. MobileNet
- 2. ShuffleNet
- 3. EfficientNet
- 五、PyTorch网络使用
一、图像分类任务介绍
图像分类任务指输入一张或多张图像。输出为将图像分配到一个或多个类别中。
一些关键概念:
类别: 预定义的目标类别,每个类别代表一种对象或场景。
训练集: 包含标注(类别信息)的图像集合,用于训练模型。
验证集和测试集: 用于评估模型性能的独立数据集。验证集用于调整模型超参数,测试集用于最终性能评估。
特征学习: 模型通过训练从数据中学习特征,这些特征有助于区分不同类别的图像。
模型评估指标: 通常包括准确率(正确分类的图像比例)、精确度(正类别中被正确分类的比例)、召回率(实际正类别中被正确分类的比例)等。
二、基于卷积的网络
1. LeNet
LeNet是由Yann LeCun等人于1998年提出的卷积神经网络(Convolutional Neural Network,CNN)架构,它是深度学习领域中最早成功应用于图像分类任务的模型之一。LeNet的设计旨在处理手写数字识别问题,特别是美国邮政服务的邮政编码识别项目。这个模型的提出对卷积神经网络的发展产生了深远的影响。

主要结构和组成部分:
-
输入层(Input Layer): LeNet最初被设计用于处理手写数字图像,因此输入层表示图像的像素。 -
第一层(第一个卷积层):卷积操作:提取输入图像的局部特征。Sigmoid激活函数:引入非线性。平均池化层:降低特征图的维度,减小计算量。 -
第二层(第二个卷积层):类似于第一层,包含卷积、激活和平均池化。 -
全连接层(Fully Connected Layers):将卷积层提取的特征映射到输出类别。采用Sigmoid激活函数。 -
输出层:通常是一个全连接层。Softmax激活函数用于将输出转换为类别概率分布。
2. AlexNet
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton等人于2012年设计的深度卷积神经网络,它在ImageNet大规模图像识别竞赛(ILSVRC)中取得了巨大的成功。这个模型标志着深度学习在计算机视觉领域的崛起,并成为后来深度卷积神经网络的开创者之一。

主要特点和结构:
-
深度: AlexNet是一个相对较深的神经网络,包含5个卷积层和3个全连接层。 -
卷积层和池化层:前两个卷积层后跟最大池化层,用于提取图像的特征。激活函数采用ReLU(Rectified Linear
Unit),这一选择在当时并不常见,但后来成为了深度学习中的常用激活函数。 -
局部响应归一化(Local Response Normalization):在激活层之后引入局部响应归一化层,这有助于抑制神经元的饱和度,增强模型的泛化性能。 -
Dropout:在全连接层中引入Dropout层,以减轻过拟合问题。Dropout通过在训练过程中随机关闭一些神经元来防止网络对特定数据过于依赖。 -
大规模并行计算:AlexNet的设计考虑到了大规模并行计算,通过分布在多个GPU上进行训练,这在当时是一项创新。
3. VGG
VGG(Visual Geometry Group)是由牛津大学的Visual Geometry Group在2014年提出的深度卷积神经网络架构。VGG以其简洁而规整的网络结构而闻名,对卷积层和池化层的堆叠使用非常规则的结构,使得整个网络非常容易理解和调整。

主要特点和结构:
-
深度和规整的结构:VGG网络非常深,有16或19个卷积层(根据不同的配置),并且所有的卷积层都是3x3的卷积核。这种深度和规整的结构有助于提取图像中的丰富特征。 -
小卷积核:VGG采用多个3x3的卷积核来替代一个较大的卷积核(如5x5或7x7)。这样的设计有助于增加非线性,提高网络的表达能力,并减少参数数量。 -
池化层:VGG网络中使用最大池化层,通过减小空间维度来降低计算复杂性。 -
全连接层:VGG在卷积层之后使用全连接层,将卷积层提取的特征映射到最终的输出。 -
激活函数:VGG使用ReLU(Rectified Linear Unit)作为激活函数,这对训练过程中的梯度流动和网络的收敛起到了积极的作用。 -
VGG16 和 VGG19:VGG16包含16个权重层,其中有13个卷积层和3个全连接层。VGG19是VGG的一个变种,包含19个权重层,其中有16个卷积层和3个全连接层。
4. GoogLeNet
GoogLeNet,也称为Inception v1,是由Google研究团队于2014年提出的深度卷积神经网络。它在ImageNet大规模图像识别竞赛(ILSVRC)中取得了显著的成功,并引入了"Inception"模块,该模块采用多尺度卷积核来提取不同层次的特征,使得网络更具表达能力。

主要特点和结构:
-
Inception 模块:Inception模块采用了不同大小的卷积核(1x1、3x3、5x5)和最大池化层,并将它们在同一层级进行堆叠。这有助于网络同时学习不同尺度的特征,提高了网络的表达能力。
1x1卷积核用于降维,减少计算量。这也可以看作是一种瓶颈结构(Bottleneck Structure)。 -
全局平均池化(Global Average Pooling):GoogLeNet采用全局平均池化层,取代了传统的全连接层。这有助于减少参数数量,降低过拟合风险,并使网络更具通用性。 -
辅助分类器:GoogLeNet在中间层添加了辅助分类器,用于提供额外的梯度信号,有助于缓解梯度消失问题,加速训练过程。 -
Batch Normalization:GoogLeNet引入了批量归一化(Batch Normalization),有助于提高网络的训练速度,增加网络的稳定性。
Inception 模块的示意图如下:
Input -> 1x1 Conv -> \-> Concatenate
Input -> 3x3 Conv -> /
Input -> 5x5 Conv -> \-> Concatenate
Input -> Max Pool -> /
-
Inception v1 (GoogLeNet): 这是最早的"Inception"版本,由Christian Szegedy等人在2014年提出。它引入了"Inception"模块,该模块使用多个不同大小的卷积核并行处理输入数据,从而提高了网络的效果。 -
Inception v2 (BN-Inception or Inception-BN): 也称为Batch Normalization Inception,这个版本在Inception v1的基础上引入了批量归一化(Batch Normalization),从而加速训练过程。 -
Inception v3: 这是"Inception"系列的第三个版本,引入了一些新的设计原则,如分解卷积(Factorized Convolutions)和更深的网络结构。它在识别精度和计算效率方面都有所提高。 -
Inception v4: 这个版本在Inception v3的基础上进行了改进,引入了一些额外的技巧,如残差连接(Residual Connections)和更深层次的网络结构。
5. ResNet
ResNet(Residual Network)是由微软研究院的Kaiming He等人在2015年提出的深度卷积神经网络结构。ResNet的设计突破了传统的深度神经网络的训练难题,通过引入残差学习(residual learning)机制,成功训练了非常深的网络,达到了当时的领先水平。

主要特点和结构:
残差学习:ResNet的关键创新是引入了残差块(Residual Block)或残差学习。在传统的卷积神经网络中,随着网络层数的增加,梯度逐渐变小,导致梯度消失问题。而残差学习通过引入跳跃连接(shortcut connection),允许网络学习残差(residual)而不是直接学习映射,从而有效解决了梯度消失问题。
残差块结构:残差块通常包括两个卷积层,每个卷积层之间有一个跳跃连接。残差块的结构可以用数学公式表示为:
o u t p u t = i n p u t + F ( i n p u t ) output=input+F(input) output=input+F(input)
其中 F ( i n p u t ) F(input) F(input)是卷积层的输出。
-
堆叠残差块:ResNet通过堆叠多个残差块来构建深度网络。深度网络的训练变得更加容易,因为残差学习机制减缓了梯度逐层传播的消失问题。 -
全局平均池化:与GoogLeNet类似,ResNet使用全局平均池化层替代全连接层,以减少参数数量。 -
批量归一化和ReLU激活:ResNet中广泛使用批量归一化(Batch Normalization)和ReLU激活函数,有助于提高网络的训练速度和稳定性。
6. DenseNet
DenseNet(Densely Connected Convolutional Networks)是由李飞飞等人于2017年提出的深度卷积神经网络架构。DenseNet的关键创新是在网络的设计中引入了密集连接(dense connectivity)的概念,即每一层都与前面所有层直接相连,使得网络具有更加紧密的信息流动,有效地缓解了梯度消失问题。

主要特点和结构:
-
密集连接(Dense Connectivity):DenseNet中每一层都与前面所有层直接相连,每一层接收来自前面所有层的特征图作为输入。这种密集连接的结构有助于保持更多的特征信息,并促使梯度更容易传播。 -
稠密块(Dense Block):DenseNet的主要构建单元是稠密块,每个稠密块包含多个密集连接的卷积层。在每个卷积层之后,都将其输出与前面层的输出连接起来,形成密集连接。 -
过渡块(Transition Block):在稠密块之间引入过渡块,通过使用1x1卷积层和平均池化层来减小特征图的尺寸。这有助于控制网络的复杂度,减少计算量。 -
全局平均池化:与其他一些先进的网络一样,DenseNet采用全局平均池化来替代全连接层,减少参数数量,提高网络的泛化能力。 -
批量归一化和ReLU激活:DenseNet中广泛使用批量归一化和ReLU激活函数,有助于提高网络的训练速度和稳定性。
7. RepVGG
RepVGG(Reparameterized VGG)是由Microsoft Research提出的一种卷积神经网络架构,旨在结合VGG的简单结构和ResNet的强大性能。RepVGG通过重新参数化卷积层,使得网络具有VGG风格的简单性,同时保留了ResNet中的残差连接,提高了网络的性能。

RepVGG 主要特点和结构:
-
重新参数化的卷积层:RepVGG使用了重新参数化的卷积层,将卷积核的权重分解成两个部分:一个是可学习的,一个是固定的。这种设计简化了卷积层的计算,同时保持了一定的灵活性。 -
ResNet 风格的残差连接:RepVGG引入了ResNet风格的残差连接,使得网络能够更有效地传递梯度、缓解梯度消失问题,并加速了训练过程。 -
简单且有效的结构:RepVGG的整体结构类似于VGG,由多个卷积层和全连接层组成,具有简单、易理解的特点,同时在性能上具备了一定的深度学习模型的优势。 -
端到端可训练:RepVGG 是一个端到端可训练的网络结构,可以通过梯度下降来学习网络中所有的参数。
三、基于Transformer的网络
1. Vision Transformer
Vision Transformer(ViT)是一种基于注意力机制的图像分类网络,由Alexey Dosovitskiy等人在2020年提出。相比于传统的卷积神经网络(CNNs),ViT采用了全注意力机制,将输入图像分割成一系列的图像块(patches),并通过自注意力机制捕捉图像全局信息。 ViT是一种在图像分类任务上取得显著成功的全新方法,它改变了传统卷积神经网络的范式,通过自注意力机制更灵活地捕捉图像中的关系。

主要特点和结构:
-
图像块的表示:输入图像被分割成固定大小的图像块(patches)。每个图像块被视为一个向量,这样整个图像就被表示为一个序列。 -
位置嵌入(Position Embeddings):为了捕捉序列中的位置信息,ViT引入了位置嵌入。这些位置嵌入向量被加到图像块的表示中,以便模型学习到图像中不同位置的关系。 -
多头注意力机制:ViT使用了多头注意力机制,允许模型关注图像中不同区域的信息。每个注意力头都学习到了图像块之间的关系,有助于捕捉全局信息。 -
全连接层(MLP):在多头注意力机制之后,ViT采用了全连接层(多层感知机,MLP)来进一步提取特征。这一部分被称为MLP处理块。 -
层归一化和残差连接:每个MLP处理块后都进行了层归一化和残差连接,以提高模型的训练稳定性。 -
全局池化:最终的序列表示经过全局平均池化,得到整个图像的表示。
2. Swin Transformer
Swin Transformer是一种用于图像分类任务的变种Transformer架构,由微软亚洲研究院在2021年提出。Swin Transformer采用了分层的局部注意力机制和窗口化的注意力机制,以处理大尺寸输入图像,并取得了在图像分类任务上的卓越性能。

主要特点和结构:
-
分层的局部注意力机制:Swin Transformer引入了分层的局部注意力机制,将输入图像分割成非重叠的块,并在每个块内部执行局部注意力,以处理大尺寸输入。 -
窗口化的注意力机制:Swin Transformer使用窗口化的注意力机制,即在每个块中只与相邻的块进行注意力交互,从而减少了计算复杂性。 -
交换操作(Shift Operation):为了促进图像信息的交流,Swin Transformer引入了交换操作,即在不同块之间进行位置的平移,有助于捕捉图像中的全局信息。 -
层次结构:Swin Transformer采用了层次结构,包含多个Swin Transformer块。每个Swin Transformer块中包含分层的局部注意力、窗口化的注意力、交换操作等模块。 -
跨层连接:Swin Transformer中引入了跨层连接,允许低层特征直接连接到高层特征,促进特征的信息流动。 -
多尺度特征:Swin Transformer通过采用多层次的注意力机制,能够处理多尺度的特征,使得模型对于不同尺度的物体具有更强的感知能力。
四、基于轻量化的网络
1. MobileNet
MobileNet是由Google在2017年提出的一系列轻量级神经网络架构,旨在在计算资源有限的移动设备上实现高效的图像分类和目标检测。MobileNet的设计目标是在保持较高的性能的同时,大幅减少参数数量和计算复杂度,使得它适用于嵌入式设备和移动端应用。
MobileNet的核心思想是采用深度可分离卷积(depthwise separable convolution)代替传统的标准卷积操作,以减少模型中的参数数量。深度可分离卷积将标准卷积分为两步:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。

MobileNet 主要特点和结构:
-
深度可分离卷积:深度可分离卷积分为两步:深度卷积对每个输入通道执行卷积,然后通过逐点卷积将其映射到输出通道。这一操作降低了计算复杂度,减少了参数数量。 -
宽度乘数(Width Multiplier):MobileNet引入了宽度乘数,允许用户控制每一层网络的宽度。通过减少中间层的通道数,可以在不显著损失性能的情况下减小网络的大小。 -
分辨率乘数(Resolution Multiplier):MobileNet还引入了分辨率乘数,允许用户缩小输入图像的分辨率。降低分辨率可以减少计算量,但可能损失一些图像细节。 -
全局平均池化:MobileNet通常使用全局平均池化层替代全连接层,以减少参数数量。 -
线性瓶颈:在每个深度可分离卷积的逐点卷积之前,MobileNet采用了线性激活函数(没有非线性变换),以提高模型的表达能力。 -
MobileNetV1(2017): 第一个MobileNet版本,采用了深度可分离卷积,成功地在移动设备上实现了高效的图像分类。 -
MobileNetV2(2018): 引入了倒残差结构(inverted residual structure),在V1的基础上进一步改进。此版本通过使用残差连接和线性瓶颈来提高性能。 -
MobileNetV3(2019): 进一步改进MobileNetV2,引入了更多的优化和设计改进,如可分离卷积的非线性激活、更大的网络输入尺寸、更精细的网络宽度调整等。
2. ShuffleNet
ShuffleNet是由微软亚洲研究院于2018年提出的一种轻量级神经网络结构,旨在在计算资源受限的移动设备上实现高效的图像分类和目标检测。ShuffleNet的设计注重在减小计算复杂度和参数数量的同时,保持较高的模型性能。
ShuffleNet的主要特点是通过引入分组卷积和通道重排操作来减少计算复杂度。分组卷积将输入通道分为若干组,每组进行独立的卷积计算,然后将结果拼接在一起。通道重排操作则用于对通道进行重新排列,从而增强信息的传递。
ShuffleNet 主要特点和结构:

-
分组卷积:ShuffleNet引入了分组卷积,将输入通道分为多个组,每个组进行独立的卷积操作。这有助于降低计算复杂度和参数数量。 -
通道重排(Channel Shuffle):通道重排操作将输入通道进行重新排列,以增强信息的传递。这一操作在分组卷积之后进行,有助于促进不同组之间的信息交流。 -
逐点卷积(Pointwise Convolution):ShuffleNet使用逐点卷积(1x1卷积)来调整通道数量,使得网络更加灵活,同时减少参数数量。 -
基础单元(ShuffleNet Unit):ShuffleNet的基础单元包括分组卷积、通道重排、逐点卷积和批量归一化等操作。多个基础单元的堆叠构成了整个网络。 -
全局平均池化:与其他一些轻量级网络一样,ShuffleNet通常使用全局平均池化层替代全连接层,以减少参数数量。 -
ShuffleNetV1(2018): 第一个版本,引入了分组卷积和通道重排的概念,取得了较好的性能。 -
ShuffleNetV2(2018): 在ShuffleNetV1的基础上进行改进,引入了更多的特征通道重排和新的网络结构设计。ShuffleNetV2进一步减小了计算复杂度,提升了性能。
3. EfficientNet
EfficientNet是由谷歌研究团队在2019年提出的一种高效且性能优越的卷积神经网络架构。EfficientNet的设计目标是在给定计算资源的情况下,取得更好的性能,同时充分考虑了网络的深度、宽度和分辨率等因素。
EfficientNet的设计基于三个主要组件:宽度乘数(width multiplier)、深度乘数(depth multiplier)和分辨率乘数(resolution multiplier)。这些乘数允许用户在不同方向上对网络进行缩放,以满足不同的性能和计算资源需求。

EfficientNet 主要特点和结构:
-
宽度乘数(Width Multiplier):宽度乘数控制每一层网络的通道数,即每个卷积层的宽度。通过调整宽度乘数,可以在不改变模型深度的情况下减小或增大模型的计算复杂度。 -
深度乘数(Depth Multiplier):深度乘数控制网络的层数。通过调整深度乘数,可以在不改变模型宽度的情况下减小或增大模型的计算复杂度。 -
分辨率乘数(Resolution Multiplier):分辨率乘数控制输入图像的分辨率。通过调整分辨率乘数,可以在不改变模型深度和宽度的情况下减小或增大模型的计算复杂度。 -
复合缩放系数(Compound Scaling):EfficientNet采用复合缩放系数,同时调整宽度、深度和分辨率,以获得更好的性能。复合缩放系数的提出是为了综合考虑这三个方向上的缩放效果。 -
MBConv(MobileNetV2-like Bottleneck Block):EfficientNet中使用了一种称为MBConv(MobileNetV2-like Bottleneck Block)的块作为基础单元,该块结合了深度可分离卷积和残差连接。
五、PyTorch网络使用
torchvision.models 模块是 PyTorch 中用于定义和加载预训练模型的模块。它提供了许多经典的图像分类、目标检测、图像生成等深度学习模型的实现。这些模型已经在大规模图像数据集上进行了预训练,可以用于各种计算机视觉任务。
下面以ResNet为例简单说明 torchvision.models 模块中图像分类网络的使用示例:
import torch
import torchvision.transforms as transforms
from torchvision.models import resnet50# 示例输入图像(需要调整为你的图像路径)
image_path = 'path/to/your/image.jpg'# 预处理图像
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),
])image = transform(Image.open(image_path)).unsqueeze(0)# 创建 ResNet50 模型
model = resnet50(pretrained=True)# 将模型设置为评估模式
model.eval()# 进行预测
with torch.no_grad():output = model(image)# 打印预测结果
print(torch.argmax(output[0]).item())文中图片大多来自论文和网络,如有侵权,联系删除,文中有不对的地方欢迎指正。
参考:
Rawat W, Wang Z. Deep convolutional neural networks for image classification: A comprehensive review[J]. Neural computation, 2017, 29(9): 2352-2449.
Chen L, Li S, Bai Q, et al. Review of image classification algorithms based on convolutional neural networks[J]. Remote Sensing, 2021, 13(22): 4712.
相关文章:
用于图像分类任务的经典神经网络综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…...

Linux如何查找某个路径下大于1G的文件
find 命令可以用于在 Linux 或 macOS 系统中查找文件和目录。如果你想查找大于1GB的文件,可以使用 -size 选项结合 参数。以下是一个示例: find /path/to/search -type f -size 1G这里的 /path/to/search 是你要搜索的目录的路径。这个命令将查找该目录…...
Java二级医院区域HIS信息管理系统源码(SaaS服务)
一个好的HIS系统,要具有开放性,便于扩展升级,增加新的功能模块,支撑好医院的业务的拓展,而且可以反过来给医院赋能,最终向更多的患者提供更好的服务。 系统采用前后端分离架构,前端由Angular、J…...
定义Token)
自制编程语言(第三弹)定义Token
终于到了激动人心的实现时候了。为了实现我们的自制语言,我们需要的步骤为: 词法分析语法分析语义分析(此处不设置)解释器 详细完整的代码可以点击这里查看github项目。 词法分析: 将代码片段识别为关键词、标识符、…...

linux下的工具---yum
一、什么是yum yum是Linux下的软件包管理器 二、什么是软件包管理器 1、在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序. 2、但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在…...
)
java全局异常处理(springboot)
介绍: 在日常项目开发中,异常是常见的,但是如何更高效的处理好异常信息,让我们能快速定位到BUG,是很重要的,不仅能够提高我们的开发效率,还能让你代码看上去更舒服,SpringBoot的项目…...
JAVA将PDF转图片
前言 当今时代,PDF 文件已经成为了常用的文档格式。然而,在某些情况下,我们可能需要将 PDF 文件转换为图片格式,以便更方便地分享和使用。这时,我们可以使用 Java 编程语言来实现这个功能。Java 提供了许多库和工具&a…...
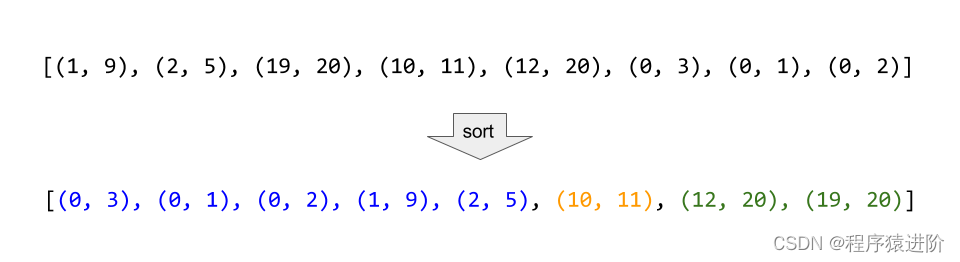
合并区间[中等]
一、题目 以数组intervals表示若干个区间的集合,其中单个区间为intervals[i] [starti, endi]。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。 示例 1: 输入:intervals […...

MYSQL基础知识之【LIKE子句的使用 ,NULL值的处理,空值的处理】
文章目录 前言MySQL LIKE 子句在PHP脚本中使用 LIKE 子句 MySQL NULL 值处理在命令提示符中使用 NULL 值使用PHP脚本处理 NULL 值 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:Mysql 🐱👓博主在前端领域还有…...

线索二叉树:C++实现
引言: 线索二叉树是一种特殊的二叉树,它可以通过线索(线索是指在二叉树中将空指针改为指向前驱或后继的指针)的方式将二叉树转化为一个线性结构,从而方便对二叉树进行遍历。本文将介绍如何使用C实现线索二叉树。 技术…...

C++——vector互换容器与预留空间
一.vector互换容器 功能描述:实现两个容器内元进行互换 函数原型: swap(vec); //将vec与本身的元素互换 实例: //1.基本使用 void test01() {vector<int>v1;for (int i 0; i < 10; i){v1.push_back(i);}cout << "交换前:" << e…...
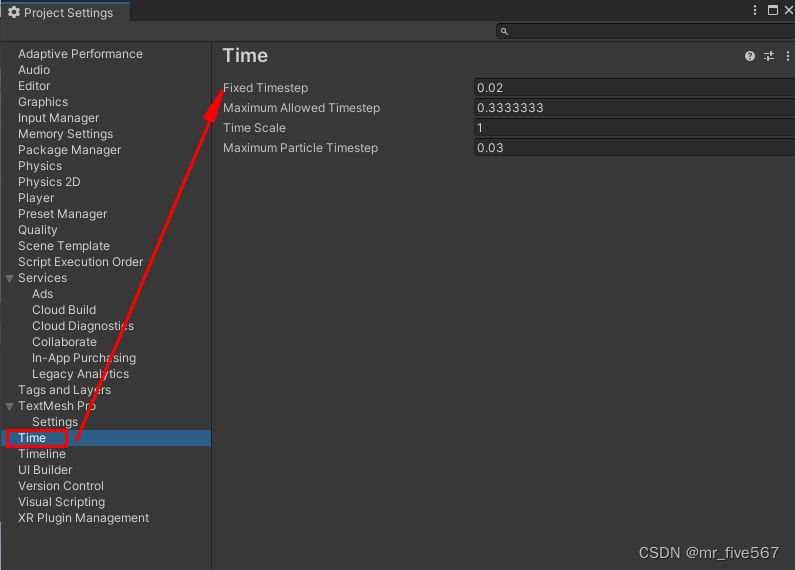
Unity 自带的一些可以操控时间的属性或方法。
今天来总结下Unity自带的一些可以操控时间的方法。 1、Time.time。比较常用计算运行时间而触发特定事件。 public class Controller : MonoBehaviour {public float eventTime 5f; // 触发事件的时间private float startTime; // 游戏开始的时间private void Start(){startT…...

vue 项目中使用 mqtt
1、在html 中用cdn方式引入 <script src"https://unpkg.com/mqtt/dist/mqtt.min.js"></script> 2、封装代码 mqtt_connect.js // import * as mqtt from mqtt/dist/mqtt.min // 不知道为什么 我用引入的方式不成,就在html 用的cdn方式接入了…...
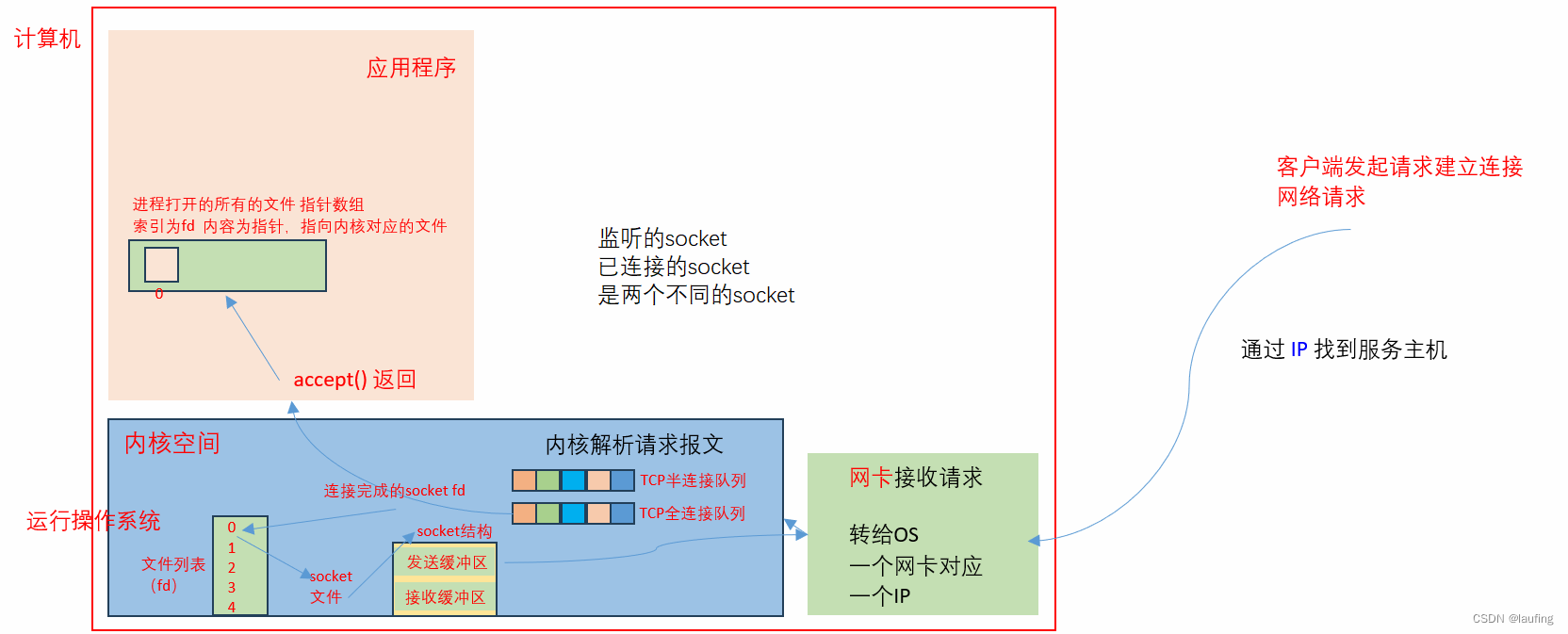
linux shell操作 - 05 进程 与 IO 模型
文章目录 计算机内存分配进程与子进程流IO模型非阻塞IOIO多路复用网络IO模型简单的socket并发的socket 计算机内存分配 一个32位,4G内存的计算机,内存使用分为两部分: 操作系统内核空间;应用程序的用户空间使用的操作系统不同&a…...

让SOME/IP运转起来——SOME/IP系统设计(下)之数据库开发
上一篇我们介绍了SOME/IP矩阵的设计流程,这一篇重点介绍如何把SOME/IP矩阵顺利的交给下游软件团队进行开发。 车载以太网通信矩阵开发完成后,下一步应该做什么? 当我们完成SOME/IP矩阵开发,下一步需要把开发完成的矩阵换成固定格…...

Mybatis反射工厂类DefaultReflectorFactory
DefaultReflectorFactory是反射工厂接口ReflectorFactory的默认实现,其主要是实现了对反射对象Reflector的创建和缓存。 有三个方法: // 判断是否开启缓存boolean isClassCacheEnabled();// 设置是否缓存void setClassCacheEnabled(boolean classCacheEn…...

antDesignPro a-table样式二次封装
antDesignPro是跟element-ui类似的一个样式框架,其本身就是一个完整的后台系统,风格样式都很统一。我使用的是antd pro vue,版本是1.7.8。公司要求使用这个框架,但是UI又有自己的一套设计。这就导致我需要对部分组件进行一定的个性…...
找免费4K高清图片素材,就上这6个网站
使用图片素材怕侵权?那就上这6个网站,免费下载,4K高清无水印,赶紧收藏起来~ 1、菜鸟图库 https://www.sucai999.com/pic.html?vNTYxMjky 一个很大的素材库,站内主要还是以设计素材为主,像图片素材就有上百…...
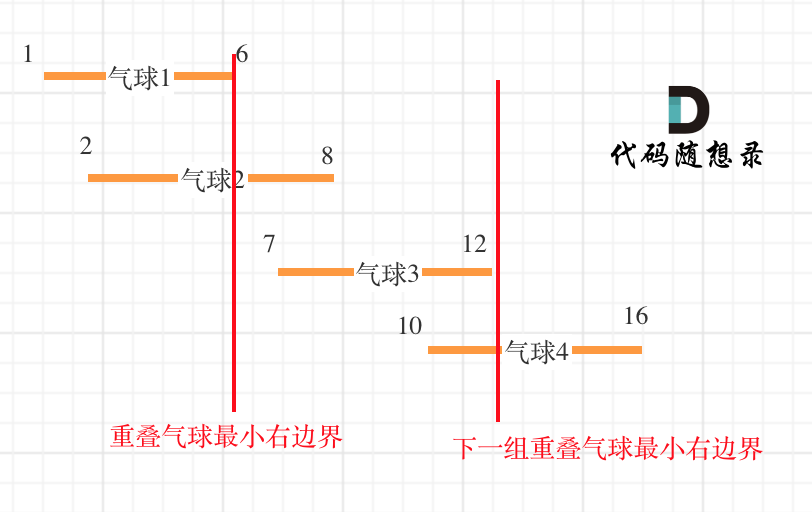
代码随想录算法训练营第35天| 860.柠檬水找零 406.根据身高重建队列 452. 用最少数量的箭引爆气球
JAVA代码编写 860.柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须…...
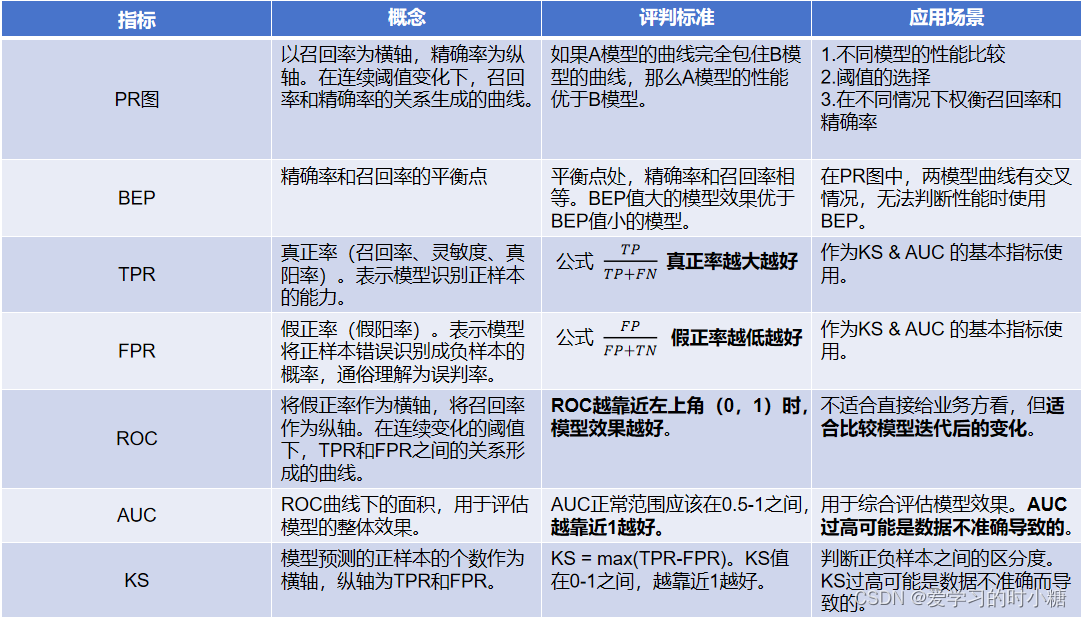
成为AI产品经理——TPR、FPR、ROC、AUC
目录 一、PR图、BEP 1.PR图 2.BEP 二、灵敏度、特异度 1.灵敏度 2.特异度 三、真正率、假正率 1.真正率 2.假正率 三、ROC、AUC 1.ROC 2.AUC 四、KS值 一、PR图、BEP 1.PR图 二分类问题模型通常输出的是一个概率值,我们需要设定一个阈值ÿ…...

E-Ink Launcher终极指南:电子墨水屏启动器的完整配置教程
E-Ink Launcher终极指南:电子墨水屏启动器的完整配置教程 【免费下载链接】E-Ink-Launcher E-reader Launcher for Android, Electronic paper book... 项目地址: https://gitcode.com/gh_mirrors/ei/E-Ink-Launcher E-Ink Launcher是一款专为电子墨水屏设备…...

避坑指南:GPUStack纳管昇腾NPU时,Worker状态Not Ready?先检查chronyd时间同步!
GPUStack纳管昇腾NPU实战:从时间同步异常到Worker节点状态修复全解析 当你在深夜收到告警通知,发现GPUStack集群中某个昇腾NPU Worker节点突然变成"Not Ready"状态时,那种焦虑感我深有体会。特别是在生产环境中,这类问题…...

隐私安全首选:DeepSeek-R1本地推理引擎快速上手指南
隐私安全首选:DeepSeek-R1本地推理引擎快速上手指南 1. 为什么选择本地推理引擎 在当今数据安全日益重要的时代,越来越多的用户开始关注AI应用的隐私保护问题。传统的云端AI服务虽然功能强大,但存在数据外泄的风险,尤其对于处理…...

零基础极速上手:用AI建站工具10分钟生成你的第一个网站
痛点与目标看着别人轻松拥有自己的品牌官网,你是不是也心动了,却因为不懂代码、不会设计、预算有限而迟迟没动手?别担心,搭建专业网站的门槛已经被新一代的AI生成网站工具彻底打破了。即使你完全不懂技术,也能在10分钟…...

基于MPC与事件触发通信的多智能体协同路径跟踪代码功能说明
无人船编队 无人车编队 MPC 模型预测控制 多智能体协同控制 一致性 MATLAB 无人车 USV 带原文献一、代码整体架构与核心目标 1. 核心目标 本套MATLAB源码针对多智能体协同路径跟踪(Cooperative Path Following, CPF) 问题,实现了受输入约束&a…...

Android RTMP推流实战:从零搭建Nginx服务器到实现摄像头直播
1. 环境准备:搭建Nginx-RTMP服务器 第一次接触直播服务器搭建时,我对着命令行界面手足无措的样子还历历在目。现在回头看,其实用Nginx搭建RTMP服务器就像组装乐高积木,只要按步骤来就能成功。这里我推荐在Ubuntu系统上操作&#x…...

别让Windows驱动变成“空间刺客“!Driver Store Explorer轻松拯救你的C盘
别让Windows驱动变成"空间刺客"!Driver Store Explorer轻松拯救你的C盘 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的C盘是不是经常莫名其妙变红࿱…...

Janus-Pro-7B在AIGC内容创作中的惊艳效果:多风格图文生成案例集
Janus-Pro-7B在AIGC内容创作中的惊艳效果:多风格图文生成案例集 最近在折腾各种AI模型的时候,我深度体验了一把Janus-Pro-7B。说实话,一开始我对“多模态”这个词有点审美疲劳了,感觉很多模型宣传得天花乱坠,用起来却…...

Pyenv vs Miniconda vs Anaconda:Python环境管理实战对比
1. Python环境管理工具全景概览 刚接触Python开发时,最让我头疼的就是环境配置问题。同一个项目在不同电脑上跑出不同结果,安装包时各种依赖报错,这些经历相信很多开发者都遇到过。Python环境管理工具就是为解决这些问题而生的,它…...

Qwen3-TTS-Tokenizer-12Hz入门到精通:掌握音频编解码核心操作
Qwen3-TTS-Tokenizer-12Hz入门到精通:掌握音频编解码核心操作 1. 音频编解码技术概述 1.1 什么是音频编解码器 音频编解码器是将音频信号在数字域进行压缩和还原的技术组件。它通过特定的算法将原始音频数据转换为更紧凑的表示形式(编码)&…...