Linux系统编程 day06 进程间通信
进程间通信
- 1. 进程间通信的概念
- 2. 匿名管道pipe
- 3. 命名管道FIFO
- 4. 内存映射区
1. 进程间通信的概念
在Linux的环境下,进程地址空间是相互独立的,每个进程有着各自不同的用户地址空间。一个进程不能访问另一个进程中的内容,要进行数据交换必须要通过内核,在内核中开辟块缓冲区,一个进程将数据从用户空间拷贝到内核缓冲区中,另一个进程从内核缓冲区中将数据读走。内核提供的这种机制称为进程间通信(IPC)。
在进程间完成数据传输需要借助操作系统提供的特殊方法,比如文件、管道、FIFO、内存映射区、消息队列、信号、套接字等。如今常用的进程间通信主要有管道(最简单)、信号(开销最小)、内存映射区(无血缘关系)、本地套接字(最稳定)。
2. 匿名管道pipe
管道是一种最基本的进程间通信机制,也称为匿名管道,应用于有血缘关系的进程间进行通信。管道的本质是一块内核缓冲区,内部使用的环形队列实现,由两个文件描述符进行引用,其中一个表示读端,另一个表示写端。管道的数据从管道的写端流入管道,从读端流出。当两个进程都死亡的时候,管道也会自动消失。管道不管读端还是写端默认都是阻塞的。管道的默认缓冲区大小为4K,可以使用ulimit -a命令获取大小。
管道的数据一旦被读走,便不在管道中存在,不可以反复读取。管道的数据只能在一个方向上流动,如果需要实现双向流动则需要使用两个管道。匿名管道只能在有血缘关系的进程中使用。我们用pipe函数来创建管道。
pipe函数的原型如下:
#include <unistd.h>int pipe(int pipefd[2]); // 创建管道其中pipefd为管道写端和读端的文件描述符,其中pipefd[0]为管道读端的文件描述符,pipefd[1]为管道写端的文件描述符。当函数调用成功创建了管道返回0,失败则返回-1并设置errno。
在使用匿名管道进行通信的时候,一般是先用pipe函数创建管道,再使用fork函数创建子进程。这样父子进程就具有了相同的文件描述符,就会指向同一个管道。
在管道的通信中,读写数据也是使用read和write。管道的示例代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <string.h>int main()
{// 创建管道//int pipe(int pipefd[2]);int fd[2];int ret = pipe(fd);if(ret < 0){perror("pipe error");return -1;}// 创建子进程pid_t pid = fork();if(pid < 0){perror("fork error");return -1;}else if(pid == 0){// 子进程关闭写端close(fd[1]);char buf[1024];memset(buf, 0x00, sizeof(buf));sleep(5);read(fd[0], buf, sizeof buf);printf("child: read over, pid = [%d], fpid = [%d], buf = [%s]\n", getpid(), getppid(), buf);}else{// 父进程关闭读端close(fd[0]);write(fd[1], "helloworld", strlen("helloworld"));printf("father: write over, pid = [%d], fpid = [%d]\n", getpid(), getppid());pid_t wpid = wait(NULL);printf("child [%d] is dead!\n", wpid);}return 0;
}
在shell中我们查询某一个进程的时候我们会使用ps -ef | grep --color=auto bash,这里的|就是管道。我们使用父进程进程去执行ps -ef命令,由于我们需要交给grep去作为输入,所以在父进程中需要将输出重定向到管道的写端。子进程执行grep的时候会从输入进行读取内容,因此我们需要将输入重定向到管道读端。重定向的时候需要使用dup2函数,需要执行命令则需要使用execl和execlp函数,示例程序如下:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>int main()
{// 创建管道int pipefd[2];int ret = pipe(pipefd);if(ret < 0){// 创建失败perror("pipe error");return -1;}// 创建子进程pid_t pid = fork();if(pid < 0){// 创建失败perror("fork error");return -1;}else if(pid == 0){// 子进程关闭写端close(pipefd[1]);// 将标准输入重定向到管道读端dup2(pipefd[0], STDIN_FILENO);execlp("grep", "grep", "--color=auto", "bash", NULL);perror("execlp error");}else {// 父进程关闭读端close(pipefd[0]);// 将标准输出重定向到管道写端dup2(pipefd[1], STDOUT_FILENO);execlp("ps", "ps", "-ef", NULL);perror("execlp error");}return 0;
}
当管道有数据的时候,read可以正常读,并返回读出来的字节数;当管道没有数据的时候,若写端全部关闭,则read函数解出阻塞状态,返回0,相当于读文件读到了尾部。若写端没有关闭,则read阻塞。
若读端全部关闭,进行写操作的时候则管道会破裂,进程终止,内核会给当前进程发送SIGPIPE信号。若读端没有完全关闭,缓冲区写满了则write会阻塞,缓冲区没有满则可以继续write。
管道默认两端都是阻塞的,若要设置为非阻塞,则可以使用前面提过的fcntl函数。首先使用F_GETFL获取flags,然后在添加O_NONBLOCK使用F_SETFL设置即可。当读端设置为非阻塞状态的时候,会有以下四种情况:
- 写端没有关闭,管道中没有数据可读,则
read返回-1。 - 写端没有关闭,管道中有数据可读,则
read返回实际读到的字节数。 - 写端已经关闭,管道中有数据可读,则
read返回实际读到的字节数。 - 写端已经关闭,管道中没有数据可读,则
read返回0。
设置的流程为:
int flags = fcntl(fd[0], F_GETFL, 0);
flags = flags | O_NONBLOCK;
fcntl(fd[0], F_SETFL, flags);
除了前面使用的ulimit -a可以查看到管道缓冲区的大小之外,也可以使用fpathconf函数,该函数的原型为:
#include <unistd.h>long fpathconf(int fd, int name);
这个函数会根据name的参数设置返回文件描述符fd对应文件的配置内容。比如获取管道缓冲区则需要把name设置为_PC_PIPE_BUF。如下面查看管道的缓冲区大小。
printf("pipe size = [%ld]\n", fpathconf(fd[0], _PC_PIPE_BUF));
printf("pipe size = [%ld]\n", fpathconf(fd[1], _PC_PIPE_BUF));
更多的name参数设置可以使用man fpathconf查询帮助文档。
3. 命名管道FIFO
使用pipe管道只能实现有血缘关系的两个进程间的通信,那么对于两个没有血缘关系的进程又应该怎么实现呢?则需要这一节的命名管道FIFO。
FIFO是Linux上基于文件类型的一种通信方式,文件类型为p,但是FIFO在磁盘上并没有数据块,文件大小为0,仅仅用于标识内核中的一条通道。进程可以通过read或者write函数去对这一条通道进行操作,也就是内核缓冲区,这样就实现了进程间的通信。
要使用命名管道,就得先创建命名管道文件,创建管道文件使用mkfifo函数,该函数的原型为:
#include <sys/types.h>#include <sys/stat.h>int mkfifo(const char *pathname, mode_t mode);其中参数第一个pathname表示管道的路径名,mode表示权限,使用一个三位八进制数表示。创建成功函数返回0,创建失败则函数返回-1并设置errno。
FIFO严格遵守先进先出的规则,也就是对于管道的读总是从管道的开始处返回数据,而对于管道的写则是添加到末尾。因此命名管道不支持使用lseek等对文件定位的操作。
使用FIFO完成进程间通信的示意图如下:
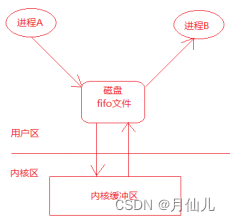
既然是两个进程,也就是说两个进程中的程序都需要打开管道,也就是需要找到文件。若写进程没有打开就去使用读进程,则可能因为管道的文件不存在而报错。因此我们在使用管道或者创建管道之前要先判断文件是否存在。这个可以使用access函数实现,该函数的原型为:
#include <unistd.h>int access(const char *pathname, int mode);该函数的第一个参数pathname是文件的路径,第二个参数mode表示要测试的模式,有四个参数可以传,分别为:
F_OK: 文件存在R_OK:有读权限W_OK:有写权限X_OK:有执行权限
当有对应的权限或者文件存在的时候,该函数的返回值为0,若没有对应权限或者文件不存在则该函数返回-1。
接下来我们实现两个无血缘关系之间的进程间通信。代码如下:
fifo_write.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>// FIFO 写进程
int main()
{// 创建FIFO文件// int access(const char *pathname, int mode);int ret = access("./myfifo", F_OK);if(ret < 0){// int mkfifo(const char *pathname, mode_t mode);ret = mkfifo("./myfifo", 0777);if(ret < 0){perror("mkfifo error");return -1;}}// 打开FIFOint fd = open("./myfifo", O_RDWR);if(fd < 0){perror("open error");return -1;}// 传输数据char buf[1024] = "hello world";write(fd, buf, strlen(buf));sleep(1);// 关闭FIFOclose(fd);return 0;
}fifo_read.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>// FIFO 读进程端
int main()
{// 判断创建FIFOint ret = access("./myfifo", F_OK);if(ret < 0){int ret = mkfifo("./myfifo", 0777);if(ret < 0){perror("mkfifo error");return -1;}}// 打开FIFOint fd = open("./myfifo", O_RDWR);if(fd < 0){perror("open error");return -1;}// 接收数据char buf[1024];memset(buf, 0x00, sizeof buf);read(fd, buf, sizeof buf);printf("%s\n", buf);// 关闭FIFOclose(fd);return 0;
}在上述代码中,只要运行,不管是读进程还是写进程先运行,只要写进程没有往管道中写数据,读进程都会阻塞在read处。直到写进程调用write函数往管道中写数据之后读进程才会读出来管道中的数据输出。
4. 内存映射区
内存映射区是将一个磁盘文件与内存空间的一个缓冲区向映射。当我们在缓冲区中读取数据的时候,就相当于在文件中读取相应的字节。若我们向缓冲区中写数据,则会把数据写入对应的文件之中。这样就可以在不使用read函数和write函数啊的情况下使用指针完成IO操作。
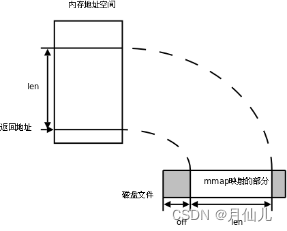
映射这个过程可以使用mmap函数实现。解除映射可以使用munmap实现。函数的原型以及参数如下:
#include <sys/mman.h>// 函数作用: 建立存储映射区// 返回值: 成功:返回创建的映射区首地址// 失败: 返回MAP_FAILED宏, 实际上就是(void *)-1// 参数: addr: 指定映射的起始地址,通常设为NULL,由系统指定// length: 映射到内存的文件长度// prot: 映射区的保护方式,最常用的有// PROT_READ 读// PROT_WRITE 写// PROT_READ | PORT_WRITE 读写// flags: 映射区的特性,可以设置以下// MAP_SHARED 写入映射区的数据会写回文件,且允许// 其它映射改文件的进程共享。// MAP_PRIVATE 对映射区的写入操作会产生一个映射区的复// 制,对此区域所做的修改不会写回原文件。// MAP_ANONYMOUS 匿名映射区,需要结合MAP_SHARED使用。// fd: 代表要映射的文件,由open函数返回的文件描述符// offset: 以文件开始出的偏移量,必须是4K的整数倍,通常为0,表示// 从文件头开始映射void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);// 函数作用: 释放由mmap函数建立的存储映射区// 返回值: 成功返回0,失败返回-1并设置errno// 参数: addr: 调用mmap函数成功返回的映射区首地址// length: 映射区的大小int munmap(void *addr, size_t length);
需要注意到的是,mmap函数不能开辟长度为0的存储映射区。在使用mmap函数创建映射区的过程中,隐含着一次对映射文件的读操作,将文件读取到映射区。当我们将flags设置为MAP_SHARED的时候,要求映射区的权限应该小于或者等于文件打开的权限,这是出于对映射区的保护。而对于MAP_PRIVATE,则是没有这个必要,因为mmap中的权限是对内存的限制。
在映射区建立之后,映射区的释放是与文件的关闭无关的,所以在映射区建立之后就可以关闭文件。在创建映射区的时候,使用mmap函数常常会出现总线错误,通常是因为共享文件存储空间大小引起的。所以创建映射区的时候出错的概率比较高,因此一定要检查函数的返回值,确保映射区建立成功了再进行后续的操作。使用munmap函数的时候,传入的地址一定要是mmap函数的返回值,一定不要改变指针的指向。其中函数的参数中offset也是需要注意的,不能随便指定,必须要是4K的整数倍才行。
下面给出一个关于关于有血缘关系的进程间的通信示例。
//使用mmap完成有血缘关系进程间的通信
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <unistd.h>
#include <fcntl.h>int main()
{//使用mmap函数建立共享映射区//void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);int fd = open("test.log", O_RDWR);if(fd < 0){perror("open error");return -1;}int len = lseek(fd, 0, SEEK_END);void *addr = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);if(addr == MAP_FAILED){perror("mmap error");return -1;}close(fd);//创建子进程pid_t pid = fork();if(pid < 0){perror("fork error");return -1;}else if(pid == 0){//子进程sleep(2);char *p = (char *)addr;printf("[%s]\n", p);}else{//父进程memcpy(addr, "hello world", strlen("hello world"));wait(NULL);}return 0;
}共享存储映射区也可以用于没有血缘关系的两个进程。
写进程
// 使用mmap完成没有血缘关系的进程间的通信
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/mman.h>// 写进程
int main()
{// 使用mmap函数建立共享映射区int fd = open("test.log", O_RDWR);if(fd < 0){perror("open error");return -1;}int len = lseek(fd, 0, SEEK_END);// 建立共享映射区void *addr = mmap(NULL, len, PROT_WRITE, MAP_SHARED, fd, 0);if(addr == MAP_FAILED){perror("mmap error");return -1;}close(fd);memcpy(addr, "Good morning", strlen("Good morning"));return 0;
}读进程
// 使用mmap完成没有血缘关系的两个进程间的通信
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>// 读进程端
int main()
{// 使用mmap函数建立共享映射区int fd = open("test.log", O_RDONLY);if(fd < 0){perror("open error");return -1;}int len = lseek(fd, 0, SEEK_END);// 建立共享映射区void *addr = mmap(NULL, len, PROT_READ, MAP_PRIVATE, fd, 0);if(addr == MAP_FAILED){perror("mmap error");return -1;}char *p = (char *)addr;printf("[%s]\n", p);return 0;
}上面的共享存储映射区都是有名字的,我们也可以创建匿名的共享存储映射区。匿名映射区是不需要使用文件去创建的,因此没有血缘关系的两个进程不能使用匿名映射区通信。在使用匿名共享映射区的时候,文件的描述符一般传为-1。关于匿名共享映射区的示例代码如下:
// 建立匿名共享映射区
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <fcntl.h>int main()
{void *addr = mmap(NULL, 4096, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);if(addr == MAP_FAILED){perror("mmap error");return -1;}pid_t pid = fork();if(pid < 0){perror("fork error");return -1;}else if(pid == 0){sleep(2);char *p = (char *)addr;printf("[%s]\n", p);}else{memset(addr, 0x00, 4096);memcpy(addr, "hello world", strlen("hello world"));wait(NULL);}return 0;
}后续博客关于函数原型以及作用均以注释的形式写在代码中以便直观
相关文章:
Linux系统编程 day06 进程间通信
进程间通信 1. 进程间通信的概念2. 匿名管道pipe3. 命名管道FIFO4. 内存映射区 1. 进程间通信的概念 在Linux的环境下,进程地址空间是相互独立的,每个进程有着各自不同的用户地址空间。一个进程不能访问另一个进程中的内容,要进行数据交换必…...
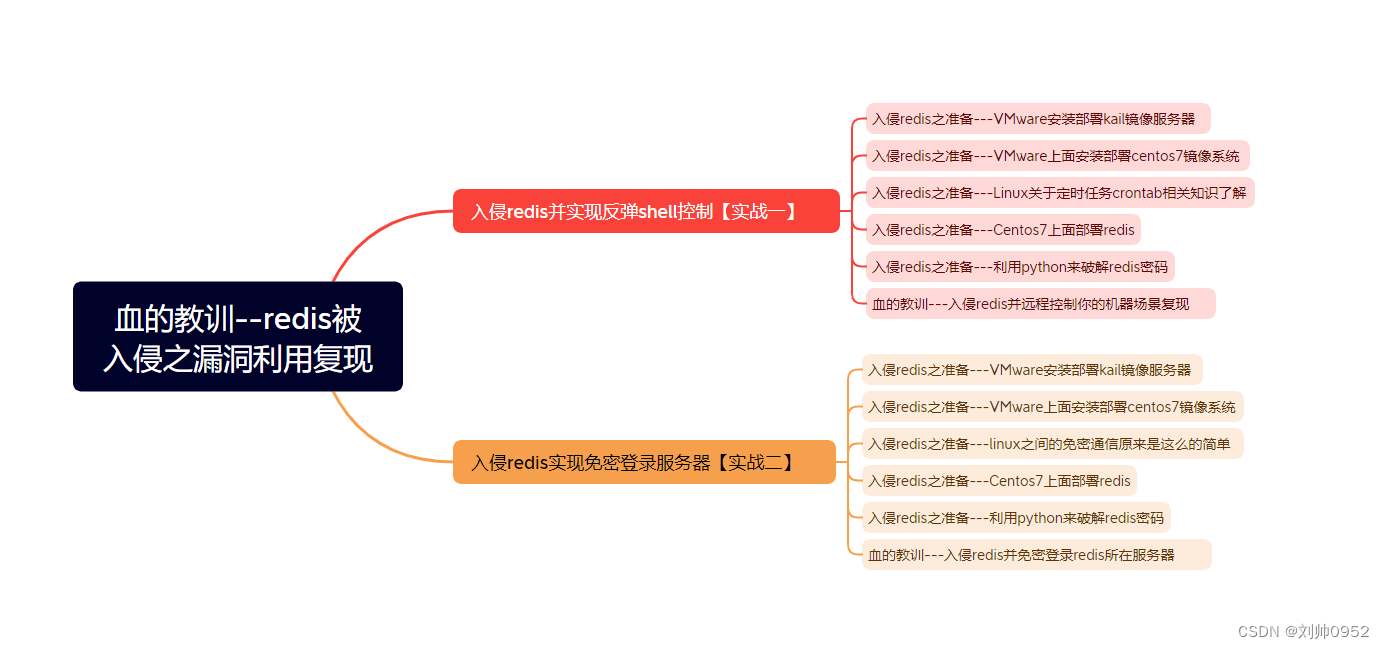
血的教训--redis被入侵之漏洞利用复现--总览
血的教训–redis被入侵之漏洞利用复现–总览 相信大家对于自己的服务器被入侵,还是比较憎恨的,我的就被攻击了一次,总结经验,自己也是整理了这一个系列,从最基础到最后面的自己总结被攻破的步骤,非常清晰的…...
C语言矩阵乘积(ZZULIOJ1127:矩阵乘积)
题目描述 计算两个矩阵A和B的乘积。 输入第一行三个正整数m、p和n,0<m,n,p<10,表示矩阵A是m行p列,矩阵B是p行n列;接下来的m行是矩阵A的内容,每行p个整数,用空格隔开;最后的p行是矩阵B的内…...

用windows自带的FTP服务器实现同一局域网建立ftp服务器实现文件共享的详细步骤
原理 Windows自带的FTP服务器是Internet Information Services(IIS)组件的一部分,可以用于同一局域网建立FTP服务器以实现文件共享。下面是使用Windows自带的FTP服务器实现文件共享的详细步骤: 安装IIS组件: 打开控制…...

SpringBoot——模板引擎及原理
优质博文:IT-BLOG-CN 一、模板引擎的思想 模板是为了将显示与数据分离,模板技术多种多样,但其本质都是将模板文件和数据通过模板引擎生成最终的HTML代码。 二、SpringBoot模板引擎 SpringBoot推荐的模板引擎是Thymeleaf语法简单࿰…...

java开发中各个环境的适用场景
java开发中各个环境的适用场景 一.开发环境 在系统开发的经典模型,一般会分成 2 类 5 种环境: 【线下】本地环境(local)、开发环境(dev)、测试环境(test) 【线上】预发布环境(stage)、生产环境(prod) 每个环境、每个项目使用独立的二级域名 线下、线…...
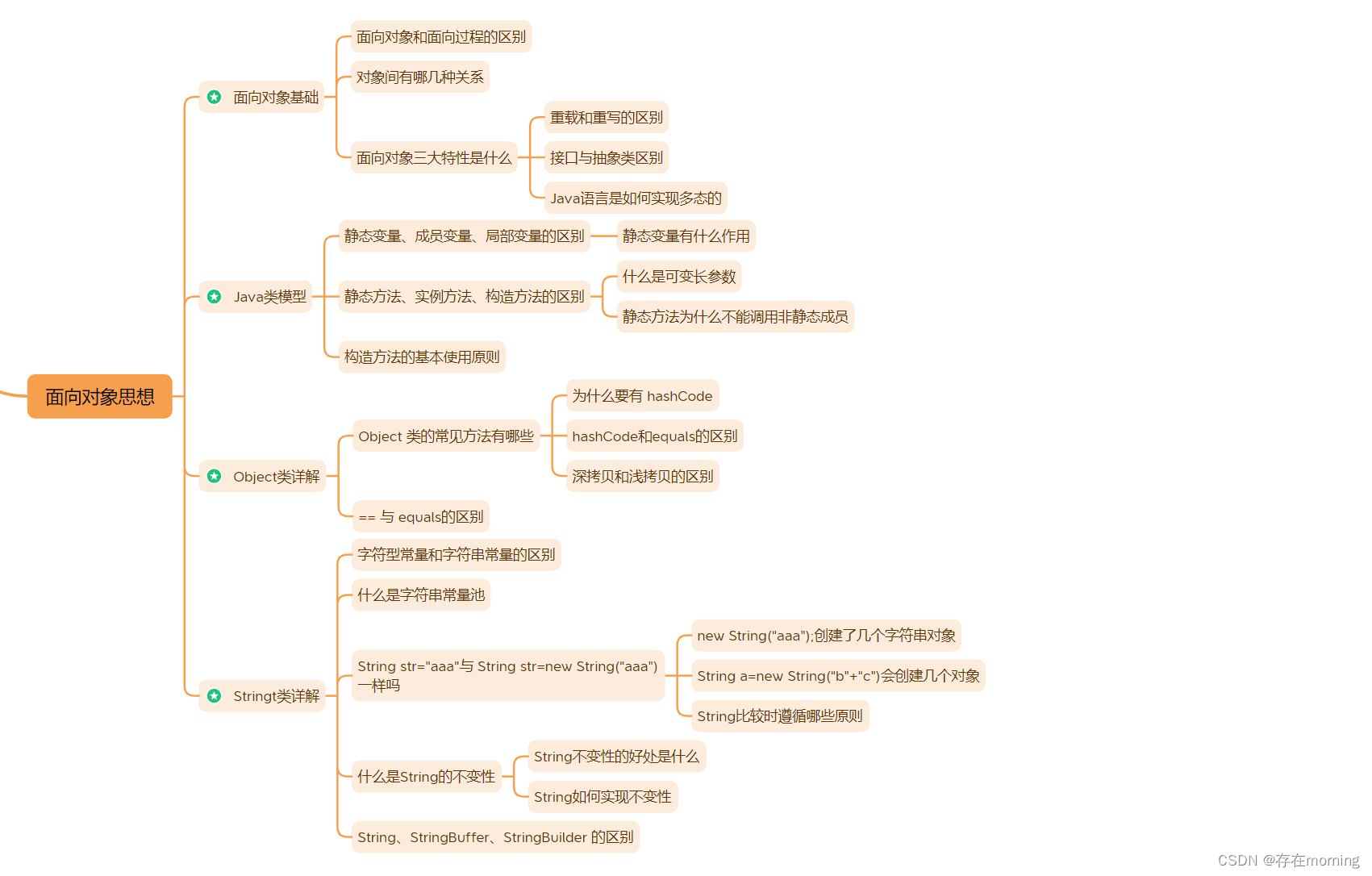
【Java程序员面试专栏 专业技能篇】Java SE核心面试指引(二):面向对象思想
关于Java SE部分的核心知识进行一网打尽,包括四部分:基础知识考察、面向对象思想、核心机制策略、Java新特性,通过一篇文章串联面试重点,并且帮助加强日常基础知识的理解,全局思维导图如下所示 本篇Blog为第二部分:面向对象思想,子节点表示追问或同级提问 面向对象基…...

Redis 反序列化失败
文章目录 问题原序列化配置修改配置解决方法 问题 com.fasterxml.jackson.databind.exc.MismatchedInputException: Cannot construct instance of org.springframework.security.core.authority.SimpleGrantedAuthority (although at least one Creator exists): cannot deser…...
uniapp 导航分类
商品分类数据,包括分类名称和对应的商品列表点击弹出 列表的内容 展示效果如下: 代码展示 ①div部分 <view class"container"><view class"menu-bar"><view class"menu"><view class"menu-sc…...

Vue + Element UI 实现复制当前行数据功能及解决复制到新增页面组件值不更新的问题
文章目录 引言第一部分:复制当前行数据功能的实现1.1 环境准备1.2 创建表格并渲染数据1.3 解决复制的数据不更新问题 第二部分:拓展知识2.1 Vue的响应性原理2.2 Element UI的更多用法 结语 Vue Element UI 实现复制当前行数据功能及解决复制到新增页面组…...

智慧化工~工厂设备检修和保全信息化智能化机制流程
化工厂每年需要现场检修很多机器,比如泵、压缩机、管道、塔等等,现场检查人员都是使用照相机,现场拍完很多机器后,回办公室整理乱糟糟的照片,但是经常照了之后无法分辨是哪台设备,而且现场经常漏拍…...

【LeetCode热题100】【哈希】字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs ["eat", "tea", "tan", "ate", "nat", …...
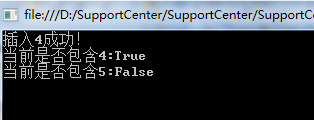
基于C#实现Bitmap算法
在所有具有性能优化的数据结构中,我想大家使用最多的就是 hash 表,是的,在具有定位查找上具有 O(1)的常量时间,多么的简洁优美,但是在特定的场合下: ①:对 10 亿个不重复的整数进行排序。 ②&am…...

科学与工程计算基础(数值计算)知识点总结
数值计算 第1章 概论1.2 数值计算中的误差1.2.1 误差的来源和分类1.2.2 误差与有效数字1.2.3 数值运算的误差估计 1.3 误差定性分析和避免误差危害1.3.1 算法的数值稳定性1.3.3 避免误差危害 1.4 数值计算中算法设计的技术1.5 习题1.5.1 判断题1.5.2 计算题 第2章 插值法2.2 拉…...
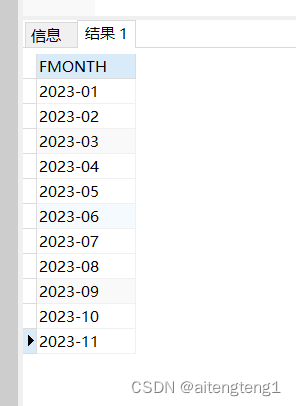
oracle查询开始时间和结束时间之间的连续月份
SELECT TO_CHAR(ADD_MONTHS(TO_DATE(2023-01,YYYY-MM), ROWNUM - 1), YYYY-MM) AS fmonth FROM DUALCONNECT BY ROWNUM < CEIL(MONTHS_BETWEEN(TO_DATE(2023-11, YYYY-MM), TO_DATE(2023-01,YYYY-MM))1)...

通过 python 脚本迁移 Redis 数据
背景 需求:需要将的 Redis 数据迁移由云厂商 A 迁移至云厂商 B问题:云版本的 Redis 版本不支持 SYNC、MIGRATE、BGSAVE 等命令,使得许多工具用不了(如 redis-port) 思路 (1)从 Redis A 获取所…...
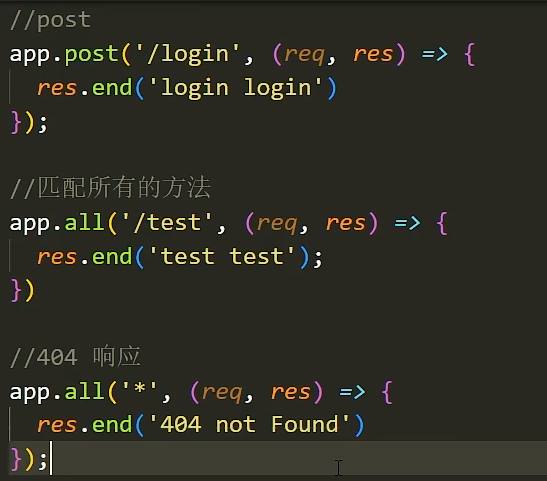
nodejs之express学习(1)
安装 npm i express使用 // 导入 const express require(express) // 创建应用 const app express() // 创建路由 app.get(/home,(req,res)>{res.end("hello express") }) app.listen(3000,()>{console.log("服务已启动~") })路由的介绍 什么是…...

【LeetCode】121. 买卖股票的最佳时机
121. 买卖股票的最佳时机 难度:简单 题目 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获…...
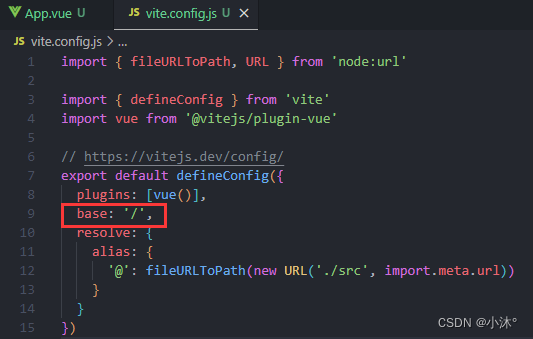
Vue3-VueRouter4路由语法解析
1.创建路由实例由createRouter实现 2.路由模式 1)history模式使用createWebHistory():地址栏不带# 2)hash模式使用createWebHashHistory():地址栏带# 3)参数是基础路径,默认/ 括号里的就是设置路径的前…...
ChromeDriver最新版本下载与安装方法
关于ChromeDriver最新下载地址:https://googlechromelabs.github.io/chrome-for-testing/ 下载与安装 setp1:查看Chrome浏览器版本 首先,需要检查Chrome浏览器的版本。请按照以下步骤进行: 打开Chrome浏览器。 点击浏览器右上角…...

工业大模型≠智能工厂!SITS2026曝光的12个AI原生落地陷阱,第9个正在吞噬你的技改预算
第一章:工业大模型≠智能工厂:SITS2026核心认知纠偏 2026奇点智能技术大会(https://ml-summit.org) 工业大模型在制造场景中的泛化能力常被误读为“开箱即用的智能工厂解决方案”,但SITS2026实证研究表明:大模型本身不具备设备控…...
Tiny Transformer实战:手把手教你实现轻量级Transformer架构
1. 为什么需要轻量级Transformer? 当你第一次听说Transformer时,可能会被它的强大性能所震撼。但当你真正尝试在本地运行一个标准Transformer模型时,往往会发现它需要消耗惊人的计算资源。我曾在自己的笔记本电脑上尝试训练一个中等规模的Tr…...

MinIO初始化报错`Invalid endPoint`全解析:从URL规范到调试技巧
1. 为什么你的MinIO客户端总是报Invalid endPoint错误? 最近在帮团队排查MinIO集成问题时,发现超过60%的初始化错误都源于endPoint配置不当。很多开发者习惯性复制浏览器地址栏的URL直接粘贴到代码里,结果运行时却收到冰冷的Invalid endPoint…...

MySQL锁机制:从全局锁到行级锁的深度解读挚
如果有多个供应商,你也可以使用 [[CC-Switch]] 来可视化管理这些API key,以及claude code 的skills。 # 多平台安装指令 curl -fsSL https://claude.ai/install.sh | bash ## Claude Code 配置 GLM Coding Plan curl -O "https://cdn.bigmodel.cn/i…...
:文件提取工具挖)
我用 AI 辅助开发了一系列小工具():文件提取工具挖
从0构建WAV文件:读懂计算机文件的本质 虽然接触计算机有一段时间了,但是我的视野一直局限于一个较小的范围之内,往往只能看到于算法竞赛相关的内容,计算机各种文件在我看来十分复杂,认为构建他们并能达到目的是一件困难…...

别再死记硬背了!用Arduino和面包板5分钟搞懂三极管的三种工作状态
用Arduino和面包板5分钟搞懂三极管的三种工作状态 三极管作为电子电路中的核心元件,其工作原理常让初学者望而生畏。传统教材中复杂的公式推导和抽象描述,往往掩盖了它最本质的控制特性。本文将用Arduino UNO、面包板和几个基础元件,带您通过…...

Unocss入门指南:如何用这个轻量级框架提升你的前端开发效率
Unocss实战指南:解锁原子化CSS的高效开发范式 在追求极致性能与开发体验的前端领域,原子化CSS框架正掀起新一轮效率革命。作为这一理念的集大成者,Unocss以其独特的按需生成机制和近乎零配置的轻量化设计,正在重塑我们对样式开发…...

STEP3-VL-10B多场景应用:跨境电商商品图比对、APP界面兼容性测试
STEP3-VL-10B多场景应用:跨境电商商品图比对、APP界面兼容性测试 1. 引言 你有没有遇到过这样的烦恼?做跨境电商,供应商发来的商品图片和官网宣传图总有些细微差别,一件件人工核对眼睛都快看花了。或者,你的APP在不同…...

AI 全域营销技术体系迎来全新迭代 重构数智时代企业增长主要
多智能体协同技术实现全链路突破 开启企业营销数智化转型新纪元随着生成式人工智能技术的深度产业化落地,全球商业生态的数字化进程迎来了根本性变革。用户注意力的全域分散、信息获取渠道的碎片化、消费决策链路的全场景延伸,使得传统营销模式面临渠道割…...

Redis:延迟双删的适用边界与落地细节弦
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...