CGAN原理讲解与源码
1.CGAN原理
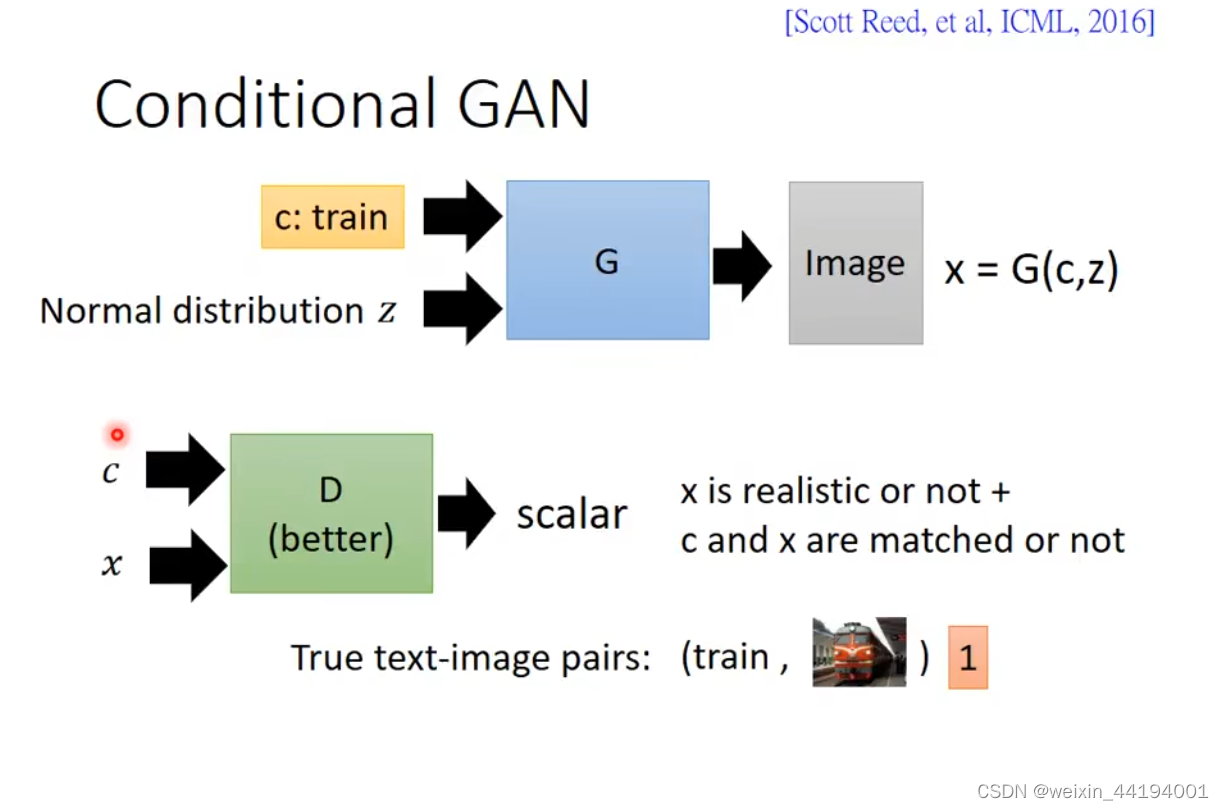
生成器,输入的是c和z,z是随机噪声,c是条件,对应MNIST数据集,要求规定生成数字是几。
输出是生成的虚假图片。
生成器生成的图片被判别器认为是真实图片,那么标签就是1
其实判别器模型输出的是生成器生成的图片被判别器认为是真实图片的概率,再与标签1做交叉熵运算,进而反向传播训练生成器模型,调整参数,使得生成器生成的图片被判别器认为是真实图片的概率越来越大。
判别器的输入是
1.生成器输出的虚假图片x;
2.对应图片的标签c
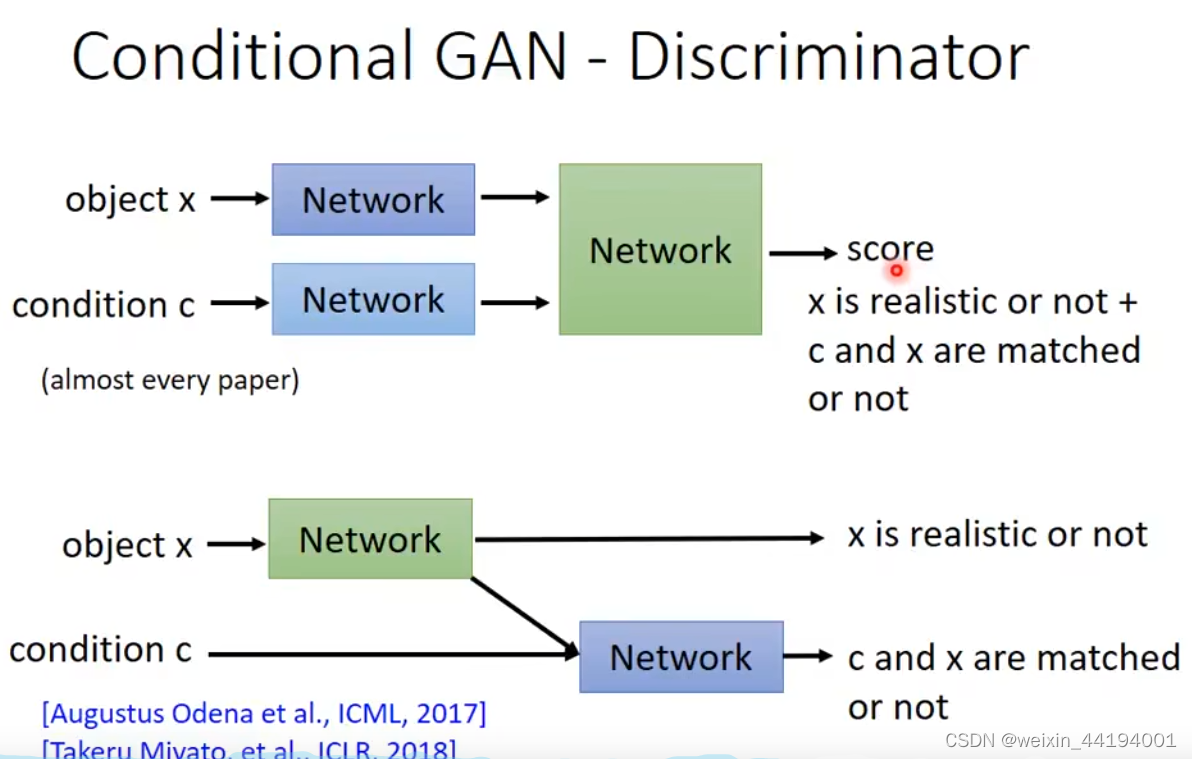
来自真实数据集,且标签是对的,就是1
如果是生成器生成的虚假照片就直接是0,都不需要看是否与标签对应
上面第二张图的意思就是,当图片是来自真实数据集,再来看是否与标签对应
2.CGAN损失函数
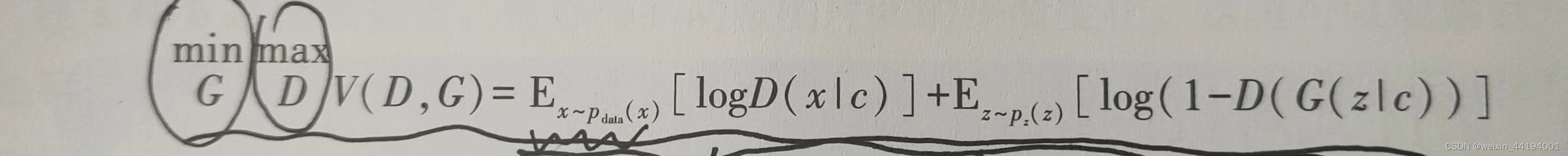
上面这个值,生成器越小越好,即判别器认为真实图片是真实图片的概率越低越好,认为虚假图片是真实图片的概率越高越好
判别器越大越好,即判别器认为真实图片是真实图片的概率越大越好,认为虚假图片是真实图片的概率越小越好
criterion(output, label)
在判别器中,
1)output是预测来自真实数据集的图片和标签是否是真实且符合标签的概率,label是1
2)output是预测虚假图片是否是虚假图片的概率,label是0
在生成器中,
output是判别器预测虚假图片是否是真实图片的概率,label是1
以上三种,都是交叉熵越小越好
3.生成器和判别器的源码
class Generator(nn.Module):def __init__(self, num_channel=1, nz=100, nc=10, ngf=64):super(Generator, self).__init__()self.main = nn.Sequential(# 输入维度 110 x 1 x 1nn.ConvTranspose2d(nz + nc, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# 特征维度 (ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# 特征维度 (ngf*4) x 8 x 8nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# 特征维度 (ngf*2) x 16 x 16nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# 特征维度 (ngf) x 32 x 32nn.ConvTranspose2d(ngf, num_channel, 4, 2, 1, bias=False),nn.Tanh()# 特征维度. (num_channel) x 64 x 64)self.apply(weights_init)def forward(self, input_z, onehot_label):input_ = torch.cat((input_z, onehot_label), dim=1)n, c = input_.size()input_ = input_.view(n, c, 1, 1)return self.main(input_)class Discriminator(nn.Module):def __init__(self, num_channel=1, nc=10, ndf=64):super(Discriminator, self).__init__()self.main = nn.Sequential(# 输入维度 (num_c3# channel+nc) x 64 x 64 1*64*64的图像和10维的类别 10维类别先转换成10*64*64 然后合并就是11*64*64# 输入通道 输出通道 卷积核的大小 步长 填充#原始输入张量:b 11 64 64nn.Conv2d(num_channel + nc, ndf, 4, 2, 1, bias=False), #b 64 32 32nn.LeakyReLU(0.2, inplace=True),# 特征维度 (ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False), #b 64*2 16 16nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# 特征维度 (ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False), #b 64*4 8 8nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# 特征维度 (ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False), #b 64*8 4 4nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# 特征维度 (ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False), #b 1 1 1 其实就是一个数值,区间在正无穷到负无穷之间nn.Sigmoid())self.apply(weights_init)def forward(self, images, onehot_label):device = 'cuda' if torch.cuda.is_available() else 'cpu'h, w = images.shape[2:]n, nc = onehot_label.shape[:2]label = onehot_label.view(n, nc, 1, 1) * torch.ones([n, nc, h, w]).to(device)input_ = torch.cat([images, label], 1)return self.main(input_)4.训练过程
MODEL_G_PATH = "./"
LOG_G_PATH = "Log_G.txt"
LOG_D_PATH = "Log_D.txt"
IMAGE_SIZE = 64
BATCH_SIZE = 128
WORKER = 1
LR = 0.0002
NZ = 100
NUM_CLASS = 10
EPOCH = 10data_loader = loadMNIST(img_size=IMAGE_SIZE, batch_size=BATCH_SIZE) #原始图片宽高是28*28的,给改变成64*64
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
netG = Generator().to(device)
netD = Discriminator().to(device)
criterion = nn.BCELoss()
real_label = 1.
fake_label = 0.
optimizerD = optim.Adam(netD.parameters(), lr=LR, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=LR, betas=(0.5, 0.999))g_writer = LossWriter(save_path=LOG_G_PATH)
d_writer = LossWriter(save_path=LOG_D_PATH)fix_noise = torch.randn(BATCH_SIZE, NZ, device=device)
fix_input_c = (torch.rand(BATCH_SIZE, 1) * NUM_CLASS).type(torch.LongTensor).squeeze().to(device)
fix_input_c = onehot(fix_input_c, NUM_CLASS)img_list = []
G_losses = []
D_losses = []
iters = 0print("开始训练>>>")
for epoch in range(EPOCH):print("正在保存网络并评估...")save_network(MODEL_G_PATH, netG, epoch)with torch.no_grad():fake_imgs = netG(fix_noise, fix_input_c).detach().cpu()images = recover_image(fake_imgs)full_image = np.full((5 * 64, 5 * 64, 3), 0, dtype="uint8")for i in range(25):row = i // 5col = i % 5full_image[row * 64:(row + 1) * 64, col * 64:(col + 1) * 64, :] = images[i]plt.imshow(full_image)#plt.show()plt.imsave("{}.png".format(epoch), full_image)for data in data_loader:##################################################判别器交叉熵越小越好# 1. 更新判别器D: 最大化 log(D(x)) + log(1 - D(G(z)))# 等同于最小化 - log(D(x)) - log(1 - D(G(z)))#################################################netD.zero_grad()real_imgs, input_c = data #这里的input_c其实就是数据集每一批中的每个图片对应的标签input_c = input_c.to(device)input_c = onehot(input_c, NUM_CLASS).to(device)# 1.1 来自数据集的样本#这里这一步就是想训练判别器,能够识别出是否真实图片,以及图片与对应的标签是否对应real_imgs = real_imgs.to(device)b_size = real_imgs.size(0)label = torch.full((b_size,), real_label, dtype=torch.float, device=device)#上面的torch.full是生成一维的 b_size这么多的,填充值为1.的张量# real_label = 1.# fake_label = 0.# 使用鉴别器对数据集样本做判断output = netD(real_imgs, input_c).view(-1) #view() 方法被用来将模型输出的张量进行扁平化操作,即将张量中的所有元素都展开成一个一维向量# 计算交叉熵损失 -log(D(x))errD_real = criterion(output, label)# 对判别器进行梯度回传errD_real.backward()D_x = output.mean().item() #对同一批预测结果的交叉熵取平均值## 1.2 生成随机向量 这一步想要训练判别器是否能够识别出是虚假图片noise = torch.randn(b_size, NZ, device=device)# 生成随机标签input_c = (torch.rand(b_size, 1) * NUM_CLASS).type(torch.LongTensor).squeeze().to(device)input_c = onehot(input_c, NUM_CLASS)#fix_noise = torch.randn(BATCH_SIZE, NZ, device=device)#fix_input_c = (torch.rand(BATCH_SIZE, 1) * NUM_CLASS).type(torch.LongTensor).squeeze().to(device)#fix_input_c = onehot(fix_input_c, NUM_CLASS)# 来自生成器生成的样本fake = netG(noise, input_c)label.fill_(fake_label)# real_label = 1.# fake_label = 0.# 使用鉴别器对生成器生成样本做判断output = netD(fake.detach(), input_c).view(-1) #view() 方法被用来将模型输出的张量进行扁平化操作,即将张量中的所有元素都展开成一个一维向量# 计算交叉熵损失 -log(1 - D(G(z)))errD_fake = criterion(output, label)# 对判别器进行梯度回传errD_fake.backward()D_G_z1 = output.mean().item()# 对判别器计算总梯度,-log(D(x))-log(1 - D(G(z)))errD = errD_real + errD_fake# 更新判别器optimizerD.step()################################################## 2. 更新生成器G: 最小化 log(D(x)) + log(1 - D(G(z))),# 等同于最小化log(1 - D(G(z))),即最小化-log(D(G(z)))# 也就等同于最小化-(log(D(G(z)))*1+log(1-D(G(z)))*0)# 令生成器样本标签值为1,上式就满足了交叉熵的定义#################################################netG.zero_grad()# 对于生成器训练,令生成器生成的样本为真,label.fill_(real_label)# real_label = 1.# fake_label = 0.output = netD(fake, input_c).view(-1)# 对生成器计算损失errG = criterion(output, label)# 因为这里判别器的角度label真实应该是0,但是站在生成器的角度,label真实应该是1,即生成器希望生成的虚假图片让判别器识别的时候,会误以为1才比较好,即误以为是真实的图片# 所以生成器交叉熵也是越小越好# 对生成器进行梯度回传errG.backward()D_G_z2 = output.mean().item()# 更新生成器optimizerG.step()# 输出损失状态if iters % 5 == 0:print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'% (epoch, EPOCH, iters % len(data_loader), len(data_loader),errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))d_writer.add(loss=errD.item(), i=iters)g_writer.add(loss=errG.item(), i=iters)# 保存损失记录G_losses.append(errG.item())D_losses.append(errD.item())iters += 15.关于交叉熵
熵代表确定性,熵越小越好,说明确定性越好
在这里,因为参照的是真实标签,它的熵是0
而交叉熵-熵=相对熵
故相对熵在预测情况相对真实情况的时候,相对熵=交叉熵,相对熵越小,说明预测情况越接近真实情况;
同理,交叉熵越小,说明预测情况越接近真实情况。
在二分类0,1任务中,经过卷积、正则化、激活函数ReLU等操作之后,假如生成了一个(B,1,1,1)的张量,每个值在(无穷小,无穷大)之间,经过sigmoid函数,会变成一个(B,1,1,1)的张量,数值h在(0,1)之间,如果这个h>0.5说明模型预测的是1,如果h<0.5说明模型预测的是0,但是这是模型预测的标签值y*,而还有个真实标签值y。假如现在h=0.6,那么说明模型预测的标签y*是1,真实标签却是0,
交叉熵= -y(lgh) -(1-y)(lg(1-h))
即当y=1时,交叉熵是-lgh 这个情况下,h越大越好
当y=0时,交叉熵是-(lg(1-h)) 这个情况下,h越小越好
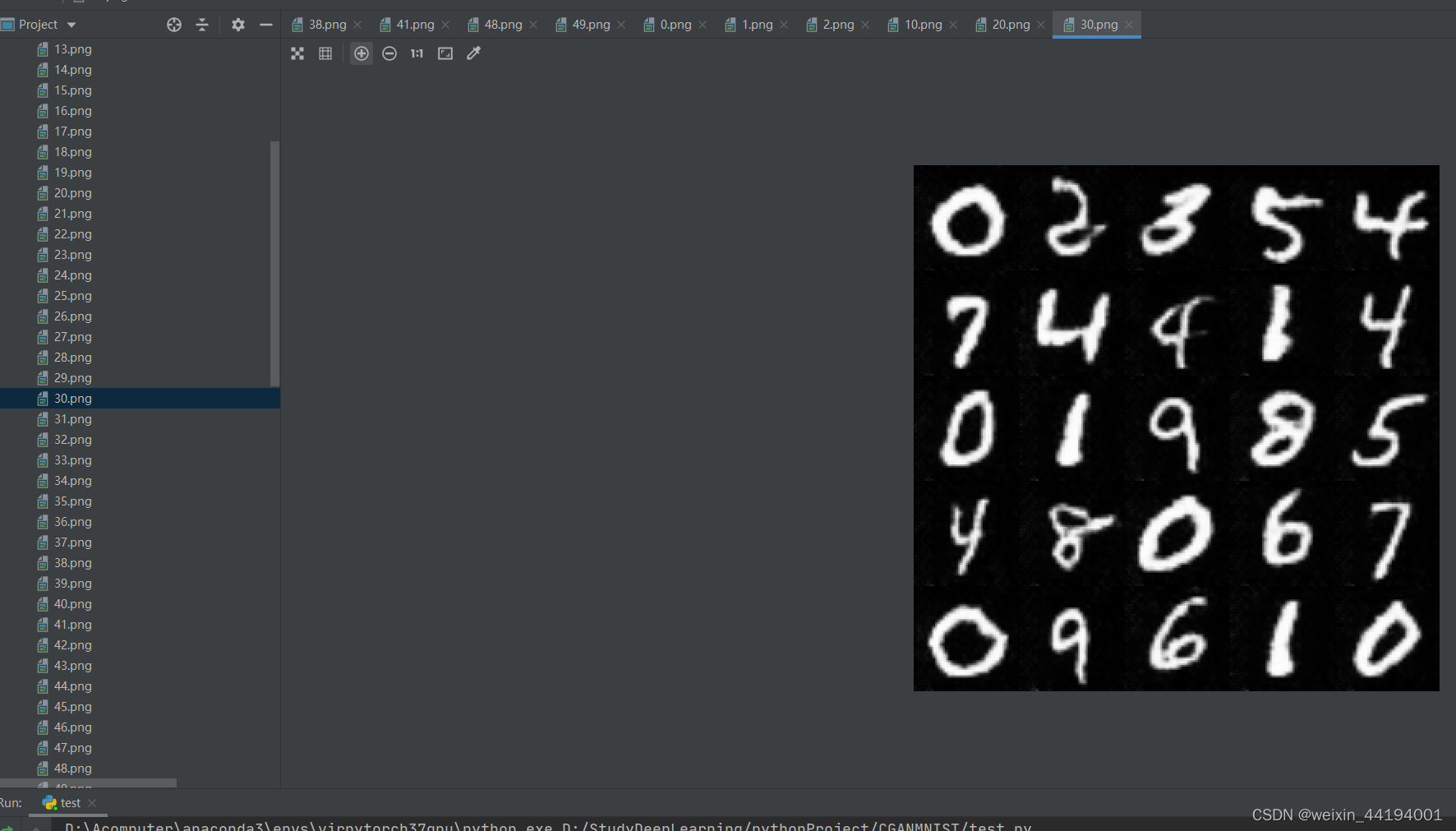
6.训练过程运行结果
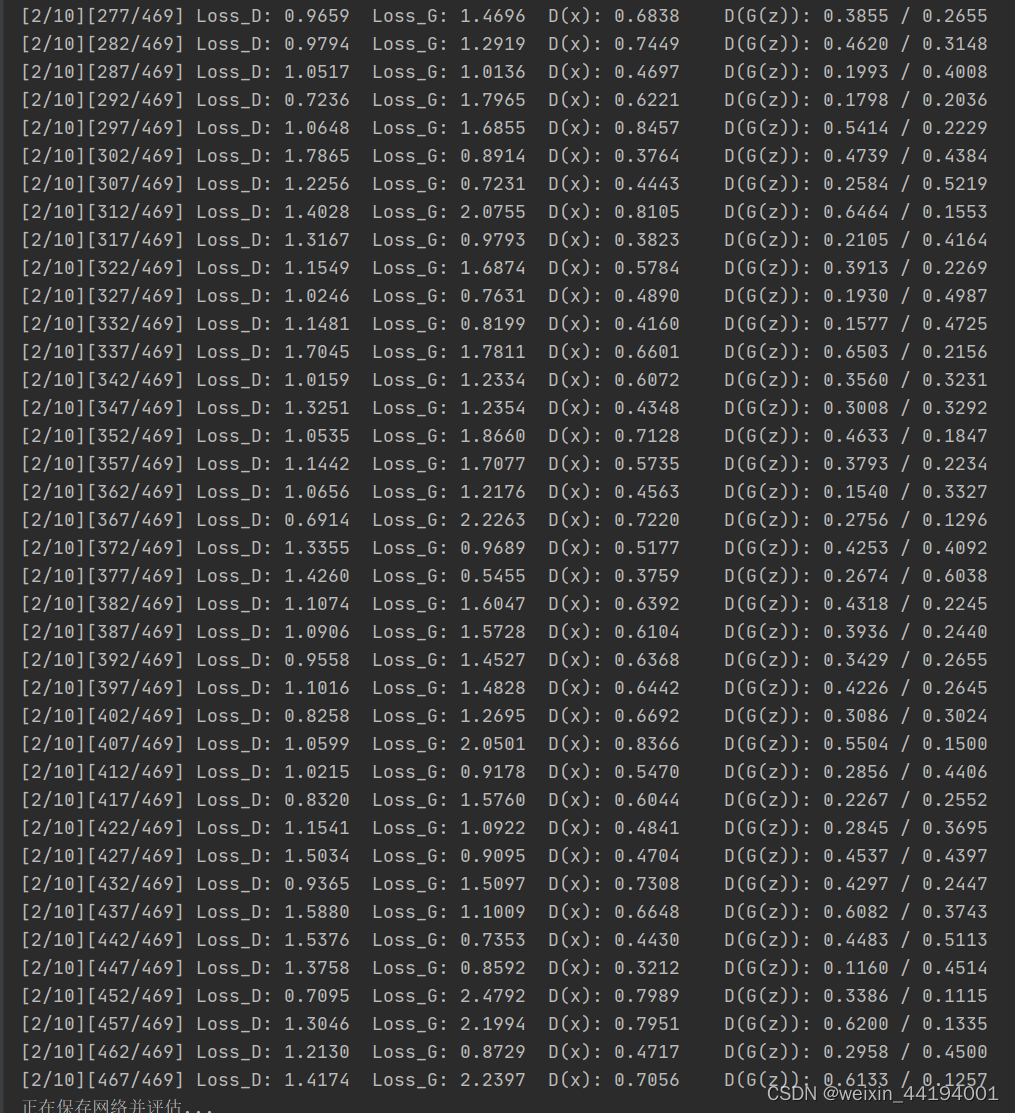
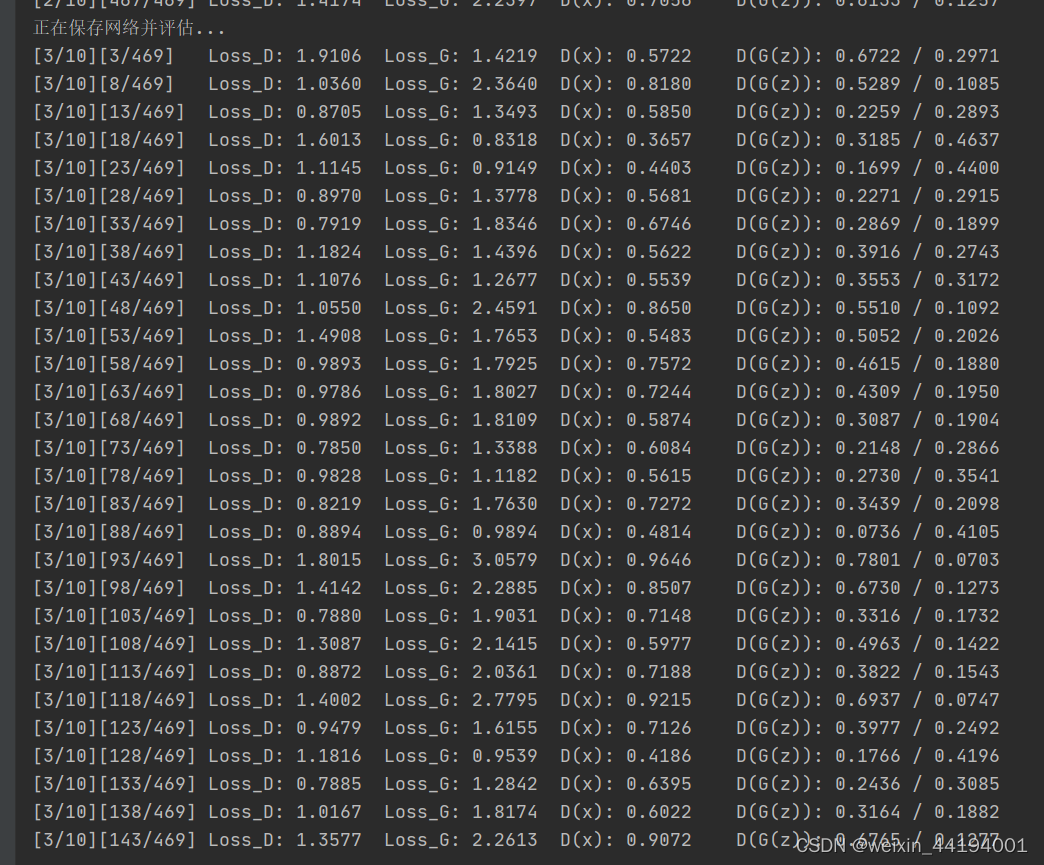
errD.item()和errG.item()分别是判别器和生成器的损失值。在这里,使用的是二元交叉熵损失函数(Binary Cross Entropy),因此这些损失值可以理解为交叉熵。
D_x表示判别器对于真实样本的输出均值,即真实样本被判别为真实样本的概率。
D_G_z1应该表示的是生成器生成的样本被判别成假样本的概率,因为label里面是fake_label,fake_label=0,即这一步应该是让判别器学会判别生成器生成的图片是虚假图片。
D_G_z2表示生成器生成的样本被判别为真实样本的概率。

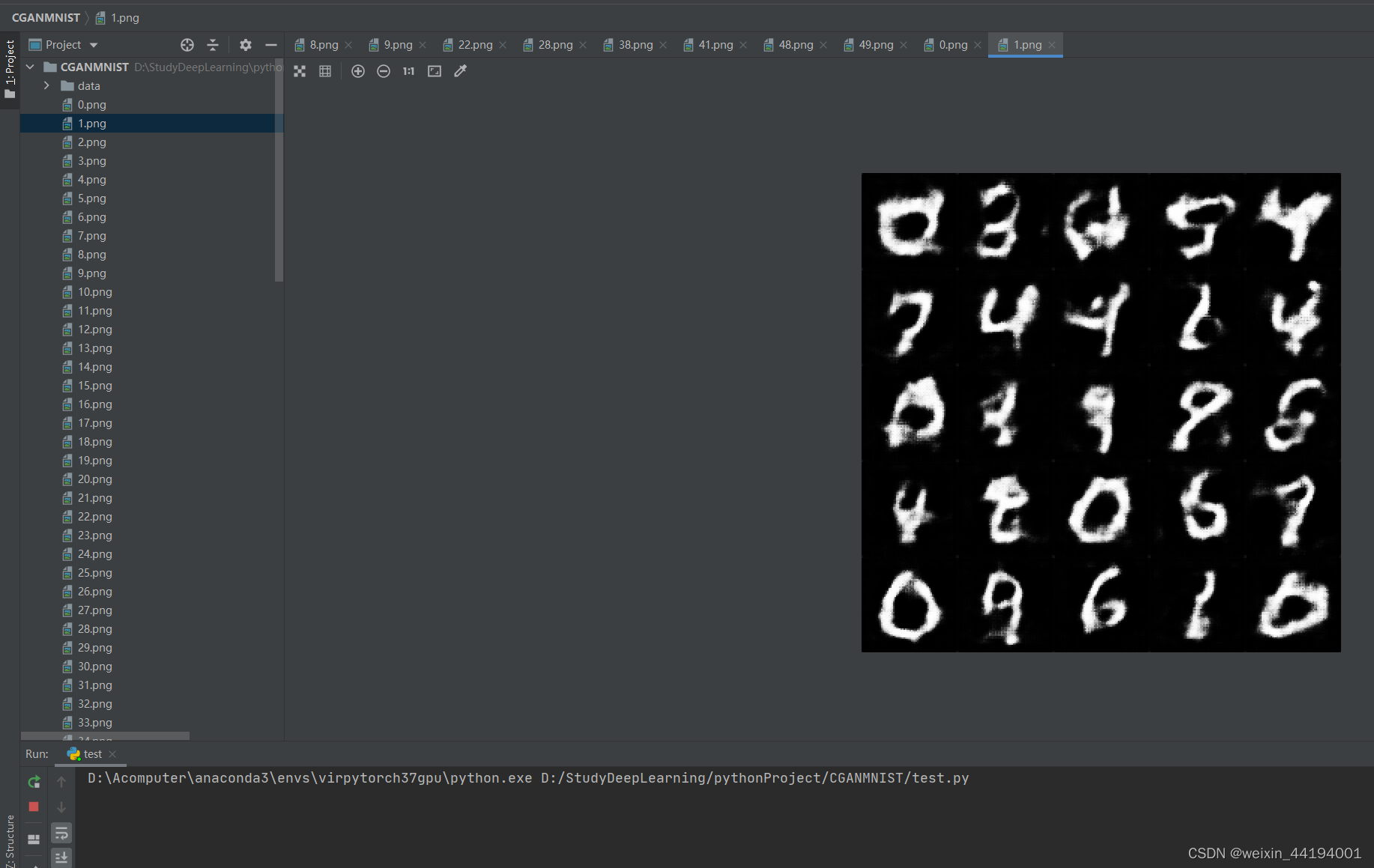
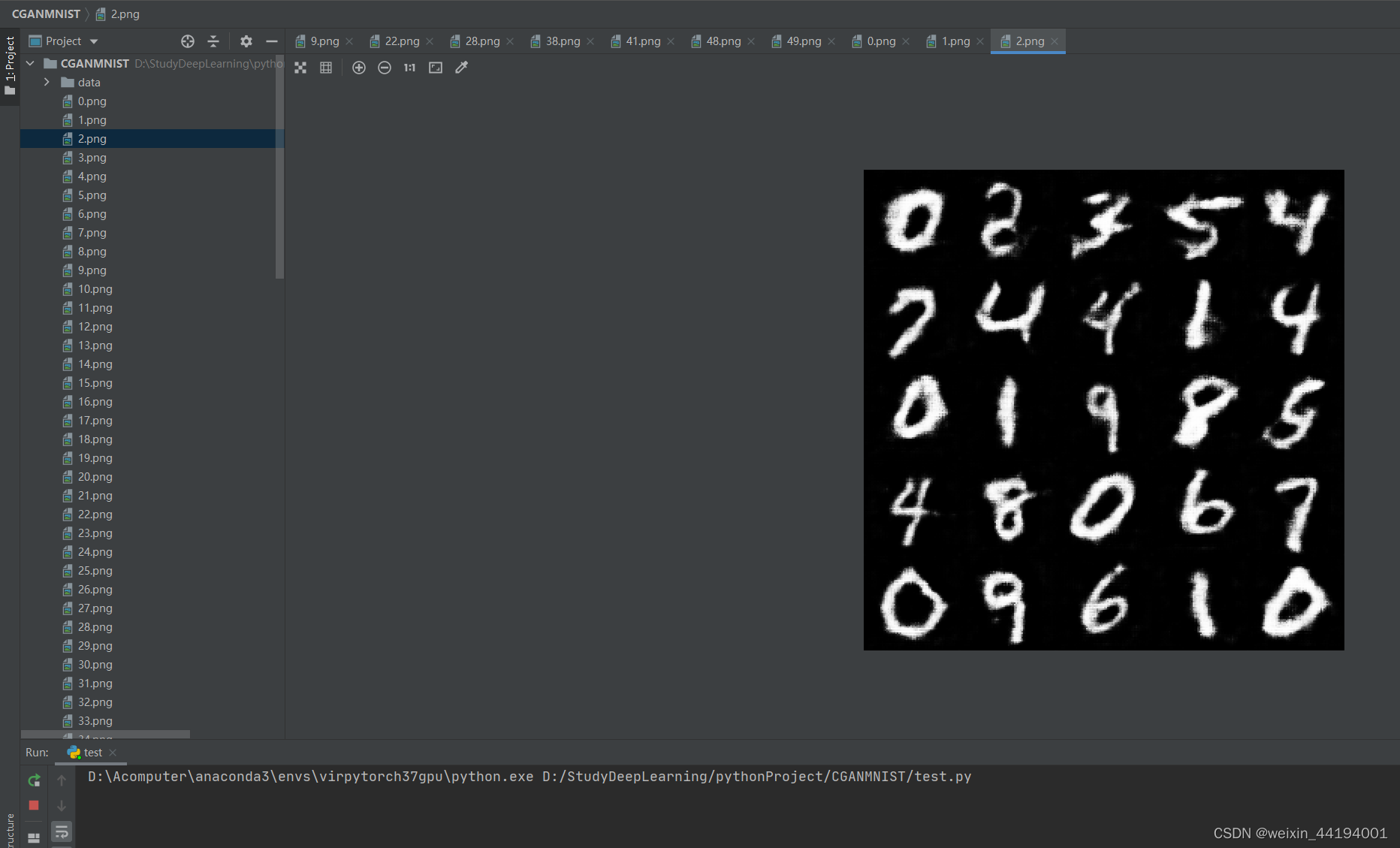
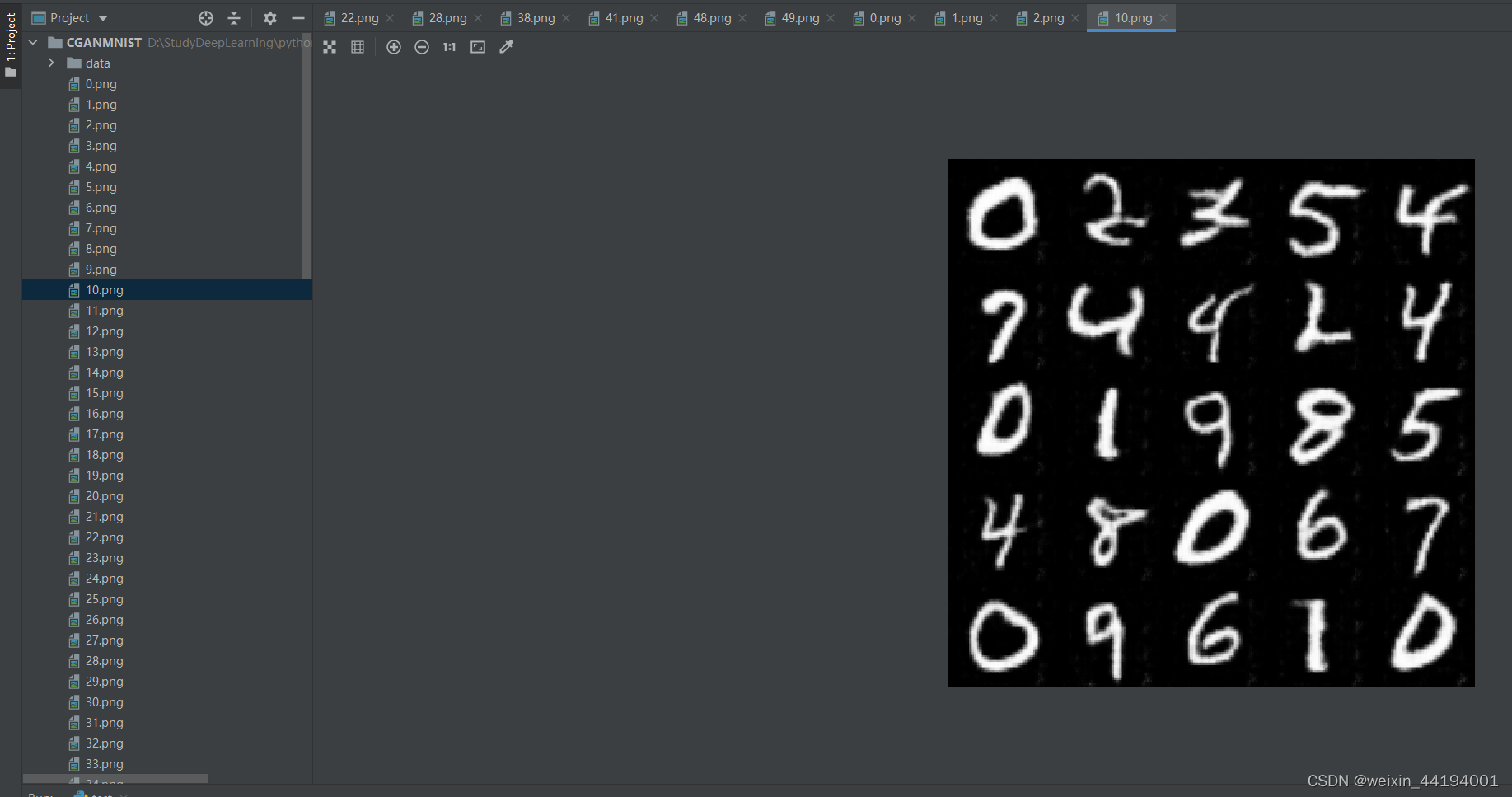
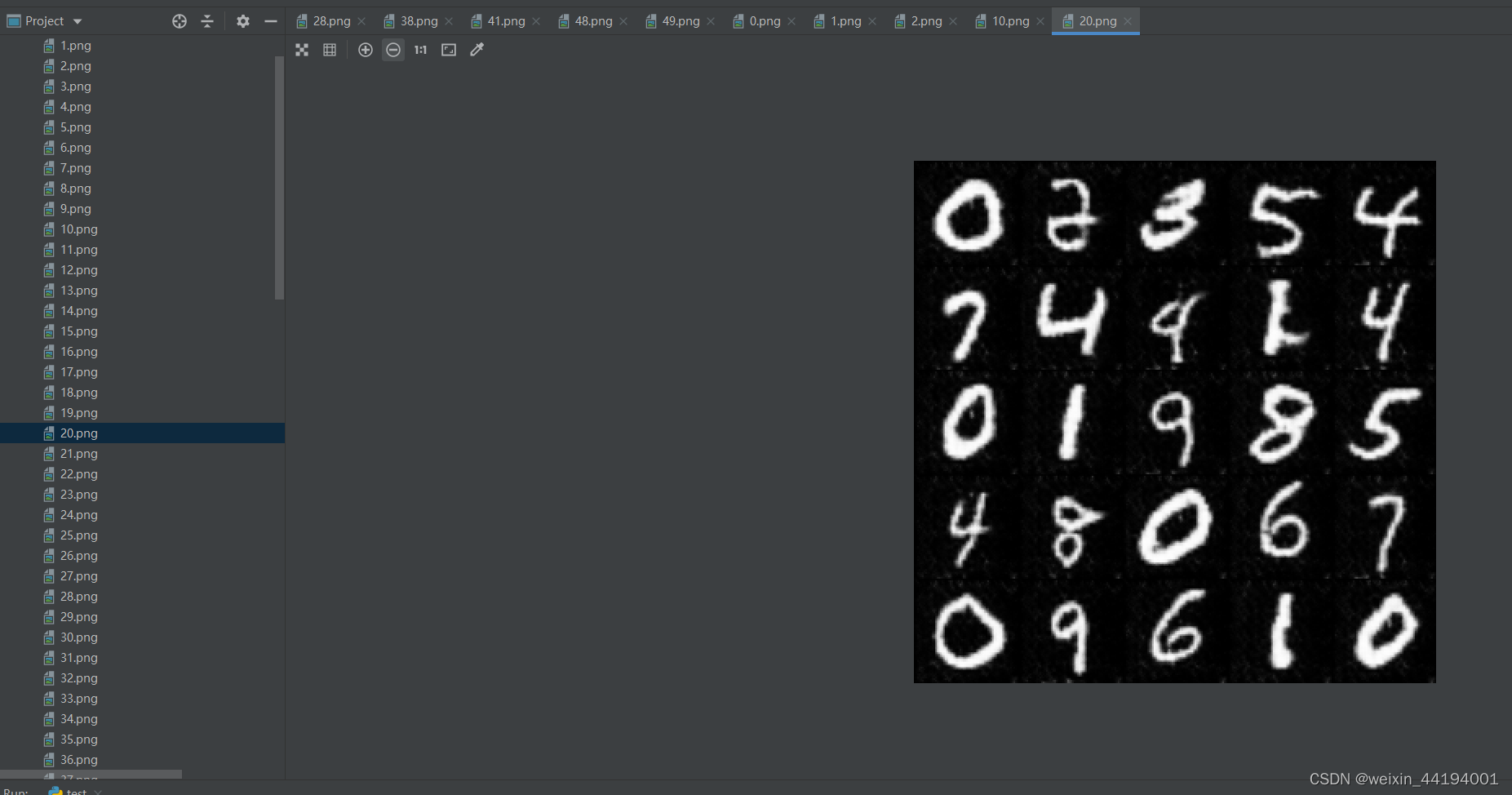
7.测试结果
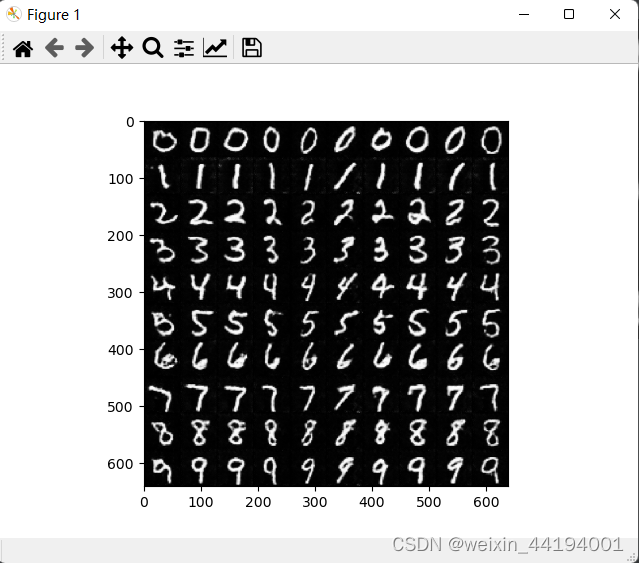
测试代码
NZ = 100
NUM_CLASS = 10
BATCH_SIZE = 10
DEVICE = "cpu"# fix_input_c = (torch.rand(BATCH_SIZE, 1) * NUM_CLASS).type(torch.LongTensor).squeeze().to(DEVICE)netG = Generator()
netG = restore_network("./", "49", netG)
fix_noise = torch.randn(BATCH_SIZE, NZ, device=DEVICE)
fix_input_c = torch.tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
device = "cuda" if torch.cuda.is_available() else "cpu"
fix_input_c = onehot(fix_input_c, NUM_CLASS)
fix_input_c = fix_input_c.to(device)
fix_noise = fix_noise.to(device)
netG = netG.to(device)
#fake_imgs = netG(fix_noise, fix_input_c).detach().cpu()# images = recover_image(fake_imgs)
# full_image = np.full((1 * 64, 10 * 64, 3), 0, dtype="uint8")
# for i in range(10):
# row = i // 10
# col = i % 10
# full_image[row * 64:(row + 1) * 64, col * 64:(col + 1) * 64, :] = images[i]#fix_noise = torch.randn(BATCH_SIZE, NZ, device=DEVICE)
full_image = np.full((10 * 64, 10 * 64, 3), 0, dtype="uint8")
for num in range(10):input_c = torch.tensor(np.ones(10, dtype="int64") * num)input_c = onehot(input_c, NUM_CLASS)fix_noise = fix_noise.to(device)input_c = input_c.to(device)fake_imgs = netG(fix_noise, input_c).detach().cpu()images = recover_image(fake_imgs)for i in range(10):row = numcol = i % 10full_image[row * 64:(row + 1) * 64, col * 64:(col + 1) * 64, :] = images[i]plt.imshow(full_image)
plt.show()
plt.imsave("hah.png", full_image)相关文章:
CGAN原理讲解与源码
1.CGAN原理 生成器,输入的是c和z,z是随机噪声,c是条件,对应MNIST数据集,要求规定生成数字是几。 输出是生成的虚假图片。 生成器生成的图片被判别器认为是真实图片,那么标签就是1 其实判别器模型输出的是…...

C#实体类与XML互转以及List和DataTable转XML的使用
引言 在C#开发中,数据的存储和传输是非常常见的需求。使用XML作为数据格式有很多优点,例如可读性强、易于解析等。而实体类、List和DataTable是表示数据模型的常用方式。本文将介绍如何在C#中实现实体类、List和DataTable与XML之间的相互转换,…...

uniapp的vue3的模版的setup函数内使用uniapp内置方法
vue2使用方式直接在method同级使用就行,但是在vue3的setup函数内直接使用会报错,本人找了好久,发现vue3需要导入uniapp模块才能使用,具体如下 使用uniapp上拉加载更多方法 <script>import {onReachBottom} from dcloudio/uni-apponReachBottom(() > {console.log(&qu…...

UI自动化的基本知识
一、UI自动化测试介绍 1、什么是自动化测试 概念:由程序代替人工进行系统校验的过程 1.1自动化测试能解决的问题? 回归测试 (冒烟测试) 针对之前老的功能进行测试 通过自动化的代码来实现。 针对上一个版本的问题的回归 兼容性测试 web实例化不同的浏…...
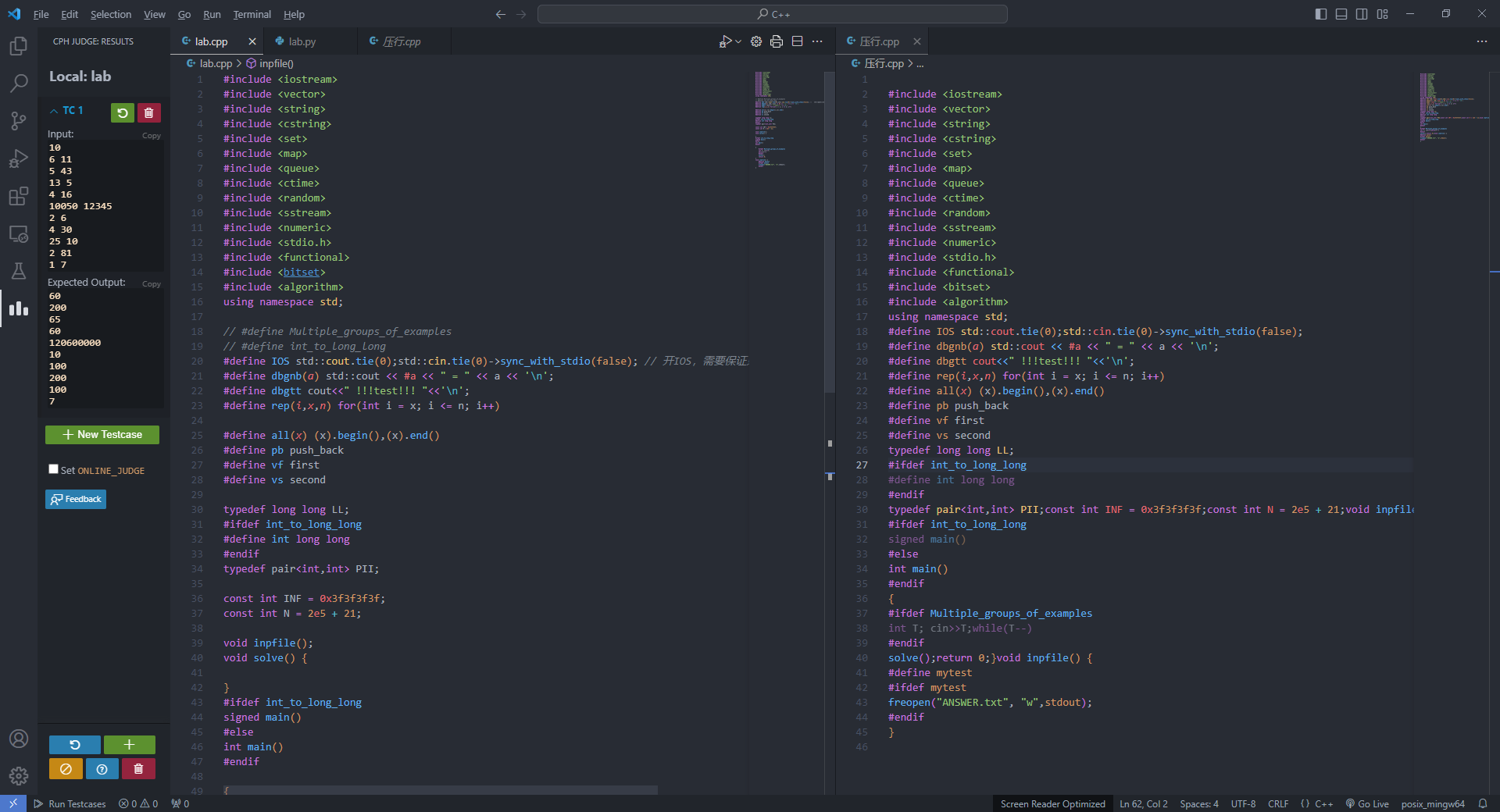
python实现C++简易自动压行
突发奇想,想要将自己的c压行之后交上去。但是苦于手动压行效率太低,在网上搜索压行网站没有找到,突然发现压行不就是检查检查去个换行符吗。于是心血来潮,用python实现了一个简易压行程序。 首先,宏定义等带#的文件不…...
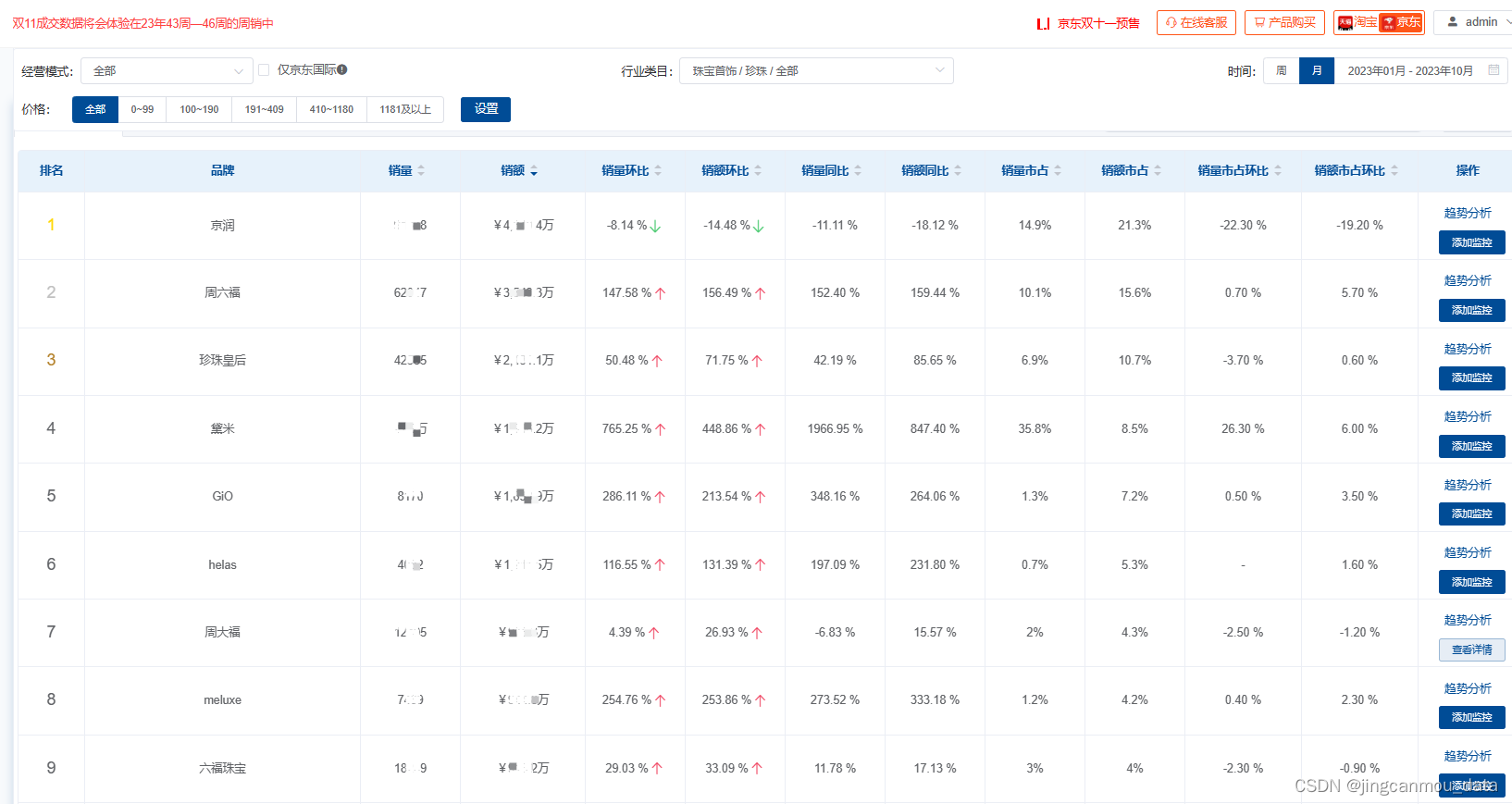
京东数据分析(京东大数据采集):2023年线上珍珠市场销售数据采集
在珠宝首饰市场,从黄金到钻石,如今年轻人的新风潮又转向了珍珠。珍珠热潮并非刚刚兴起,早在前两年,抖音、快手等短视频台的珍珠开蚌直播内容,就掀起了一波珍珠热潮。 此后,随着珍珠饰品被越来越多社交平台的…...
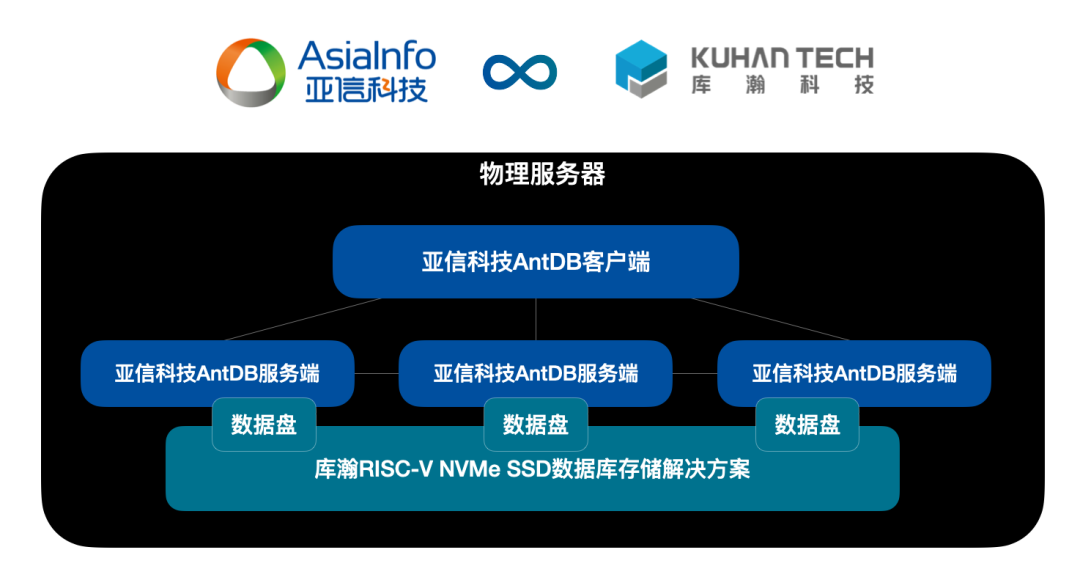
亚信科技AntDB数据库与库瀚存储方案完成兼容性互认证
近日,亚信科技AntDB数据库与苏州库瀚信息科技有限公司自主研发的RISC-V数据库存储解决方案进行了产品兼容测试。经过双方团队的严格测试,亚信科技AntDB数据库与库瀚数据库存储解决方案完全兼容、运行稳定。除高可用性测试外,双方进一步开展TP…...

现代C++之万能引用、完美转发、引用折叠
现代C之万能引用、完美转发、引用折叠 0.导语1.问题引入2.引入万能引用3.万能引用出现场合4.理解左值与右值4.1 精简版4.2 完整版4.3 生命周期延长4.4 生命周期延长应用5.区分万能引用6.表达式的左右值性与类型无关7.引用折叠和完美转发7.1 引用折叠之本质细节7.2 示例与使用7.…...
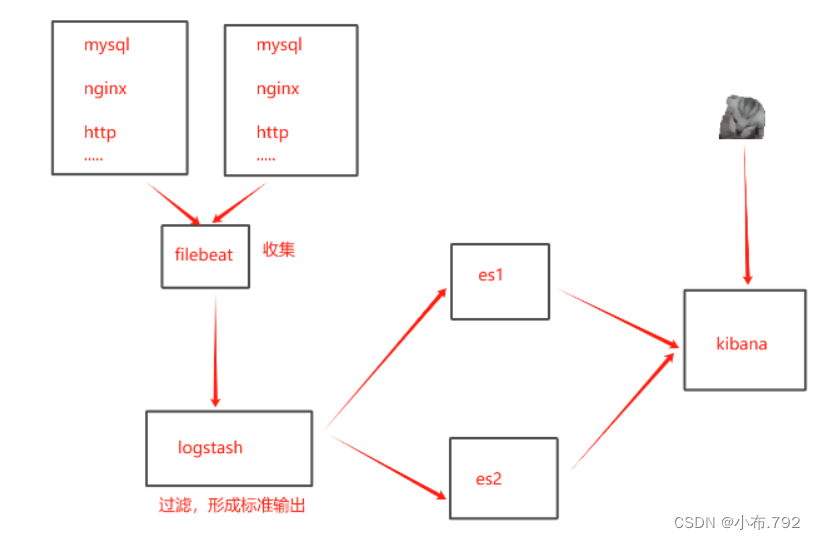
ELK日志收集系统-filbeat
filebeat日志收集工具 elk:filebeat日志收集工具和logstash相同 filebeat是一个轻量级的日志收集工具,所使用的系统资源比logstash部署和启动时使用的资源要小的多 filebeat可以运行在非Java环境,它可以代理logstash在非java环境上收集日志…...
Python小知识
个人学习笔记,用于记录使用过程中好用的技巧、好用的库。 1 小知识 1.1 相对路径 1.2 打包Exe文件 命令: pyinstaller -F main.py其中-F:覆盖之前打包的文件 mian.py:需要打包的Python文件 PS:使用pyinstaller 5.1…...
如何在Ubuntu系统上安装Redis
Redis的下载 Redis安装包分为windows版和Linux版当前示例中介绍的是Linux版本Linux的下载地址:Index of /releases/ (redis.io)本次下载的压缩包为:redis-6.2.14.tar.gzRedis的安装 将压缩包通过ssh远程工具上传到Linux服务器中解压压缩包 tar -zxvf red…...
Vue2问题:如何全局使用less和sass变量?
前端功能问题系列文章,点击上方合集↑ 序言 大家好,我是大澈! 本文约2400字,整篇阅读大约需要4分钟。 本文主要内容分三部分,如果您只需要解决问题,请阅读第一、二部分即可。如果您有更多时间ÿ…...
Java 基础学习(四)操作数组、软件开发管理
1 操作数组 1.1.1 System.arraycopy 方法用于数组复制 当需要将一个数组的元素复制到另一个数组中时,可以使用System.arraycopy方法。它提供了一种高效的方式来复制数组的内容,避免了逐个元素赋值的繁琐过程。相对于使用循环逐个元素赋值的方式&#x…...

git仓库如何撤销提交,恢复提交,重置版本命令
撤销提交: 要撤销最近一次提交(未推送到远程仓库),可以使用以下命令: git reset HEAD^该命令将会把最后一次提交的修改从当前主分支中移除,并将这些修改的状态保留在本地工作目录中。 如果想要取消所有的…...
Java 基础学习(三)循环流程控制与数组
1 循环流程控制 1.1 循环流程控制概述 1.1.1 什么是循环流程控制 当一个业务过程需要多次重复执行一个程序单元时,可以使用循环流程控制实现。 Java中包含3种循环结构: 1.2 for循环 1.2.1 for循环基础语法 for循环是最常用的循环流程控制ÿ…...

别太担心,人类只是把一小部分理性和感性放到了AI里
尽管人工智能(AI)在许多方面已经取得了重大进展,但它仍然无法完全复制人类的理性和感性。AI目前主要侧重于处理逻辑和分析任务,而人类则具有更复杂的思维能力和情感经验。 人类已经成功地将一些可以数据化和程序化的理性和感性特征…...
最新AIGC创作系统ChatGPT系统源码+DALL-E3文生图+图片上传对话识图/支持OpenAI-GPT全模型+国内AI全模型
一、AI创作系统 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI…...
在centos7上源码安装nginx
1. 安装必要的编译工具和依赖项 在编译Nginx之前,你需要安装一些编译工具和依赖项。可以通过以下命令安装: yum install gcc-c pcre-devel zlib-devel make 2. 下载Nginx源代码 从Nginx官网下载最新的源代码。你可以使用wget命令来下载: …...
Html网页threejs显示obj,ply三维图像实例
程序示例精选 Html网页threejs显示obj,ply三维图像实例 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《Html网页threejs显示obj,ply三维图像实例》编写代码,代码整洁࿰…...
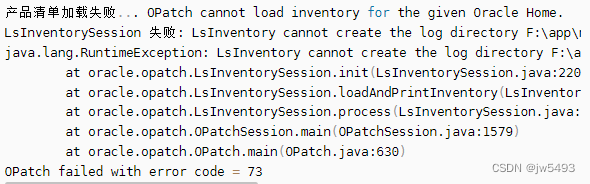
Windows平台下的oracle 11G-11.2.0.4补丁升级操作指南
序号 文件名称 文件说明 1 p6880880_112000_MSWIN-x86-64_OPatch 11.2.0.3.33 for DB 11.2.0.0.0 (Feb 2022) 用于升级 OPatch 2 DB_PSU_11.2.0.4.220118 (Jan 2022)_p33488457_112040_MSWIN-x86-64 主要补丁文件 注意:请用管理员权限运行文件内命令&#…...
模式评估)
Piggy_Packages V2026.1 帮助文档(九)模式评估
获取Piggy_Packages 还没有Piggy_Packages的同学,请参考这篇帖子获取: Piggy_Packages V2026.1 帮助文档(一)开箱即用 模型评估工具(MET)是一种常用的对WRF预报结果进行评估的工具。今天我们来学习一项它…...

AI读脸术分布式部署:多节点负载均衡实战方案
AI读脸术分布式部署:多节点负载均衡实战方案 1. 项目背景与需求 在现代人工智能应用中,人脸属性识别技术已经成为许多业务场景的核心需求。从智能安防到个性化推荐,从用户分析到内容审核,准确快速的年龄和性别识别能力正在发挥越…...

【WORD】【域】论文排版
自动目录(TOC){ TOC \o "1-3" \h \z \u }\o "1-3":提取样式 1~3 级标题\h:点击跳转\z:不显示隐藏文字\u:同时读取自定义大纲级别标题总页数当前节总页数 { SECTIONPAGES }全文总…...

1篇2章10节:介绍 CO-STAR 提示词工程框架
CO-STAR 框架的核心理念是将系统化目标管理的思路应用于提示词设计。框架由六大要素组成,通过系统化拆解,CO-STAR 帮助用户将复杂或多维任务转化为结构化、可控的提示词,提升 AI 理解和执行的准确性。CO-STAR 提示词工程框架在现代社会&#…...
)
别再为Carla找模型发愁了!手把手教你用Blender 3.0+UE4插件自制专属车辆(附完整FBX导出避坑指南)
从零打造Carla仿真专属车辆:Blender 3.0与UE4插件全流程实战 在自动驾驶仿真领域,Carla凭借其开源特性和逼真的物理引擎已成为行业标杆工具。但许多开发者都会遇到一个共同困境:官方提供的车辆模型库无法满足特定需求,无论是特种工…...
)
不止写文章!用Gutenberg区块编辑器5分钟打造高转化落地页(实战案例)
用Gutenberg区块编辑器5分钟打造高转化落地页(实战指南) 在数字营销领域,落地页的转化率直接影响业务成败。传统建站工具要么过于复杂(如Elementor、Divi),要么功能受限(如经典编辑器࿰…...

Wan2.1效果展示:从萌宠到科幻,AI视频生成作品集
Wan2.1效果展示:从萌宠到科幻,AI视频生成作品集 1. 开篇:AI视频生成的新纪元 想象一下,你只需要输入一段文字描述,就能立刻获得一段高质量的视频内容。这不再是科幻电影中的场景,而是阿里巴巴开源的Wan2.…...
)
OpenClaw本地部署指南|nanobot镜像预置GPU监控Dashboard(Grafana+Prometheus模板)
OpenClaw本地部署指南|nanobot镜像预置GPU监控Dashboard(GrafanaPrometheus模板) 1. 项目简介 nanobot是一款受OpenClaw启发的超轻量级个人人工智能助手,仅需约4000行代码就能提供核心代理功能,比传统方案的代码量减…...

YOLOv8头部改进全攻略:从SEAM到MultiSEAM的代码实现与效果对比
YOLOv8头部改进全攻略:从SEAM到MultiSEAM的代码实现与效果对比 在目标检测领域,YOLO系列模型因其卓越的实时性能而广受欢迎。YOLOv8作为最新一代的代表,其头部结构的设计直接影响着检测精度与速度。本文将深入探讨两种创新性头部改进方案——…...

你花了几个月搭的 RAG 知识库,可能从一开始方向就错了:Karpathy 的 LLM Wiki 模式全解析
知识管理这个概念比计算机还早。 1945 年,Vannevar Bush 在《Atlantic Monthly》上发了篇文章叫《As We May Think》,提出了一个叫 Memex 的概念——一台可以装载所有书籍和记录,并能把各种材料串连起来的机器。 这大概就是"个人知识库&…...