Spark on YARN运行过程,YARN-Client和YARN-Cluster
Spark on YARN运行过程
YARN是一种统一资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapReduce、storm等计算框架。Spark基于此种情况开发了Spark on YARN的运行模式,由于借助了YARN良好的弹性资源管理机制,不仅部署Application更加方便,而且用户在YARN集群中运行的服务和Application的资源也完全隔离,更具实践应用价值的是YARN可以通过队列的方式,管理同时运行在集群中的多个服务。
Spark on YARN模式根据Driver在集群中的位置分为两种模式:一种是YARN-Client模式,另一种是YARN-Cluster。
YARN-Client
简单版本
1、在客户端执行提交命令,在本地启动一个Drive进程.
2、Drive进程启动完毕后,会向ResourceManager申请启动一个ApplicationMaster.
3、RM 收到请求,随机选择一台 NodeManager 启动 ApplicationMaster.
4、AM启动后,会向RM请求一批Container资源(用于启动Executor).
5、RM会找到一批NM返回给AM,AM会向NM发送命令启动Executor.
6、Executor启动后,会反向注册给Driver,Driver发送Task到Executor.
详细版本
YARN-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark
Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问。
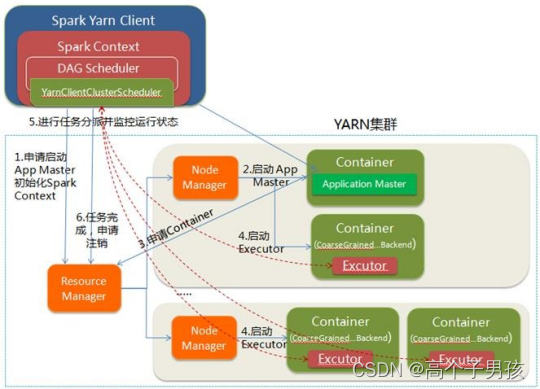
YARN-Client的工作流程分为以下几个步骤:
1.Spark YARN Client向YARN的ResourceManager申请启动ApplicationMaster。同时在SparkContent初始化中将创建DAGScheduler和TaskScheduler等,由于我们选择的是YARN-Client模式,程序会选择
YARNClientClusterScheduler和YARNClientSchedulerBackend;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动
CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
总结
YARN-Client模式适用于测试,因为Driver运行在本地,Driver会与YARN集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加
ApplicationMaster的作用:
1、为当前的Application申请资源
2、给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExcutor和申请资源的功能,并没有作业调度的功能。
YARN-Cluster
简单版本
执行流程
1、客户端执行提交命令,并不会启动Drive进程,客户端向RM申请启动一个ApplicationMaster
2、RM收到请求后随机在一台NM上启动AM(相当于Driver端)
ApplicationMaster(Driver)启动成功后向RM申请资源
3、AM启动后,AM发送请求到RM,请求一批Container(用于启动Excutor)。
4、RM返回一批NM节点给AM,AM发送请求到NM启动Executor。
5、 Executor反向注册到AM所在的节点的Driver。Driver发送Task到Executor。
详细版本
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成。
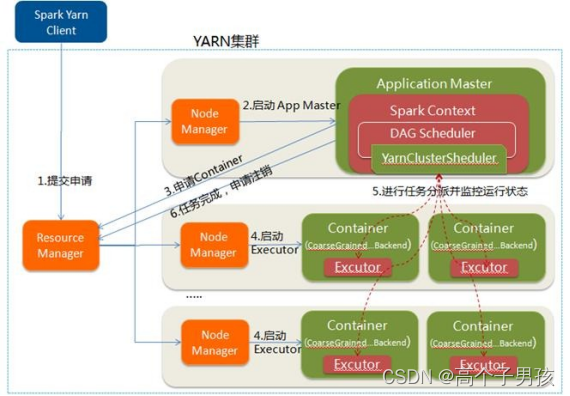
YARN-Cluster的工作流程分为以下几个步骤:
1.Spark YARN Cluster向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3.ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YARNClusterScheduler进行任务的调度,其中YARNClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5.ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
总结
YARN-Cluster主要用于生产环境中,因为Driver运行在YARN集群中某一台NodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过YARN查看日志。
ApplicationMaster的作用:
1、为当前的Application申请资源。
2、给NameNode发送消息启动Excutor。
3、任务调度。
相关文章:
Spark on YARN运行过程,YARN-Client和YARN-Cluster
Spark on YARN运行过程 YARN是一种统一资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapRed…...
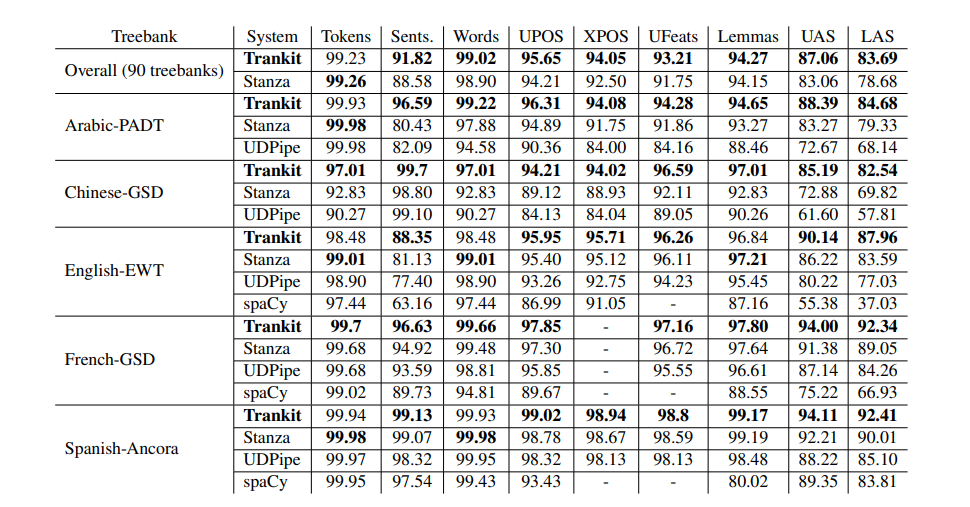
NLP中一些工具列举
文章目录StanfordcoreNLPStanzaTankitspaCySuPar总结StanfordcoreNLP 这个老早就出来了,用java写的,但是已经有很多比他效果好的了。 Stanza 2020ACL发表的,看名字就知道和上一个是同一家的。 用已经切好词的句子进行依存分析。 这个功能…...

面试官:给你一段有问题的SQL,如何优化?
大家好,我是飘渺!我在面试的时候很喜欢问候选人这样一个问题:“你在项目中遇到过慢查询问题吗?你是怎么做SQL优化的?”很多时候,候选人会直接跟我说他们在编写SQL时会遵循的一些常用技巧,比如&a…...

嵌入式 Linux 文件IO操作
目录 Linux 文件操作 1 Linux 系统环境文件操作概念 2 缓冲 IO 文件操作 1 文件的创建,打开与关闭 fopen 函数函数 2 freopen 函数 3、fdopen函数 4、fclose函数 5、格式化读写 6、单个字符读写 7、文件定位 8、标准目录文件 9、非缓冲IO文件操作 Linux 文…...
植物大战 二叉搜索树——C++
这里是目录标题二叉排序树的概念模拟二叉搜索树定义节点类insert非递归Finderase(重点)析构函数拷贝构造(深拷贝)赋值构造递归FindRInsertR二叉搜索树的应用k模型KV模型二叉排序树的概念 单纯的二叉树存储数据没有太大的作用。 搜索二叉树作用很大。 搜索二叉树的一般都是用…...

[MatLab]矩阵运算和程序结构
一、矩阵 1.定义 矩阵以[ ]包含,以空格表示数据分隔,以;表示换行。 A [1 2 3 4 5 6] B 1:2:9 %1-9中的数,中间是步长(不能缺省) C repmat(B,3,2) %将B横向重复2次,纵向重复2次 D ones(2,4) …...

【Leedcode】栈和队列必备的面试题(第四期)
【Leedcode】栈和队列必备的面试题(第四期) 文章目录【Leedcode】栈和队列必备的面试题(第四期)一、题目二、思路图解1.声明结构体2.循环链表开辟动态结构体空间3.向循环队列插入一个元素4.循环队列中删除一个元素5. 从队首获取元…...
Windows Server 2016搭建文件服务器
1:进入系统在服务器管理器仪表盘中添加角色和功能。 2:下一步。 3:继续下一步。 4:下一步。 5:勾选Web服务器(IIS) 6:添加功能。 7:下一步。 8:下一步。 9:下一步。 10&a…...
零基础学SQL(十一、视图)
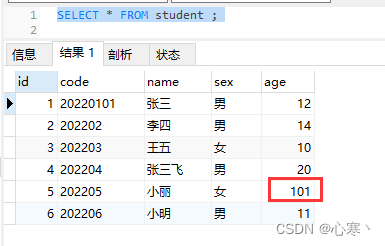
目录 前置建表 一、什么是视图 二、为什么使用视图 三、视图的规则和限制 四、视图的增删改查 五、视图数据的更新 前置建表 CREATE TABLE student (id int NOT NULL AUTO_INCREMENT COMMENT 主键,code varchar(255) NOT NULL COMMENT 学号,name varchar(255) DEFAULT NUL…...
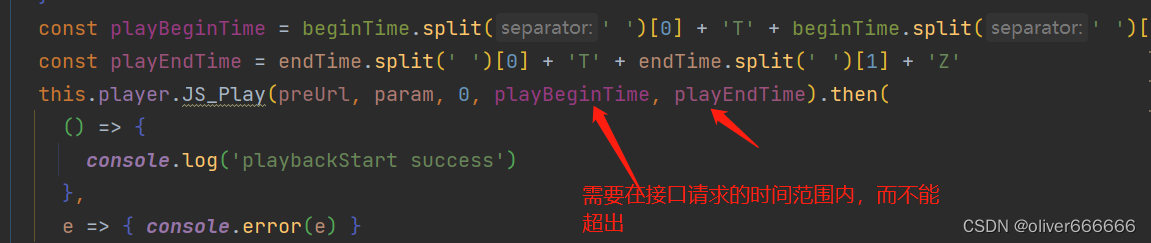
web,h5海康视频接入监控视频流记录三(后台node取流)
前端vue,接入ws视频播放 云台控制 ,回放预览,都是需要调对应的海康接口。相当于,点击时,请求后台写好的接口,接口再去请求海康的接口 调用云台控制是,操作一次,不会自己停止&#x…...
网络安全从入门到精通:30天速成教程到底有多狠?你能坚持下来么?
毫无疑问,网络安全是当下最具潜力的编程方向之一。对于许多未曾涉足计算机编程的领域「小白」来说,深入地掌握网络安全看似是一件十分困难的事。至于一个月能不能学会网络安全,这个要看个人,对于时间管理不是很高的,肯…...

世界上最流行的编程语言,用户数超过Python,Java,JavaScript,C的总和!
世界上最流行的编程语言是什么? Python? Java? JavaScript? C?都不是,是Excel!外媒估计,全球有12亿人使用微软的Office套件,其中估计有7.5亿人使用Excel!可是Excel不就是能写点儿公式&#x…...

杂谈:created中两次数据修改,会触发几次页面更新?
面试题:created生命周期中两次修改数据,会触发几次页面更新? 一、同步的 先举个简单的同步的例子: new Vue({el: "#app",template: <div><div>{{count}}</div></div>,data() {return {count…...

原生JS实现拖拽排序
拖拽(这两个字看了几遍已经不认识了) 说到拖拽,应用场景不可谓不多。无论是打开电脑还是手机,第一眼望去的界面都是可拖拽的,靠拖拽实现APP或者应用的重新布局,或者拖拽文件进行操作文件。 先看效果图&am…...

Coredump-N: corrupted double-linked list
文章目录 问题安装debuginfo之后分析参数确定确定代码逻辑解决问题 今天碰到一例: #0 0xf7f43129 in __kernel_vsyscall () #1 0xf6942b16 in raise () from /lib/libc.so.6 #2 0xf6928e64 in abort () from /lib/libc.so.6 #3 0xf6986e8c in __libc_message () from /lib/li…...

5个好用的视频素材网站
推荐五个高质量视频素材网站,免费、可商用,赶紧收藏起来! 1、菜鸟图库 视频素材下载_mp4视频大全 - 菜鸟图库 网站素材非常丰富,有平面、UI、电商、办公、视频、音频等相关素材,视频素材质量很高,全部都是…...

使用码匠连接一切|二
目录 Elasticsearch Oracle ClickHouse DynamoDB CouchDB 关于码匠 作为一款面向开发者的低代码平台,码匠提供了丰富的数据连接能力,能帮助用户快速、轻松地连接和集成多种数据源,包括关系型数据库、非关系型数据库、API 等。平台提供了…...

3.1.1 表的相关设计
文章目录1.表中实体与实体对应的关系2.实际案例分析3.表的实际创建4.总结1.表中实体与实体对应的关系 一对多 如一个班级对应多名学生,一个客户拥有多个订单等这种类型表的建表要遵循主外键关系原则,即在从表创建一个字段,此字段作为外键指向…...
Vue3 企业级项目实战:认识 Spring Boot
Vue3 企业级项目实战 - 程序员十三 - 掘金小册Vue3 Element Plus Spring Boot 企业级项目开发,升职加薪,快人一步。。「Vue3 企业级项目实战」由程序员十三撰写,2744人购买https://s.juejin.cn/ds/S2RkR9F/ 越来越流行的 Spring Boot Spr…...
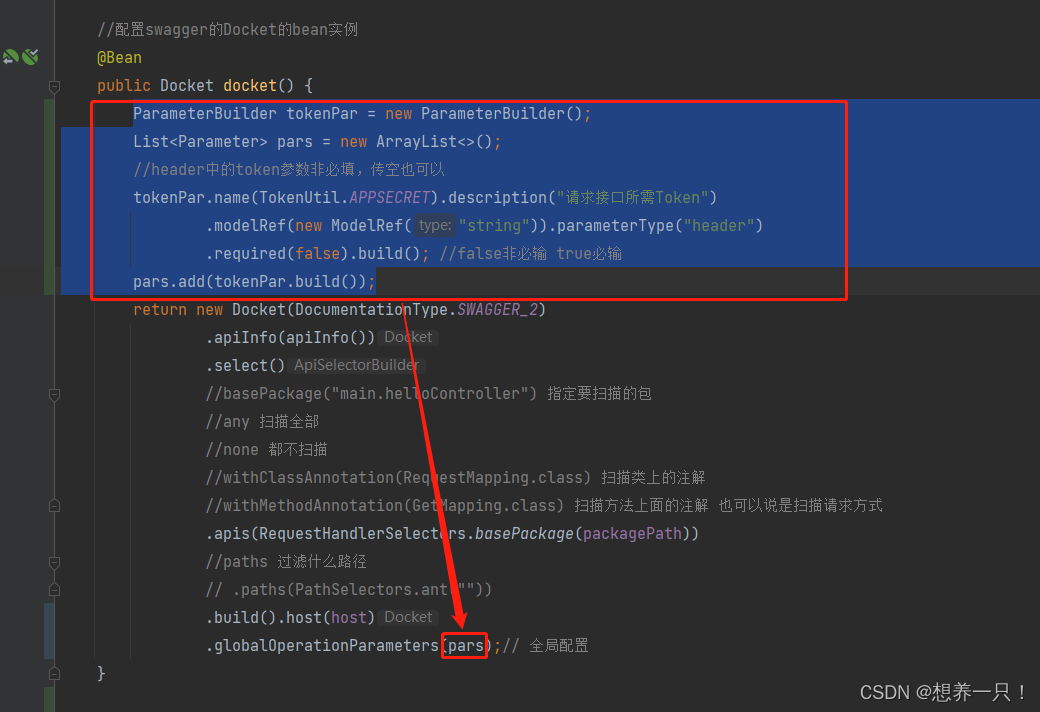
Swagger2实现配置Header请求头
效果 实现 大家使用swagger肯定知道在代码中会写一个 SwaggerConfig 配置类,如果没有这个类swagger指定也用不起来,所以在swagger中配置请求头也是在这个 SwaggerConfig 中操作。 1、要实现配置请求头在配置swagger的Docket的bean实例中添加一个 globa…...

Flutter 轻量存储方案介绍、区别、对比和使用场景
在 Flutter 项目中,本地存储通常可以分为几类: 第一类是轻量 Key-Value 存储,例如 shared_preferences、get_storage、mmkv,适合保存开关、配置、登录状态等简单数据。 第二类是安全存储,例如 flutter_secure_storage&…...

秋招编程面试,应届生必备的面试技巧,通过率直接翻倍
文章目录前言一、2026秋招编程面试新趋势:别再用老方法准备,踩坑就出局1.1 八股文不再是核心,底层理解才是硬通货1.2 代码手撕重思路轻结果,工程思维成加分项1.3 项目经历拒绝烂大街,真实落地细节把控是关键二、简历优…...

智能体可观测性实践:元观察技能的设计、集成与效能优化
1. 项目概述:一个面向智能体的“元观察者”技能最近在折腾智能体(Agent)开发的朋友,可能都遇到过类似的问题:你精心设计了一个智能体,给它配备了各种工具和技能,希望它能自主、流畅地完成一系列…...
首次公开)
为什么顶尖SRE团队已停用Ctrl+F搜索Stack Overflow?Perplexity智能查询协议(P-SOQ v2.1)首次公开
更多请点击: https://intelliparadigm.com 第一章:为什么顶尖SRE团队已停用CtrlF搜索Stack Overflow?Perplexity智能查询协议(P-SOQ v2.1)首次公开 搜索范式的根本性迁移 传统 SRE 工作流中,工程师依赖关…...

本地AI自动化工具monoClaw:让AI直接执行你的命令行指令
1. 项目概述:一个真正为你干活的本地AI自动化工具如果你也厌倦了在聊天窗口和终端之间来回切换,输入一个指令还得等AI生成代码,再手动复制粘贴去执行,那么monoClaw的出现,可能正是你期待的那个转折点。这个由codewithf…...

FMCP协议:构建创作者统一文件管理中枢,打破应用孤岛
1. 项目概述:一个为创作者而生的文件管理中枢如果你是一位内容创作者,无论是视频剪辑师、摄影师、平面设计师,还是播客制作人,你的工作流里一定少不了与海量文件打交道。原始素材、工程文件、渲染输出、版本迭代……这些文件散落在…...

Radon实战指南:在CI/CD中集成Python代码质量检查的完整教程
Radon实战指南:在CI/CD中集成Python代码质量检查的完整教程 【免费下载链接】radon Various code metrics for Python code 项目地址: https://gitcode.com/gh_mirrors/rad/radon Radon是一个强大的Python代码质量分析工具,能够帮助开发者自动检测…...

家用扫地机器人研发技术路线
第四部分:如何一步步做出来 | 18个月 4阶段 从原型到量产 摘要:本文详细介绍了扫地机器人从原型到量产的研发流程,分为4个关键阶段。首先聚焦四大技术难点:SLAM定位、AI视觉识别、仿生机械臂和静音风机系统。研发过程包括实验室原型验证、工程样机测试、小批量真实场景测…...

Windows安全组件深度解析与优化:2025专业版系统性能调优完整指南
Windows安全组件深度解析与优化:2025专业版系统性能调优完整指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_m…...

信发系统-排版/发布 配置操作教程-智慧大屏幕—东方仙盟
政务大屏幕节目管理-选择系统模板选择对应行业选择适合的模板选中你的节目点击设计设计节目直接管理/上传 资源:图片/视频/网页/文字/文档手指/鼠标选中显示区域上传资源,在右侧点击上传从资源库选择图片选择历史素材上传网站选中网页区域点击上传配置文…...