函数式接口
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
咱们今天讨论下函数式接口
以Predicate为例,之前在分析山寨Stream API时,我们已经不知不觉使用过函数式接口:

// 1.用Lambda表达式实现Predicate接口的抽象方法test(),并赋值给函数式接口
Predicate<User> ifHigherThan180 = user -> user.getHeight()>180;
// 2.作为参数传入filter(Predicate<T> ifHigherThan180),filter()会在内部调用test()用来判断
ifHigherThan180.test(user);总的来说,就是把方法A(Lambda)传给方法B(filter),然后在方法B内部调用方法A完成一些操作:
public void methodB(method a) {// 操作1// 调用method a// 操作3
}我们可以理解为Java8支持传递方法(之前只能传递基本数据类型和引用类型),也可以按原来面向对象的思维将Lambda理解为“特殊的匿名对象”。
为什么函数式接口很重要
有些同学应该会有疑问:
函数式接口有什么好讲的,我们不是在《Lambda表达式》中学过了吗?
不,当时只是向大家介绍了函数式接口的定义:
有且仅有一个抽象方法的接口(不包括默认方法、静态方法以及对Object方法的重写)
就我个人学习体会来看,函数式接口虽然不难,但作为参数类型出现时,经常会让初学者感到无所适从,甚至不知道该传递什么。比如Stream API中就大量使用了函数式接口接收形参:

CompletableFuture中也大量使用了函数式接口:

不知道大家是否曾经在调用filter()、supplyAsync()等方法时感到迷茫,起码我刚接触Java8时,每次调用这些方法都力不从心,不知道该传什么进去,也不知道Lambda表达式该怎么写。
如果你问我函数式接口难吗,我大概率会告诉你,它本身很简单。但如果你问我函数式接口重要吗,我会告诉你,它非常非常重要,能否熟练使用Java8的诸多新特性(Stream、CompletableFuture等)取决于你对函数式接口的熟悉程度。
函数式接口的类型
根据方法的出入参类型不同,各种排列组合后,其实有很多种类型,最常用的有以下4种函数式接口:
public class FunctionalInterfaceTest {/*** 给函数式接口赋值的格式:* 函数式接口 = 入参 -> 出参/制造出参的语句** @param args*/public static void main(String[] args) {FunctionalInterface1 interface1 = str -> System.out.println(str);FunctionalInterface2 interface2 = () -> {return "abc";};FunctionalInterface3 interface3 = str -> Integer.parseInt(str);FunctionalInterface4 interface4 = str -> str.length() > 3;}/*** 消费型,吃葡萄不吐葡萄皮:有入参,无返回值* (T t) -> {}*/interface FunctionalInterface1 {void method(String str);}/*** 供给型,无中生有:没有入参,却有返回值* () -> T t*/interface FunctionalInterface2 {String method();}/*** 映射型,转换器:把T转成R返回* T t -> R r*/interface FunctionalInterface3 {int method(String str);}/*** 特殊的映射型:把T转为boolean* T t -> boolean*/interface FunctionalInterface4 {boolean method(String str);}
}
大家看,以上函数式接口是我自定义瞎写的,但牢牢把握了住了出入参的特点(接口名、方法名不重要),代表了4种不同的函数式接口。正因为各自出入参不同,导致Lambda表达式的写法也不同。
函数式接口的作用
实际开发中,出入参类型的排列组合是有限的,所以JDK干脆内置了一部分函数式接口。一般来说,我们只需熟练掌握以下4大核心函数式接口即可:
- 消费型接口 Consumer<T> void accept(T t)
- 供给型接口 Supplier<T> T get()
- 函数型接口 Function<T, R> R apply(T t)
- 断定型接口 Predicate<T> boolean test(T t)
为什么JDK要在Java8这个版本引入函数式接口,并且提供这么多内置接口呢?
其实这些接口本不是给我们用的,而是JDK自己要用。
还记得前几章我编写的山寨Stream API吗?为了顺利构造出山寨Stream API,我自定义了Predicate接口和Function接口:
/*** 新建Predicate接口** @param <T>*/
@FunctionalInterface
interface Predicate<T> {/*** 定义了一个test()方法,传入任意对象,返回true or false,具体判断逻辑由子类实现** @param t* @return*/boolean test(T t);
}// Function接口 略...同样的,我和Java8一样,也把Predicate接口作为形参类型(详见myPrint方法):
public class MockStream {public static void main(String[] args) {Person bravo = new Person("bravo", 18);// 1.匿名对象,调用它的test()方法Predicate<Person> predicate1 = new Predicate<Person>() {@Overridepublic boolean test(Person person) {return person.getAge() < 18;}};myPrint(bravo, predicate1); // false// 2.Lambda表达式,调用它的test()方法。// 按照Lambda表达式的标准,只要你是个函数式接口,那么就可以接收Lambda表达式Predicate<Person> predicate2 = person -> person.getAge() == 18;myPrint(bravo, predicate2); // true}public static void myPrint(Person person, Predicate<Person> filter) {if (filter.test(person)) {System.out.println("true");} else {System.out.println("false");}}
}JDK之所以要在Java8内置那么多函数式接口,本质原因和我的山寨Stream API一样,是为了配合Java8的各种API。单独发布Stream API和CompletableFuture是不现实的,它们的方法形参都依赖函数式接口呢。
Java8函数式接口的作用和我们自定义的Predicate接口一样:
- 接收Lambda表达式/方法引用
- 占坑
或者说,这两个作用是一体两面的。
所谓占坑,之前已经提过了,这里再说一下吧。
比如新冠病毒爆发时,我们需要对潜在感染者进行检测,但检测的手段有很多,比如CT和核酸测试。
虽然定义getHealthPerson()时并不确定实际会采用哪种方式进行新冠检测,可能是CT也可能是核酸测试,具体由子类实现。但不管怎么说,有一点是肯定的:一定要测试。
此时如果创建一个函数式接口,定义boolean test()方法,并将getHealthPerson()的形参定为getHealthPerson(List<Person>, Predicate<Person>),就能保证未来无论是谁调用这个方法,都必须明确检测方法,也就是必须传入Predicate接口的实例或者Lambda表达式。
/*** 用Predicate占坑* @param uncheckPersonList* @param predicate* @return*/
public static List<Person> getHealthPerson(List<Person> uncheckPersonList, Predicate<Person> predicate) {ArrayList<Person> healthyPersonList = new ArrayList<>();for (Person person : uncheckPersonList) {// 占坑,反正需要检测,但是具体拍CT还是核酸检测具体情况具体分析if (predicate.test(person)) {healthyPersonList.add(person);}}return healthyPersonList;
}此后如果有其他方法调用getHealthPerson(),必须传入具体的检测手段:
public static void main(String[] args) throws JsonProcessingException {ArrayList<Person> uncheckPersonList = new ArrayList<>();uncheckPersonList.add(new Person("张三", 18));uncheckPersonList.add(new Person("李四", 20));// 传入Lambda表达式getHealthPerson(uncheckPersonList, person -> 核酸检测(person));getHealthPerson(uncheckPersonList, person -> 胸部CT(person));}这就是函数式接口的作用。
如何克服面向对象的思维惯性
对于函数式接口,上面已经讲得很多了,本身很简单,没什么好介绍的。这里主要聊一聊初学者应该如何习惯函数式接口传参的方式,以及关注点应该放哪里。换句话说,帮助初学者克服面向对象的思维惯性,学会用函数式编程的思维去使用Java8的诸多特性。
还是以Predicate为例,它唯一的抽象方法是:
boolean test(T t);假设有个方法叫:getHealthPerson(List<User> users, Predicate<User> filter),你知道该给filter传什么吗?
很多Java程序员会对这种传参形式感到眩晕,因为我们的潜意识一直无法摆脱面向对象的影响。当你看到getHealthPerson(List<User> users, Predicate<User> filter)时,你的大脑会告诉你Predicate是一个接口,所以应该传一个匿名对象给它。然后你的大脑自己也懵了,因为它突然发现光看Predicate接口,根本不知道该实现什么方法,甚至连入参和返回值都不清楚,怎么手写Lambda?
但之前介绍Python的函数时,我们很自然就接受了:
# encoding: utf-8# abs是Python的内置函数
result = abs(-1)
print(result)# 定义add()方法,f显然是一个函数
def add(x, y, f):return f(x) + f(y)print(add(-1, -2, abs))因为相比Python这些原本就支持函数式编程的语言来说,形参就是函数,不需要用接口做中间层过渡!而对于Stream这种面向对象世界中的异类,Java程序员还没准备好如何接纳它,看到接口形参第一时间想到的还是传匿名对象,突然要改成Lambda确实有点棘手,因为我们对接口内部的方法及出入参一概不知!
如何克服呢?两种方式:
- 以面向对象的思维直接new匿名对象,靠IDEA优化成Lambda(曲线救国,减少记忆负担)
- 每个函数式接口就一个方法,记住那个方法的出入参,看到接口就写对应方法的Lambda(需要记忆)
这里主要讲讲如何记忆函数式接口的方法。一定要注意,函数式接口的方法名字不重要,重要的是出入参:
- 消费型接口 Consumer<T> T t -> void 例:x -> System.out.println(x)
- 供给型接口 Supplier<T> () -> T t 例:() -> {return 1+2;}
- 映射型接口 Function<T, R> T t -> R r 例:user -> user.getAge(),T是入参,R是出参
- 断定型接口 Predicate<T> T t -> boolean 例:user -> user.getAge()>18
Consumer,消费型接口,是黑洞,只管吃(C),不会往外吐,所以只有入参,没有返回值。
Supplier,供给型接口,是泉眼,不断往外涌出泉水(S),不需要入参,有返回值。
Function,映射型接口,就是高中数学的函数映射,x --> f(x) --> result,所以有入参,也有返回值。
Predicate,断定型接口,是特殊的映射函数,x --> f(x) --> boolean,只会评(P)论true/false。
如果你觉得口诀很生硬,就把上面的例子记住,把每个函数式接口都和一个例子绑定,实际开发时去套用例子即可。
记住了接口对应的出入参,Lambda就好办了,其实传递的都是:
接口声明 = 入参 -> 出参/制造出参的语句
不信你可以重新看看上面给出的例子,比如Function:user -> user.getAge(),就是把User user映射为Integer age,user是入参,user.getAge()是制造出参的语句。又比如Predicate:user -> user.getAge()>18,user是入参,user.getAge()>18就是制造出参的语句,因为boolean test(T t)需要返回boolean。
所以要习惯函数式接口传参,最重要的是记住该接口对应的方法的出入参,然后编写Lambda时套用模板:
接口声明 = 入参(有无入参?) -> 出参/制造出参的语句(有无出参?什么类型?)
虽然我们还没正式学习Stream API,但已经可以试着写写啦:
public class FunctionalInterfaceTest {public static void main(String[] args) {List<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6));/*** Predicate:特殊映射,只断是非 Function:T t --> f(x) --> boolean* Function:映射 Function:T t --> f(x) --> R r*/list.stream().filter().map().collect(Collectors.toList());// Supplier,无源之水(S),却滔滔不绝,没有入参,却可以get()CompletableFuture<Object> completableFuture = CompletableFuture.supplyAsync();// Consumer,黑洞,吃(C)葡萄不吐葡萄皮,入参拿过来就是一顿操作,不返回completableFuture.thenAccept();}}私底下多写几次,形成肌肉记忆就好啦。我们走路时,虽然确实有一个规则:左右脚要交替向前,但我们实际行走时从来不会意识到这个规则,否则就走太慢了!
函数式接口与类型推断
之前在《Lambda表达式》中,我举过一个例子:

当接口内只有一个抽象方法时,可以使用Lambda表达时给接口赋值:
MyInterface interface = () -> System.out.println("吃东西");
但如果函数式接口内有多个方法抽象方法,就无法传递Lambda表达式:


此时只能传入匿名对象分别实现两个抽象方法:

学完这一章,相信大家会有更深刻的理解:
public void run()和public void eat()如果只看出入参,其实是一样的,所以编译时无法自动推断。
由于本章节一直在强调函数式接口传参,所以这里再给出一个例子:
public class FunctionalInterfaceTest {public static void main(String[] args) {// Ambiguous method calllambdaMethod(() -> System.out.println("test"));}/*** 方法重载** @param param1*/public static void lambdaMethod(Param1 param1) {param1.print();}/*** 方法重载** @param param2*/public static void lambdaMethod(Param2 param2) {param2.print();}/*** 函数式接口1*/interface Param1 {void print();}/*** 函数式接口2*/interface Param2 {void print();}}
原因也是一样的,Lambda只关注方法的出入参,所以在进行类型推断时,interface Param1和interface Param2是一样的,编译器无法替我们决定实现哪一个接口,解决办法是使用匿名对象。
如果说《Lambda表达式》中举的例子是方法级别的推断冲突,那么上面的例子讲的就是接口级别的推断冲突,但归根结底就一句话:Lambda上下文推断只看出入参,无论是接口名还是方法名,都不重要!
所以,学习函数式接口最重要的就是记住出入参的格式!!
回顾ConvertUtil
之前在《实用小算法》中我们封装过一个工具类,当时大家可能对于函数式接口并不熟悉,现在重新复习一下,看看自己能否完全理解这个工具类的设计细节:
public class ConvertUtil {private ConvertUtil() {}/*** 将List转为Map** @param list 原数据* @param keyExtractor Key的抽取规则* @param <K> Key* @param <V> Value* @return*/public static <K, V> Map<K, V> listToMap(List<V> list, Function<V, K> keyExtractor) {if (list == null || list.isEmpty()) {return new HashMap<>();}Map<K, V> map = new HashMap<>(list.size());for (V element : list) {K key = keyExtractor.apply(element);if (key == null) {continue;}map.put(key, element);}return map;}/*** 将List转为Map,可以指定过滤规则** @param list 原数据* @param keyExtractor Key的抽取规则* @param predicate 过滤规则* @param <K> Key* @param <V> Value* @return*/public static <K, V> Map<K, V> listToMap(List<V> list, Function<V, K> keyExtractor, Predicate<V> predicate) {if (list == null || list.isEmpty()) {return new HashMap<>();}Map<K, V> map = new HashMap<>(list.size());for (V element : list) {K key = keyExtractor.apply(element);if (key == null || !predicate.test(element)) {continue;}map.put(key, element);}return map;}/*** 将List映射为List,比如List<Person> personList转为List<String> nameList** @param originList 原数据* @param mapper 映射规则* @param <T> 原数据的元素类型* @param <R> 新数据的元素类型* @return*/public static <T, R> List<R> resultToList(List<T> originList, Function<T, R> mapper) {if (originList == null || originList.isEmpty()) {return new ArrayList<>();}List<R> newList = new ArrayList<>(originList.size());for (T originElement : originList) {R newElement = mapper.apply(originElement);if (newElement == null) {continue;}newList.add(newElement);}return newList;}/*** 将List映射为List,比如List<Person> personList转为List<String> nameList* 可以指定过滤规则** @param originList 原数据* @param mapper 映射规则* @param predicate 过滤规则* @param <T> 原数据的元素类型* @param <R> 新数据的元素类型* @return*/public static <T, R> List<R> resultToList(List<T> originList, Function<T, R> mapper, Predicate<T> predicate) {if (originList == null || originList.isEmpty()) {return new ArrayList<>();}List<R> newList = new ArrayList<>(originList.size());for (T originElement : originList) {R newElement = mapper.apply(originElement);if (newElement == null || !predicate.test(originElement)) {continue;}newList.add(newElement);}return newList;}// ---------- 以下是测试案例 ----------private static List<Person> list;static {list = new ArrayList<>();list.add(new Person("i", 18, "杭州", 999.9));list.add(new Person("am", 19, "温州", 777.7));list.add(new Person("iron", 21, "杭州", 888.8));list.add(new Person("man", 17, "宁波", 888.8));}public static void main(String[] args) {Map<String, Person> nameToPersonMap = listToMap(list, Person::getName);System.out.println(nameToPersonMap);Map<String, Person> personGt18 = listToMap(list, Person::getName, person -> person.getAge() >= 18);System.out.println(personGt18);}@Data@AllArgsConstructor@NoArgsConstructorstatic class Person {private String name;private Integer age;private String address;private Double salary;}
}小试牛刀
实际开发中,经常会看到这样的写法:
public void XxMethod(){// ...List<Long> iidList = new ArrayList<>();List<Long> eventList = new ArrayList<>();if(items != null && items.size > 0) {for(Item item : items){iidList.add(item.getId());eventList.add(item.getEvent());}}// ...
}这里能用ConvertUtil的resultToList()吗?
答案是,不能。resultToList()一次只处理一个List,而上面一次循环可能处理N个List。所以我们能做的,只是抽取循环的操作,具体循环里做什么,每个List可能不同,不好抽取。
有了上面的经验,我们完全可以再给ConvertUtil封装个方法:
/*** foreach,内部判空** @param originList 需要遍历的List* @param processor 需要执行的操作* @param <T>*/
public static <T> void foreachIfNonNull(List<T> originList, Consumer<T> processor) {if (originList == null || originList.isEmpty()) {return;}for (T originElement : originList) {if (originElement != null) {processor.accept(originElement);}}
}public void XxMethod(){// ...List<Long> iidList = new ArrayList<>();List<Long> eventList = new ArrayList<>();ConvertUtil.foreachIfNonNull(items, item -> {iidList.add(item.getId());eventList.add(item.getEvent());})// ...
}上面相当于自己实现了foreach。你可能会想,为什么不直接用Stream API或者直接List.foreach()?原因在于它们都要额外判断非空,否则可能引发NPE。
最后留个思考题:自己实现groupBy()。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬
相关文章:
函数式接口
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 咱们今天讨论下函数式接…...
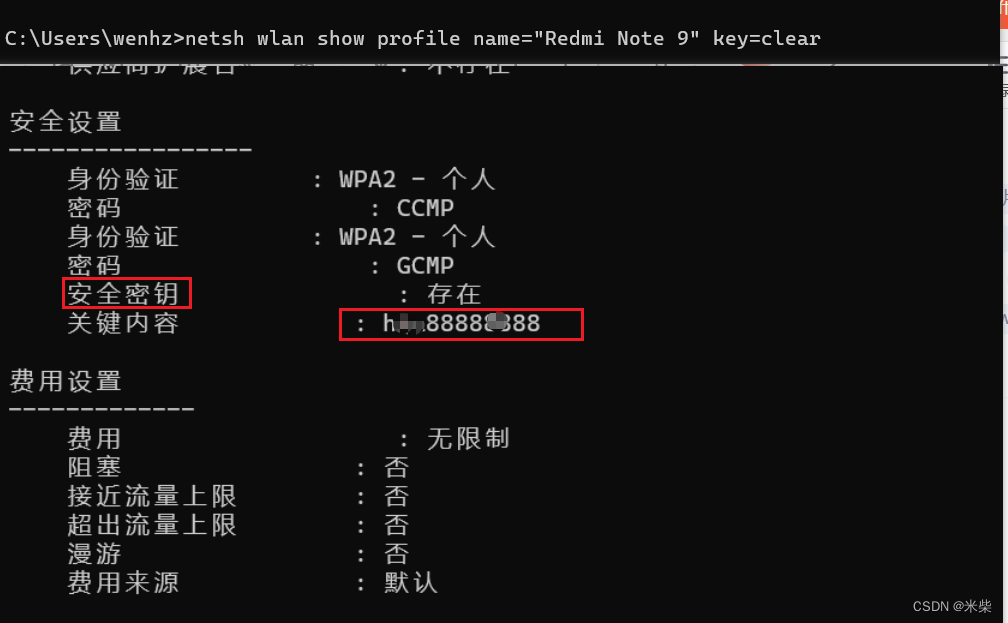
使用shell快速查看电脑曾经连接过的WiFi密码
此方法只能查看以前连接过的wifi名称和对应的密码 查看连接过的WiFi名称netsh wlan show profiles查看具体的WiFi名称netsh wlan show profile name"你的wifi名称" keyclear...
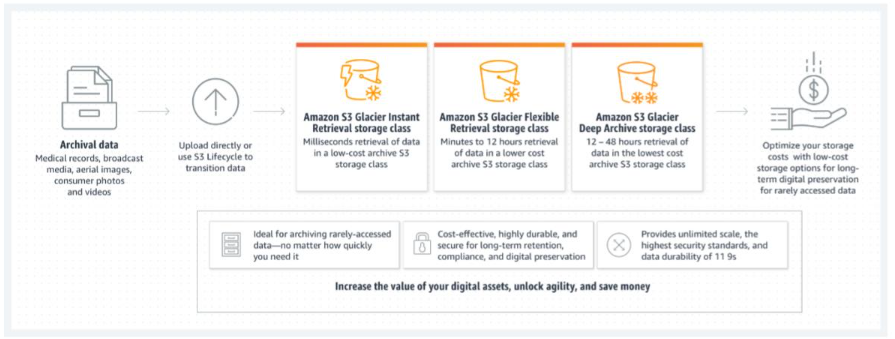
通过亚马逊云科技云存储服务探索云原生应用的威力
文章作者:Libai 欢迎来到我们关于“使用亚马逊云科技云存储服务构建云原生应用”的文章的第一部分。在本文中,我们将深入探讨云原生应用的世界,并探索亚马逊云科技云存储服务在构建和扩展这些应用中的关键作用。 亚马逊云科技开发者社区为开发…...

Boot工程快速启动【Linux】
Boot工程快速启动【Linux】 在idea中打包cd usr/在local文件夹下mkdir app进入app文件夹把打包好的文件(只上传其中的jar)上传到app文件下检查linux中的Java版本,保证和项目的Java 版本保持一致运行 java -jar sp补全***.jar想看效果得查询当…...
三 STM32F4使用Sys_Tick 实现微秒定时器和延时
更多细节参考这篇 1. 什么是时钟以及作用 1.1 什么是时钟 时钟是由电路产生的周期性的脉冲信号,相当于单片机的心脏 1.2 时钟对于STM32的作用 指令同步:cpu和内核外设使用时钟信号来进行指令同步数据传输控制: 时钟信号控制数据在内部总…...

唯创知音WT2003H系列MP3录音语音芯片:高精度ADC与DAC,强大IO驱动能力成就音频卓越
在音频领域里,高精度和强大的驱动能力一直是工程师们追求的目标。唯创知音的WT2003H系列MP3录音芯片恰好满足了这一需求,该芯片具备16 bit高精度的ADC及DAC功能,大功率的IO驱动能力,能够直接驱动64mA,为电子产品带来卓…...
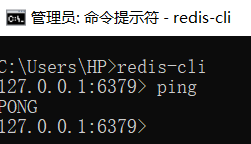
记录Windows下安装redis的过程
开源博客项目Blog支持使用EasyCaching组件操作redis等缓存数据库,在继续学习开源博客项目Blog之前,准备先学习redis和EasyCaching组件的基本用法,本文记录在Windows下安装redis的过程。 虽然redis官网文档写着支持Linux、macOS、Windows等…...
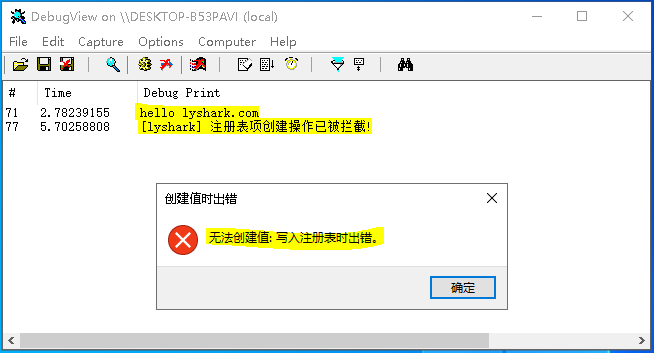
7.5 Windows驱动开发:监控Register注册表回调
在笔者前一篇文章《内核枚举Registry注册表回调》中实现了对注册表的枚举,本章将实现对注册表的监控,不同于32位系统在64位系统中,微软为我们提供了两个针对注册表的专用内核监控函数,通过这两个函数可以在不劫持内核API的前提下实…...

NC56 XML 报文校验出错一例
好好的上线了、下午开完会告诉我有个凭证没法传入 NC 了。 请求报文如下: <?xml version"1.0" encodingUTF-8?> <ufinterface roottag"voucher" billtype"gl" replace"Y" receiver"10108" sender&q…...
STM32 ADC转换器、串口输出
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、ADC是什么?二、STM32的ADC2.1 认识STM32 ADC2.2转换方式2.3 为什么要校准?2.4 采样时间计算2.5 触发方式2.6 多通道采集解决方案2.7…...
[MySQL--基础]函数、约束
hello! 这里是欧_aita的频道。 今日语录:不管你觉得自己能做什么,或者你觉得你不能做什么,你都是对的。 祝福语:愿你的程序像太阳一样明亮,给世界带来温暖和光明。 大家可以在评论区畅所欲言,可以指出我的错误…...

企业数字化决策者深度分享
2023年11月18日,数聚股份应邀参加在台州椒江举办的数字中国企业峰会。本次会议中,诸多在企业数字化进程中做出重要贡献的高层管理者分享了各行各业极具引领性、创新性的数字化实践案例、产品和解决方案;数聚股份董事长陈庆华携其前瞻的数字化…...

JMeter压测常见面试问题
1、JMeter可以模拟哪些类型的负载? JMeter可以模拟各种类型的负载,包括但不限于Web应用程序、API、数据库、FTP、SMTP、JMS、SOAP / RESTful Web服务等。这使得JMeter成为一个功能强大且灵活的压力测试工具。 2、如何配置JMeter来进行分布式压力测试&a…...

使用opencv将sRGB格式的图片转换为DCI-P3格式【sRGB】【DCI-P3】
要将图像从 sRGB 格式转换为 DCI-P3 格式,您需要使用适当的线性转换矩阵。在 OpenCV 中,这通常涉及使用色彩转换函数,但 OpenCV 默认情况下不直接支持 sRGB 到 DCI-P3 的转换。因此,您需要手动计算并应用转换矩阵。 转换矩阵取决…...

【协议设计与实现】Linux环境下,如何从0开始设计并实现一个网络协议之一——需要考虑的因素
🐚作者简介:花神庙码农(专注于Linux、WLAN、TCP/IP、Python等技术方向)🐳博客主页:花神庙码农 ,地址:https://blog.csdn.net/qxhgd🌐系列专栏:TCP/IP协议&…...

【前端】JS实现SQL格式化
sqlFormatter sql-formatter - npm (npmjs.com) const sqlFormatter require(/utils/sqlFormatter)let sql select count(1) as cnt from t_user where id < 7;// 格式化 // let sqlF sqlFormatter.format(sql);let sqlF sqlFormatter.format(sql, {language:mysql,})…...
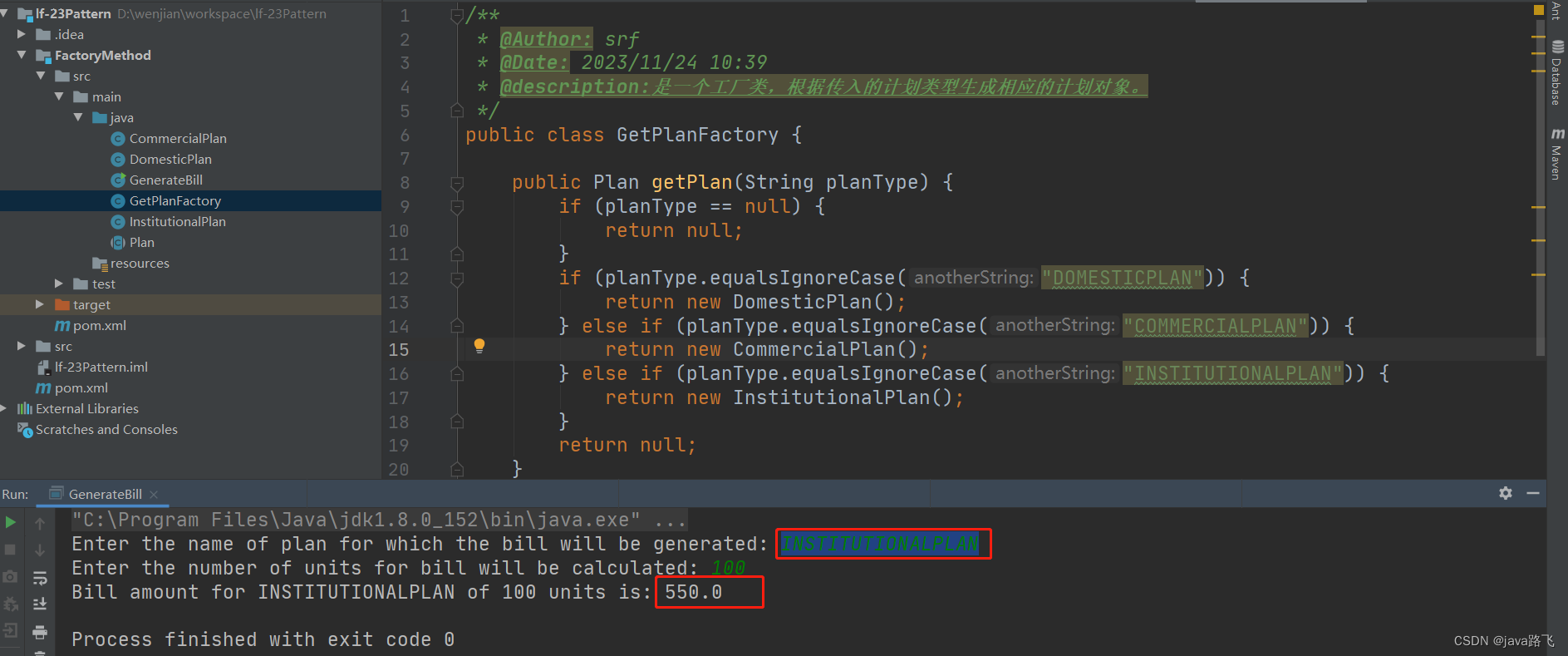
java设计模式学习之【工厂模式】
文章目录 引言工厂方法模式简介定义与用途:实现方式: 使用场景优势与劣势工厂模式在spring中的应用电费计算示例(简单工厂模式)改善为方法工厂模式代码地址 引言 在软件开发的世界中,对象的创建可能是一个复杂且重复的…...
)
android 内存分析(待续)
/proc/meminfo memory状态解读 命令:adb shell cat /proc/meminfo内存分布log 查看方式 命令:adb shell cat /proc/meminfo 用途:可以整体的了解memory使用情况 我们说的可用memory一般以MemAvailable的数据为准。所以了解MemAvailable的组成可以帮助…...

2023-简单点-机器学习中的数值计算问题
上溢和下溢: 上溢:指数函数或对数函数的输入值过大,导致计算结果超出了计算机可以表示的最大值。例如,在softmax函数中,当输入的数值很大时,指数运算的结果可能非常大,导致上溢。 下溢&#x…...

Qt5的事件处理函数有哪些?
2023年11月29日,周三上午 通过查看QWidget的定义可知,事件处理函数有: bool event(QEvent *event) override;virtual void mousePressEvent(QMouseEvent *event);virtual void mouseReleaseEvent(QMouseEvent *event);virtual void mouseDou…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

13456
12356...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...